 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bootstrapping Reinforcement Learning with Imitation for Vision-Based Agile Flight
Mar 18, 2024
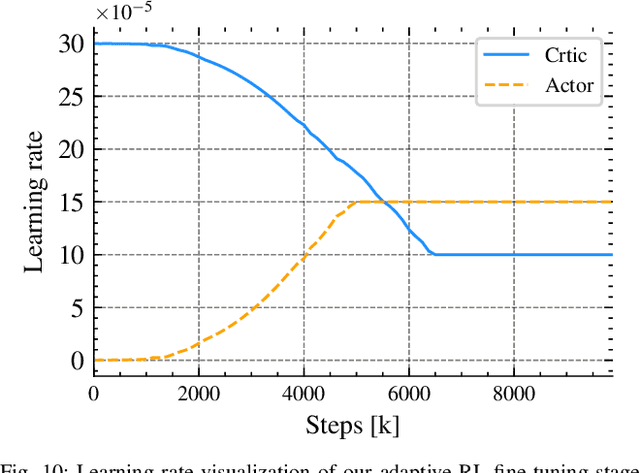
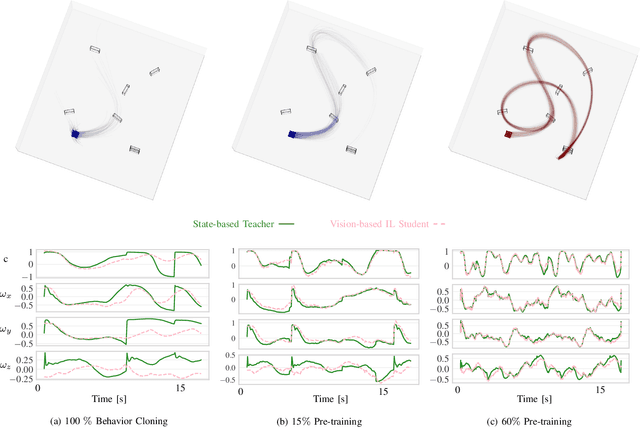


We combine the effectiveness of Reinforcement Learning (RL) and the efficiency of Imitation Learning (IL) in the context of vision-based, autonomous drone racing. We focus on directly processing visual input without explicit state estimation. While RL offers a general framework for learning complex controllers through trial and error, it faces challenges regarding sample efficiency and computational demands due to the high dimensionality of visual inputs. Conversely, IL demonstrates efficiency in learning from visual demonstrations but is limited by the quality of those demonstrations and faces issues like covariate shift. To overcome these limitations, we propose a novel training framework combining RL and IL's advantages. Our framework involves three stages: initial training of a teacher policy using privileged state information, distilling this policy into a student policy using IL, and performance-constrained adaptive RL fine-tuning. Our experiments in both simulated and real-world environments demonstrate that our approach achieves superior performance and robustness than IL or RL alone in navigating a quadrotor through a racing course using only visual information without explicit state estimation.
FLex: Joint Pose and Dynamic Radiance Fields Optimization for Stereo Endoscopic Videos
Mar 18, 2024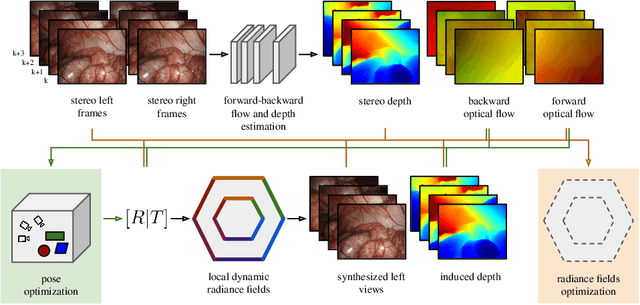
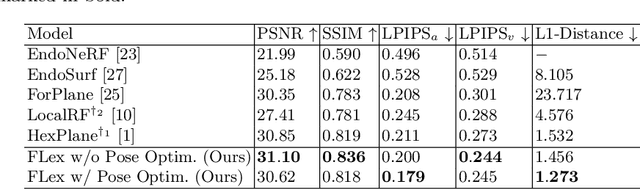
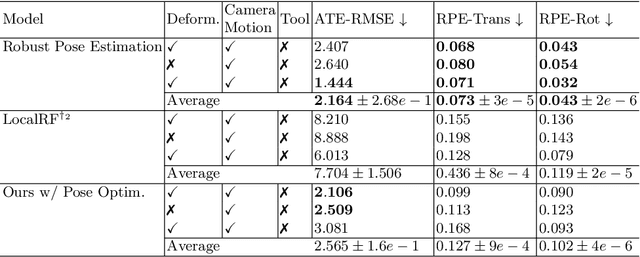
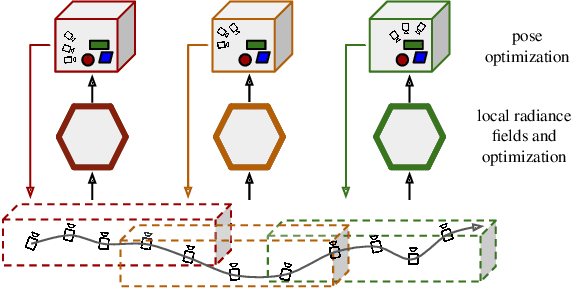
Reconstruction of endoscopic scenes is an important asset for various medical applications, from post-surgery analysis to educational training. Neural rendering has recently shown promising results in endoscopic reconstruction with deforming tissue. However, the setup has been restricted to a static endoscope, limited deformation, or required an external tracking device to retrieve camera pose information of the endoscopic camera. With FLex we adress the challenging setup of a moving endoscope within a highly dynamic environment of deforming tissue. We propose an implicit scene separation into multiple overlapping 4D neural radiance fields (NeRFs) and a progressive optimization scheme jointly optimizing for reconstruction and camera poses from scratch. This improves the ease-of-use and allows to scale reconstruction capabilities in time to process surgical videos of 5,000 frames and more; an improvement of more than ten times compared to the state of the art while being agnostic to external tracking information. Extensive evaluations on the StereoMIS dataset show that FLex significantly improves the quality of novel view synthesis while maintaining competitive pose accuracy.
CRS-Diff: Controllable Generative Remote Sensing Foundation Model
Mar 18, 2024
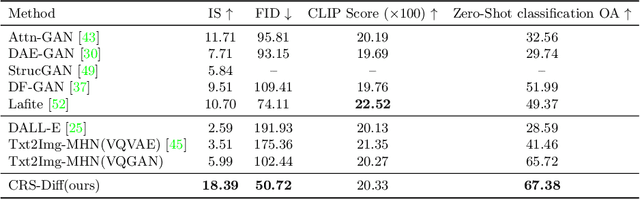
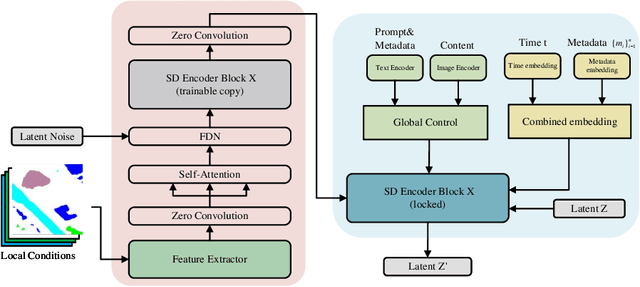
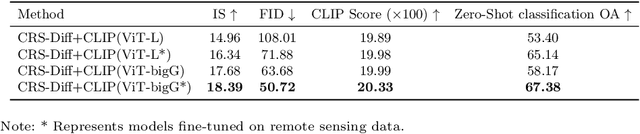
The emergence of diffusion models has revolutionized the field of image generation, providing new methods for creating high-quality, high-resolution images across various applications. However, the potential of these models for generating domain-specific images, particularly remote sensing (RS) images, remains largely untapped. RS images that are notable for their high resolution, extensive coverage, and rich information content, bring new challenges that general diffusion models may not adequately address. This paper proposes CRS-Diff, a pioneering diffusion modeling framework specifically tailored for generating remote sensing imagery, leveraging the inherent advantages of diffusion models while integrating advanced control mechanisms to ensure that the imagery is not only visually clear but also enriched with geographic and temporal information. The model integrates global and local control inputs, enabling precise combinations of generation conditions to refine the generation process. A comprehensive evaluation of CRS-Diff has demonstrated its superior capability to generate RS imagery both in a single condition and multiple conditions compared with previous methods in terms of image quality and diversity.
EMIE-MAP: Large-Scale Road Surface Reconstruction Based on Explicit Mesh and Implicit Encoding
Mar 18, 2024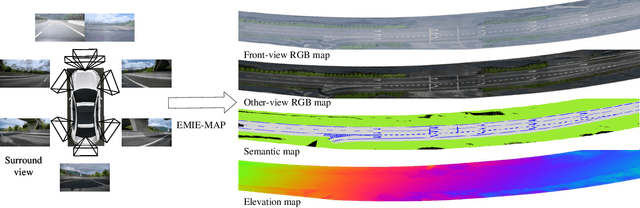

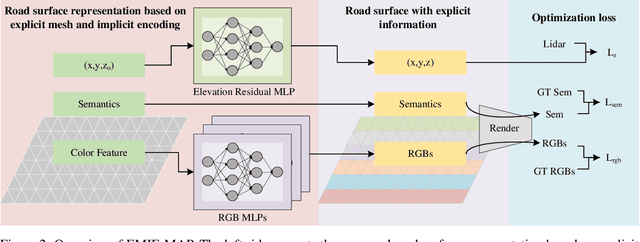

Road surface reconstruction plays a vital role in autonomous driving systems, enabling road lane perception and high-precision mapping. Recently, neural implicit encoding has achieved remarkable results in scene representation, particularly in the realistic rendering of scene textures. However, it faces challenges in directly representing geometric information for large-scale scenes. To address this, we propose EMIE-MAP, a novel method for large-scale road surface reconstruction based on explicit mesh and implicit encoding. The road geometry is represented using explicit mesh, where each vertex stores implicit encoding representing the color and semantic information. To overcome the difficulty in optimizing road elevation, we introduce a trajectory-based elevation initialization and an elevation residual learning method based on Multi-Layer Perceptron (MLP). Additionally, by employing implicit encoding and multi-camera color MLPs decoding, we achieve separate modeling of scene physical properties and camera characteristics, allowing surround-view reconstruction compatible with different camera models. Our method achieves remarkable road surface reconstruction performance in a variety of real-world challenging scenarios.
Depth Information Assisted Collaborative Mutual Promotion Network for Single Image Dehazing
Mar 02, 2024Recovering a clear image from a single hazy image is an open inverse problem. Although significant research progress has been made, most existing methods ignore the effect that downstream tasks play in promoting upstream dehazing. From the perspective of the haze generation mechanism, there is a potential relationship between the depth information of the scene and the hazy image. Based on this, we propose a dual-task collaborative mutual promotion framework to achieve the dehazing of a single image. This framework integrates depth estimation and dehazing by a dual-task interaction mechanism and achieves mutual enhancement of their performance. To realize the joint optimization of the two tasks, an alternative implementation mechanism with the difference perception is developed. On the one hand, the difference perception between the depth maps of the dehazing result and the ideal image is proposed to promote the dehazing network to pay attention to the non-ideal areas of the dehazing. On the other hand, by improving the depth estimation performance in the difficult-to-recover areas of the hazy image, the dehazing network can explicitly use the depth information of the hazy image to assist the clear image recovery. To promote the depth estimation, we propose to use the difference between the dehazed image and the ground truth to guide the depth estimation network to focus on the dehazed unideal areas. It allows dehazing and depth estimation to leverage their strengths in a mutually reinforcing manner. Experimental results show that the proposed method can achieve better performance than that of the state-of-the-art approaches.
Global-guided Focal Neural Radiance Field for Large-scale Scene Rendering
Mar 19, 2024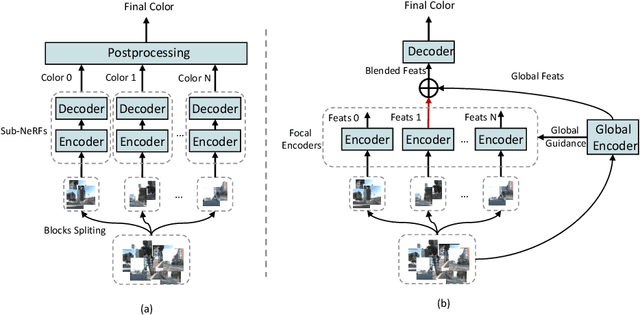

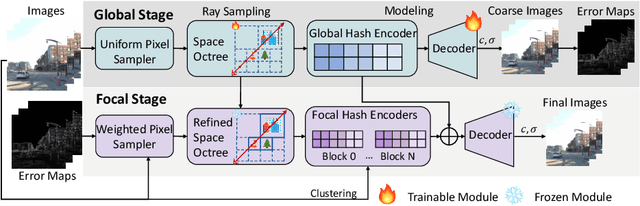
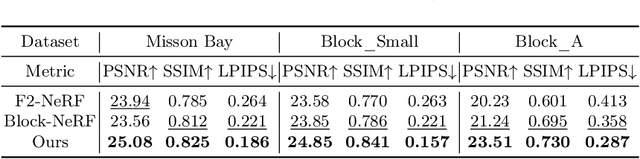
Neural radiance fields~(NeRF) have recently been applied to render large-scale scenes. However, their limited model capacity typically results in blurred rendering results. Existing large-scale NeRFs primarily address this limitation by partitioning the scene into blocks, which are subsequently handled by separate sub-NeRFs. These sub-NeRFs, trained from scratch and processed independently, lead to inconsistencies in geometry and appearance across the scene. Consequently, the rendering quality fails to exhibit significant improvement despite the expansion of model capacity. In this work, we present global-guided focal neural radiance field (GF-NeRF) that achieves high-fidelity rendering of large-scale scenes. Our proposed GF-NeRF utilizes a two-stage (Global and Focal) architecture and a global-guided training strategy. The global stage obtains a continuous representation of the entire scene while the focal stage decomposes the scene into multiple blocks and further processes them with distinct sub-encoders. Leveraging this two-stage architecture, sub-encoders only need fine-tuning based on the global encoder, thus reducing training complexity in the focal stage while maintaining scene-wide consistency. Spatial information and error information from the global stage also benefit the sub-encoders to focus on crucial areas and effectively capture more details of large-scale scenes. Notably, our approach does not rely on any prior knowledge about the target scene, attributing GF-NeRF adaptable to various large-scale scene types, including street-view and aerial-view scenes. We demonstrate that our method achieves high-fidelity, natural rendering results on various types of large-scale datasets. Our project page: https://shaomq2187.github.io/GF-NeRF/
Bayesian multi-exposure image fusion for robust high dynamic range ptychography
Mar 19, 2024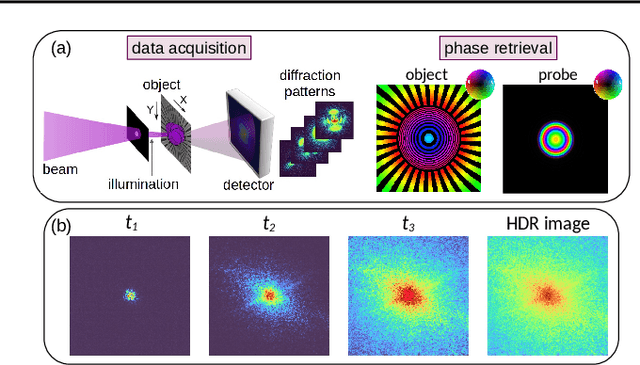
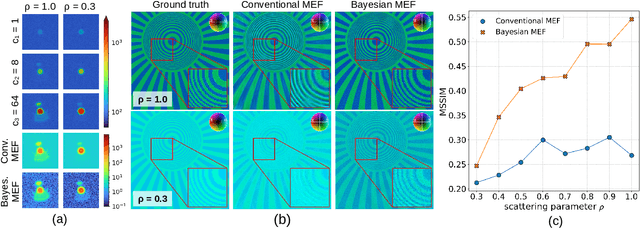
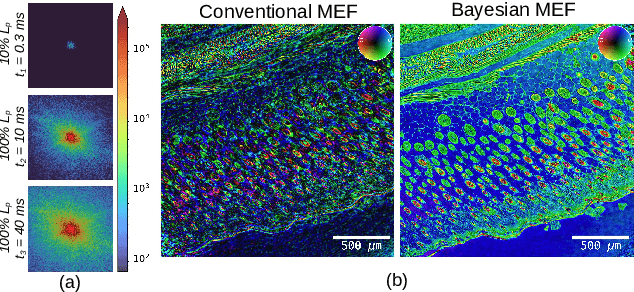
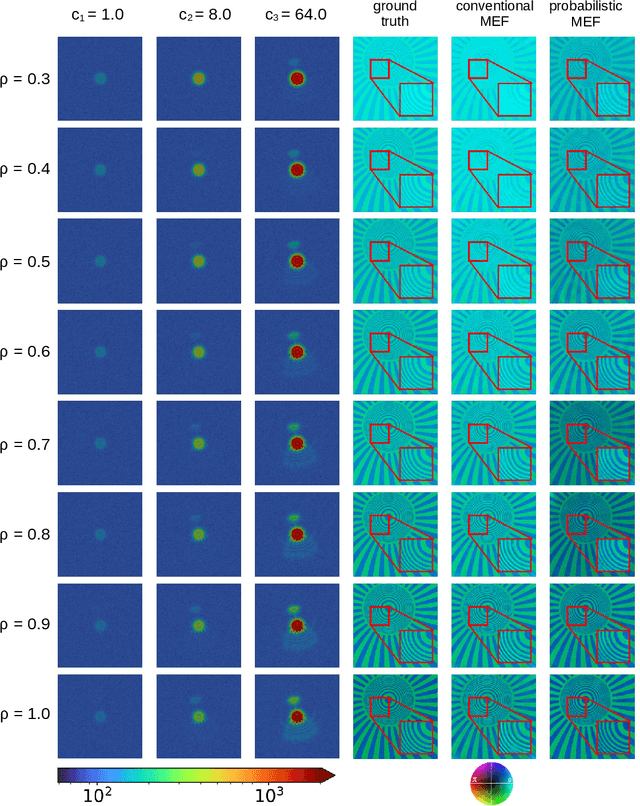
Image information is restricted by the dynamic range of the detector, which can be addressed using multi-exposure image fusion (MEF). The conventional MEF approach employed in ptychography is often inadequate under conditions of low signal-to-noise ratio (SNR) or variations in illumination intensity. To address this, we developed a Bayesian approach for MEF based on a modified Poisson noise model that considers the background and saturation. Our method outperforms conventional MEF under challenging experimental conditions, as demonstrated by the synthetic and experimental data. Furthermore, this method is versatile and applicable to any imaging scheme requiring high dynamic range (HDR).
Uncertainty Driven Active Learning for Image Segmentation in Underwater Inspection
Mar 20, 2024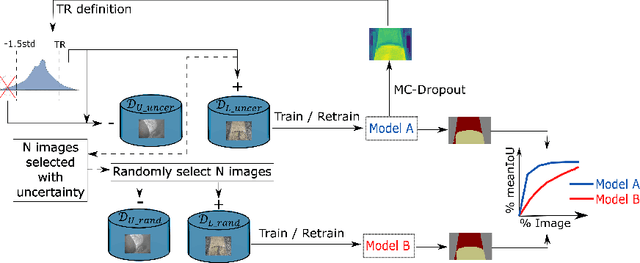
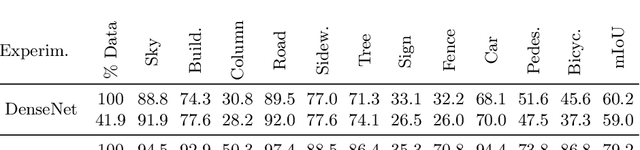


Active learning aims to select the minimum amount of data to train a model that performs similarly to a model trained with the entire dataset. We study the potential of active learning for image segmentation in underwater infrastructure inspection tasks, where large amounts of data are typically collected. The pipeline inspection images are usually semantically repetitive but with great variations in quality. We use mutual information as the acquisition function, calculated using Monte Carlo dropout. To assess the effectiveness of the framework, DenseNet and HyperSeg are trained with the CamVid dataset using active learning. In addition, HyperSeg is trained with a pipeline inspection dataset of over 50,000 images. For the pipeline dataset, HyperSeg with active learning achieved 67.5% meanIoU using 12.5% of the data, and 61.4% with the same amount of randomly selected images. This shows that using active learning for segmentation models in underwater inspection tasks can lower the cost significantly.
Cell Tracking in C. elegans with Cell Position Heatmap-Based Alignment and Pairwise Detection
Mar 20, 2024
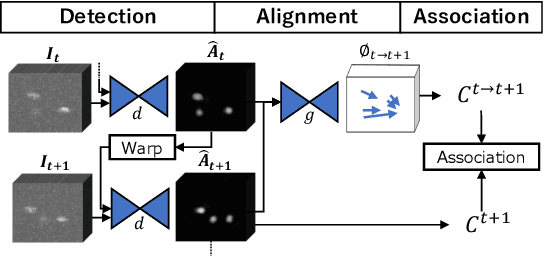
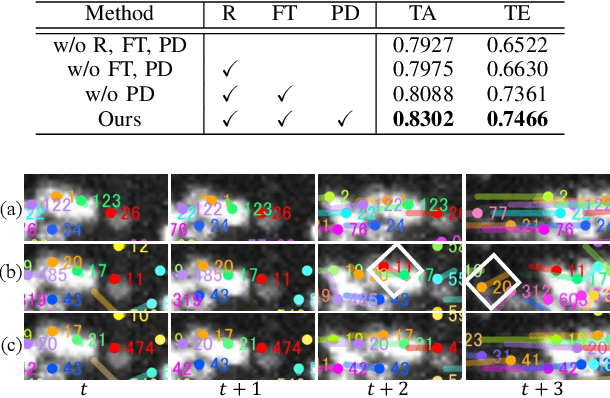

3D cell tracking in a living organism has a crucial role in live cell image analysis. Cell tracking in C. elegans has two difficulties. First, cell migration in a consecutive frame is large since they move their head during scanning. Second, cell detection is often inconsistent in consecutive frames due to touching cells and low-contrast images, and these inconsistent detections affect the tracking performance worse. In this paper, we propose a cell tracking method to address these issues, which has two main contributions. First, we introduce cell position heatmap-based non-rigid alignment with test-time fine-tuning, which can warp the detected points to near the positions at the next frame. Second, we propose a pairwise detection method, which uses the information of detection results at the previous frame for detecting cells at the current frame. The experimental results demonstrate the effectiveness of each module, and the proposed method achieved the best performance in comparison.
Motion Generation from Fine-grained Textual Descriptions
Mar 20, 2024



The task of text2motion is to generate motion sequences from given textual descriptions, where a model should explore the interactions between natural language instructions and human body movements. While most existing works are confined to coarse-grained motion descriptions (e.g., "A man squats."), fine-grained ones specifying movements of relevant body parts are barely explored. Models trained with coarse texts may not be able to learn mappings from fine-grained motion-related words to motion primitives, resulting in the failure in generating motions from unseen descriptions. In this paper, we build a large-scale language-motion dataset with fine-grained textual descriptions, FineHumanML3D, by feeding GPT-3.5-turbo with delicate prompts. Accordingly, we design a new text2motion model, FineMotionDiffuse, which makes full use of fine-grained textual information. Our experiments show that FineMotionDiffuse trained on FineHumanML3D acquires good results in quantitative evaluation. We also find this model can better generate spatially/chronologically composite motions by learning the implicit mappings from simple descriptions to the corresponding basic motions.