 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Conditional Flow Variational Autoencoder for Controllable Synthesis of Virtual Populations of Anatomy
Jun 26, 2023
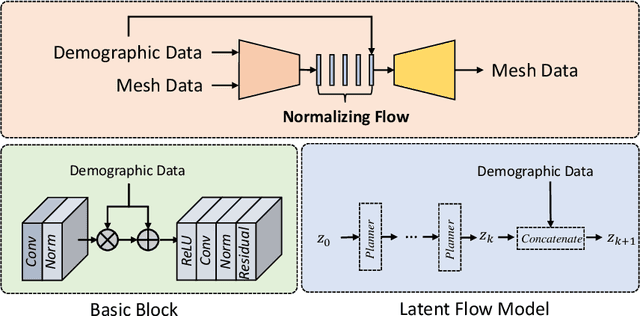
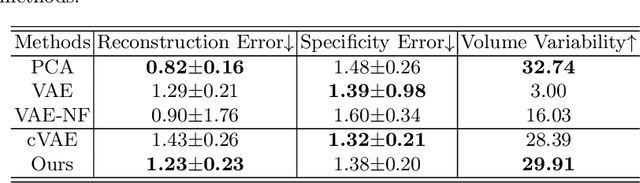

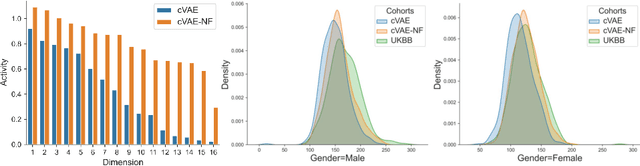
Generating virtual populations (VPs) of anatomy is essential for conducting in-silico trials of medical devices. Typically, the generated VP should capture sufficient variability while remaining plausible, and should reflect specific characteristics and patient demographics observed in real populations. It is desirable in several applications to synthesize VPs in a \textit{controlled} manner, where relevant covariates are used to conditionally synthesise virtual populations that fit specific target patient populations/characteristics. We propose to equip a conditional variational autoencoder (cVAE) with normalizing flows to boost the flexibility and complexity of the approximate posterior learned, leading to enhanced flexibility for controllable synthesis of VPs of anatomical structures. We demonstrate the performance of our conditional-flow VAE using a dataset of cardiac left ventricles acquired from 2360 patients, with associated demographic information and clinical measurements (used as covariates/conditioning information). The obtained results indicate the superiority of the proposed method for conditional synthesis of virtual populations of cardiac left ventricles relative to a cVAE. Conditional synthesis performance was assessed in terms of generalisation and specificity errors, and in terms of the ability to preserve clinical relevant biomarkers in the synthesised VPs, I.e. left ventricular blood pool and myocardial volume, relative to the observed real population.
Who Needs to Know? Minimal Knowledge for Optimal Coordination
Jun 15, 2023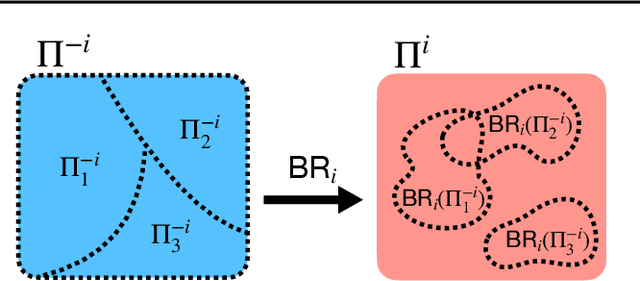
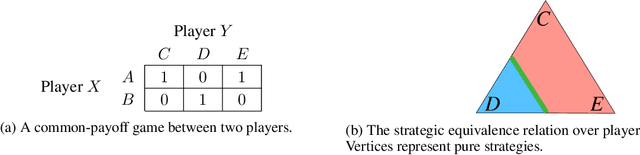
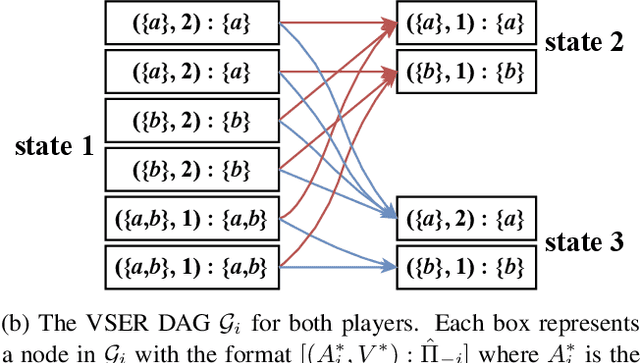
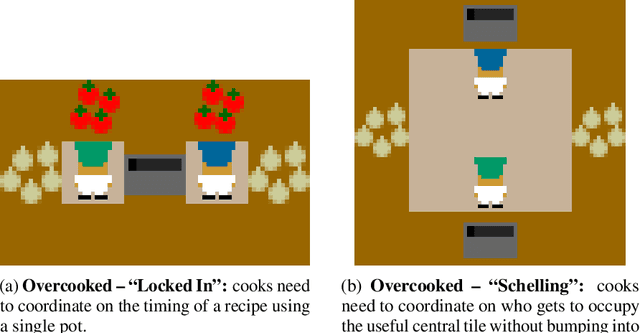
To optimally coordinate with others in cooperative games, it is often crucial to have information about one's collaborators: successful driving requires understanding which side of the road to drive on. However, not every feature of collaborators is strategically relevant: the fine-grained acceleration of drivers may be ignored while maintaining optimal coordination. We show that there is a well-defined dichotomy between strategically relevant and irrelevant information. Moreover, we show that, in dynamic games, this dichotomy has a compact representation that can be efficiently computed via a Bellman backup operator. We apply this algorithm to analyze the strategically relevant information for tasks in both a standard and a partially observable version of the Overcooked environment. Theoretical and empirical results show that our algorithms are significantly more efficient than baselines. Videos are available at https://minknowledge.github.io.
Predictive Patentomics: Forecasting Innovation Success and Valuation with ChatGPT
Jun 22, 2023
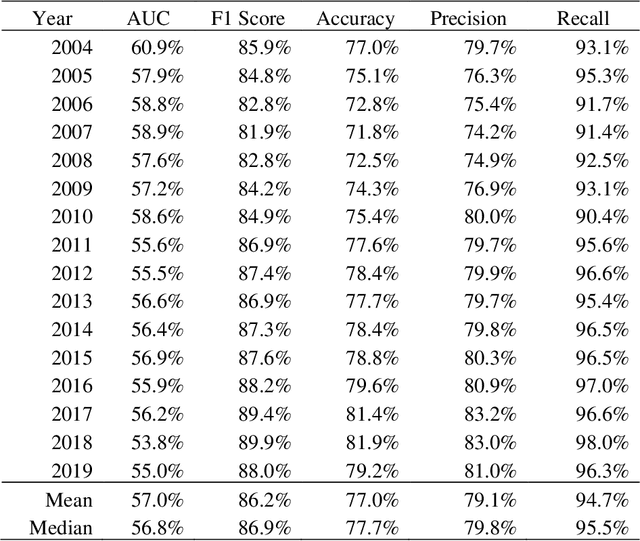
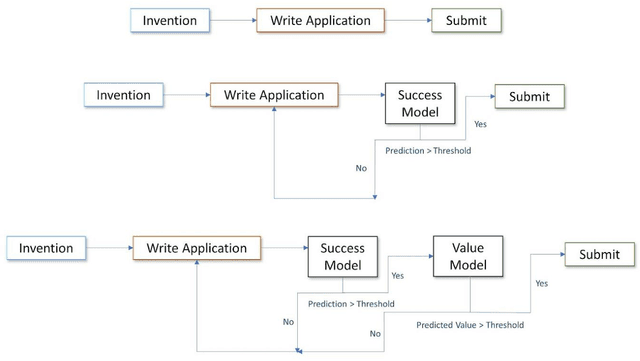
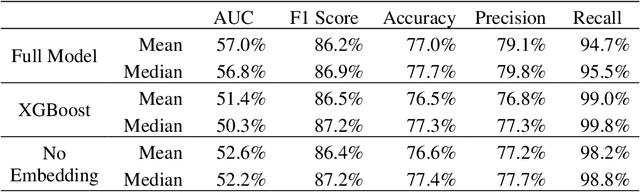
Analysis of innovation has been fundamentally limited by conventional approaches to broad, structural variables. This paper pushes the boundaries, taking an LLM approach to patent analysis with the groundbreaking ChatGPT technology. OpenAI's state-of-the-art textual embedding accesses complex information about the quality and impact of each invention to power deep learning predictive models. The nuanced embedding drives a 24% incremental improvement in R-squared predicting patent value and clearly isolates the worst and best applications. These models enable a revision of the contemporary Kogan, Papanikolaou, Seru, and Stoffman (2017) valuation of patents by a median deviation of 1.5 times, accounting for potential institutional predictions. Furthermore, the market fails to incorporate timely information about applications; a long-short portfolio based on predicted acceptance rates achieves significant abnormal returns of 3.3% annually. The models provide an opportunity to revolutionize startup and small-firm corporate policy vis-a-vis patenting.
Implicit spoken language diarization
Jun 22, 2023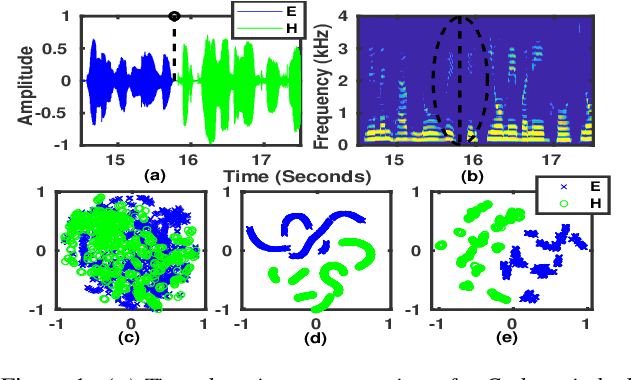
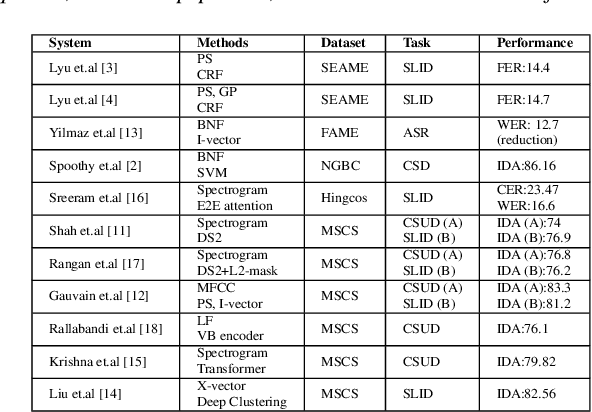
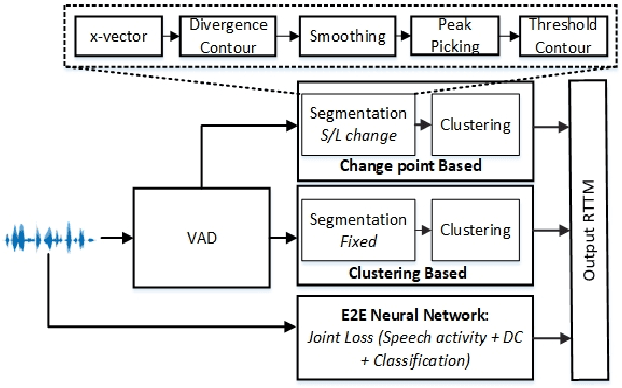
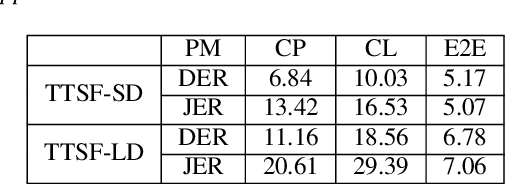
Spoken language diarization (LD) and related tasks are mostly explored using the phonotactic approach. Phonotactic approaches mostly use explicit way of language modeling, hence requiring intermediate phoneme modeling and transcribed data. Alternatively, the ability of deep learning approaches to model temporal dynamics may help for the implicit modeling of language information through deep embedding vectors. Hence this work initially explores the available speaker diarization frameworks that capture speaker information implicitly to perform LD tasks. The performance of the LD system on synthetic code-switch data using the end-to-end x-vector approach is 6.78% and 7.06%, and for practical data is 22.50% and 60.38%, in terms of diarization error rate and Jaccard error rate (JER), respectively. The performance degradation is due to the data imbalance and resolved to some extent by using pre-trained wave2vec embeddings that provide a relative improvement of 30.74% in terms of JER.
Enlighten Anything: When Segment Anything Model Meets Low-Light Image Enhancement
Jun 22, 2023
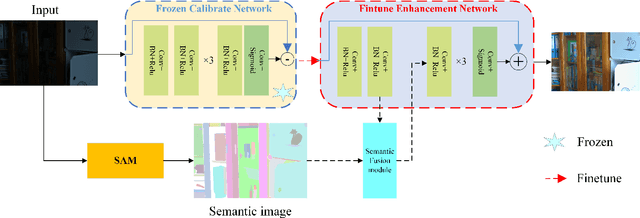


Image restoration is a low-level visual task, and most CNN methods are designed as black boxes, lacking transparency and intrinsic aesthetics. Many unsupervised approaches ignore the degradation of visible information in low-light scenes, which will seriously affect the aggregation of complementary information and also make the fusion algorithm unable to produce satisfactory fusion results under extreme conditions. In this paper, we propose Enlighten-anything, which is able to enhance and fuse the semantic intent of SAM segmentation with low-light images to obtain fused images with good visual perception. The generalization ability of unsupervised learning is greatly improved, and experiments on LOL dataset are conducted to show that our method improves 3db in PSNR over baseline and 8 in SSIM. Zero-shot learning of SAM introduces a powerful aid for unsupervised low-light enhancement. The source code of Enlighten Anything can be obtained from https://github.com/zhangbaijin/enlighten-anything
Fourier-Mixed Window Attention: Accelerating Informer for Long Sequence Time-Series Forecasting
Jul 02, 2023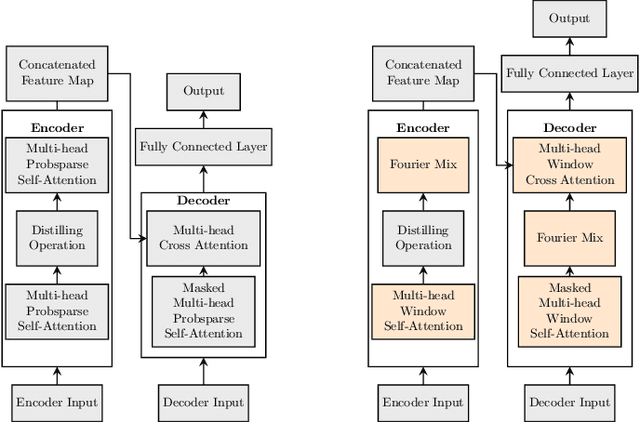

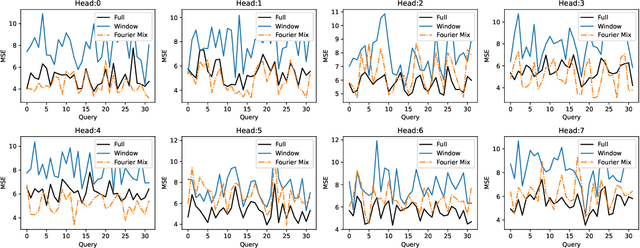

We study a fast local-global window-based attention method to accelerate Informer for long sequence time-series forecasting. While window attention is local and a considerable computational saving, it lacks the ability to capture global token information which is compensated by a subsequent Fourier transform block. Our method, named FWin, does not rely on query sparsity hypothesis and an empirical approximation underlying the ProbSparse attention of Informer. Through experiments on univariate and multivariate datasets, we show that FWin transformers improve the overall prediction accuracies of Informer while accelerating its inference speeds by 40 to 50 %. We also show in a nonlinear regression model that a learned FWin type attention approaches or even outperforms softmax full attention based on key vectors extracted from an Informer model's full attention layer acting on time series data.
Crossway Diffusion: Improving Diffusion-based Visuomotor Policy via Self-supervised Learning
Jul 04, 2023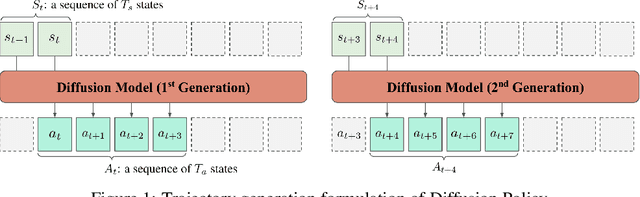

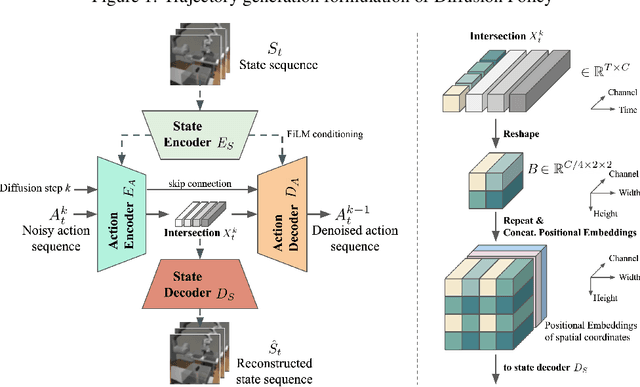

Sequence modeling approaches have shown promising results in robot imitation learning. Recently, diffusion models have been adopted for behavioral cloning, benefiting from their exceptional capabilities in modeling complex data distribution. In this work, we propose Crossway Diffusion, a method to enhance diffusion-based visuomotor policy learning by using an extra self-supervised learning (SSL) objective. The standard diffusion-based policy generates action sequences from random noise conditioned on visual observations and other low-dimensional states. We further extend this by introducing a new decoder that reconstructs raw image pixels (and other state information) from the intermediate representations of the reverse diffusion process, and train the model jointly using the SSL loss. Our experiments demonstrate the effectiveness of Crossway Diffusion in various simulated and real-world robot tasks, confirming its advantages over the standard diffusion-based policy. We demonstrate that such self-supervised reconstruction enables better representation for policy learning, especially when the demonstrations have different proficiencies.
S-Nav: Semantic-Geometric Planning for Mobile Robots
Jul 04, 2023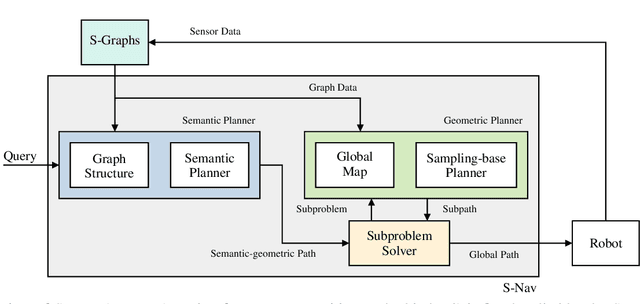

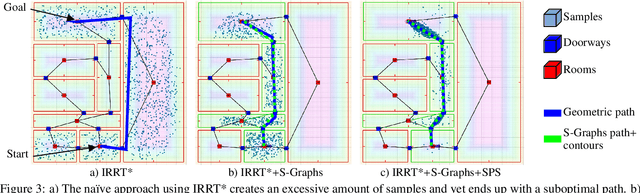
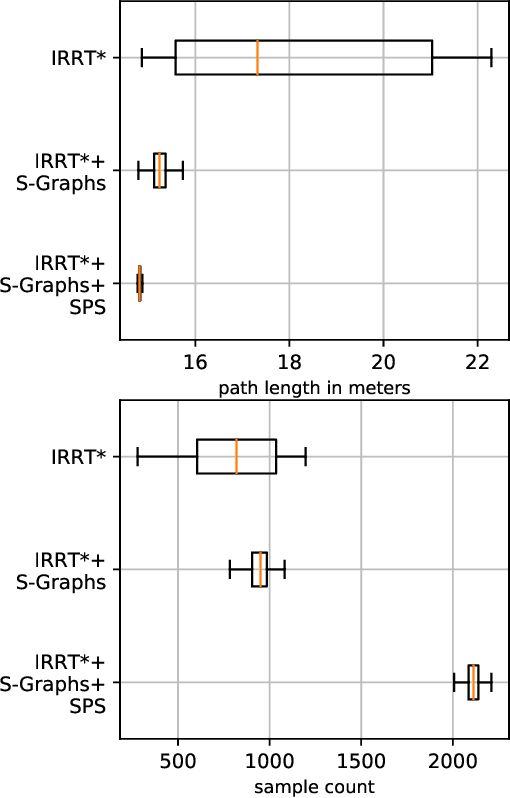
Path planning is a basic capability of autonomous mobile robots. Former approaches in path planning exploit only the given geometric information from the environment without leveraging the inherent semantics within the environment. The recently presented S-Graphs constructs 3D situational graphs incorporating geometric, semantic, and relational aspects between the elements to improve the overall scene understanding and the localization of the robot. But these works do not exploit the underlying semantic graphs for improving the path planning for mobile robots. To that aim, in this paper, we present S-Nav a novel semantic-geometric path planner for mobile robots. It leverages S-Graphs to enable fast and robust hierarchical high-level planning in complex indoor environments. The hierarchical architecture of S-Nav adds a novel semantic search on top of a traditional geometric planner as well as precise map reconstruction from S-Graphs to improve planning speed, robustness, and path quality. We demonstrate improved results of S-Nav in a synthetic environment.
Decoding the Popularity of TV Series: A Network Analysis Perspective
Jul 04, 2023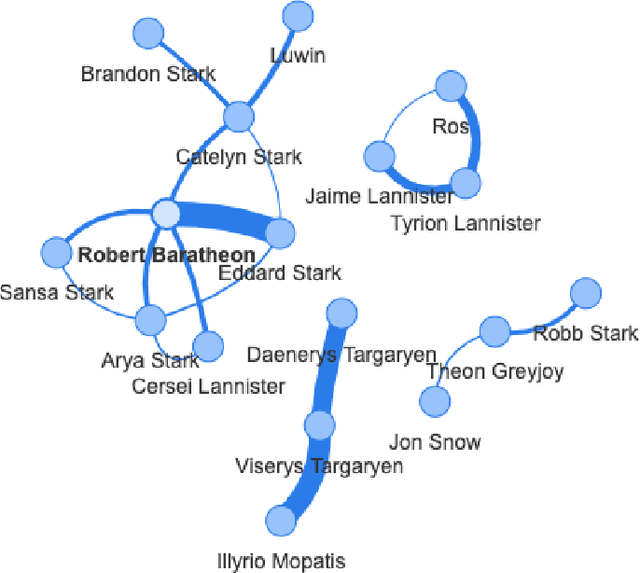
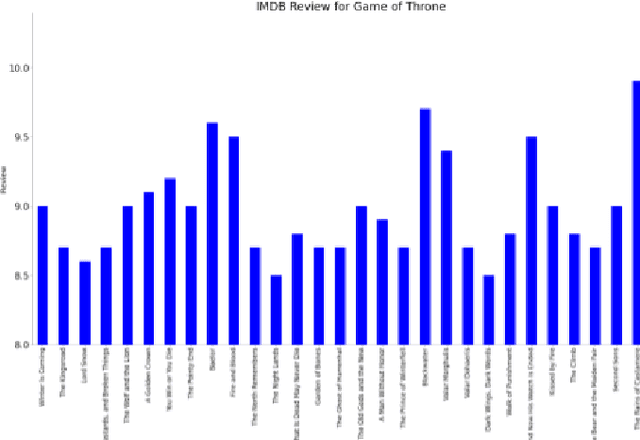
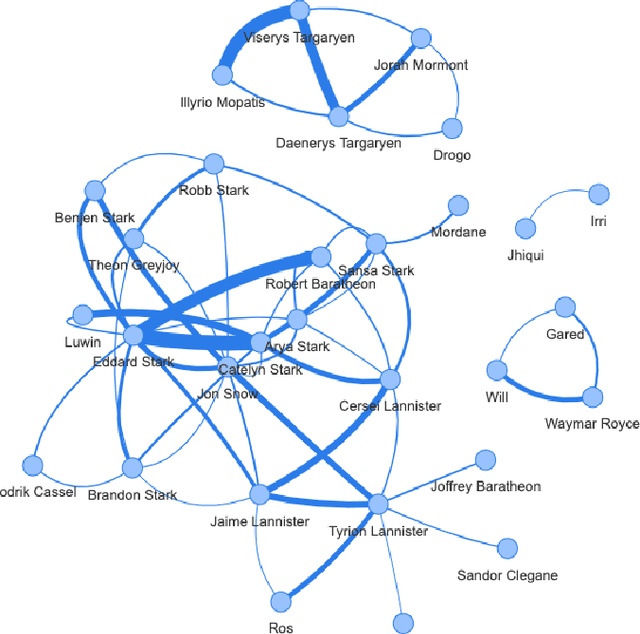
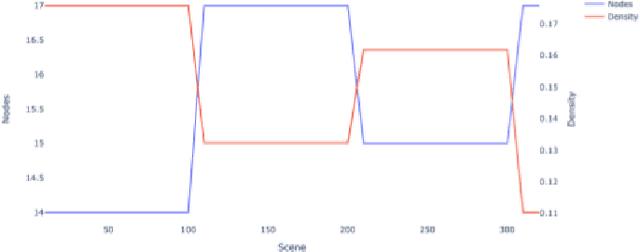
In this paper, we analyze the character networks extracted from three popular television series and explore the relationship between a TV show episode's character network metrics and its review from IMDB. Character networks are graphs created from the plot of a TV show that represents the interactions of characters in scenes, indicating the presence of a connection between them. We calculate various network metrics for each episode, such as node degree and graph density, and use these metrics to explore the potential relationship between network metrics and TV series reviews from IMDB. Our results show that certain network metrics of character interactions in episodes have a strong correlation with the review score of TV series. Our research aims to provide more quantitative information that can help TV producers understand how to adjust the character dynamics of future episodes to appeal to their audience. By understanding the impact of character interactions on audience engagement and enjoyment, producers can make informed decisions about the development of their shows.
Pretraining Conformer with ASR or ASV for Anti-Spoofing Countermeasure
Jul 04, 2023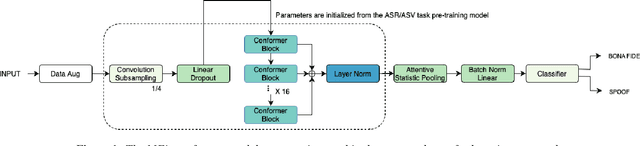
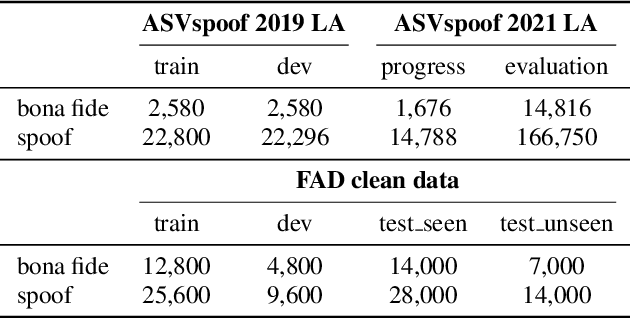
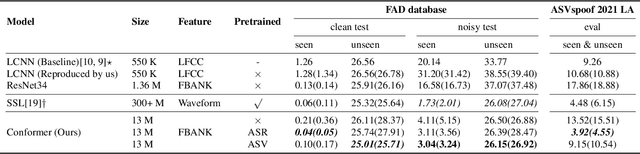
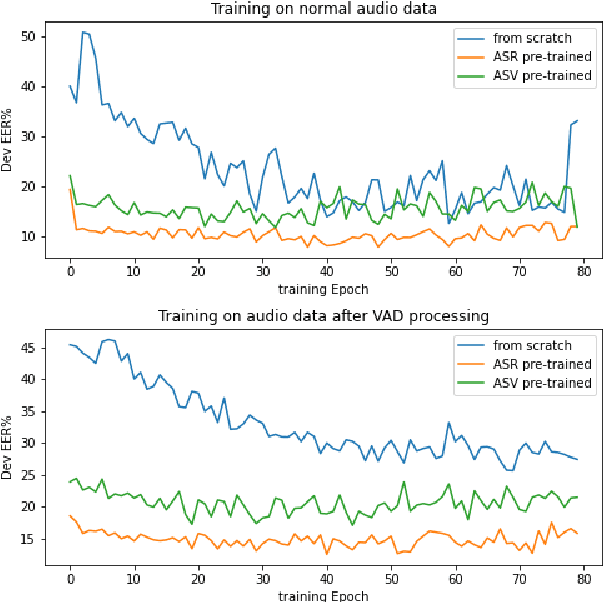
This paper introduces the Multi-scale Feature Aggregation Conformer (MFA-Conformer) structure for audio anti-spoofing countermeasure (CM). MFA-Conformer combines a convolutional neural networkbased on the Transformer, allowing it to aggregate global andlocal information. This may benefit the anti-spoofing CM system to capture the synthetic artifacts hidden both locally and globally. In addition, given the excellent performance of MFA Conformer on automatic speech recognition (ASR) and automatic speaker verification (ASV) tasks, we present a transfer learning method that utilizes pretrained Conformer models on ASR or ASV tasks to enhance the robustness of CM systems. The proposed method is evaluated on both Chinese and Englishs poofing detection databases. On the FAD clean set, the MFA-Conformer model pretrained on the ASR task achieves an EER of 0.038%, which dramatically outperforms the baseline. Moreover, experimental results demonstrate that proposed transfer learning method on Conformer is effective on pure speech segments after voice activity detection processing.