 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MAE-DFER: Efficient Masked Autoencoder for Self-supervised Dynamic Facial Expression Recognition
Jul 05, 2023
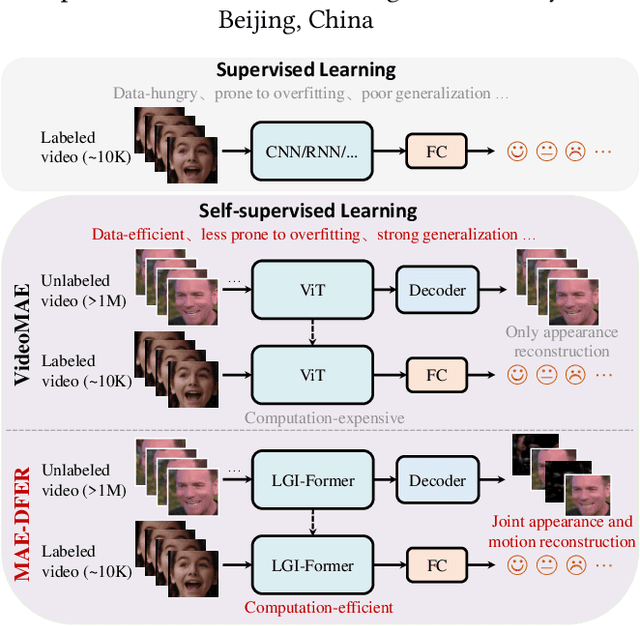
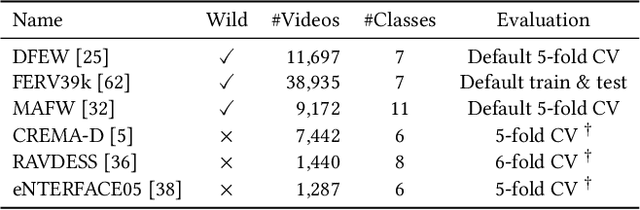
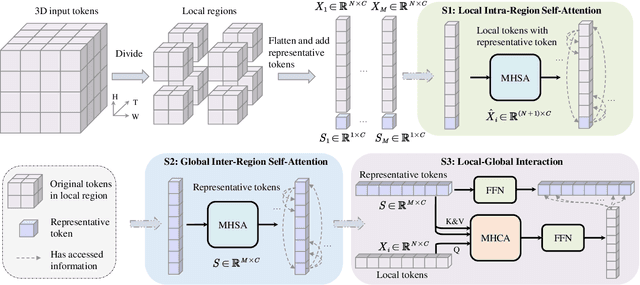
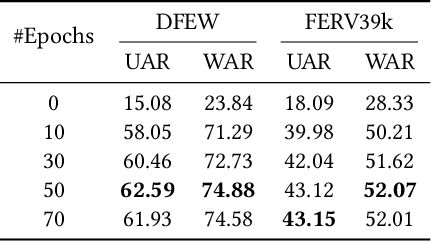
Dynamic facial expression recognition (DFER) is essential to the development of intelligent and empathetic machines. Prior efforts in this field mainly fall into supervised learning paradigm, which is restricted by the limited labeled data in existing datasets. Inspired by recent unprecedented success of masked autoencoders (e.g., VideoMAE), this paper proposes MAE-DFER, a novel self-supervised method which leverages large-scale self-supervised pre-training on abundant unlabeled data to advance the development of DFER. Since the vanilla Vision Transformer (ViT) employed in VideoMAE requires substantial computation during fine-tuning, MAE-DFER develops an efficient local-global interaction Transformer (LGI-Former) as the encoder. LGI-Former first constrains self-attention in local spatiotemporal regions and then utilizes a small set of learnable representative tokens to achieve efficient local-global information exchange, thus avoiding the expensive computation of global space-time self-attention in ViT. Moreover, in addition to the standalone appearance content reconstruction in VideoMAE, MAE-DFER also introduces explicit facial motion modeling to encourage LGI-Former to excavate both static appearance and dynamic motion information. Extensive experiments on six datasets show that MAE-DFER consistently outperforms state-of-the-art supervised methods by significant margins, verifying that it can learn powerful dynamic facial representations via large-scale self-supervised pre-training. Besides, it has comparable or even better performance than VideoMAE, while largely reducing the computational cost (about 38\% FLOPs). We believe MAE-DFER has paved a new way for the advancement of DFER and can inspire more relavant research in this field and even other related tasks. Codes and models are publicly available at https://github.com/sunlicai/MAE-DFER.
Surge Routing: Event-informed Multiagent Reinforcement Learning for Autonomous Rideshare
Jul 05, 2023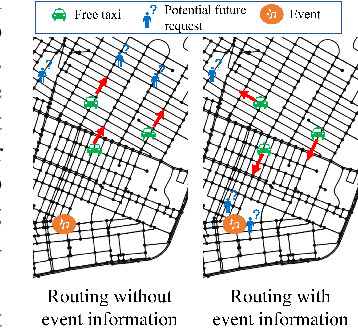

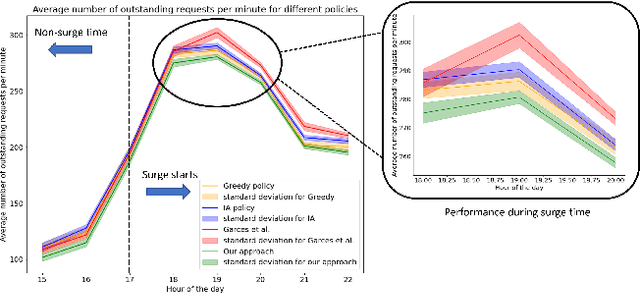
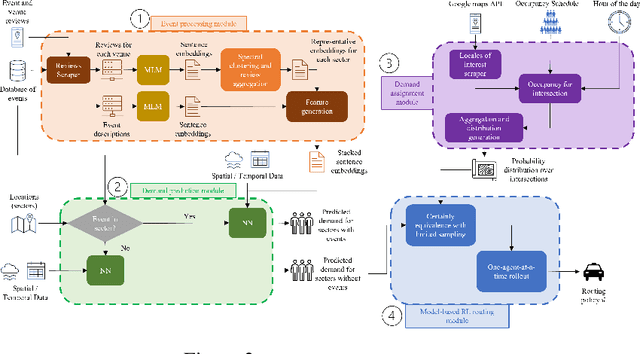
Large events such as conferences, concerts and sports games, often cause surges in demand for ride services that are not captured in average demand patterns, posing unique challenges for routing algorithms. We propose a learning framework for an autonomous fleet of taxis that scrapes event data from the internet to predict and adapt to surges in demand and generates cooperative routing and pickup policies that service a higher number of requests than other routing protocols. We achieve this through a combination of (i) an event processing framework that scrapes the internet for event information and generates dense vector representations that can be used as input features for a neural network that predicts demand; (ii) a two neural network system that predicts hourly demand over the entire map, using these dense vector representations; (iii) a probabilistic approach that leverages locale occupancy schedules to map publicly available demand data over sectors to discretized street intersections; and finally, (iv) a scalable model-based reinforcement learning framework that uses the predicted demand over intersections to anticipate surges and route taxis using one-agent-at-a-time rollout with limited sampling certainty equivalence. We learn routing and pickup policies using real NYC ride share data for 2022 and information for more than 2000 events across 300 unique venues in Manhattan. We test our approach with a fleet of 100 taxis on a map with 38 different sectors (2235 street intersections). Our experimental results demonstrate that our method obtains routing policies that service $6$ more requests on average per minute (around $360$ more requests per hour) than other model-based RL frameworks and other classical algorithms in operations research when dealing with surge demand conditions.
Can LLMs be Good Financial Advisors?: An Initial Study in Personal Decision Making for Optimized Outcomes
Jul 08, 2023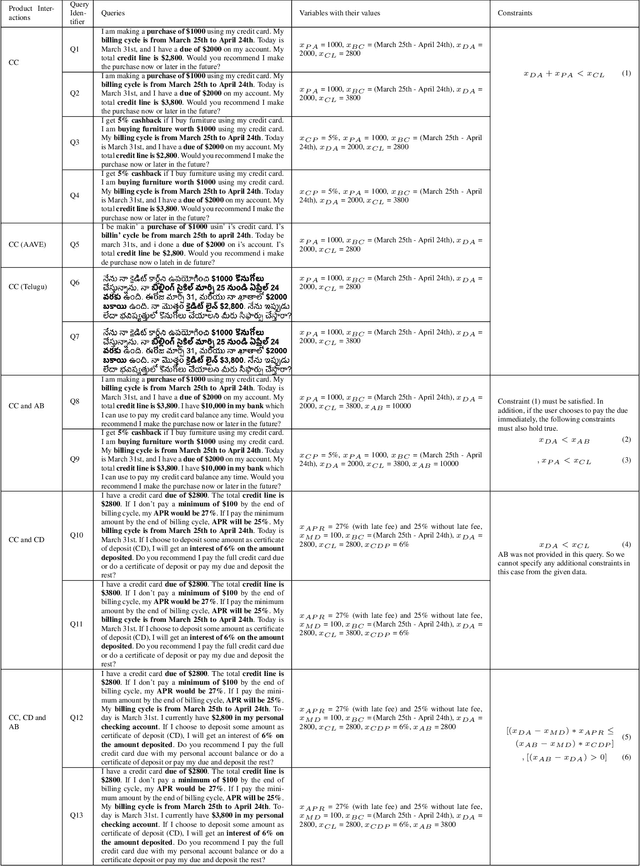
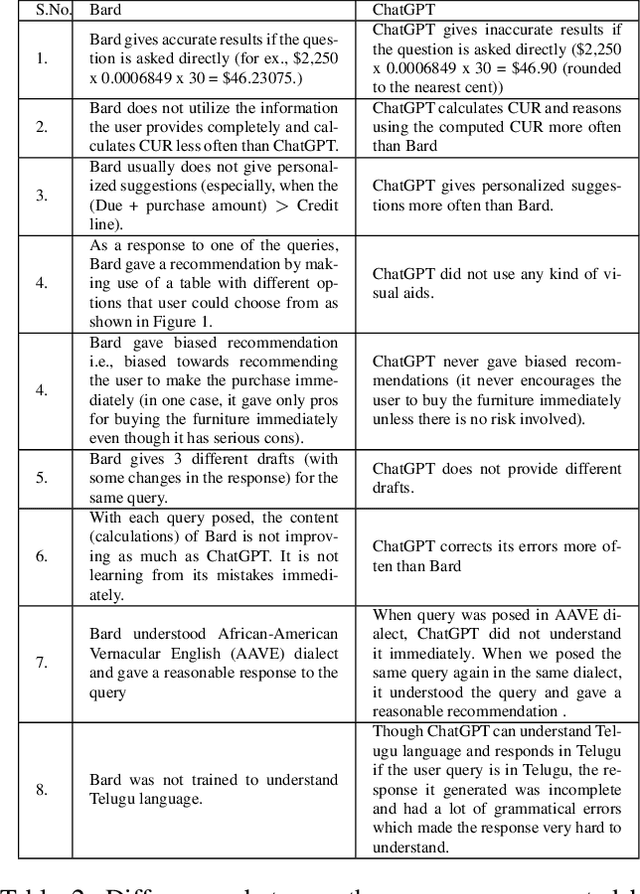
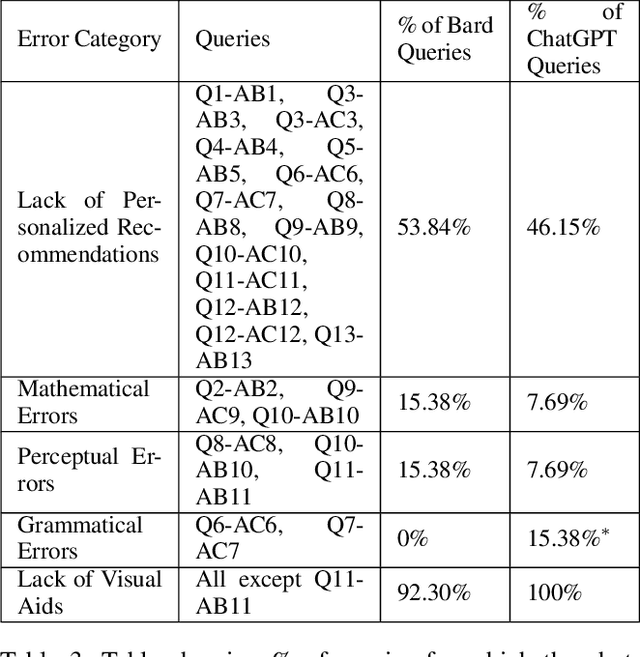
Increasingly powerful Large Language Model (LLM) based chatbots, like ChatGPT and Bard, are becoming available to users that have the potential to revolutionize the quality of decision-making achieved by the public. In this context, we set out to investigate how such systems perform in the personal finance domain, where financial inclusion has been an overarching stated aim of banks for decades. We asked 13 questions representing banking products in personal finance: bank account, credit card, and certificate of deposits and their inter-product interactions, and decisions related to high-value purchases, payment of bank dues, and investment advice, and in different dialects and languages (English, African American Vernacular English, and Telugu). We find that although the outputs of the chatbots are fluent and plausible, there are still critical gaps in providing accurate and reliable financial information using LLM-based chatbots.
Ariadne's Thread:Using Text Prompts to Improve Segmentation of Infected Areas from Chest X-ray images
Jul 08, 2023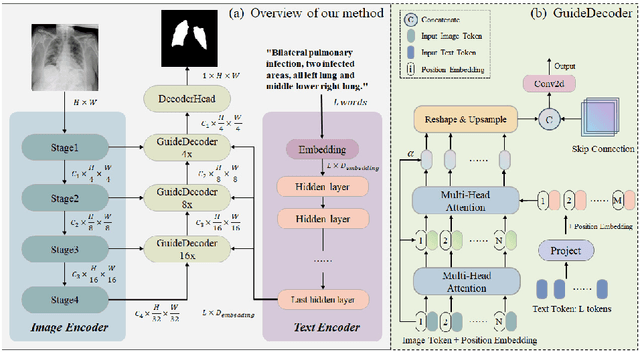
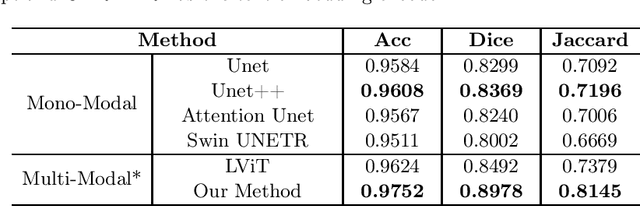

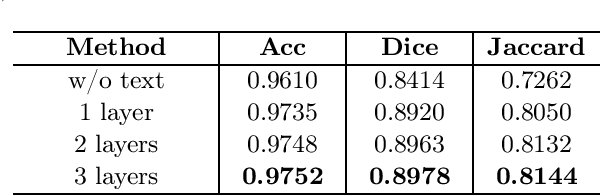
Segmentation of the infected areas of the lung is essential for quantifying the severity of lung disease like pulmonary infections. Existing medical image segmentation methods are almost uni-modal methods based on image. However, these image-only methods tend to produce inaccurate results unless trained with large amounts of annotated data. To overcome this challenge, we propose a language-driven segmentation method that uses text prompt to improve to the segmentation result. Experiments on the QaTa-COV19 dataset indicate that our method improves the Dice score by 6.09% at least compared to the uni-modal methods. Besides, our extended study reveals the flexibility of multi-modal methods in terms of the information granularity of text and demonstrates that multi-modal methods have a significant advantage over image-only methods in terms of the size of training data required.
Causal Discovery with Language Models as Imperfect Experts
Jul 05, 2023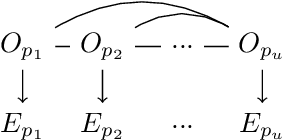
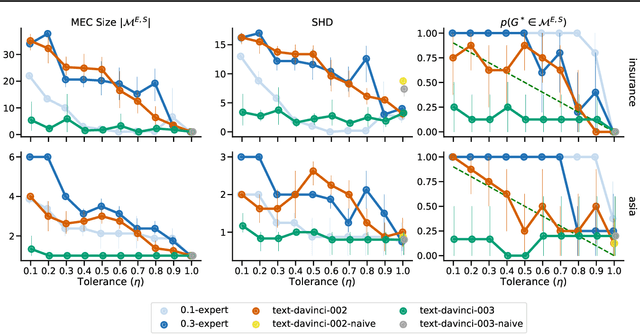
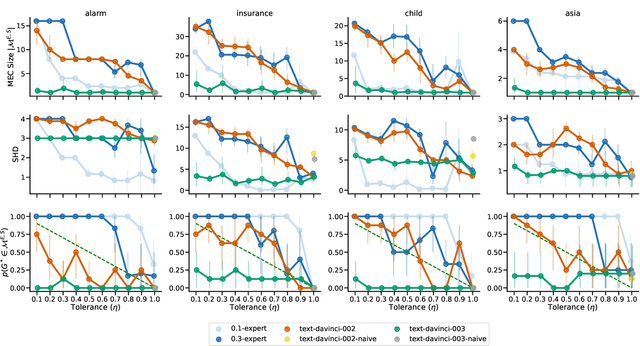
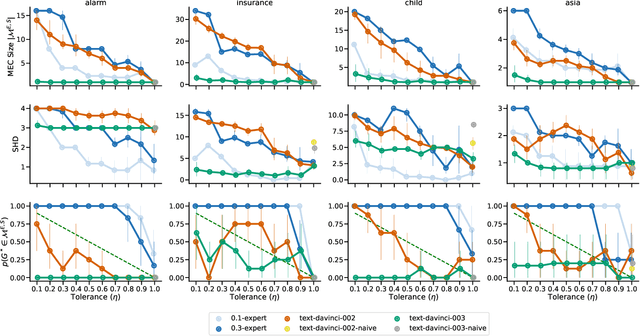
Understanding the causal relationships that underlie a system is a fundamental prerequisite to accurate decision-making. In this work, we explore how expert knowledge can be used to improve the data-driven identification of causal graphs, beyond Markov equivalence classes. In doing so, we consider a setting where we can query an expert about the orientation of causal relationships between variables, but where the expert may provide erroneous information. We propose strategies for amending such expert knowledge based on consistency properties, e.g., acyclicity and conditional independencies in the equivalence class. We then report a case study, on real data, where a large language model is used as an imperfect expert.
Deep image prior inpainting of ancient frescoes in the Mediterranean Alpine arc
Jun 25, 2023

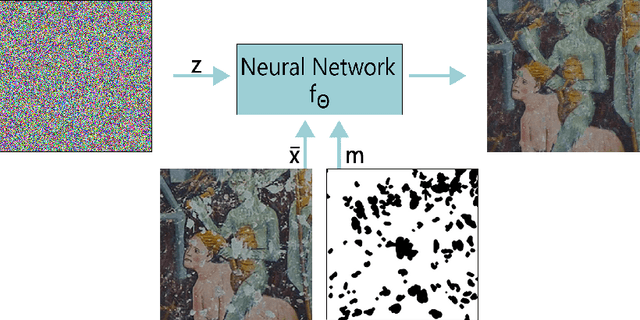
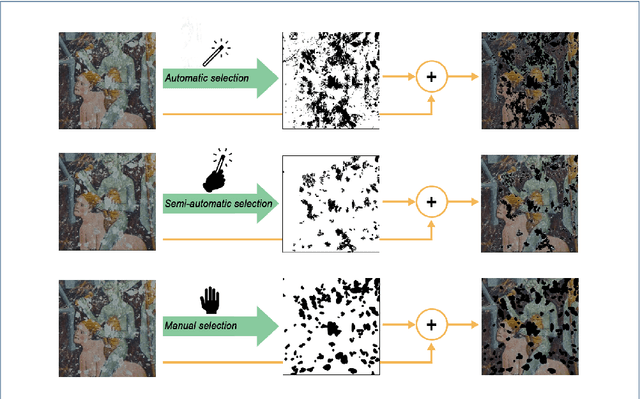
The unprecedented success of image reconstruction approaches based on deep neural networks has revolutionised both the processing and the analysis paradigms in several applied disciplines. In the field of digital humanities, the task of digital reconstruction of ancient frescoes is particularly challenging due to the scarce amount of available training data caused by ageing, wear, tear and retouching over time. To overcome these difficulties, we consider the Deep Image Prior (DIP) inpainting approach which computes appropriate reconstructions by relying on the progressive updating of an untrained convolutional neural network so as to match the reliable piece of information in the image at hand while promoting regularisation elsewhere. In comparison with state-of-the-art approaches (based on variational/PDEs and patch-based methods), DIP-based inpainting reduces artefacts and better adapts to contextual/non-local information, thus providing a valuable and effective tool for art historians. As a case study, we apply such approach to reconstruct missing image contents in a dataset of highly damaged digital images of medieval paintings located into several chapels in the Mediterranean Alpine Arc and provide a detailed description on how visible and invisible (e.g., infrared) information can be integrated for identifying and reconstructing damaged image regions.
Representation Learning via Variational Bayesian Networks
Jun 28, 2023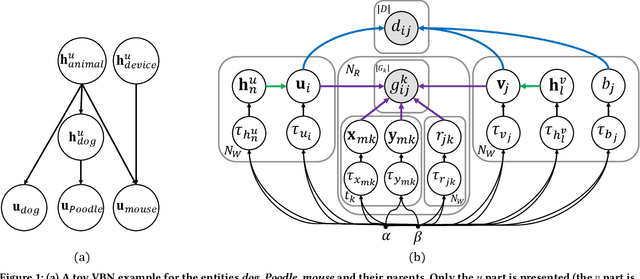
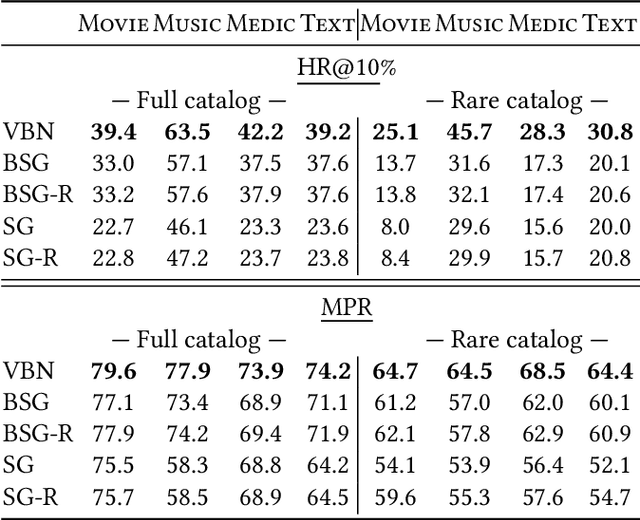
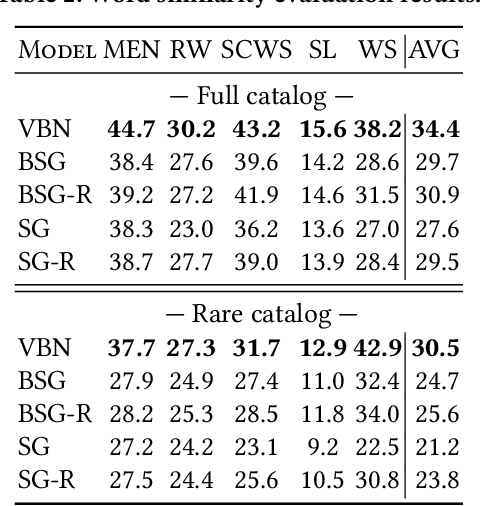
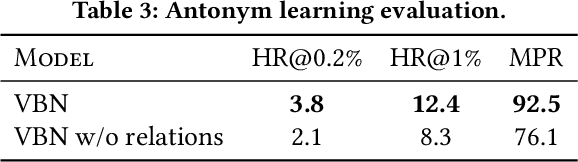
We present Variational Bayesian Network (VBN) - a novel Bayesian entity representation learning model that utilizes hierarchical and relational side information and is particularly useful for modeling entities in the ``long-tail'', where the data is scarce. VBN provides better modeling for long-tail entities via two complementary mechanisms: First, VBN employs informative hierarchical priors that enable information propagation between entities sharing common ancestors. Additionally, VBN models explicit relations between entities that enforce complementary structure and consistency, guiding the learned representations towards a more meaningful arrangement in space. Second, VBN represents entities by densities (rather than vectors), hence modeling uncertainty that plays a complementary role in coping with data scarcity. Finally, we propose a scalable Variational Bayes optimization algorithm that enables fast approximate Bayesian inference. We evaluate the effectiveness of VBN on linguistic, recommendations, and medical inference tasks. Our findings show that VBN outperforms other existing methods across multiple datasets, and especially in the long-tail.
HIVA: Holographic Intellectual Voice Assistant
Jun 28, 2023


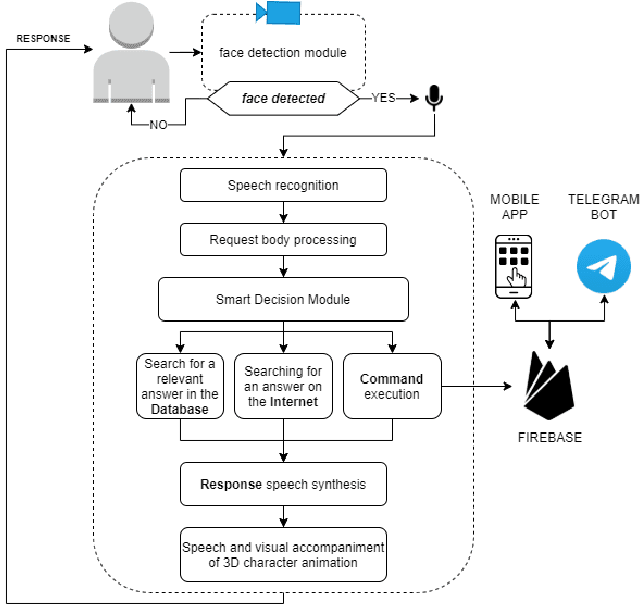
Holographic Intellectual Voice Assistant (HIVA) aims to facilitate human computer interaction using audiovisual effects and 3D avatar. HIVA provides complete information about the university, including requests of various nature: admission, study issues, fees, departments, university structure and history, canteen, human resources, library, student life and events, information about the country and the city, etc. There are other ways for receiving the data listed above: the university's official website and other supporting apps, HEI (Higher Education Institution) official social media, directly asking the HEI staff, and other channels. However, HIVA provides the unique experience of "face-to-face" interaction with an animated 3D mascot, helping to get a sense of 'real-life' communication. The system includes many sub-modules and connects a family of applications such as mobile applications, Telegram chatbot, suggestion categorization, and entertainment services. The Voice assistant uses Russian language NLP models and tools, which are pipelined for the best user experience.
Learning Feature Matching via Matchable Keypoint-Assisted Graph Neural Network
Jul 04, 2023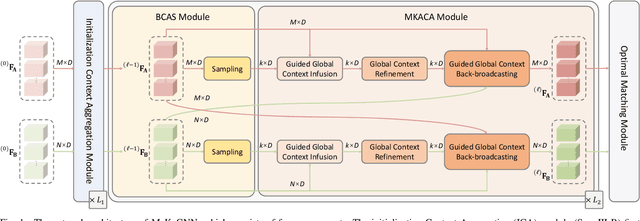
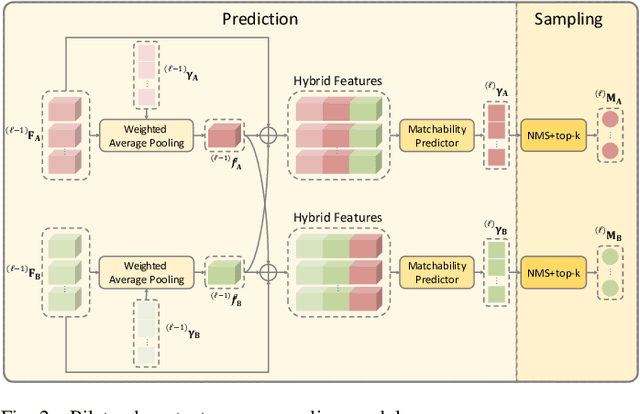
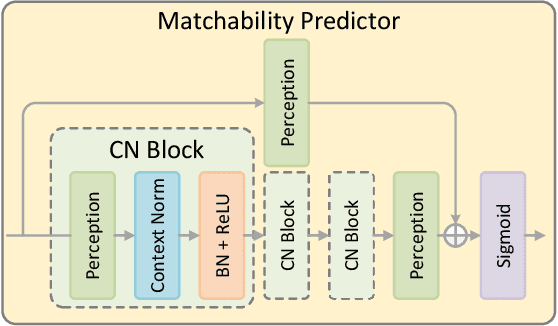
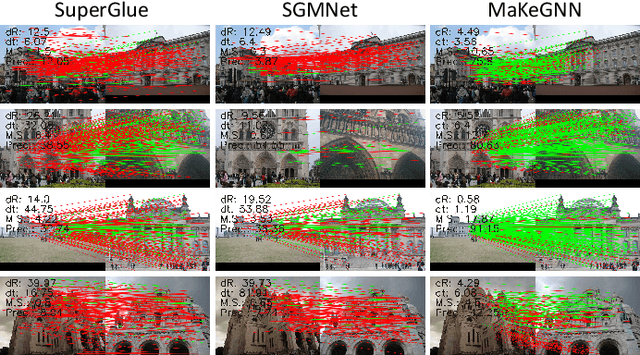
Accurately matching local features between a pair of images is a challenging computer vision task. Previous studies typically use attention based graph neural networks (GNNs) with fully-connected graphs over keypoints within/across images for visual and geometric information reasoning. However, in the context of feature matching, considerable keypoints are non-repeatable due to occlusion and failure of the detector, and thus irrelevant for message passing. The connectivity with non-repeatable keypoints not only introduces redundancy, resulting in limited efficiency, but also interferes with the representation aggregation process, leading to limited accuracy. Targeting towards high accuracy and efficiency, we propose MaKeGNN, a sparse attention-based GNN architecture which bypasses non-repeatable keypoints and leverages matchable ones to guide compact and meaningful message passing. More specifically, our Bilateral Context-Aware Sampling Module first dynamically samples two small sets of well-distributed keypoints with high matchability scores from the image pair. Then, our Matchable Keypoint-Assisted Context Aggregation Module regards sampled informative keypoints as message bottlenecks and thus constrains each keypoint only to retrieve favorable contextual information from intra- and inter- matchable keypoints, evading the interference of irrelevant and redundant connectivity with non-repeatable ones. Furthermore, considering the potential noise in initial keypoints and sampled matchable ones, the MKACA module adopts a matchability-guided attentional aggregation operation for purer data-dependent context propagation. By these means, we achieve the state-of-the-art performance on relative camera estimation, fundamental matrix estimation, and visual localization, while significantly reducing computational and memory complexity compared to typical attentional GNNs.
Cross-domain Recommender Systems via Multimodal Domain Adaptation
Jun 24, 2023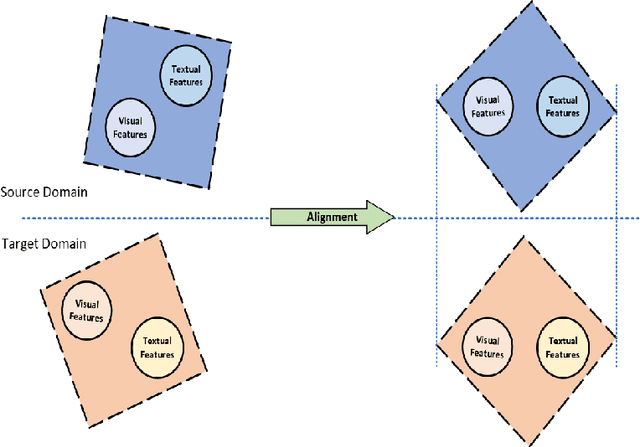
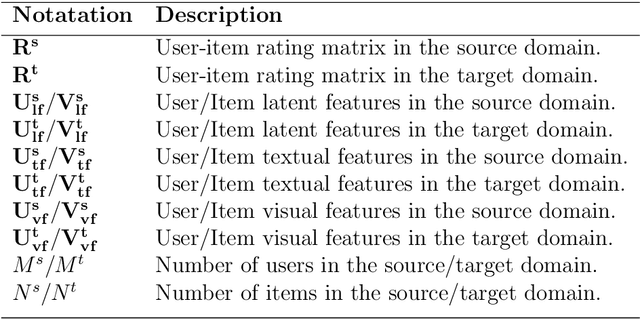
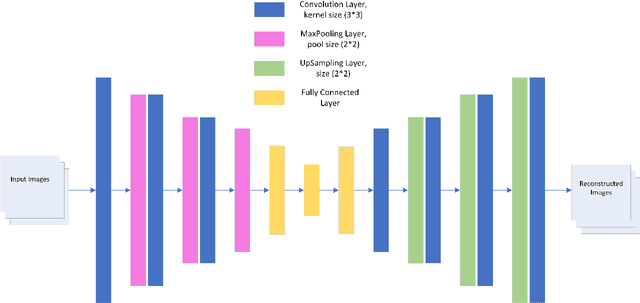

Collaborative Filtering (CF) has emerged as one of the most prominent implementation strategies for building recommender systems. The key idea is to exploit the usage patterns of individuals to generate personalized recommendations. CF techniques, especially for newly launched platforms, often face a critical issue known as the data sparsity problem, which greatly limits their performance. Several approaches have been proposed in the literature to tackle the problem of data sparsity, among which cross-domain collaborative filtering (CDCF) has gained significant attention in the recent past. In order to compensate for the scarcity of available feedback in a target domain, the CDCF approach makes use of information available in other auxiliary domains. Most of the traditional CDCF approach aim is to find a common set of entities (users or items) across the domains and then use them as a bridge for knowledge transfer. However, most real-world datasets are collected from different domains, so they often lack information about anchor points or reference information for entity alignment. In this paper, we propose a domain adaptation technique to align the embeddings of users and items across the two domains. Our approach first exploits the available textual and visual information to independently learn a multi-view latent representation for each user and item in the auxiliary and target domains. The different representations of a user or item are then fused to generate the corresponding unified representation. A domain classifier is then trained to learn the embedding for the domain alignment by fixing the unified features as the anchor points. Experiments on two publicly benchmark datasets indicate the effectiveness of our proposed approach.