 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ELM-based Timing Synchronization for OFDM Systems by Exploiting Computer-aided Training Strategy
Jun 30, 2023
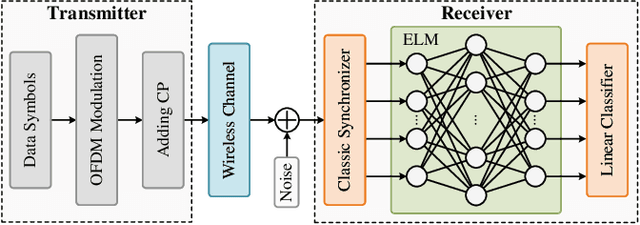
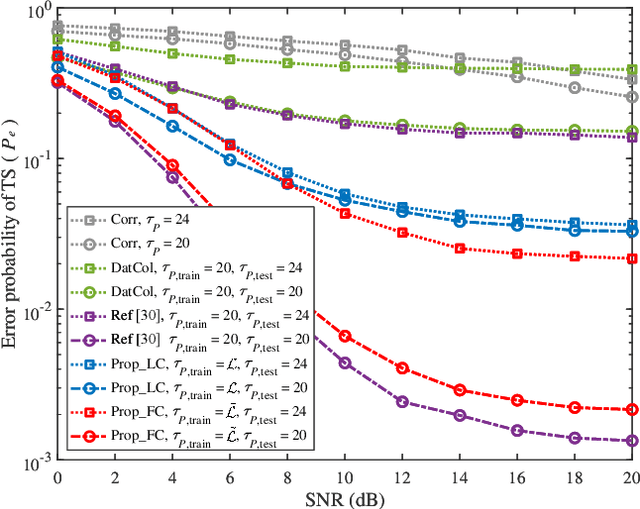
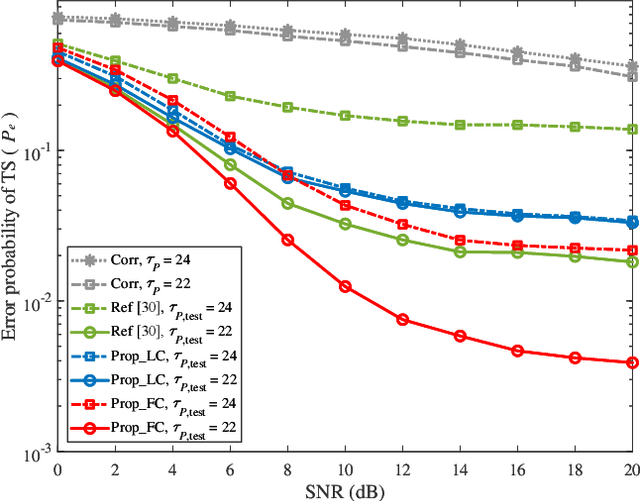
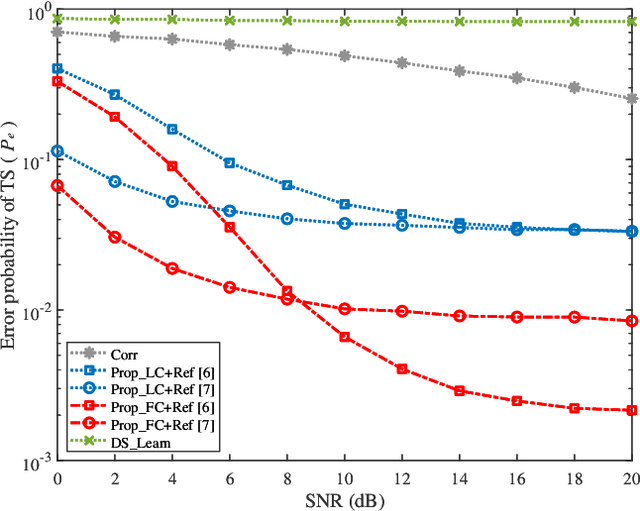
Due to the implementation bottleneck of training data collection in realistic wireless communications systems, supervised learning-based timing synchronization (TS) is challenged by the incompleteness of training data. To tackle this bottleneck, we extend the computer-aided approach, with which the local device can generate the training data instead of generating learning labels from the received samples collected in realistic systems, and then construct an extreme learning machine (ELM)-based TS network in orthogonal frequency division multiplexing (OFDM) systems. Specifically, by leveraging the rough information of channel impulse responses (CIRs), i.e., root-mean-square (r.m.s) delay, we propose the loose constraint-based and flexible constraint-based training strategies for the learning-label design against the maximum multi-path delay. The underlying mechanism is to improve the completeness of multi-path delays that may appear in the realistic wireless channels and thus increase the statistical efficiency of the designed TS learner. By this means, the proposed ELM-based TS network can alleviate the degradation of generalization performance. Numerical results reveal the robustness and generalization of the proposed scheme against varying parameters.
Artifacts Mapping: Multi-Modal Semantic Mapping for Object Detection and 3D Localization
Jul 03, 2023
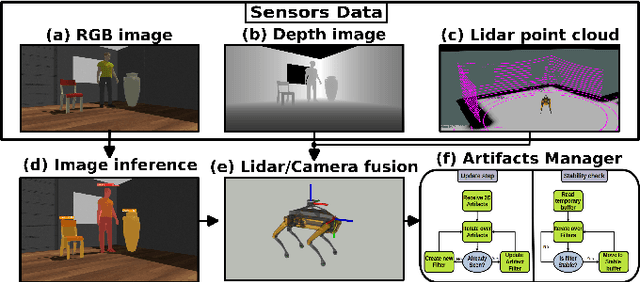

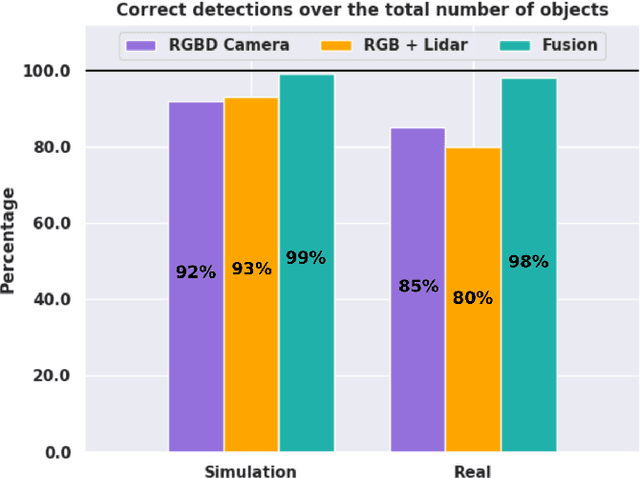
Geometric navigation is nowadays a well-established field of robotics and the research focus is shifting towards higher-level scene understanding, such as Semantic Mapping. When a robot needs to interact with its environment, it must be able to comprehend the contextual information of its surroundings. This work focuses on classifying and localising objects within a map, which is under construction (SLAM) or already built. To further explore this direction, we propose a framework that can autonomously detect and localize predefined objects in a known environment using a multi-modal sensor fusion approach (combining RGB and depth data from an RGB-D camera and a lidar). The framework consists of three key elements: understanding the environment through RGB data, estimating depth through multi-modal sensor fusion, and managing artifacts (i.e., filtering and stabilizing measurements). The experiments show that the proposed framework can accurately detect 98% of the objects in the real sample environment, without post-processing, while 85% and 80% of the objects were mapped using the single RGBD camera or RGB + lidar setup respectively. The comparison with single-sensor (camera or lidar) experiments is performed to show that sensor fusion allows the robot to accurately detect near and far obstacles, which would have been noisy or imprecise in a purely visual or laser-based approach.
HODINet: High-Order Discrepant Interaction Network for RGB-D Salient Object Detection
Jul 03, 2023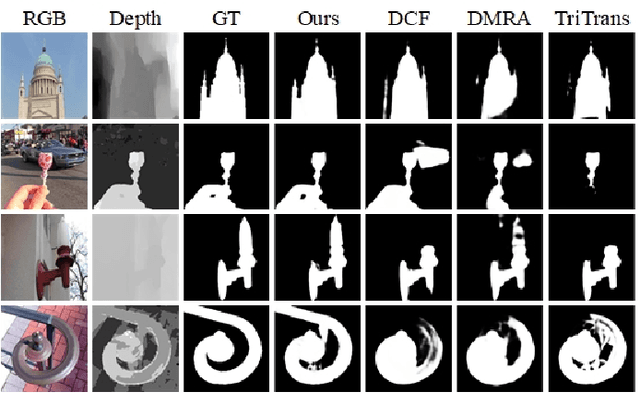
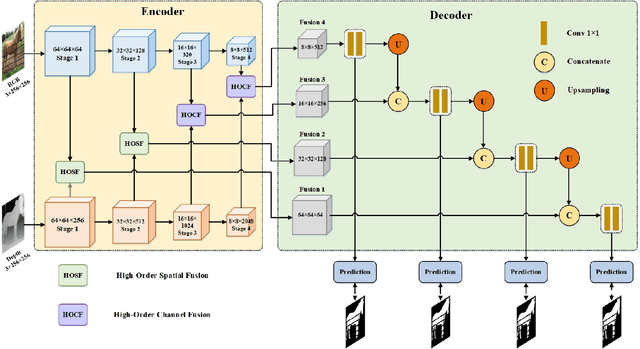
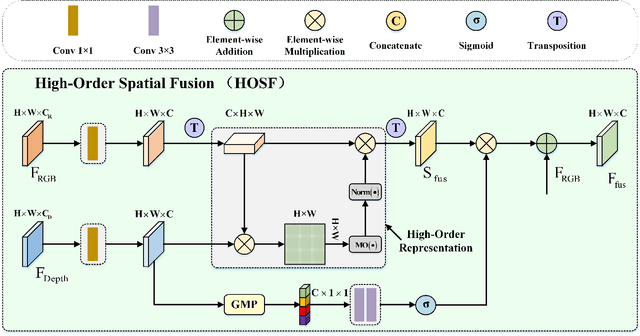
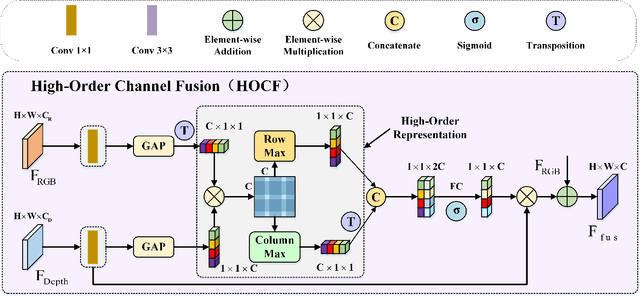
RGB-D salient object detection (SOD) aims to detect the prominent regions by jointly modeling RGB and depth information. Most RGB-D SOD methods apply the same type of backbones and fusion modules to identically learn the multimodality and multistage features. However, these features contribute differently to the final saliency results, which raises two issues: 1) how to model discrepant characteristics of RGB images and depth maps; 2) how to fuse these cross-modality features in different stages. In this paper, we propose a high-order discrepant interaction network (HODINet) for RGB-D SOD. Concretely, we first employ transformer-based and CNN-based architectures as backbones to encode RGB and depth features, respectively. Then, the high-order representations are delicately extracted and embedded into spatial and channel attentions for cross-modality feature fusion in different stages. Specifically, we design a high-order spatial fusion (HOSF) module and a high-order channel fusion (HOCF) module to fuse features of the first two and the last two stages, respectively. Besides, a cascaded pyramid reconstruction network is adopted to progressively decode the fused features in a top-down pathway. Extensive experiments are conducted on seven widely used datasets to demonstrate the effectiveness of the proposed approach. We achieve competitive performance against 24 state-of-the-art methods under four evaluation metrics.
Metric Learning-Based Timing Synchronization by Using Lightweight Neural Network
Jul 01, 2023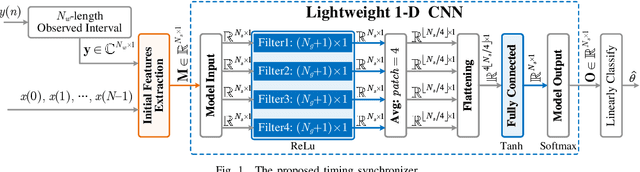
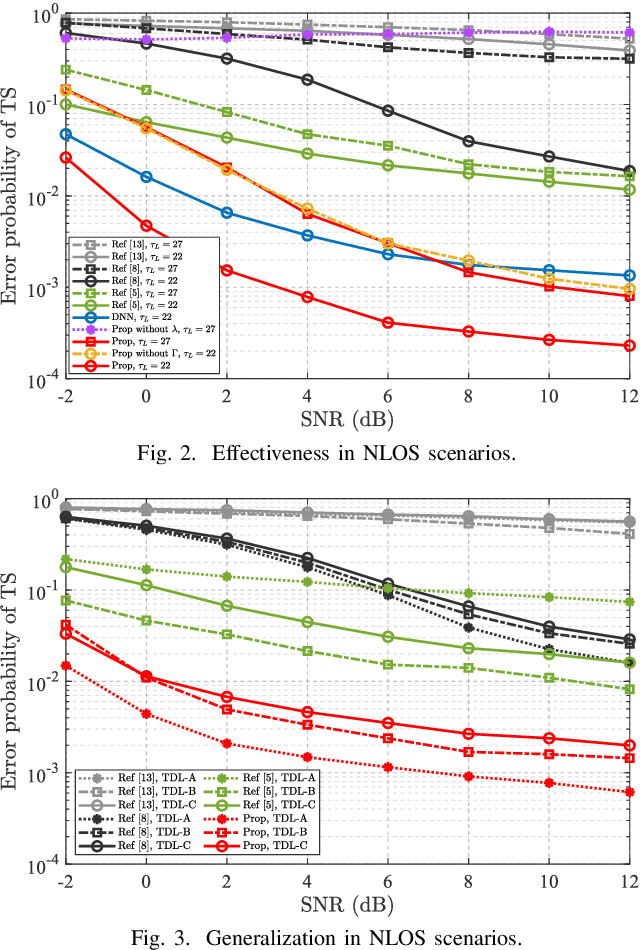
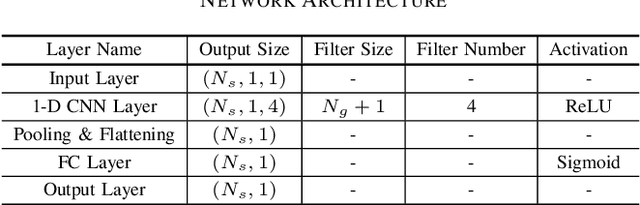

Timing synchronization (TS) is one of the key tasks in orthogonal frequency division multiplexing (OFDM) systems. However, multi-path uncertainty corrupts the TS correctness, making OFDM systems suffer from a severe inter-symbol-interference (ISI). To tackle this issue, we propose a timing-metric learning-based TS method assisted by a lightweight one-dimensional convolutional neural network (1-D CNN). Specifically, the receptive field of 1-D CNN is specifically designed to extract the metric features from the classic synchronizer. Then, to combat the multi-path uncertainty, we employ the varying delays and gains of multi-path (the characteristics of multi-path uncertainty) to design the timing-metric objective, and thus form the training labels. This is typically different from the existing timing-metric objectives with respect to the timing synchronization point. Our method substantively increases the completeness of training data against the multi-path uncertainty due to the complete preservation of metric information. By this mean, the TS correctness is improved against the multi-path uncertainty. Numerical results demonstrate the effectiveness and generalization of the proposed TS method against the multi-path uncertainty.
RH20T: A Robotic Dataset for Learning Diverse Skills in One-Shot
Jul 02, 2023
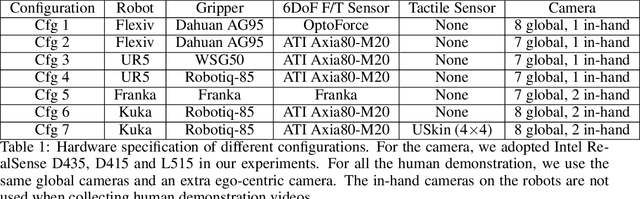

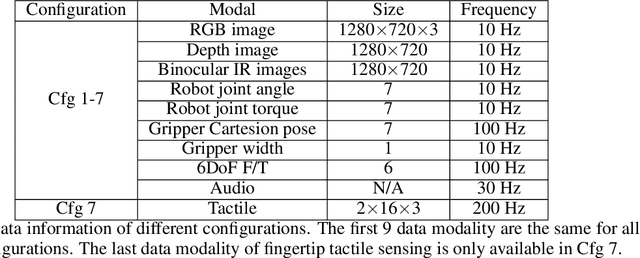
A key challenge in robotic manipulation in open domains is how to acquire diverse and generalizable skills for robots. Recent research in one-shot imitation learning has shown promise in transferring trained policies to new tasks based on demonstrations. This feature is attractive for enabling robots to acquire new skills and improving task and motion planning. However, due to limitations in the training dataset, the current focus of the community has mainly been on simple cases, such as push or pick-place tasks, relying solely on visual guidance. In reality, there are many complex skills, some of which may even require both visual and tactile perception to solve. This paper aims to unlock the potential for an agent to generalize to hundreds of real-world skills with multi-modal perception. To achieve this, we have collected a dataset comprising over 110,000 \emph{contact-rich} robot manipulation sequences across diverse skills, contexts, robots, and camera viewpoints, all collected \emph{in the real world}. Each sequence in the dataset includes visual, force, audio, and action information, along with a corresponding human demonstration video. We have invested significant efforts in calibrating all the sensors and ensuring a high-quality dataset. The dataset is made publicly available at rh20t.github.io
Vietnamese multi-document summary using subgraph selection approach -- VLSP 2022 AbMuSu Shared Task
Jun 26, 2023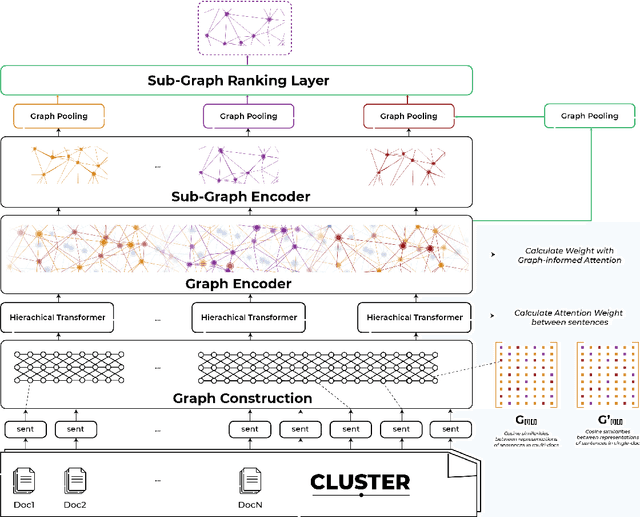
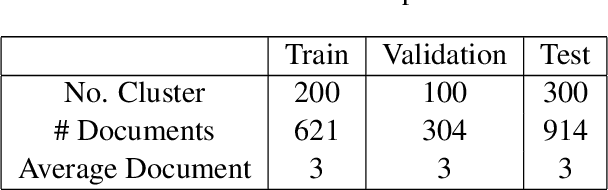
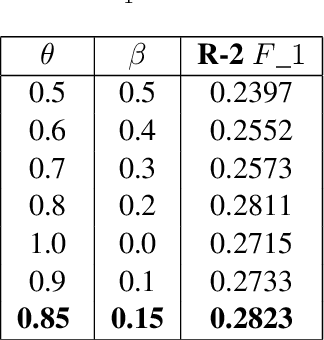
Document summarization is a task to generate afluent, condensed summary for a document, andkeep important information. A cluster of documents serves as the input for multi-document summarizing (MDS), while the cluster summary serves as the output. In this paper, we focus on transforming the extractive MDS problem into subgraph selection. Approaching the problem in the form of graphs helps to capture simultaneously the relationship between sentences in the same document and between sentences in the same cluster based on exploiting the overall graph structure and selected subgraphs. Experiments have been implemented on the Vietnamese dataset published in VLSP Evaluation Campaign 2022. This model currently results in the top 10 participating teams reported on the ROUGH-2 $F\_1$ measure on the public test set.
Mass Spectra Prediction with Structural Motif-based Graph Neural Networks
Jun 28, 2023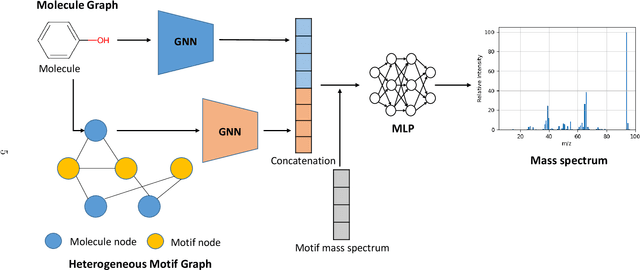
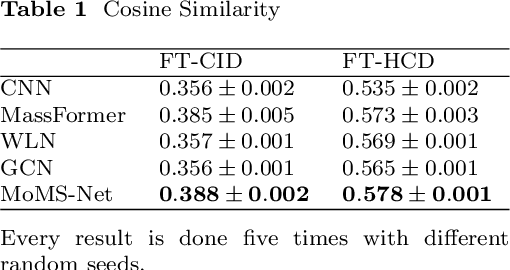
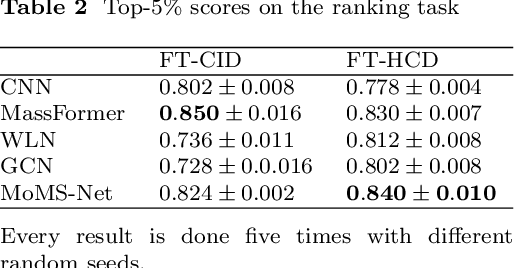
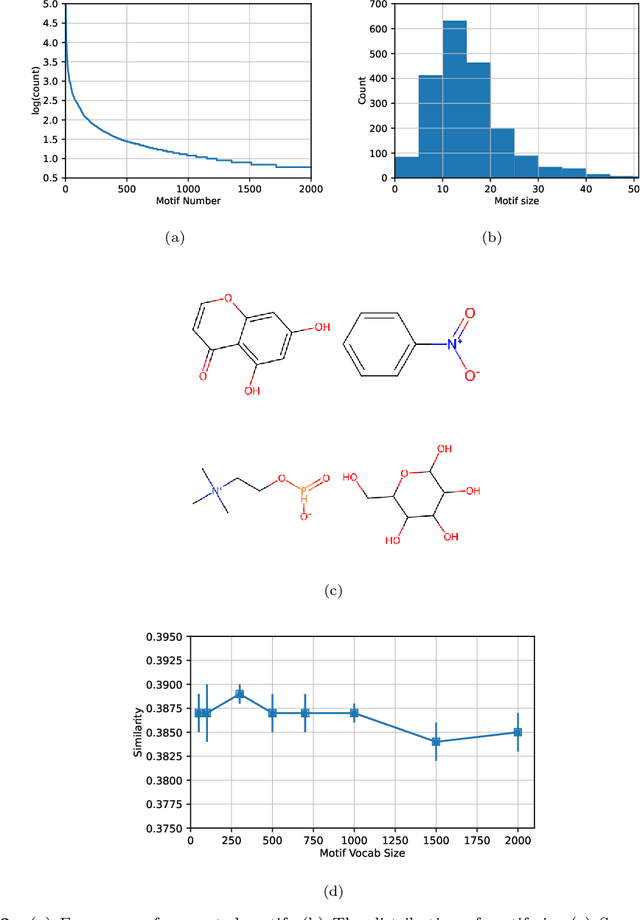
Mass spectra, which are agglomerations of ionized fragments from targeted molecules, play a crucial role across various fields for the identification of molecular structures. A prevalent analysis method involves spectral library searches,where unknown spectra are cross-referenced with a database. The effectiveness of such search-based approaches, however, is restricted by the scope of the existing mass spectra database, underscoring the need to expand the database via mass spectra prediction. In this research, we propose the Motif-based Mass Spectrum Prediction Network (MoMS-Net), a system that predicts mass spectra using the information derived from structural motifs and the implementation of Graph Neural Networks (GNNs). We have tested our model across diverse mass spectra and have observed its superiority over other existing models. MoMS-Net considers substructure at the graph level, which facilitates the incorporation of long-range dependencies while using less memory compared to the graph transformer model.
Point2Point : A Framework for Efficient Deep Learning on Hilbert sorted Point Clouds with applications in Spatio-Temporal Occupancy Prediction
Jun 28, 2023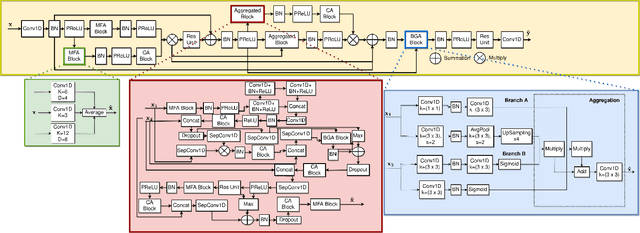

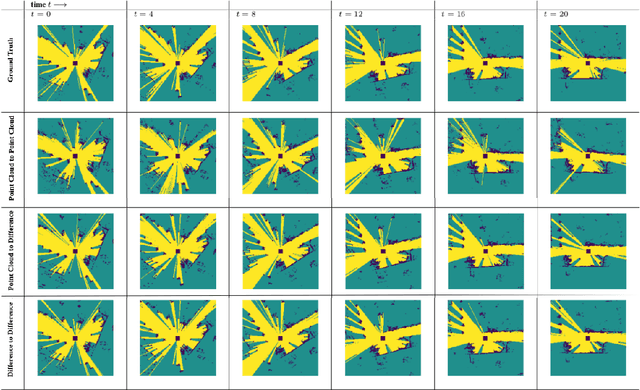
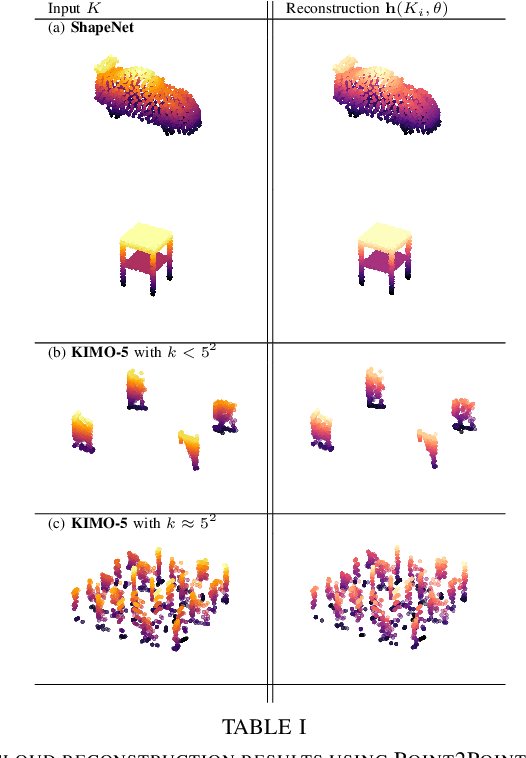
The irregularity and permutation invariance of point cloud data pose challenges for effective learning. Conventional methods for addressing this issue involve converting raw point clouds to intermediate representations such as 3D voxel grids or range images. While such intermediate representations solve the problem of permutation invariance, they can result in significant loss of information. Approaches that do learn on raw point clouds either have trouble in resolving neighborhood relationships between points or are too complicated in their formulation. In this paper, we propose a novel approach to representing point clouds as a locality preserving 1D ordering induced by the Hilbert space-filling curve. We also introduce Point2Point, a neural architecture that can effectively learn on Hilbert-sorted point clouds. We show that Point2Point shows competitive performance on point cloud segmentation and generation tasks. Finally, we show the performance of Point2Point on Spatio-temporal Occupancy prediction from Point clouds.
Chan-Vese Attention U-Net: An attention mechanism for robust segmentation
Jun 28, 2023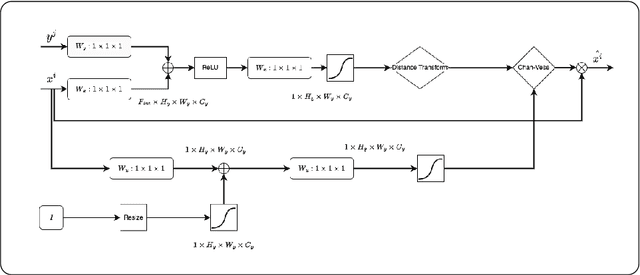
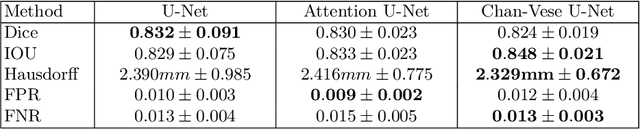
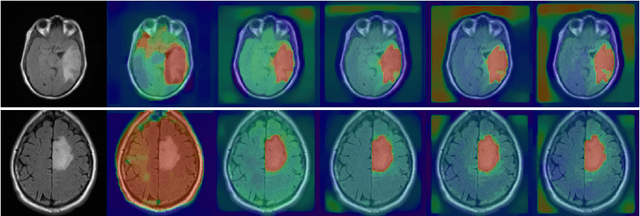
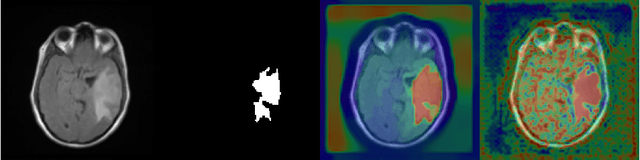
When studying the results of a segmentation algorithm using convolutional neural networks, one wonders about the reliability and consistency of the results. This leads to questioning the possibility of using such an algorithm in applications where there is little room for doubt. We propose in this paper a new attention gate based on the use of Chan-Vese energy minimization to control more precisely the segmentation masks given by a standard CNN architecture such as the U-Net model. This mechanism allows to obtain a constraint on the segmentation based on the resolution of a PDE. The study of the results allows us to observe the spatial information retained by the neural network on the region of interest and obtains competitive results on the binary segmentation. We illustrate the efficiency of this approach for medical image segmentation on a database of MRI brain images.
Variational Information Pursuit for Interpretable Predictions
Feb 16, 2023

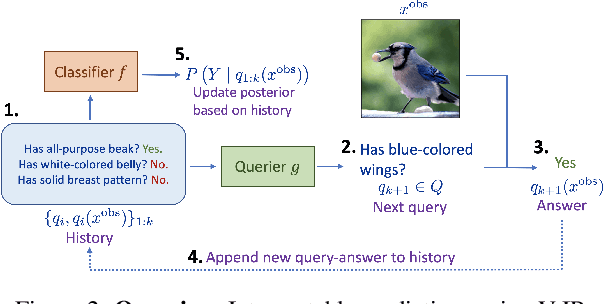
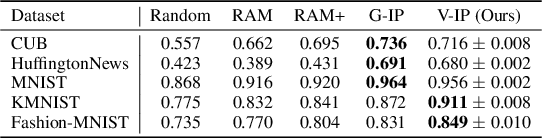
There is a growing interest in the machine learning community in developing predictive algorithms that are "interpretable by design". Towards this end, recent work proposes to make interpretable decisions by sequentially asking interpretable queries about data until a prediction can be made with high confidence based on the answers obtained (the history). To promote short query-answer chains, a greedy procedure called Information Pursuit (IP) is used, which adaptively chooses queries in order of information gain. Generative models are employed to learn the distribution of query-answers and labels, which is in turn used to estimate the most informative query. However, learning and inference with a full generative model of the data is often intractable for complex tasks. In this work, we propose Variational Information Pursuit (V-IP), a variational characterization of IP which bypasses the need for learning generative models. V-IP is based on finding a query selection strategy and a classifier that minimizes the expected cross-entropy between true and predicted labels. We then demonstrate that the IP strategy is the optimal solution to this problem. Therefore, instead of learning generative models, we can use our optimal strategy to directly pick the most informative query given any history. We then develop a practical algorithm by defining a finite-dimensional parameterization of our strategy and classifier using deep networks and train them end-to-end using our objective. Empirically, V-IP is 10-100x faster than IP on different Vision and NLP tasks with competitive performance. Moreover, V-IP finds much shorter query chains when compared to reinforcement learning which is typically used in sequential-decision-making problems. Finally, we demonstrate the utility of V-IP on challenging tasks like medical diagnosis where the performance is far superior to the generative modelling approach.