 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MWPRanker: An Expression Similarity Based Math Word Problem Retriever
Jul 03, 2023
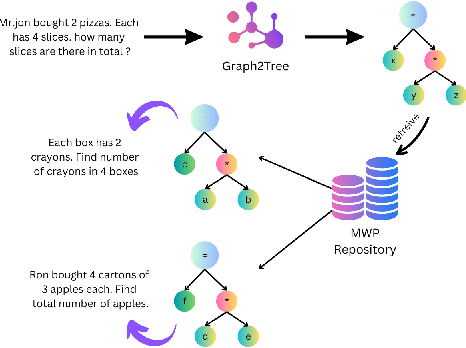
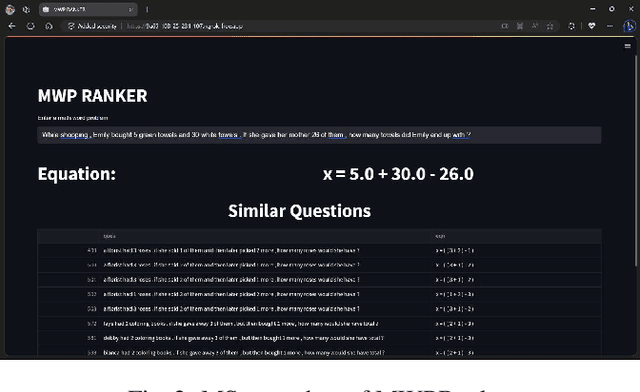
Math Word Problems (MWPs) in online assessments help test the ability of the learner to make critical inferences by interpreting the linguistic information in them. To test the mathematical reasoning capabilities of the learners, sometimes the problem is rephrased or the thematic setting of the original MWP is changed. Since manual identification of MWPs with similar problem models is cumbersome, we propose a tool in this work for MWP retrieval. We propose a hybrid approach to retrieve similar MWPs with the same problem model. In our work, the problem model refers to the sequence of operations to be performed to arrive at the solution. We demonstrate that our tool is useful for the mentioned tasks and better than semantic similarity-based approaches, which fail to capture the arithmetic and logical sequence of the MWPs. A demo of the tool can be found at https://www.youtube.com/watch?v=gSQWP3chFIs
Cross-modal Place Recognition in Image Databases using Event-based Sensors
Jul 03, 2023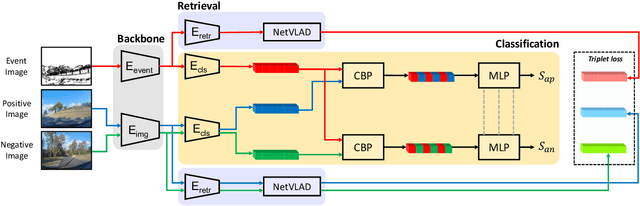



Visual place recognition is an important problem towards global localization in many robotics tasks. One of the biggest challenges is that it may suffer from illumination or appearance changes in surrounding environments. Event cameras are interesting alternatives to frame-based sensors as their high dynamic range enables robust perception in difficult illumination conditions. However, current event-based place recognition methods only rely on event information, which restricts downstream applications of VPR. In this paper, we present the first cross-modal visual place recognition framework that is capable of retrieving regular images from a database given an event query. Our method demonstrates promising results with respect to the state-of-the-art frame-based and event-based methods on the Brisbane-Event-VPR dataset under different scenarios. We also verify the effectiveness of the combination of retrieval and classification, which can boost performance by a large margin.
Bridging the Gap between Decision and Logits in Decision-based Knowledge Distillation for Pre-trained Language Models
Jun 15, 2023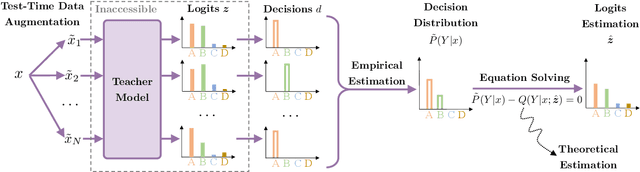
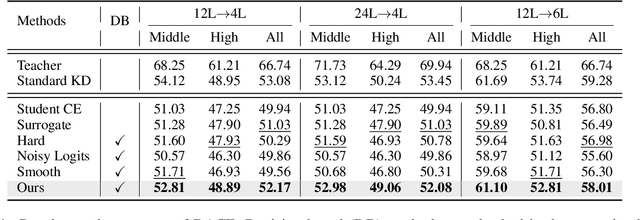
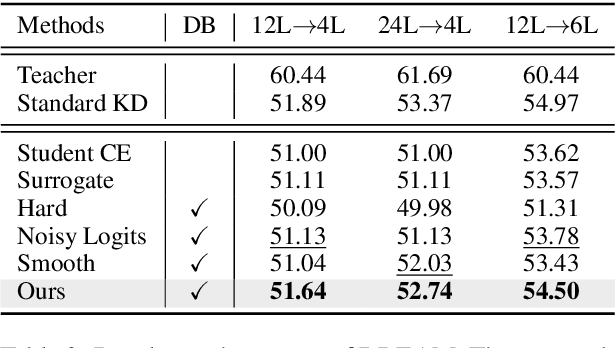
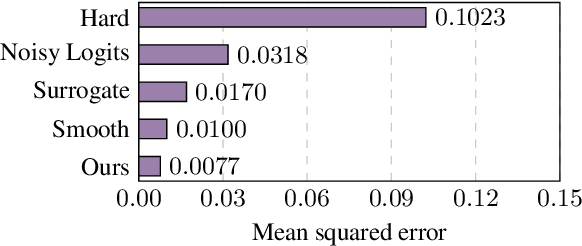
Conventional knowledge distillation (KD) methods require access to the internal information of teachers, e.g., logits. However, such information may not always be accessible for large pre-trained language models (PLMs). In this work, we focus on decision-based KD for PLMs, where only teacher decisions (i.e., top-1 labels) are accessible. Considering the information gap between logits and decisions, we propose a novel method to estimate logits from the decision distributions. Specifically, decision distributions can be both derived as a function of logits theoretically and estimated with test-time data augmentation empirically. By combining the theoretical and empirical estimations of the decision distributions together, the estimation of logits can be successfully reduced to a simple root-finding problem. Extensive experiments show that our method significantly outperforms strong baselines on both natural language understanding and machine reading comprehension datasets.
GIRA: Gaussian Mixture Models for Inference and Robot Autonomy
Jun 30, 2023
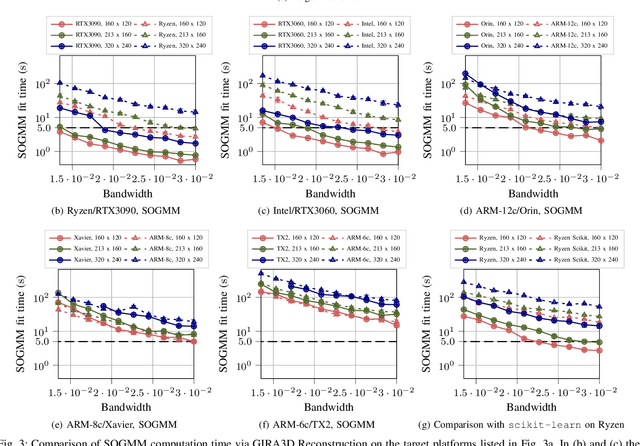
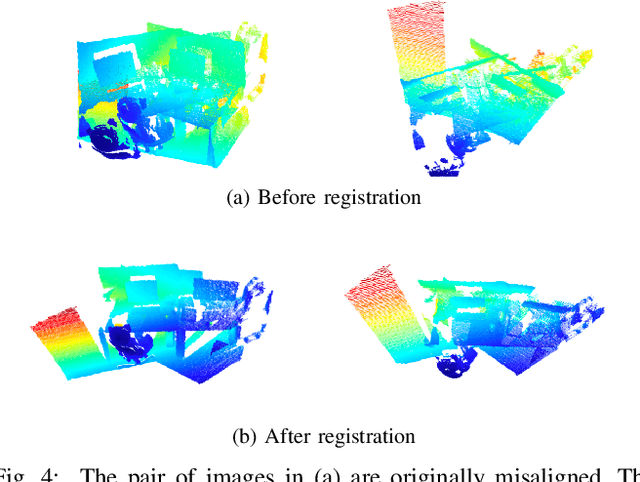
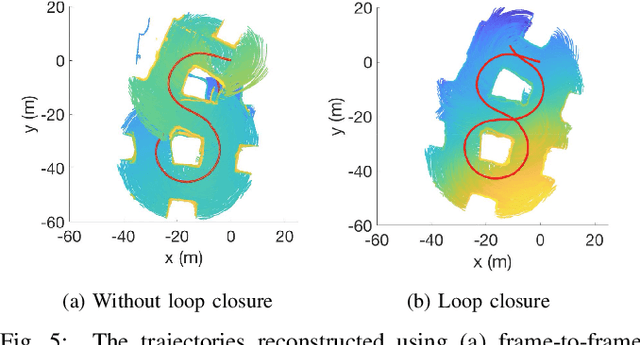
Large-scale deployments of robot teams are challenged by the need to share high-resolution perceptual information over low-bandwidth communication channels. Individual size, weight, and power constrained robots rely on environment models to assess navigability and safely traverse unstructured and complex environments. State of the art perception frameworks construct these models via multiple disparate pipelines that reuse the same underlying sensor data, which leads to increased computation, redundancy, and complexity. To bridge this gap, this paper introduces GIRA -- an open-source framework for compact, high-resolution environment modeling using Gaussian mixture models (GMMs). GIRA provides fundamental robotics capabilities such as high-fidelity reconstruction, pose estimation, and occupancy modeling in a single continuous representation.
Color Learning for Image Compression
Jun 30, 2023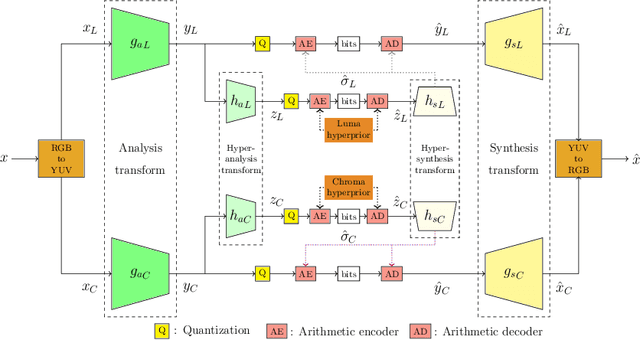
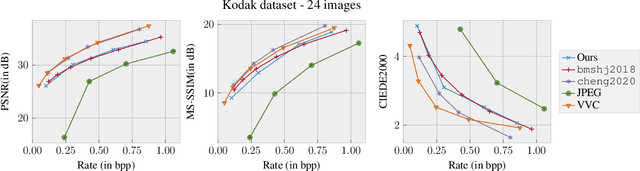


Deep learning based image compression has gained a lot of momentum in recent times. To enable a method that is suitable for image compression and subsequently extended to video compression, we propose a novel deep learning model architecture, where the task of image compression is divided into two sub-tasks, learning structural information from luminance channel and color from chrominance channels. The model has two separate branches to process the luminance and chrominance components. The color difference metric CIEDE2000 is employed in the loss function to optimize the model for color fidelity. We demonstrate the benefits of our approach and compare the performance to other codecs. Additionally, the visualization and analysis of latent channel impulse response is performed.
Latent Space Perspicacity and Interpretation Enhancement (LS-PIE) Framework
Jul 11, 2023Linear latent variable models such as principal component analysis (PCA), independent component analysis (ICA), canonical correlation analysis (CCA), and factor analysis (FA) identify latent directions (or loadings) either ordered or unordered. The data is then projected onto the latent directions to obtain their projected representations (or scores). For example, PCA solvers usually rank the principal directions by explaining the most to least variance, while ICA solvers usually return independent directions unordered and often with single sources spread across multiple directions as multiple sub-sources, which is of severe detriment to their usability and interpretability. This paper proposes a general framework to enhance latent space representations for improving the interpretability of linear latent spaces. Although the concepts in this paper are language agnostic, the framework is written in Python. This framework automates the clustering and ranking of latent vectors to enhance the latent information per latent vector, as well as, the interpretation of latent vectors. Several innovative enhancements are incorporated including latent ranking (LR), latent scaling (LS), latent clustering (LC), and latent condensing (LCON). For a specified linear latent variable model, LR ranks latent directions according to a specified metric, LS scales latent directions according to a specified metric, LC automatically clusters latent directions into a specified number of clusters, while, LCON automatically determines an appropriate number of clusters into which to condense the latent directions for a given metric. Additional functionality of the framework includes single-channel and multi-channel data sources, data preprocessing strategies such as Hankelisation to seamlessly expand the applicability of linear latent variable models (LLVMs) to a wider variety of data. The effectiveness of LR, LS, and LCON are showcased on two crafted foundational problems with two applied latent variable models, namely, PCA and ICA.
CT-based Subchondral Bone Microstructural Analysis in Knee Osteoarthritis via MR-Guided Distillation Learning
Jul 11, 2023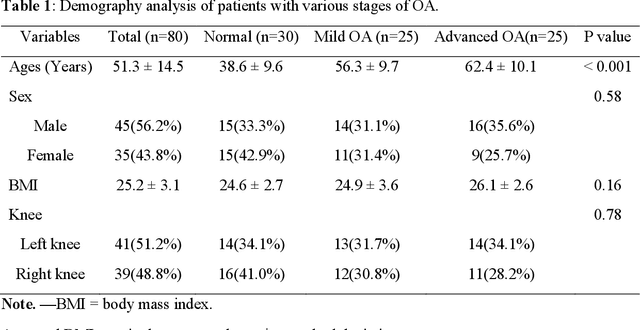

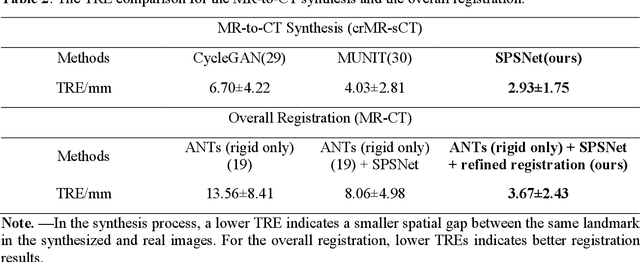
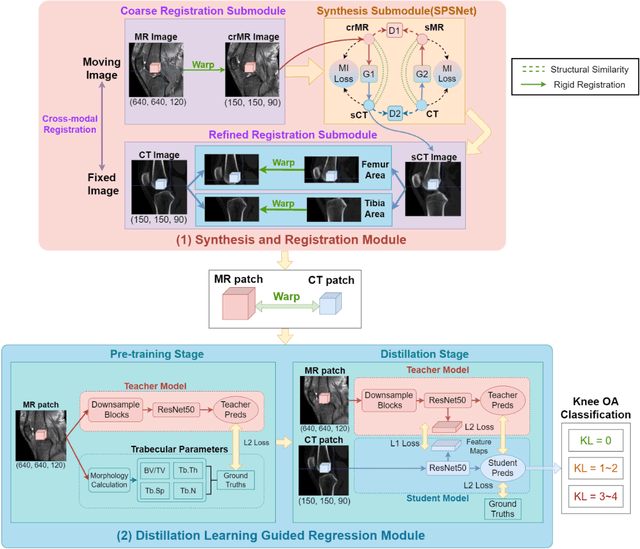
Background: MR-based subchondral bone effectively predicts knee osteoarthritis. However, its clinical application is limited by the cost and time of MR. Purpose: We aim to develop a novel distillation-learning-based method named SRRD for subchondral bone microstructural analysis using easily-acquired CT images, which leverages paired MR images to enhance the CT-based analysis model during training. Materials and Methods: Knee joint images of both CT and MR modalities were collected from October 2020 to May 2021. Firstly, we developed a GAN-based generative model to transform MR images into CT images, which was used to establish the anatomical correspondence between the two modalities. Next, we obtained numerous patches of subchondral bone regions of MR images, together with their trabecular parameters (BV / TV, Tb. Th, Tb. Sp, Tb. N) from the corresponding CT image patches via regression. The distillation-learning technique was used to train the regression model and transfer MR structural information to the CT-based model. The regressed trabecular parameters were further used for knee osteoarthritis classification. Results: A total of 80 participants were evaluated. CT-based regression results of trabecular parameters achieved intra-class correlation coefficients (ICCs) of 0.804, 0.773, 0.711, and 0.622 for BV / TV, Tb. Th, Tb. Sp, and Tb. N, respectively. The use of distillation learning significantly improved the performance of the CT-based knee osteoarthritis classification method using the CNN approach, yielding an AUC score of 0.767 (95% CI, 0.681-0.853) instead of 0.658 (95% CI, 0.574-0.742) (p<.001). Conclusions: The proposed SRRD method showed high reliability and validity in MR-CT registration, regression, and knee osteoarthritis classification, indicating the feasibility of subchondral bone microstructural analysis based on CT images.
WiCo: Win-win Cooperation of Bottom-up and Top-down Referring Image Segmentation
Jun 19, 2023
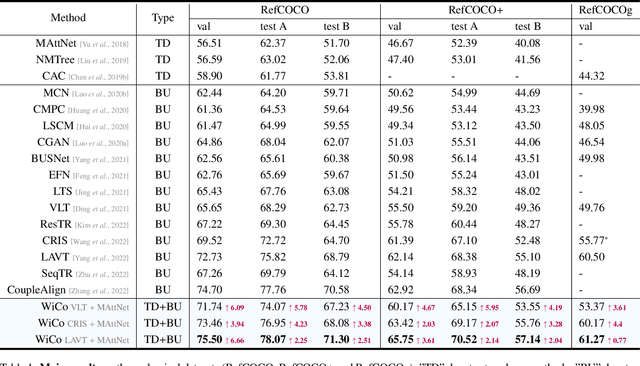
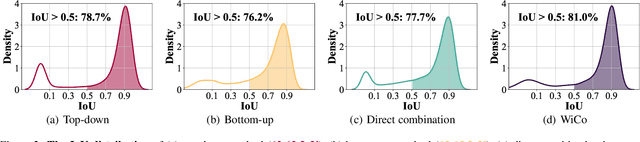
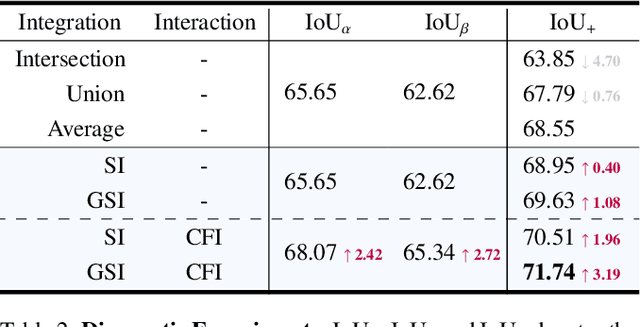
The top-down and bottom-up methods are two mainstreams of referring segmentation, while both methods have their own intrinsic weaknesses. Top-down methods are chiefly disturbed by Polar Negative (PN) errors owing to the lack of fine-grained cross-modal alignment. Bottom-up methods are mainly perturbed by Inferior Positive (IP) errors due to the lack of prior object information. Nevertheless, we discover that two types of methods are highly complementary for restraining respective weaknesses but the direct average combination leads to harmful interference. In this context, we build Win-win Cooperation (WiCo) to exploit complementary nature of two types of methods on both interaction and integration aspects for achieving a win-win improvement. For the interaction aspect, Complementary Feature Interaction (CFI) provides fine-grained information to top-down branch and introduces prior object information to bottom-up branch for complementary feature enhancement. For the integration aspect, Gaussian Scoring Integration (GSI) models the gaussian performance distributions of two branches and weightedly integrates results by sampling confident scores from the distributions. With our WiCo, several prominent top-down and bottom-up combinations achieve remarkable improvements on three common datasets with reasonable extra costs, which justifies effectiveness and generality of our method.
Learning to Incentivize Information Acquisition: Proper Scoring Rules Meet Principal-Agent Model
Mar 15, 2023
We study the incentivized information acquisition problem, where a principal hires an agent to gather information on her behalf. Such a problem is modeled as a Stackelberg game between the principal and the agent, where the principal announces a scoring rule that specifies the payment, and then the agent then chooses an effort level that maximizes her own profit and reports the information. We study the online setting of such a problem from the principal's perspective, i.e., designing the optimal scoring rule by repeatedly interacting with the strategic agent. We design a provably sample efficient algorithm that tailors the UCB algorithm (Auer et al., 2002) to our model, which achieves a sublinear $T^{2/3}$-regret after $T$ iterations. Our algorithm features a delicate estimation procedure for the optimal profit of the principal, and a conservative correction scheme that ensures the desired agent's actions are incentivized. Furthermore, a key feature of our regret bound is that it is independent of the number of states of the environment.
Laxity-Aware Scalable Reinforcement Learning for HVAC Control
Jun 29, 2023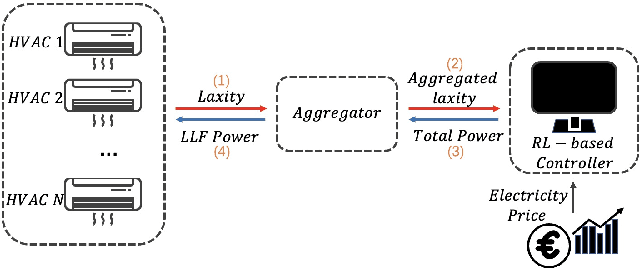
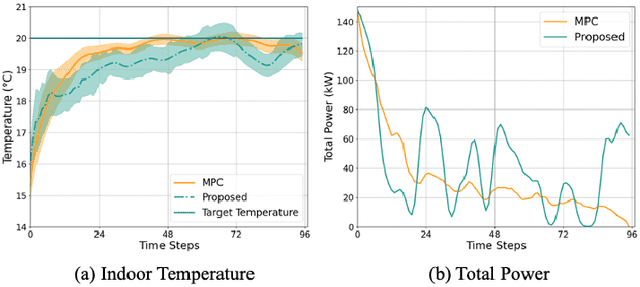
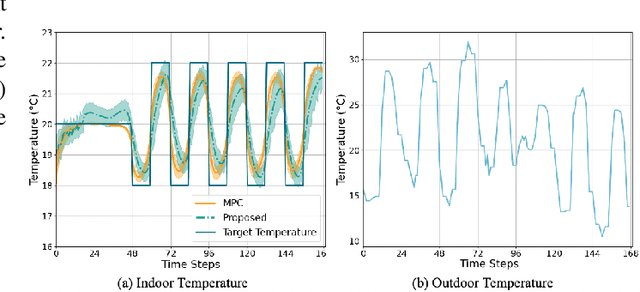
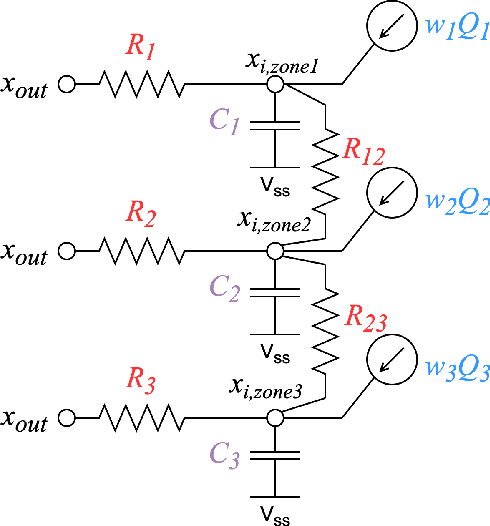
Demand flexibility plays a vital role in maintaining grid balance, reducing peak demand, and saving customers' energy bills. Given their highly shiftable load and significant contribution to a building's energy consumption, Heating, Ventilation, and Air Conditioning (HVAC) systems can provide valuable demand flexibility to the power systems by adjusting their energy consumption in response to electricity price and power system needs. To exploit this flexibility in both operation time and power, it is imperative to accurately model and aggregate the load flexibility of a large population of HVAC systems as well as designing effective control algorithms. In this paper, we tackle the curse of dimensionality issue in modeling and control by utilizing the concept of laxity to quantify the emergency level of each HVAC operation request. We further propose a two-level approach to address energy optimization for a large population of HVAC systems. The lower level involves an aggregator to aggregate HVAC load laxity information and use least-laxity-first (LLF) rule to allocate real-time power for individual HVAC systems based on the controller's total power. Due to the complex and uncertain nature of HVAC systems, we leverage a reinforcement learning (RL)-based controller to schedule the total power based on the aggregated laxity information and electricity price. We evaluate the temperature control and energy cost saving performance of a large-scale group of HVAC systems in both single-zone and multi-zone scenarios, under varying climate and electricity market conditions. The experiment results indicate that proposed approach outperforms the centralized methods in the majority of test scenarios, and performs comparably to model-based method in some scenarios.