 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Valid Information Guidance Network for Compressed Video Quality Enhancement
Feb 28, 2023


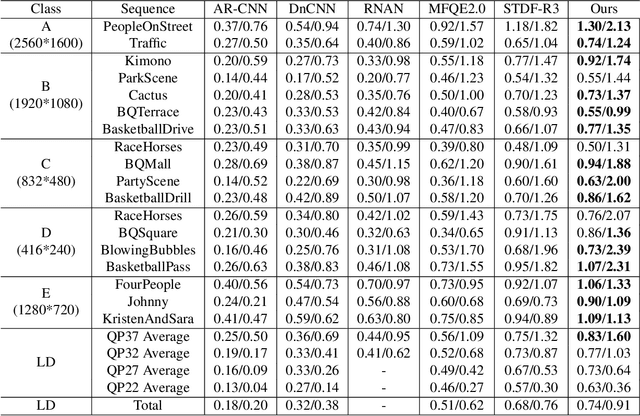
In recent years deep learning methods have shown great superiority in compressed video quality enhancement tasks. Existing methods generally take the raw video as the ground truth and extract practical information from consecutive frames containing various artifacts. However, they do not fully exploit the valid information of compressed and raw videos to guide the quality enhancement for compressed videos. In this paper, we propose a unique Valid Information Guidance scheme (VIG) to enhance the quality of compressed videos by mining valid information from both compressed videos and raw videos. Specifically, we propose an efficient framework, Compressed Redundancy Filtering (CRF) network, to balance speed and enhancement. After removing the redundancy by filtering the information, CRF can use the valid information of the compressed video to reconstruct the texture. Furthermore, we propose a progressive Truth Guidance Distillation (TGD) strategy, which does not need to design additional teacher models and distillation loss functions. By only using the ground truth as input to guide the model to aggregate the correct spatio-temporal correspondence across the raw frames, TGD can significantly improve the enhancement effect without increasing the extra training cost. Extensive experiments show that our method achieves the state-of-the-art performance of compressed video quality enhancement in terms of accuracy and efficiency.
Improving Segmentation and Detection of Lesions in CT Scans Using Intensity Distribution Supervision
Jul 11, 2023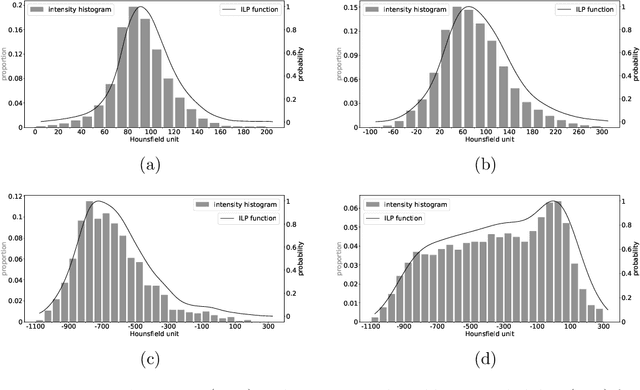
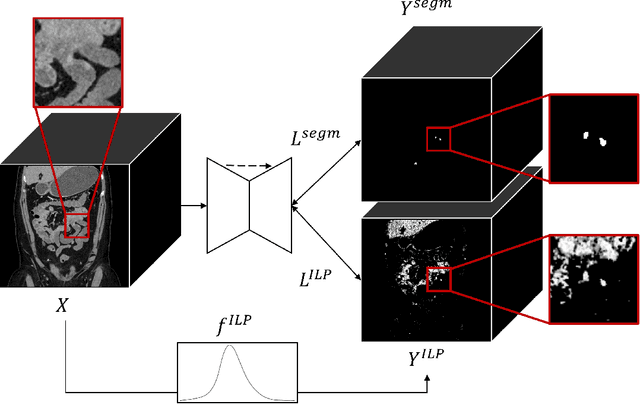
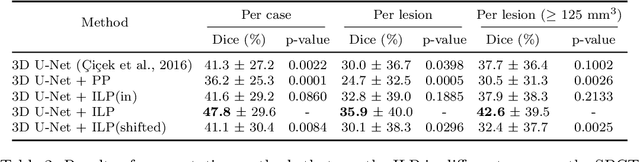
We propose a method to incorporate the intensity information of a target lesion on CT scans in training segmentation and detection networks. We first build an intensity-based lesion probability (ILP) function from an intensity histogram of the target lesion. It is used to compute the probability of being the lesion for each voxel based on its intensity. Finally, the computed ILP map of each input CT scan is provided as additional supervision for network training, which aims to inform the network about possible lesion locations in terms of intensity values at no additional labeling cost. The method was applied to improve the segmentation of three different lesion types, namely, small bowel carcinoid tumor, kidney tumor, and lung nodule. The effectiveness of the proposed method on a detection task was also investigated. We observed improvements of 41.3% -> 47.8%, 74.2% -> 76.0%, and 26.4% -> 32.7% in segmenting small bowel carcinoid tumor, kidney tumor, and lung nodule, respectively, in terms of per case Dice scores. An improvement of 64.6% -> 75.5% was achieved in detecting kidney tumors in terms of average precision. The results of different usages of the ILP map and the effect of varied amount of training data are also presented.
Joint Radio Frequency Fingerprints Identification via Multi-antenna Receiver
Jul 11, 2023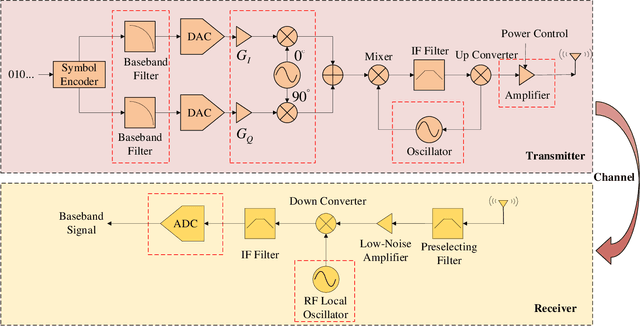
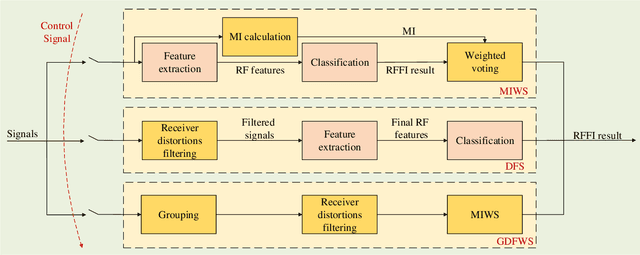
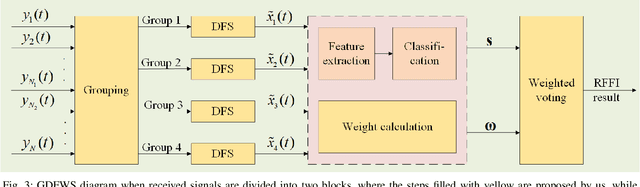
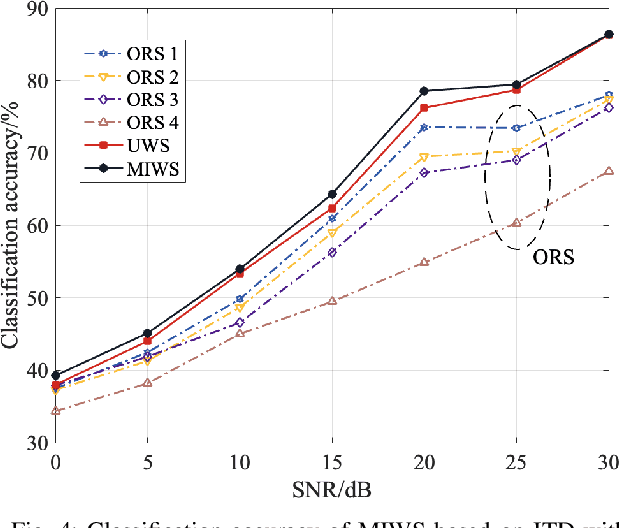
In Internet of Things (IoT), radio frequency fingerprints (RFF) technology has been widely used for passive security authentication to identify the special emitter. However, few works took advantage of independent oscillator distortions at the receiver side, and no work has yet considered filtering receiver distortions. In this paper, we investigate the RFF identification (RFFI) involving unknown receiver distortions, where the phase noise caused by each antenna oscillator is independent. Three RFF schemes are proposed according to the number of receiving antennas. When the number is small, the Mutual Information Weighting Scheme (MIWS) is developed by calculating the weighted voting of RFFI result at each antenna; when the number is moderate, the Distortions Filtering Scheme (DFS) is developed by filtering out the channel noise and receiver distortions; when the number is large enough, the Group-Distortions Filtering and Weighting Scheme (GDFWS) is developed, which integrates the advantages of MIWS and DFS. Furthermore, the ability of DFS to filter out the channel noise and receiver distortions is theoretically analyzed at a specific confidence level. Experiments are provided when both channel noise and receiver distortions exist, which verify the effectiveness and robustness of the proposed schemes.
PowerFusion: A Tensor Compiler with Explicit Data Movement Description and Instruction-level Graph IR
Jul 11, 2023
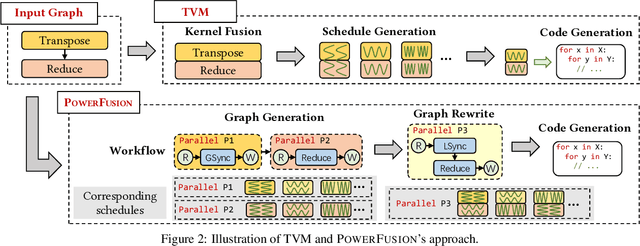
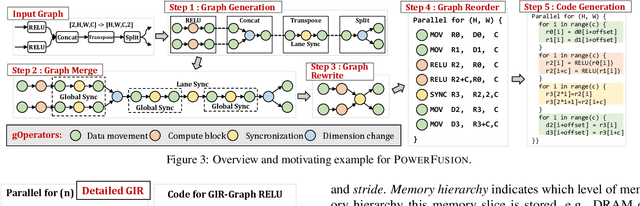
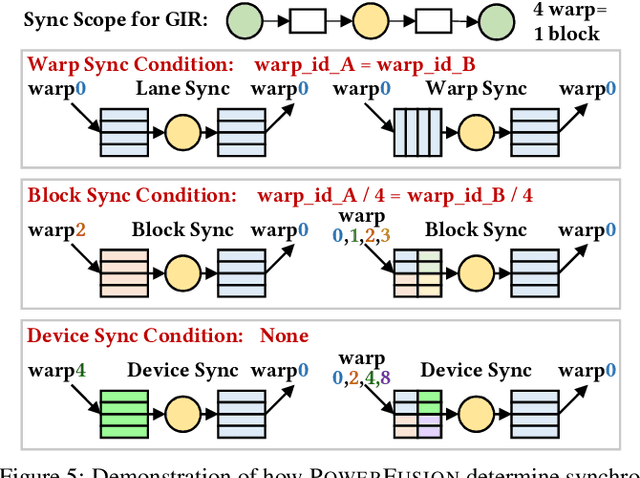
Deep neural networks (DNNs) are of critical use in different domains. To accelerate DNN computation, tensor compilers are proposed to generate efficient code on different domain-specific accelerators. Existing tensor compilers mainly focus on optimizing computation efficiency. However, memory access is becoming a key performance bottleneck because the computational performance of accelerators is increasing much faster than memory performance. The lack of direct description of memory access and data dependence in current tensor compilers' intermediate representation (IR) brings significant challenges to generate memory-efficient code. In this paper, we propose IntelliGen, a tensor compiler that can generate high-performance code for memory-intensive operators by considering both computation and data movement optimizations. IntelliGen represent a DNN program using GIR, which includes primitives indicating its computation, data movement, and parallel strategies. This information will be further composed as an instruction-level dataflow graph to perform holistic optimizations by searching different memory access patterns and computation operations, and generating memory-efficient code on different hardware. We evaluate IntelliGen on NVIDIA GPU, AMD GPU, and Cambricon MLU, showing speedup up to 1.97x, 2.93x, and 16.91x(1.28x, 1.23x, and 2.31x on average), respectively, compared to current most performant frameworks.
Super-resolution imaging through a multimode fiber: the physical upsampling of speckle-driven
Jul 11, 2023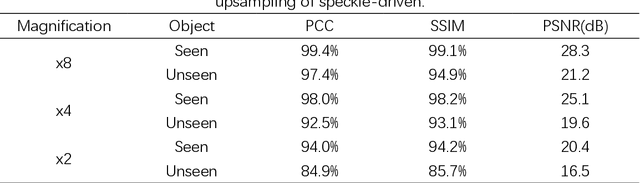
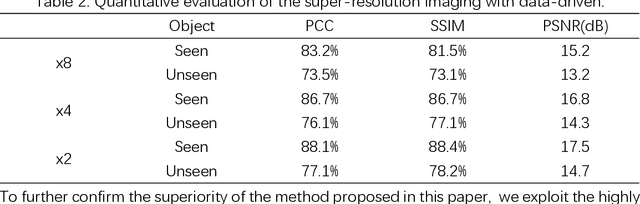
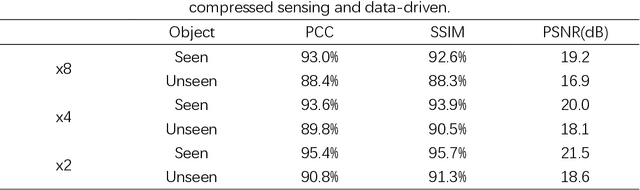
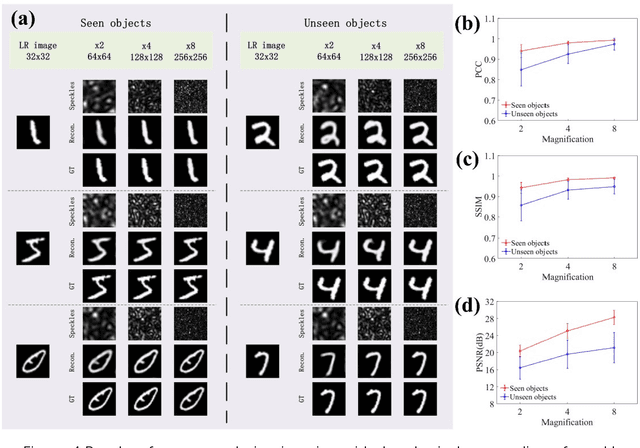
Following recent advancements in multimode fiber (MMF), miniaturization of imaging endoscopes has proven crucial for minimally invasive surgery in vivo. Recent progress enabled by super-resolution imaging methods with a data-driven deep learning (DL) framework has balanced the relationship between the core size and resolution. However, most of the DL approaches lack attention to the physical properties of the speckle, which is crucial for reconciling the relationship between the magnification of super-resolution imaging and the quality of reconstruction quality. In the paper, we find that the interferometric process of speckle formation is an essential basis for creating DL models with super-resolution imaging. It physically realizes the upsampling of low-resolution (LR) images and enhances the perceptual capabilities of the models. The finding experimentally validates the role played by the physical upsampling of speckle-driven, effectively complementing the lack of information in data-driven. Experimentally, we break the restriction of the poor reconstruction quality at great magnification by inputting the same size of the speckle with the size of the high-resolution (HR) image to the model. The guidance of our research for endoscopic imaging may accelerate the further development of minimally invasive surgery.
Transaction Fraud Detection via an Adaptive Graph Neural Network
Jul 11, 2023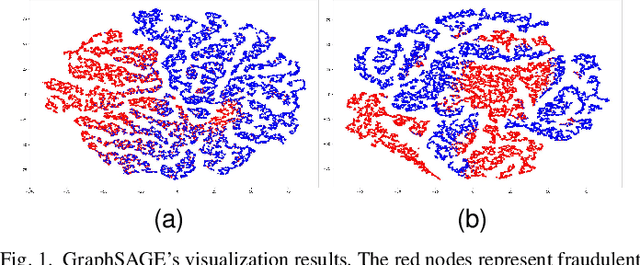
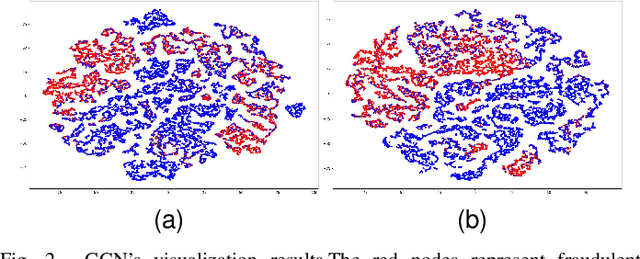
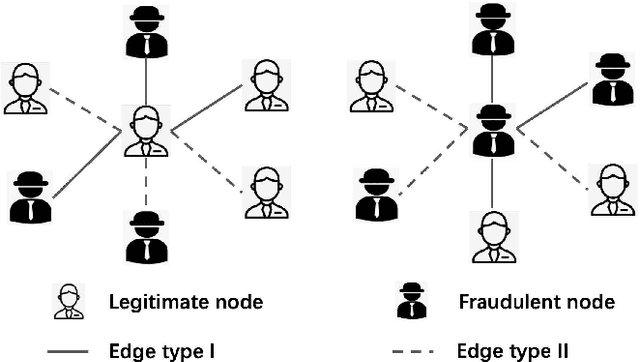
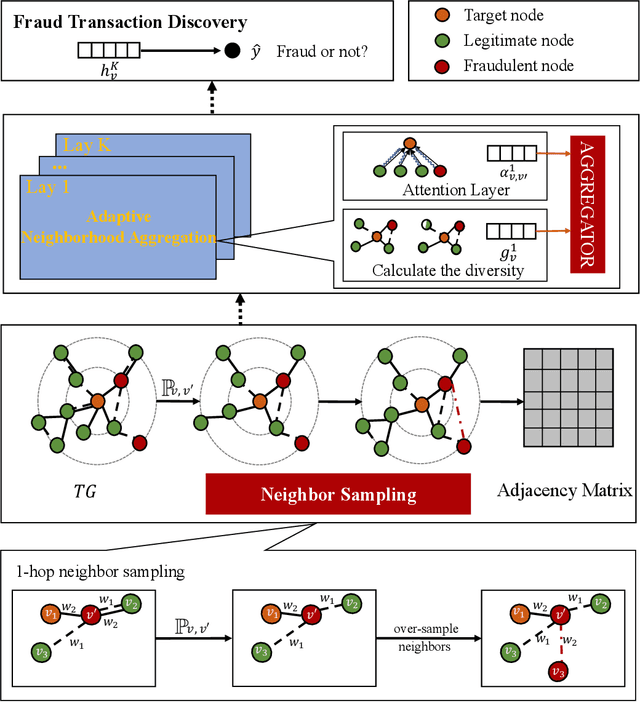
Many machine learning methods have been proposed to achieve accurate transaction fraud detection, which is essential to the financial security of individuals and banks. However, most existing methods leverage original features only or require manual feature engineering. They lack the ability to learn discriminative representations from transaction data. Moreover, criminals often commit fraud by imitating cardholders' behaviors, which causes the poor performance of existing detection models. In this paper, we propose an Adaptive Sampling and Aggregation-based Graph Neural Network (ASA-GNN) that learns discriminative representations to improve the performance of transaction fraud detection. A neighbor sampling strategy is performed to filter noisy nodes and supplement information for fraudulent nodes. Specifically, we leverage cosine similarity and edge weights to adaptively select neighbors with similar behavior patterns for target nodes and then find multi-hop neighbors for fraudulent nodes. A neighbor diversity metric is designed by calculating the entropy among neighbors to tackle the camouflage issue of fraudsters and explicitly alleviate the over-smoothing phenomena. Extensive experiments on three real financial datasets demonstrate that the proposed method ASA-GNN outperforms state-of-the-art ones.
Semantic-Aware Image Compressed Sensing
Jul 11, 2023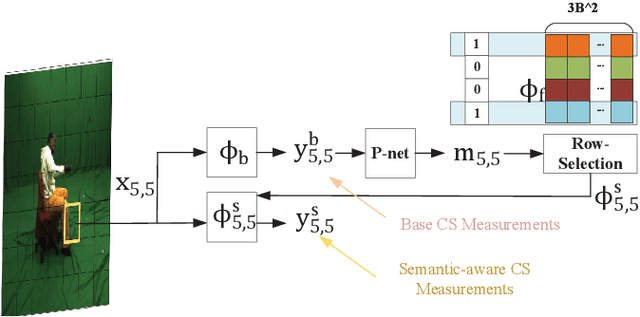
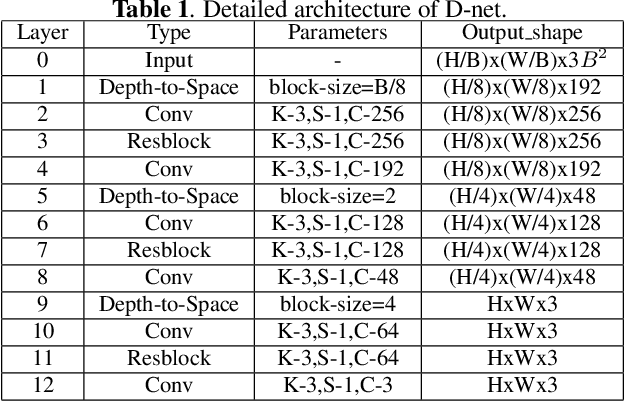
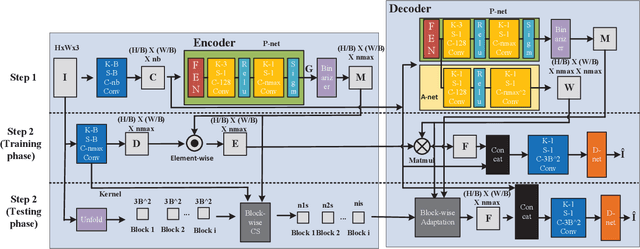
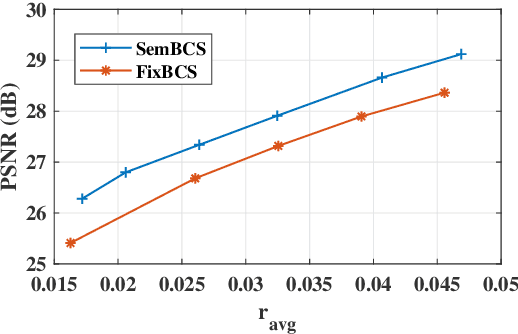
Deep learning based image compressed sensing (CS) has achieved great success. However, existing CS systems mainly adopt a fixed measurement matrix to images, ignoring the fact the optimal measurement numbers and bases are different for different images. To further improve the sensing efficiency, we propose a novel semantic-aware image CS system. In our system, the encoder first uses a fixed number of base CS measurements to sense different images. According to the base CS results, the encoder then employs a policy network to analyze the semantic information in images and determines the measurement matrix for different image areas. At the decoder side, a semantic-aware initial reconstruction network is developed to deal with the changes of measurement matrices used at the encoder. A rate-distortion training loss is further introduced to dynamically adjust the average compression ratio for the semantic-aware CS system and the policy network is trained jointly with the encoder and the decoder in an en-to-end manner by using some proxy functions. Numerical results show that the proposed semantic-aware image CS system is superior to the traditional ones with fixed measurement matrices.
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
Jul 12, 2023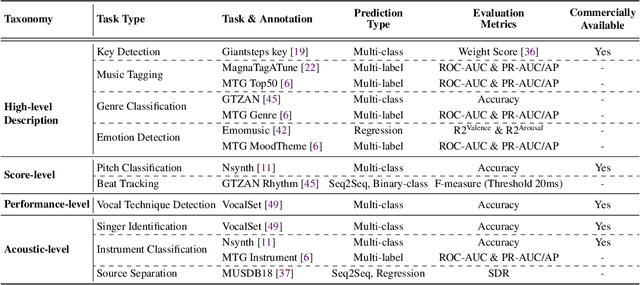
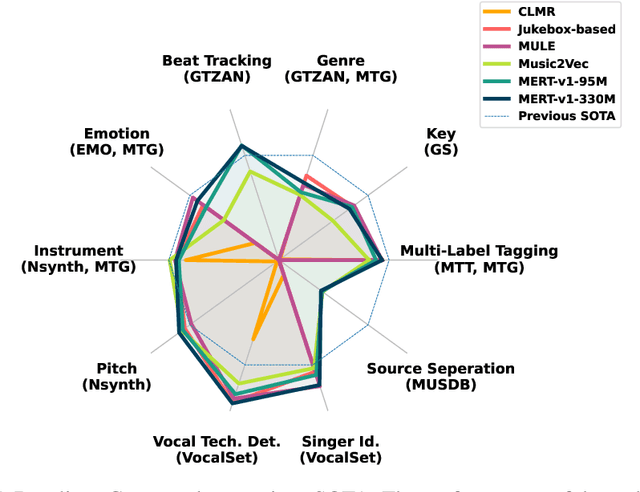
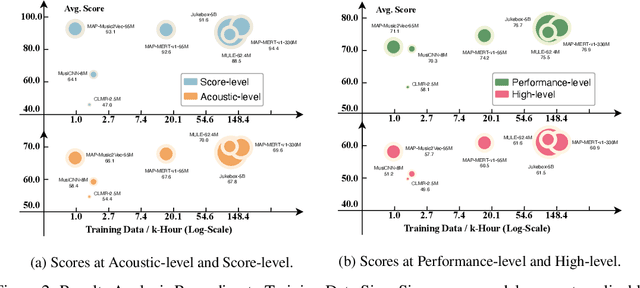
In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.
Distilling Large Language Models for Biomedical Knowledge Extraction: A Case Study on Adverse Drug Events
Jul 12, 2023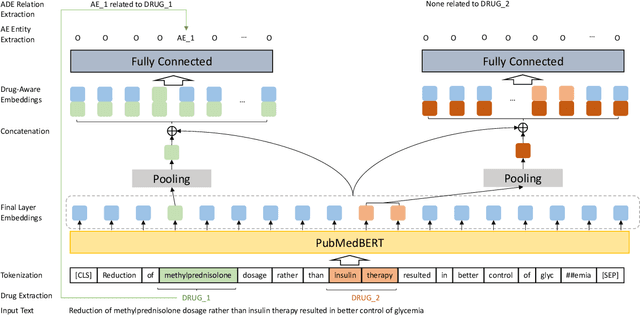
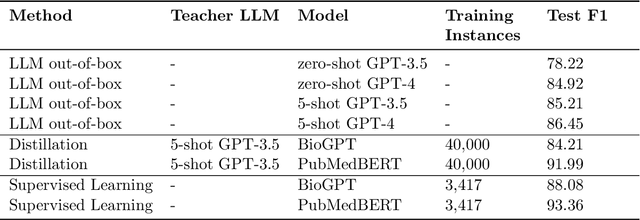
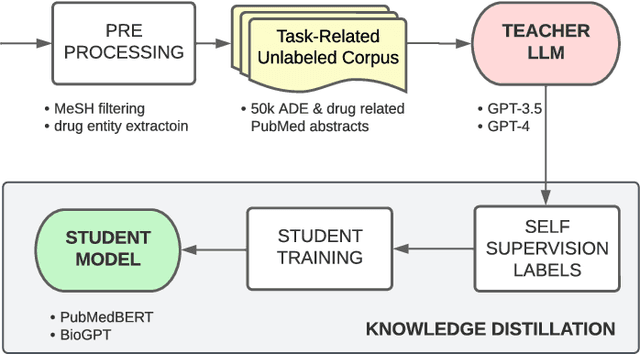
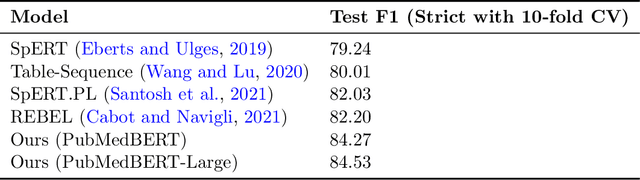
Large language models (LLMs), such as GPT-4, have demonstrated remarkable capabilities across a wide range of tasks, including health applications. In this paper, we study how LLMs can be used to scale biomedical knowledge curation. We find that while LLMs already possess decent competency in structuring biomedical text, by distillation into a task-specific student model through self-supervised learning, substantial gains can be attained over out-of-box LLMs, with additional advantages such as cost, efficiency, and white-box model access. We conduct a case study on adverse drug event (ADE) extraction, which is an important area for improving care. On standard ADE extraction evaluation, a GPT-3.5 distilled PubMedBERT model attained comparable accuracy as supervised state-of-the-art models without using any labeled data. Despite being over 1,000 times smaller, the distilled model outperformed its teacher GPT-3.5 by over 6 absolute points in F1 and GPT-4 by over 5 absolute points. Ablation studies on distillation model choice (e.g., PubMedBERT vs BioGPT) and ADE extraction architecture shed light on best practice for biomedical knowledge extraction. Similar gains were attained by distillation for other standard biomedical knowledge extraction tasks such as gene-disease associations and protected health information, further illustrating the promise of this approach.
Navigating Uncertainty: The Role of Short-Term Trajectory Prediction in Autonomous Vehicle Safety
Jul 12, 2023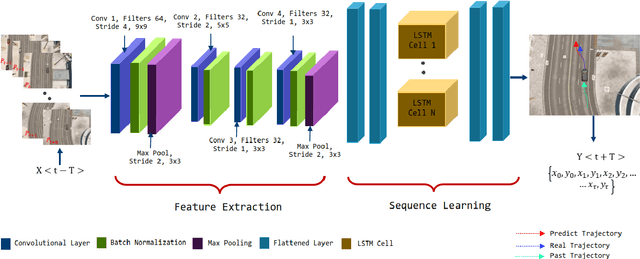
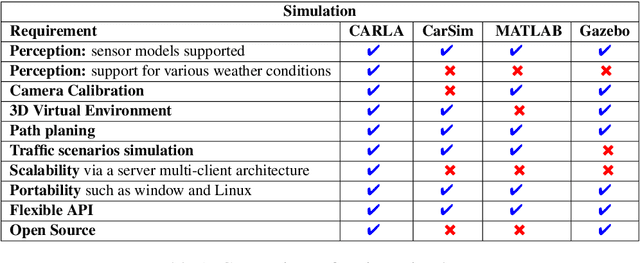
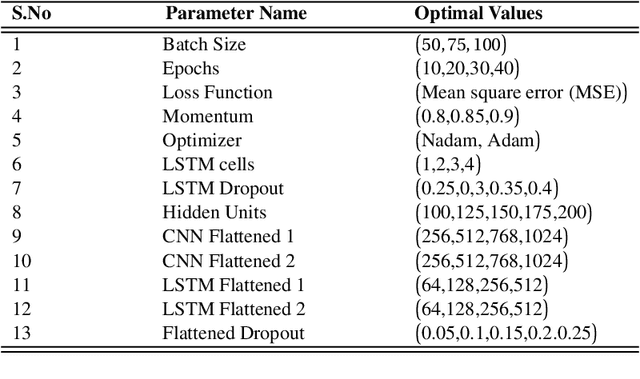
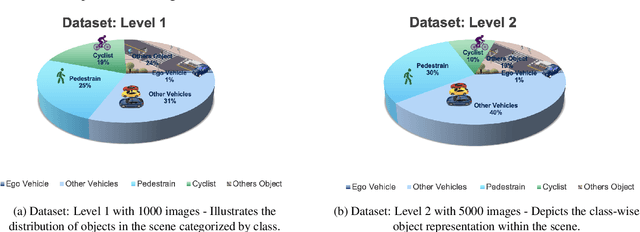
Autonomous vehicles require accurate and reliable short-term trajectory predictions for safe and efficient driving. While most commercial automated vehicles currently use state machine-based algorithms for trajectory forecasting, recent efforts have focused on end-to-end data-driven systems. Often, the design of these models is limited by the availability of datasets, which are typically restricted to generic scenarios. To address this limitation, we have developed a synthetic dataset for short-term trajectory prediction tasks using the CARLA simulator. This dataset is extensive and incorporates what is considered complex scenarios - pedestrians crossing the road, vehicles overtaking - and comprises 6000 perspective view images with corresponding IMU and odometry information for each frame. Furthermore, an end-to-end short-term trajectory prediction model using convolutional neural networks (CNN) and long short-term memory (LSTM) networks has also been developed. This model can handle corner cases, such as slowing down near zebra crossings and stopping when pedestrians cross the road, without the need for explicit encoding of the surrounding environment. In an effort to accelerate this research and assist others, we are releasing our dataset and model to the research community. Our datasets are publicly available on https://github.com/sharmasushil/Navigating-Uncertainty-Trajectory-Prediction .