 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Common Knowledge Learning for Generating Transferable Adversarial Examples
Jul 01, 2023
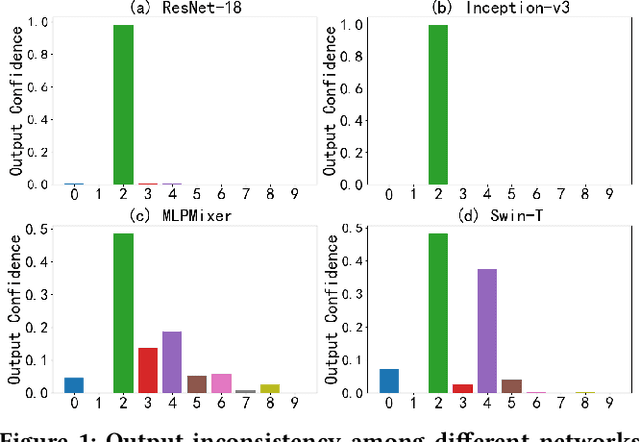
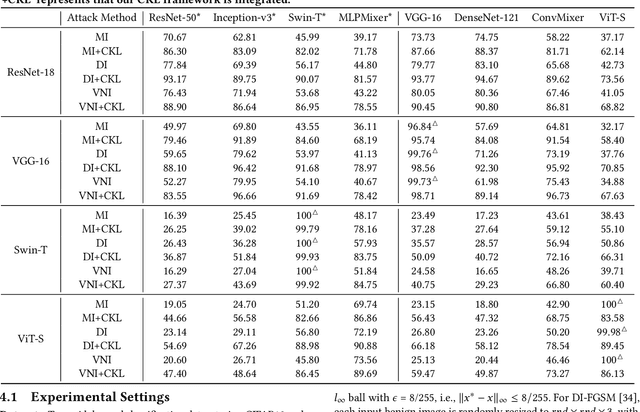
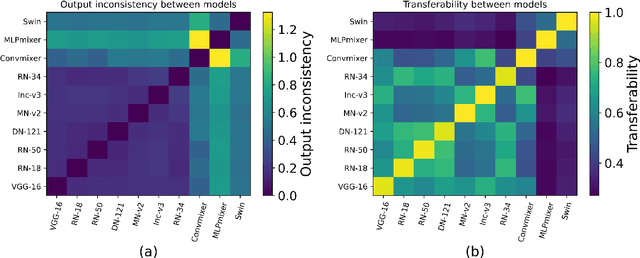
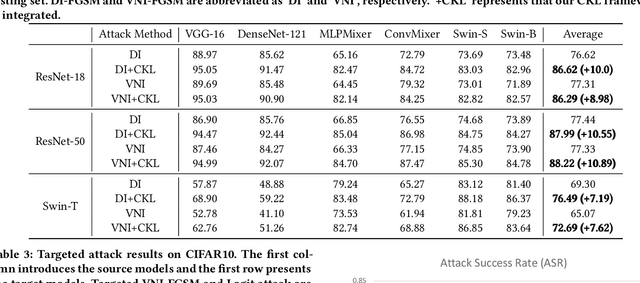
This paper focuses on an important type of black-box attacks, i.e., transfer-based adversarial attacks, where the adversary generates adversarial examples by a substitute (source) model and utilize them to attack an unseen target model, without knowing its information. Existing methods tend to give unsatisfactory adversarial transferability when the source and target models are from different types of DNN architectures (e.g. ResNet-18 and Swin Transformer). In this paper, we observe that the above phenomenon is induced by the output inconsistency problem. To alleviate this problem while effectively utilizing the existing DNN models, we propose a common knowledge learning (CKL) framework to learn better network weights to generate adversarial examples with better transferability, under fixed network architectures. Specifically, to reduce the model-specific features and obtain better output distributions, we construct a multi-teacher framework, where the knowledge is distilled from different teacher architectures into one student network. By considering that the gradient of input is usually utilized to generated adversarial examples, we impose constraints on the gradients between the student and teacher models, to further alleviate the output inconsistency problem and enhance the adversarial transferability. Extensive experiments demonstrate that our proposed work can significantly improve the adversarial transferability.
Graph Based Long-Term And Short-Term Interest Model for Click-Through Rate Prediction
Jun 05, 2023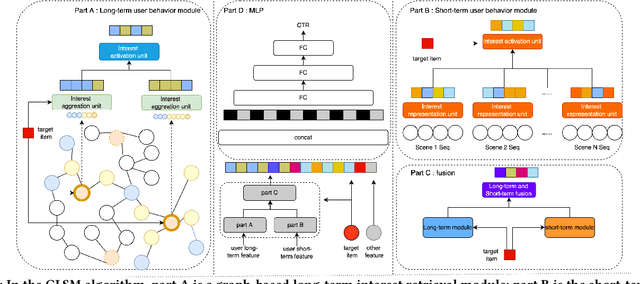
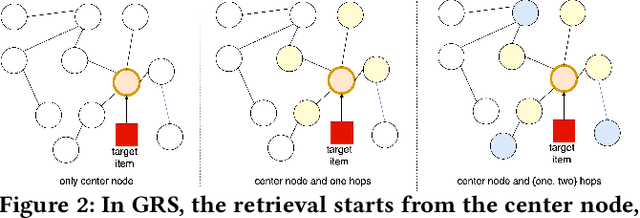
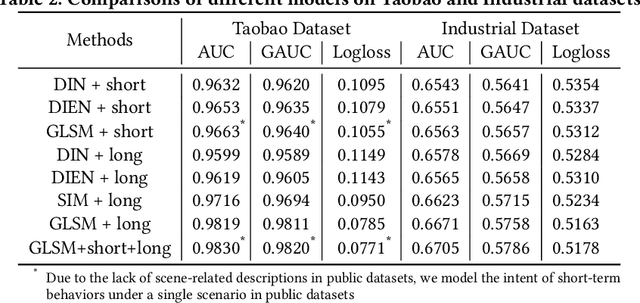
Click-through rate (CTR) prediction aims to predict the probability that the user will click an item, which has been one of the key tasks in online recommender and advertising systems. In such systems, rich user behavior (viz. long- and short-term) has been proved to be of great value in capturing user interests. Both industry and academy have paid much attention to this topic and propose different approaches to modeling with long-term and short-term user behavior data. But there are still some unresolved issues. More specially, (1) rule and truncation based methods to extract information from long-term behavior are easy to cause information loss, and (2) single feedback behavior regardless of scenario to extract information from short-term behavior lead to information confusion and noise. To fill this gap, we propose a Graph based Long-term and Short-term interest Model, termed GLSM. It consists of a multi-interest graph structure for capturing long-term user behavior, a multi-scenario heterogeneous sequence model for modeling short-term information, then an adaptive fusion mechanism to fused information from long-term and short-term behaviors. Comprehensive experiments on real-world datasets, GLSM achieved SOTA score on offline metrics. At the same time, the GLSM algorithm has been deployed in our industrial application, bringing 4.9% CTR and 4.3% GMV lift, which is significant to the business.
Opportunities and Challenges for ChatGPT and Large Language Models in Biomedicine and Health
Jun 15, 2023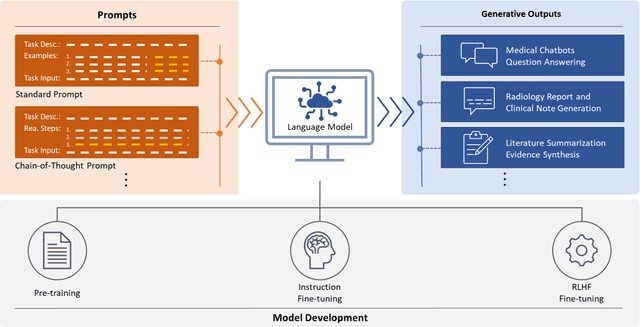
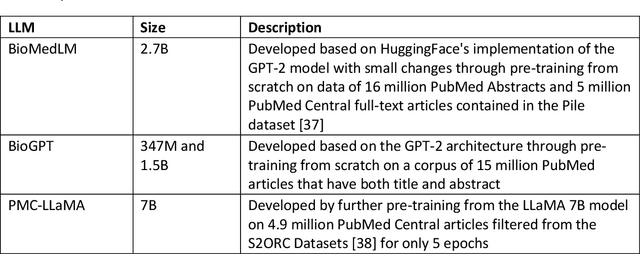
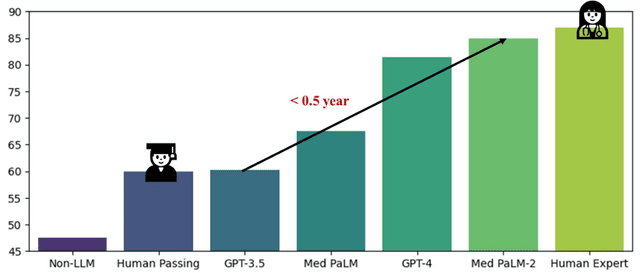
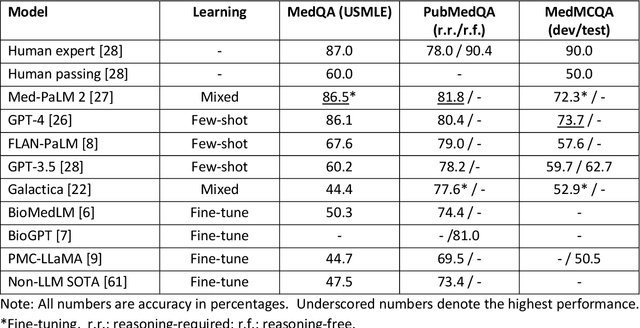
ChatGPT has drawn considerable attention from both the general public and domain experts with its remarkable text generation capabilities. This has subsequently led to the emergence of diverse applications in the field of biomedicine and health. In this work, we examine the diverse applications of large language models (LLMs), such as ChatGPT, in biomedicine and health. Specifically we explore the areas of biomedical information retrieval, question answering, medical text summarization, information extraction, and medical education, and investigate whether LLMs possess the transformative power to revolutionize these tasks or whether the distinct complexities of biomedical domain presents unique challenges. Following an extensive literature survey, we find that significant advances have been made in the field of text generation tasks, surpassing the previous state-of-the-art methods. For other applications, the advances have been modest. Overall, LLMs have not yet revolutionized the biomedicine, but recent rapid progress indicates that such methods hold great potential to provide valuable means for accelerating discovery and improving health. We also find that the use of LLMs, like ChatGPT, in the fields of biomedicine and health entails various risks and challenges, including fabricated information in its generated responses, as well as legal and privacy concerns associated with sensitive patient data. We believe this first-of-its-kind survey can provide a comprehensive overview to biomedical researchers and healthcare practitioners on the opportunities and challenges associated with using ChatGPT and other LLMs for transforming biomedicine and health.
A Hybrid Feature Selection and Construction Method for Detection of Wind Turbine Generator Heating Faults
Jun 15, 2023

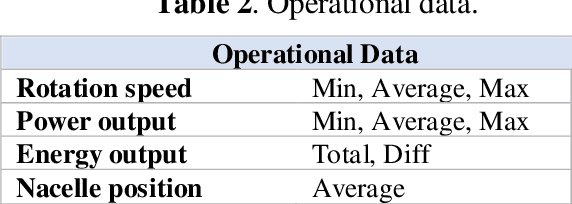
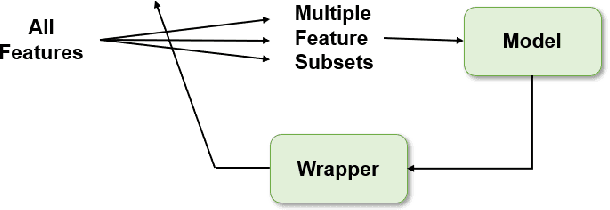
Preprocessing of information is an essential step for the effective design of machine learning applications. Feature construction and selection are powerful techniques used for this aim. In this paper, a feature selection and construction approach is presented for the detection of wind turbine generator heating faults. Data were collected from Supervisory Control and Data Acquisition (SCADA) system of a wind turbine. The original features directly collected from the data collection system consist of wind characteristics, operational data, temperature measurements and status information. In addition to these original features, new features were created in the feature construction step to obtain information that can be more powerful indications of the faults. After the construction of new features, a hybrid feature selection technique was implemented to find out the most relevant features in the overall set to increase the classification accuracy and decrease the computational burden. Feature selection step consists of filter and wrapper-based parts. Filter based feature selection was applied to exclude the features which are non-discriminative and wrapper-based method was used to determine the final features considering the redundancies and mutual relations amongst them. Artificial Neural Networks were used both in the detection phase and as the induction algorithm of the wrapper-based feature selection part. The results show that, the proposed approach contributes to the fault detection system to be more reliable especially in terms of reducing the number of false fault alarms.
Tighter Information-Theoretic Generalization Bounds from Supersamples
Feb 05, 2023
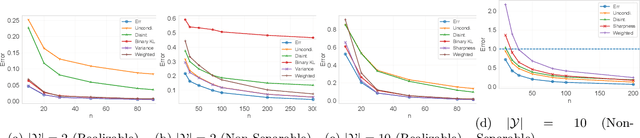
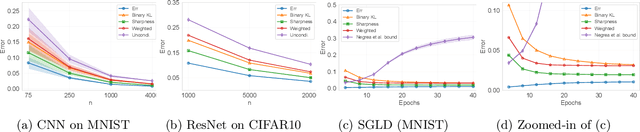
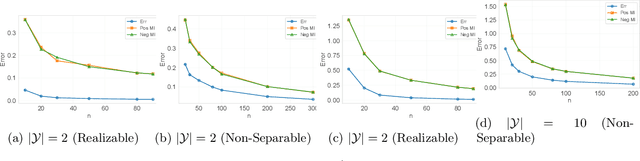
We present a variety of novel information-theoretic generalization bounds for learning algorithms, from the supersample setting of Steinke & Zakynthinou (2020)-the setting of the "conditional mutual information" framework. Our development exploits projecting the loss pair (obtained from a training instance and a testing instance) down to a single number and correlating loss values with a Rademacher sequence (and its shifted variants). The presented bounds include square-root bounds, fast-rate bounds, including those based on variance and sharpness, and bounds for interpolating algorithms etc. We show theoretically or empirically that these bounds are tighter than all information-theoretic bounds known to date on the same supersample setting.
Semi-supervised Learning from Street-View Images and OpenStreetMap for Automatic Building Height Estimation
Jul 05, 2023
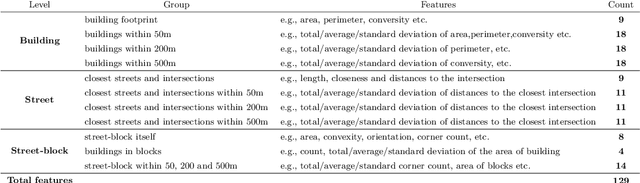
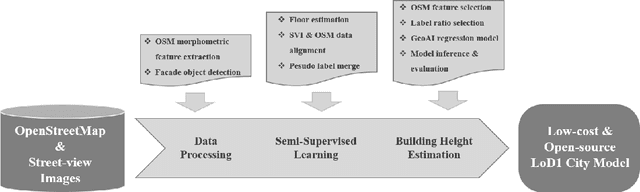

Accurate building height estimation is key to the automatic derivation of 3D city models from emerging big geospatial data, including Volunteered Geographical Information (VGI). However, an automatic solution for large-scale building height estimation based on low-cost VGI data is currently missing. The fast development of VGI data platforms, especially OpenStreetMap (OSM) and crowdsourced street-view images (SVI), offers a stimulating opportunity to fill this research gap. In this work, we propose a semi-supervised learning (SSL) method of automatically estimating building height from Mapillary SVI and OSM data to generate low-cost and open-source 3D city modeling in LoD1. The proposed method consists of three parts: first, we propose an SSL schema with the option of setting a different ratio of "pseudo label" during the supervised regression; second, we extract multi-level morphometric features from OSM data (i.e., buildings and streets) for the purposed of inferring building height; last, we design a building floor estimation workflow with a pre-trained facade object detection network to generate "pseudo label" from SVI and assign it to the corresponding OSM building footprint. In a case study, we validate the proposed SSL method in the city of Heidelberg, Germany and evaluate the model performance against the reference data of building heights. Based on three different regression models, namely Random Forest (RF), Support Vector Machine (SVM), and Convolutional Neural Network (CNN), the SSL method leads to a clear performance boosting in estimating building heights with a Mean Absolute Error (MAE) around 2.1 meters, which is competitive to state-of-the-art approaches. The preliminary result is promising and motivates our future work in scaling up the proposed method based on low-cost VGI data, with possibilities in even regions and areas with diverse data quality and availability.
SACHA: Soft Actor-Critic with Heuristic-Based Attention for Partially Observable Multi-Agent Path Finding
Jul 05, 2023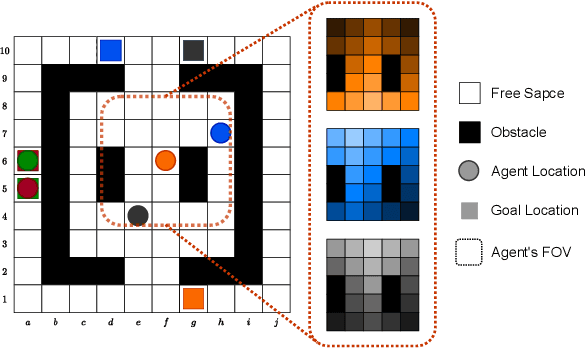
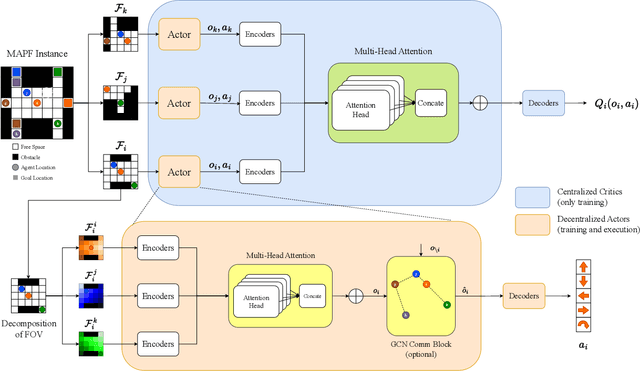
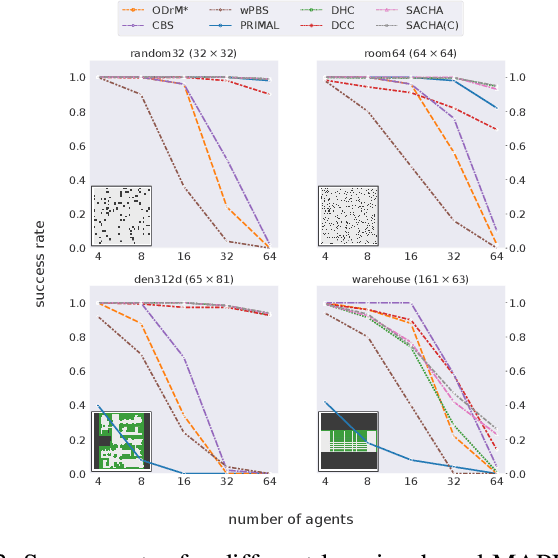

Multi-Agent Path Finding (MAPF) is a crucial component for many large-scale robotic systems, where agents must plan their collision-free paths to their given goal positions. Recently, multi-agent reinforcement learning has been introduced to solve the partially observable variant of MAPF by learning a decentralized single-agent policy in a centralized fashion based on each agent's partial observation. However, existing learning-based methods are ineffective in achieving complex multi-agent cooperation, especially in congested environments, due to the non-stationarity of this setting. To tackle this challenge, we propose a multi-agent actor-critic method called Soft Actor-Critic with Heuristic-Based Attention (SACHA), which employs novel heuristic-based attention mechanisms for both the actors and critics to encourage cooperation among agents. SACHA learns a neural network for each agent to selectively pay attention to the shortest path heuristic guidance from multiple agents within its field of view, thereby allowing for more scalable learning of cooperation. SACHA also extends the existing multi-agent actor-critic framework by introducing a novel critic centered on each agent to approximate $Q$-values. Compared to existing methods that use a fully observable critic, our agent-centered multi-agent actor-critic method results in more impartial credit assignment and better generalizability of the learned policy to MAPF instances with varying numbers of agents and types of environments. We also implement SACHA(C), which embeds a communication module in the agent's policy network to enable information exchange among agents. We evaluate both SACHA and SACHA(C) on a variety of MAPF instances and demonstrate decent improvements over several state-of-the-art learning-based MAPF methods with respect to success rate and solution quality.
Generative Semantic Communication: Diffusion Models Beyond Bit Recovery
Jun 07, 2023
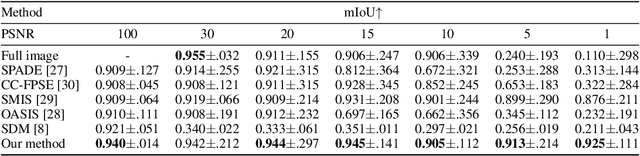
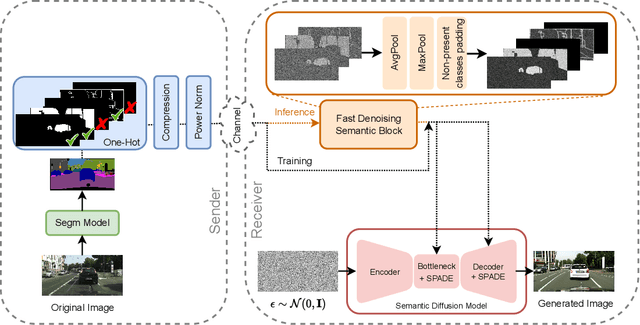
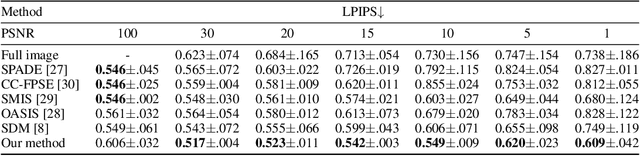
Semantic communication is expected to be one of the cores of next-generation AI-based communications. One of the possibilities offered by semantic communication is the capability to regenerate, at the destination side, images or videos semantically equivalent to the transmitted ones, without necessarily recovering the transmitted sequence of bits. The current solutions still lack the ability to build complex scenes from the received partial information. Clearly, there is an unmet need to balance the effectiveness of generation methods and the complexity of the transmitted information, possibly taking into account the goal of communication. In this paper, we aim to bridge this gap by proposing a novel generative diffusion-guided framework for semantic communication that leverages the strong abilities of diffusion models in synthesizing multimedia content while preserving semantic features. We reduce bandwidth usage by sending highly-compressed semantic information only. Then, the diffusion model learns to synthesize semantic-consistent scenes through spatially-adaptive normalizations from such denoised semantic information. We prove, through an in-depth assessment of multiple scenarios, that our method outperforms existing solutions in generating high-quality images with preserved semantic information even in cases where the received content is significantly degraded. More specifically, our results show that objects, locations, and depths are still recognizable even in the presence of extremely noisy conditions of the communication channel. The code is available at https://github.com/ispamm/GESCO.
On the Convergence of Decentralized Federated Learning Under Imperfect Information Sharing
Mar 19, 2023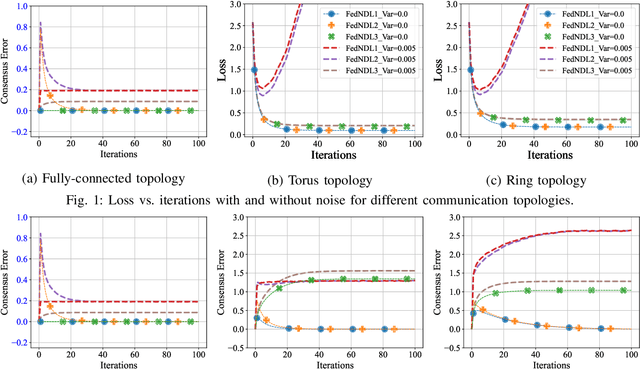
Decentralized learning and optimization is a central problem in control that encompasses several existing and emerging applications, such as federated learning. While there exists a vast literature on this topic and most methods centered around the celebrated average-consensus paradigm, less attention has been devoted to scenarios where the communication between the agents may be imperfect. To this end, this paper presents three different algorithms of Decentralized Federated Learning (DFL) in the presence of imperfect information sharing modeled as noisy communication channels. The first algorithm, Federated Noisy Decentralized Learning (FedNDL1), comes from the literature, where the noise is added to their parameters to simulate the scenario of the presence of noisy communication channels. This algorithm shares parameters to form a consensus with the clients based on a communication graph topology through a noisy communication channel. The proposed second algorithm (FedNDL2) is similar to the first algorithm but with added noise to the parameters, and it performs the gossip averaging before the gradient optimization. The proposed third algorithm (FedNDL3), on the other hand, shares the gradients through noisy communication channels instead of the parameters. Theoretical and experimental results demonstrate that under imperfect information sharing, the third scheme that mixes gradients is more robust in the presence of a noisy channel compared with the algorithms from the literature that mix the parameters.
Towards Effective and Compact Contextual Representation for Conformer Transducer Speech Recognition Systems
Jun 26, 2023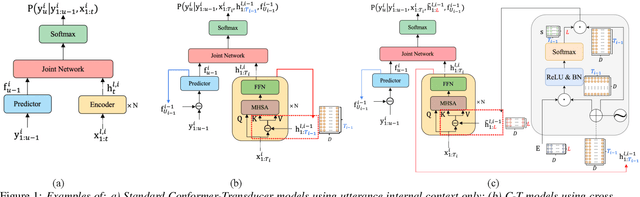
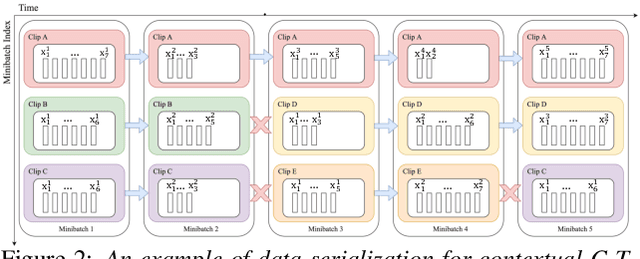
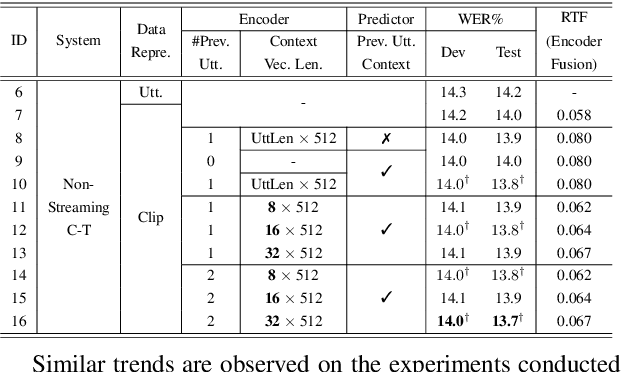
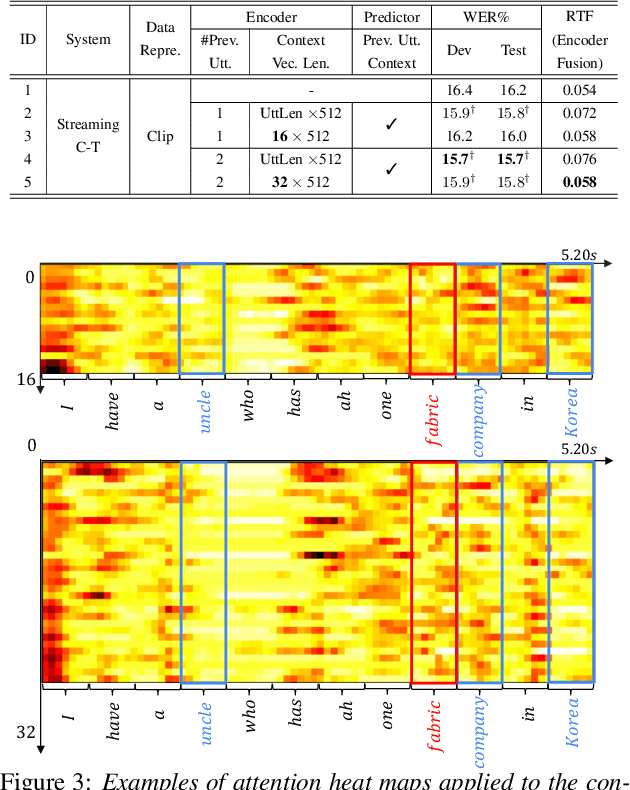
Current ASR systems are mainly trained and evaluated at the utterance level. Long range cross utterance context can be incorporated. A key task is to derive a suitable compact representation of the most relevant history contexts. In contrast to previous researches based on either LSTM-RNN encoded histories that attenuate the information from longer range contexts, or frame level concatenation of transformer context embeddings, in this paper compact low-dimensional cross utterance contextual features are learned in the Conformer-Transducer Encoder using specially designed attention pooling layers that are applied over efficiently cached preceding utterances history vectors. Experiments on the 1000-hr Gigaspeech corpus demonstrate that the proposed contextualized streaming Conformer-Transducers outperform the baseline using utterance internal context only with statistically significant WER reductions of 0.7% to 0.5% absolute (4.3% to 3.1% relative) on the dev and test data.