 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Toward Automated Detection of Microbleeds with Anatomical Scale Localization: A Complete Clinical Diagnosis Support Using Deep Learning
Jun 22, 2023

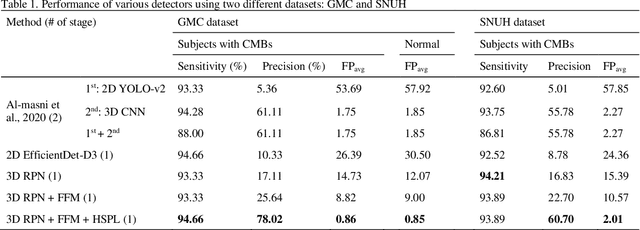
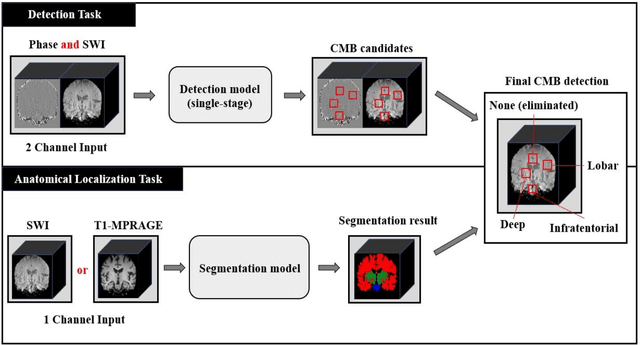
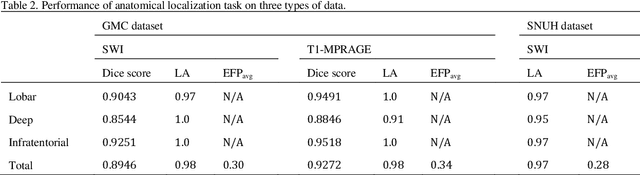
Cerebral Microbleeds (CMBs) are chronic deposits of small blood products in the brain tissues, which have explicit relation to various cerebrovascular diseases depending on their anatomical location, including cognitive decline, intracerebral hemorrhage, and cerebral infarction. However, manual detection of CMBs is a time-consuming and error-prone process because of their sparse and tiny structural properties. The detection of CMBs is commonly affected by the presence of many CMB mimics that cause a high false-positive rate (FPR), such as calcification and pial vessels. This paper proposes a novel 3D deep learning framework that does not only detect CMBs but also inform their anatomical location in the brain (i.e., lobar, deep, and infratentorial regions). For the CMB detection task, we propose a single end-to-end model by leveraging the U-Net as a backbone with Region Proposal Network (RPN). To significantly reduce the FPs within the same single model, we develop a new scheme, containing Feature Fusion Module (FFM) that detects small candidates utilizing contextual information and Hard Sample Prototype Learning (HSPL) that mines CMB mimics and generates additional loss term called concentration loss using Convolutional Prototype Learning (CPL). The anatomical localization task does not only tell to which region the CMBs belong but also eliminate some FPs from the detection task by utilizing anatomical information. The results show that the proposed RPN that utilizes the FFM and HSPL outperforms the vanilla RPN and achieves a sensitivity of 94.66% vs. 93.33% and an average number of false positives per subject (FPavg) of 0.86 vs. 14.73. Also, the anatomical localization task further improves the detection performance by reducing the FPavg to 0.56 while maintaining the sensitivity of 94.66%.
GraphSHA: Synthesizing Harder Samples for Class-Imbalanced Node Classification
Jun 16, 2023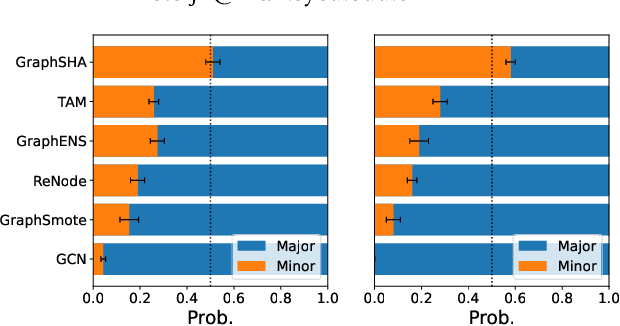
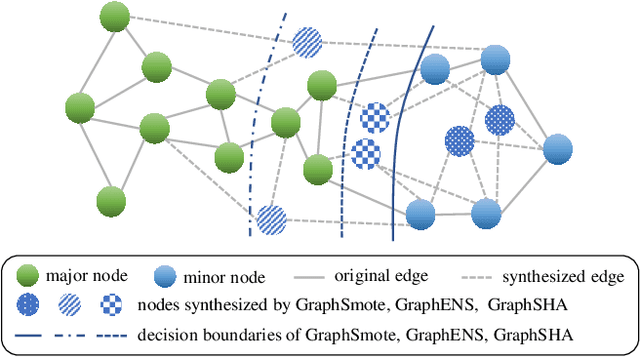
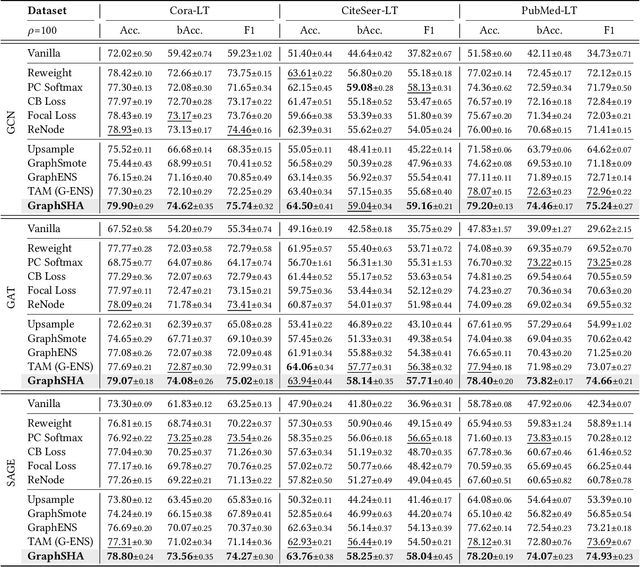
Class imbalance is the phenomenon that some classes have much fewer instances than others, which is ubiquitous in real-world graph-structured scenarios. Recent studies find that off-the-shelf Graph Neural Networks (GNNs) would under-represent minor class samples. We investigate this phenomenon and discover that the subspaces of minor classes being squeezed by those of the major ones in the latent space is the main cause of this failure. We are naturally inspired to enlarge the decision boundaries of minor classes and propose a general framework GraphSHA by Synthesizing HArder minor samples. Furthermore, to avoid the enlarged minor boundary violating the subspaces of neighbor classes, we also propose a module called SemiMixup to transmit enlarged boundary information to the interior of the minor classes while blocking information propagation from minor classes to neighbor classes. Empirically, GraphSHA shows its effectiveness in enlarging the decision boundaries of minor classes, as it outperforms various baseline methods in class-imbalanced node classification with different GNN backbone encoders over seven public benchmark datasets. Code is avilable at https://github.com/wenzhilics/GraphSHA.
SSE: A Metric for Evaluating Search System Explainability
Jun 16, 2023Explainable Information Retrieval (XIR) is a growing research area focused on enhancing transparency and trustworthiness of the complex decision-making processes taking place in modern information retrieval systems. While there has been progress in developing XIR systems, empirical evaluation tools to assess the degree of explainability attained by such systems are lacking. To close this gap and gain insights into the true merit of XIR systems, we extend existing insights from a factor analysis of search explainability to introduce SSE (Search System Explainability), an evaluation metric for XIR search systems. Through a crowdsourced user study, we demonstrate SSE's ability to distinguish between explainable and non-explainable systems, showing that systems with higher scores indeed indicate greater interpretability. Additionally, we observe comparable perceived temporal demand and performance levels between non-native and native English speakers. We hope that aside from these concrete contributions to XIR, this line of work will serve as a blueprint for similar explainability evaluation efforts in other domains of machine learning and natural language processing.
Multi-View Class Incremental Learning
Jun 16, 2023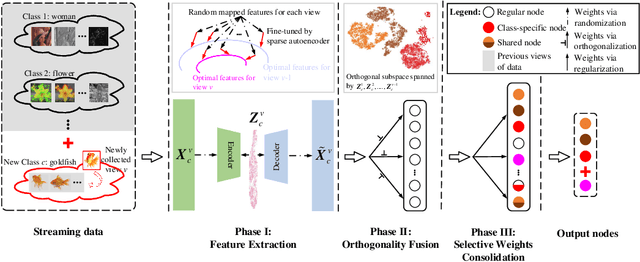
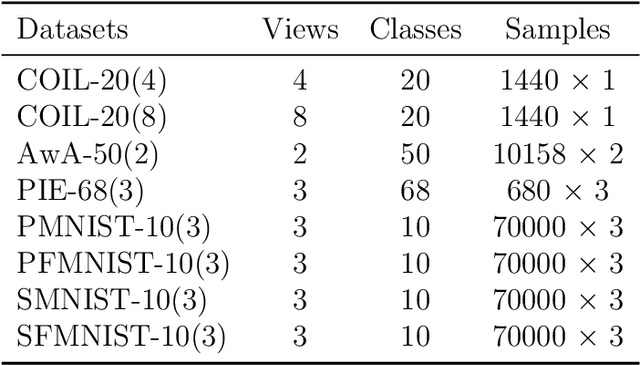
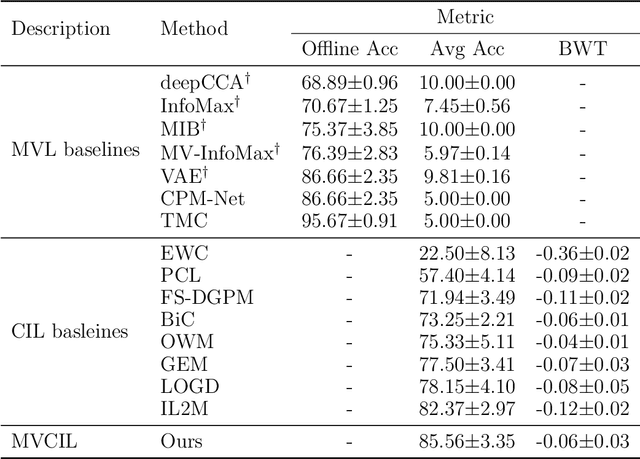
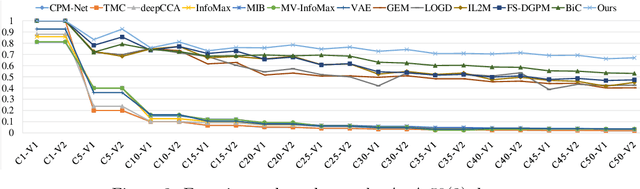
Multi-view learning (MVL) has gained great success in integrating information from multiple perspectives of a dataset to improve downstream task performance. To make MVL methods more practical in an open-ended environment, this paper investigates a novel paradigm called multi-view class incremental learning (MVCIL), where a single model incrementally classifies new classes from a continual stream of views, requiring no access to earlier views of data. However, MVCIL is challenged by the catastrophic forgetting of old information and the interference with learning new concepts. To address this, we first develop a randomization-based representation learning technique serving for feature extraction to guarantee their separate view-optimal working states, during which multiple views belonging to a class are presented sequentially; Then, we integrate them one by one in the orthogonality fusion subspace spanned by the extracted features; Finally, we introduce selective weight consolidation for learning-without-forgetting decision-making while encountering new classes. Extensive experiments on synthetic and real-world datasets validate the effectiveness of our approach.
Can Adversarial Examples Be Parsed to Reveal Victim Model Information?
Mar 15, 2023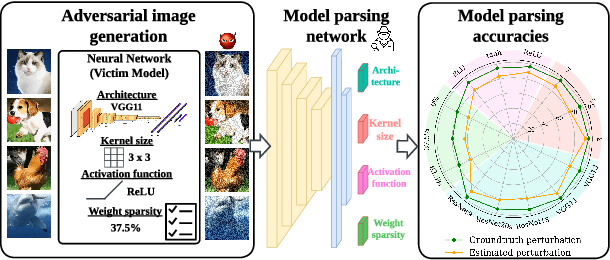
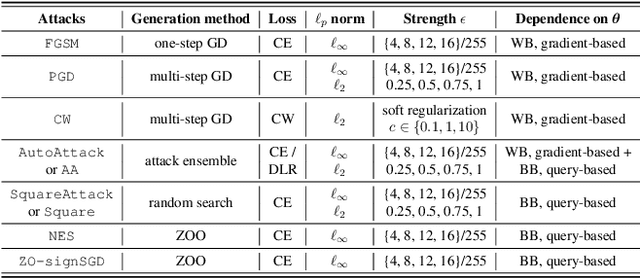
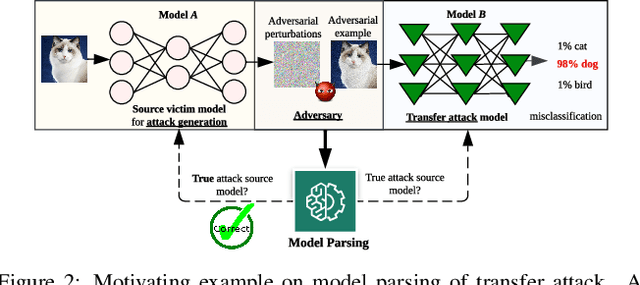
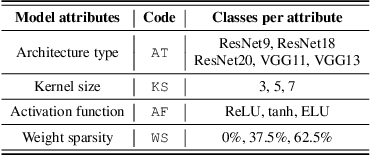
Numerous adversarial attack methods have been developed to generate imperceptible image perturbations that can cause erroneous predictions of state-of-the-art machine learning (ML) models, in particular, deep neural networks (DNNs). Despite intense research on adversarial attacks, little effort was made to uncover 'arcana' carried in adversarial attacks. In this work, we ask whether it is possible to infer data-agnostic victim model (VM) information (i.e., characteristics of the ML model or DNN used to generate adversarial attacks) from data-specific adversarial instances. We call this 'model parsing of adversarial attacks' - a task to uncover 'arcana' in terms of the concealed VM information in attacks. We approach model parsing via supervised learning, which correctly assigns classes of VM's model attributes (in terms of architecture type, kernel size, activation function, and weight sparsity) to an attack instance generated from this VM. We collect a dataset of adversarial attacks across 7 attack types generated from 135 victim models (configured by 5 architecture types, 3 kernel size setups, 3 activation function types, and 3 weight sparsity ratios). We show that a simple, supervised model parsing network (MPN) is able to infer VM attributes from unseen adversarial attacks if their attack settings are consistent with the training setting (i.e., in-distribution generalization assessment). We also provide extensive experiments to justify the feasibility of VM parsing from adversarial attacks, and the influence of training and evaluation factors in the parsing performance (e.g., generalization challenge raised in out-of-distribution evaluation). We further demonstrate how the proposed MPN can be used to uncover the source VM attributes from transfer attacks, and shed light on a potential connection between model parsing and attack transferability.
DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
Jun 25, 2023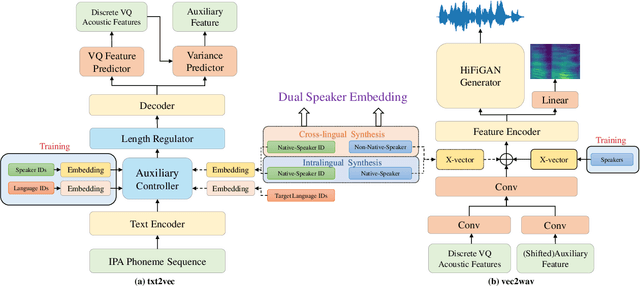
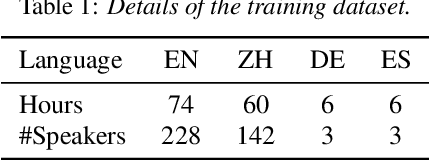
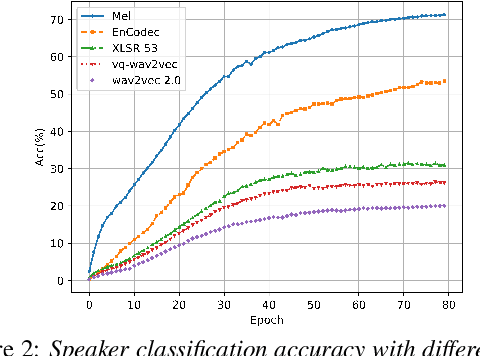
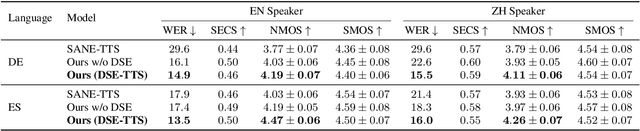
Although high-fidelity speech can be obtained for intralingual speech synthesis, cross-lingual text-to-speech (CTTS) is still far from satisfactory as it is difficult to accurately retain the speaker timbres(i.e. speaker similarity) and eliminate the accents from their first language(i.e. nativeness). In this paper, we demonstrated that vector-quantized(VQ) acoustic feature contains less speaker information than mel-spectrogram. Based on this finding, we propose a novel dual speaker embedding TTS (DSE-TTS) framework for CTTS with authentic speaking style. Here, one embedding is fed to the acoustic model to learn the linguistic speaking style, while the other one is integrated into the vocoder to mimic the target speaker's timbre. Experiments show that by combining both embeddings, DSE-TTS significantly outperforms the state-of-the-art SANE-TTS in cross-lingual synthesis, especially in terms of nativeness.
Localised Adaptive Spatial-Temporal Graph Neural Network
Jun 15, 2023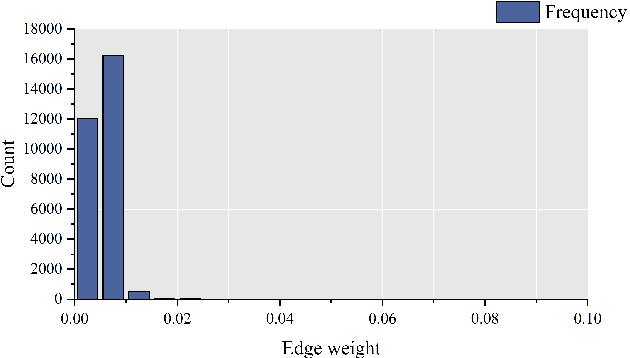
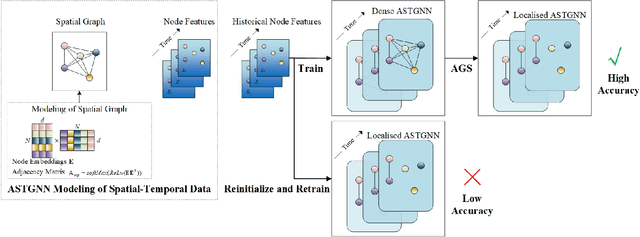

Spatial-temporal graph models are prevailing for abstracting and modelling spatial and temporal dependencies. In this work, we ask the following question: whether and to what extent can we localise spatial-temporal graph models? We limit our scope to adaptive spatial-temporal graph neural networks (ASTGNNs), the state-of-the-art model architecture. Our approach to localisation involves sparsifying the spatial graph adjacency matrices. To this end, we propose Adaptive Graph Sparsification (AGS), a graph sparsification algorithm which successfully enables the localisation of ASTGNNs to an extreme extent (fully localisation). We apply AGS to two distinct ASTGNN architectures and nine spatial-temporal datasets. Intriguingly, we observe that spatial graphs in ASTGNNs can be sparsified by over 99.5\% without any decline in test accuracy. Furthermore, even when ASTGNNs are fully localised, becoming graph-less and purely temporal, we record no drop in accuracy for the majority of tested datasets, with only minor accuracy deterioration observed in the remaining datasets. However, when the partially or fully localised ASTGNNs are reinitialised and retrained on the same data, there is a considerable and consistent drop in accuracy. Based on these observations, we reckon that \textit{(i)} in the tested data, the information provided by the spatial dependencies is primarily included in the information provided by the temporal dependencies and, thus, can be essentially ignored for inference; and \textit{(ii)} although the spatial dependencies provide redundant information, it is vital for the effective training of ASTGNNs and thus cannot be ignored during training. Furthermore, the localisation of ASTGNNs holds the potential to reduce the heavy computation overhead required on large-scale spatial-temporal data and further enable the distributed deployment of ASTGNNs.
ChatGPT Chemistry Assistant for Text Mining and Prediction of MOF Synthesis
Jun 20, 2023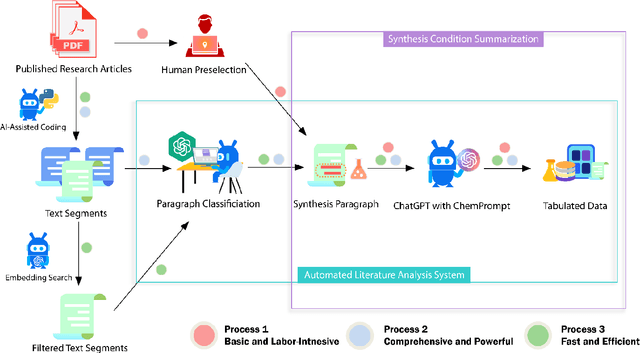

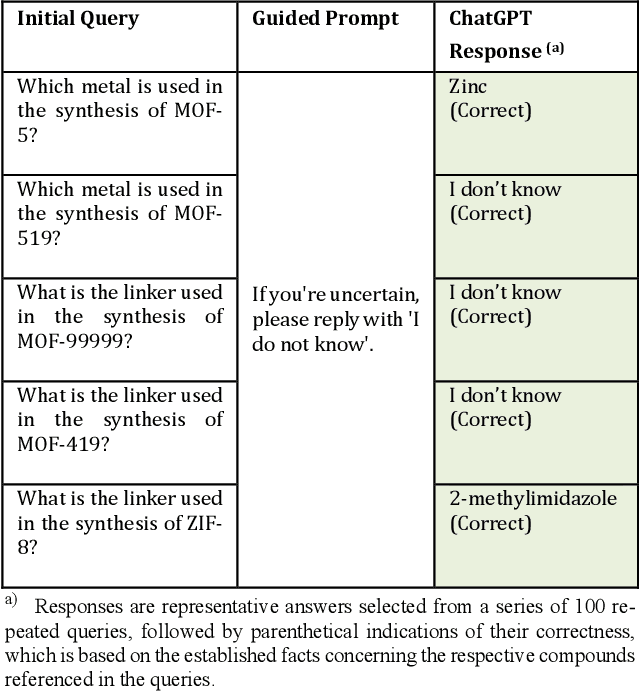
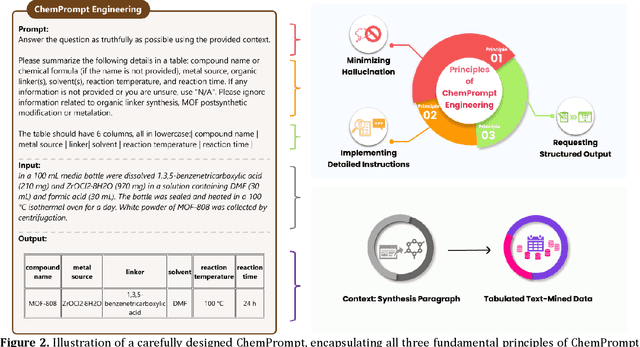
We use prompt engineering to guide ChatGPT in the automation of text mining of metal-organic frameworks (MOFs) synthesis conditions from diverse formats and styles of the scientific literature. This effectively mitigates ChatGPT's tendency to hallucinate information -- an issue that previously made the use of Large Language Models (LLMs) in scientific fields challenging. Our approach involves the development of a workflow implementing three different processes for text mining, programmed by ChatGPT itself. All of them enable parsing, searching, filtering, classification, summarization, and data unification with different tradeoffs between labor, speed, and accuracy. We deploy this system to extract 26,257 distinct synthesis parameters pertaining to approximately 800 MOFs sourced from peer-reviewed research articles. This process incorporates our ChemPrompt Engineering strategy to instruct ChatGPT in text mining, resulting in impressive precision, recall, and F1 scores of 90-99%. Furthermore, with the dataset built by text mining, we constructed a machine-learning model with over 86% accuracy in predicting MOF experimental crystallization outcomes and preliminarily identifying important factors in MOF crystallization. We also developed a reliable data-grounded MOF chatbot to answer questions on chemical reactions and synthesis procedures. Given that the process of using ChatGPT reliably mines and tabulates diverse MOF synthesis information in a unified format, while using only narrative language requiring no coding expertise, we anticipate that our ChatGPT Chemistry Assistant will be very useful across various other chemistry sub-disciplines.
Using Semantic Information for Defining and Detecting OOD Inputs
Feb 21, 2023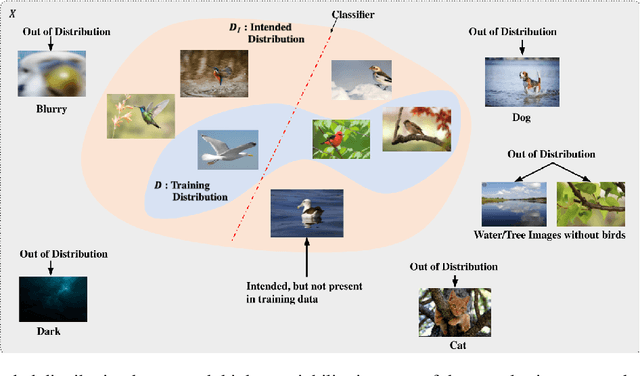
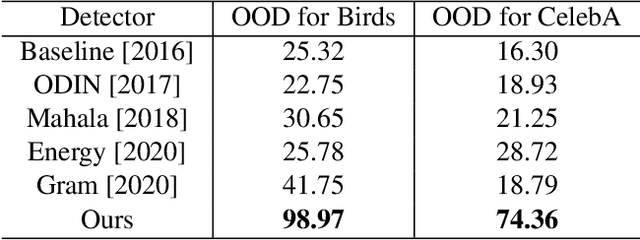


As machine learning models continue to achieve impressive performance across different tasks, the importance of effective anomaly detection for such models has increased as well. It is common knowledge that even well-trained models lose their ability to function effectively on out-of-distribution inputs. Thus, out-of-distribution (OOD) detection has received some attention recently. In the vast majority of cases, it uses the distribution estimated by the training dataset for OOD detection. We demonstrate that the current detectors inherit the biases in the training dataset, unfortunately. This is a serious impediment, and can potentially restrict the utility of the trained model. This can render the current OOD detectors impermeable to inputs lying outside the training distribution but with the same semantic information (e.g. training class labels). To remedy this situation, we begin by defining what should ideally be treated as an OOD, by connecting inputs with their semantic information content. We perform OOD detection on semantic information extracted from the training data of MNIST and COCO datasets and show that it not only reduces false alarms but also significantly improves the detection of OOD inputs with spurious features from the training data.
Wildfire Detection Via Transfer Learning: A Survey
Jun 21, 2023


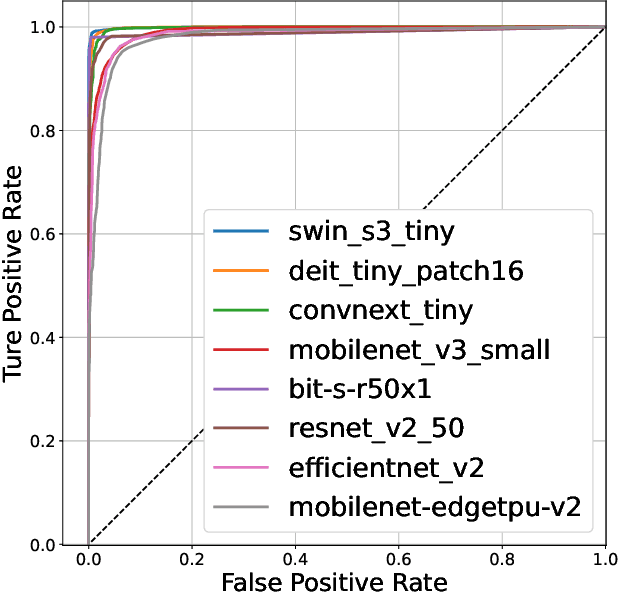
This paper surveys different publicly available neural network models used for detecting wildfires using regular visible-range cameras which are placed on hilltops or forest lookout towers. The neural network models are pre-trained on ImageNet-1K and fine-tuned on a custom wildfire dataset. The performance of these models is evaluated on a diverse set of wildfire images, and the survey provides useful information for those interested in using transfer learning for wildfire detection. Swin Transformer-tiny has the highest AUC value but ConvNext-tiny detects all the wildfire events and has the lowest false alarm rate in our dataset.