 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Convergence of Communications, Control, and Machine Learning for Secure and Autonomous Vehicle Navigation
Jul 05, 2023
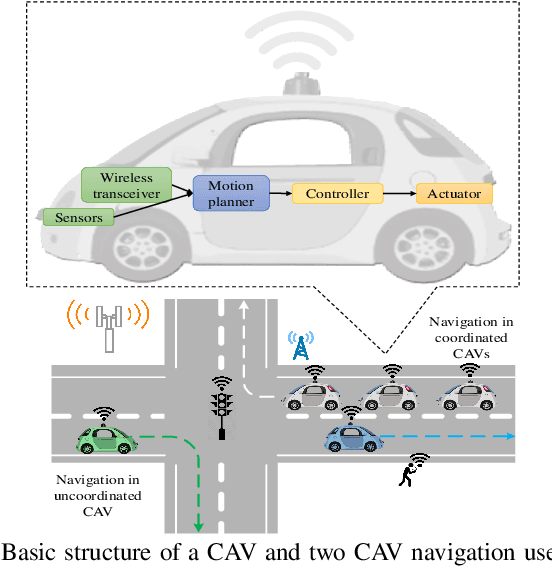
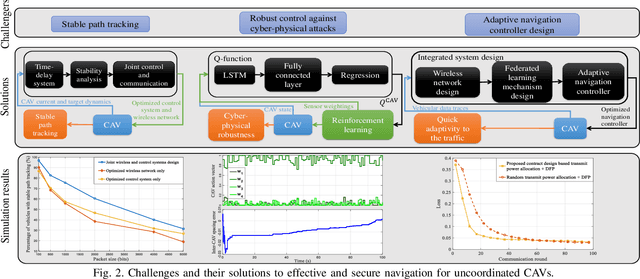
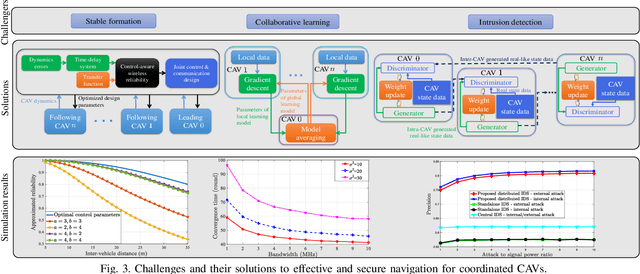
Connected and autonomous vehicles (CAVs) can reduce human errors in traffic accidents, increase road efficiency, and execute various tasks ranging from delivery to smart city surveillance. Reaping these benefits requires CAVs to autonomously navigate to target destinations. To this end, each CAV's navigation controller must leverage the information collected by sensors and wireless systems for decision-making on longitudinal and lateral movements. However, enabling autonomous navigation for CAVs requires a convergent integration of communication, control, and learning systems. The goal of this article is to explicitly expose the challenges related to this convergence and propose solutions to address them in two major use cases: Uncoordinated and coordinated CAVs. In particular, challenges related to the navigation of uncoordinated CAVs include stable path tracking, robust control against cyber-physical attacks, and adaptive navigation controller design. Meanwhile, when multiple CAVs coordinate their movements during navigation, fundamental problems such as stable formation, fast collaborative learning, and distributed intrusion detection are analyzed. For both cases, solutions using the convergence of communication theory, control theory, and machine learning are proposed to enable effective and secure CAV navigation. Preliminary simulation results are provided to show the merits of proposed solutions.
RefVSR++: Exploiting Reference Inputs for Reference-based Video Super-resolution
Jul 06, 2023
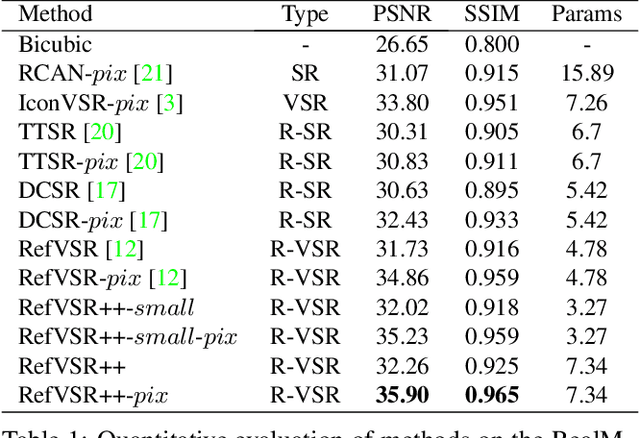
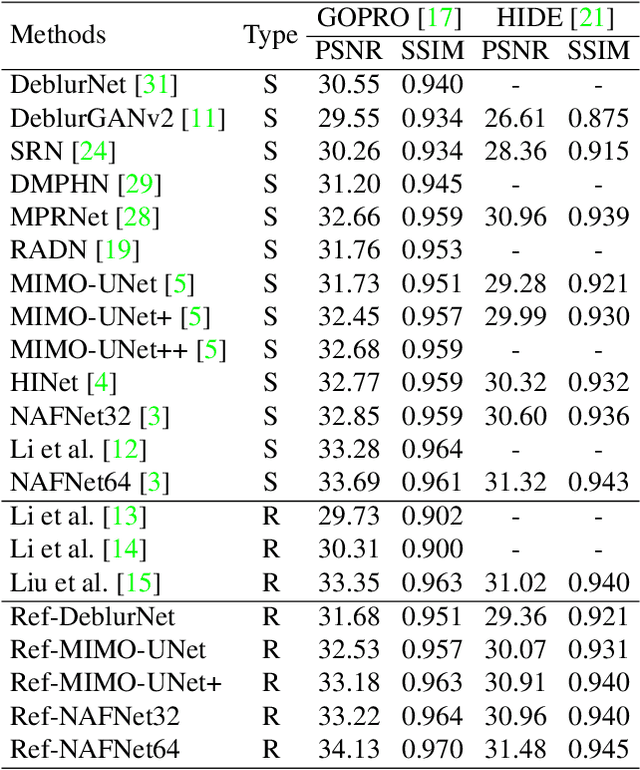
Smartphones equipped with a multi-camera system comprising multiple cameras with different field-of-view (FoVs) are becoming more prevalent. These camera configurations are compatible with reference-based SR and video SR, which can be executed simultaneously while recording video on the device. Thus, combining these two SR methods can improve image quality. Recently, Lee et al. have presented such a method, RefVSR. In this paper, we consider how to optimally utilize the observations obtained, including input low-resolution (LR) video and reference (Ref) video. RefVSR extends conventional video SR quite simply, aggregating the LR and Ref inputs over time in a single bidirectional stream. However, considering the content difference between LR and Ref images due to their FoVs, we can derive the maximum information from the two image sequences by aggregating them independently in the temporal direction. Then, we propose an improved method, RefVSR++, which can aggregate two features in parallel in the temporal direction, one for aggregating the fused LR and Ref inputs and the other for Ref inputs over time. Furthermore, we equip RefVSR++ with enhanced mechanisms to align image features over time, which is the key to the success of video SR. We experimentally show that RefVSR++ outperforms RefVSR by over 1dB in PSNR, achieving the new state-of-the-art.
Reference-based Motion Blur Removal: Learning to Utilize Sharpness in the Reference Image
Jul 06, 2023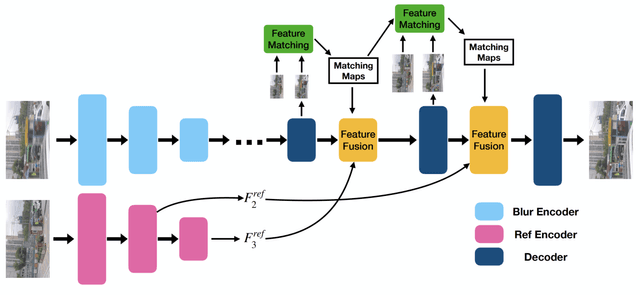
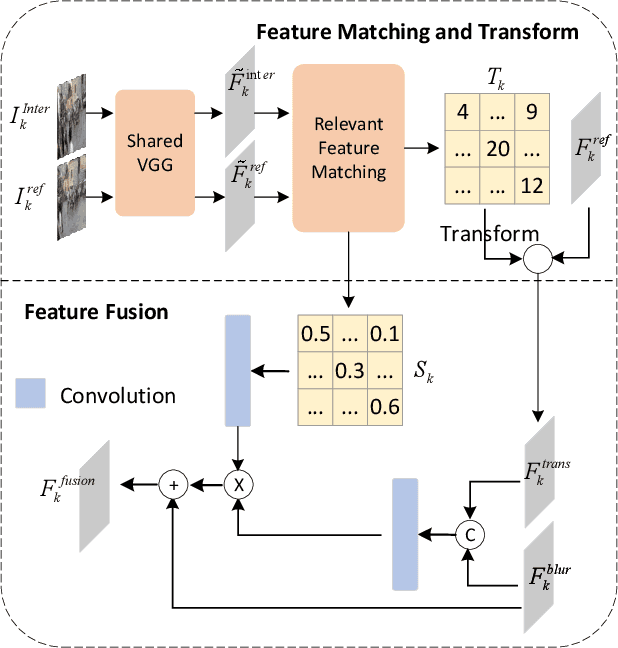
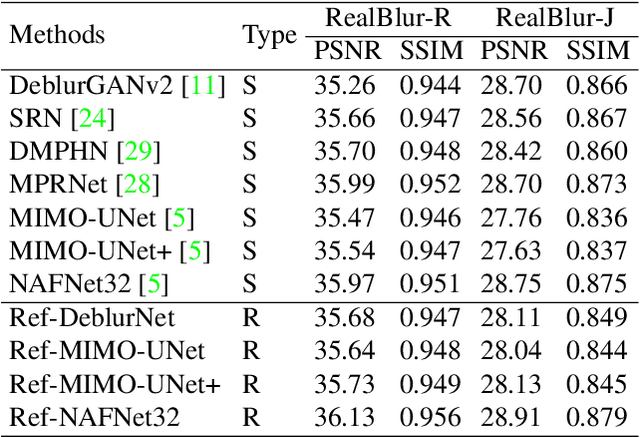
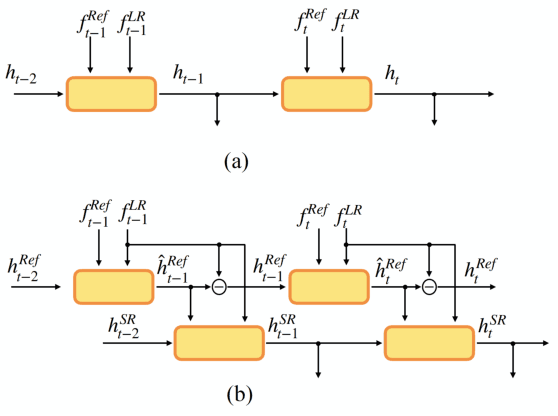
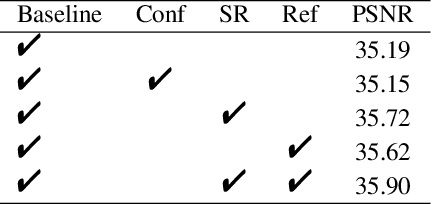
Despite the recent advancement in the study of removing motion blur in an image, it is still hard to deal with strong blurs. While there are limits in removing blurs from a single image, it has more potential to use multiple images, e.g., using an additional image as a reference to deblur a blurry image. A typical setting is deburring an image using a nearby sharp image(s) in a video sequence, as in the studies of video deblurring. This paper proposes a better method to use the information present in a reference image. The method does not need a strong assumption on the reference image. We can utilize an alternative shot of the identical scene, just like in video deblurring, or we can even employ a distinct image from another scene. Our method first matches local patches of the target and reference images and then fuses their features to estimate a sharp image. We employ a patch-based feature matching strategy to solve the difficult problem of matching the blurry image with the sharp reference. Our method can be integrated into pre-existing networks designed for single image deblurring. The experimental results show the effectiveness of the proposed method.
A Hybrid End-to-End Spatio-Temporal Attention Neural Network with Graph-Smooth Signals for EEG Emotion Recognition
Jul 06, 2023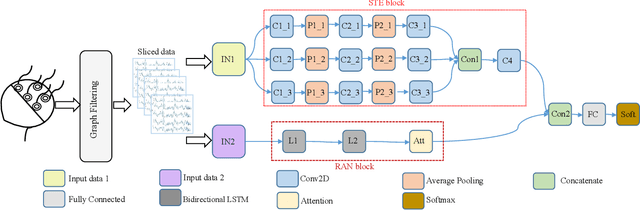
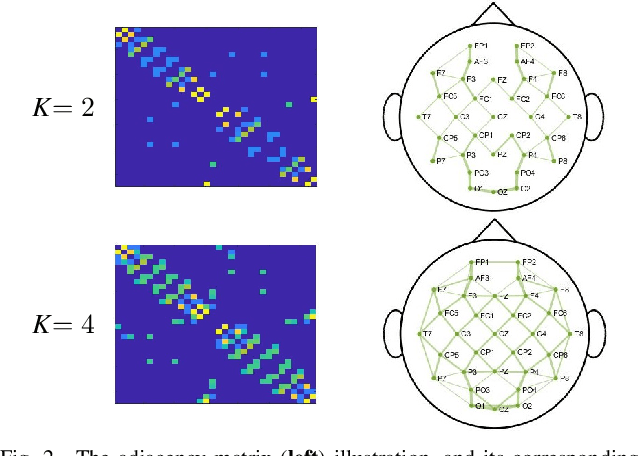
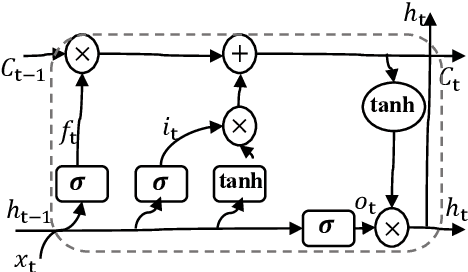
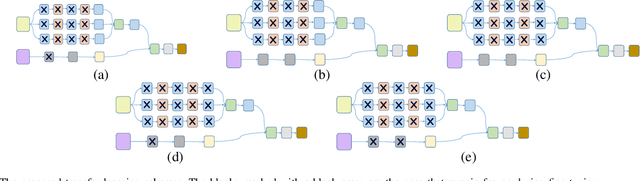
Recently, physiological data such as electroencephalography (EEG) signals have attracted significant attention in affective computing. In this context, the main goal is to design an automated model that can assess emotional states. Lately, deep neural networks have shown promising performance in emotion recognition tasks. However, designing a deep architecture that can extract practical information from raw data is still a challenge. Here, we introduce a deep neural network that acquires interpretable physiological representations by a hybrid structure of spatio-temporal encoding and recurrent attention network blocks. Furthermore, a preprocessing step is applied to the raw data using graph signal processing tools to perform graph smoothing in the spatial domain. We demonstrate that our proposed architecture exceeds state-of-the-art results for emotion classification on the publicly available DEAP dataset. To explore the generality of the learned model, we also evaluate the performance of our architecture towards transfer learning (TL) by transferring the model parameters from a specific source to other target domains. Using DEAP as the source dataset, we demonstrate the effectiveness of our model in performing cross-modality TL and improving emotion classification accuracy on DREAMER and the Emotional English Word (EEWD) datasets, which involve EEG-based emotion classification tasks with different stimuli.
Focused Transformer: Contrastive Training for Context Scaling
Jul 06, 2023
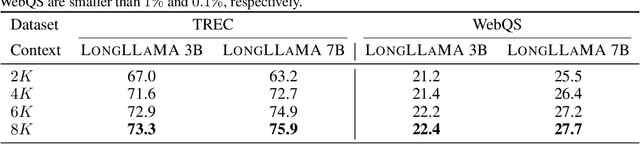
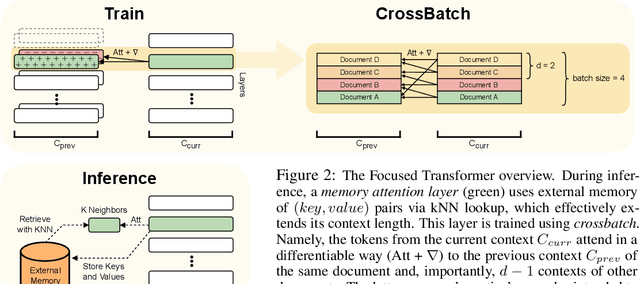
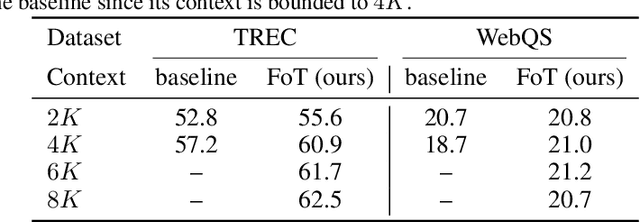
Large language models have an exceptional capability to incorporate new information in a contextual manner. However, the full potential of such an approach is often restrained due to a limitation in the effective context length. One solution to this issue is to endow an attention layer with access to an external memory, which comprises of (key, value) pairs. Yet, as the number of documents increases, the proportion of relevant keys to irrelevant ones decreases, leading the model to focus more on the irrelevant keys. We identify a significant challenge, dubbed the distraction issue, where keys linked to different semantic values might overlap, making them hard to distinguish. To tackle this problem, we introduce the Focused Transformer (FoT), a technique that employs a training process inspired by contrastive learning. This novel approach enhances the structure of the (key, value) space, enabling an extension of the context length. Our method allows for fine-tuning pre-existing, large-scale models to lengthen their effective context. This is demonstrated by our fine-tuning of $3B$ and $7B$ OpenLLaMA checkpoints. The resulting models, which we name LongLLaMA, exhibit advancements in tasks requiring a long context. We further illustrate that our LongLLaMA models adeptly manage a $256 k$ context length for passkey retrieval.
ALPCAH: Sample-wise Heteroscedastic PCA with Tail Singular Value Regularization
Jul 06, 2023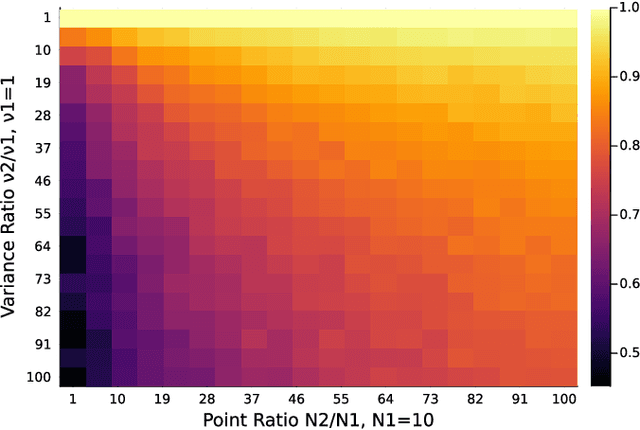
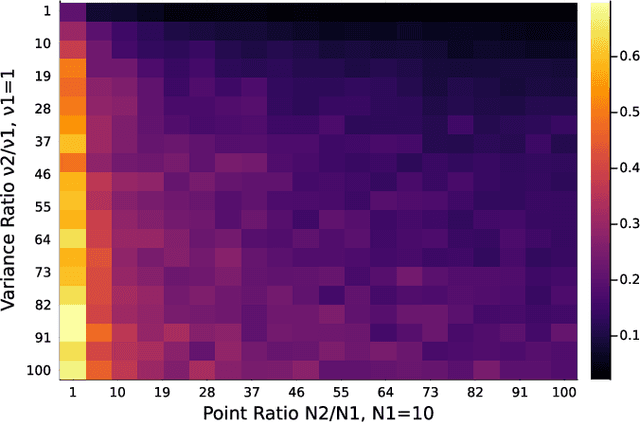
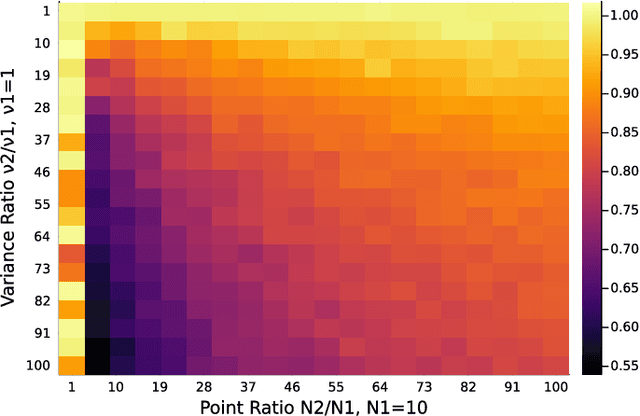
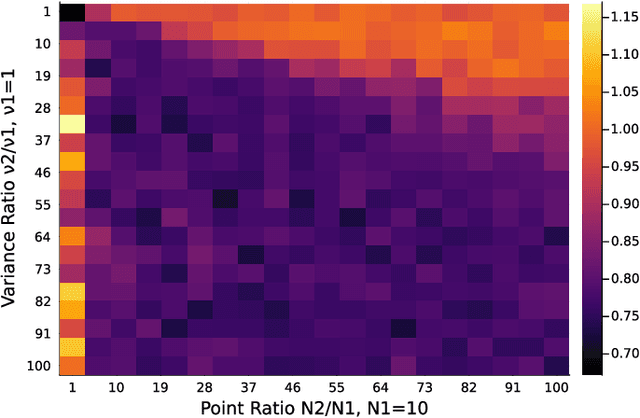
Principal component analysis (PCA) is a key tool in the field of data dimensionality reduction that is useful for various data science problems. However, many applications involve heterogeneous data that varies in quality due to noise characteristics associated with different sources of the data. Methods that deal with this mixed dataset are known as heteroscedastic methods. Current methods like HePPCAT make Gaussian assumptions of the basis coefficients that may not hold in practice. Other methods such as Weighted PCA (WPCA) assume the noise variances are known, which may be difficult to know in practice. This paper develops a PCA method that can estimate the sample-wise noise variances and use this information in the model to improve the estimate of the subspace basis associated with the low-rank structure of the data. This is done without distributional assumptions of the low-rank component and without assuming the noise variances are known. Simulations show the effectiveness of accounting for such heteroscedasticity in the data, the benefits of using such a method with all of the data versus retaining only good data, and comparisons are made against other PCA methods established in the literature like PCA, Robust PCA (RPCA), and HePPCAT. Code available at https://github.com/javiersc1/ALPCAH
Dense Retrieval Adaptation using Target Domain Description
Jul 06, 2023
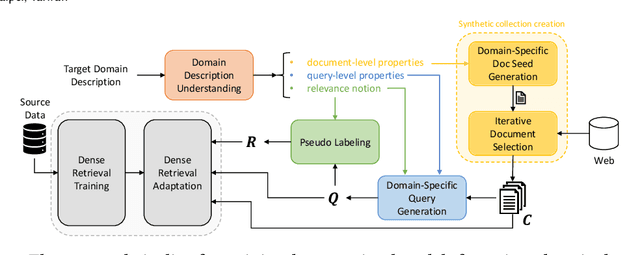
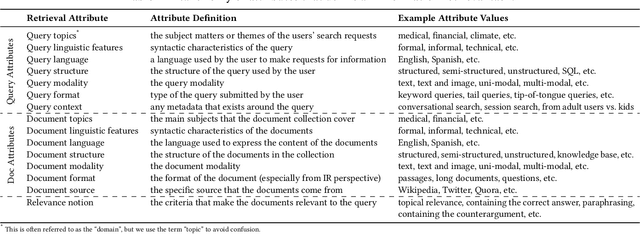
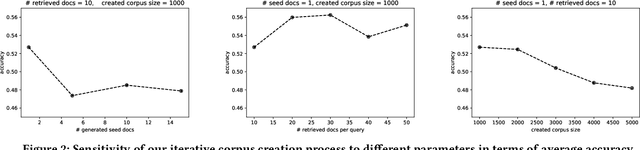
In information retrieval (IR), domain adaptation is the process of adapting a retrieval model to a new domain whose data distribution is different from the source domain. Existing methods in this area focus on unsupervised domain adaptation where they have access to the target document collection or supervised (often few-shot) domain adaptation where they additionally have access to (limited) labeled data in the target domain. There also exists research on improving zero-shot performance of retrieval models with no adaptation. This paper introduces a new category of domain adaptation in IR that is as-yet unexplored. Here, similar to the zero-shot setting, we assume the retrieval model does not have access to the target document collection. In contrast, it does have access to a brief textual description that explains the target domain. We define a taxonomy of domain attributes in retrieval tasks to understand different properties of a source domain that can be adapted to a target domain. We introduce a novel automatic data construction pipeline that produces a synthetic document collection, query set, and pseudo relevance labels, given a textual domain description. Extensive experiments on five diverse target domains show that adapting dense retrieval models using the constructed synthetic data leads to effective retrieval performance on the target domain.
Learning Multi-Agent Intention-Aware Communication for Optimal Multi-Order Execution in Finance
Jul 06, 2023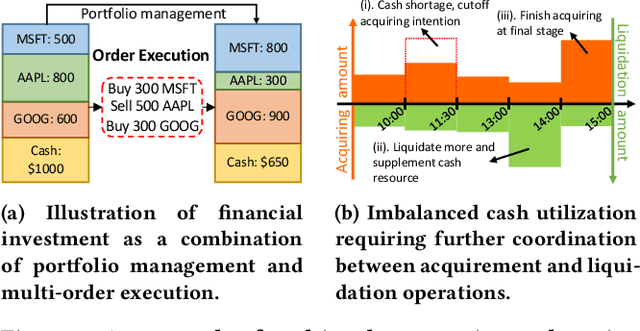
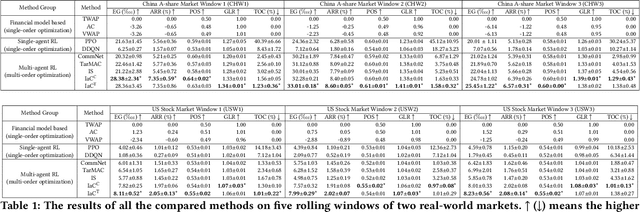
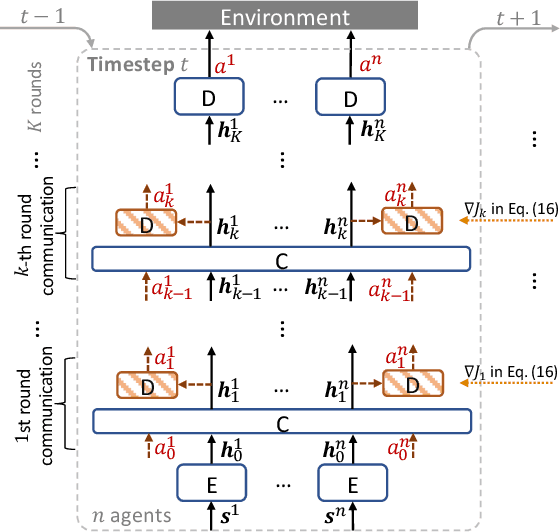
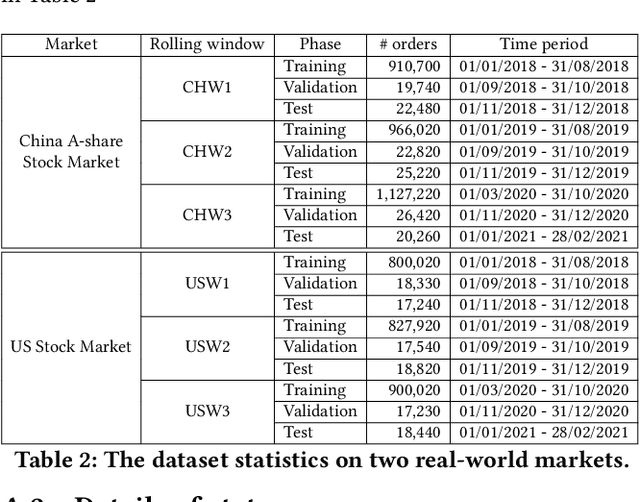
Order execution is a fundamental task in quantitative finance, aiming at finishing acquisition or liquidation for a number of trading orders of the specific assets. Recent advance in model-free reinforcement learning (RL) provides a data-driven solution to the order execution problem. However, the existing works always optimize execution for an individual order, overlooking the practice that multiple orders are specified to execute simultaneously, resulting in suboptimality and bias. In this paper, we first present a multi-agent RL (MARL) method for multi-order execution considering practical constraints. Specifically, we treat every agent as an individual operator to trade one specific order, while keeping communicating with each other and collaborating for maximizing the overall profits. Nevertheless, the existing MARL algorithms often incorporate communication among agents by exchanging only the information of their partial observations, which is inefficient in complicated financial market. To improve collaboration, we then propose a learnable multi-round communication protocol, for the agents communicating the intended actions with each other and refining accordingly. It is optimized through a novel action value attribution method which is provably consistent with the original learning objective yet more efficient. The experiments on the data from two real-world markets have illustrated superior performance with significantly better collaboration effectiveness achieved by our method.
Massive MIMO with Cauchy Noise: Channel Estimation, Achievable Rate and Data Decoding
Jul 06, 2023We consider massive multiple-input multiple-output (MIMO) systems in the presence of Cauchy noise. First, we focus on the channel estimation problem. In the standard massive MIMO setup, the users transmit orthonormal pilots during the training phase and the received signal at the base station is projected onto each pilot. This processing is optimum when the noise is Gaussian. We show that this processing is not optimal when the noise is Cauchy and as a remedy propose a channel estimation technique that operates on the raw received signal. Second, we derive uplink-downlink achievable rates in the presence of Cauchy noise for perfect and imperfect channel state information. Finally, we derive log-likelihood ratio expressions for soft bit detection for both uplink and downlink, and simulate coded bit-error-rate curves. In addition to this, we derive and compare the symbol detectors in the presence of both Gaussian and Cauchy noises. An important observation is that the detector constructed for Cauchy noise performs well with both Gaussian and Cauchy noises; on the other hand, the detector for Gaussian noise works poorly in the presence of Cauchy noise. That is, the Cauchy detector is robust against heavy-tailed noise, whereas the Gaussian detector is not.
* To appear in the IEEE Transactions on Wireless Communications, 2023
Facial Landmark Detection Evaluation on MOBIO Database
Jul 06, 2023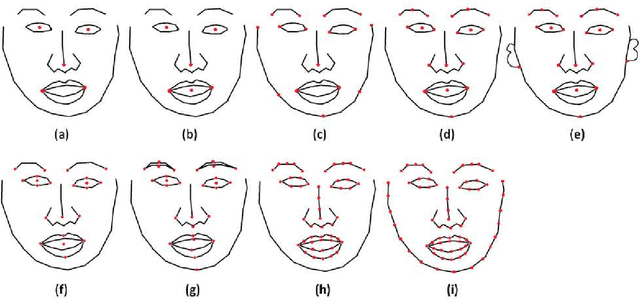
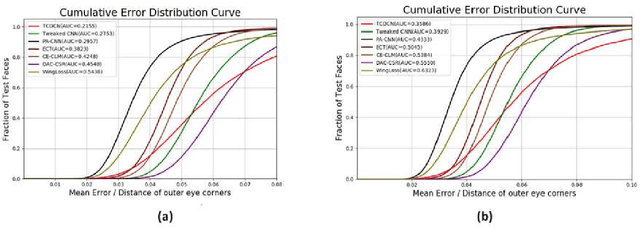
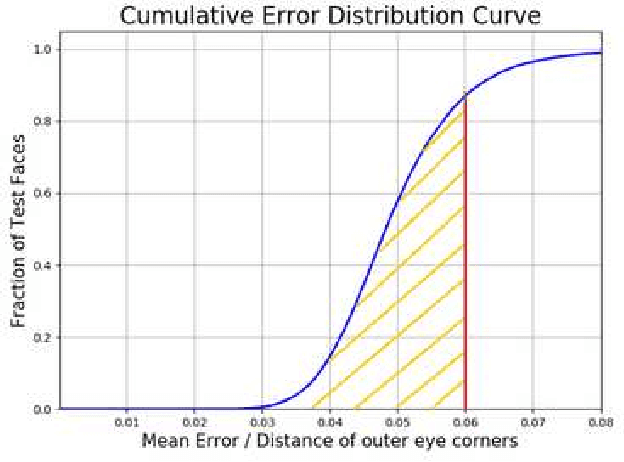
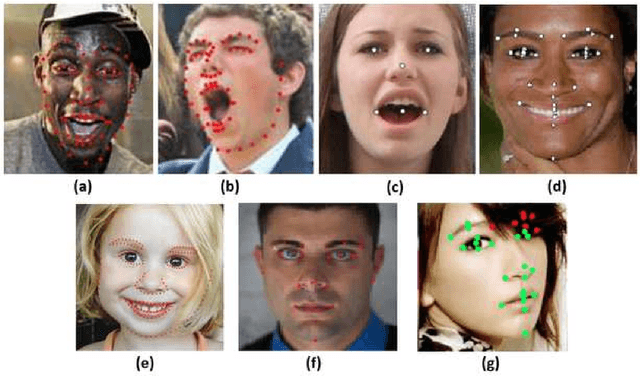
MOBIO is a bi-modal database that was captured almost exclusively on mobile phones. It aims to improve research into deploying biometric techniques to mobile devices. Research has been shown that face and speaker recognition can be performed in a mobile environment. Facial landmark localization aims at finding the coordinates of a set of pre-defined key points for 2D face images. A facial landmark usually has specific semantic meaning, e.g. nose tip or eye centre, which provides rich geometric information for other face analysis tasks such as face recognition, emotion estimation and 3D face reconstruction. Pretty much facial landmark detection methods adopt still face databases, such as 300W, AFW, AFLW, or COFW, for evaluation, but seldomly use mobile data. Our work is first to perform facial landmark detection evaluation on the mobile still data, i.e., face images from MOBIO database. About 20,600 face images have been extracted from this audio-visual database and manually labeled with 22 landmarks as the groundtruth. Several state-of-the-art facial landmark detection methods are adopted to evaluate their performance on these data. The result shows that the data from MOBIO database is pretty challenging. This database can be a new challenging one for facial landmark detection evaluation.