 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Active Sensing with Predictive Coding and Uncertainty Minimization
Jul 04, 2023
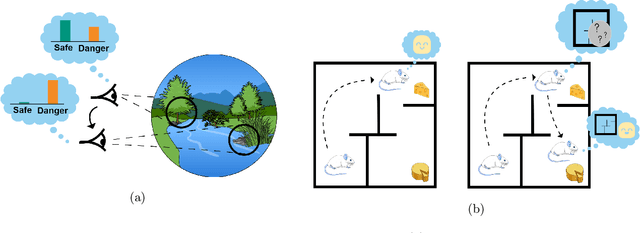
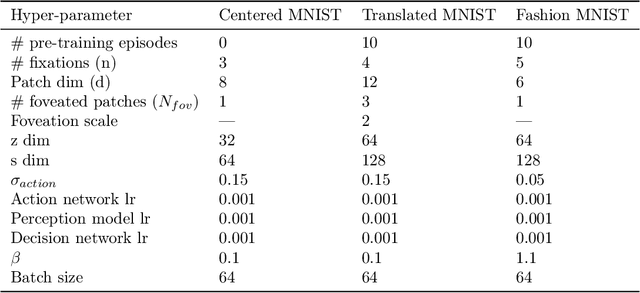
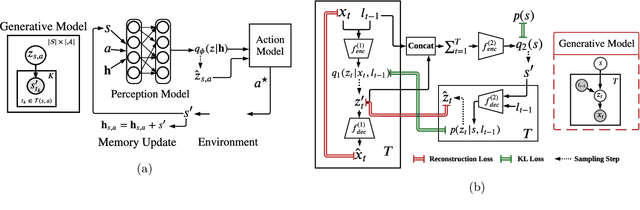
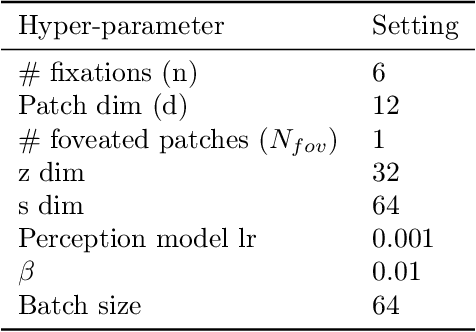
We present an end-to-end procedure for embodied exploration based on two biologically inspired computations: predictive coding and uncertainty minimization. The procedure can be applied to any exploration setting in a task-independent and intrinsically driven manner. We first demonstrate our approach in a maze navigation task and show that our model is capable of discovering the underlying transition distribution and reconstructing the spatial features of the environment. Second, we apply our model to the more complex task of active vision, where an agent must actively sample its visual environment to gather information. We show that our model is able to build unsupervised representations that allow it to actively sample and efficiently categorize sensory scenes. We further show that using these representations as input for downstream classification leads to superior data efficiency and learning speed compared to other baselines, while also maintaining lower parameter complexity. Finally, the modularity of our model allows us to analyze its internal mechanisms and to draw insight into the interactions between perception and action during exploratory behavior.
Hyperspectral and Multispectral Image Fusion Using the Conditional Denoising Diffusion Probabilistic Model
Jul 07, 2023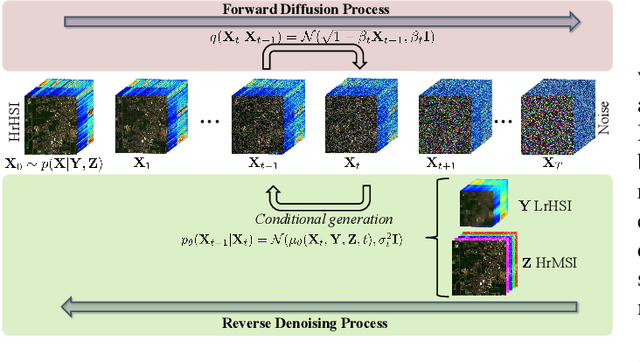
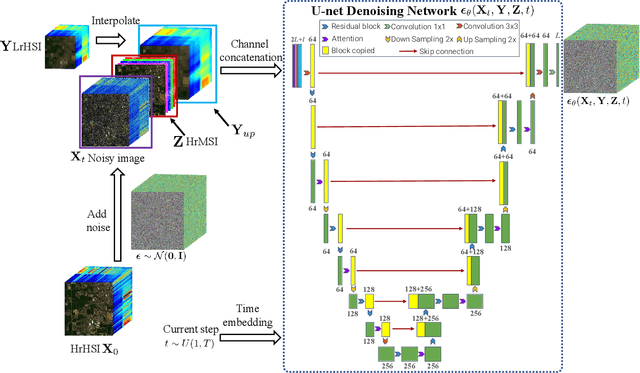

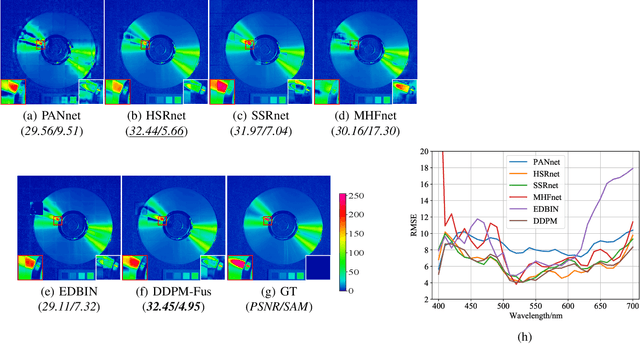
Hyperspectral images (HSI) have a large amount of spectral information reflecting the characteristics of matter, while their spatial resolution is low due to the limitations of imaging technology. Complementary to this are multispectral images (MSI), e.g., RGB images, with high spatial resolution but insufficient spectral bands. Hyperspectral and multispectral image fusion is a technique for acquiring ideal images that have both high spatial and high spectral resolution cost-effectively. Many existing HSI and MSI fusion algorithms rely on known imaging degradation models, which are often not available in practice. In this paper, we propose a deep fusion method based on the conditional denoising diffusion probabilistic model, called DDPM-Fus. Specifically, the DDPM-Fus contains the forward diffusion process which gradually adds Gaussian noise to the high spatial resolution HSI (HrHSI) and another reverse denoising process which learns to predict the desired HrHSI from its noisy version conditioning on the corresponding high spatial resolution MSI (HrMSI) and low spatial resolution HSI (LrHSI). Once the training is completes, the proposed DDPM-Fus implements the reverse process on the test HrMSI and LrHSI to generate the fused HrHSI. Experiments conducted on one indoor and two remote sensing datasets show the superiority of the proposed model when compared with other advanced deep learningbased fusion methods. The codes of this work will be opensourced at this address: https://github.com/shuaikaishi/DDPMFus for reproducibility.
Weakly-supervised Contrastive Learning for Unsupervised Object Discovery
Jul 07, 2023Unsupervised object discovery (UOD) refers to the task of discriminating the whole region of objects from the background within a scene without relying on labeled datasets, which benefits the task of bounding-box-level localization and pixel-level segmentation. This task is promising due to its ability to discover objects in a generic manner. We roughly categorise existing techniques into two main directions, namely the generative solutions based on image resynthesis, and the clustering methods based on self-supervised models. We have observed that the former heavily relies on the quality of image reconstruction, while the latter shows limitations in effectively modeling semantic correlations. To directly target at object discovery, we focus on the latter approach and propose a novel solution by incorporating weakly-supervised contrastive learning (WCL) to enhance semantic information exploration. We design a semantic-guided self-supervised learning model to extract high-level semantic features from images, which is achieved by fine-tuning the feature encoder of a self-supervised model, namely DINO, via WCL. Subsequently, we introduce Principal Component Analysis (PCA) to localize object regions. The principal projection direction, corresponding to the maximal eigenvalue, serves as an indicator of the object region(s). Extensive experiments on benchmark unsupervised object discovery datasets demonstrate the effectiveness of our proposed solution. The source code and experimental results are publicly available via our project page at https://github.com/npucvr/WSCUOD.git.
Novel Categories Discovery from probability matrix perspective
Jul 07, 2023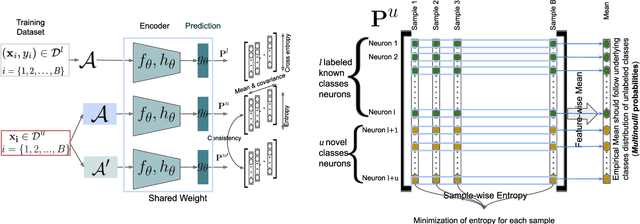
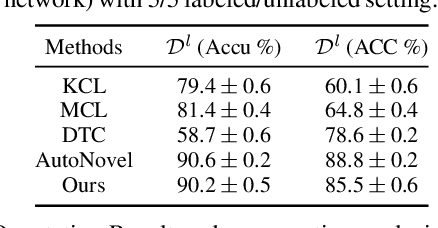
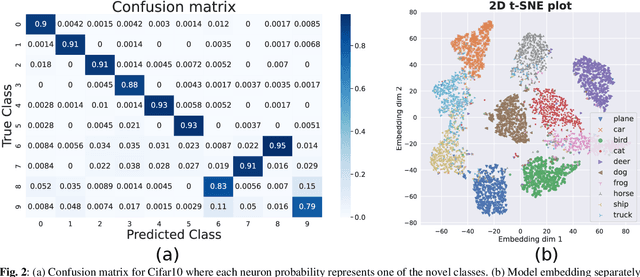
Novel Categories Discovery (NCD) tackles the open-world problem of classifying known and clustering novel categories based on the class semantics using partial class space annotated data. Unlike traditional pseudo-label and retraining, we investigate NCD from the novel data probability matrix perspective. We leverage the connection between NCD novel data sampling with provided novel class Multinoulli (categorical) distribution and hypothesize to implicitly achieve semantic-based novel data clustering by learning their class distribution. We propose novel constraints on first-order (mean) and second-order (covariance) statistics of probability matrix features while applying instance-wise information constraints. In particular, we align the neuron distribution (activation patterns) under a large batch of Monte-Carlo novel data sampling by matching their empirical features mean and covariance with the provided Multinoulli-distribution. Simultaneously, we minimize entropy and enforce prediction consistency for each instance. Our simple approach successfully realizes semantic-based novel data clustering provided the semantic similarity between label-unlabeled classes. We demonstrate the discriminative capacity of our approaches in image and video modalities. Moreover, we perform extensive ablation studies regarding data, networks, and our framework components to provide better insights. Our approach maintains ~94%, ~93%, and ~85%, classification accuracy in labeled data while achieving ~90%, ~84%, and ~72% clustering accuracy for novel categories for Cifar10, UCF101, and MPSC-ARL datasets that matches state-of-the-art approaches without any external clustering.
Towards Deep Network Steganography: From Networks to Networks
Jul 07, 2023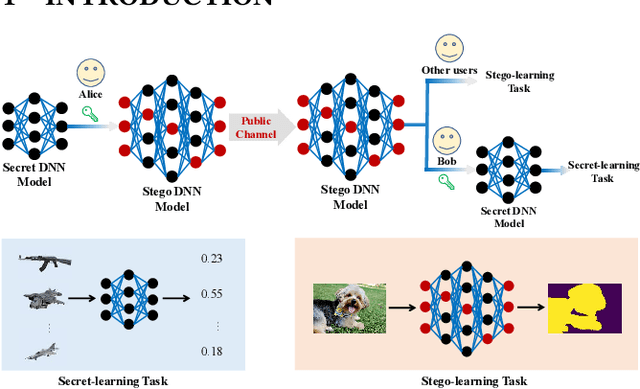
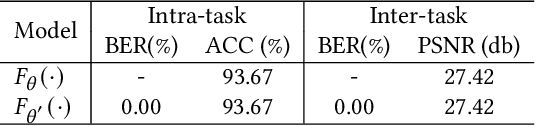
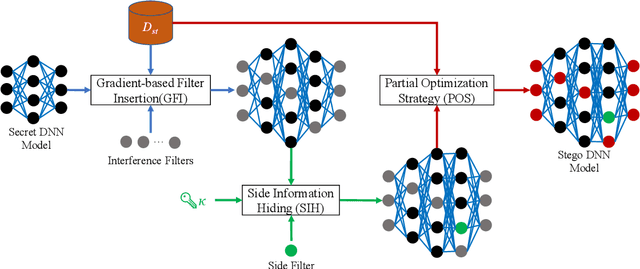
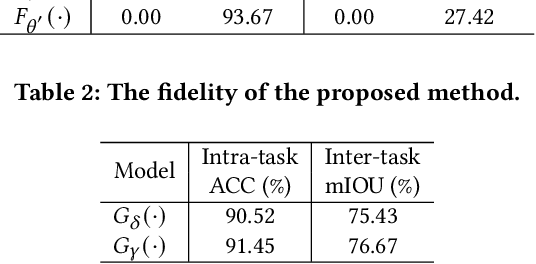
With the widespread applications of the deep neural network (DNN), how to covertly transmit the DNN models in public channels brings us the attention, especially for those trained for secret-learning tasks. In this paper, we propose deep network steganography for the covert communication of DNN models. Unlike the existing steganography schemes which focus on the subtle modification of the cover data to accommodate the secrets, our scheme is learning task oriented, where the learning task of the secret DNN model (termed as secret-learning task) is disguised into another ordinary learning task conducted in a stego DNN model (termed as stego-learning task). To this end, we propose a gradient-based filter insertion scheme to insert interference filters into the important positions in the secret DNN model to form a stego DNN model. These positions are then embedded into the stego DNN model using a key by side information hiding. Finally, we activate the interference filters by a partial optimization strategy, such that the generated stego DNN model works on the stego-learning task. We conduct the experiments on both the intra-task steganography and inter-task steganography (i.e., the secret and stego-learning tasks belong to the same and different categories), both of which demonstrate the effectiveness of our proposed method for covert communication of DNN models.
Open-Vocabulary Object Detection via Scene Graph Discovery
Jul 07, 2023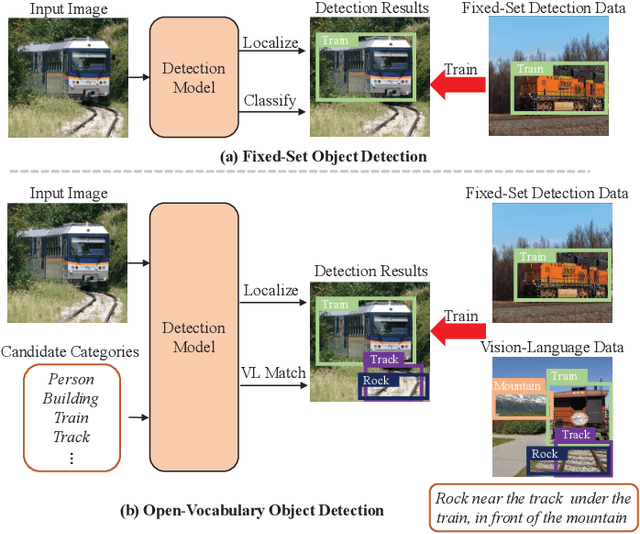
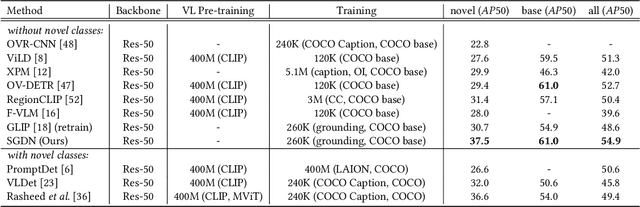
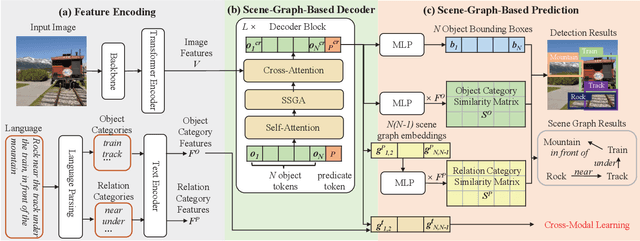
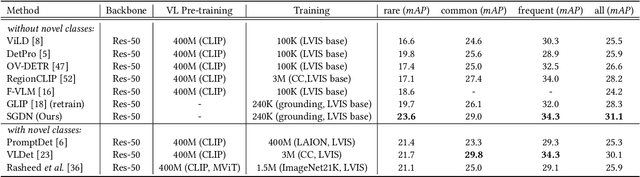
In recent years, open-vocabulary (OV) object detection has attracted increasing research attention. Unlike traditional detection, which only recognizes fixed-category objects, OV detection aims to detect objects in an open category set. Previous works often leverage vision-language (VL) training data (e.g., referring grounding data) to recognize OV objects. However, they only use pairs of nouns and individual objects in VL data, while these data usually contain much more information, such as scene graphs, which are also crucial for OV detection. In this paper, we propose a novel Scene-Graph-Based Discovery Network (SGDN) that exploits scene graph cues for OV detection. Firstly, a scene-graph-based decoder (SGDecoder) including sparse scene-graph-guided attention (SSGA) is presented. It captures scene graphs and leverages them to discover OV objects. Secondly, we propose scene-graph-based prediction (SGPred), where we build a scene-graph-based offset regression (SGOR) mechanism to enable mutual enhancement between scene graph extraction and object localization. Thirdly, we design a cross-modal learning mechanism in SGPred. It takes scene graphs as bridges to improve the consistency between cross-modal embeddings for OV object classification. Experiments on COCO and LVIS demonstrate the effectiveness of our approach. Moreover, we show the ability of our model for OV scene graph detection, while previous OV scene graph generation methods cannot tackle this task.
Enlighten-anything:When Segment Anything Model Meets Low-light Image Enhancement
Jun 21, 2023
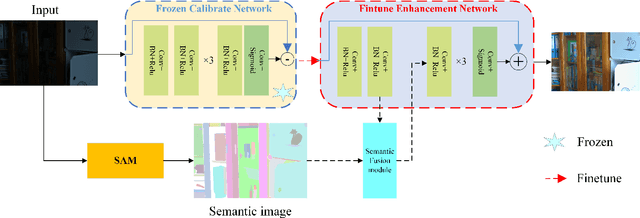


Image restoration is a low-level visual task, and most CNN methods are designed as black boxes, lacking transparency and intrinsic aesthetics. Many unsupervised approaches ignore the degradation of visible information in low-light scenes, which will seriously affect the aggregation of complementary information and also make the fusion algorithm unable to produce satisfactory fusion results under extreme conditions. In this paper, we propose Enlighten-anything, which is able to enhance and fuse the semantic intent of SAM segmentation with low-light images to obtain fused images with good visual perception. The generalization ability of unsupervised learning is greatly improved, and experiments on LOL dataset are conducted to show that our method improves 3db in PSNR over baseline and 8 in SSIM. zero-shot learning of SAM introduces a powerful aid for unsupervised low-light enhancement. The source code of Enlighten-anything can be obtained from https://github.com/zhangbaijin/enlighten-anything
Balanced Filtering via Non-Disclosive Proxies
Jul 05, 2023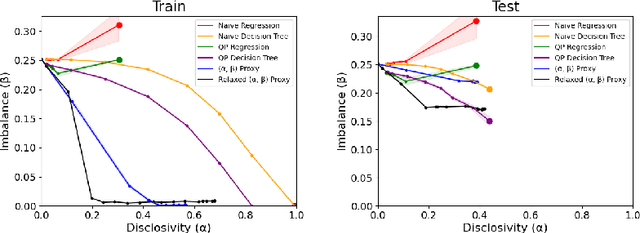
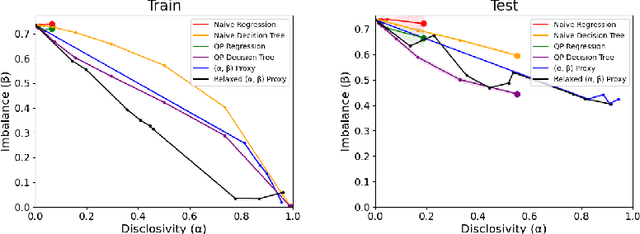
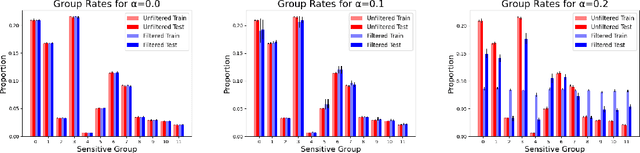
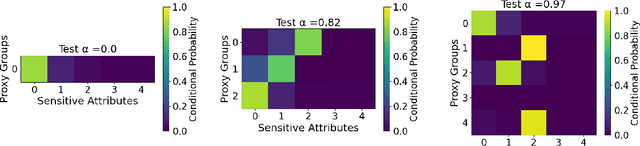
We study the problem of non-disclosively collecting a sample of data that is balanced with respect to sensitive groups when group membership is unavailable or prohibited from use at collection time. Specifically, our collection mechanism does not reveal significantly more about group membership of any individual sample than can be ascertained from base rates alone. To do this, we adopt a fairness pipeline perspective, in which a learner can use a small set of labeled data to train a proxy function that can later be used for this filtering task. We then associate the range of the proxy function with sampling probabilities; given a new candidate, we classify it using our proxy function, and then select it for our sample with probability proportional to the sampling probability corresponding to its proxy classification. Importantly, we require that the proxy classification itself not reveal significant information about the sensitive group membership of any individual sample (i.e., it should be sufficiently non-disclosive). We show that under modest algorithmic assumptions, we find such a proxy in a sample- and oracle-efficient manner. Finally, we experimentally evaluate our algorithm and analyze generalization properties.
Multimodal Imbalance-Aware Gradient Modulation for Weakly-supervised Audio-Visual Video Parsing
Jul 05, 2023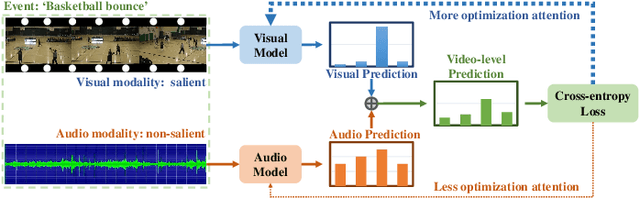
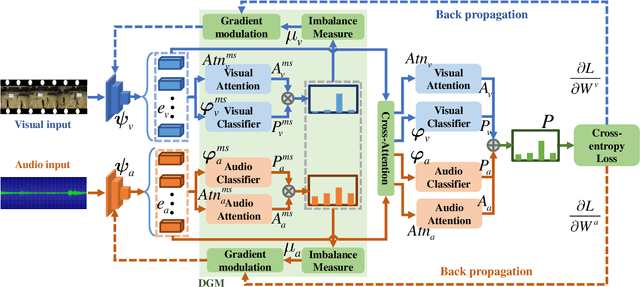
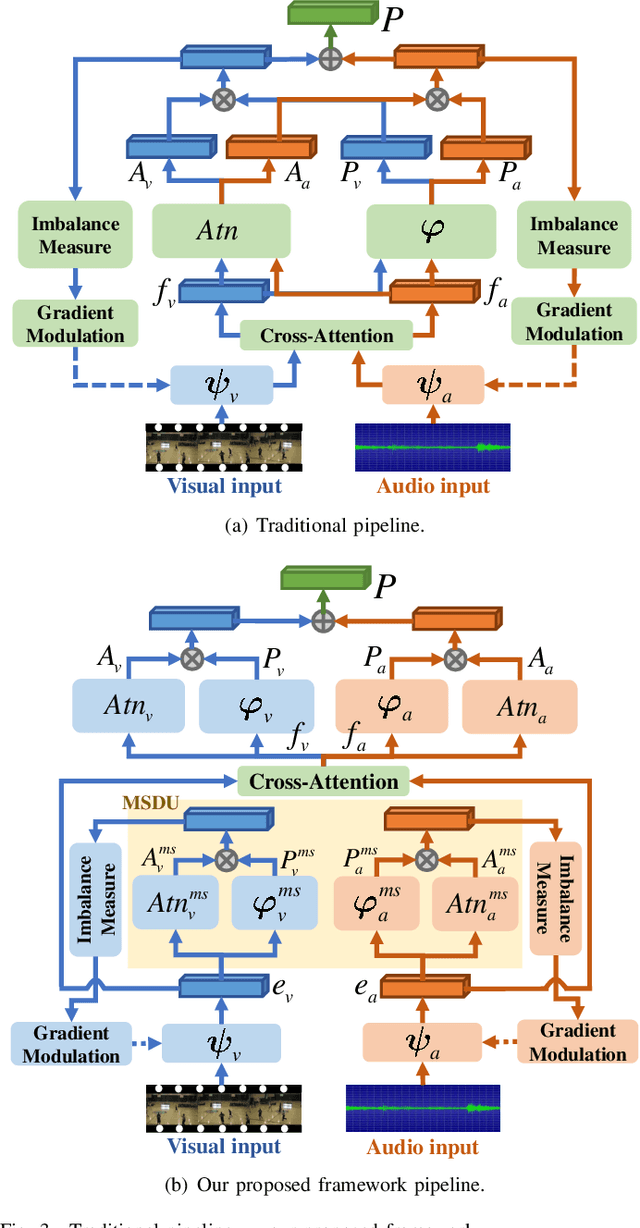
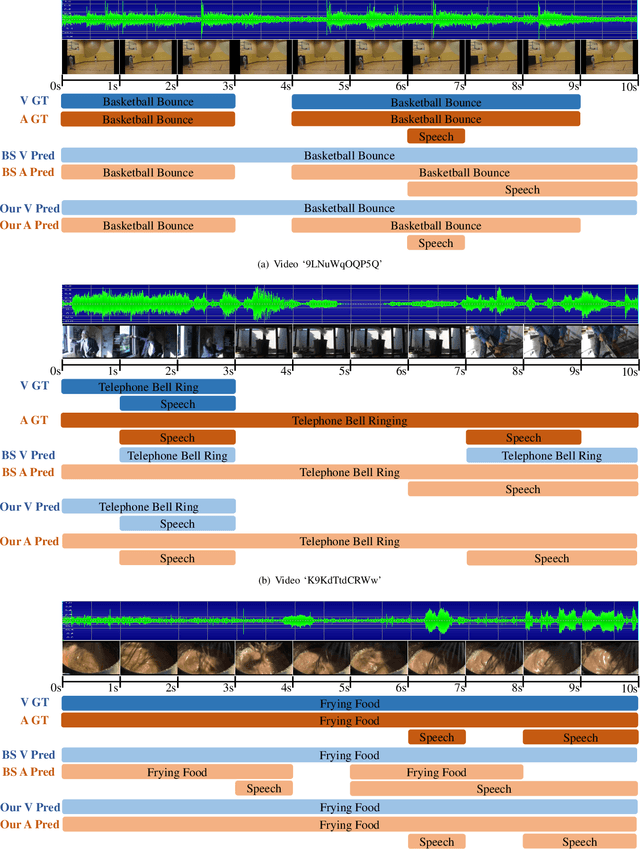
Weakly-supervised audio-visual video parsing (WS-AVVP) aims to localize the temporal extents of audio, visual and audio-visual event instances as well as identify the corresponding event categories with only video-level category labels for training. Most previous methods pay much attention to refining the supervision for each modality or extracting fruitful cross-modality information for more reliable feature learning. None of them have noticed the imbalanced feature learning between different modalities in the task. In this paper, to balance the feature learning processes of different modalities, a dynamic gradient modulation (DGM) mechanism is explored, where a novel and effective metric function is designed to measure the imbalanced feature learning between audio and visual modalities. Furthermore, principle analysis indicates that the multimodal confusing calculation will hamper the precise measurement of multimodal imbalanced feature learning, which further weakens the effectiveness of our DGM mechanism. To cope with this issue, a modality-separated decision unit (MSDU) is designed for more precise measurement of imbalanced feature learning between audio and visual modalities. Comprehensive experiments are conducted on public benchmarks and the corresponding experimental results demonstrate the effectiveness of our proposed method.
Convergence of Communications, Control, and Machine Learning for Secure and Autonomous Vehicle Navigation
Jul 05, 2023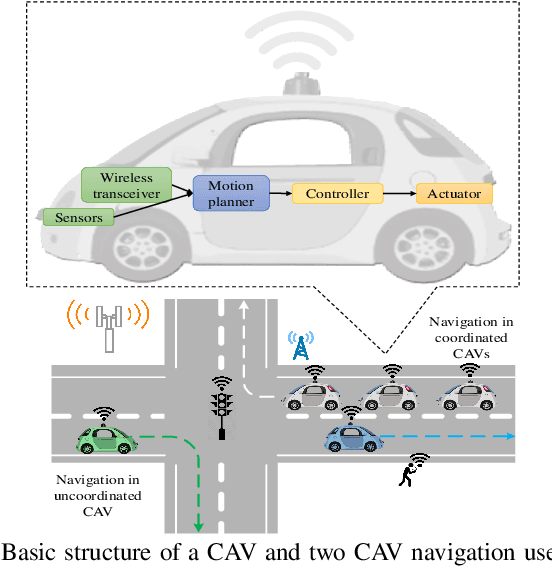
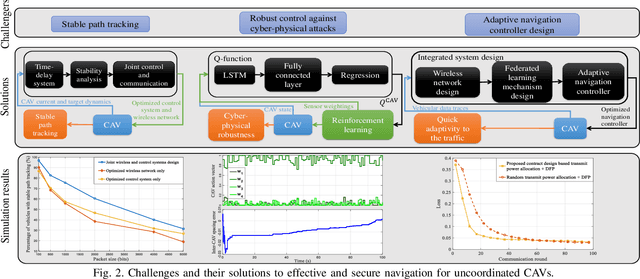
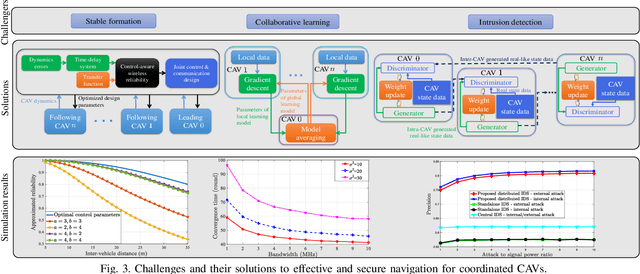
Connected and autonomous vehicles (CAVs) can reduce human errors in traffic accidents, increase road efficiency, and execute various tasks ranging from delivery to smart city surveillance. Reaping these benefits requires CAVs to autonomously navigate to target destinations. To this end, each CAV's navigation controller must leverage the information collected by sensors and wireless systems for decision-making on longitudinal and lateral movements. However, enabling autonomous navigation for CAVs requires a convergent integration of communication, control, and learning systems. The goal of this article is to explicitly expose the challenges related to this convergence and propose solutions to address them in two major use cases: Uncoordinated and coordinated CAVs. In particular, challenges related to the navigation of uncoordinated CAVs include stable path tracking, robust control against cyber-physical attacks, and adaptive navigation controller design. Meanwhile, when multiple CAVs coordinate their movements during navigation, fundamental problems such as stable formation, fast collaborative learning, and distributed intrusion detection are analyzed. For both cases, solutions using the convergence of communication theory, control theory, and machine learning are proposed to enable effective and secure CAV navigation. Preliminary simulation results are provided to show the merits of proposed solutions.