 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Spatial-Temporal Aggregation for Skeleton-Aware Sign Language Recognition
Mar 19, 2024
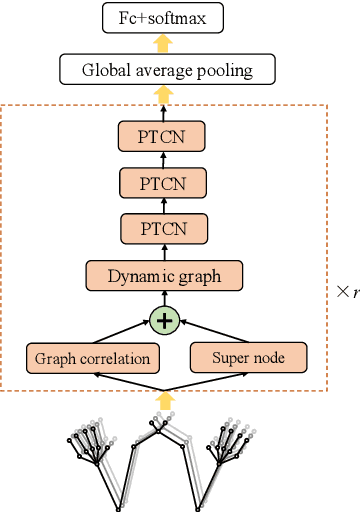
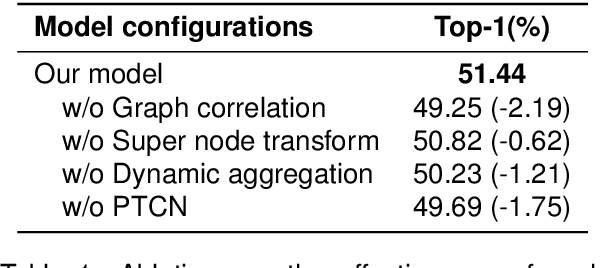
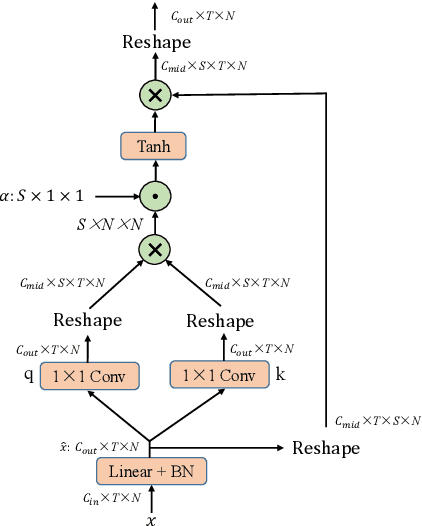

Skeleton-aware sign language recognition (SLR) has gained popularity due to its ability to remain unaffected by background information and its lower computational requirements. Current methods utilize spatial graph modules and temporal modules to capture spatial and temporal features, respectively. However, their spatial graph modules are typically built on fixed graph structures such as graph convolutional networks or a single learnable graph, which only partially explore joint relationships. Additionally, a simple temporal convolution kernel is used to capture temporal information, which may not fully capture the complex movement patterns of different signers. To overcome these limitations, we propose a new spatial architecture consisting of two concurrent branches, which build input-sensitive joint relationships and incorporates specific domain knowledge for recognition, respectively. These two branches are followed by an aggregation process to distinguishe important joint connections. We then propose a new temporal module to model multi-scale temporal information to capture complex human dynamics. Our method achieves state-of-the-art accuracy compared to previous skeleton-aware methods on four large-scale SLR benchmarks. Moreover, our method demonstrates superior accuracy compared to RGB-based methods in most cases while requiring much fewer computational resources, bringing better accuracy-computation trade-off. Code is available at https://github.com/hulianyuyy/DSTA-SLR.
Task-Customized Mixture of Adapters for General Image Fusion
Mar 19, 2024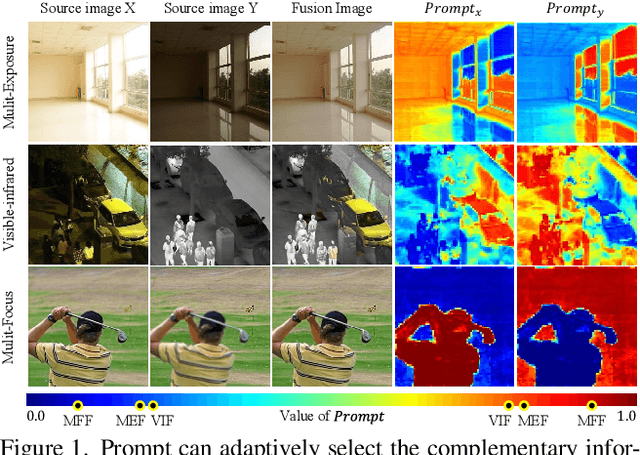
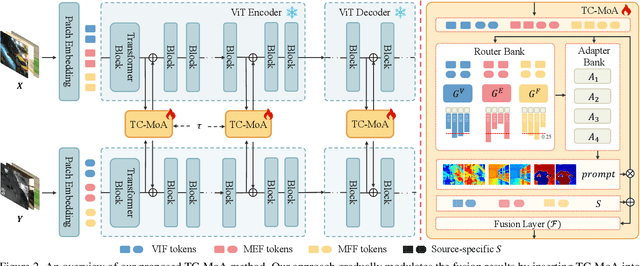
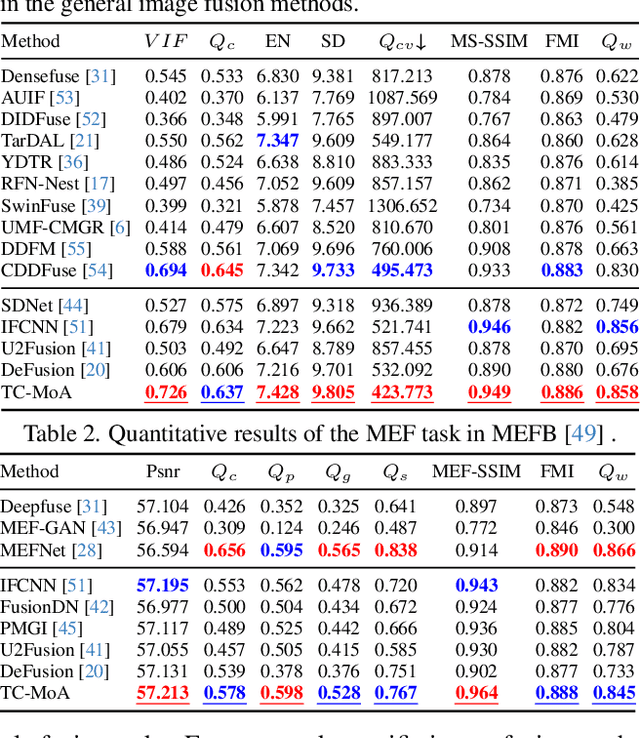

General image fusion aims at integrating important information from multi-source images. However, due to the significant cross-task gap, the respective fusion mechanism varies considerably in practice, resulting in limited performance across subtasks. To handle this problem, we propose a novel task-customized mixture of adapters (TC-MoA) for general image fusion, adaptively prompting various fusion tasks in a unified model. We borrow the insight from the mixture of experts (MoE), taking the experts as efficient tuning adapters to prompt a pre-trained foundation model. These adapters are shared across different tasks and constrained by mutual information regularization, ensuring compatibility with different tasks while complementarity for multi-source images. The task-specific routing networks customize these adapters to extract task-specific information from different sources with dynamic dominant intensity, performing adaptive visual feature prompt fusion. Notably, our TC-MoA controls the dominant intensity bias for different fusion tasks, successfully unifying multiple fusion tasks in a single model. Extensive experiments show that TC-MoA outperforms the competing approaches in learning commonalities while retaining compatibility for general image fusion (multi-modal, multi-exposure, and multi-focus), and also demonstrating striking controllability on more generalization experiments. The code is available at https://github.com/YangSun22/TC-MoA .
PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency
Mar 18, 2024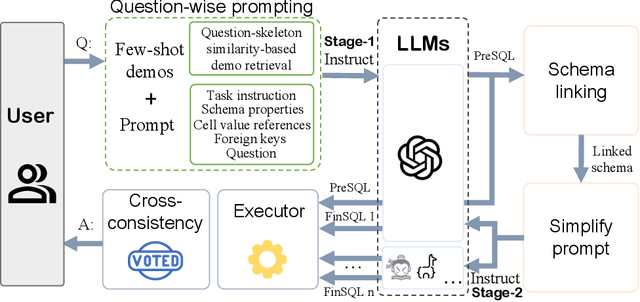

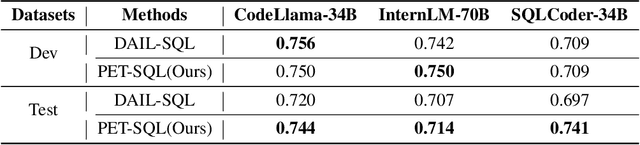
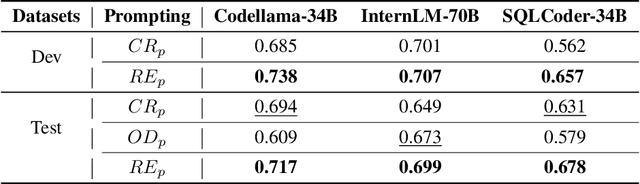
Recent advancements in Text-to-SQL (Text2SQL) emphasize stimulating the large language models (LLM) on in-context learning, achieving significant results. Nevertheless, they face challenges when dealing with verbose database information and complex user intentions. This paper presents a two-stage framework to enhance the performance of current LLM-based natural language to SQL systems. We first introduce a novel prompt representation, called reference-enhanced representation, which includes schema information and randomly sampled cell values from tables to instruct LLMs in generating SQL queries. Then, in the first stage, question-SQL pairs are retrieved as few-shot demonstrations, prompting the LLM to generate a preliminary SQL (PreSQL). After that, the mentioned entities in PreSQL are parsed to conduct schema linking, which can significantly compact the useful information. In the second stage, with the linked schema, we simplify the prompt's schema information and instruct the LLM to produce the final SQL. Finally, as the post-refinement module, we propose using cross-consistency across different LLMs rather than self-consistency within a particular LLM. Our methods achieve new SOTA results on the Spider benchmark, with an execution accuracy of 87.6%.
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Feb 29, 2024Today's deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth. Meanwhile, an appropriate architecture that can facilitate acquisition of enough information for prediction has to be designed. Existing methods ignore a fact that when input data undergoes layer-by-layer feature extraction and spatial transformation, large amount of information will be lost. This paper will delve into the important issues of data loss when data is transmitted through deep networks, namely information bottleneck and reversible functions. We proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple objectives. PGI can provide complete input information for the target task to calculate objective function, so that reliable gradient information can be obtained to update network weights. In addition, a new lightweight network architecture -- Generalized Efficient Layer Aggregation Network (GELAN), based on gradient path planning is designed. GELAN's architecture confirms that PGI has gained superior results on lightweight models. We verified the proposed GELAN and PGI on MS COCO dataset based object detection. The results show that GELAN only uses conventional convolution operators to achieve better parameter utilization than the state-of-the-art methods developed based on depth-wise convolution. PGI can be used for variety of models from lightweight to large. It can be used to obtain complete information, so that train-from-scratch models can achieve better results than state-of-the-art models pre-trained using large datasets, the comparison results are shown in Figure 1. The source codes are at: https://github.com/WongKinYiu/yolov9.
Overview of Publicly Available Degradation Data Sets for Tasks within Prognostics and Health Management
Mar 20, 2024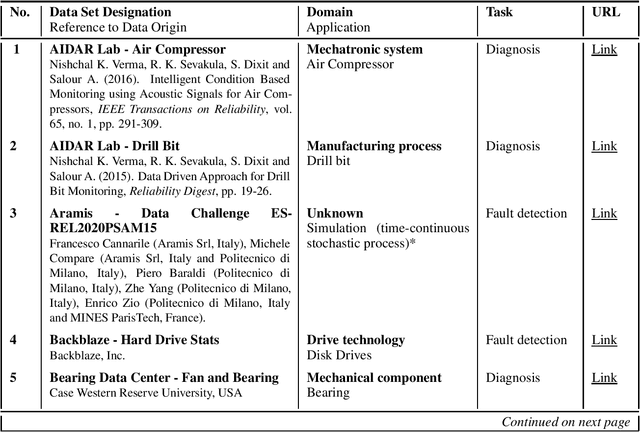
Central to the efficacy of prognostics and health management methods is the acquisition and analysis of degradation data, which encapsulates the evolving health condition of engineering systems over time. Degradation data serves as a rich source of information, offering invaluable insights into the underlying degradation processes, failure modes, and performance trends of engineering systems. This paper provides an overview of publicly available degradation data sets.
Parametric Encoding with Attention and Convolution Mitigate Spectral Bias of Neural Partial Differential Equation Solvers
Mar 22, 2024Deep neural networks (DNNs) are increasingly used to solve partial differential equations (PDEs) that naturally arise while modeling a wide range of systems and physical phenomena. However, the accuracy of such DNNs decreases as the PDE complexity increases and they also suffer from spectral bias as they tend to learn the low-frequency solution characteristics. To address these issues, we introduce Parametric Grid Convolutional Attention Networks (PGCANs) that can solve PDE systems without leveraging any labeled data in the domain. The main idea of PGCAN is to parameterize the input space with a grid-based encoder whose parameters are connected to the output via a DNN decoder that leverages attention to prioritize feature training. Our encoder provides a localized learning ability and uses convolution layers to avoid overfitting and improve information propagation rate from the boundaries to the interior of the domain. We test the performance of PGCAN on a wide range of PDE systems and show that it effectively addresses spectral bias and provides more accurate solutions compared to competing methods.
RetiGen: A Framework for Generalized Retinal Diagnosis Using Multi-View Fundus Images
Mar 22, 2024This study introduces a novel framework for enhancing domain generalization in medical imaging, specifically focusing on utilizing unlabelled multi-view colour fundus photographs. Unlike traditional approaches that rely on single-view imaging data and face challenges in generalizing across diverse clinical settings, our method leverages the rich information in the unlabelled multi-view imaging data to improve model robustness and accuracy. By incorporating a class balancing method, a test-time adaptation technique and a multi-view optimization strategy, we address the critical issue of domain shift that often hampers the performance of machine learning models in real-world applications. Experiments comparing various state-of-the-art domain generalization and test-time optimization methodologies show that our approach consistently outperforms when combined with existing baseline and state-of-the-art methods. We also show our online method improves all existing techniques. Our framework demonstrates improvements in domain generalization capabilities and offers a practical solution for real-world deployment by facilitating online adaptation to new, unseen datasets. Our code is available at https://github.com/zgy600/RetiGen .
Investigating Use Cases of AI-Powered Scene Description Applications for Blind and Low Vision People
Mar 22, 2024"Scene description" applications that describe visual content in a photo are useful daily tools for blind and low vision (BLV) people. Researchers have studied their use, but they have only explored those that leverage remote sighted assistants; little is known about applications that use AI to generate their descriptions. Thus, to investigate their use cases, we conducted a two-week diary study where 16 BLV participants used an AI-powered scene description application we designed. Through their diary entries and follow-up interviews, users shared their information goals and assessments of the visual descriptions they received. We analyzed the entries and found frequent use cases, such as identifying visual features of known objects, and surprising ones, such as avoiding contact with dangerous objects. We also found users scored the descriptions relatively low on average, 2.76 out of 5 (SD=1.49) for satisfaction and 2.43 out of 4 (SD=1.16) for trust, showing that descriptions still need significant improvements to deliver satisfying and trustworthy experiences. We discuss future opportunities for AI as it becomes a more powerful accessibility tool for BLV users.
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
Mar 22, 2024We introduce InternVideo2, a new video foundation model (ViFM) that achieves the state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue. Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction. Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text. We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks. Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts. Code and models are available at https://github.com/OpenGVLab/InternVideo2/.
CoLLEGe: Concept Embedding Generation for Large Language Models
Mar 22, 2024Current language models are unable to quickly learn new concepts on the fly, often requiring a more involved finetuning process to learn robustly. Prompting in-context is not robust to context distractions, and often fails to confer much information about the new concepts. Classic methods for few-shot word learning in NLP, relying on global word vectors, are less applicable to large language models. In this paper, we introduce a novel approach named CoLLEGe (Concept Learning with Language Embedding Generation) to modernize few-shot concept learning. CoLLEGe is a meta-learning framework capable of generating flexible embeddings for new concepts using a small number of example sentences or definitions. Our primary meta-learning objective is simply to facilitate a language model to make next word predictions in forthcoming sentences, making it compatible with language model pretraining. We design a series of tasks to test new concept learning in challenging real-world scenarios, including new word acquisition, definition inference, and verbal reasoning, and demonstrate that our method succeeds in each setting without task-specific training.