 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Multi-view Impartial Decision Network for Frontotemporal Dementia Diagnosis
Jul 11, 2023
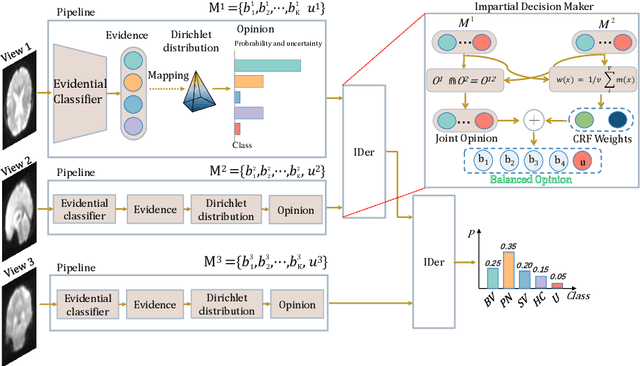
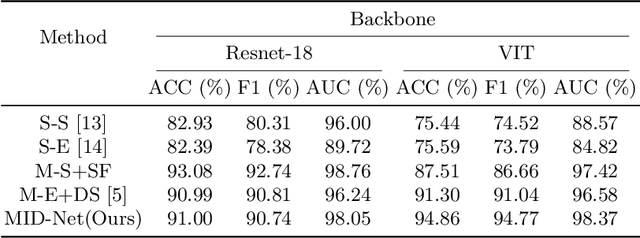
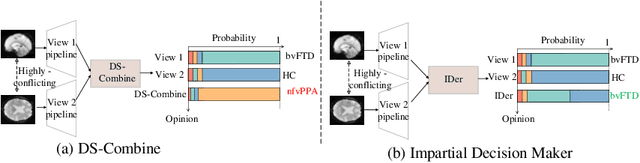
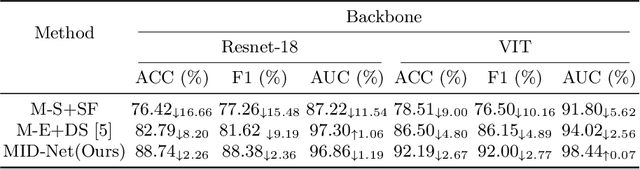
Frontotemporal Dementia (FTD) diagnosis has been successfully progress using deep learning techniques. However, current FTD identification methods suffer from two limitations. Firstly, they do not exploit the potential of multi-view functional magnetic resonance imaging (fMRI) for classifying FTD. Secondly, they do not consider the reliability of the multi-view FTD diagnosis. To address these limitations, we propose a reliable multi-view impartial decision network (MID-Net) for FTD diagnosis in fMRI. Our MID-Net provides confidence for each view and generates a reliable prediction without any conflict. To achieve this, we employ multiple expert models to extract evidence from the abundant neural network information contained in fMRI images. We then introduce the Dirichlet Distribution to characterize the expert class probability distribution from an evidence level. Additionally, a novel Impartial Decision Maker (IDer) is proposed to combine the different opinions inductively to arrive at an unbiased prediction without additional computation cost. Overall, our MID-Net dynamically integrates the decisions of different experts on FTD disease, especially when dealing with multi-view high-conflict cases. Extensive experiments on a high-quality FTD fMRI dataset demonstrate that our model outperforms previous methods and provides high uncertainty for hard-to-classify examples. We believe that our approach represents a significant step toward the deployment of reliable FTD decision-making under multi-expert conditions. We will release the codes for reproduction after acceptance.
Unleashing Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration
Jul 11, 2023

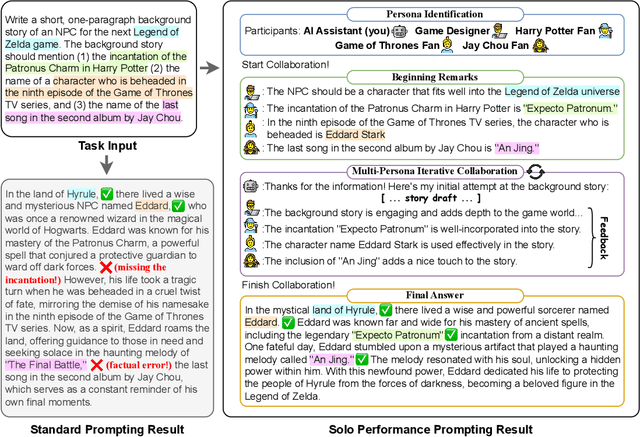

Human intelligence thrives on the concept of cognitive synergy, where collaboration and information integration among different cognitive processes yield superior outcomes compared to individual cognitive processes in isolation. Although Large Language Models (LLMs) have demonstrated promising performance as general task-solving agents, they still struggle with tasks that require intensive domain knowledge and complex reasoning. In this work, we propose Solo Performance Prompting (SPP), which transforms a single LLM into a cognitive synergist by engaging in multi-turn self-collaboration with multiple personas. A cognitive synergist refers to an intelligent agent that collaborates with multiple minds, combining their individual strengths and knowledge, to enhance problem-solving and overall performance in complex tasks. By dynamically identifying and simulating different personas based on task inputs, SPP unleashes the potential of cognitive synergy in LLMs. We have discovered that assigning multiple, fine-grained personas in LLMs elicits better problem-solving abilities compared to using a single or fixed number of personas. We evaluate SPP on three challenging tasks: Trivia Creative Writing, Codenames Collaborative, and Logic Grid Puzzle, encompassing both knowledge-intensive and reasoning-intensive types. Unlike previous works, such as Chain-of-Thought, that solely enhance the reasoning abilities in LLMs, SPP effectively elicits internal knowledge acquisition abilities, reduces hallucination, and maintains strong reasoning capabilities. Code, data, and prompts can be found at: https://github.com/MikeWangWZHL/Solo-Performance-Prompting.git.
Optimal Coordinated Transmit Beamforming for Networked Integrated Sensing and Communications
Jul 11, 2023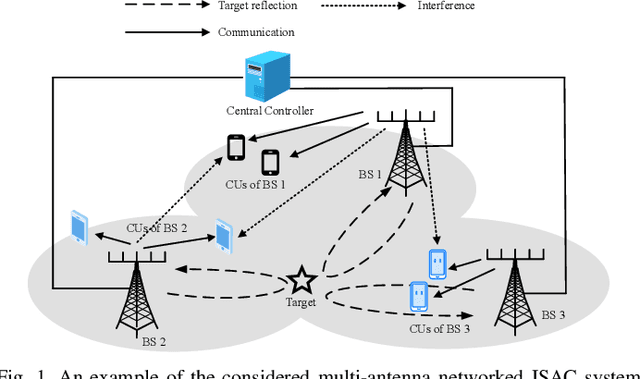
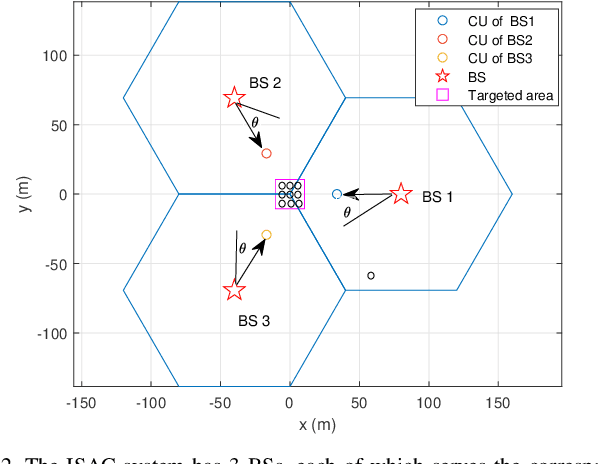
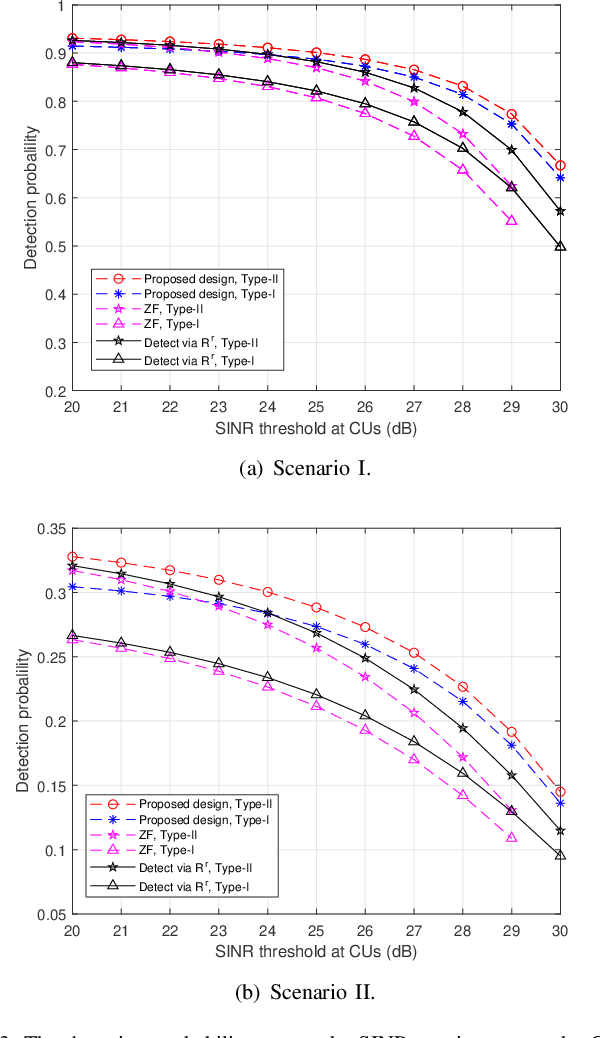
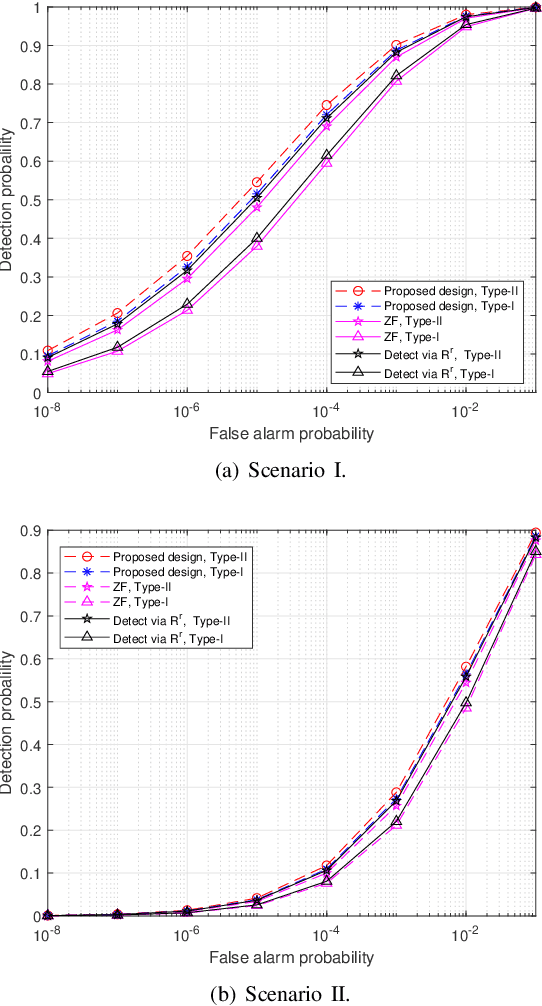
This paper studies a multi-antenna networked integrated sensing and communications (ISAC) system, in which a set of multi-antenna base stations (BSs) employ the coordinated transmit beamforming to serve multiple single-antenna communication users (CUs) and perform joint target detection by exploiting the reflected signals simultaneously. To facilitate target sensing, the BSs transmit dedicated sensing signals combined with their information signals. Accordingly, we consider two types of CU receivers with and without the capability of canceling the interference from the dedicated sensing signals, respectively. In addition, we investigate two scenarios with and without time synchronization among the BSs. For the scenario with synchronization, the BSs can exploit the target-reflected signals over both the direct links (BS-to-target-to-originated BS links) and the cross-links (BS-to-target-to-other BSs links) for joint detection, while in the unsynchronized scenario, the BSs can only utilize the target-reflected signals over the direct links. For each scenario under different types of CU receivers, we optimize the coordinated transmit beamforming at the BSs to maximize the minimum detection probability over a particular targeted area, while guaranteeing the required minimum signal-to-interference-plus-noise ratio (SINR) constraints at the CUs. These SINR-constrained detection probability maximization problems are recast as non-convex quadratically constrained quadratic programs (QCQPs), which are then optimally solved via the semi-definite relaxation (SDR) technique.
Separate-and-Aggregate: A Transformer-based Patch Refinement Model for Knowledge Graph Completion
Jul 11, 2023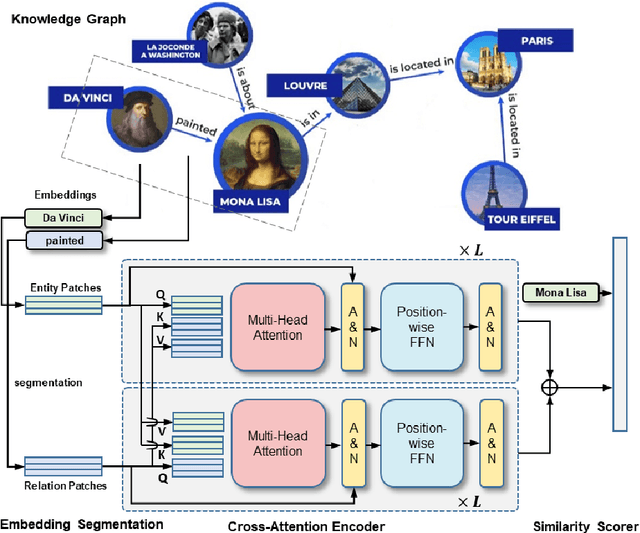
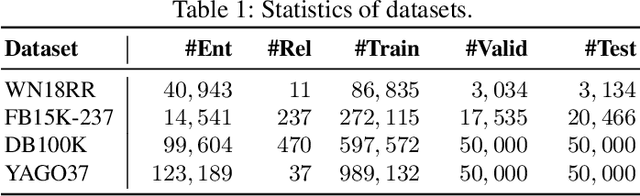
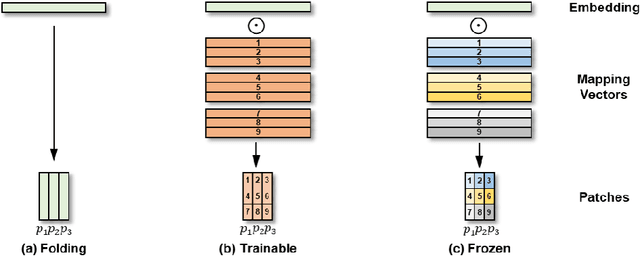
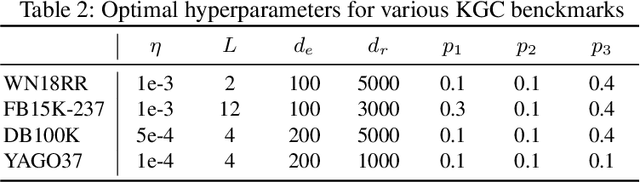
Knowledge graph completion (KGC) is the task of inferencing missing facts from any given knowledge graphs (KG). Previous KGC methods typically represent knowledge graph entities and relations as trainable continuous embeddings and fuse the embeddings of the entity $h$ (or $t$) and relation $r$ into hidden representations of query $(h, r, ?)$ (or $(?, r, t$)) to approximate the missing entities. To achieve this, they either use shallow linear transformations or deep convolutional modules. However, the linear transformations suffer from the expressiveness issue while the deep convolutional modules introduce unnecessary inductive bias, which could potentially degrade the model performance. Thus, we propose a novel Transformer-based Patch Refinement Model (PatReFormer) for KGC. PatReFormer first segments the embedding into a sequence of patches and then employs cross-attention modules to allow bi-directional embedding feature interaction between the entities and relations, leading to a better understanding of the underlying KG. We conduct experiments on four popular KGC benchmarks, WN18RR, FB15k-237, YAGO37 and DB100K. The experimental results show significant performance improvement from existing KGC methods on standard KGC evaluation metrics, e.g., MRR and H@n. Our analysis first verifies the effectiveness of our model design choices in PatReFormer. We then find that PatReFormer can better capture KG information from a large relation embedding dimension. Finally, we demonstrate that the strength of PatReFormer is at complex relation types, compared to other KGC models
Cross-modal Orthogonal High-rank Augmentation for RGB-Event Transformer-trackers
Jul 09, 2023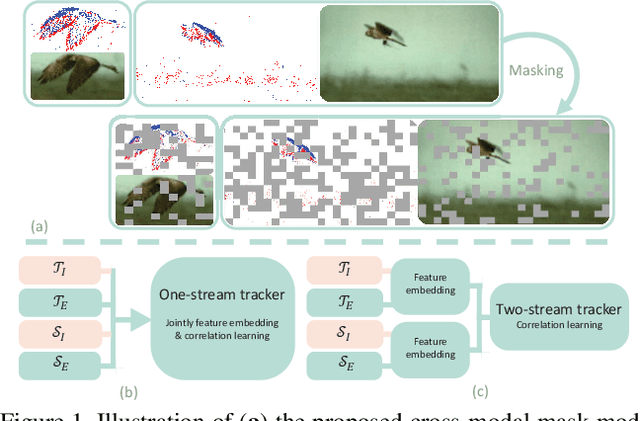
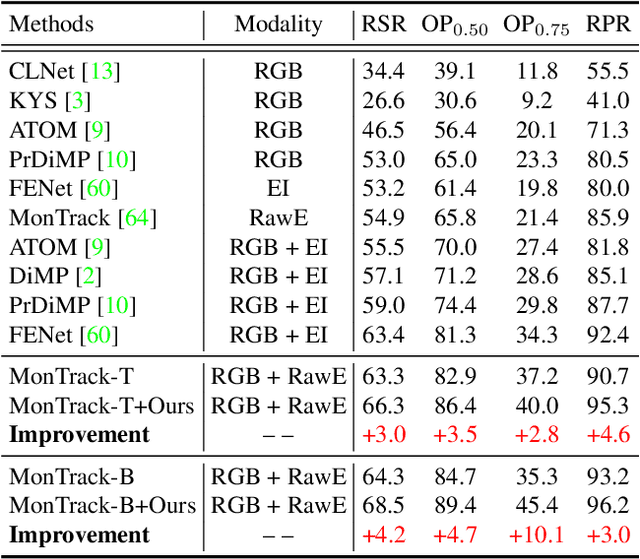
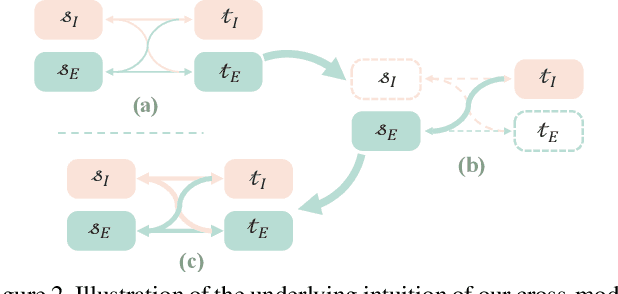
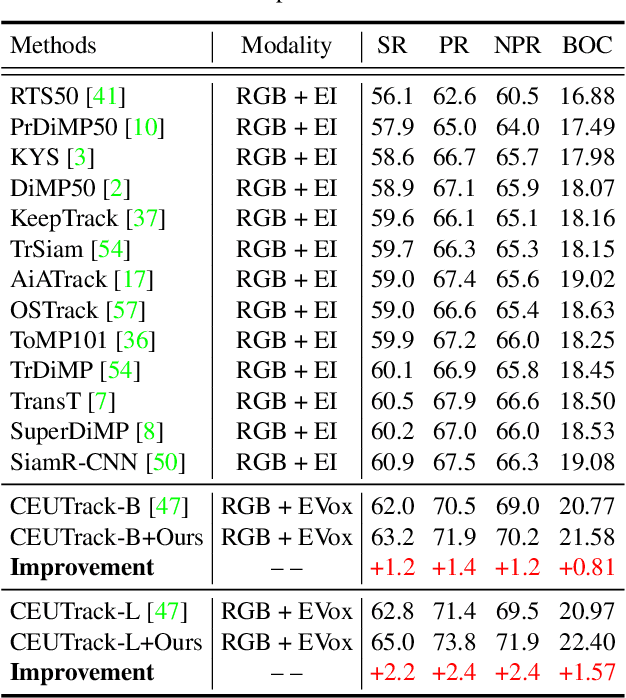
This paper addresses the problem of cross-modal object tracking from RGB videos and event data. Rather than constructing a complex cross-modal fusion network, we explore the great potential of a pre-trained vision Transformer (ViT). Particularly, we delicately investigate plug-and-play training augmentations that encourage the ViT to bridge the vast distribution gap between the two modalities, enabling comprehensive cross-modal information interaction and thus enhancing its ability. Specifically, we propose a mask modeling strategy that randomly masks a specific modality of some tokens to enforce the interaction between tokens from different modalities interacting proactively. To mitigate network oscillations resulting from the masking strategy and further amplify its positive effect, we then theoretically propose an orthogonal high-rank loss to regularize the attention matrix. Extensive experiments demonstrate that our plug-and-play training augmentation techniques can significantly boost state-of-the-art one-stream and twostream trackers to a large extent in terms of both tracking precision and success rate. Our new perspective and findings will potentially bring insights to the field of leveraging powerful pre-trained ViTs to model cross-modal data. The code will be publicly available.
Meta Federated Reinforcement Learning for Distributed Resource Allocation
Jul 09, 2023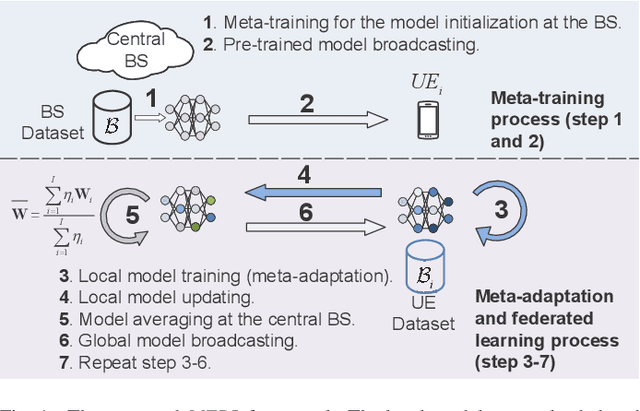
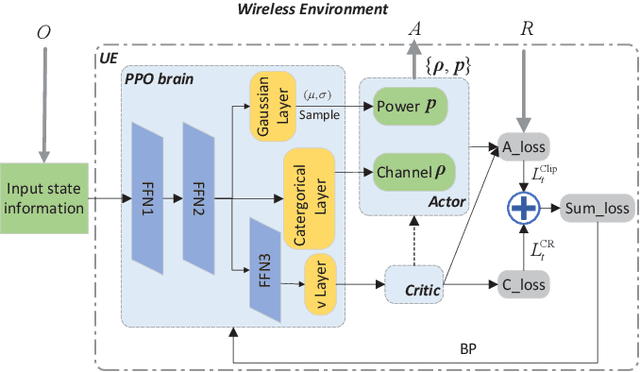
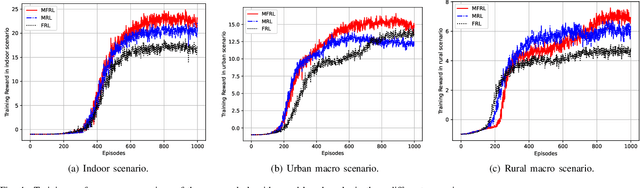
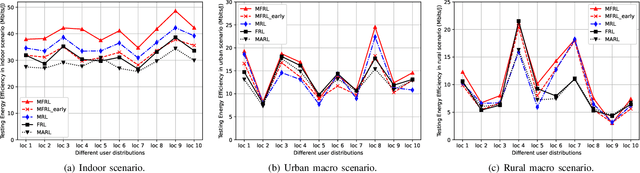
In cellular networks, resource allocation is usually performed in a centralized way, which brings huge computation complexity to the base station (BS) and high transmission overhead. This paper explores a distributed resource allocation method that aims to maximize energy efficiency (EE) while ensuring the quality of service (QoS) for users. Specifically, in order to address wireless channel conditions, we propose a robust meta federated reinforcement learning (\textit{MFRL}) framework that allows local users to optimize transmit power and assign channels using locally trained neural network models, so as to offload computational burden from the cloud server to the local users, reducing transmission overhead associated with local channel state information. The BS performs the meta learning procedure to initialize a general global model, enabling rapid adaptation to different environments with improved EE performance. The federated learning technique, based on decentralized reinforcement learning, promotes collaboration and mutual benefits among users. Analysis and numerical results demonstrate that the proposed \textit{MFRL} framework accelerates the reinforcement learning process, decreases transmission overhead, and offloads computation, while outperforming the conventional decentralized reinforcement learning algorithm in terms of convergence speed and EE performance across various scenarios.
SageFormer: Series-Aware Graph-Enhanced Transformers for Multivariate Time Series Forecasting
Jul 04, 2023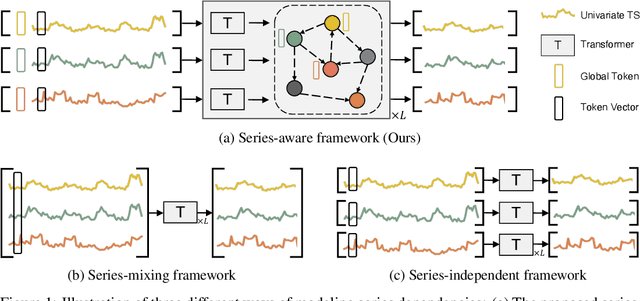

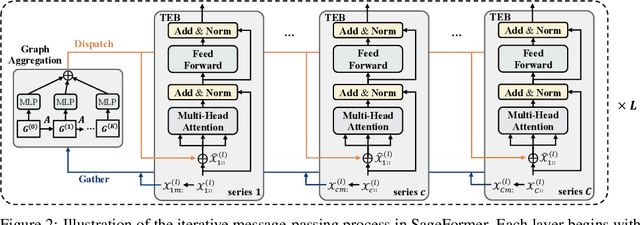
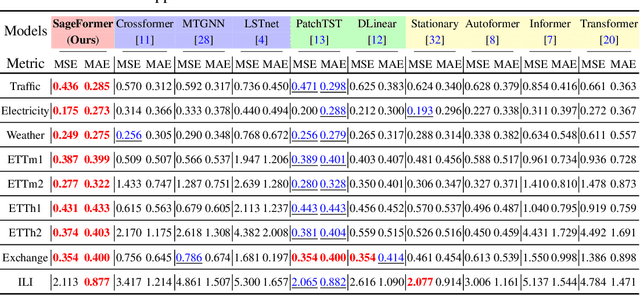
Multivariate time series forecasting plays a critical role in diverse domains. While recent advancements in deep learning methods, especially Transformers, have shown promise, there remains a gap in addressing the significance of inter-series dependencies. This paper introduces SageFormer, a Series-aware Graph-enhanced Transformer model designed to effectively capture and model dependencies between series using graph structures. SageFormer tackles two key challenges: effectively representing diverse temporal patterns across series and mitigating redundant information among series. Importantly, the proposed series-aware framework seamlessly integrates with existing Transformer-based models, augmenting their ability to model inter-series dependencies. Through extensive experiments on real-world and synthetic datasets, we showcase the superior performance of SageFormer compared to previous state-of-the-art approaches.
Online Ad Procurement in Non-stationary Autobidding Worlds
Jul 10, 2023

Today's online advertisers procure digital ad impressions through interacting with autobidding platforms: advertisers convey high level procurement goals via setting levers such as budget, target return-on-investment, max cost per click, etc.. Then ads platforms subsequently procure impressions on advertisers' behalf, and report final procurement conversions (e.g. click) to advertisers. In practice, advertisers may receive minimal information on platforms' procurement details, and procurement outcomes are subject to non-stationary factors like seasonal patterns, occasional system corruptions, and market trends which make it difficult for advertisers to optimize lever decisions effectively. Motivated by this, we present an online learning framework that helps advertisers dynamically optimize ad platform lever decisions while subject to general long-term constraints in a realistic bandit feedback environment with non-stationary procurement outcomes. In particular, we introduce a primal-dual algorithm for online decision making with multi-dimension decision variables, bandit feedback and long-term uncertain constraints. We show that our algorithm achieves low regret in many worlds when procurement outcomes are generated through procedures that are stochastic, adversarial, adversarially corrupted, periodic, and ergodic, respectively, without having to know which procedure is the ground truth. Finally, we emphasize that our proposed algorithm and theoretical results extend beyond the applications of online advertising.
Ethicist: Targeted Training Data Extraction Through Loss Smoothed Soft Prompting and Calibrated Confidence Estimation
Jul 10, 2023
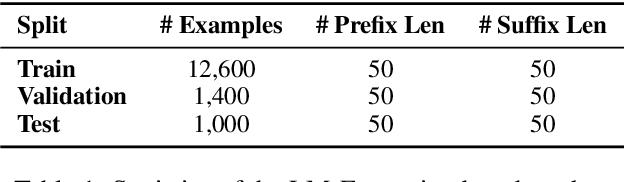
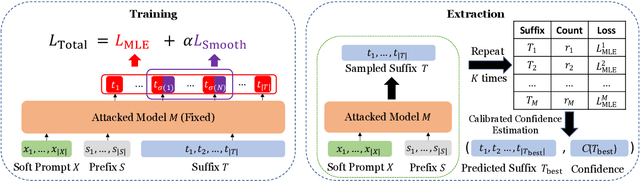
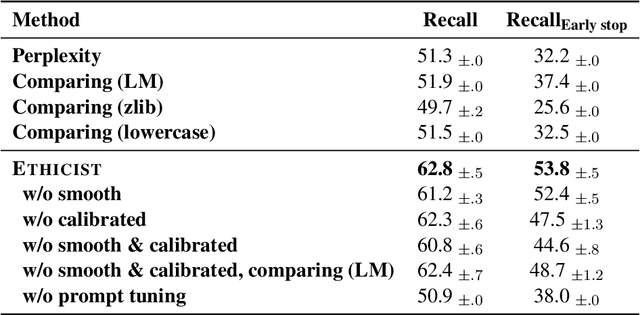
Large pre-trained language models achieve impressive results across many tasks. However, recent works point out that pre-trained language models may memorize a considerable fraction of their training data, leading to the privacy risk of information leakage. In this paper, we propose a method named Ethicist for targeted training data extraction through loss smoothed soft prompting and calibrated confidence estimation, investigating how to recover the suffix in the training data when given a prefix. To elicit memorization in the attacked model, we tune soft prompt embeddings while keeping the model fixed. We further propose a smoothing loss that smooths the loss distribution of the suffix tokens to make it easier to sample the correct suffix. In order to select the most probable suffix from a collection of sampled suffixes and estimate the prediction confidence, we propose a calibrated confidence estimation method, which normalizes the confidence of the generated suffixes with a local estimation. We show that Ethicist significantly improves the extraction performance on a recently proposed public benchmark. We also investigate several factors influencing the data extraction performance, including decoding strategy, model scale, prefix length, and suffix length. Our code is available at https://github.com/thu-coai/Targeted-Data-Extraction.
Counterfactual Explanation for Fairness in Recommendation
Jul 10, 2023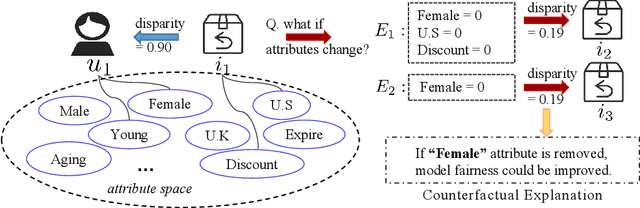
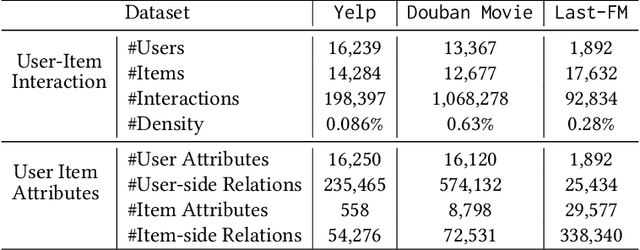
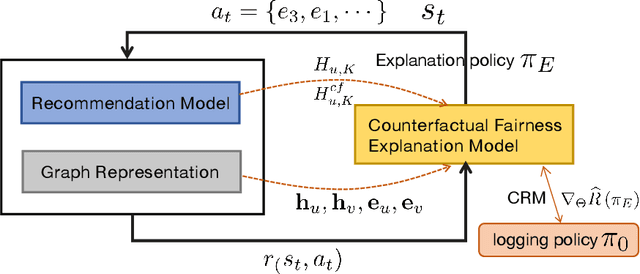
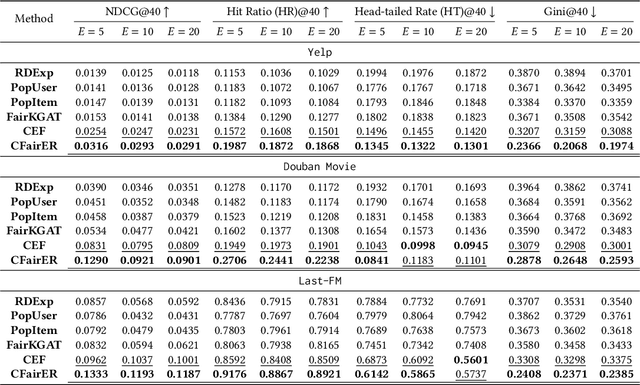
Fairness-aware recommendation eliminates discrimination issues to build trustworthy recommendation systems.Explaining the causes of unfair recommendations is critical, as it promotes fairness diagnostics, and thus secures users' trust in recommendation models. Existing fairness explanation methods suffer high computation burdens due to the large-scale search space and the greedy nature of the explanation search process. Besides, they perform score-based optimizations with continuous values, which are not applicable to discrete attributes such as gender and race. In this work, we adopt the novel paradigm of counterfactual explanation from causal inference to explore how minimal alterations in explanations change model fairness, to abandon the greedy search for explanations. We use real-world attributes from Heterogeneous Information Networks (HINs) to empower counterfactual reasoning on discrete attributes. We propose a novel Counterfactual Explanation for Fairness (CFairER) that generates attribute-level counterfactual explanations from HINs for recommendation fairness. Our CFairER conducts off-policy reinforcement learning to seek high-quality counterfactual explanations, with an attentive action pruning reducing the search space of candidate counterfactuals. The counterfactual explanations help to provide rational and proximate explanations for model fairness, while the attentive action pruning narrows the search space of attributes. Extensive experiments demonstrate our proposed model can generate faithful explanations while maintaining favorable recommendation performance.