 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ReadProbe: A Demo of Retrieval-Enhanced Large Language Models to Support Lateral Reading
Jun 13, 2023
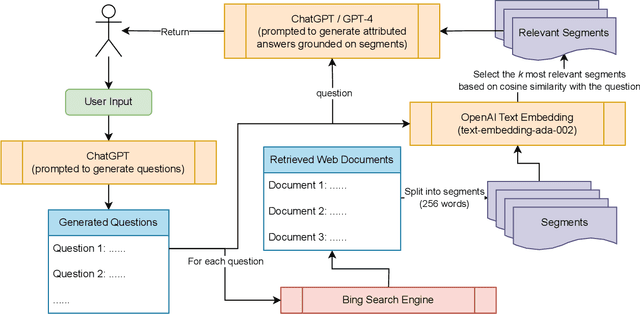

With the rapid growth and spread of online misinformation, people need tools to help them evaluate the credibility and accuracy of online information. Lateral reading, a strategy that involves cross-referencing information with multiple sources, may be an effective approach to achieving this goal. In this paper, we present ReadProbe, a tool to support lateral reading, powered by generative large language models from OpenAI and the Bing search engine. Our tool is able to generate useful questions for lateral reading, scour the web for relevant documents, and generate well-attributed answers to help people better evaluate online information. We made a web-based application to demonstrate how ReadProbe can help reduce the risk of being misled by false information. The code is available at https://github.com/DakeZhang1998/ReadProbe. An earlier version of our tool won the first prize in a national AI misinformation hackathon.
Dual-Gated Fusion with Prefix-Tuning for Multi-Modal Relation Extraction
Jun 19, 2023

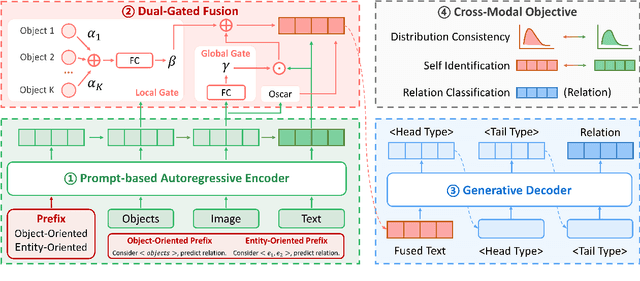
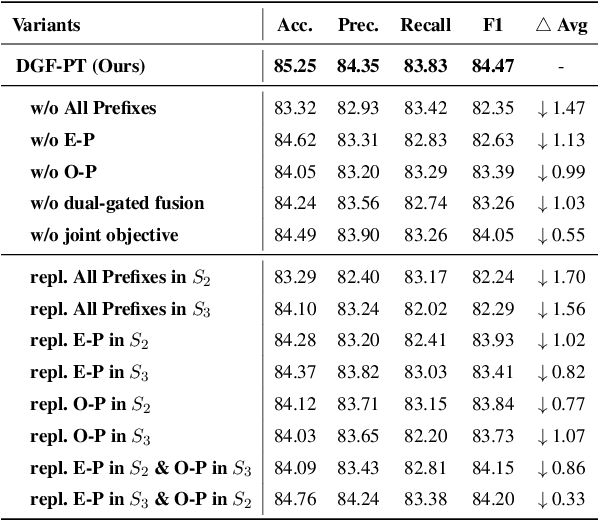
Multi-Modal Relation Extraction (MMRE) aims at identifying the relation between two entities in texts that contain visual clues. Rich visual content is valuable for the MMRE task, but existing works cannot well model finer associations among different modalities, failing to capture the truly helpful visual information and thus limiting relation extraction performance. In this paper, we propose a novel MMRE framework to better capture the deeper correlations of text, entity pair, and image/objects, so as to mine more helpful information for the task, termed as DGF-PT. We first propose a prompt-based autoregressive encoder, which builds the associations of intra-modal and inter-modal features related to the task, respectively by entity-oriented and object-oriented prefixes. To better integrate helpful visual information, we design a dual-gated fusion module to distinguish the importance of image/objects and further enrich text representations. In addition, a generative decoder is introduced with entity type restriction on relations, better filtering out candidates. Extensive experiments conducted on the benchmark dataset show that our approach achieves excellent performance compared to strong competitors, even in the few-shot situation.
Machine Learning for Real-Time Anomaly Detection in Optical Networks
Jun 19, 2023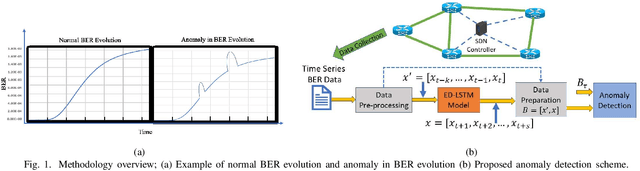
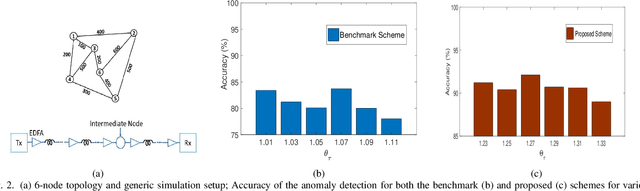
This work proposes a real-time anomaly detection scheme that leverages the multi-step ahead prediction capabilities of encoder-decoder (ED) deep learning models with recurrent units. Specifically, an encoder-decoder is used to model soft-failure evolution over a long future horizon (i.e., for several days ahead) by analyzing past quality-of-transmission (QoT) observations. This information is subsequently used for real-time anomaly detection (e.g., of attack incidents), as the knowledge of how the QoT is expected to evolve allows capturing unexpected network behavior. Specifically, for anomaly detection, a statistical hypothesis testing scheme is used, alleviating the limitations of supervised (SL) and unsupervised learning (UL) schemes, usually applied for this purpose. Indicatively, the proposed scheme eliminates the need for labeled anomalies, required when SL is applied, and the need for on-line analyzing entire datasets to identify abnormal instances (i.e., UL). Overall, it is shown that by utilizing QoT evolution information, the proposed approach can effectively detect abnormal deviations in real-time. Importantly, it is shown that the information concerning soft-failure evolution (i.e., QoT predictions) is essential to accurately detect anomalies.
Fourier-Mixed Window Attention: Accelerating Informer for Long Sequence Time-Series Forecasting
Jul 02, 2023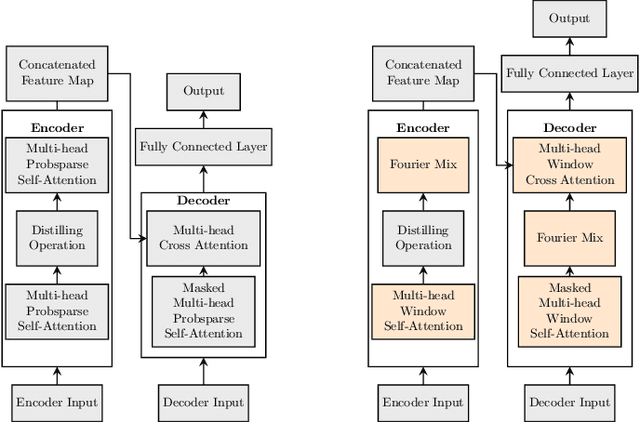

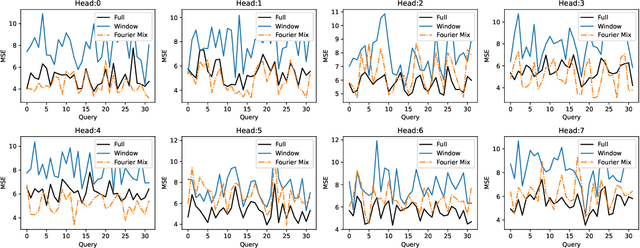

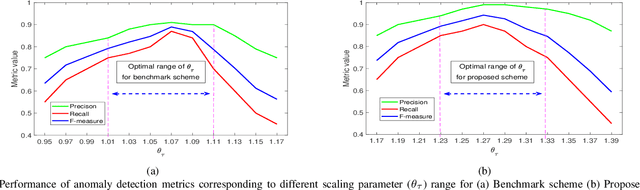
We study a fast local-global window-based attention method to accelerate Informer for long sequence time-series forecasting. While window attention is local and a considerable computational saving, it lacks the ability to capture global token information which is compensated by a subsequent Fourier transform block. Our method, named FWin, does not rely on query sparsity hypothesis and an empirical approximation underlying the ProbSparse attention of Informer. Through experiments on univariate and multivariate datasets, we show that FWin transformers improve the overall prediction accuracies of Informer while accelerating its inference speeds by 40 to 50 %. We also show in a nonlinear regression model that a learned FWin type attention approaches or even outperforms softmax full attention based on key vectors extracted from an Informer model's full attention layer acting on time series data.
Real-World Video for Zoom Enhancement based on Spatio-Temporal Coupling
Jun 24, 2023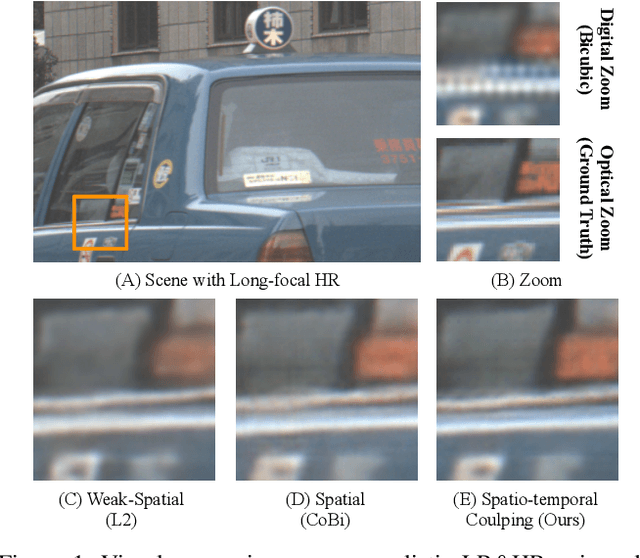
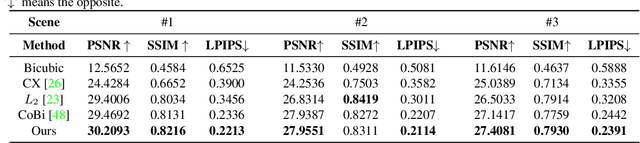
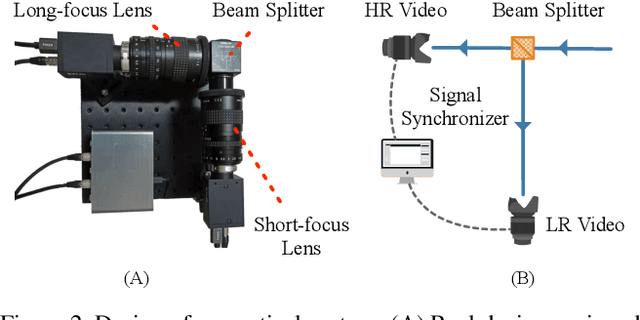
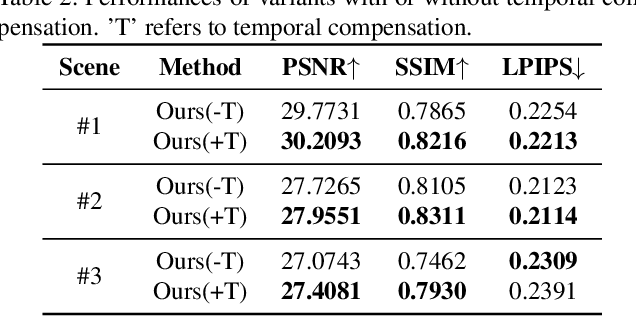
In recent years, single-frame image super-resolution (SR) has become more realistic by considering the zooming effect and using real-world short- and long-focus image pairs. In this paper, we further investigate the feasibility of applying realistic multi-frame clips to enhance zoom quality via spatio-temporal information coupling. Specifically, we first built a real-world video benchmark, VideoRAW, by a synchronized co-axis optical system. The dataset contains paired short-focus raw and long-focus sRGB videos of different dynamic scenes. Based on VideoRAW, we then presented a Spatio-Temporal Coupling Loss, termed as STCL. The proposed STCL is intended for better utilization of information from paired and adjacent frames to align and fuse features both temporally and spatially at the feature level. The outperformed experimental results obtained in different zoom scenarios demonstrate the superiority of integrating real-world video dataset and STCL into existing SR models for zoom quality enhancement, and reveal that the proposed method can serve as an advanced and viable tool for video zoom.
A Universal Semantic-Geometric Representation for Robotic Manipulation
Jun 18, 2023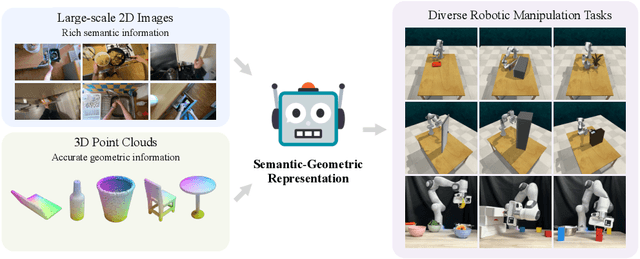
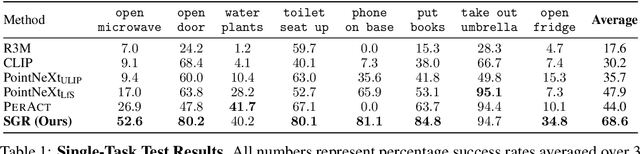
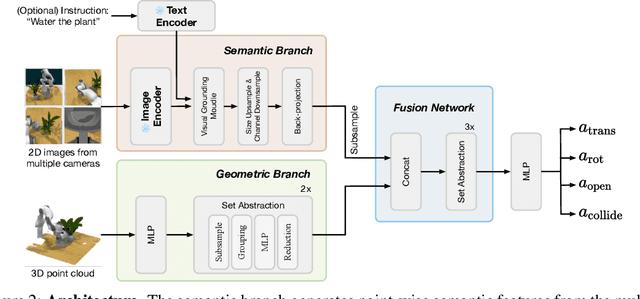
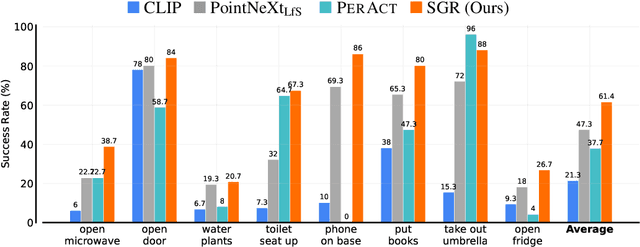
Robots rely heavily on sensors, especially RGB and depth cameras, to perceive and interact with the world. RGB cameras record 2D images with rich semantic information while missing precise spatial information. On the other side, depth cameras offer critical 3D geometry data but capture limited semantics. Therefore, integrating both modalities is crucial for learning representations for robotic perception and control. However, current research predominantly focuses on only one of these modalities, neglecting the benefits of incorporating both. To this end, we present Semantic-Geometric Representation (SGR), a universal perception module for robotics that leverages the rich semantic information of large-scale pre-trained 2D models and inherits the merits of 3D spatial reasoning. Our experiments demonstrate that SGR empowers the agent to successfully complete a diverse range of simulated and real-world robotic manipulation tasks, outperforming state-of-the-art methods significantly in both single-task and multi-task settings. Furthermore, SGR possesses the unique capability to generalize to novel semantic attributes, setting it apart from the other methods.
Comparative analysis of various web crawler algorithms
Jun 21, 2023This presentation focuses on the importance of web crawling and page ranking algorithms in dealing with the massive amount of data present on the World Wide Web. As the web continues to grow exponentially, efficient search and retrieval methods become crucial. Web crawling is a process that converts unstructured data into structured data, enabling effective information retrieval. Additionally, page ranking algorithms play a significant role in assessing the quality and popularity of web pages. The presentation explores the background of these algorithms and evaluates five different crawling algorithms: Shark Search, Priority-Based Queue, Naive Bayes, Breadth-First, and Depth-First. The goal is to identify the most effective algorithm for crawling web pages. By understanding these algorithms, we can enhance our ability to navigate the web and extract valuable information efficiently.
Channel Adaptive DL based Joint Source-Channel Coding without A Prior Knowledge
Jun 27, 2023
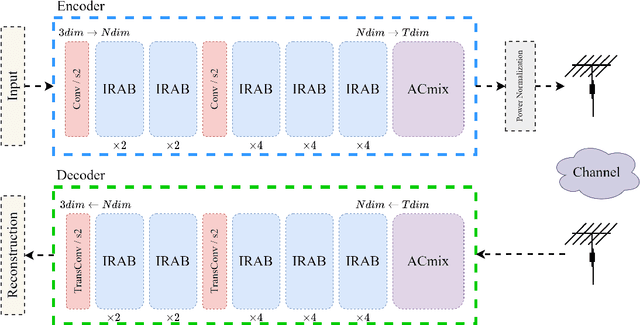
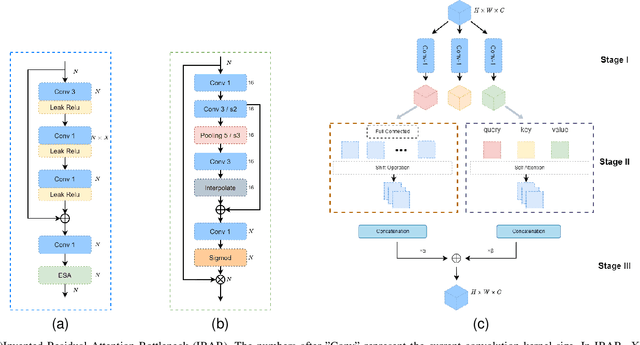
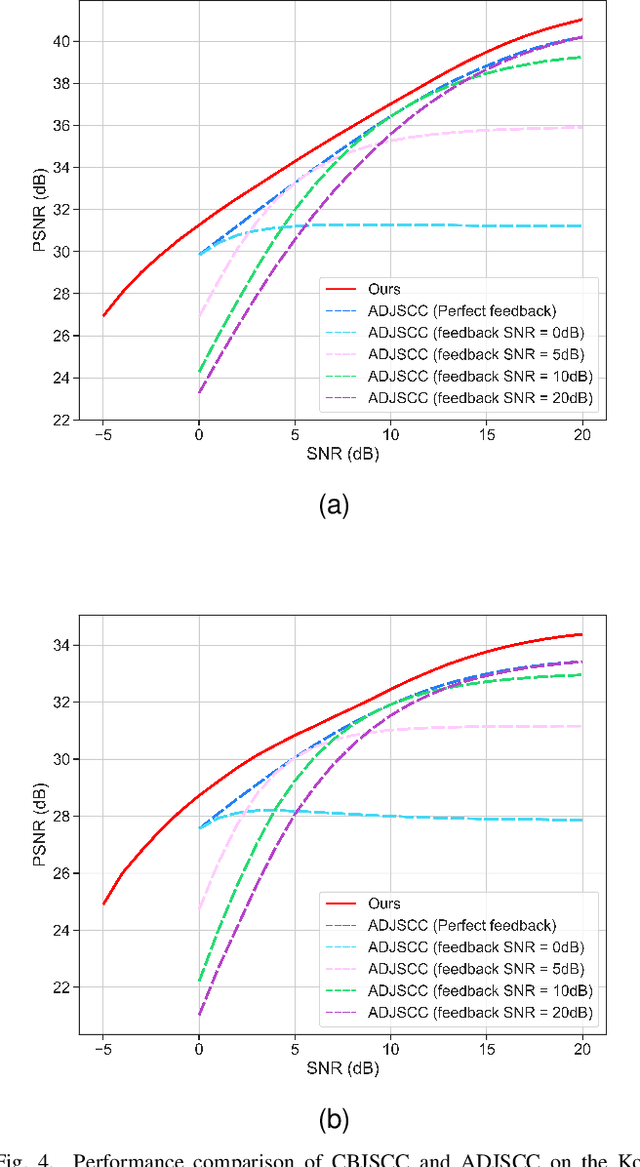
Significant progress has been made in wireless Joint Source-Channel Coding (JSCC) using deep learning techniques. The latest DL-based image JSCC methods have demonstrated exceptional performance across various signal-to-noise ratio (SNR) levels during transmission, while also avoiding cliff effects. However, current channel adaptive JSCC methods rely heavily on channel prior knowledge, which can lead to performance degradation in practical applications due to channel mismatch effects. This paper proposes a novel approach for image transmission, called Channel Blind Joint Source-Channel Coding (CBJSCC). CBJSCC utilizes Deep Learning techniques to achieve exceptional performance across various signal-to-noise ratio (SNR) levels during transmission, without relying on channel prior information. We have designed an Inverted Residual Attention Bottleneck (IRAB) module for the model, which can effectively reduce the number of parameters while expanding the receptive field. In addition, we have incorporated a convolution and self-attention mixed encoding module to establish long-range dependency relationships between channel symbols. Our experiments have shown that CBJSCC outperforms existing channel adaptive DL-based JSCC methods that rely on feedback information. Furthermore, we found that channel estimation does not significantly benefit CBJSCC, which provides insights for the future design of DL-based JSCC methods. The reliability of the proposed method is further demonstrated through an analysis of the model bottleneck and its adaptability to different domains, as shown by our experiments.
Communication-Efficient Federated Learning through Importance Sampling
Jun 25, 2023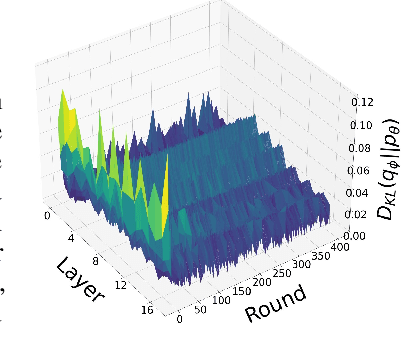
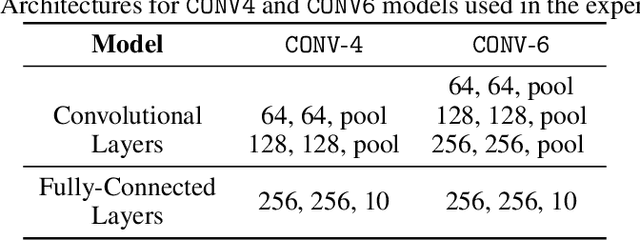
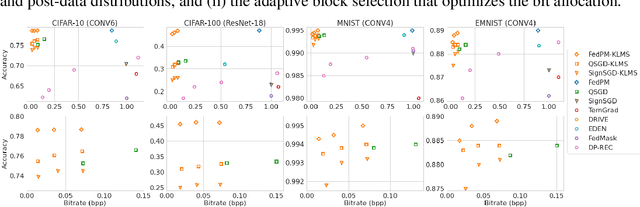
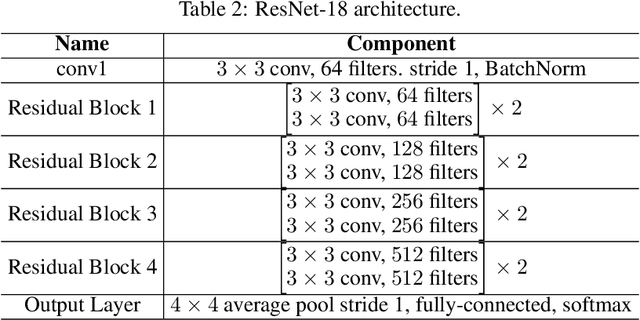
The high communication cost of sending model updates from the clients to the server is a significant bottleneck for scalable federated learning (FL). Among existing approaches, state-of-the-art bitrate-accuracy tradeoffs have been achieved using stochastic compression methods -- in which the client $n$ sends a sample from a client-only probability distribution $q_{\phi^{(n)}}$, and the server estimates the mean of the clients' distributions using these samples. However, such methods do not take full advantage of the FL setup where the server, throughout the training process, has side information in the form of a pre-data distribution $p_{\theta}$ that is close to the client's distribution $q_{\phi^{(n)}}$ in Kullback-Leibler (KL) divergence. In this work, we exploit this closeness between the clients' distributions $q_{\phi^{(n)}}$'s and the side information $p_{\theta}$ at the server, and propose a framework that requires approximately $D_{KL}(q_{\phi^{(n)}}|| p_{\theta})$ bits of communication. We show that our method can be integrated into many existing stochastic compression frameworks such as FedPM, Federated SGLD, and QSGD to attain the same (and often higher) test accuracy with up to $50$ times reduction in the bitrate.
A Conditional Flow Variational Autoencoder for Controllable Synthesis of Virtual Populations of Anatomy
Jun 26, 2023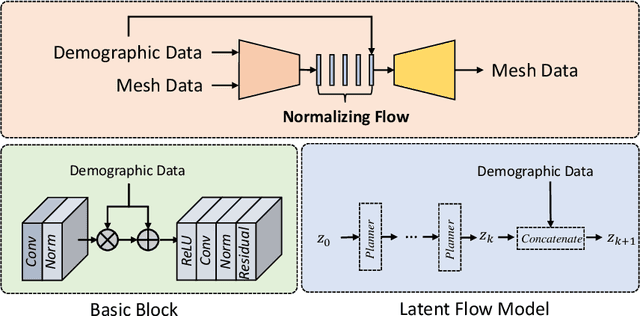
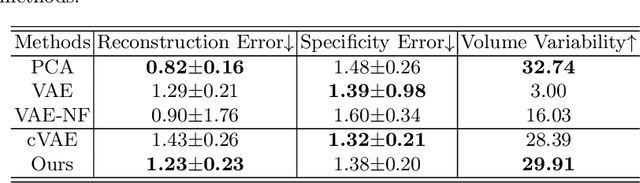

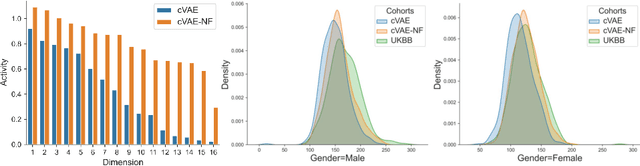
Generating virtual populations (VPs) of anatomy is essential for conducting in-silico trials of medical devices. Typically, the generated VP should capture sufficient variability while remaining plausible, and should reflect specific characteristics and patient demographics observed in real populations. It is desirable in several applications to synthesize VPs in a \textit{controlled} manner, where relevant covariates are used to conditionally synthesise virtual populations that fit specific target patient populations/characteristics. We propose to equip a conditional variational autoencoder (cVAE) with normalizing flows to boost the flexibility and complexity of the approximate posterior learned, leading to enhanced flexibility for controllable synthesis of VPs of anatomical structures. We demonstrate the performance of our conditional-flow VAE using a dataset of cardiac left ventricles acquired from 2360 patients, with associated demographic information and clinical measurements (used as covariates/conditioning information). The obtained results indicate the superiority of the proposed method for conditional synthesis of virtual populations of cardiac left ventricles relative to a cVAE. Conditional synthesis performance was assessed in terms of generalisation and specificity errors, and in terms of the ability to preserve clinical relevant biomarkers in the synthesised VPs, I.e. left ventricular blood pool and myocardial volume, relative to the observed real population.