 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HiNet: Novel Multi-Scenario & Multi-Task Learning with Hierarchical Information Extraction
Mar 14, 2023
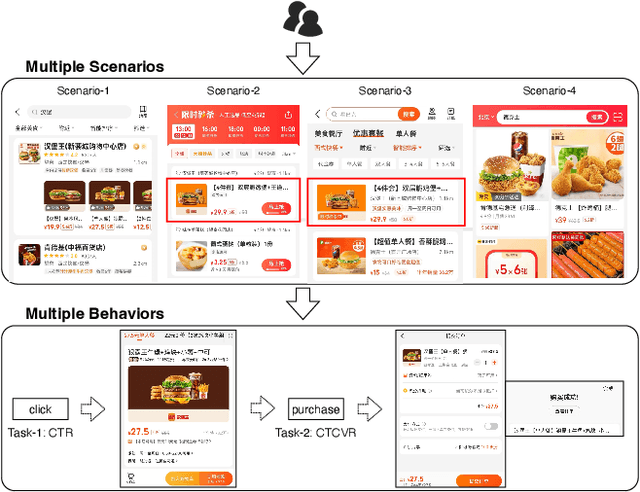
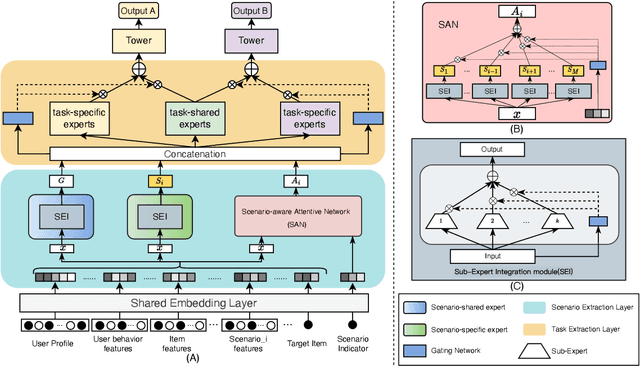
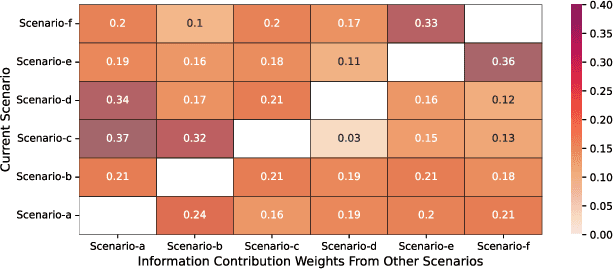
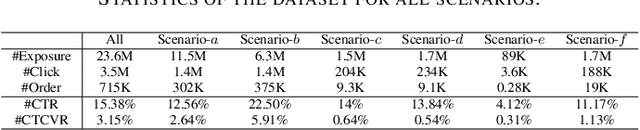
Multi-scenario & multi-task learning has been widely applied to many recommendation systems in industrial applications, wherein an effective and practical approach is to carry out multi-scenario transfer learning on the basis of the Mixture-of-Expert (MoE) architecture. However, the MoE-based method, which aims to project all information in the same feature space, cannot effectively deal with the complex relationships inherent among various scenarios and tasks, resulting in unsatisfactory performance. To tackle the problem, we propose a Hierarchical information extraction Network (HiNet) for multi-scenario and multi-task recommendation, which achieves hierarchical extraction based on coarse-to-fine knowledge transfer scheme. The multiple extraction layers of the hierarchical network enable the model to enhance the capability of transferring valuable information across scenarios while preserving specific features of scenarios and tasks. Furthermore, a novel scenario-aware attentive network module is proposed to model correlations between scenarios explicitly. Comprehensive experiments conducted on real-world industrial datasets from Meituan Meishi platform demonstrate that HiNet achieves a new state-of-the-art performance and significantly outperforms existing solutions. HiNet is currently fully deployed in two scenarios and has achieved 2.87% and 1.75% order quantity gain respectively.
S-TLLR: STDP-inspired Temporal Local Learning Rule for Spiking Neural Networks
Jun 27, 2023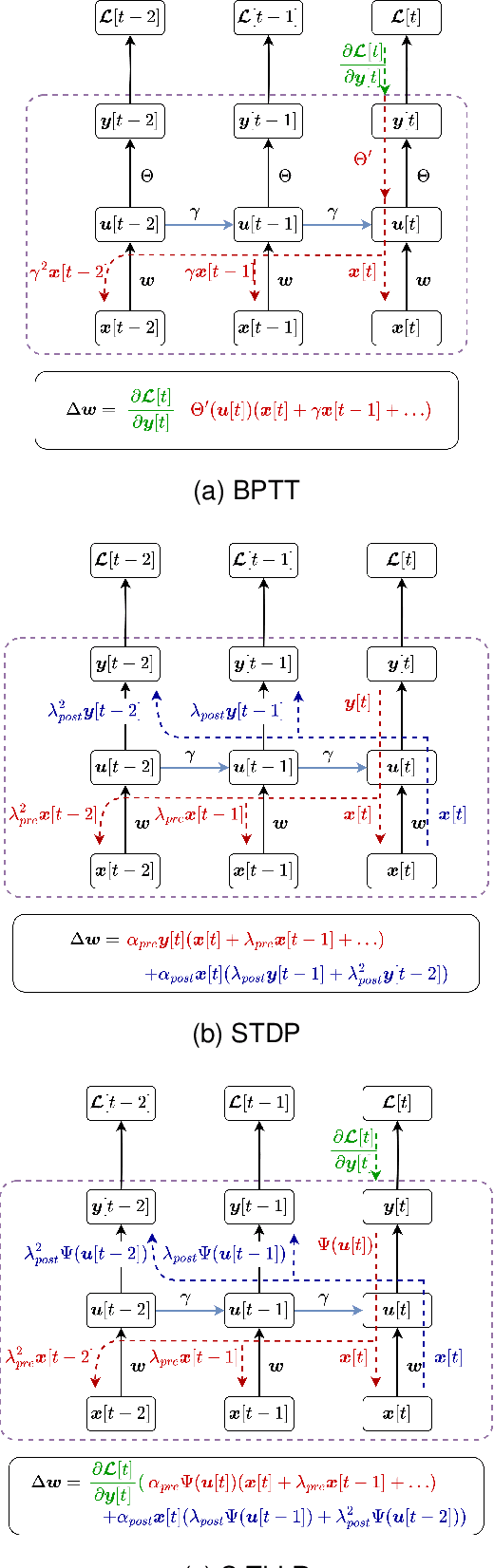
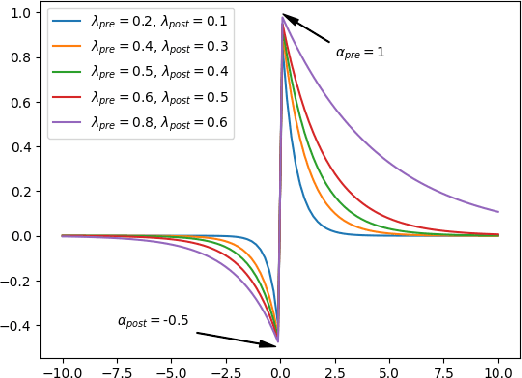
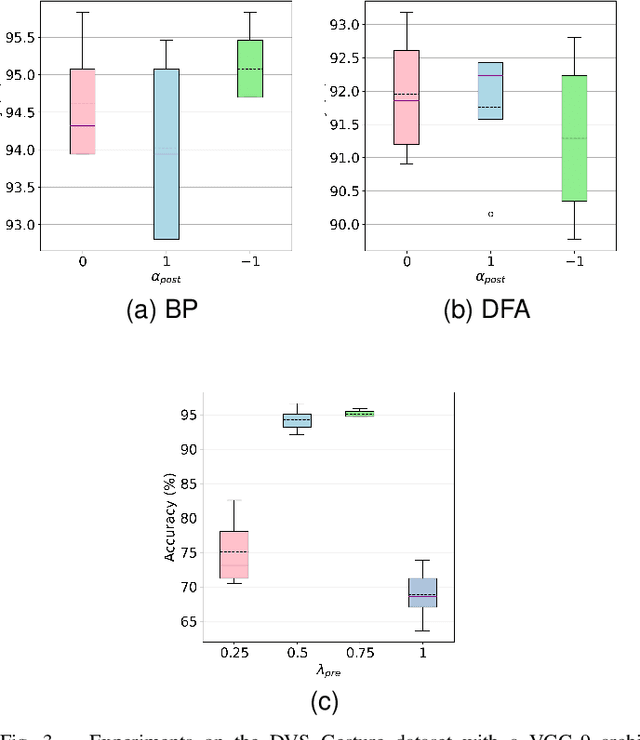
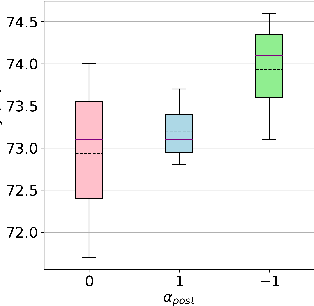
Spiking Neural Networks (SNNs) are biologically plausible models that have been identified as potentially apt for the deployment for energy-efficient intelligence at the edge, particularly for sequential learning tasks. However, training of SNNs poses a significant challenge due to the necessity for precise temporal and spatial credit assignment. Back-propagation through time (BPTT) algorithm, whilst being the most widely used method for addressing these issues, incurs a high computational cost due to its temporal dependency. Moreover, BPTT and its approximations solely utilize causal information derived from the spiking activity to compute the synaptic updates, thus neglecting non-causal relationships. In this work, we propose S-TLLR, a novel three-factor temporal local learning rule inspired by the Spike-Timing Dependent Plasticity (STDP) mechanism, aimed at training SNNs on event-based learning tasks. S-TLLR considers both causal and non-causal relationships between pre and post-synaptic activities, achieving performance comparable to BPTT and enhancing performance relative to methods using only causal information. Furthermore, S-TLLR has low memory and time complexity, which is independent of the number of time steps, rendering it suitable for online learning on low-power devices. To demonstrate the scalability of our proposed method, we have conducted extensive evaluations on event-based datasets spanning a wide range of applications, such as image and gesture recognition, audio classification, and optical flow estimation. In all the experiments, S-TLLR achieved high accuracy with a reduction in the number of computations between $1.1-10\times$.
Evidential Detection and Tracking Collaboration: New Problem, Benchmark and Algorithm for Robust Anti-UAV System
Jun 27, 2023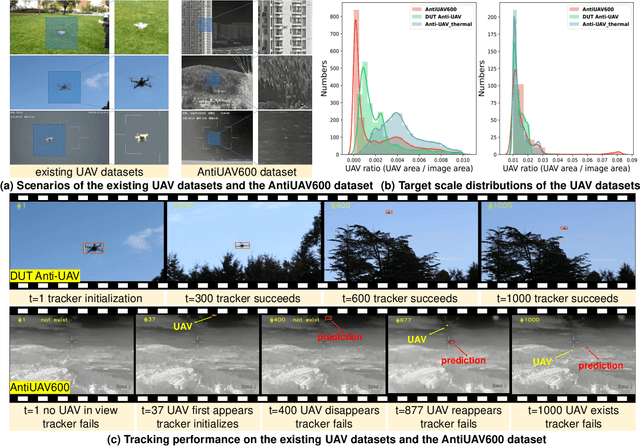
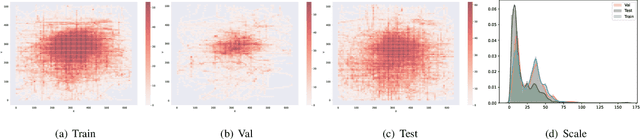
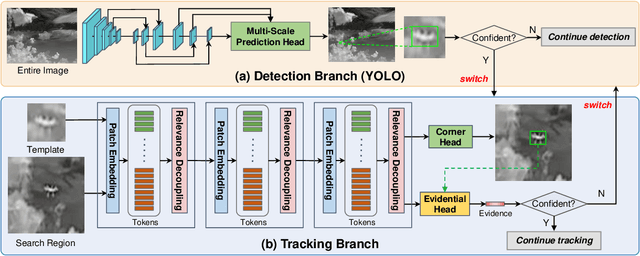
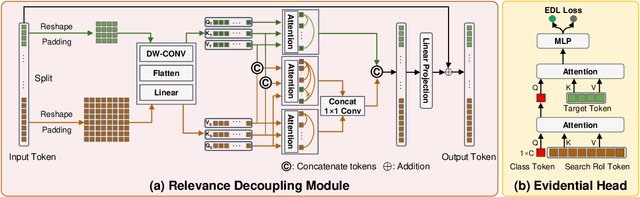
Unmanned Aerial Vehicles (UAVs) have been widely used in many areas, including transportation, surveillance, and military. However, their potential for safety and privacy violations is an increasing issue and highly limits their broader applications, underscoring the critical importance of UAV perception and defense (anti-UAV). Still, previous works have simplified such an anti-UAV task as a tracking problem, where the prior information of UAVs is always provided; such a scheme fails in real-world anti-UAV tasks (i.e. complex scenes, indeterminate-appear and -reappear UAVs, and real-time UAV surveillance). In this paper, we first formulate a new and practical anti-UAV problem featuring the UAVs perception in complex scenes without prior UAVs information. To benchmark such a challenging task, we propose the largest UAV dataset dubbed AntiUAV600 and a new evaluation metric. The AntiUAV600 comprises 600 video sequences of challenging scenes with random, fast, and small-scale UAVs, with over 723K thermal infrared frames densely annotated with bounding boxes. Finally, we develop a novel anti-UAV approach via an evidential collaboration of global UAVs detection and local UAVs tracking, which effectively tackles the proposed problem and can serve as a strong baseline for future research. Extensive experiments show our method outperforms SOTA approaches and validate the ability of AntiUAV600 to enhance UAV perception performance due to its large scale and complexity. Our dataset, pretrained models, and source codes will be released publically.
Ensemble learning for blending gridded satellite and gauge-measured precipitation data
Jul 09, 2023
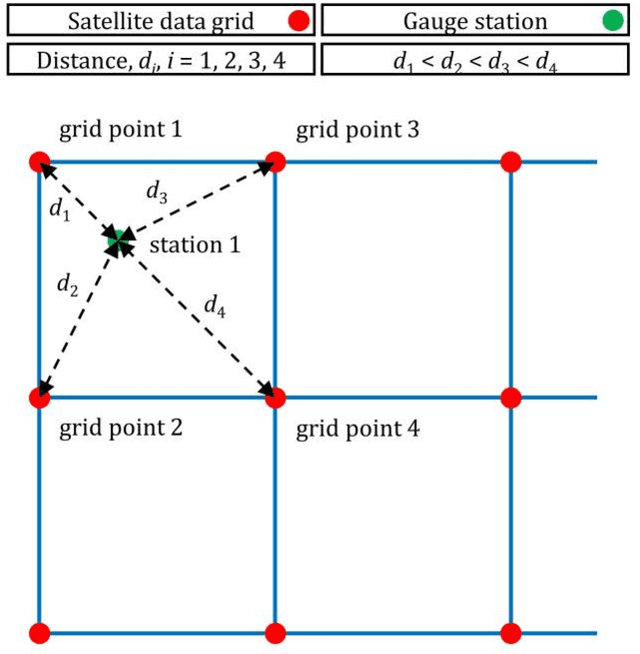
Regression algorithms are regularly used for improving the accuracy of satellite precipitation products. In this context, ground-based measurements are the dependent variable and the satellite data are the predictor variables, together with topography factors. Alongside this, it is increasingly recognised in many fields that combinations of algorithms through ensemble learning can lead to substantial predictive performance improvements. Still, a sufficient number of ensemble learners for improving the accuracy of satellite precipitation products and their large-scale comparison are currently missing from the literature. In this work, we fill this specific gap by proposing 11 new ensemble learners in the field and by extensively comparing them for the entire contiguous United States and for a 15-year period. We use monthly data from the PERSIANN (Precipitation Estimation from Remotely Sensed Information using Artificial Neural Networks) and IMERG (Integrated Multi-satellitE Retrievals for GPM) gridded datasets. We also use gauge-measured precipitation data from the Global Historical Climatology Network monthly database, version 2 (GHCNm). The ensemble learners combine the predictions by six regression algorithms (base learners), namely the multivariate adaptive regression splines (MARS), multivariate adaptive polynomial splines (poly-MARS), random forests (RF), gradient boosting machines (GBM), extreme gradient boosting (XGBoost) and Bayesian regularized neural networks (BRNN), and each of them is based on a different combiner. The combiners include the equal-weight combiner, the median combiner, two best learners and seven variants of a sophisticated stacking method. The latter stacks a regression algorithm on the top of the base learners to combine their independent predictions...
Augmenting Deep Learning Adaptation for Wearable Sensor Data through Combined Temporal-Frequency Image Encoding
Jul 03, 2023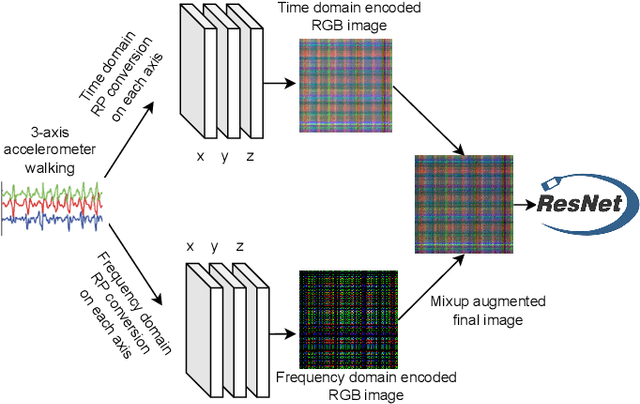
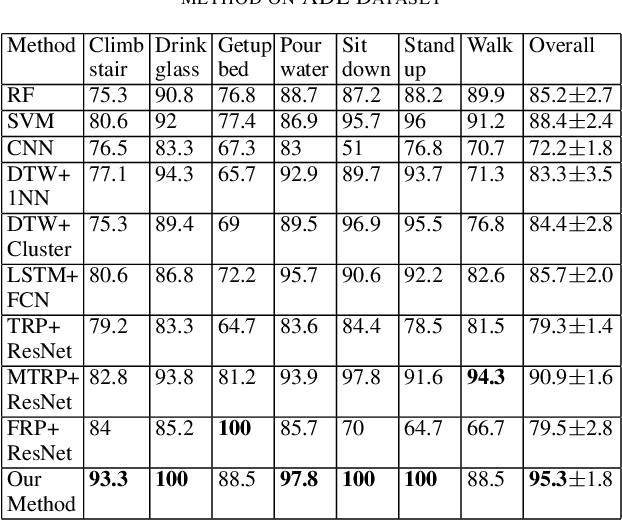
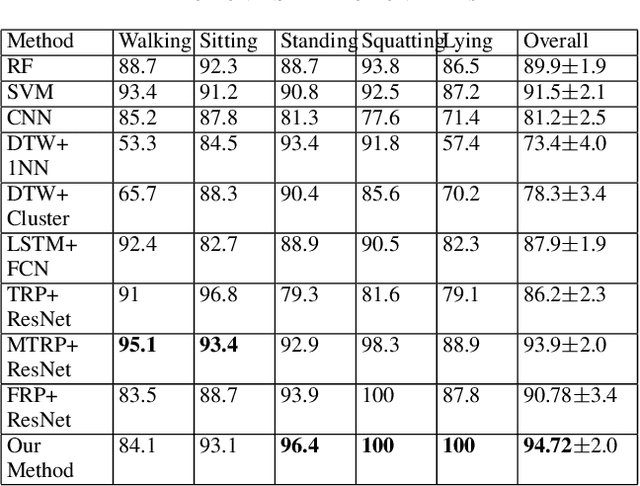
Deep learning advancements have revolutionized scalable classification in many domains including computer vision. However, when it comes to wearable-based classification and domain adaptation, existing computer vision-based deep learning architectures and pretrained models trained on thousands of labeled images for months fall short. This is primarily because wearable sensor data necessitates sensor-specific preprocessing, architectural modification, and extensive data collection. To overcome these challenges, researchers have proposed encoding of wearable temporal sensor data in images using recurrent plots. In this paper, we present a novel modified-recurrent plot-based image representation that seamlessly integrates both temporal and frequency domain information. Our approach incorporates an efficient Fourier transform-based frequency domain angular difference estimation scheme in conjunction with the existing temporal recurrent plot image. Furthermore, we employ mixup image augmentation to enhance the representation. We evaluate the proposed method using accelerometer-based activity recognition data and a pretrained ResNet model, and demonstrate its superior performance compared to existing approaches.
Dynamical Graph Echo State Networks with Snapshot Merging for Dissemination Process Classification
Jul 03, 2023The Dissemination Process Classification (DPC) is a popular application of temporal graph classification. The aim of DPC is to classify different spreading patterns of information or pestilence within a community represented by discrete-time temporal graphs. Recently, a reservoir computing-based model named Dynamical Graph Echo State Network (DynGESN) has been proposed for processing temporal graphs with relatively high effectiveness and low computational costs. In this study, we propose a novel model which combines a novel data augmentation strategy called snapshot merging with the DynGESN for dealing with DPC tasks. In our model, the snapshot merging strategy is designed for forming new snapshots by merging neighboring snapshots over time, and then multiple reservoir encoders are set for capturing spatiotemporal features from merged snapshots. After those, the logistic regression is adopted for decoding the sum-pooled embeddings into the classification results. Experimental results on six benchmark DPC datasets show that our proposed model has better classification performances than the DynGESN and several kernel-based models.
RobustL2S: Speaker-Specific Lip-to-Speech Synthesis exploiting Self-Supervised Representations
Jul 03, 2023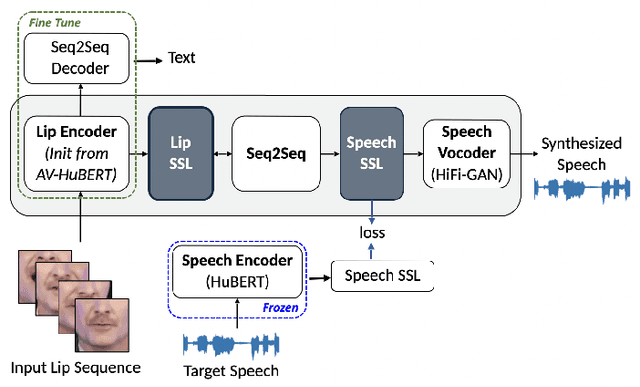
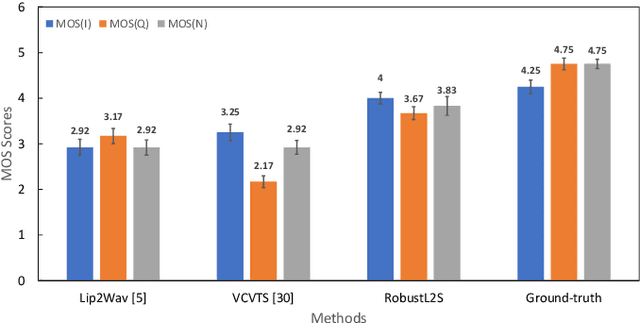
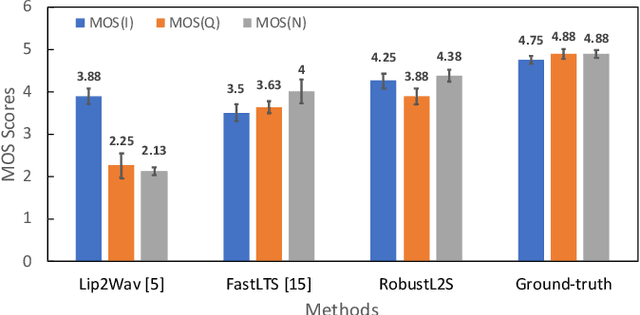
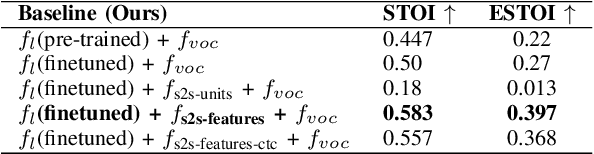
Significant progress has been made in speaker dependent Lip-to-Speech synthesis, which aims to generate speech from silent videos of talking faces. Current state-of-the-art approaches primarily employ non-autoregressive sequence-to-sequence architectures to directly predict mel-spectrograms or audio waveforms from lip representations. We hypothesize that the direct mel-prediction hampers training/model efficiency due to the entanglement of speech content with ambient information and speaker characteristics. To this end, we propose RobustL2S, a modularized framework for Lip-to-Speech synthesis. First, a non-autoregressive sequence-to-sequence model maps self-supervised visual features to a representation of disentangled speech content. A vocoder then converts the speech features into raw waveforms. Extensive evaluations confirm the effectiveness of our setup, achieving state-of-the-art performance on the unconstrained Lip2Wav dataset and the constrained GRID and TCD-TIMIT datasets. Speech samples from RobustL2S can be found at https://neha-sherin.github.io/RobustL2S/
Enlighten-anything:When Segment Anything Model Meets Low-light Image Enhancement
Jun 21, 2023
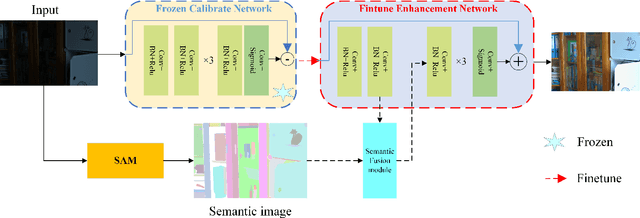


Image restoration is a low-level visual task, and most CNN methods are designed as black boxes, lacking transparency and intrinsic aesthetics. Many unsupervised approaches ignore the degradation of visible information in low-light scenes, which will seriously affect the aggregation of complementary information and also make the fusion algorithm unable to produce satisfactory fusion results under extreme conditions. In this paper, we propose Enlighten-anything, which is able to enhance and fuse the semantic intent of SAM segmentation with low-light images to obtain fused images with good visual perception. The generalization ability of unsupervised learning is greatly improved, and experiments on LOL dataset are conducted to show that our method improves 3db in PSNR over baseline and 8 in SSIM. zero-shot learning of SAM introduces a powerful aid for unsupervised low-light enhancement. The source code of Enlighten-anything can be obtained from https://github.com/zhangbaijin/enlighten-anything
Energy-Efficient URLLC Service Provision via a Near-Space Information Network
Apr 09, 2023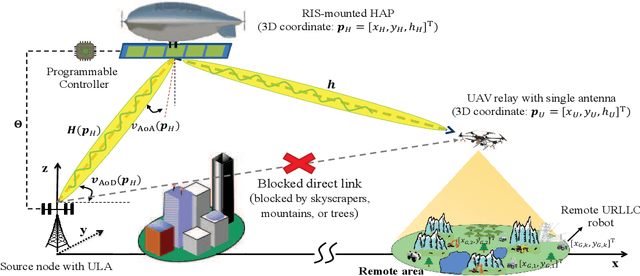
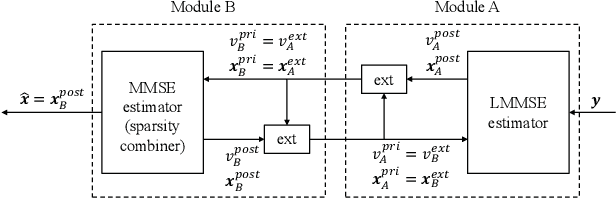
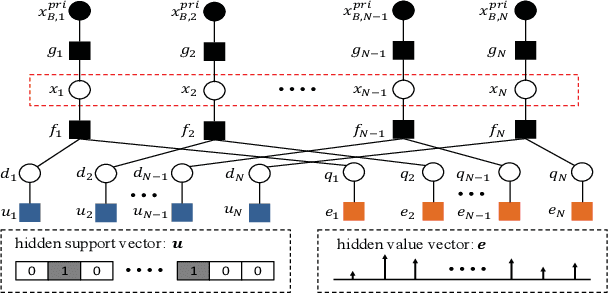
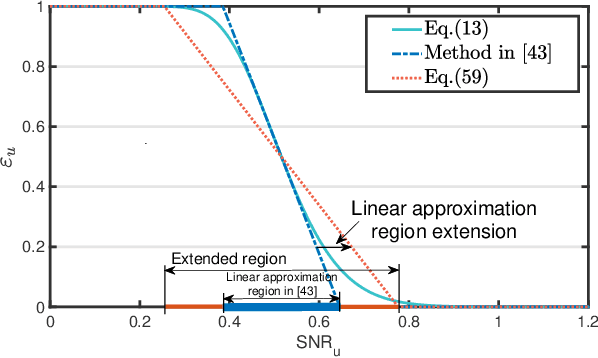
The integration of a near-space information network (NSIN) with the reconfigurable intelligent surface (RIS) is envisioned to significantly enhance the communication performance of future wireless communication systems by proactively altering wireless channels. This paper investigates the problem of deploying a RIS-integrated NSIN to provide energy-efficient, ultra-reliable and low-latency communications (URLLC) services. We mathematically formulate this problem as a resource optimization problem, aiming to maximize the effective throughput and minimize the system power consumption, subject to URLLC and physical resource constraints. The formulated problem is challenging in terms of accurate channel estimation, RIS phase alignment, theoretical analysis, and effective solution. We propose a joint resource allocation algorithm to handle these challenges. In this algorithm, we develop an accurate channel estimation approach by exploring message passing and optimize phase shifts of RIS reflecting elements to further increase the channel gain. Besides, we derive an analysis-friend expression of decoding error probability and decompose the problem into two-layered optimization problems by analyzing the monotonicity, which makes the formulated problem analytically tractable. Extensive simulations have been conducted to verify the performance of the proposed algorithm. Simulation results show that the proposed algorithm can achieve outstanding channel estimation performance and is more energy-efficient than diverse benchmark algorithms.
Learning to Incentivize Information Acquisition: Proper Scoring Rules Meet Principal-Agent Model
Mar 15, 2023
We study the incentivized information acquisition problem, where a principal hires an agent to gather information on her behalf. Such a problem is modeled as a Stackelberg game between the principal and the agent, where the principal announces a scoring rule that specifies the payment, and then the agent then chooses an effort level that maximizes her own profit and reports the information. We study the online setting of such a problem from the principal's perspective, i.e., designing the optimal scoring rule by repeatedly interacting with the strategic agent. We design a provably sample efficient algorithm that tailors the UCB algorithm (Auer et al., 2002) to our model, which achieves a sublinear $T^{2/3}$-regret after $T$ iterations. Our algorithm features a delicate estimation procedure for the optimal profit of the principal, and a conservative correction scheme that ensures the desired agent's actions are incentivized. Furthermore, a key feature of our regret bound is that it is independent of the number of states of the environment.