 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ACDNet: Attention-guided Collaborative Decision Network for Effective Medication Recommendation
Jul 06, 2023
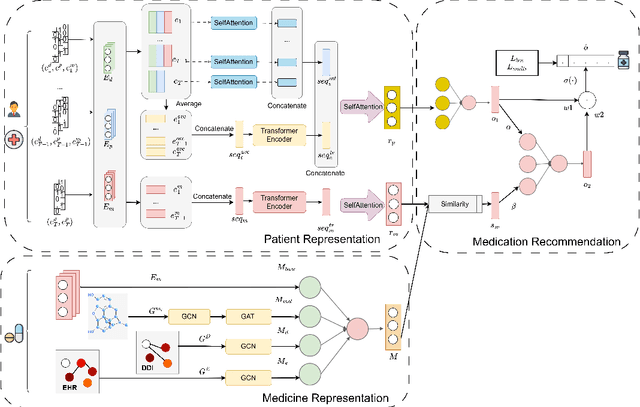
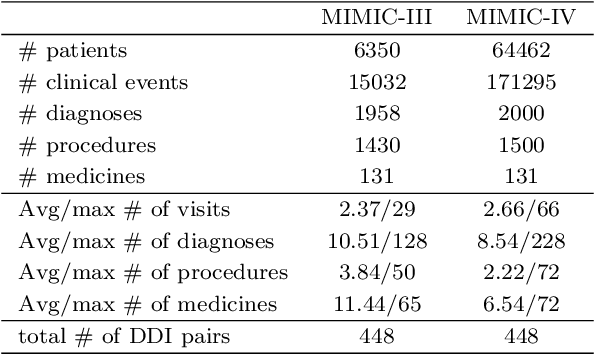
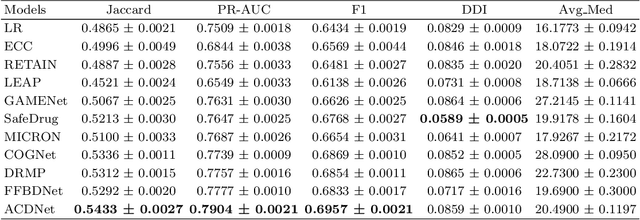
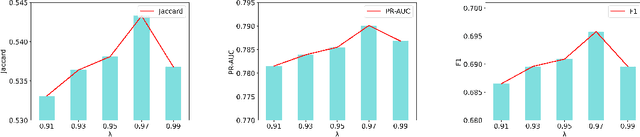
Medication recommendation using Electronic Health Records (EHR) is challenging due to complex medical data. Current approaches extract longitudinal information from patient EHR to personalize recommendations. However, existing models often lack sufficient patient representation and overlook the importance of considering the similarity between a patient's medication records and specific medicines. Therefore, an Attention-guided Collaborative Decision Network (ACDNet) for medication recommendation is proposed in this paper. Specifically, ACDNet utilizes attention mechanism and Transformer to effectively capture patient health conditions and medication records by modeling their historical visits at both global and local levels. ACDNet also employs a collaborative decision framework, utilizing the similarity between medication records and medicine representation to facilitate the recommendation process. The experimental results on two extensive medical datasets, MIMIC-III and MIMIC-IV, clearly demonstrate that ACDNet outperforms state-of-the-art models in terms of Jaccard, PR-AUC, and F1 score, reaffirming its superiority. Moreover, the ablation experiments provide solid evidence of the effectiveness of each module in ACDNet, validating their contribution to the overall performance. Furthermore, a detailed case study reinforces the effectiveness of ACDNet in medication recommendation based on EHR data, showcasing its practical value in real-world healthcare scenarios.
The Distortion of Binomial Voting Defies Expectation
Jun 27, 2023In computational social choice, the distortion of a voting rule quantifies the degree to which the rule overcomes limited preference information to select a socially desirable outcome. This concept has been investigated extensively, but only through a worst-case lens. Instead, we study the expected distortion of voting rules with respect to an underlying distribution over voter utilities. Our main contribution is the design and analysis of a novel and intuitive rule, binomial voting, which provides strong expected distortion guarantees for all distributions.
CT-based Subchondral Bone Microstructural Analysis in Knee Osteoarthritis via MR-Guided Distillation Learning
Jul 11, 2023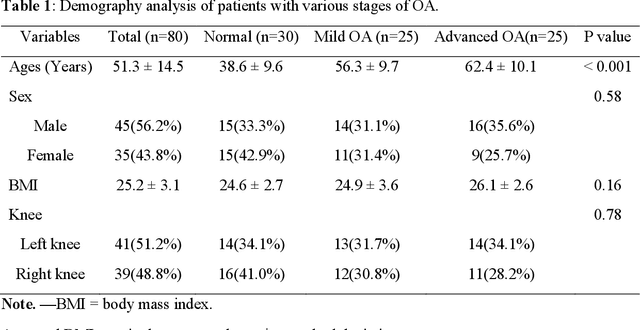

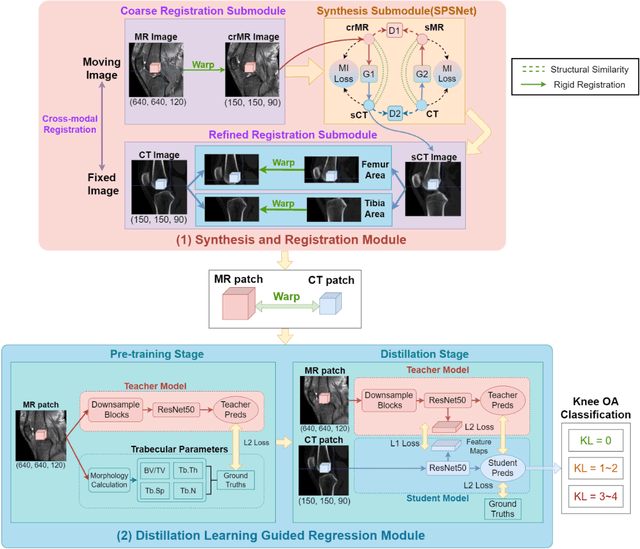
Background: MR-based subchondral bone effectively predicts knee osteoarthritis. However, its clinical application is limited by the cost and time of MR. Purpose: We aim to develop a novel distillation-learning-based method named SRRD for subchondral bone microstructural analysis using easily-acquired CT images, which leverages paired MR images to enhance the CT-based analysis model during training. Materials and Methods: Knee joint images of both CT and MR modalities were collected from October 2020 to May 2021. Firstly, we developed a GAN-based generative model to transform MR images into CT images, which was used to establish the anatomical correspondence between the two modalities. Next, we obtained numerous patches of subchondral bone regions of MR images, together with their trabecular parameters (BV / TV, Tb. Th, Tb. Sp, Tb. N) from the corresponding CT image patches via regression. The distillation-learning technique was used to train the regression model and transfer MR structural information to the CT-based model. The regressed trabecular parameters were further used for knee osteoarthritis classification. Results: A total of 80 participants were evaluated. CT-based regression results of trabecular parameters achieved intra-class correlation coefficients (ICCs) of 0.804, 0.773, 0.711, and 0.622 for BV / TV, Tb. Th, Tb. Sp, and Tb. N, respectively. The use of distillation learning significantly improved the performance of the CT-based knee osteoarthritis classification method using the CNN approach, yielding an AUC score of 0.767 (95% CI, 0.681-0.853) instead of 0.658 (95% CI, 0.574-0.742) (p<.001). Conclusions: The proposed SRRD method showed high reliability and validity in MR-CT registration, regression, and knee osteoarthritis classification, indicating the feasibility of subchondral bone microstructural analysis based on CT images.
Latent Space Perspicacity and Interpretation Enhancement (LS-PIE) Framework
Jul 11, 2023Linear latent variable models such as principal component analysis (PCA), independent component analysis (ICA), canonical correlation analysis (CCA), and factor analysis (FA) identify latent directions (or loadings) either ordered or unordered. The data is then projected onto the latent directions to obtain their projected representations (or scores). For example, PCA solvers usually rank the principal directions by explaining the most to least variance, while ICA solvers usually return independent directions unordered and often with single sources spread across multiple directions as multiple sub-sources, which is of severe detriment to their usability and interpretability. This paper proposes a general framework to enhance latent space representations for improving the interpretability of linear latent spaces. Although the concepts in this paper are language agnostic, the framework is written in Python. This framework automates the clustering and ranking of latent vectors to enhance the latent information per latent vector, as well as, the interpretation of latent vectors. Several innovative enhancements are incorporated including latent ranking (LR), latent scaling (LS), latent clustering (LC), and latent condensing (LCON). For a specified linear latent variable model, LR ranks latent directions according to a specified metric, LS scales latent directions according to a specified metric, LC automatically clusters latent directions into a specified number of clusters, while, LCON automatically determines an appropriate number of clusters into which to condense the latent directions for a given metric. Additional functionality of the framework includes single-channel and multi-channel data sources, data preprocessing strategies such as Hankelisation to seamlessly expand the applicability of linear latent variable models (LLVMs) to a wider variety of data. The effectiveness of LR, LS, and LCON are showcased on two crafted foundational problems with two applied latent variable models, namely, PCA and ICA.
Implicit spoken language diarization
Jun 22, 2023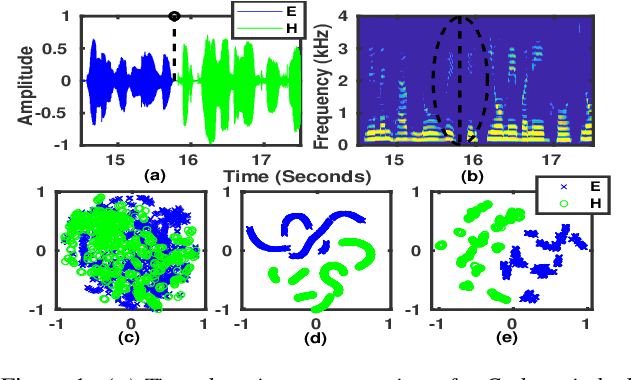
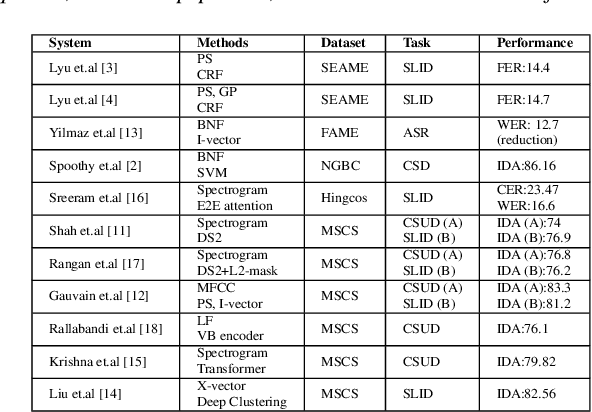
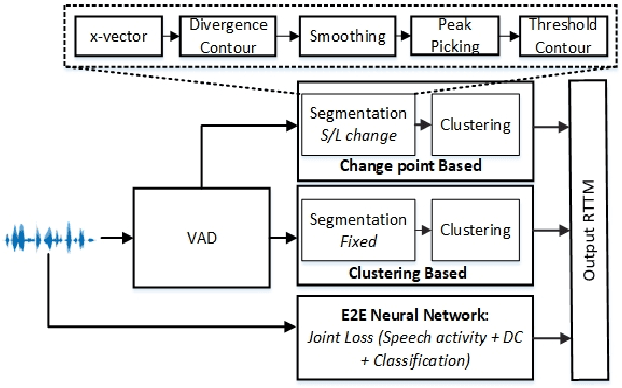
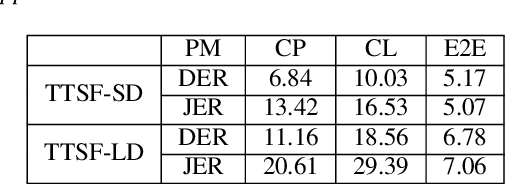
Spoken language diarization (LD) and related tasks are mostly explored using the phonotactic approach. Phonotactic approaches mostly use explicit way of language modeling, hence requiring intermediate phoneme modeling and transcribed data. Alternatively, the ability of deep learning approaches to model temporal dynamics may help for the implicit modeling of language information through deep embedding vectors. Hence this work initially explores the available speaker diarization frameworks that capture speaker information implicitly to perform LD tasks. The performance of the LD system on synthetic code-switch data using the end-to-end x-vector approach is 6.78% and 7.06%, and for practical data is 22.50% and 60.38%, in terms of diarization error rate and Jaccard error rate (JER), respectively. The performance degradation is due to the data imbalance and resolved to some extent by using pre-trained wave2vec embeddings that provide a relative improvement of 30.74% in terms of JER.
Predictive Patentomics: Forecasting Innovation Success and Valuation with ChatGPT
Jun 22, 2023
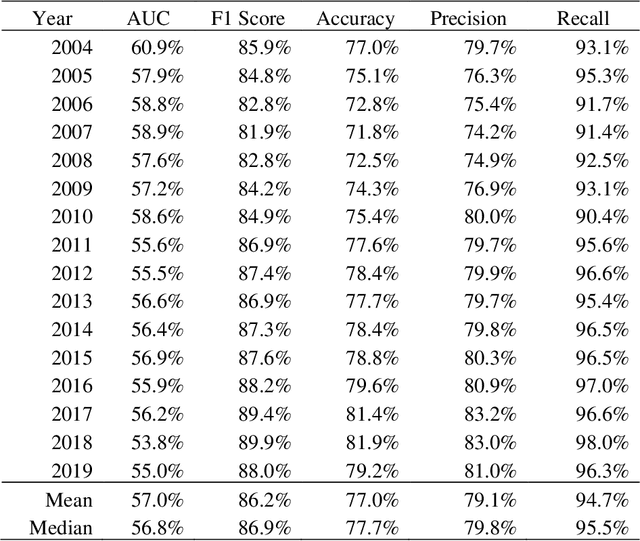
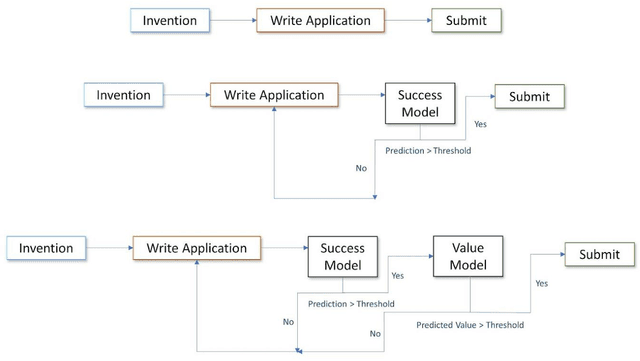
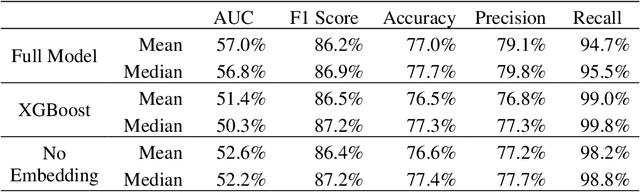
Analysis of innovation has been fundamentally limited by conventional approaches to broad, structural variables. This paper pushes the boundaries, taking an LLM approach to patent analysis with the groundbreaking ChatGPT technology. OpenAI's state-of-the-art textual embedding accesses complex information about the quality and impact of each invention to power deep learning predictive models. The nuanced embedding drives a 24% incremental improvement in R-squared predicting patent value and clearly isolates the worst and best applications. These models enable a revision of the contemporary Kogan, Papanikolaou, Seru, and Stoffman (2017) valuation of patents by a median deviation of 1.5 times, accounting for potential institutional predictions. Furthermore, the market fails to incorporate timely information about applications; a long-short portfolio based on predicted acceptance rates achieves significant abnormal returns of 3.3% annually. The models provide an opportunity to revolutionize startup and small-firm corporate policy vis-a-vis patenting.
Enlighten Anything: When Segment Anything Model Meets Low-Light Image Enhancement
Jun 22, 2023
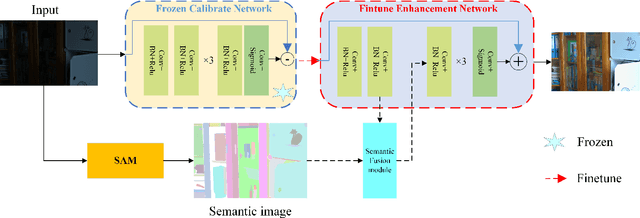


Image restoration is a low-level visual task, and most CNN methods are designed as black boxes, lacking transparency and intrinsic aesthetics. Many unsupervised approaches ignore the degradation of visible information in low-light scenes, which will seriously affect the aggregation of complementary information and also make the fusion algorithm unable to produce satisfactory fusion results under extreme conditions. In this paper, we propose Enlighten-anything, which is able to enhance and fuse the semantic intent of SAM segmentation with low-light images to obtain fused images with good visual perception. The generalization ability of unsupervised learning is greatly improved, and experiments on LOL dataset are conducted to show that our method improves 3db in PSNR over baseline and 8 in SSIM. Zero-shot learning of SAM introduces a powerful aid for unsupervised low-light enhancement. The source code of Enlighten Anything can be obtained from https://github.com/zhangbaijin/enlighten-anything
A novel approach for predicting epidemiological forecasting parameters based on real-time signals and Data Assimilation
Jul 03, 2023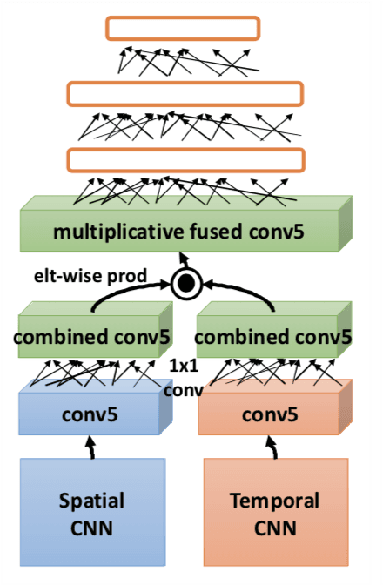
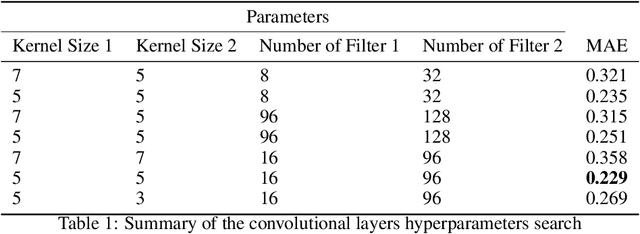
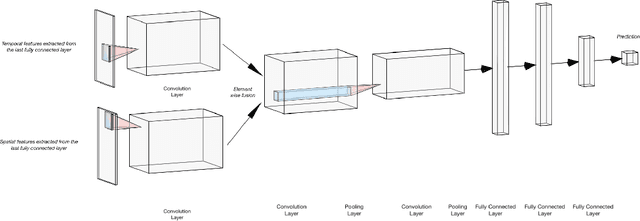
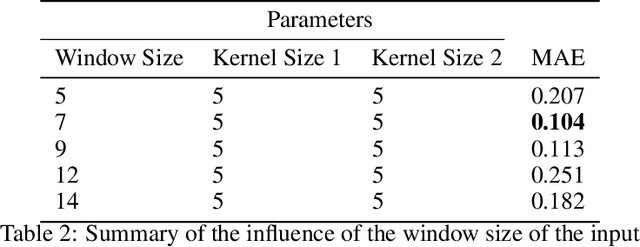
This paper proposes a novel approach to predict epidemiological parameters by integrating new real-time signals from various sources of information, such as novel social media-based population density maps and Air Quality data. We implement an ensemble of Convolutional Neural Networks (CNN) models using various data sources and fusion methodology to build robust predictions and simulate several dynamic parameters that could improve the decision-making process for policymakers. Additionally, we used data assimilation to estimate the state of our system from fused CNN predictions. The combination of meteorological signals and social media-based population density maps improved the performance and flexibility of our prediction of the COVID-19 outbreak in London. While the proposed approach outperforms standard models, such as compartmental models traditionally used in disease forecasting (SEIR), generating robust and consistent predictions allows us to increase the stability of our model while increasing its accuracy.
Cross-modal Place Recognition in Image Databases using Event-based Sensors
Jul 03, 2023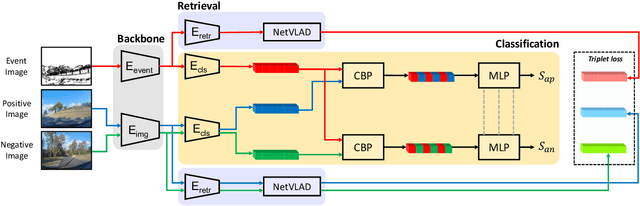



Visual place recognition is an important problem towards global localization in many robotics tasks. One of the biggest challenges is that it may suffer from illumination or appearance changes in surrounding environments. Event cameras are interesting alternatives to frame-based sensors as their high dynamic range enables robust perception in difficult illumination conditions. However, current event-based place recognition methods only rely on event information, which restricts downstream applications of VPR. In this paper, we present the first cross-modal visual place recognition framework that is capable of retrieving regular images from a database given an event query. Our method demonstrates promising results with respect to the state-of-the-art frame-based and event-based methods on the Brisbane-Event-VPR dataset under different scenarios. We also verify the effectiveness of the combination of retrieval and classification, which can boost performance by a large margin.
MWPRanker: An Expression Similarity Based Math Word Problem Retriever
Jul 03, 2023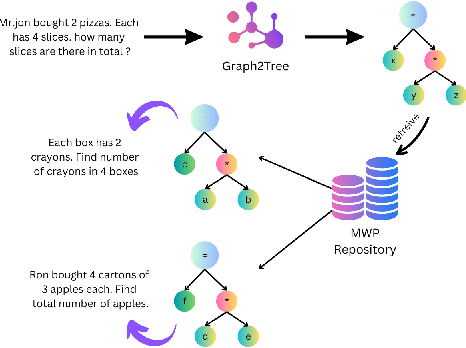
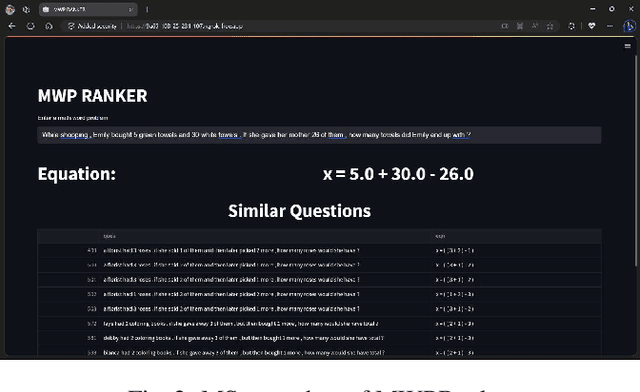
Math Word Problems (MWPs) in online assessments help test the ability of the learner to make critical inferences by interpreting the linguistic information in them. To test the mathematical reasoning capabilities of the learners, sometimes the problem is rephrased or the thematic setting of the original MWP is changed. Since manual identification of MWPs with similar problem models is cumbersome, we propose a tool in this work for MWP retrieval. We propose a hybrid approach to retrieve similar MWPs with the same problem model. In our work, the problem model refers to the sequence of operations to be performed to arrive at the solution. We demonstrate that our tool is useful for the mentioned tasks and better than semantic similarity-based approaches, which fail to capture the arithmetic and logical sequence of the MWPs. A demo of the tool can be found at https://www.youtube.com/watch?v=gSQWP3chFIs