 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MIRACLE: Multi-task Learning based Interpretable Regulation of Autoimmune Diseases through Common Latent Epigenetics
Jun 24, 2023
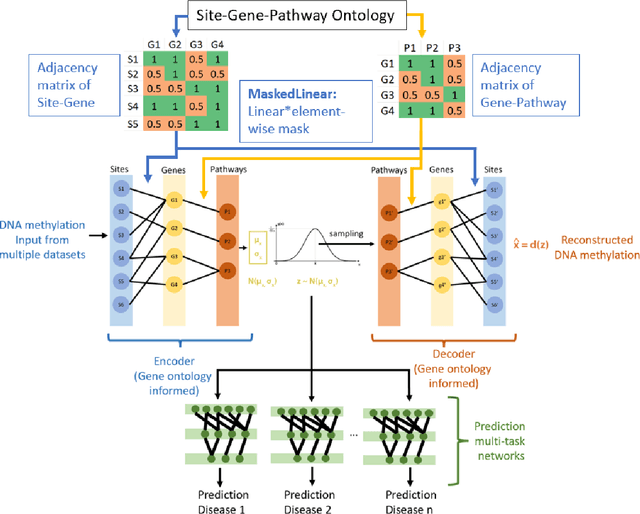

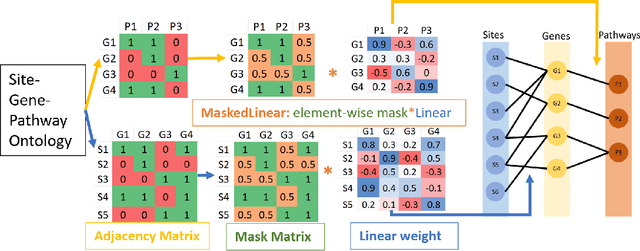
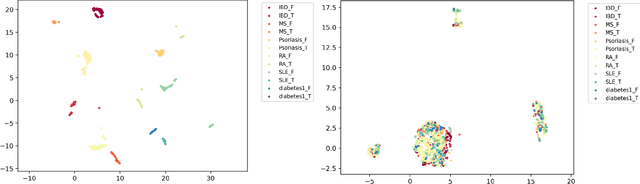
DNA methylation is a crucial regulator of gene transcription and has been linked to various diseases, including autoimmune diseases and cancers. However, diagnostics based on DNA methylation face challenges due to large feature sets and small sample sizes, resulting in overfitting and suboptimal performance. To address these issues, we propose MIRACLE, a novel interpretable neural network that leverages autoencoder-based multi-task learning to integrate multiple datasets and jointly identify common patterns in DNA methylation. MIRACLE's architecture reflects the relationships between methylation sites, genes, and pathways, ensuring biological interpretability and meaningfulness. The network comprises an encoder and a decoder, with a bottleneck layer representing pathway information as the basic unit of heredity. Customized defined MaskedLinear Layer is constrained by site-gene-pathway graph adjacency matrix information, which provides explainability and expresses the site-gene-pathway hierarchical structure explicitly. And from the embedding, there are different multi-task classifiers to predict diseases. Tested on six datasets, including rheumatoid arthritis, systemic lupus erythematosus, multiple sclerosis, inflammatory bowel disease, psoriasis, and type 1 diabetes, MIRACLE demonstrates robust performance in identifying common functions of DNA methylation across different phenotypes, with higher accuracy in prediction dieseases than baseline methods. By incorporating biological prior knowledge, MIRACLE offers a meaningful and interpretable framework for DNA methylation data analysis in the context of autoimmune diseases.
Communication-Efficient Federated Learning through Importance Sampling
Jun 22, 2023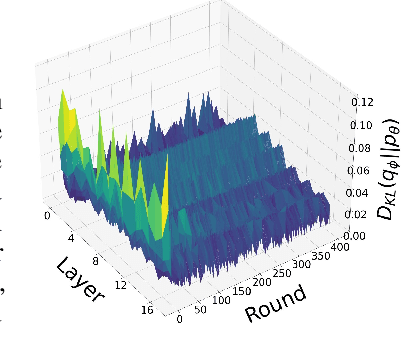
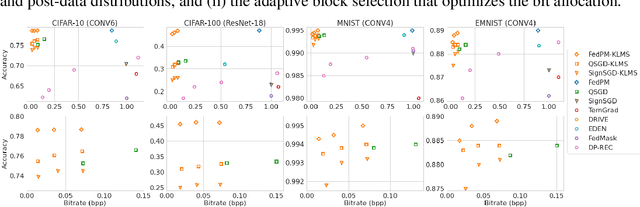
The high communication cost of sending model updates from the clients to the server is a significant bottleneck for scalable federated learning (FL). Among existing approaches, state-of-the-art bitrate-accuracy tradeoffs have been achieved using stochastic compression methods -- in which the client $n$ sends a sample from a client-only probability distribution $q_{\phi^{(n)}}$, and the server estimates the mean of the clients' distributions using these samples. However, such methods do not take full advantage of the FL setup where the server, throughout the training process, has side information in the form of a pre-data distribution $p_{\theta}$ that is close to the client's distribution $q_{\phi^{(n)}}$ in Kullback-Leibler (KL) divergence. In this work, we exploit this closeness between the clients' distributions $q_{\phi^{(n)}}$'s and the side information $p_{\theta}$ at the server, and propose a framework that requires approximately $D_{KL}(q_{\phi^{(n)}}|| p_{\theta})$ bits of communication. We show that our method can be integrated into many existing stochastic compression frameworks such as FedPM, Federated SGLD, and QSGD to attain the same (and often higher) test accuracy with up to $50$ times reduction in the bitrate.
PromptIR: Prompting for All-in-One Blind Image Restoration
Jun 22, 2023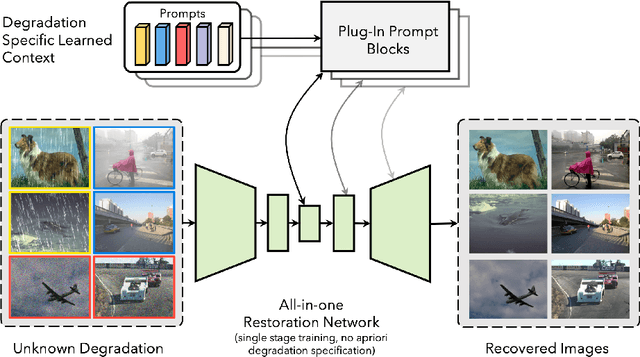
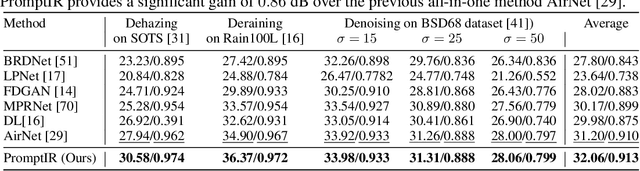
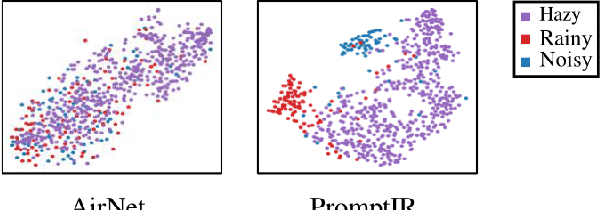

Image restoration involves recovering a high-quality clean image from its degraded version. Deep learning-based methods have significantly improved image restoration performance, however, they have limited generalization ability to different degradation types and levels. This restricts their real-world application since it requires training individual models for each specific degradation and knowing the input degradation type to apply the relevant model. We present a prompt-based learning approach, PromptIR, for All-In-One image restoration that can effectively restore images from various types and levels of degradation. In particular, our method uses prompts to encode degradation-specific information, which is then used to dynamically guide the restoration network. This allows our method to generalize to different degradation types and levels, while still achieving state-of-the-art results on image denoising, deraining, and dehazing. Overall, PromptIR offers a generic and efficient plugin module with few lightweight prompts that can be used to restore images of various types and levels of degradation with no prior information on the corruptions present in the image. Our code and pretrained models are available here: https://github.com/va1shn9v/PromptIR
Super-Resolution of BVOC Emission Maps Via Domain Adaptation
Jun 22, 2023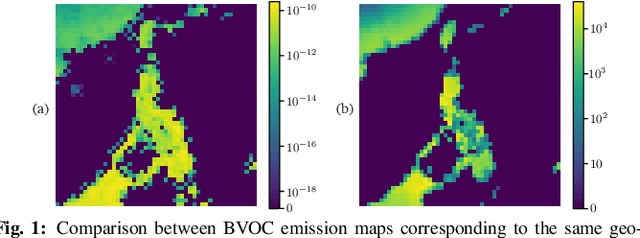
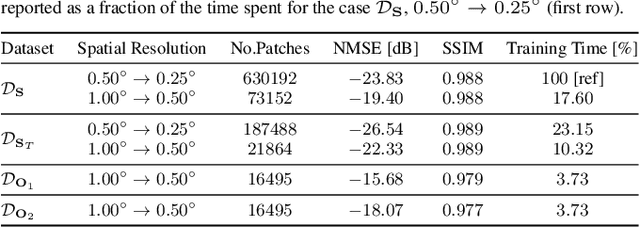
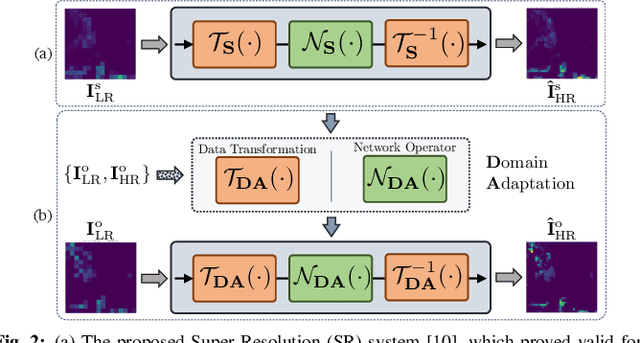
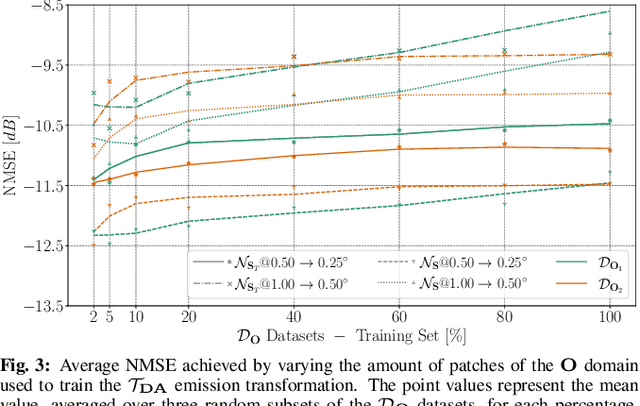
Enhancing the resolution of Biogenic Volatile Organic Compound (BVOC) emission maps is a critical task in remote sensing. Recently, some Super-Resolution (SR) methods based on Deep Learning (DL) have been proposed, leveraging data from numerical simulations for their training process. However, when dealing with data derived from satellite observations, the reconstruction is particularly challenging due to the scarcity of measurements to train SR algorithms with. In our work, we aim at super-resolving low resolution emission maps derived from satellite observations by leveraging the information of emission maps obtained through numerical simulations. To do this, we combine a SR method based on DL with Domain Adaptation (DA) techniques, harmonizing the different aggregation strategies and spatial information used in simulated and observed domains to ensure compatibility. We investigate the effectiveness of DA strategies at different stages by systematically varying the number of simulated and observed emissions used, exploring the implications of data scarcity on the adaptation strategies. To the best of our knowledge, there are no prior investigations of DA in satellite-derived BVOC maps enhancement. Our work represents a first step toward the development of robust strategies for the reconstruction of observed BVOC emissions.
DreamDiffusion: Generating High-Quality Images from Brain EEG Signals
Jun 29, 2023
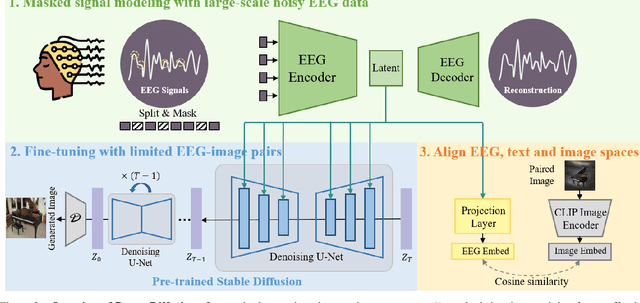
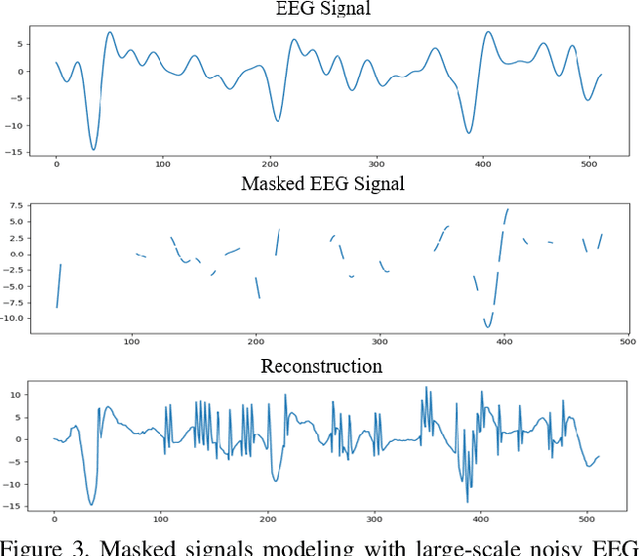

This paper introduces DreamDiffusion, a novel method for generating high-quality images directly from brain electroencephalogram (EEG) signals, without the need to translate thoughts into text. DreamDiffusion leverages pre-trained text-to-image models and employs temporal masked signal modeling to pre-train the EEG encoder for effective and robust EEG representations. Additionally, the method further leverages the CLIP image encoder to provide extra supervision to better align EEG, text, and image embeddings with limited EEG-image pairs. Overall, the proposed method overcomes the challenges of using EEG signals for image generation, such as noise, limited information, and individual differences, and achieves promising results. Quantitative and qualitative results demonstrate the effectiveness of the proposed method as a significant step towards portable and low-cost ``thoughts-to-image'', with potential applications in neuroscience and computer vision.
TACOformer:Token-channel compounded Cross Attention for Multimodal Emotion Recognition
Jun 23, 2023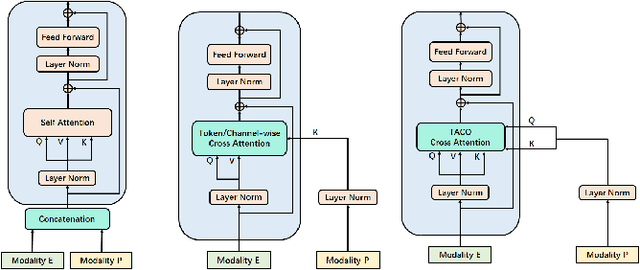
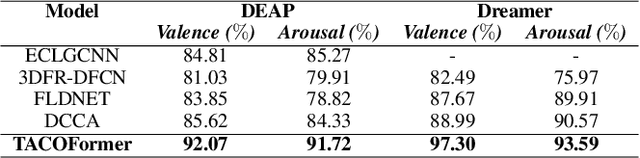
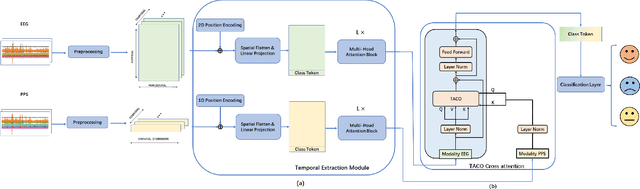

Recently, emotion recognition based on physiological signals has emerged as a field with intensive research. The utilization of multi-modal, multi-channel physiological signals has significantly improved the performance of emotion recognition systems, due to their complementarity. However, effectively integrating emotion-related semantic information from different modalities and capturing inter-modal dependencies remains a challenging issue. Many existing multimodal fusion methods ignore either token-to-token or channel-to-channel correlations of multichannel signals from different modalities, which limits the classification capability of the models to some extent. In this paper, we propose a comprehensive perspective of multimodal fusion that integrates channel-level and token-level cross-modal interactions. Specifically, we introduce a unified cross attention module called Token-chAnnel COmpound (TACO) Cross Attention to perform multimodal fusion, which simultaneously models channel-level and token-level dependencies between modalities. Additionally, we propose a 2D position encoding method to preserve information about the spatial distribution of EEG signal channels, then we use two transformer encoders ahead of the fusion module to capture long-term temporal dependencies from the EEG signal and the peripheral physiological signal, respectively. Subject-independent experiments on emotional dataset DEAP and Dreamer demonstrate that the proposed model achieves state-of-the-art performance.
Learning World Models with Identifiable Factorization
Jun 11, 2023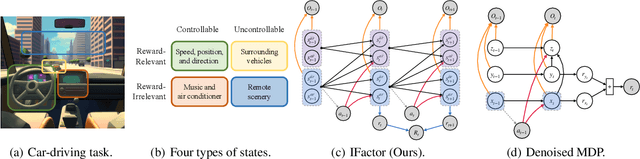
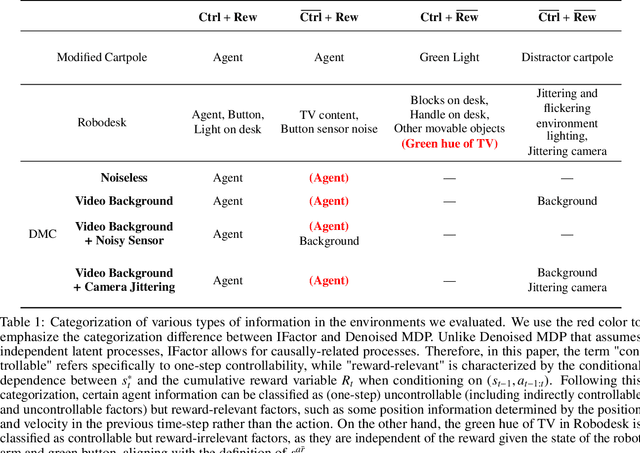
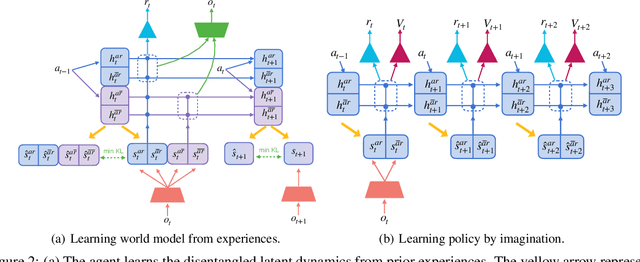
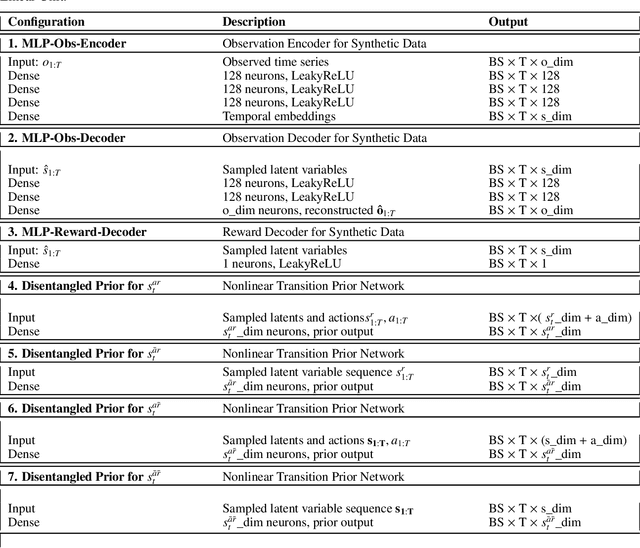
Extracting a stable and compact representation of the environment is crucial for efficient reinforcement learning in high-dimensional, noisy, and non-stationary environments. Different categories of information coexist in such environments -- how to effectively extract and disentangle these information remains a challenging problem. In this paper, we propose IFactor, a general framework to model four distinct categories of latent state variables that capture various aspects of information within the RL system, based on their interactions with actions and rewards. Our analysis establishes block-wise identifiability of these latent variables, which not only provides a stable and compact representation but also discloses that all reward-relevant factors are significant for policy learning. We further present a practical approach to learning the world model with identifiable blocks, ensuring the removal of redundants but retaining minimal and sufficient information for policy optimization. Experiments in synthetic worlds demonstrate that our method accurately identifies the ground-truth latent variables, substantiating our theoretical findings. Moreover, experiments in variants of the DeepMind Control Suite and RoboDesk showcase the superior performance of our approach over baselines.
Undecimated Wavelet Transform for Word Embedded Semantic Marginal Autoencoder in Security improvement and Denoising different Languages
Jul 06, 2023By combining the undecimated wavelet transform within a Word Embedded Semantic Marginal Autoencoder (WESMA), this research study provides a novel strategy for improving security measures and denoising multiple languages. The incorporation of these strategies is intended to address the issues of robustness, privacy, and multilingualism in data processing applications. The undecimated wavelet transform is used as a feature extraction tool to identify prominent language patterns and structural qualities in the input data. The proposed system may successfully capture significant information while preserving the temporal and geographical links within the data by employing this transform. This improves security measures by increasing the system's ability to detect abnormalities, discover hidden patterns, and distinguish between legitimate content and dangerous threats. The Word Embedded Semantic Marginal Autoencoder also functions as an intelligent framework for dimensionality and noise reduction. The autoencoder effectively learns the underlying semantics of the data and reduces noise components by exploiting word embeddings and semantic context. As a result, data quality and accuracy are increased in following processing stages. The suggested methodology is tested using a diversified dataset that includes several languages and security scenarios. The experimental results show that the proposed approach is effective in attaining security enhancement and denoising capabilities across multiple languages. The system is strong in dealing with linguistic variances, producing consistent outcomes regardless of the language used. Furthermore, incorporating the undecimated wavelet transform considerably improves the system's ability to efficiently address complex security concerns
A Meta-Evaluation of C/W/L/A Metrics: System Ranking Similarity, System Ranking Consistency and Discriminative Power
Jul 06, 2023


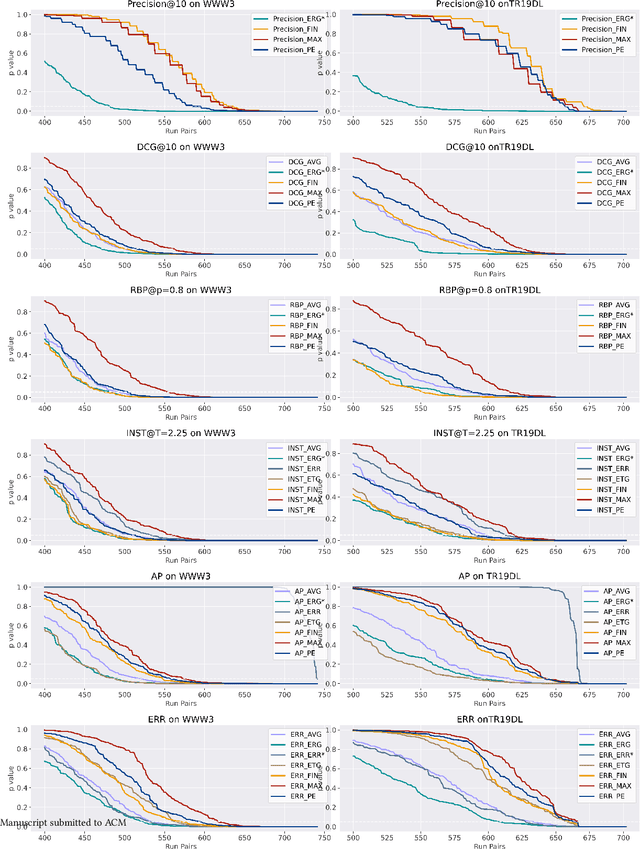
Recently, Moffat et al. proposed an analytic framework, namely C/W/L/A, for offline evaluation metrics. This framework allows information retrieval (IR) researchers to design evaluation metrics through the flexible combination of user browsing models and user gain aggregations. However, the statistical stability of C/W/L/A metrics with different aggregations is not yet investigated. In this study, we investigate the statistical stability of C/W/L/A metrics from the perspective of: (1) the system ranking similarity among aggregations, (2) the system ranking consistency of aggregations and (3) the discriminative power of aggregations. More specifically, we combined various aggregation functions with the browsing model of Precision, Discounted Cumulative Gain (DCG), Rank-Biased Precision (RBP), INST, Average Precision (AP) and Expected Reciprocal Rank (ERR), examing their performances in terms of system ranking similarity, system ranking consistency and discriminative power on two offline test collections. Our experimental result suggests that, in terms of system ranking consistency and discriminative power, the aggregation function of expected rate of gain (ERG) has an outstanding performance while the aggregation function of maximum relevance usually has an insufficient performance. The result also suggests that Precision, DCG, RBP, INST and AP with their canonical aggregation all have favourable performances in system ranking consistency and discriminative power; but for ERR, replacing its canonical aggregation with ERG can further strengthen the discriminative power while obtaining a system ranking list similar to the canonical version at the same time.
Learning Models of Adversarial Agent Behavior under Partial Observability
Jun 19, 2023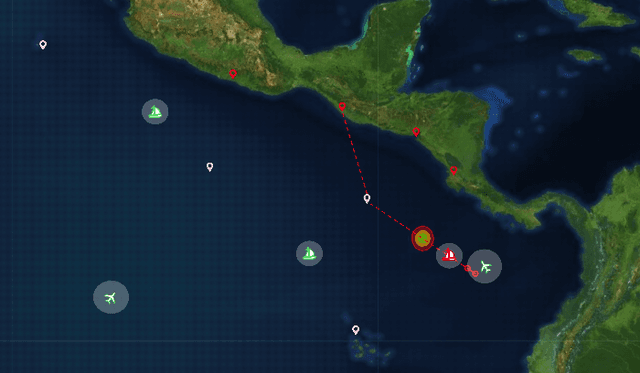
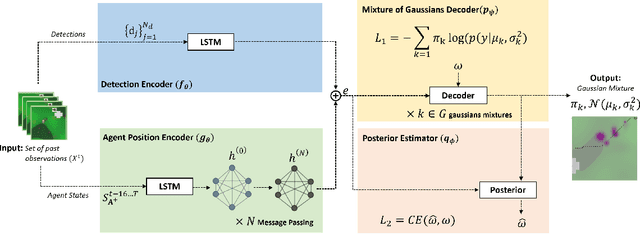
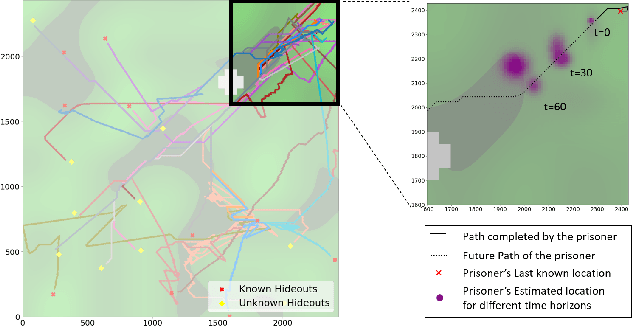
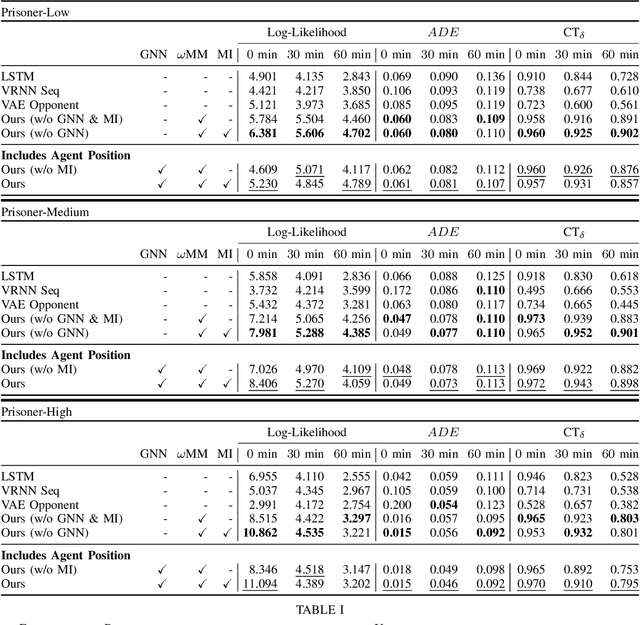
The need for opponent modeling and tracking arises in several real-world scenarios, such as professional sports, video game design, and drug-trafficking interdiction. In this work, we present graPh neurAl Network aDvErsarial MOdeliNg wIth mUtual informMation for modeling the behavior of an adversarial opponent agent. PANDEMONIUM is a novel graph neural network (GNN) based approach that uses mutual information maximization as an auxiliary objective to predict the current and future states of an adversarial opponent with partial observability. To evaluate PANDEMONIUM, we design two large-scale, pursuit-evasion domains inspired by real-world scenarios, where a team of heterogeneous agents is tasked with tracking and interdicting a single adversarial agent, and the adversarial agent must evade detection while achieving its own objectives. With the mutual information formulation, PANDEMONIUM outperforms all baselines in both domains and achieves 31.68% higher log-likelihood on average for future adversarial state predictions across both domains.