 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ViP: A Differentially Private Foundation Model for Computer Vision
Jun 28, 2023

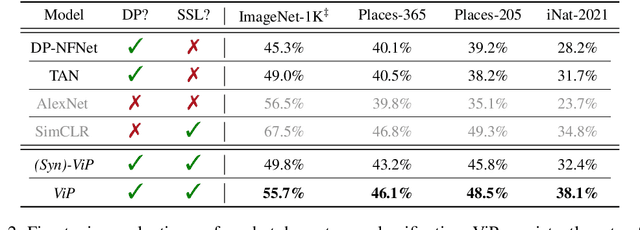
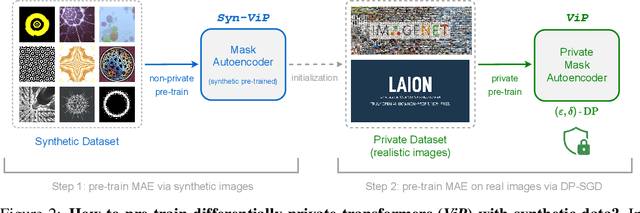
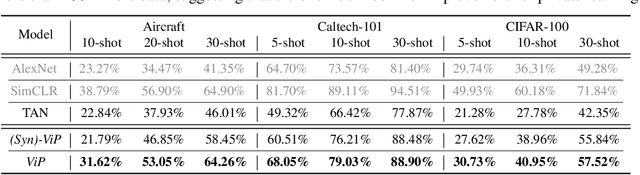
Artificial intelligence (AI) has seen a tremendous surge in capabilities thanks to the use of foundation models trained on internet-scale data. On the flip side, the uncurated nature of internet-scale data also poses significant privacy and legal risks, as they often contain personal information or copyrighted material that should not be trained on without permission. In this work, we propose as a mitigation measure a recipe to train foundation vision models with differential privacy (DP) guarantee. We identify masked autoencoders as a suitable learning algorithm that aligns well with DP-SGD, and train ViP -- a Vision transformer with differential Privacy -- under a strict privacy budget of $\epsilon=8$ on the LAION400M dataset. We evaluate the quality of representation learned by ViP using standard downstream vision tasks; in particular, ViP achieves a (non-private) linear probing accuracy of $55.7\%$ on ImageNet, comparable to that of end-to-end trained AlexNet (trained and evaluated on ImageNet). Our result suggests that scaling to internet-scale data can be practical for private learning. Code is available at \url{https://github.com/facebookresearch/ViP-MAE}.
RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation based on Visual Foundation Model
Jun 28, 2023
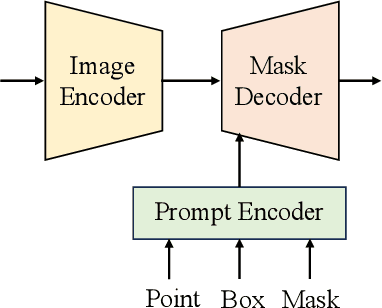
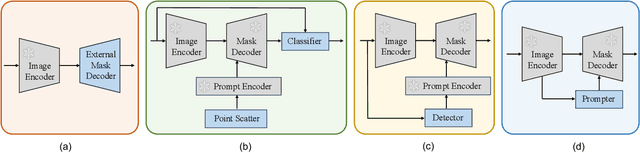
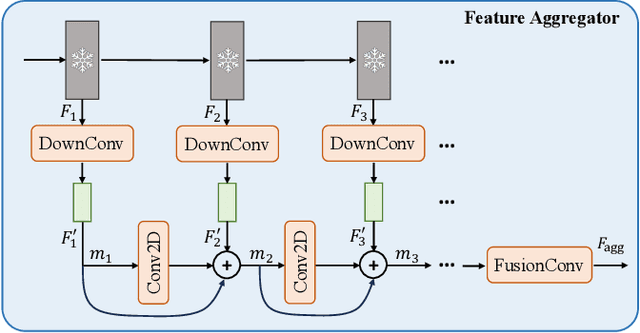
Leveraging vast training data (SA-1B), the foundation Segment Anything Model (SAM) proposed by Meta AI Research exhibits remarkable generalization and zero-shot capabilities. Nonetheless, as a category-agnostic instance segmentation method, SAM heavily depends on prior manual guidance involving points, boxes, and coarse-grained masks. Additionally, its performance on remote sensing image segmentation tasks has yet to be fully explored and demonstrated. In this paper, we consider designing an automated instance segmentation approach for remote sensing images based on the SAM foundation model, incorporating semantic category information. Inspired by prompt learning, we propose a method to learn the generation of appropriate prompts for SAM input. This enables SAM to produce semantically discernible segmentation results for remote sensing images, which we refer to as RSPrompter. We also suggest several ongoing derivatives for instance segmentation tasks, based on recent developments in the SAM community, and compare their performance with RSPrompter. Extensive experimental results on the WHU building, NWPU VHR-10, and SSDD datasets validate the efficacy of our proposed method. Our code is accessible at \url{https://kyanchen.github.io/RSPrompter}.
Stone Needle: A General Multimodal Large-scale Model Framework towards Healthcare
Jun 28, 2023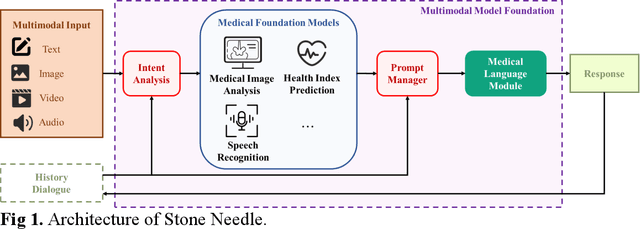

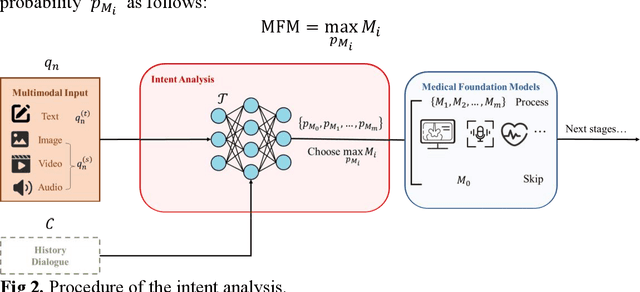
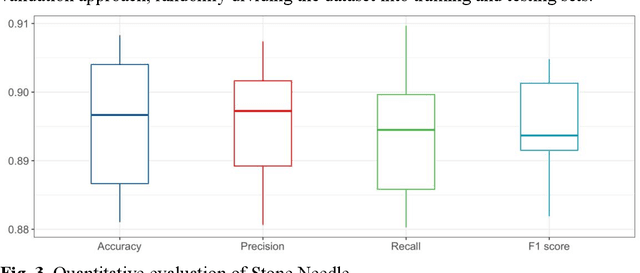
In healthcare, multimodal data is prevalent and requires to be comprehensively analyzed before diagnostic decisions, including medical images, clinical reports, etc. However, current large-scale artificial intelligence models predominantly focus on single-modal cognitive abilities and neglect the integration of multiple modalities. Therefore, we propose Stone Needle, a general multimodal large-scale model framework tailored explicitly for healthcare applications. Stone Needle serves as a comprehensive medical multimodal model foundation, integrating various modalities such as text, images, videos, and audio to surpass the limitations of single-modal systems. Through the framework components of intent analysis, medical foundation models, prompt manager, and medical language module, our architecture can perform multi-modal interaction in multiple rounds of dialogue. Our method is a general multimodal large-scale model framework, integrating diverse modalities and allowing us to tailor for specific tasks. The experimental results demonstrate the superior performance of our method compared to single-modal systems. The fusion of different modalities and the ability to process complex medical information in Stone Needle benefits accurate diagnosis, treatment recommendations, and patient care.
Multi-Site Clinical Federated Learning using Recursive and Attentive Models and NVFlare
Jun 28, 2023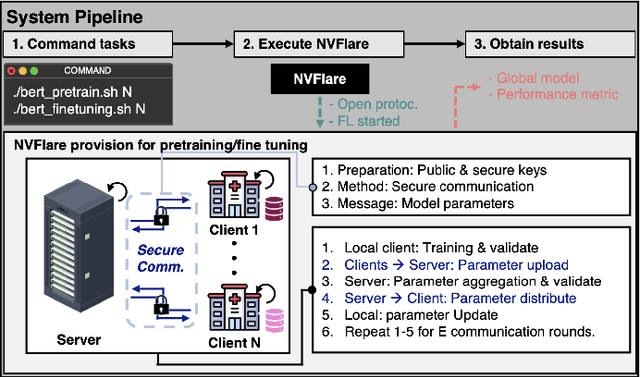
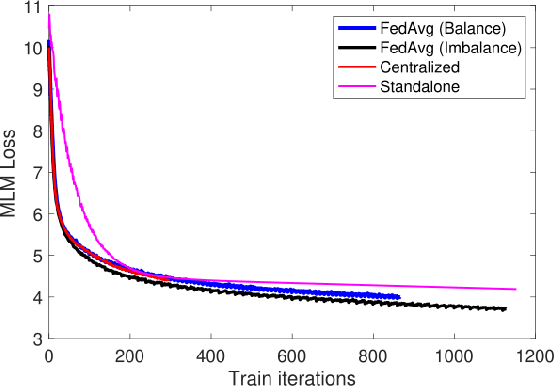
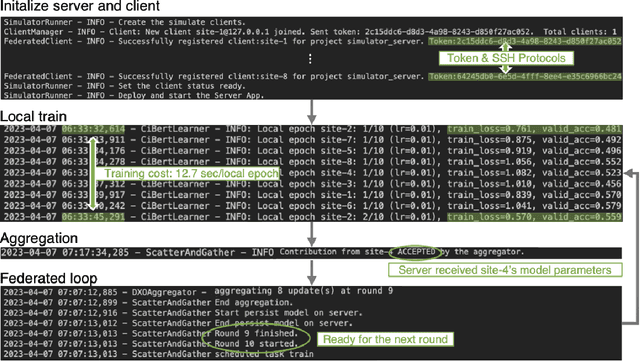
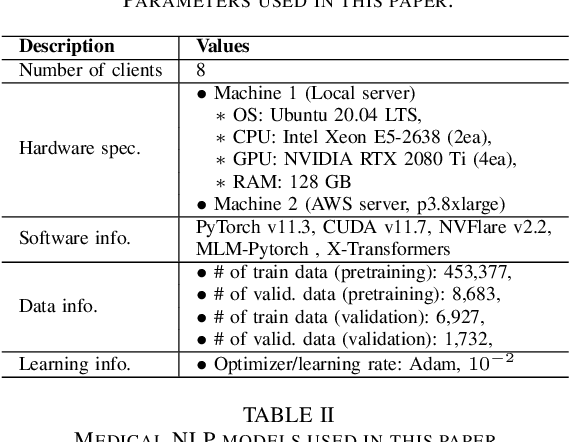
The prodigious growth of digital health data has precipitated a mounting interest in harnessing machine learning methodologies, such as natural language processing (NLP), to scrutinize medical records, clinical notes, and other text-based health information. Although NLP techniques have exhibited substantial potential in augmenting patient care and informing clinical decision-making, data privacy and adherence to regulations persist as critical concerns. Federated learning (FL) emerges as a viable solution, empowering multiple organizations to train machine learning models collaboratively without disseminating raw data. This paper proffers a pragmatic approach to medical NLP by amalgamating FL, NLP models, and the NVFlare framework, developed by NVIDIA. We introduce two exemplary NLP models, the Long-Short Term Memory (LSTM)-based model and Bidirectional Encoder Representations from Transformers (BERT), which have demonstrated exceptional performance in comprehending context and semantics within medical data. This paper encompasses the development of an integrated framework that addresses data privacy and regulatory compliance challenges while maintaining elevated accuracy and performance, incorporating BERT pretraining, and comprehensively substantiating the efficacy of the proposed approach.
Low-Confidence Samples Mining for Semi-supervised Object Detection
Jun 28, 2023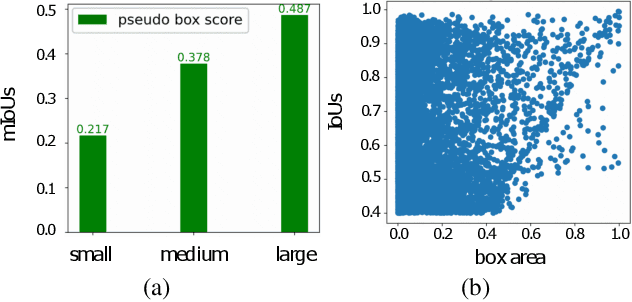
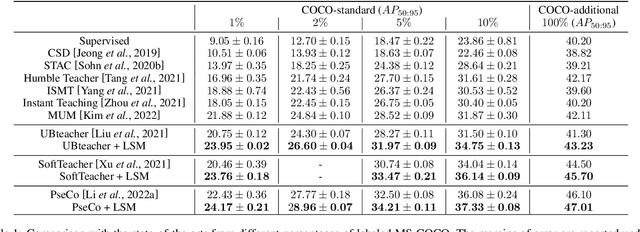

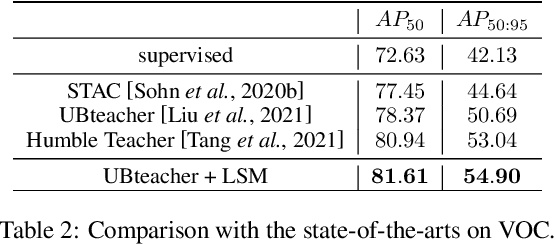
Reliable pseudo-labels from unlabeled data play a key role in semi-supervised object detection (SSOD). However, the state-of-the-art SSOD methods all rely on pseudo-labels with high confidence, which ignore valuable pseudo-labels with lower confidence. Additionally, the insufficient excavation for unlabeled data results in an excessively low recall rate thus hurting the network training. In this paper, we propose a novel Low-confidence Samples Mining (LSM) method to utilize low-confidence pseudo-labels efficiently. Specifically, we develop an additional pseudo information mining (PIM) branch on account of low-resolution feature maps to extract reliable large-area instances, the IoUs of which are higher than small-area ones. Owing to the complementary predictions between PIM and the main branch, we further design self-distillation (SD) to compensate for both in a mutually-learning manner. Meanwhile, the extensibility of the above approaches enables our LSM to apply to Faster-RCNN and Deformable-DETR respectively. On the MS-COCO benchmark, our method achieves 3.54% mAP improvement over state-of-the-art methods under 5% labeling ratios.
Neural network analysis of neutron and X-ray reflectivity data: Incorporating prior knowledge for tackling the phase problem
Jun 28, 2023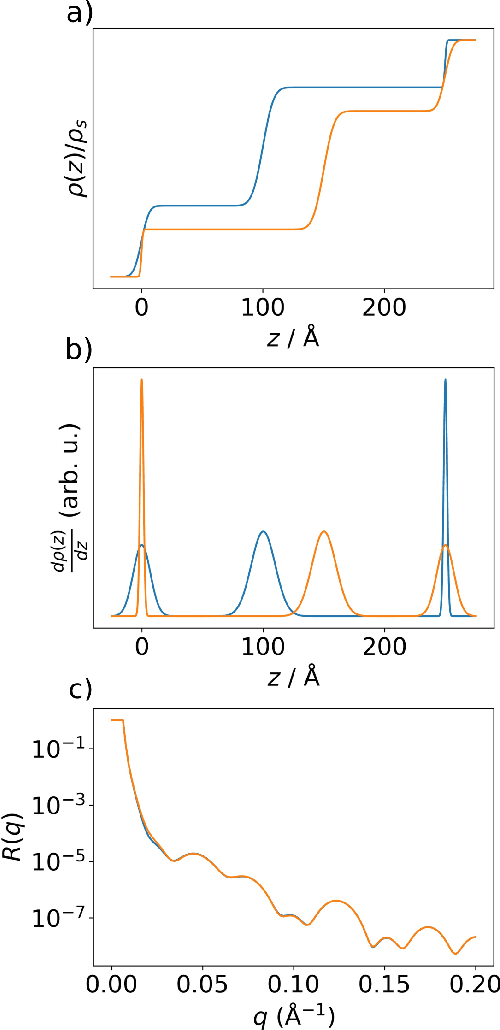
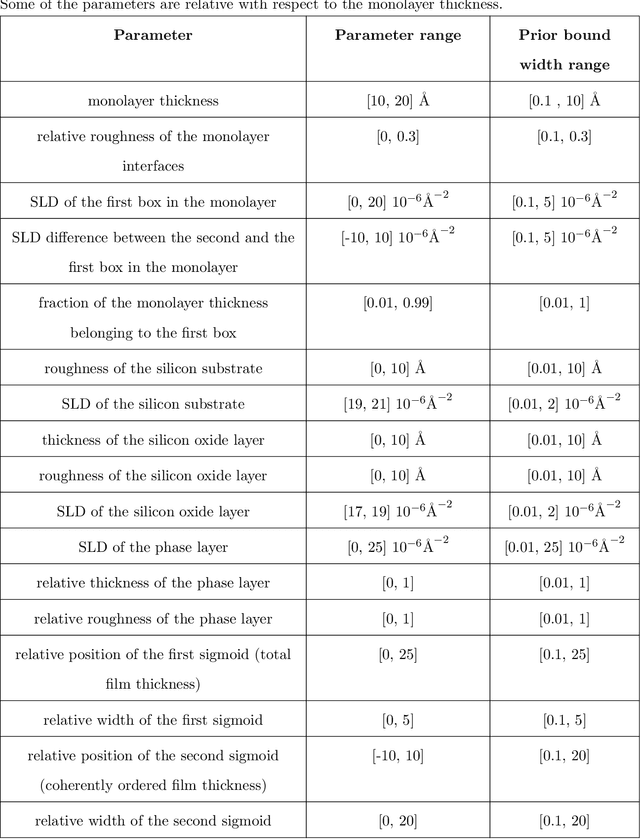
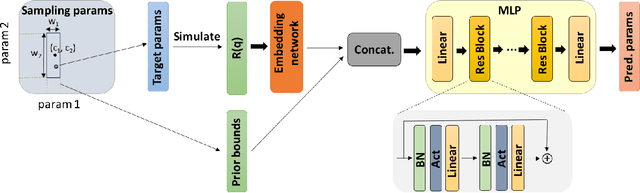
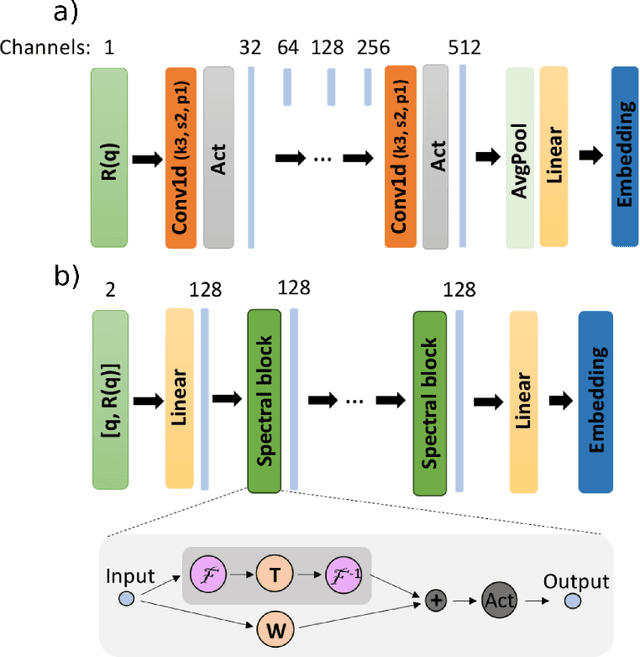
Due to the lack of phase information, determining the physical parameters of multilayer thin films from measured neutron and X-ray reflectivity curves is, on a fundamental level, an underdetermined inverse problem. This so-called phase problem poses limitations on standard neural networks, constraining the range and number of considered parameters in previous machine learning solutions. To overcome this, we present an approach that utilizes prior knowledge to regularize the training process over larger parameter spaces. We demonstrate the effectiveness of our method in various scenarios, including multilayer structures with box model parameterization and a physics-inspired special parameterization of the scattering length density profile for a multilayer structure. By leveraging the input of prior knowledge, we can improve the training dynamics and address the underdetermined ("ill-posed") nature of the problem. In contrast to previous methods, our approach scales favorably when increasing the complexity of the inverse problem, working properly even for a 5-layer multilayer model and an N-layer periodic multilayer model with up to 17 open parameters.
Robo-centric ESDF: A Fast and Accurate Whole-body Collision Evaluation Tool for Any-shape Robotic Planning
Jun 28, 2023
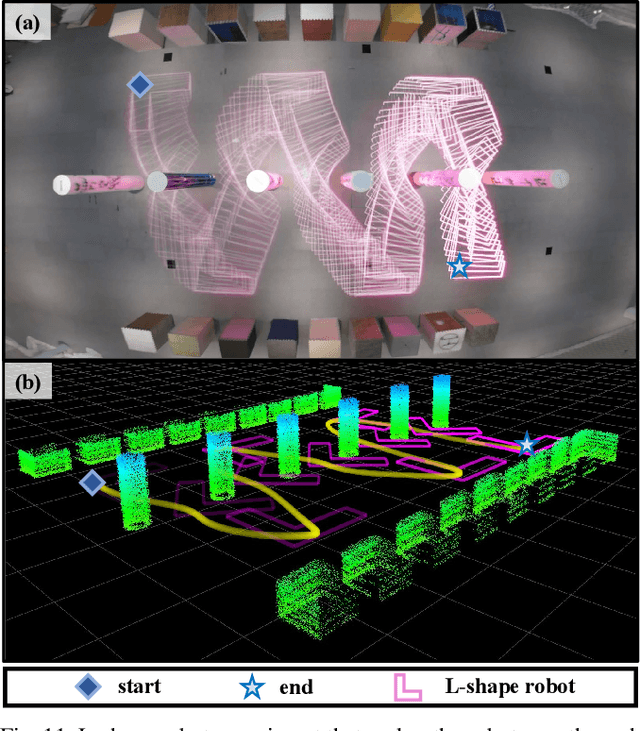
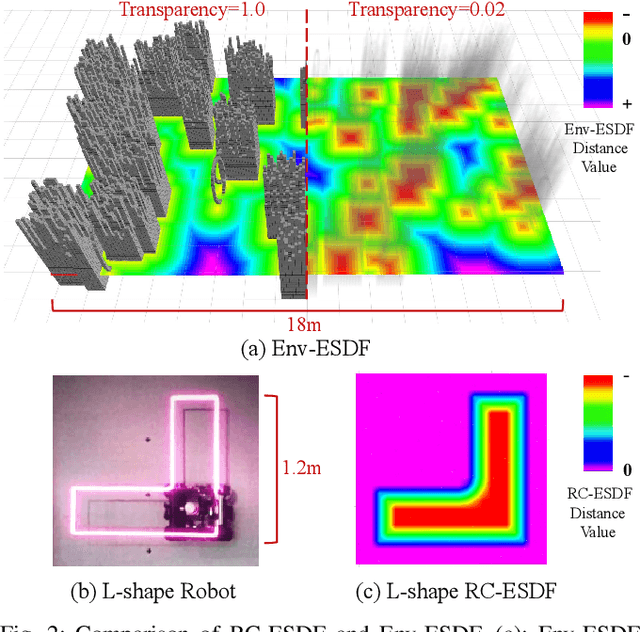
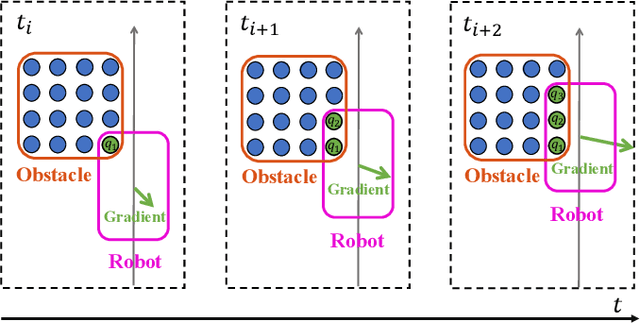
For letting mobile robots travel flexibly through complicated environments, increasing attention has been paid to the whole-body collision evaluation. Most existing works either opt for the conservative corridor-based methods that impose strict requirements on the corridor generation, or ESDF-based methods that suffer from high computational overhead. It is still a great challenge to achieve fast and accurate whole-body collision evaluation. In this paper, we propose a Robo-centric ESDF (RC-ESDF) that is pre-built in the robot body frame and is capable of seamlessly applied to any-shape mobile robots, even for those with non-convex shapes. RC-ESDF enjoys lazy collision evaluation, which retains only the minimum information sufficient for whole-body safety constraint and significantly speeds up trajectory optimization. Based on the analytical gradients provided by RC-ESDF, we optimize the position and rotation of robot jointly, with whole-body safety, smoothness, and dynamical feasibility taken into account. Extensive simulation and real-world experiments verified the reliability and generalizability of our method.
Inferring the Goals of Communicating Agents from Actions and Instructions
Jun 28, 2023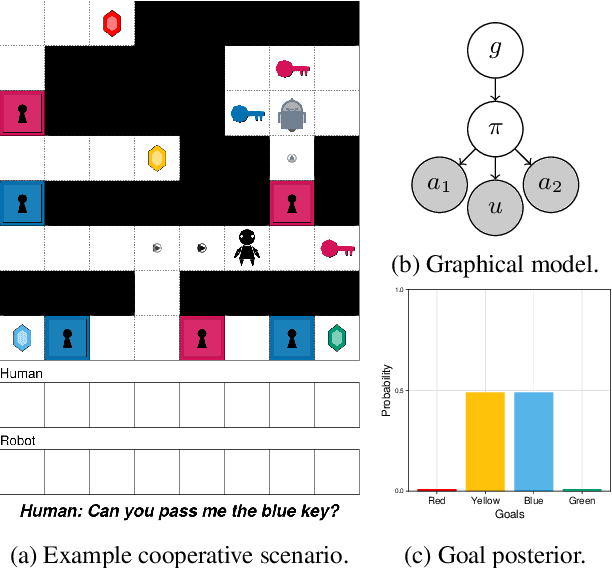


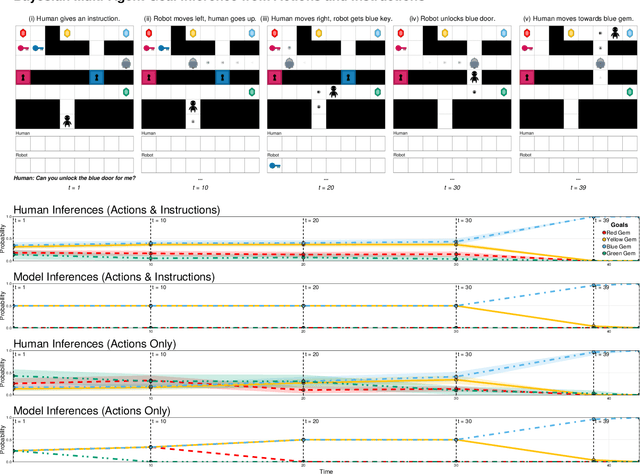
When humans cooperate, they frequently coordinate their activity through both verbal communication and non-verbal actions, using this information to infer a shared goal and plan. How can we model this inferential ability? In this paper, we introduce a model of a cooperative team where one agent, the principal, may communicate natural language instructions about their shared plan to another agent, the assistant, using GPT-3 as a likelihood function for instruction utterances. We then show how a third person observer can infer the team's goal via multi-modal Bayesian inverse planning from actions and instructions, computing the posterior distribution over goals under the assumption that agents will act and communicate rationally to achieve them. We evaluate this approach by comparing it with human goal inferences in a multi-agent gridworld, finding that our model's inferences closely correlate with human judgments (R = 0.96). When compared to inference from actions alone, we also find that instructions lead to more rapid and less uncertain goal inference, highlighting the importance of verbal communication for cooperative agents.
Unveiling the Two-Faced Truth: Disentangling Morphed Identities for Face Morphing Detection
Jun 05, 2023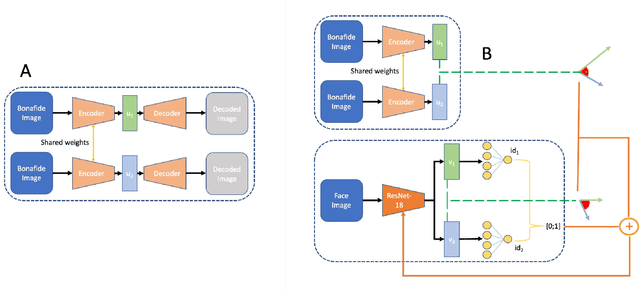
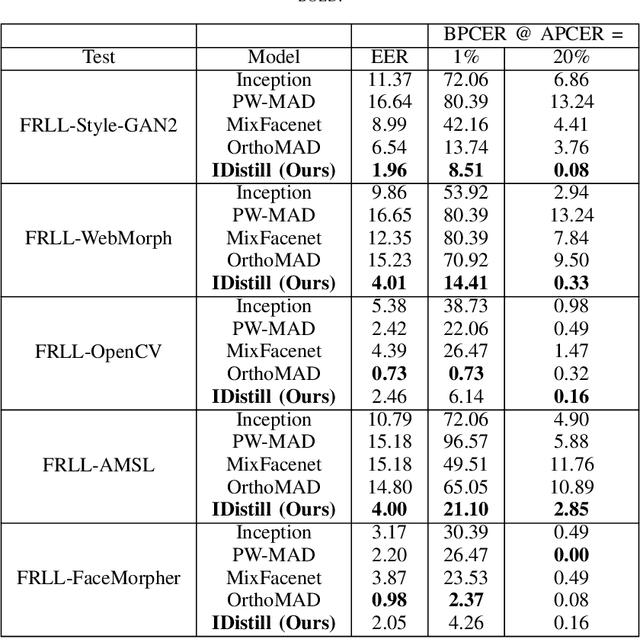
Morphing attacks keep threatening biometric systems, especially face recognition systems. Over time they have become simpler to perform and more realistic, as such, the usage of deep learning systems to detect these attacks has grown. At the same time, there is a constant concern regarding the lack of interpretability of deep learning models. Balancing performance and interpretability has been a difficult task for scientists. However, by leveraging domain information and proving some constraints, we have been able to develop IDistill, an interpretable method with state-of-the-art performance that provides information on both the identity separation on morph samples and their contribution to the final prediction. The domain information is learnt by an autoencoder and distilled to a classifier system in order to teach it to separate identity information. When compared to other methods in the literature it outperforms them in three out of five databases and is competitive in the remaining.
The Effect of Information Type on Human Cognitive Augmentation
Feb 15, 2023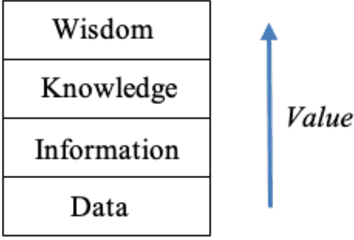

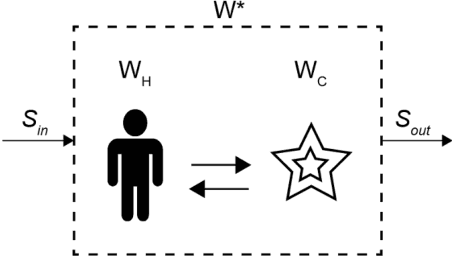
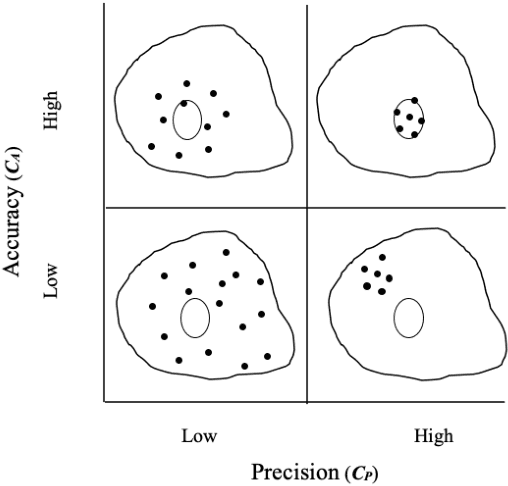
When performing a task alone, humans achieve a certain level of performance. When humans are assisted by a tool or automation to perform the same task, performance is enhanced (augmented). Recently developed cognitive systems are able to perform cognitive processing at or above the level of a human in some domains. When humans work collaboratively with such cogs in a human/cog ensemble, we expect augmentation of cognitive processing to be evident and measurable. This paper shows the degree of cognitive augmentation depends on the nature of the information the cog contributes to the ensemble. Results of an experiment are reported showing conceptual information is the most effective type of information resulting in increases in cognitive accuracy, cognitive precision, and cognitive power.