 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
From Two Stream to One Stream: Efficient RGB-T Tracking via Mutual Prompt Learning and Knowledge Distillation
Mar 25, 2024
Due to the complementary nature of visible light and thermal in-frared modalities, object tracking based on the fusion of visible light images and thermal images (referred to as RGB-T tracking) has received increasing attention from researchers in recent years. How to achieve more comprehensive fusion of information from the two modalities at a lower cost has been an issue that re-searchers have been exploring. Inspired by visual prompt learn-ing, we designed a novel two-stream RGB-T tracking architecture based on cross-modal mutual prompt learning, and used this model as a teacher to guide a one-stream student model for rapid learning through knowledge distillation techniques. Extensive experiments have shown that, compared to similar RGB-T track-ers, our designed teacher model achieved the highest precision rate, while the student model, with comparable precision rate to the teacher model, realized an inference speed more than three times faster than the teacher model.(Codes will be available if accepted.)
Visual Action Planning with Multiple Heterogeneous Agents
Mar 25, 2024Visual planning methods are promising to handle complex settings where extracting the system state is challenging. However, none of the existing works tackles the case of multiple heterogeneous agents which are characterized by different capabilities and/or embodiment. In this work, we propose a method to realize visual action planning in multi-agent settings by exploiting a roadmap built in a low-dimensional structured latent space and used for planning. To enable multi-agent settings, we infer possible parallel actions from a dataset composed of tuples associated with individual actions. Next, we evaluate feasibility and cost of them based on the capabilities of the multi-agent system and endow the roadmap with this information, building a capability latent space roadmap (C-LSR). Additionally, a capability suggestion strategy is designed to inform the human operator about possible missing capabilities when no paths are found. The approach is validated in a simulated burger cooking task and a real-world box packing task.
Revealing Vulnerabilities of Neural Networks in Parameter Learning and Defense Against Explanation-Aware Backdoors
Mar 25, 2024Explainable Artificial Intelligence (XAI) strategies play a crucial part in increasing the understanding and trustworthiness of neural networks. Nonetheless, these techniques could potentially generate misleading explanations. Blinding attacks can drastically alter a machine learning algorithm's prediction and explanation, providing misleading information by adding visually unnoticeable artifacts into the input, while maintaining the model's accuracy. It poses a serious challenge in ensuring the reliability of XAI methods. To ensure the reliability of XAI methods poses a real challenge, we leverage statistical analysis to highlight the changes in CNN weights within a CNN following blinding attacks. We introduce a method specifically designed to limit the effectiveness of such attacks during the evaluation phase, avoiding the need for extra training. The method we suggest defences against most modern explanation-aware adversarial attacks, achieving an approximate decrease of ~99\% in the Attack Success Rate (ASR) and a ~91\% reduction in the Mean Square Error (MSE) between the original explanation and the defended (post-attack) explanation across three unique types of attacks.
Enhancing Audio Generation Diversity with Visual Information
Mar 02, 2024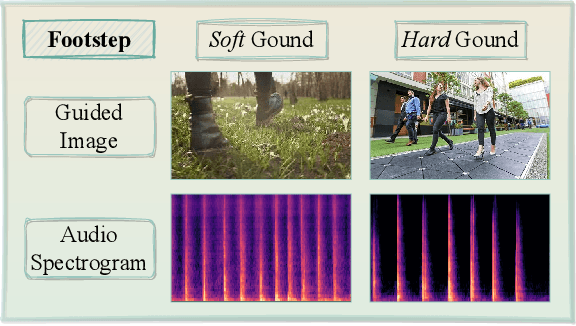
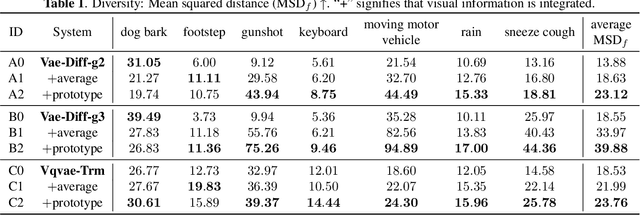
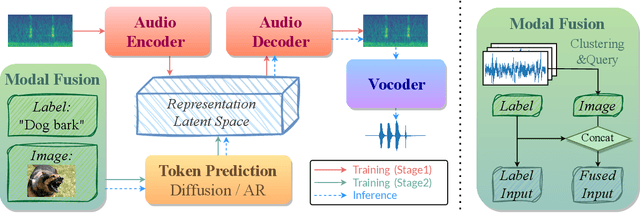
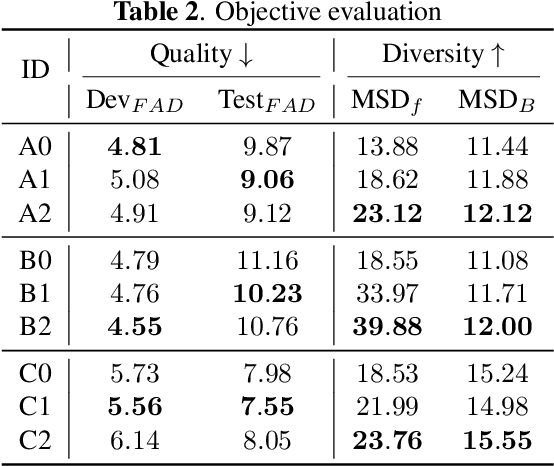
Audio and sound generation has garnered significant attention in recent years, with a primary focus on improving the quality of generated audios. However, there has been limited research on enhancing the diversity of generated audio, particularly when it comes to audio generation within specific categories. Current models tend to produce homogeneous audio samples within a category. This work aims to address this limitation by improving the diversity of generated audio with visual information. We propose a clustering-based method, leveraging visual information to guide the model in generating distinct audio content within each category. Results on seven categories indicate that extra visual input can largely enhance audio generation diversity. Audio samples are available at https://zeyuxie29.github.io/DiverseAudioGeneration.
KC-GenRe: A Knowledge-constrained Generative Re-ranking Method Based on Large Language Models for Knowledge Graph Completion
Mar 26, 2024The goal of knowledge graph completion (KGC) is to predict missing facts among entities. Previous methods for KGC re-ranking are mostly built on non-generative language models to obtain the probability of each candidate. Recently, generative large language models (LLMs) have shown outstanding performance on several tasks such as information extraction and dialog systems. Leveraging them for KGC re-ranking is beneficial for leveraging the extensive pre-trained knowledge and powerful generative capabilities. However, it may encounter new problems when accomplishing the task, namely mismatch, misordering and omission. To this end, we introduce KC-GenRe, a knowledge-constrained generative re-ranking method based on LLMs for KGC. To overcome the mismatch issue, we formulate the KGC re-ranking task as a candidate identifier sorting generation problem implemented by generative LLMs. To tackle the misordering issue, we develop a knowledge-guided interactive training method that enhances the identification and ranking of candidates. To address the omission issue, we design a knowledge-augmented constrained inference method that enables contextual prompting and controlled generation, so as to obtain valid rankings. Experimental results show that KG-GenRe achieves state-of-the-art performance on four datasets, with gains of up to 6.7% and 7.7% in the MRR and Hits@1 metric compared to previous methods, and 9.0% and 11.1% compared to that without re-ranking. Extensive analysis demonstrates the effectiveness of components in KG-GenRe.
Hawk: Accurate and Fast Privacy-Preserving Machine Learning Using Secure Lookup Table Computation
Mar 26, 2024Training machine learning models on data from multiple entities without direct data sharing can unlock applications otherwise hindered by business, legal, or ethical constraints. In this work, we design and implement new privacy-preserving machine learning protocols for logistic regression and neural network models. We adopt a two-server model where data owners secret-share their data between two servers that train and evaluate the model on the joint data. A significant source of inefficiency and inaccuracy in existing methods arises from using Yao's garbled circuits to compute non-linear activation functions. We propose new methods for computing non-linear functions based on secret-shared lookup tables, offering both computational efficiency and improved accuracy. Beyond introducing leakage-free techniques, we initiate the exploration of relaxed security measures for privacy-preserving machine learning. Instead of claiming that the servers gain no knowledge during the computation, we contend that while some information is revealed about access patterns to lookup tables, it maintains epsilon-dX-privacy. Leveraging this relaxation significantly reduces the computational resources needed for training. We present new cryptographic protocols tailored to this relaxed security paradigm and define and analyze the leakage. Our evaluations show that our logistic regression protocol is up to 9x faster, and the neural network training is up to 688x faster than SecureML. Notably, our neural network achieves an accuracy of 96.6% on MNIST in 15 epochs, outperforming prior benchmarks that capped at 93.4% using the same architecture.
RIS-assisted Cell-Free Massive MIMO Systems With Two-Timescale Design and Hardware Impairments
Mar 26, 2024Integrating the reconfigurable intelligent surface (RIS) into a cell-free massive multiple-input multiple-output (CF-mMIMO) system is an effective solution to achieve high system capacity with low cost and power consumption. However, existing works of RIS-assisted systems mostly assumed perfect hardware, while the impact of hardware impairments (HWIs) is generally ignored. In this paper, we consider the general Rician fading channel and uplink transmission of the RIS-assisted CF-mMIMO system under transceiver impairments and RIS phase noise. To reduce the feedback overhead and power consumption, we propose a two-timescale transmission scheme to optimize the passive beamformers at RISs with statistical channel state information (CSI), while transmit beamformers at access points (APs) are designed based on instantaneous CSI. Also, the maximum ratio combining (MRC) detection is applied to the central processing unit (CPU). On this basis, we derive the closed-form approximate expression of the achievable rate, based on which the impact of HWIs and the power scaling laws are analyzed to draw useful theoretical insights. To maximize the users' sum rate or minimum rate, we first transform our rate expression into a tractable form, and then optimize the phase shifts of RISs based on an accelerated gradient ascent method. Finally, numerical results are presented to demonstrate the correctness of our derived expressions and validate the previous analysis, which provide some guidelines for the practical application of the imperfect RISs in the CF-mMIMO with transceiver HWIs.
Spiking Wavelet Transformer
Mar 26, 2024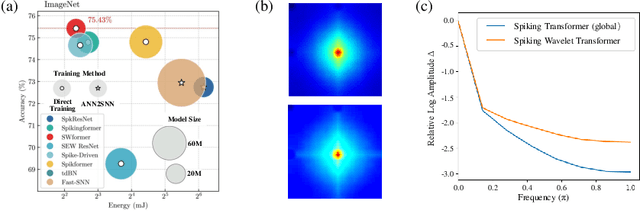
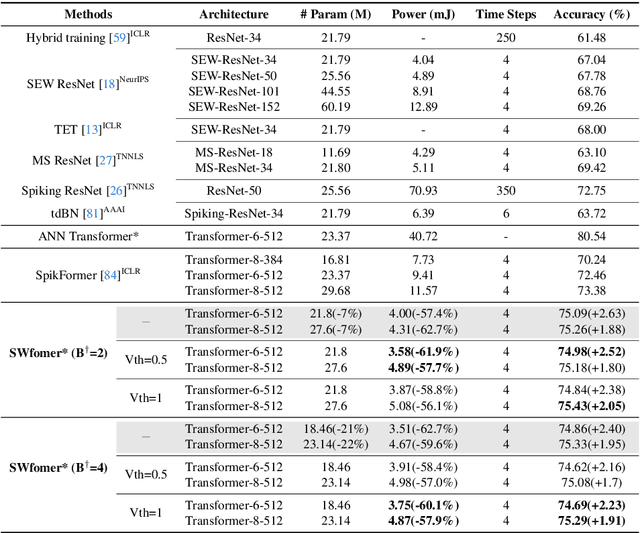
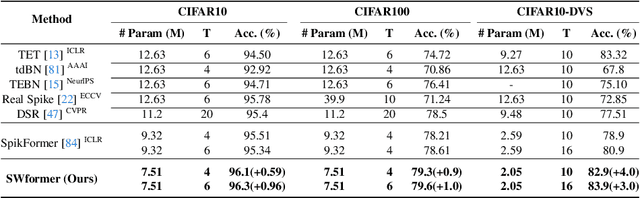
Spiking neural networks (SNNs) offer an energy-efficient alternative to conventional deep learning by mimicking the event-driven processing of the brain. Incorporating the Transformers with SNNs has shown promise for accuracy, yet it is incompetent to capture high-frequency patterns like moving edge and pixel-level brightness changes due to their reliance on global self-attention operations. Porting frequency representations in SNN is challenging yet crucial for event-driven vision. To address this issue, we propose the Spiking Wavelet Transformer (SWformer), an attention-free architecture that effectively learns comprehensive spatial-frequency features in a spike-driven manner by leveraging the sparse wavelet transform. The critical component is a Frequency-Aware Token Mixer (FATM) with three branches: 1) spiking wavelet learner for spatial-frequency domain learning, 2) convolution-based learner for spatial feature extraction, and 3) spiking pointwise convolution for cross-channel information aggregation. We also adopt negative spike dynamics to strengthen the frequency representation further. This enables the SWformer to outperform vanilla Spiking Transformers in capturing high-frequency visual components, as evidenced by our empirical results. Experiments on both static and neuromorphic datasets demonstrate SWformer's effectiveness in capturing spatial-frequency patterns in a multiplication-free, event-driven fashion, outperforming state-of-the-art SNNs. SWformer achieves an over 50% reduction in energy consumption, a 21.1% reduction in parameter count, and a 2.40% performance improvement on the ImageNet dataset compared to vanilla Spiking Transformers.
EgoPoseFormer: A Simple Baseline for Egocentric 3D Human Pose Estimation
Mar 26, 2024We present EgoPoseFormer, a simple yet effective transformer-based model for stereo egocentric human pose estimation. The main challenge in egocentric pose estimation is overcoming joint invisibility, which is caused by self-occlusion or a limited field of view (FOV) of head-mounted cameras. Our approach overcomes this challenge by incorporating a two-stage pose estimation paradigm: in the first stage, our model leverages the global information to estimate each joint's coarse location, then in the second stage, it employs a DETR style transformer to refine the coarse locations by exploiting fine-grained stereo visual features. In addition, we present a deformable stereo operation to enable our transformer to effectively process multi-view features, which enables it to accurately localize each joint in the 3D world. We evaluate our method on the stereo UnrealEgo dataset and show it significantly outperforms previous approaches while being computationally efficient: it improves MPJPE by 27.4mm (45% improvement) with only 7.9% model parameters and 13.1% FLOPs compared to the state-of-the-art. Surprisingly, with proper training techniques, we find that even our first-stage pose proposal network can achieve superior performance compared to previous arts. We also show that our method can be seamlessly extended to monocular settings, which achieves state-of-the-art performance on the SceneEgo dataset, improving MPJPE by 25.5mm (21% improvement) compared to the best existing method with only 60.7% model parameters and 36.4% FLOPs.
Touch the Core: Exploring Task Dependence Among Hybrid Targets for Recommendation
Mar 26, 2024As user behaviors become complicated on business platforms, online recommendations focus more on how to touch the core conversions, which are highly related to the interests of platforms. These core conversions are usually continuous targets, such as \textit{watch time}, \textit{revenue}, and so on, whose predictions can be enhanced by previous discrete conversion actions. Therefore, multi-task learning (MTL) can be adopted as the paradigm to learn these hybrid targets. However, existing works mainly emphasize investigating the sequential dependence among discrete conversion actions, which neglects the complexity of dependence between discrete conversions and the final continuous conversion. Moreover, simultaneously optimizing hybrid tasks with stronger task dependence will suffer from volatile issues where the core regression task might have a larger influence on other tasks. In this paper, we study the MTL problem with hybrid targets for the first time and propose the model named Hybrid Targets Learning Network (HTLNet) to explore task dependence and enhance optimization. Specifically, we introduce label embedding for each task to explicitly transfer the label information among these tasks, which can effectively explore logical task dependence. We also further design the gradient adjustment regime between the final regression task and other classification tasks to enhance the optimization. Extensive experiments on two offline public datasets and one real-world industrial dataset are conducted to validate the effectiveness of HTLNet. Moreover, online A/B tests on the financial recommender system also show our model has superior improvement.