 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RXFOOD: Plug-in RGB-X Fusion for Object of Interest Detection
Jun 22, 2023
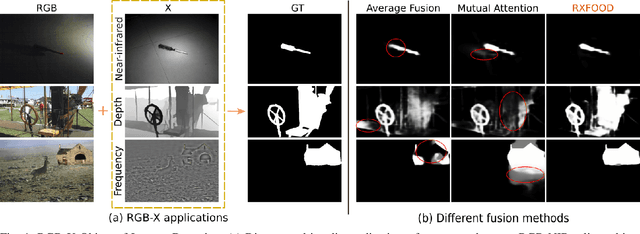
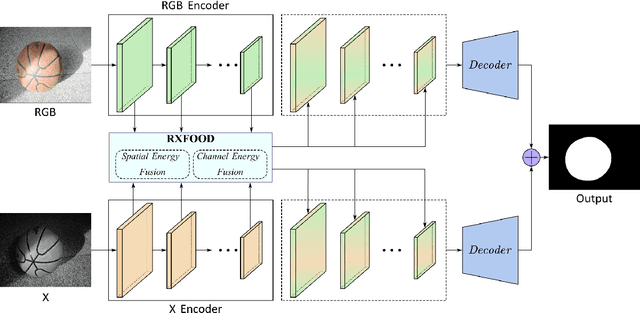
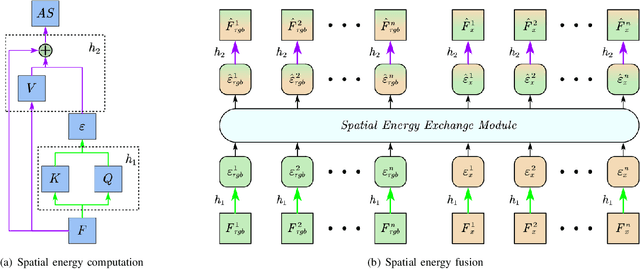
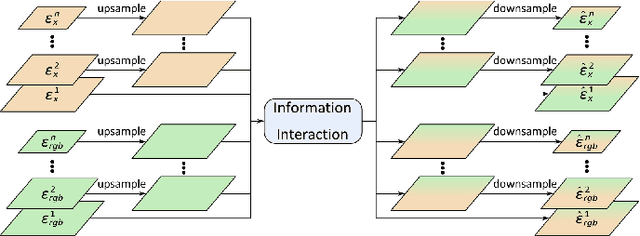
The emergence of different sensors (Near-Infrared, Depth, etc.) is a remedy for the limited application scenarios of traditional RGB camera. The RGB-X tasks, which rely on RGB input and another type of data input to resolve specific problems, have become a popular research topic in multimedia. A crucial part in two-branch RGB-X deep neural networks is how to fuse information across modalities. Given the tremendous information inside RGB-X networks, previous works typically apply naive fusion (e.g., average or max fusion) or only focus on the feature fusion at the same scale(s). While in this paper, we propose a novel method called RXFOOD for the fusion of features across different scales within the same modality branch and from different modality branches simultaneously in a unified attention mechanism. An Energy Exchange Module is designed for the interaction of each feature map's energy matrix, who reflects the inter-relationship of different positions and different channels inside a feature map. The RXFOOD method can be easily incorporated to any dual-branch encoder-decoder network as a plug-in module, and help the original backbone network better focus on important positions and channels for object of interest detection. Experimental results on RGB-NIR salient object detection, RGB-D salient object detection, and RGBFrequency image manipulation detection demonstrate the clear effectiveness of the proposed RXFOOD.
Text Alignment Is An Efficient Unified Model for Massive NLP Tasks
Jul 06, 2023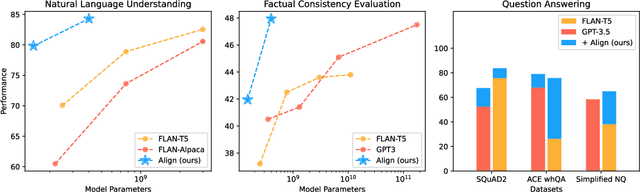
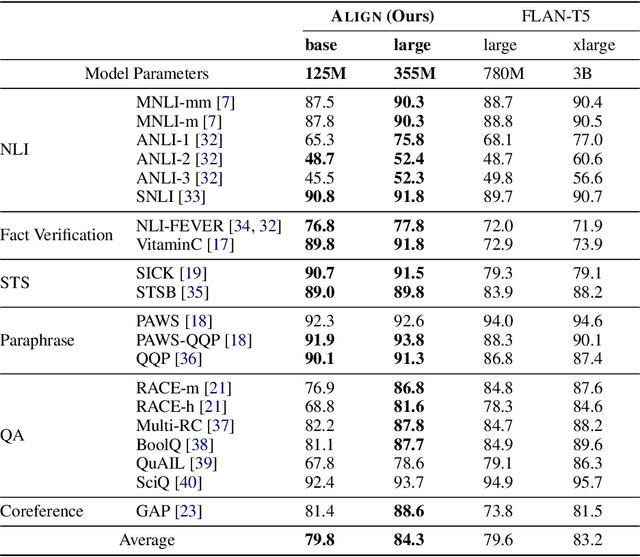
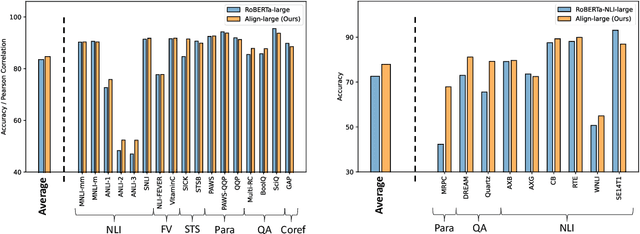
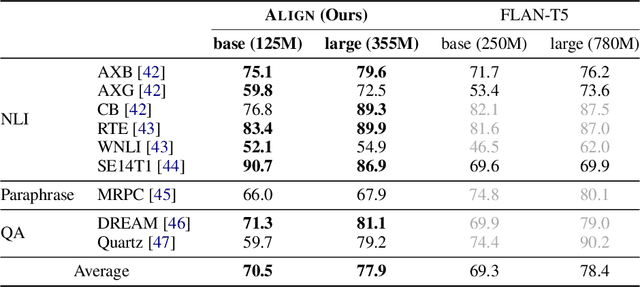
Large language models (LLMs), typically designed as a function of next-word prediction, have excelled across extensive NLP tasks. Despite the generality, next-word prediction is often not an efficient formulation for many of the tasks, demanding an extreme scale of model parameters (10s or 100s of billions) and sometimes yielding suboptimal performance. In practice, it is often desirable to build more efficient models -- despite being less versatile, they still apply to a substantial subset of problems, delivering on par or even superior performance with much smaller model sizes. In this paper, we propose text alignment as an efficient unified model for a wide range of crucial tasks involving text entailment, similarity, question answering (and answerability), factual consistency, and so forth. Given a pair of texts, the model measures the degree of alignment between their information. We instantiate an alignment model (Align) through lightweight finetuning of RoBERTa (355M parameters) using 5.9M examples from 28 datasets. Despite its compact size, extensive experiments show the model's efficiency and strong performance: (1) On over 20 datasets of aforementioned diverse tasks, the model matches or surpasses FLAN-T5 models that have around 2x or 10x more parameters; the single unified model also outperforms task-specific models finetuned on individual datasets; (2) When applied to evaluate factual consistency of language generation on 23 datasets, our model improves over various baselines, including the much larger GPT-3.5 (ChatGPT) and sometimes even GPT-4; (3) The lightweight model can also serve as an add-on component for LLMs such as GPT-3.5 in question answering tasks, improving the average exact match (EM) score by 17.94 and F1 score by 15.05 through identifying unanswerable questions.
Performance Analysis and Approximate Message Passing Detection of Orthogonal Time Sequency Multiplexing Modulation
Jul 06, 2023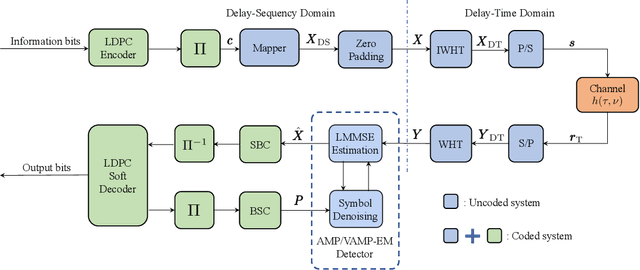
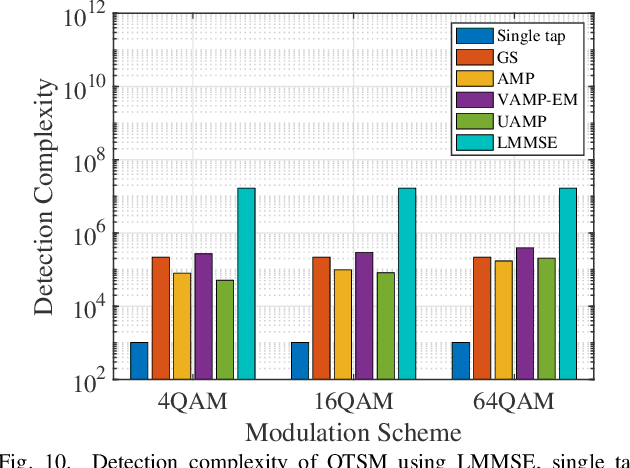
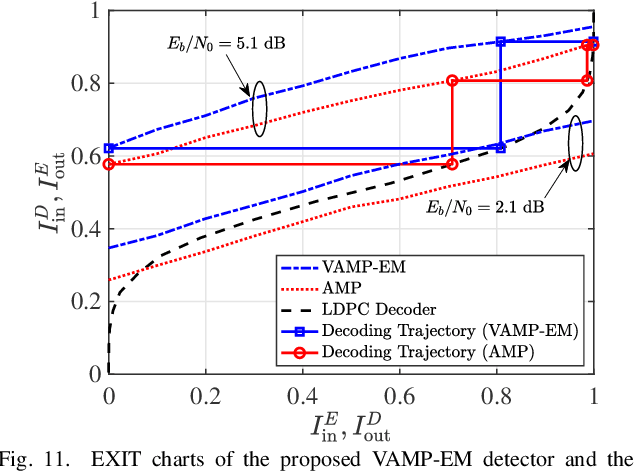
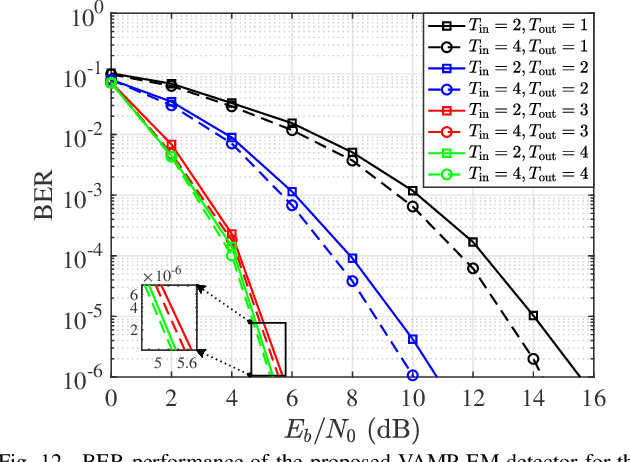
In orthogonal time sequency multiplexing (OTSM) modulation, the information symbols are conveyed in the delay-sequency domain upon exploiting the inverse Walsh Hadamard transform (IWHT). It has been shown that OTSM is capable of attaining a bit error ratio (BER) similar to that of orthogonal time-frequency space (OTFS) modulation at a lower complexity, since the saving of multiplication operations in the IWHT. Hence we provide its BER performance analysis and characterize its detection complexity. We commence by deriving its generalized input-output relationship and its unconditional pairwise error probability (UPEP). Then, its BER upper bound is derived in closed form under both ideal and imperfect channel estimation conditions, which is shown to be tight at moderate to high signal-to-noise ratios (SNRs). Moreover, a novel approximate message passing (AMP) aided OTSM detection framework is proposed. Specifically, to circumvent the high residual BER of the conventional AMP detector, we proposed a vector AMP-based expectation-maximization (VAMP-EM) detector for performing joint data detection and noise variance estimation. The variance auto-tuning algorithm based on the EM algorithm is designed for the VAMP-EM detector to further improve the convergence performance. The simulation results illustrate that the VAMP-EM detector is capable of striking an attractive BER vs. complexity trade-off than the state-of-the-art schemes as well as providing a better convergence. Finally, we propose AMP and VAMP-EM turbo receivers for low-density parity-check (LDPC)-coded OTSM systems. It is demonstrated that our proposed VAMP-EM turbo receiver is capable of providing both BER and convergence performance improvements over the conventional AMP solution.
Is Information Extraction Solved by ChatGPT? An Analysis of Performance, Evaluation Criteria, Robustness and Errors
May 23, 2023
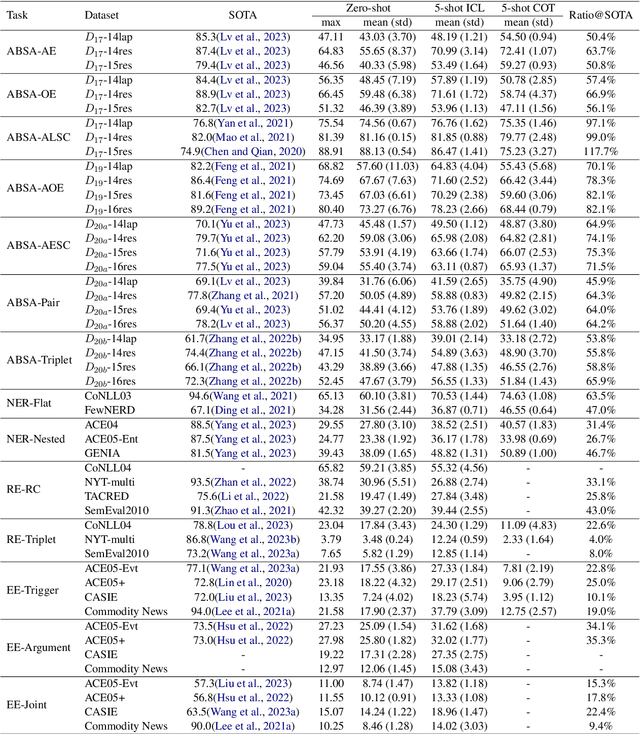
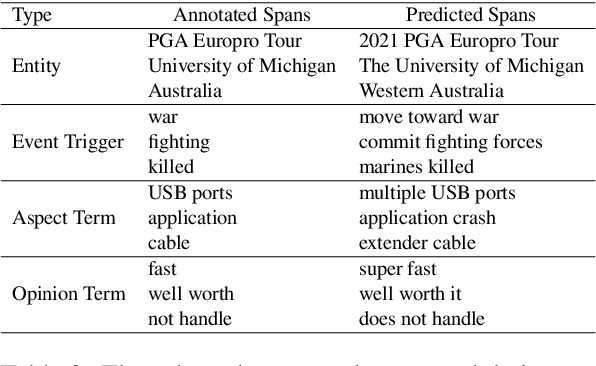
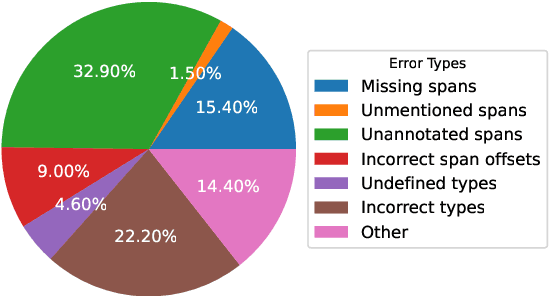
ChatGPT has stimulated the research boom in the field of large language models. In this paper, we assess the capabilities of ChatGPT from four perspectives including Performance, Evaluation Criteria, Robustness and Error Types. Specifically, we first evaluate ChatGPT's performance on 17 datasets with 14 IE sub-tasks under the zero-shot, few-shot and chain-of-thought scenarios, and find a huge performance gap between ChatGPT and SOTA results. Next, we rethink this gap and propose a soft-matching strategy for evaluation to more accurately reflect ChatGPT's performance. Then, we analyze the robustness of ChatGPT on 14 IE sub-tasks, and find that: 1) ChatGPT rarely outputs invalid responses; 2) Irrelevant context and long-tail target types greatly affect ChatGPT's performance; 3) ChatGPT cannot understand well the subject-object relationships in RE task. Finally, we analyze the errors of ChatGPT, and find that "unannotated spans" is the most dominant error type. This raises concerns about the quality of annotated data, and indicates the possibility of annotating data with ChatGPT. The data and code are released at Github site.
Reconfigurable Intelligent Surface Assisted Semantic Communication Systems
Jun 29, 2023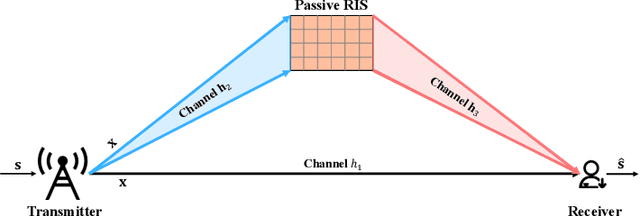
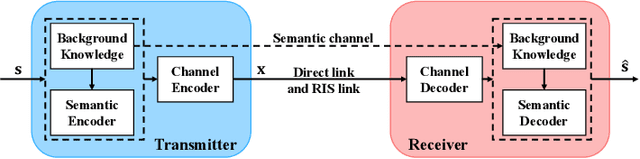
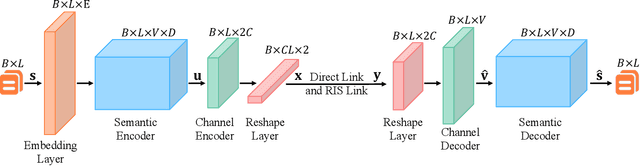
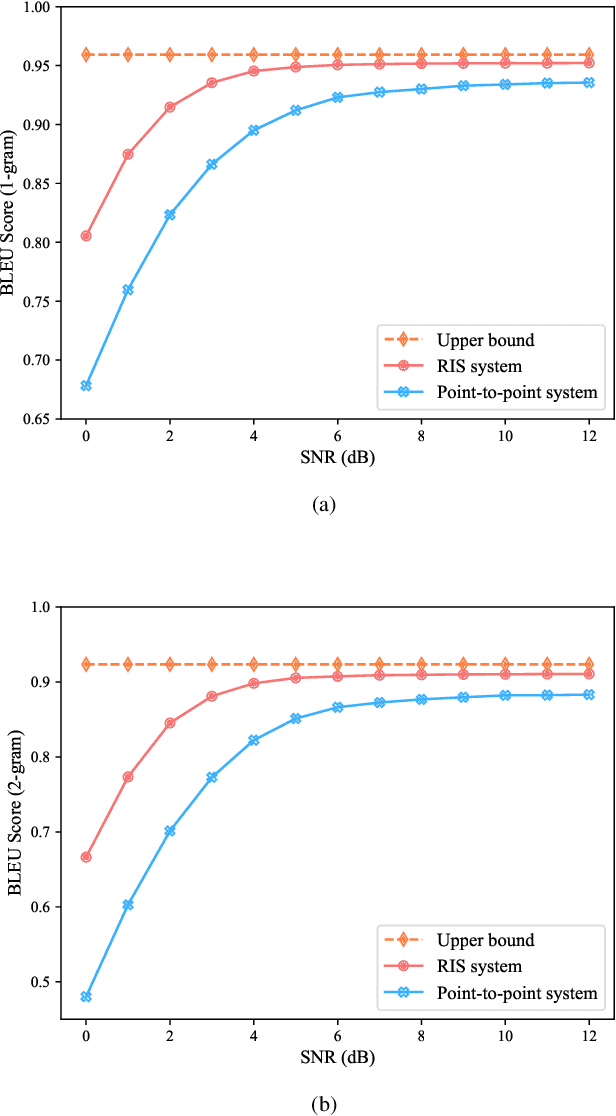
Semantic communication, which focuses on conveying the meaning of information rather than exact bit reconstruction, has gained considerable attention in recent years. Meanwhile, reconfigurable intelligent surface (RIS) is a promising technology that can achieve high spectral and energy efficiency by dynamically reflecting incident signals through programmable passive components. In this paper, we put forth a semantic communication scheme aided by RIS. Using text transmission as an example, experimental results demonstrate that the RIS-assisted semantic communication system outperforms the point-to-point semantic communication system in terms of bilingual evaluation understudy (BLEU) scores in Rayleigh fading channels, especially at low signal-to-noise ratio (SNR) regimes. In addition, the RIS-assisted semantic communication system exhibits superior robustness against channel estimation errors compared to its point-to-point counterpart. RIS can improve performance as it provides extra line-of-sight (LoS) paths and enhances signal propagation conditions compared to point-to-point systems.
DreamEditor: Text-Driven 3D Scene Editing with Neural Fields
Jun 29, 2023
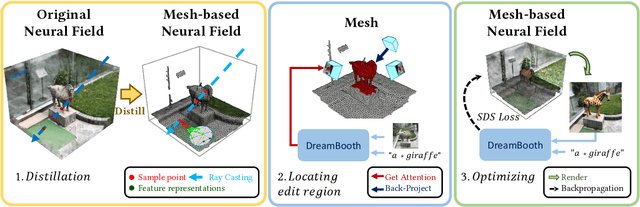

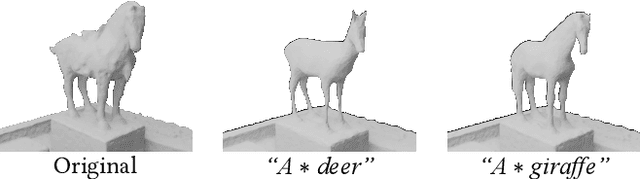
Neural fields have achieved impressive advancements in view synthesis and scene reconstruction. However, editing these neural fields remains challenging due to the implicit encoding of geometry and texture information. In this paper, we propose DreamEditor, a novel framework that enables users to perform controlled editing of neural fields using text prompts. By representing scenes as mesh-based neural fields, DreamEditor allows localized editing within specific regions. DreamEditor utilizes the text encoder of a pretrained text-to-Image diffusion model to automatically identify the regions to be edited based on the semantics of the text prompts. Subsequently, DreamEditor optimizes the editing region and aligns its geometry and texture with the text prompts through score distillation sampling [29]. Extensive experiments have demonstrated that DreamEditor can accurately edit neural fields of real-world scenes according to the given text prompts while ensuring consistency in irrelevant areas. DreamEditor generates highly realistic textures and geometry, significantly surpassing previous works in both quantitative and qualitative evaluations.
CMATH: Can Your Language Model Pass Chinese Elementary School Math Test?
Jun 29, 2023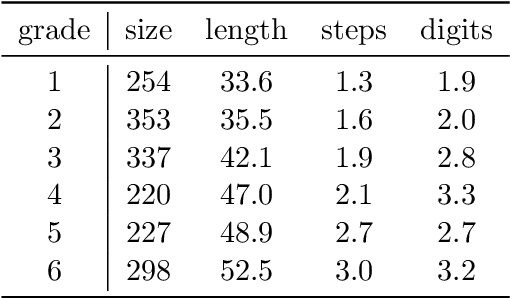
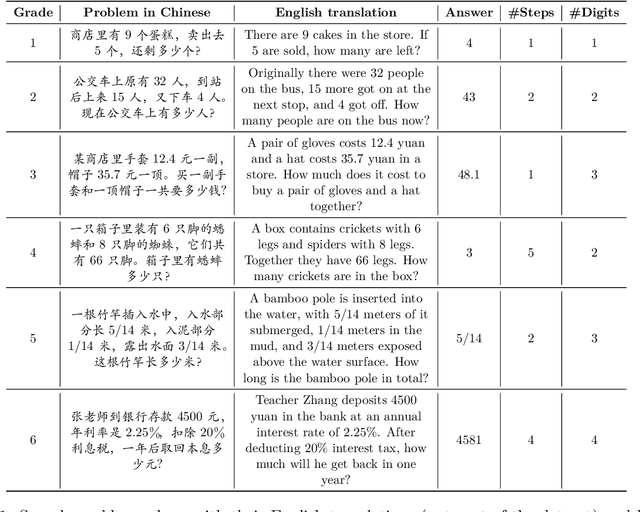
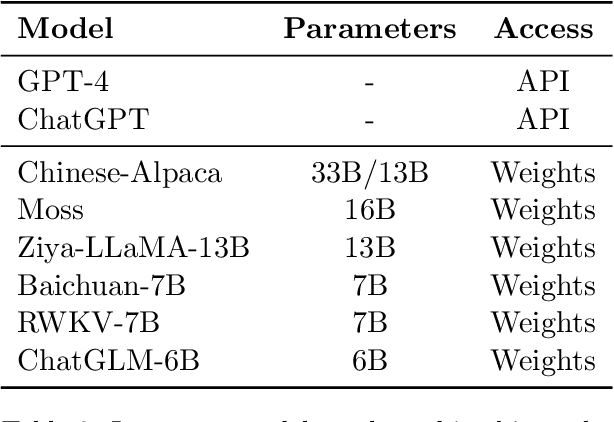
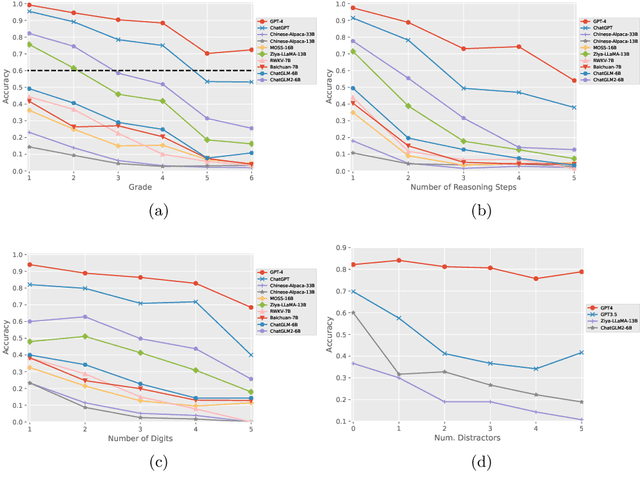
We present the Chinese Elementary School Math Word Problems (CMATH) dataset, comprising 1.7k elementary school-level math word problems with detailed annotations, source from actual Chinese workbooks and exams. This dataset aims to provide a benchmark tool for assessing the following question: to what grade level of elementary school math do the abilities of popular large language models (LLMs) correspond? We evaluate a variety of popular LLMs, including both commercial and open-source options, and discover that only GPT-4 achieves success (accuracy $\geq$ 60\%) across all six elementary school grades, while other models falter at different grade levels. Furthermore, we assess the robustness of several top-performing LLMs by augmenting the original problems in the CMATH dataset with distracting information. Our findings reveal that GPT-4 is able to maintains robustness, while other model fail. We anticipate that our study will expose limitations in LLMs' arithmetic and reasoning capabilities, and promote their ongoing development and advancement.
Tokenization and the Noiseless Channel
Jun 29, 2023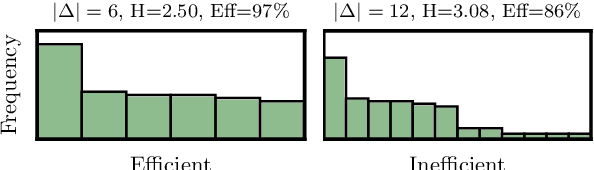
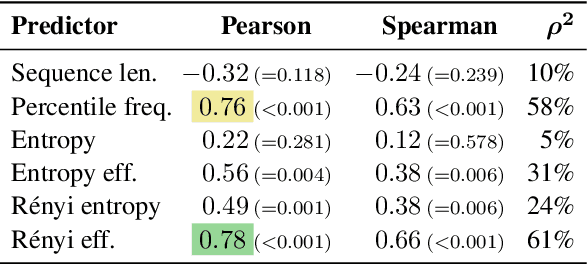
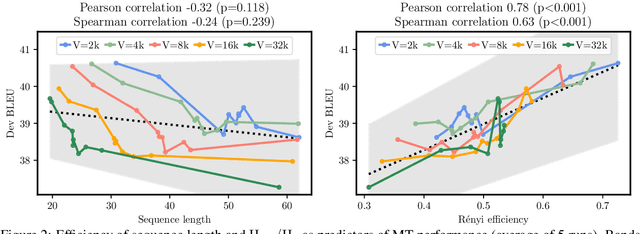
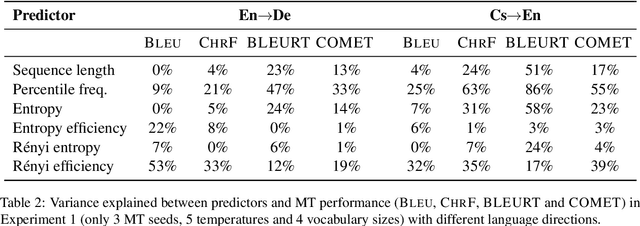
Subword tokenization is a key part of many NLP pipelines. However, little is known about why some tokenizer and hyperparameter combinations lead to better downstream model performance than others. We propose that good tokenizers lead to \emph{efficient} channel usage, where the channel is the means by which some input is conveyed to the model and efficiency can be quantified in information-theoretic terms as the ratio of the Shannon entropy to the maximum possible entropy of the token distribution. Yet, an optimal encoding according to Shannon entropy assigns extremely long codes to low-frequency tokens and very short codes to high-frequency tokens. Defining efficiency in terms of R\'enyi entropy, on the other hand, penalizes distributions with either very high or very low-frequency tokens. In machine translation, we find that across multiple tokenizers, the R\'enyi entropy with $\alpha = 2.5$ has a very strong correlation with \textsc{Bleu}: $0.78$ in comparison to just $-0.32$ for compressed length.
Unified Language Representation for Question Answering over Text, Tables, and Images
Jun 29, 2023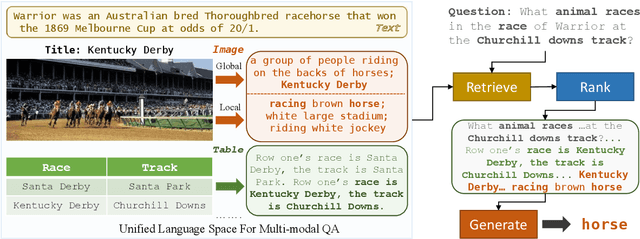
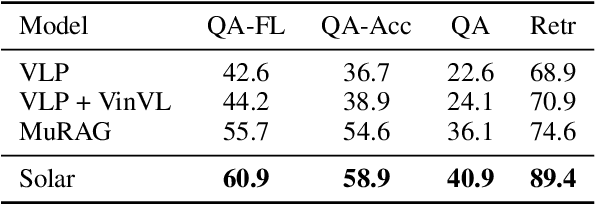
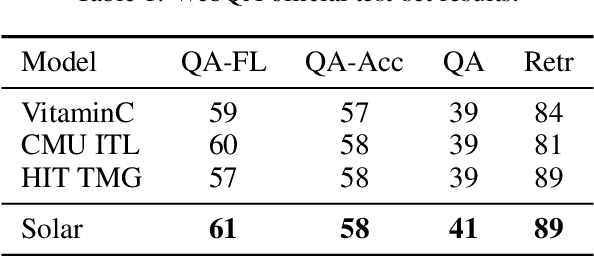
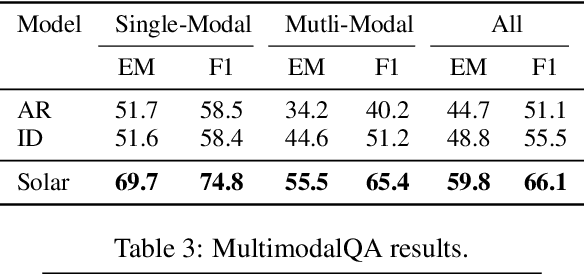
When trying to answer complex questions, people often rely on multiple sources of information, such as visual, textual, and tabular data. Previous approaches to this problem have focused on designing input features or model structure in the multi-modal space, which is inflexible for cross-modal reasoning or data-efficient training. In this paper, we call for an alternative paradigm, which transforms the images and tables into unified language representations, so that we can simplify the task into a simpler textual QA problem that can be solved using three steps: retrieval, ranking, and generation, all within a language space. This idea takes advantage of the power of pre-trained language models and is implemented in a framework called Solar. Our experimental results show that Solar outperforms all existing methods by 10.6-32.3 pts on two datasets, MultimodalQA and MMCoQA, across ten different metrics. Additionally, Solar achieves the best performance on the WebQA leaderboard
Task-Specific Alignment and Multiple Level Transformer for Few-Shot Action Recognition
Jul 05, 2023
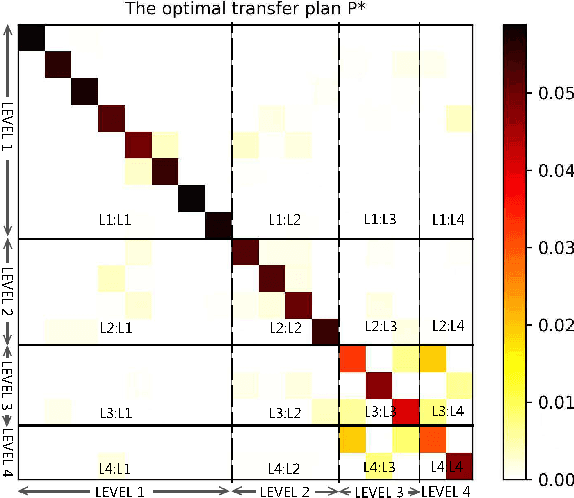
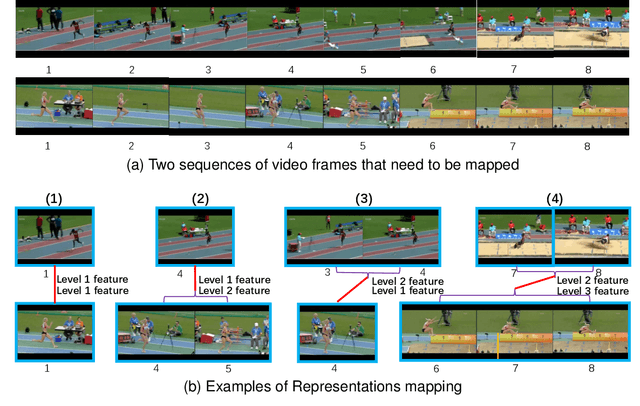
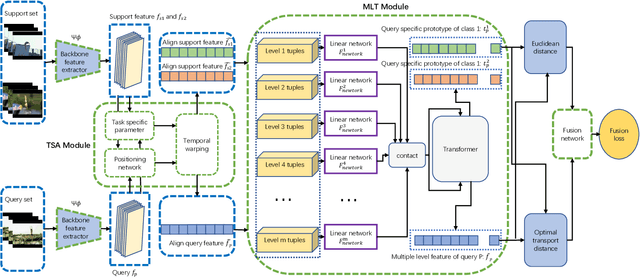
In the research field of few-shot learning, the main difference between image-based and video-based is the additional temporal dimension for videos. In recent years, many approaches for few-shot action recognition have followed the metric-based methods, especially, since some works use the Transformer to get the cross-attention feature of the videos or the enhanced prototype, and the results are competitive. However, they do not mine enough information from the Transformer because they only focus on the feature of a single level. In our paper, we have addressed this problem. We propose an end-to-end method named "Task-Specific Alignment and Multiple Level Transformer Network (TSA-MLT)". In our model, the Multiple Level Transformer focuses on the multiple-level feature of the support video and query video. Especially before Multiple Level Transformer, we use task-specific TSA to filter unimportant or misleading frames as a pre-processing. Furthermore, we adopt a fusion loss using two kinds of distance, the first is L2 sequence distance, which focuses on temporal order alignment. The second one is Optimal transport distance, which focuses on measuring the gap between the appearance and semantics of the videos. Using a simple fusion network, we fuse the two distances element-wise, then use the cross-entropy loss as our fusion loss. Extensive experiments show our method achieves state-of-the-art results on the HMDB51 and UCF101 datasets and a competitive result on the benchmark of Kinetics and something-2-something V2 datasets. Our code will be available at the URL: https://github.com/cofly2014/tsa-mlt.git