 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SRCD: Semantic Reasoning with Compound Domains for Single-Domain Generalized Object Detection
Jul 09, 2023
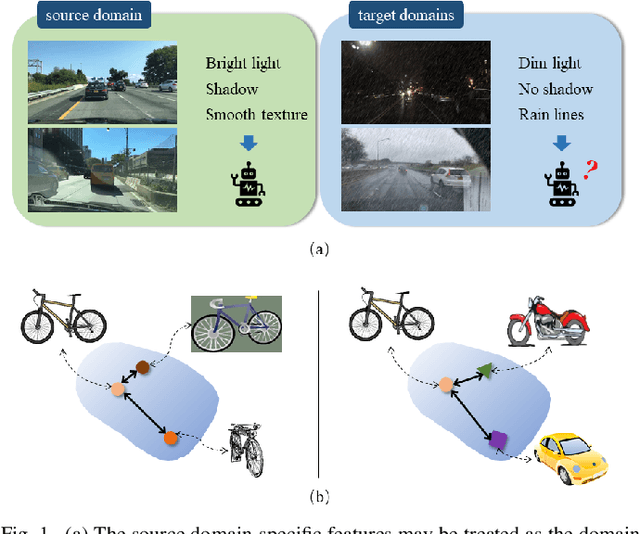

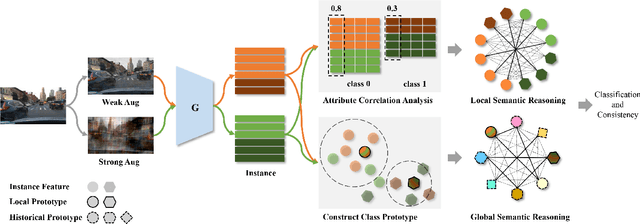

This paper provides a novel framework for single-domain generalized object detection (i.e., Single-DGOD), where we are interested in learning and maintaining the semantic structures of self-augmented compound cross-domain samples to enhance the model's generalization ability. Different from DGOD trained on multiple source domains, Single-DGOD is far more challenging to generalize well to multiple target domains with only one single source domain. Existing methods mostly adopt a similar treatment from DGOD to learn domain-invariant features by decoupling or compressing the semantic space. However, there may have two potential limitations: 1) pseudo attribute-label correlation, due to extremely scarce single-domain data; and 2) the semantic structural information is usually ignored, i.e., we found the affinities of instance-level semantic relations in samples are crucial to model generalization. In this paper, we introduce Semantic Reasoning with Compound Domains (SRCD) for Single-DGOD. Specifically, our SRCD contains two main components, namely, the texture-based self-augmentation (TBSA) module, and the local-global semantic reasoning (LGSR) module. TBSA aims to eliminate the effects of irrelevant attributes associated with labels, such as light, shadow, color, etc., at the image level by a light-yet-efficient self-augmentation. Moreover, LGSR is used to further model the semantic relationships on instance features to uncover and maintain the intrinsic semantic structures. Extensive experiments on multiple benchmarks demonstrate the effectiveness of the proposed SRCD.
Automatic Coding at Scale: Design and Deployment of a Nationwide System for Normalizing Referrals in the Chilean Public Healthcare System
Jul 09, 2023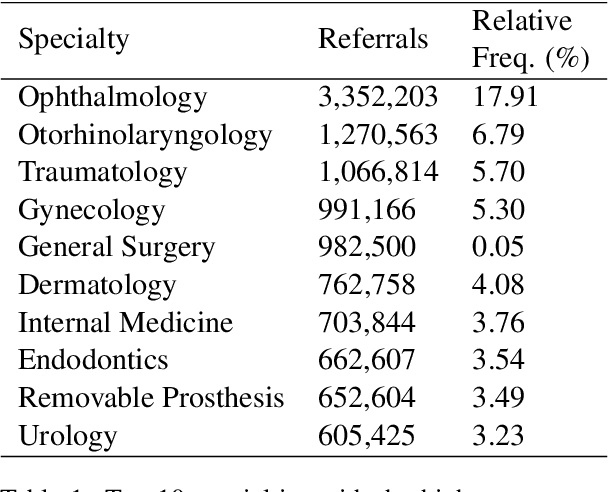
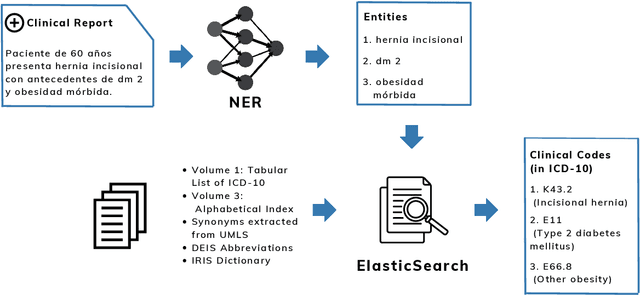
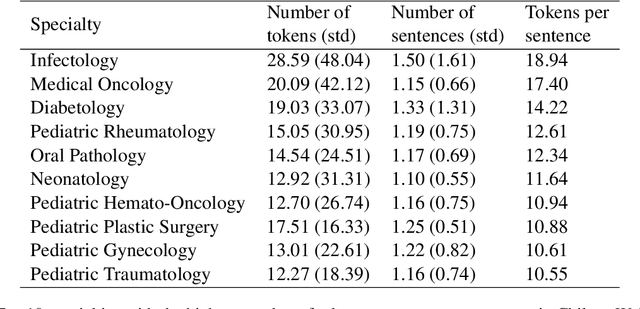
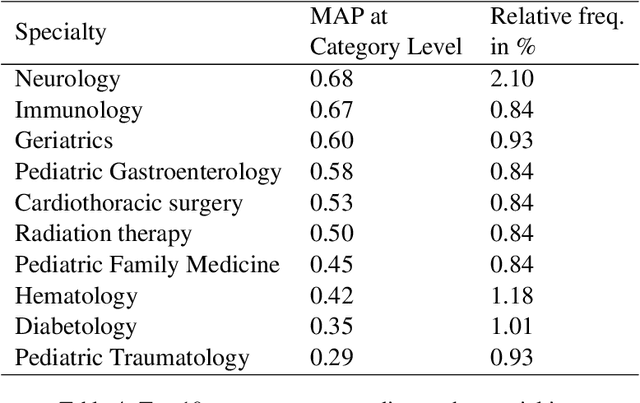
The disease coding task involves assigning a unique identifier from a controlled vocabulary to each disease mentioned in a clinical document. This task is relevant since it allows information extraction from unstructured data to perform, for example, epidemiological studies about the incidence and prevalence of diseases in a determined context. However, the manual coding process is subject to errors as it requires medical personnel to be competent in coding rules and terminology. In addition, this process consumes a lot of time and energy, which could be allocated to more clinically relevant tasks. These difficulties can be addressed by developing computational systems that automatically assign codes to diseases. In this way, we propose a two-step system for automatically coding diseases in referrals from the Chilean public healthcare system. Specifically, our model uses a state-of-the-art NER model for recognizing disease mentions and a search engine system based on Elasticsearch for assigning the most relevant codes associated with these disease mentions. The system's performance was evaluated on referrals manually coded by clinical experts. Our system obtained a MAP score of 0.63 for the subcategory level and 0.83 for the category level, close to the best-performing models in the literature. This system could be a support tool for health professionals, optimizing the coding and management process. Finally, to guarantee reproducibility, we publicly release the code of our models and experiments.
TensorGPT: Efficient Compression of the Embedding Layer in LLMs based on the Tensor-Train Decomposition
Jul 02, 2023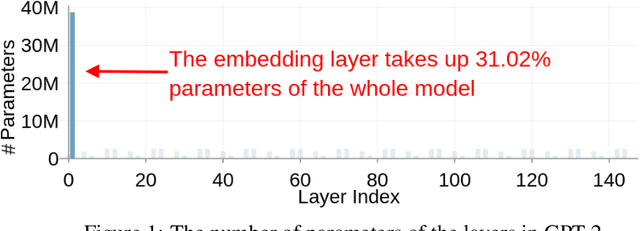
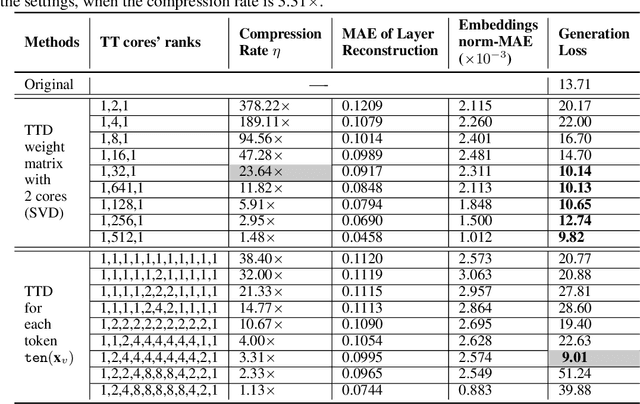
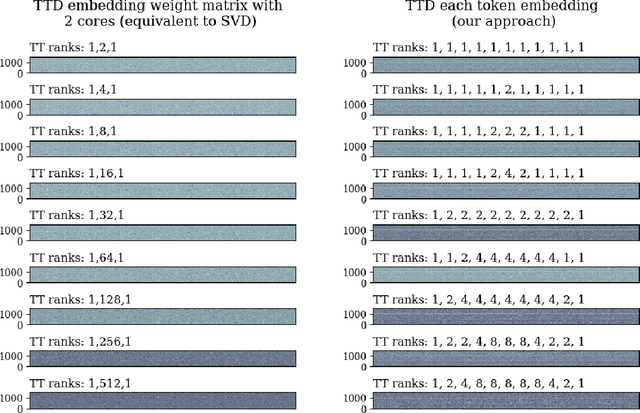
High-dimensional token embeddings underpin Large Language Models (LLMs), as they can capture subtle semantic information and significantly enhance the modelling of complex language patterns. However, the associated high dimensionality also introduces considerable model parameters, and a prohibitively high model storage. To address this issue, this work proposes an approach based on the Tensor-Train Decomposition (TTD), where each token embedding is treated as a Matrix Product State (MPS) that can be efficiently computed in a distributed manner. The experimental results on GPT-2 demonstrate that, through our approach, the embedding layer can be compressed by a factor of up to 38.40 times, and when the compression factor is 3.31 times, even produced a better performance than the original GPT-2 model.
Learning from Heterogeneity: A Dynamic Learning Framework for Hypergraphs
Jul 07, 2023
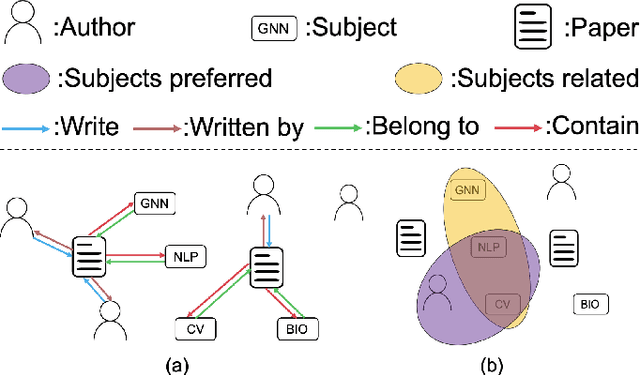
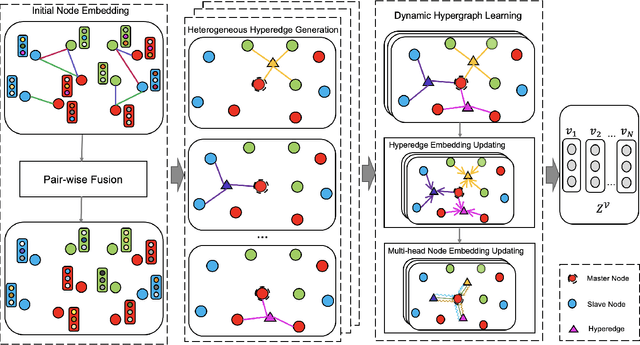
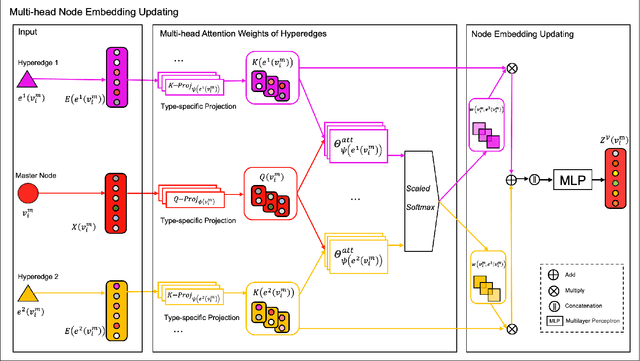
Graph neural network (GNN) has gained increasing popularity in recent years owing to its capability and flexibility in modeling complex graph structure data. Among all graph learning methods, hypergraph learning is a technique for exploring the implicit higher-order correlations when training the embedding space of the graph. In this paper, we propose a hypergraph learning framework named LFH that is capable of dynamic hyperedge construction and attentive embedding update utilizing the heterogeneity attributes of the graph. Specifically, in our framework, the high-quality features are first generated by the pairwise fusion strategy that utilizes explicit graph structure information when generating initial node embedding. Afterwards, a hypergraph is constructed through the dynamic grouping of implicit hyperedges, followed by the type-specific hypergraph learning process. To evaluate the effectiveness of our proposed framework, we conduct comprehensive experiments on several popular datasets with eleven state-of-the-art models on both node classification and link prediction tasks, which fall into categories of homogeneous pairwise graph learning, heterogeneous pairwise graph learning, and hypergraph learning. The experiment results demonstrate a significant performance gain (average 12.5% in node classification and 13.3% in link prediction) compared with recent state-of-the-art methods.
A Self-Supervised Algorithm for Denoising Photoplethysmography Signals for Heart Rate Estimation from Wearables
Jul 07, 2023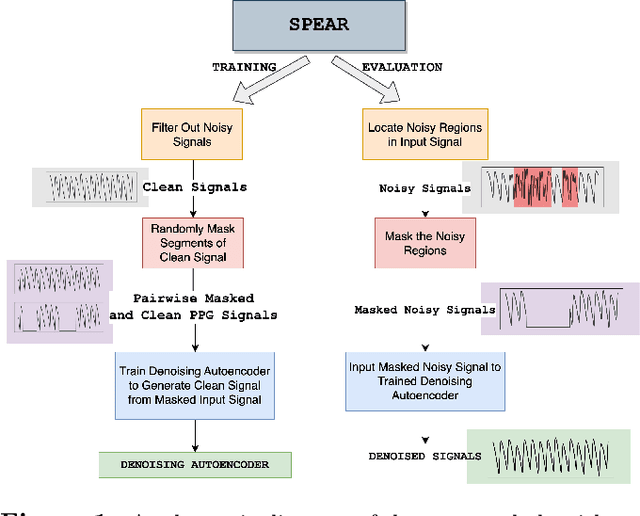
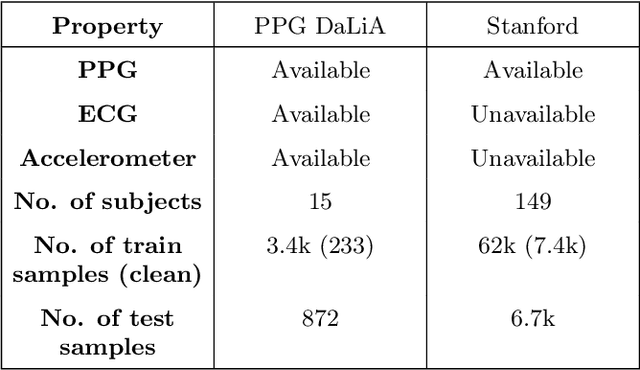
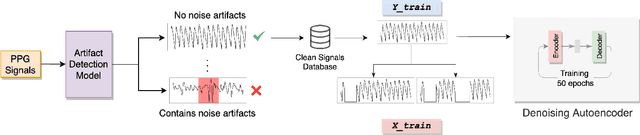
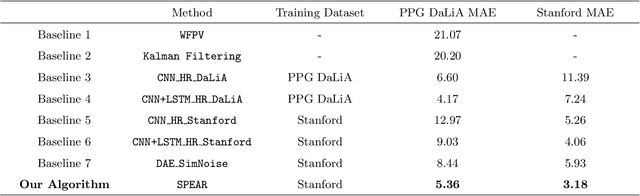
Smart watches and other wearable devices are equipped with photoplethysmography (PPG) sensors for monitoring heart rate and other aspects of cardiovascular health. However, PPG signals collected from such devices are susceptible to corruption from noise and motion artifacts, which cause errors in heart rate estimation. Typical denoising approaches filter or reconstruct the signal in ways that eliminate much of the morphological information, even from the clean parts of the signal that would be useful to preserve. In this work, we develop an algorithm for denoising PPG signals that reconstructs the corrupted parts of the signal, while preserving the clean parts of the PPG signal. Our novel framework relies on self-supervised training, where we leverage a large database of clean PPG signals to train a denoising autoencoder. As we show, our reconstructed signals provide better estimates of heart rate from PPG signals than the leading heart rate estimation methods. Further experiments show significant improvement in Heart Rate Variability (HRV) estimation from PPG signals using our algorithm. We conclude that our algorithm denoises PPG signals in a way that can improve downstream analysis of many different health metrics from wearable devices.
A Fine Grained Stochastic Geometry Based Analysis on LEO Satellite Communication Systems
Jul 04, 2023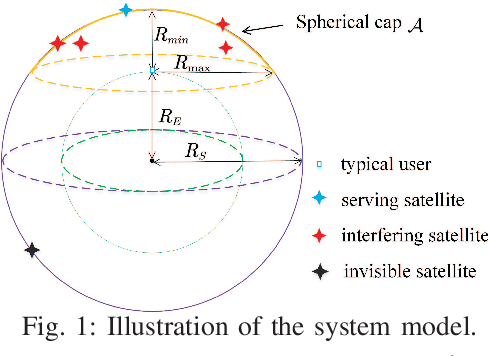
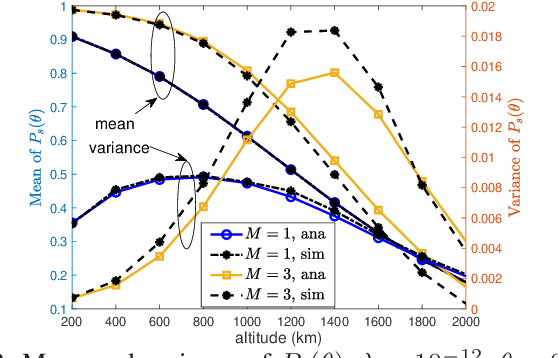
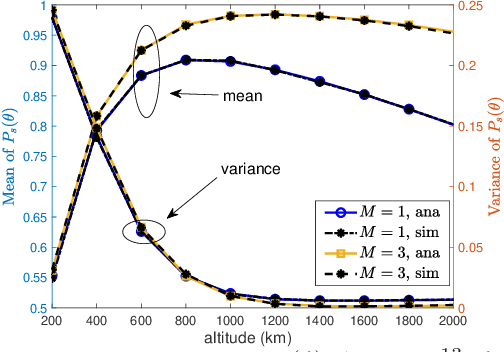
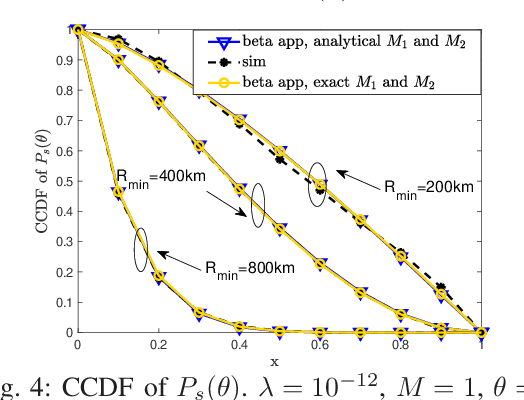
Recently, stochastic geometry has been applied to provide tractable performance analysis for low earth orbit (LEO) satellite networks. However, existing works mainly focus on analyzing the ``coverage probability'', which provides limited information. To provide more insights, this paper provides a more fine grained analysis on LEO satellite networks modeled by a homogeneous Poisson point process (HPPP). Specifically, the distribution and moments of the conditional coverage probability given the point process are studied. The developed analytical results can provide characterizations on LEO satellite networks, which are not available in existing literature, such as ``user fairness'' and ``what fraction of users can achieve a given transmission reliability ''. Simulation results are provided to verify the developed analysis. Numerical results show that, in a dense satellite network, {\color{black}it is} beneficial to deploy satellites at low altitude, for the sake of both coverage probability and user fairness.
TACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning
Jun 22, 2023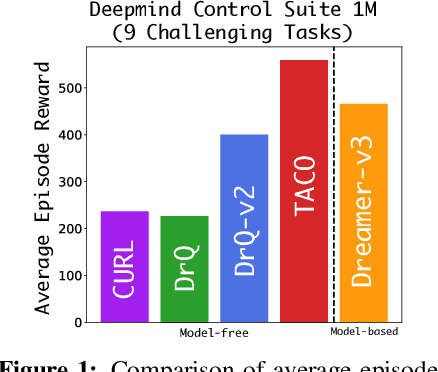
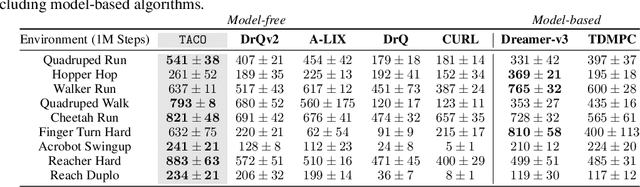
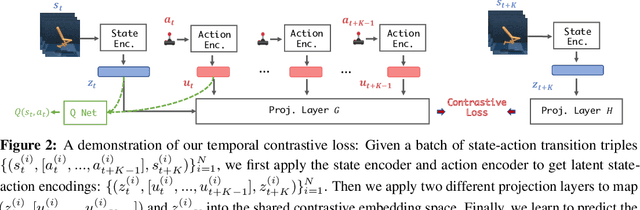
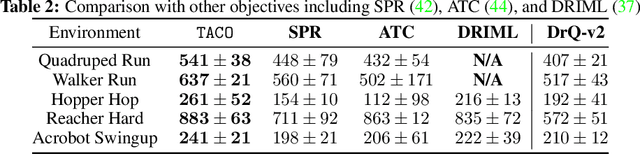
Despite recent progress in reinforcement learning (RL) from raw pixel data, sample inefficiency continues to present a substantial obstacle. Prior works have attempted to address this challenge by creating self-supervised auxiliary tasks, aiming to enrich the agent's learned representations with control-relevant information for future state prediction. However, these objectives are often insufficient to learn representations that can represent the optimal policy or value function, and they often consider tasks with small, abstract discrete action spaces and thus overlook the importance of action representation learning in continuous control. In this paper, we introduce TACO: Temporal Action-driven Contrastive Learning, a simple yet powerful temporal contrastive learning approach that facilitates the concurrent acquisition of latent state and action representations for agents. TACO simultaneously learns a state and an action representation by optimizing the mutual information between representations of current states paired with action sequences and representations of the corresponding future states. Theoretically, TACO can be shown to learn state and action representations that encompass sufficient information for control, thereby improving sample efficiency. For online RL, TACO achieves 40% performance boost after one million environment interaction steps on average across nine challenging visual continuous control tasks from Deepmind Control Suite. In addition, we show that TACO can also serve as a plug-and-play module adding to existing offline visual RL methods to establish the new state-of-the-art performance for offline visual RL across offline datasets with varying quality.
IRS-Aided Overloaded Multi-Antenna Systems: Joint User Grouping and Resource Allocation
Jul 01, 2023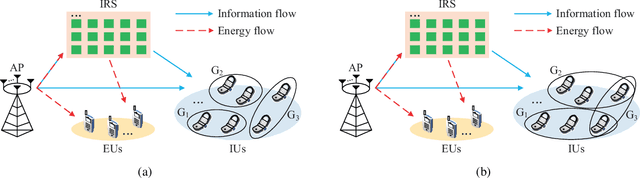
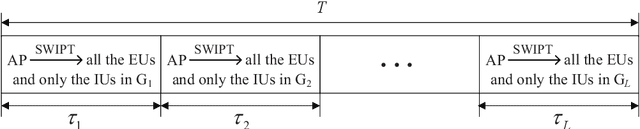
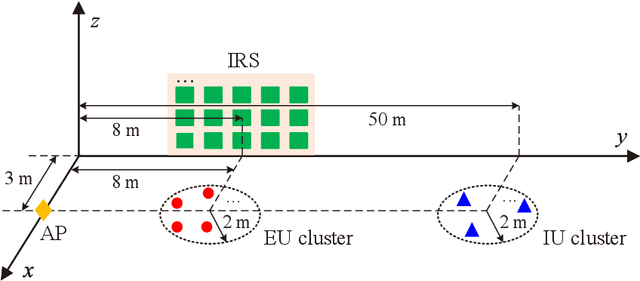
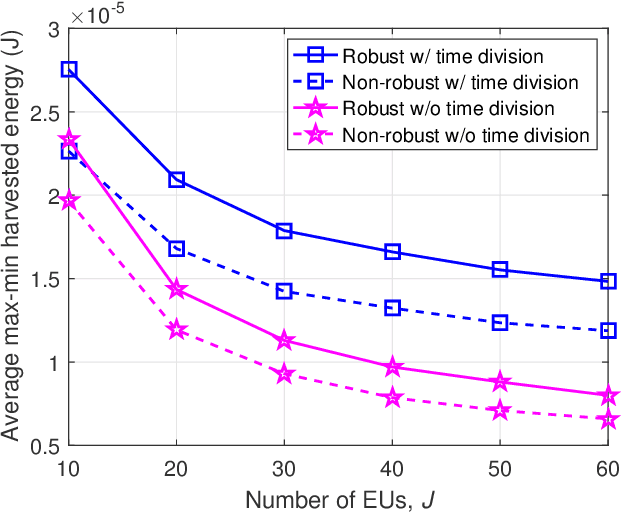
This paper studies an intelligent reflecting surface (IRS)-aided multi-antenna simultaneous wireless information and power transfer (SWIPT) system where an $M$-antenna access point (AP) serves $K$ single-antenna information users (IUs) and $J$ single-antenna energy users (EUs) with the aid of an IRS with phase errors. We explicitly concentrate on overloaded scenarios where $K + J > M$ and $K \geq M$. Our goal is to maximize the minimum throughput among all the IUs by optimizing the allocation of resources (including time, transmit beamforming at the AP, and reflect beamforming at the IRS), while guaranteeing the minimum amount of harvested energy at each EU. Towards this goal, we propose two user grouping (UG) schemes, namely, the non-overlapping UG scheme and the overlapping UG scheme, where the difference lies in whether identical IUs can exist in multiple groups. Different IU groups are served in orthogonal time dimensions, while the IUs in the same group are served simultaneously with all the EUs via spatial multiplexing. The two problems corresponding to the two UG schemes are mixed-integer non-convex optimization problems and difficult to solve optimally. We propose efficient algorithms for these two problems based on the big-M formulation, the penalty method, the block coordinate descent, and the successive convex approximation. Simulation results show that: 1) the non-robust counterparts of the proposed robust designs are unsuitable for practical IRS-aided SWIPT systems with phase errors since the energy harvesting constraints cannot be satisfied; 2) the proposed UG strategies can significantly improve the max-min throughput over the benchmark schemes without UG or adopting random UG; 3) the overlapping UG scheme performs much better than its non-overlapping counterpart when the absolute difference between $K$ and $M$ is small and the EH constraints are not stringent.
Learning Unseen Modality Interaction
Jun 22, 2023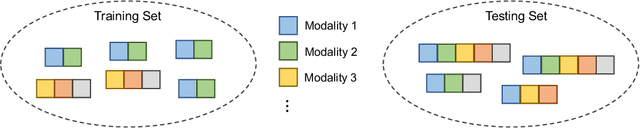

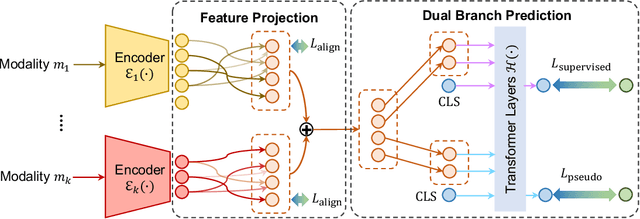
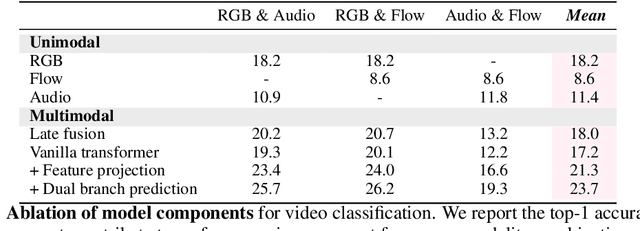
Multimodal learning assumes all modality combinations of interest are available during training to learn cross-modal correspondences. In this paper, we challenge this modality-complete assumption for multimodal learning and instead strive for generalization to unseen modality combinations during inference. We pose the problem of unseen modality interaction and introduce a first solution. It exploits a feature projection module to project the multidimensional features of different modalities into a common space with rich information reserved. This allows the information to be accumulated with a simple summation operation across available modalities. To reduce overfitting to unreliable modality combinations during training, we further improve the model learning with pseudo-supervision indicating the reliability of a modality's prediction. We demonstrate that our approach is effective for diverse tasks and modalities by evaluating it for multimodal video classification, robot state regression, and multimedia retrieval.
Uncertainty Estimation by Fisher Information-based Evidential Deep Learning
Mar 13, 2023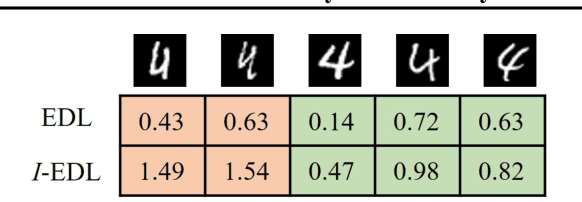
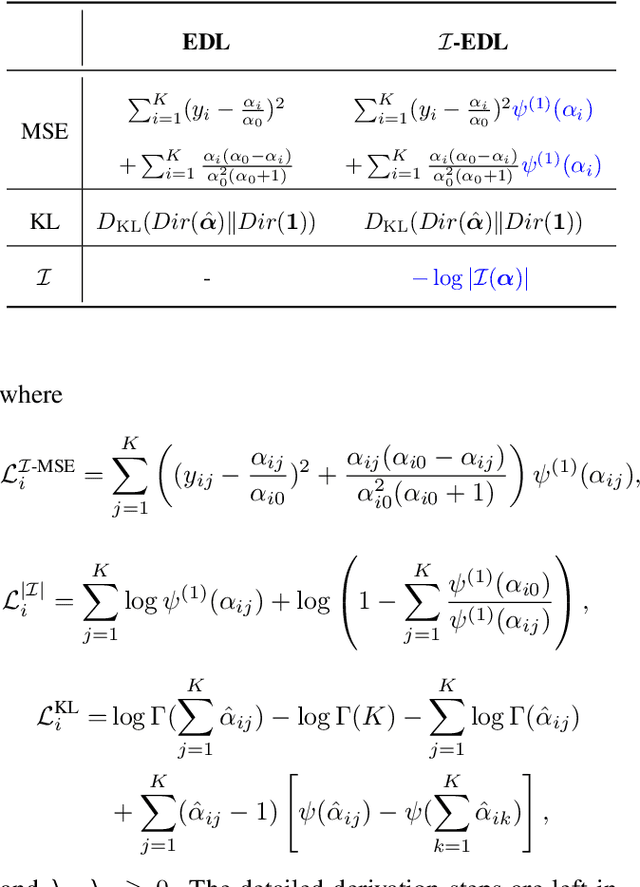
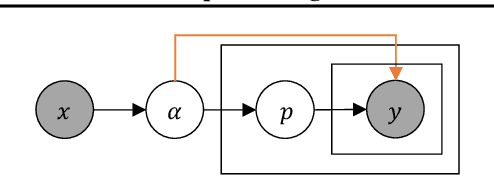
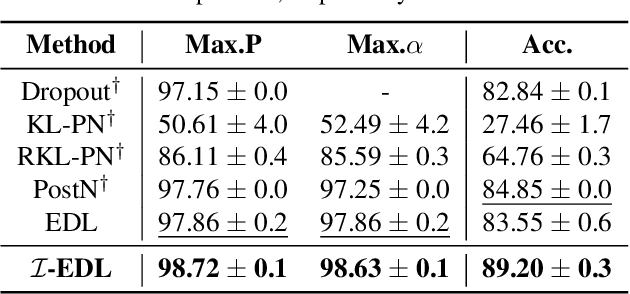
Uncertainty estimation is a key factor that makes deep learning reliable in practical applications. Recently proposed evidential neural networks explicitly account for different uncertainties by treating the network's outputs as evidence to parameterize the Dirichlet distribution, and achieve impressive performance in uncertainty estimation. However, for high data uncertainty samples but annotated with the one-hot label, the evidence-learning process for those mislabeled classes is over-penalized and remains hindered. To address this problem, we propose a novel method, Fisher Information-based Evidential Deep Learning ($\mathcal{I}$-EDL). In particular, we introduce Fisher Information Matrix (FIM) to measure the informativeness of evidence carried by each sample, according to which we can dynamically reweight the objective loss terms to make the network more focused on the representation learning of uncertain classes. The generalization ability of our network is further improved by optimizing the PAC-Bayesian bound. As demonstrated empirically, our proposed method consistently outperforms traditional EDL-related algorithms in multiple uncertainty estimation tasks, especially in the more challenging few-shot classification settings.