 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sentence-to-Label Generation Framework for Multi-task Learning of Japanese Sentence Classification and Named Entity Recognition
Jun 28, 2023
Information extraction(IE) is a crucial subfield within natural language processing. In this study, we introduce a Sentence Classification and Named Entity Recognition Multi-task (SCNM) approach that combines Sentence Classification (SC) and Named Entity Recognition (NER). We develop a Sentence-to-Label Generation (SLG) framework for SCNM and construct a Wikipedia dataset containing both SC and NER. Using a format converter, we unify input formats and employ a generative model to generate SC-labels, NER-labels, and associated text segments. We propose a Constraint Mechanism (CM) to improve generated format accuracy. Our results show SC accuracy increased by 1.13 points and NER by 1.06 points in SCNM compared to standalone tasks, with CM raising format accuracy from 63.61 to 100. The findings indicate mutual reinforcement effects between SC and NER, and integration enhances both tasks' performance.
A semantically enhanced dual encoder for aspect sentiment triplet extraction
Jun 14, 2023Aspect sentiment triplet extraction (ASTE) is a crucial subtask of aspect-based sentiment analysis (ABSA) that aims to comprehensively identify sentiment triplets. Previous research has focused on enhancing ASTE through innovative table-filling strategies. However, these approaches often overlook the multi-perspective nature of language expressions, resulting in a loss of valuable interaction information between aspects and opinions. To address this limitation, we propose a framework that leverages both a basic encoder, primarily based on BERT, and a particular encoder comprising a Bi-LSTM network and graph convolutional network (GCN ). The basic encoder captures the surface-level semantics of linguistic expressions, while the particular encoder extracts deeper semantics, including syntactic and lexical information. By modeling the dependency tree of comments and considering the part-of-speech and positional information of words, we aim to capture semantics that are more relevant to the underlying intentions of the sentences. An interaction strategy combines the semantics learned by the two encoders, enabling the fusion of multiple perspectives and facilitating a more comprehensive understanding of aspect--opinion relationships. Experiments conducted on benchmark datasets demonstrate the state-of-the-art performance of our proposed framework.
Performance Analysis and Approximate Message Passing Detection of Orthogonal Time Sequency Multiplexing Modulation
Jul 06, 2023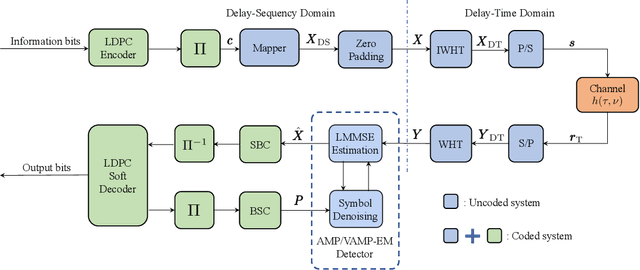
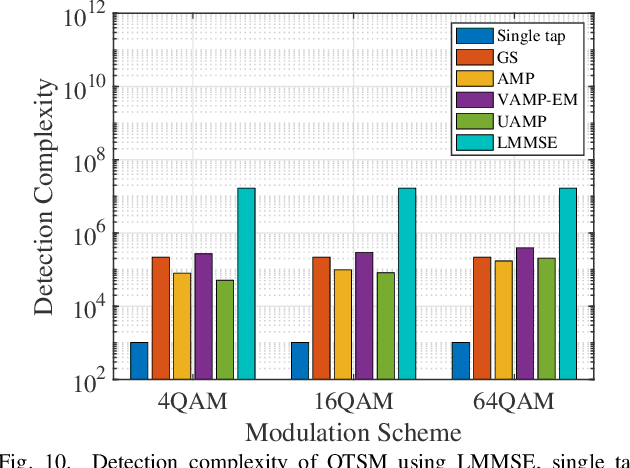
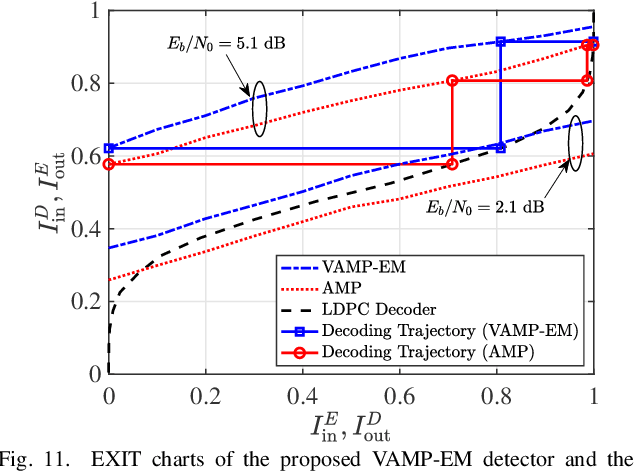
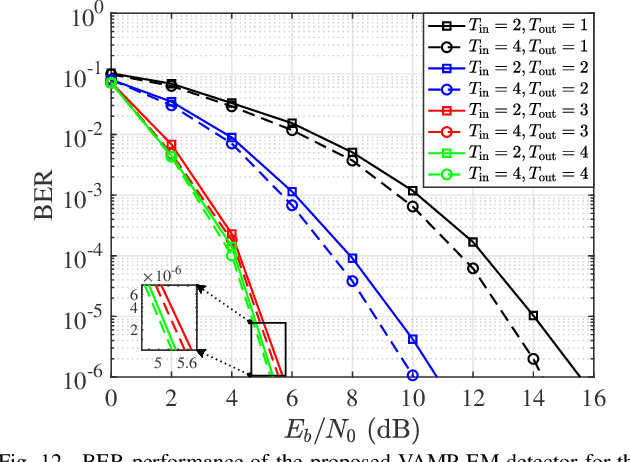
In orthogonal time sequency multiplexing (OTSM) modulation, the information symbols are conveyed in the delay-sequency domain upon exploiting the inverse Walsh Hadamard transform (IWHT). It has been shown that OTSM is capable of attaining a bit error ratio (BER) similar to that of orthogonal time-frequency space (OTFS) modulation at a lower complexity, since the saving of multiplication operations in the IWHT. Hence we provide its BER performance analysis and characterize its detection complexity. We commence by deriving its generalized input-output relationship and its unconditional pairwise error probability (UPEP). Then, its BER upper bound is derived in closed form under both ideal and imperfect channel estimation conditions, which is shown to be tight at moderate to high signal-to-noise ratios (SNRs). Moreover, a novel approximate message passing (AMP) aided OTSM detection framework is proposed. Specifically, to circumvent the high residual BER of the conventional AMP detector, we proposed a vector AMP-based expectation-maximization (VAMP-EM) detector for performing joint data detection and noise variance estimation. The variance auto-tuning algorithm based on the EM algorithm is designed for the VAMP-EM detector to further improve the convergence performance. The simulation results illustrate that the VAMP-EM detector is capable of striking an attractive BER vs. complexity trade-off than the state-of-the-art schemes as well as providing a better convergence. Finally, we propose AMP and VAMP-EM turbo receivers for low-density parity-check (LDPC)-coded OTSM systems. It is demonstrated that our proposed VAMP-EM turbo receiver is capable of providing both BER and convergence performance improvements over the conventional AMP solution.
Text Alignment Is An Efficient Unified Model for Massive NLP Tasks
Jul 06, 2023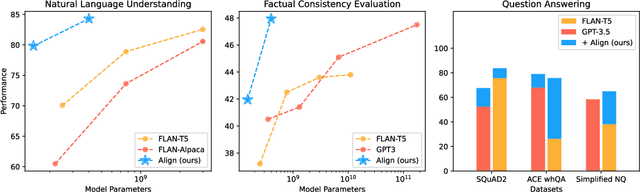
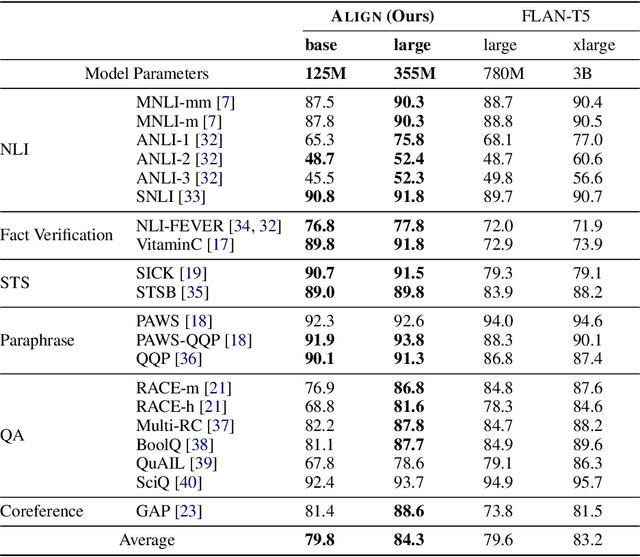
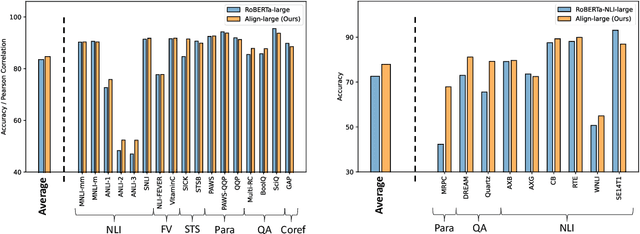
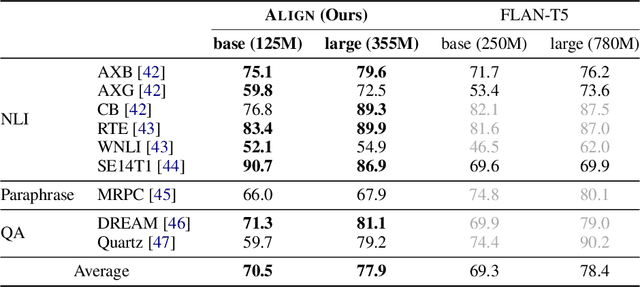
Large language models (LLMs), typically designed as a function of next-word prediction, have excelled across extensive NLP tasks. Despite the generality, next-word prediction is often not an efficient formulation for many of the tasks, demanding an extreme scale of model parameters (10s or 100s of billions) and sometimes yielding suboptimal performance. In practice, it is often desirable to build more efficient models -- despite being less versatile, they still apply to a substantial subset of problems, delivering on par or even superior performance with much smaller model sizes. In this paper, we propose text alignment as an efficient unified model for a wide range of crucial tasks involving text entailment, similarity, question answering (and answerability), factual consistency, and so forth. Given a pair of texts, the model measures the degree of alignment between their information. We instantiate an alignment model (Align) through lightweight finetuning of RoBERTa (355M parameters) using 5.9M examples from 28 datasets. Despite its compact size, extensive experiments show the model's efficiency and strong performance: (1) On over 20 datasets of aforementioned diverse tasks, the model matches or surpasses FLAN-T5 models that have around 2x or 10x more parameters; the single unified model also outperforms task-specific models finetuned on individual datasets; (2) When applied to evaluate factual consistency of language generation on 23 datasets, our model improves over various baselines, including the much larger GPT-3.5 (ChatGPT) and sometimes even GPT-4; (3) The lightweight model can also serve as an add-on component for LLMs such as GPT-3.5 in question answering tasks, improving the average exact match (EM) score by 17.94 and F1 score by 15.05 through identifying unanswerable questions.
Prior Information based Decomposition and Reconstruction Learning for Micro-Expression Recognition
Mar 03, 2023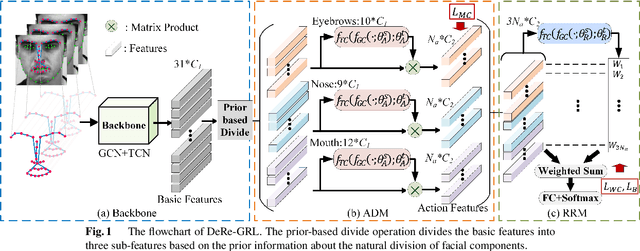
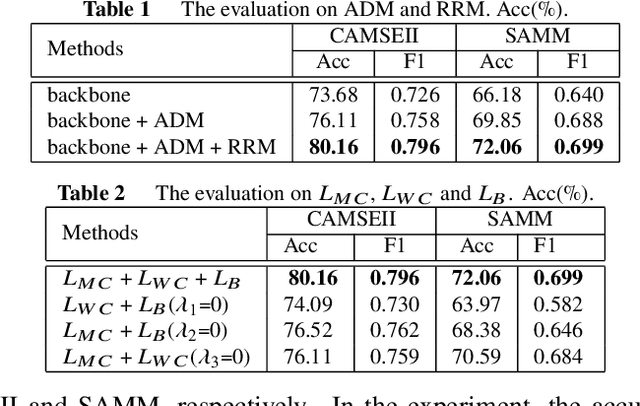
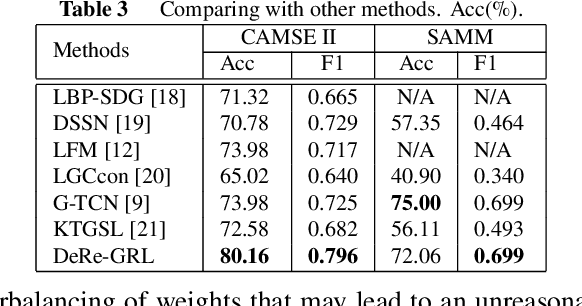
Micro-expression recognition (MER) draws intensive research interest as micro-expressions (MEs) can infer genuine emotions. Prior information can guide the model to learn discriminative ME features effectively. However, most works focus on researching the general models with a stronger representation ability to adaptively aggregate ME movement information in a holistic way, which may ignore the prior information and properties of MEs. To solve this issue, driven by the prior information that the category of ME can be inferred by the relationship between the actions of facial different components, this work designs a novel model that can conform to this prior information and learn ME movement features in an interpretable way. Specifically, this paper proposes a Decomposition and Reconstruction-based Graph Representation Learning (DeRe-GRL) model to effectively learn high-level ME features. DeRe-GRL includes two modules: Action Decomposition Module (ADM) and Relation Reconstruction Module (RRM), where ADM learns action features of facial key components and RRM explores the relationship between these action features. Based on facial key components, ADM divides the geometric movement features extracted by the graph model-based backbone into several sub-features, and learns the map matrix to map these sub-features into multiple action features; then, RRM learns weights to weight all action features to build the relationship between action features. The experimental results demonstrate the effectiveness of the proposed modules, and the proposed method achieves competitive performance.
Smart Sentiment Analysis-based Search Engine Classification Intelligence
Jun 16, 2023

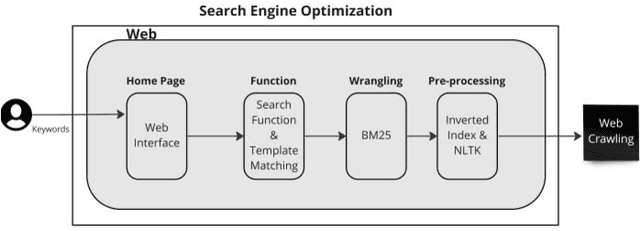
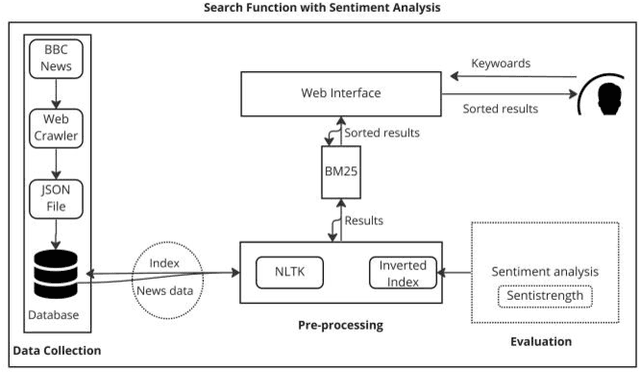
Search engines are widely used for finding information on the internet. However, there are limitations in the current search approach, such as providing popular but not necessarily relevant results. This research addresses the issue of polysemy in search results by implementing a search function that determines the sentimentality of the retrieved information. The study utilizes a web crawler to collect data from the British Broadcasting Corporation (BBC) news site, and the sentimentality of the news articles is determined using the Sentistrength program. The results demonstrate that the proposed search function improves recall value while accurately retrieving nonpolysemous news. Furthermore, Sentistrength outperforms deep learning and clustering methods in classifying search results. The methodology presented in this article can be applied to analyze the sentimentality and reputation of entities on the internet.
Learning to Rank when Grades Matter
Jun 20, 2023
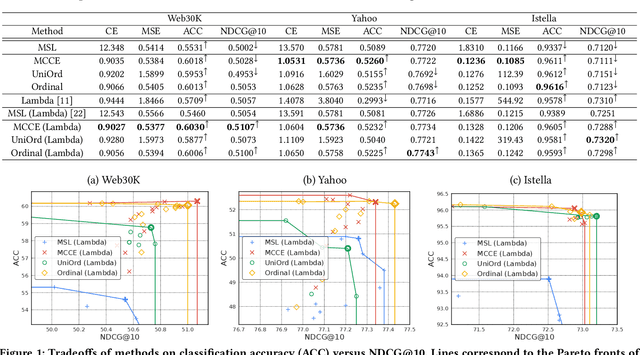
Graded labels are ubiquitous in real-world learning-to-rank applications, especially in human rated relevance data. Traditional learning-to-rank techniques aim to optimize the ranked order of documents. They typically, however, ignore predicting actual grades. This prevents them from being adopted in applications where grades matter, such as filtering out ``poor'' documents. Achieving both good ranking performance and good grade prediction performance is still an under-explored problem. Existing research either focuses only on ranking performance by not calibrating model outputs, or treats grades as numerical values, assuming labels are on a linear scale and failing to leverage the ordinal grade information. In this paper, we conduct a rigorous study of learning to rank with grades, where both ranking performance and grade prediction performance are important. We provide a formal discussion on how to perform ranking with non-scalar predictions for grades, and propose a multiobjective formulation to jointly optimize both ranking and grade predictions. In experiments, we verify on several public datasets that our methods are able to push the Pareto frontier of the tradeoff between ranking and grade prediction performance, showing the benefit of leveraging ordinal grade information.
RXFOOD: Plug-in RGB-X Fusion for Object of Interest Detection
Jun 22, 2023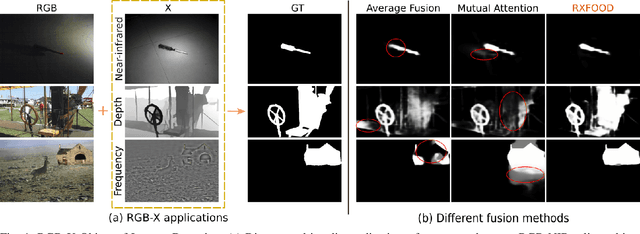
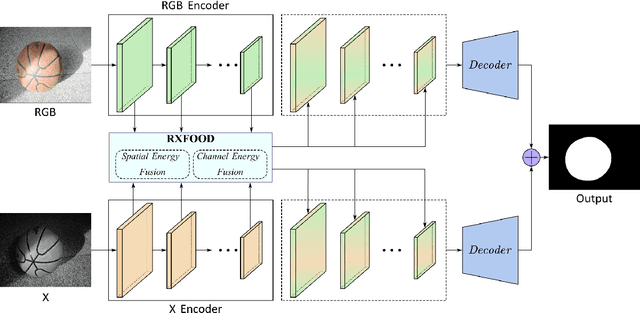
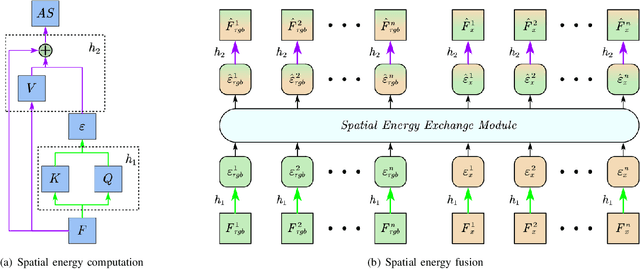
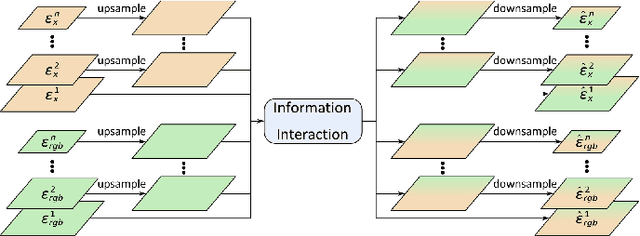
The emergence of different sensors (Near-Infrared, Depth, etc.) is a remedy for the limited application scenarios of traditional RGB camera. The RGB-X tasks, which rely on RGB input and another type of data input to resolve specific problems, have become a popular research topic in multimedia. A crucial part in two-branch RGB-X deep neural networks is how to fuse information across modalities. Given the tremendous information inside RGB-X networks, previous works typically apply naive fusion (e.g., average or max fusion) or only focus on the feature fusion at the same scale(s). While in this paper, we propose a novel method called RXFOOD for the fusion of features across different scales within the same modality branch and from different modality branches simultaneously in a unified attention mechanism. An Energy Exchange Module is designed for the interaction of each feature map's energy matrix, who reflects the inter-relationship of different positions and different channels inside a feature map. The RXFOOD method can be easily incorporated to any dual-branch encoder-decoder network as a plug-in module, and help the original backbone network better focus on important positions and channels for object of interest detection. Experimental results on RGB-NIR salient object detection, RGB-D salient object detection, and RGBFrequency image manipulation detection demonstrate the clear effectiveness of the proposed RXFOOD.
Task-Specific Alignment and Multiple Level Transformer for Few-Shot Action Recognition
Jul 05, 2023
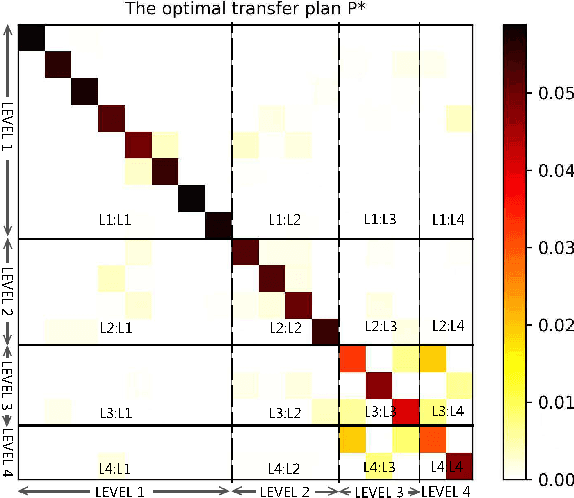
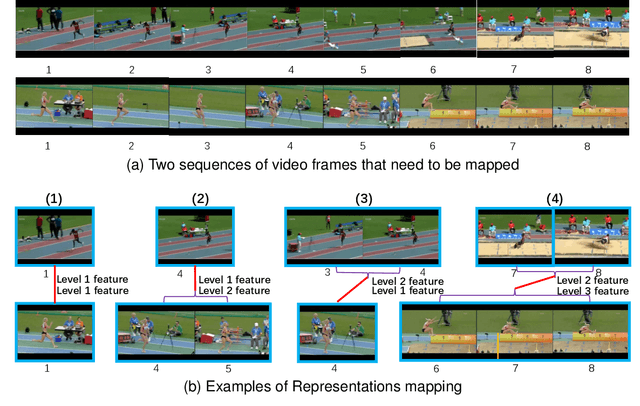
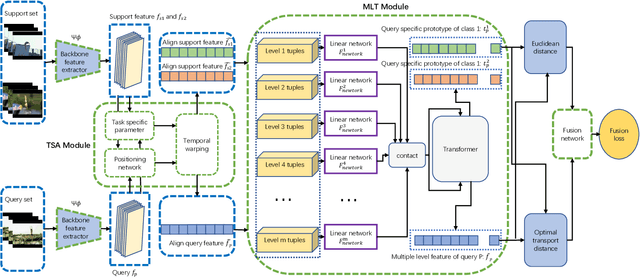
In the research field of few-shot learning, the main difference between image-based and video-based is the additional temporal dimension for videos. In recent years, many approaches for few-shot action recognition have followed the metric-based methods, especially, since some works use the Transformer to get the cross-attention feature of the videos or the enhanced prototype, and the results are competitive. However, they do not mine enough information from the Transformer because they only focus on the feature of a single level. In our paper, we have addressed this problem. We propose an end-to-end method named "Task-Specific Alignment and Multiple Level Transformer Network (TSA-MLT)". In our model, the Multiple Level Transformer focuses on the multiple-level feature of the support video and query video. Especially before Multiple Level Transformer, we use task-specific TSA to filter unimportant or misleading frames as a pre-processing. Furthermore, we adopt a fusion loss using two kinds of distance, the first is L2 sequence distance, which focuses on temporal order alignment. The second one is Optimal transport distance, which focuses on measuring the gap between the appearance and semantics of the videos. Using a simple fusion network, we fuse the two distances element-wise, then use the cross-entropy loss as our fusion loss. Extensive experiments show our method achieves state-of-the-art results on the HMDB51 and UCF101 datasets and a competitive result on the benchmark of Kinetics and something-2-something V2 datasets. Our code will be available at the URL: https://github.com/cofly2014/tsa-mlt.git
Spiking Neural Network for Ultra-low-latency and High-accurate Object Detection
Jun 21, 2023
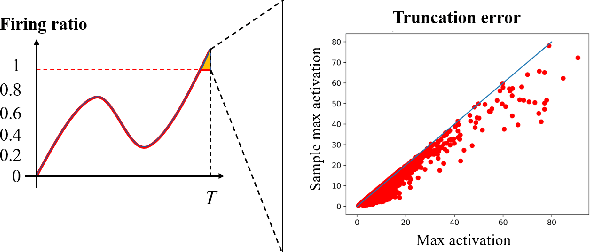
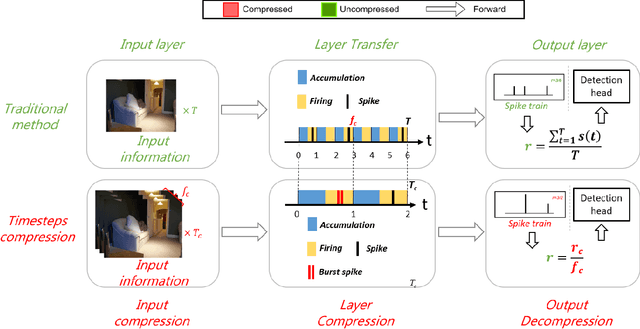
Spiking Neural Networks (SNNs) have garnered widespread interest for their energy efficiency and brain-inspired event-driven properties. While recent methods like Spiking-YOLO have expanded the SNNs to more challenging object detection tasks, they often suffer from high latency and low detection accuracy, making them difficult to deploy on latency sensitive mobile platforms. Furthermore, the conversion method from Artificial Neural Networks (ANNs) to SNNs is hard to maintain the complete structure of the ANNs, resulting in poor feature representation and high conversion errors. To address these challenges, we propose two methods: timesteps compression and spike-time-dependent integrated (STDI) coding. The former reduces the timesteps required in ANN-SNN conversion by compressing information, while the latter sets a time-varying threshold to expand the information holding capacity. We also present a SNN-based ultra-low latency and high accurate object detection model (SUHD) that achieves state-of-the-art performance on nontrivial datasets like PASCAL VOC and MS COCO, with about remarkable 750x fewer timesteps and 30% mean average precision (mAP) improvement, compared to the Spiking-YOLO on MS COCO datasets. To the best of our knowledge, SUHD is the deepest spike-based object detection model to date that achieves ultra low timesteps to complete the lossless conversion.