 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery
Apr 26, 2023
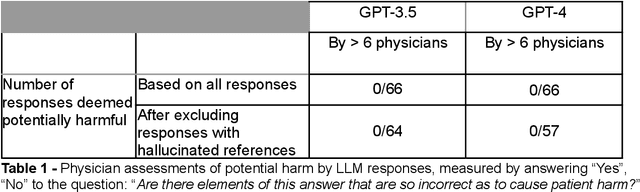
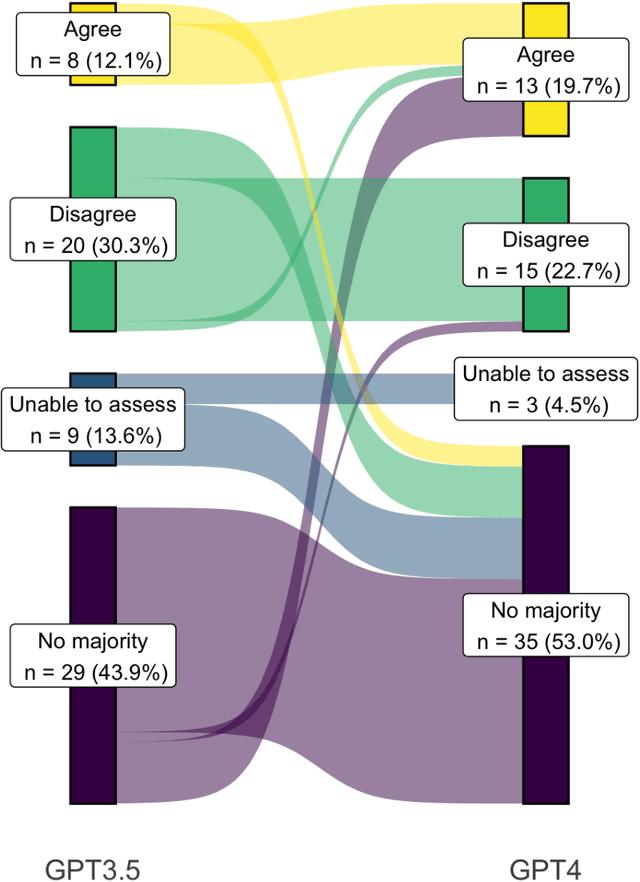
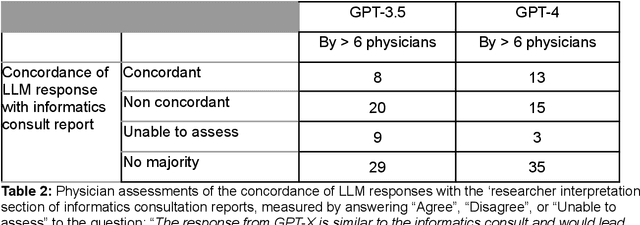
Despite growing interest in using large language models (LLMs) in healthcare, current explorations do not assess the real-world utility and safety of LLMs in clinical settings. Our objective was to determine whether two LLMs can serve information needs submitted by physicians as questions to an informatics consultation service in a safe and concordant manner. Sixty six questions from an informatics consult service were submitted to GPT-3.5 and GPT-4 via simple prompts. 12 physicians assessed the LLM responses' possibility of patient harm and concordance with existing reports from an informatics consultation service. Physician assessments were summarized based on majority vote. For no questions did a majority of physicians deem either LLM response as harmful. For GPT-3.5, responses to 8 questions were concordant with the informatics consult report, 20 discordant, and 9 were unable to be assessed. There were 29 responses with no majority on "Agree", "Disagree", and "Unable to assess". For GPT-4, responses to 13 questions were concordant, 15 discordant, and 3 were unable to be assessed. There were 35 responses with no majority. Responses from both LLMs were largely devoid of overt harm, but less than 20% of the responses agreed with an answer from an informatics consultation service, responses contained hallucinated references, and physicians were divided on what constitutes harm. These results suggest that while general purpose LLMs are able to provide safe and credible responses, they often do not meet the specific information need of a given question. A definitive evaluation of the usefulness of LLMs in healthcare settings will likely require additional research on prompt engineering, calibration, and custom-tailoring of general purpose models.
General-Purpose Multimodal Transformer meets Remote Sensing Semantic Segmentation
Jul 07, 2023

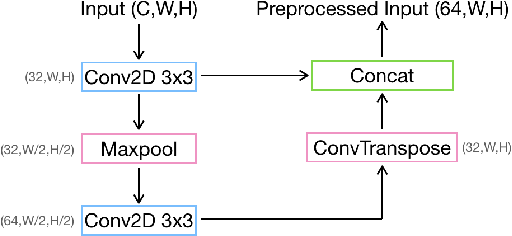
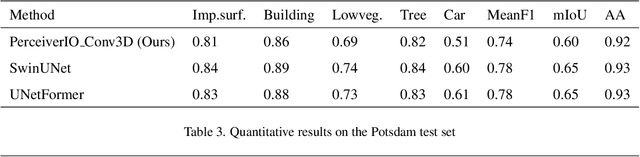
The advent of high-resolution multispectral/hyperspectral sensors, LiDAR DSM (Digital Surface Model) information and many others has provided us with an unprecedented wealth of data for Earth Observation. Multimodal AI seeks to exploit those complementary data sources, particularly for complex tasks like semantic segmentation. While specialized architectures have been developed, they are highly complicated via significant effort in model design, and require considerable re-engineering whenever a new modality emerges. Recent trends in general-purpose multimodal networks have shown great potential to achieve state-of-the-art performance across multiple multimodal tasks with one unified architecture. In this work, we investigate the performance of PerceiverIO, one in the general-purpose multimodal family, in the remote sensing semantic segmentation domain. Our experiments reveal that this ostensibly universal network struggles with object scale variation in remote sensing images and fails to detect the presence of cars from a top-down view. To address these issues, even with extreme class imbalance issues, we propose a spatial and volumetric learning component. Specifically, we design a UNet-inspired module that employs 3D convolution to encode vital local information and learn cross-modal features simultaneously, while reducing network computational burden via the cross-attention mechanism of PerceiverIO. The effectiveness of the proposed component is validated through extensive experiments comparing it with other methods such as 2D convolution, and dual local module (\ie the combination of Conv2D 1x1 and Conv2D 3x3 inspired by UNetFormer). The proposed method achieves competitive results with specialized architectures like UNetFormer and SwinUNet, showing its potential to minimize network architecture engineering with a minimal compromise on the performance.
Integrating Large Pre-trained Models into Multimodal Named Entity Recognition with Evidential Fusion
Jun 29, 2023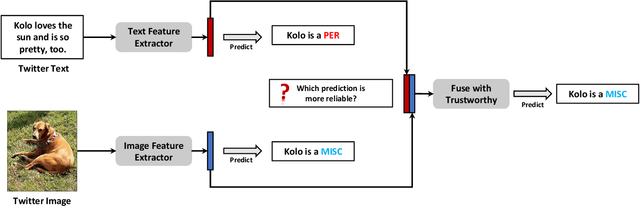
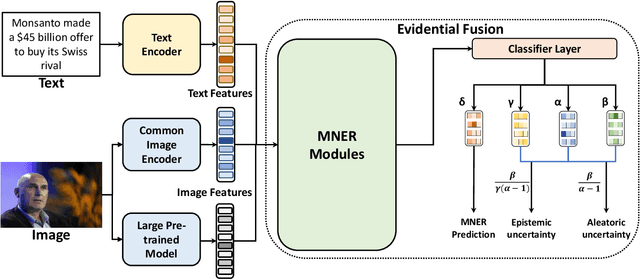
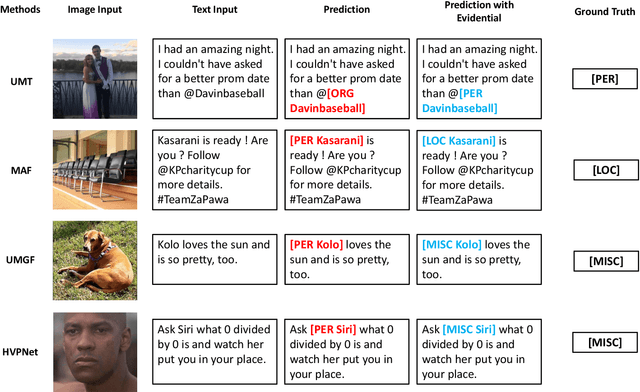
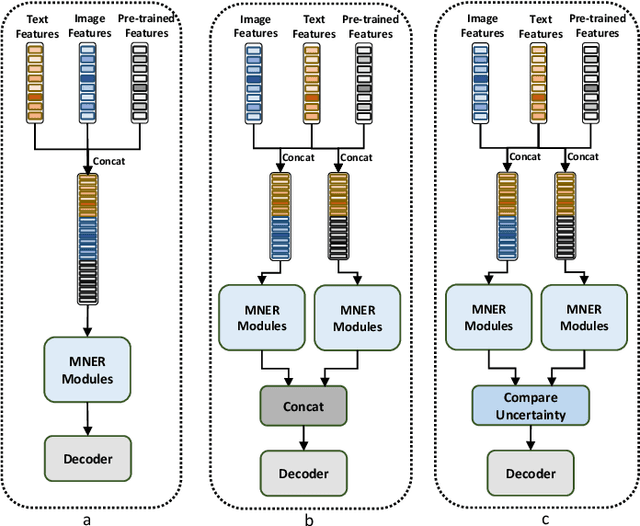
Multimodal Named Entity Recognition (MNER) is a crucial task for information extraction from social media platforms such as Twitter. Most current methods rely on attention weights to extract information from both text and images but are often unreliable and lack interpretability. To address this problem, we propose incorporating uncertainty estimation into the MNER task, producing trustworthy predictions. Our proposed algorithm models the distribution of each modality as a Normal-inverse Gamma distribution, and fuses them into a unified distribution with an evidential fusion mechanism, enabling hierarchical characterization of uncertainties and promotion of prediction accuracy and trustworthiness. Additionally, we explore the potential of pre-trained large foundation models in MNER and propose an efficient fusion approach that leverages their robust feature representations. Experiments on two datasets demonstrate that our proposed method outperforms the baselines and achieves new state-of-the-art performance.
Learning Multilingual Expressive Speech Representation for Prosody Prediction without Parallel Data
Jun 29, 2023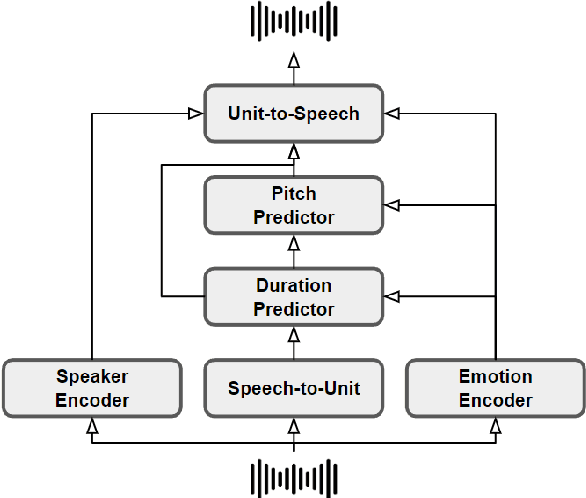
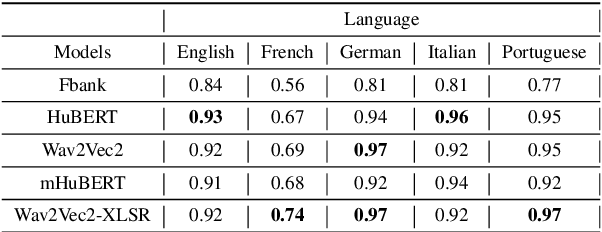
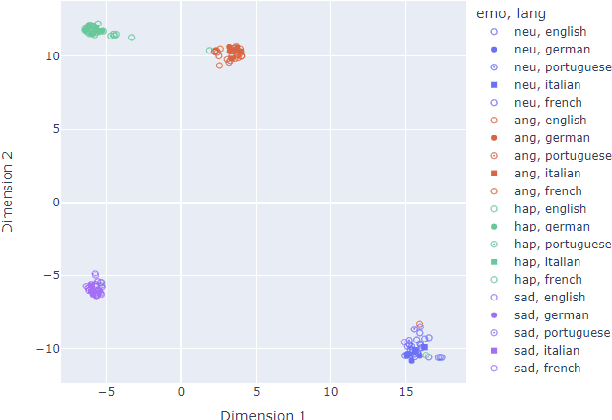
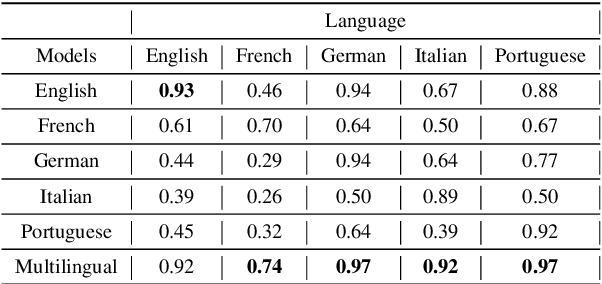
We propose a method for speech-to-speech emotionpreserving translation that operates at the level of discrete speech units. Our approach relies on the use of multilingual emotion embedding that can capture affective information in a language-independent manner. We show that this embedding can be used to predict the pitch and duration of speech units in a target language, allowing us to resynthesize the source speech signal with the same emotional content. We evaluate our approach to English and French speech signals and show that it outperforms a baseline method that does not use emotional information, including when the emotion embedding is extracted from a different language. Even if this preliminary study does not address directly the machine translation issue, our results demonstrate the effectiveness of our approach for cross-lingual emotion preservation in the context of speech resynthesis.
Deep Learning-based F0 Synthesis for Speaker Anonymization
Jun 29, 2023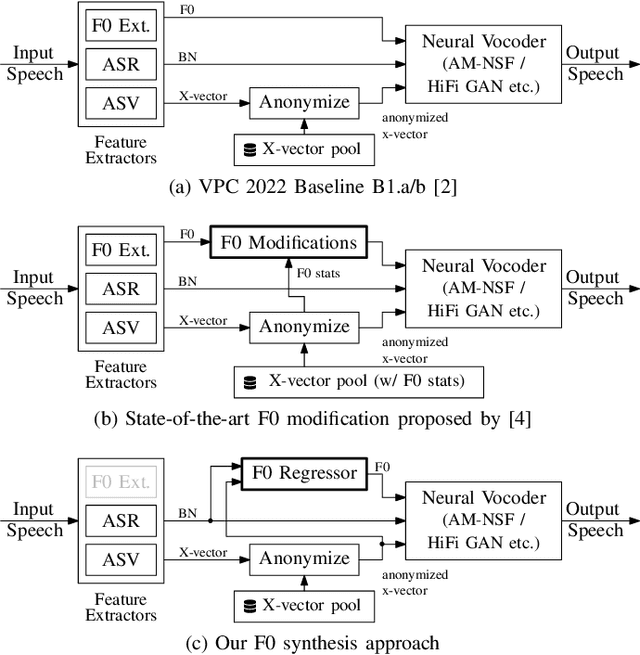
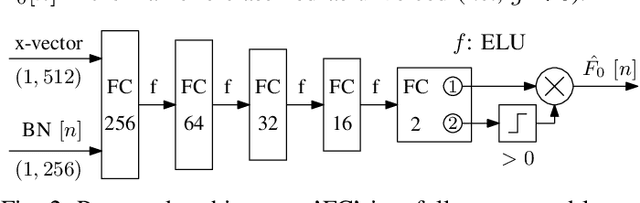
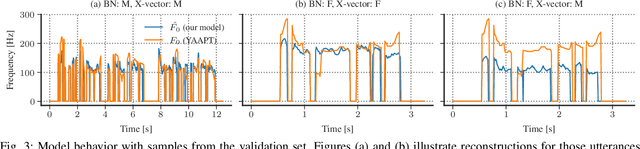
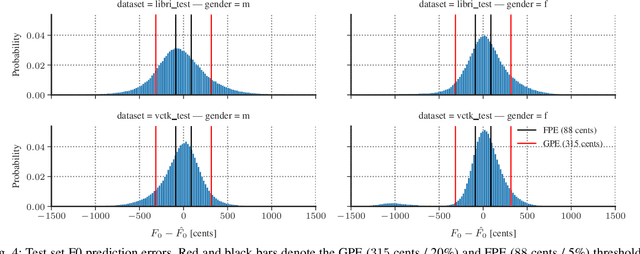
Voice conversion for speaker anonymization is an emerging concept for privacy protection. In a deep learning setting, this is achieved by extracting multiple features from speech, altering the speaker identity, and waveform synthesis. However, many existing systems do not modify fundamental frequency (F0) trajectories, which convey prosody information and can reveal speaker identity. Moreover, mismatch between F0 and other features can degrade speech quality and intelligibility. In this paper, we formally introduce a method that synthesizes F0 trajectories from other speech features and evaluate its reconstructional capabilities. Then we test our approach within a speaker anonymization framework, comparing it to a baseline and a state-of-the-art F0 modification that utilizes speaker information. The results show that our method improves both speaker anonymity, measured by the equal error rate, and utility, measured by the word error rate.
TRAC: Trustworthy Retrieval Augmented Chatbot
Jul 07, 2023Although conversational AIs have demonstrated fantastic performance, they often generate incorrect information, or hallucinations. Retrieval augmented generation has emerged as a promising solution to reduce these hallucinations. However, these techniques still cannot guarantee correctness. Focusing on question answering, we propose a framework that can provide statistical guarantees for the retrieval augmented question answering system by combining conformal prediction and global testing. In addition, we use Bayesian optimization to choose hyperparameters of the global test to maximize the performance of the system. Our empirical results on the Natural Questions dataset demonstrate that our method can provide the desired coverage guarantee while minimizing the average prediction set size.
Scale-Aware Modulation Meet Transformer
Jul 17, 2023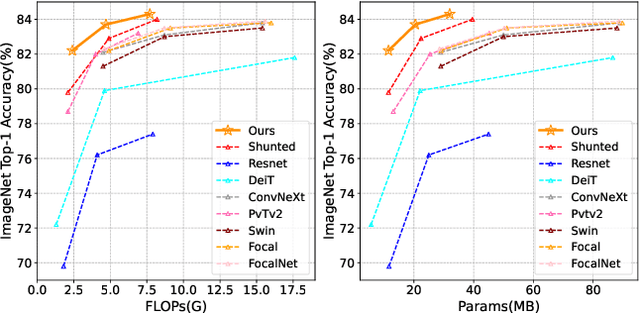
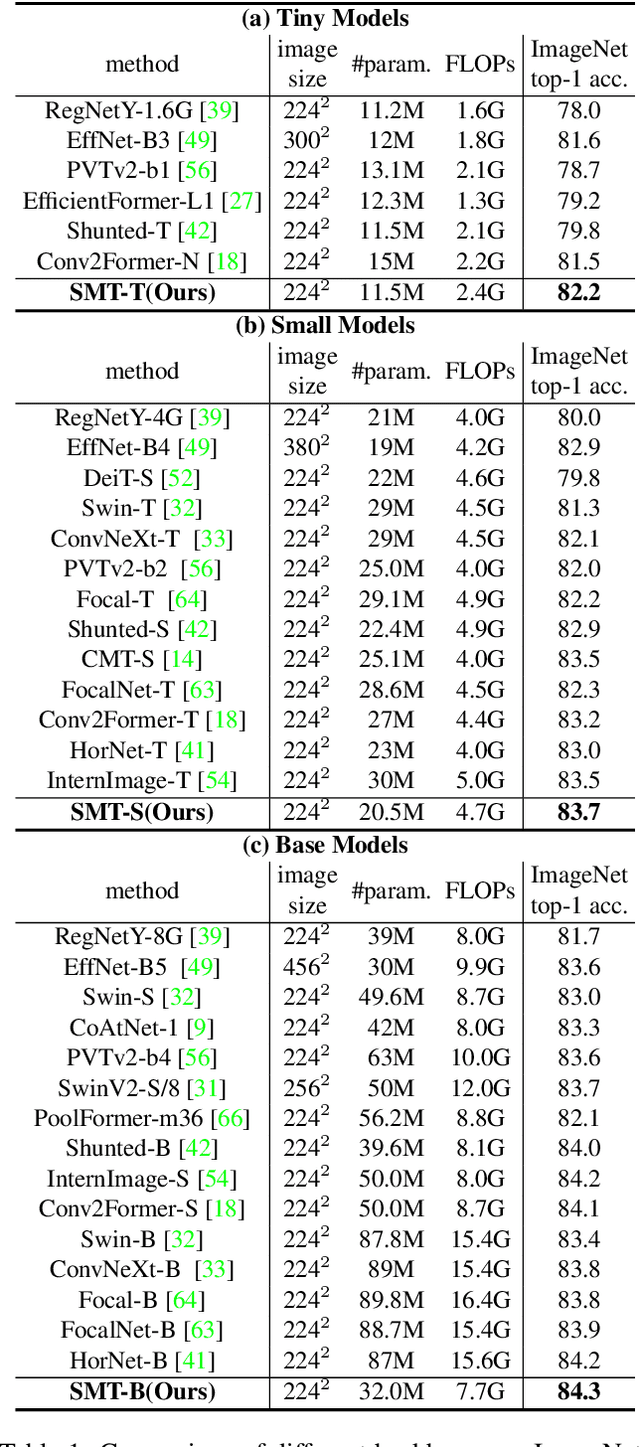
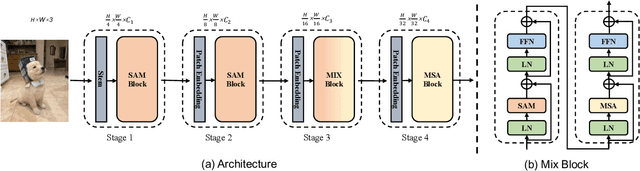
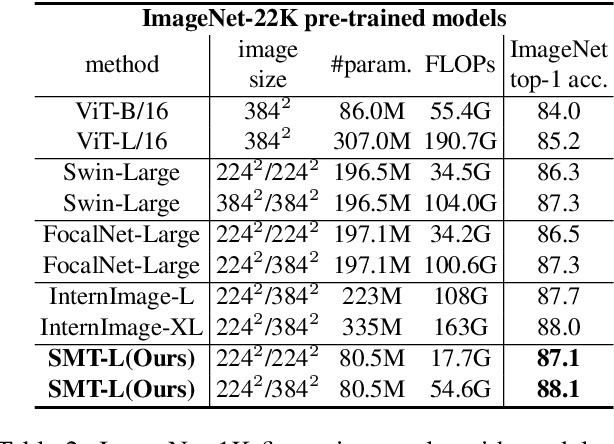
This paper presents a new vision Transformer, Scale-Aware Modulation Transformer (SMT), that can handle various downstream tasks efficiently by combining the convolutional network and vision Transformer. The proposed Scale-Aware Modulation (SAM) in the SMT includes two primary novel designs. Firstly, we introduce the Multi-Head Mixed Convolution (MHMC) module, which can capture multi-scale features and expand the receptive field. Secondly, we propose the Scale-Aware Aggregation (SAA) module, which is lightweight but effective, enabling information fusion across different heads. By leveraging these two modules, convolutional modulation is further enhanced. Furthermore, in contrast to prior works that utilized modulations throughout all stages to build an attention-free network, we propose an Evolutionary Hybrid Network (EHN), which can effectively simulate the shift from capturing local to global dependencies as the network becomes deeper, resulting in superior performance. Extensive experiments demonstrate that SMT significantly outperforms existing state-of-the-art models across a wide range of visual tasks. Specifically, SMT with 11.5M / 2.4GFLOPs and 32M / 7.7GFLOPs can achieve 82.2% and 84.3% top-1 accuracy on ImageNet-1K, respectively. After pretrained on ImageNet-22K in 224^2 resolution, it attains 87.1% and 88.1% top-1 accuracy when finetuned with resolution 224^2 and 384^2, respectively. For object detection with Mask R-CNN, the SMT base trained with 1x and 3x schedule outperforms the Swin Transformer counterpart by 4.2 and 1.3 mAP on COCO, respectively. For semantic segmentation with UPerNet, the SMT base test at single- and multi-scale surpasses Swin by 2.0 and 1.1 mIoU respectively on the ADE20K.
Privacy-preserving patient clustering for personalized federated learning
Jul 17, 2023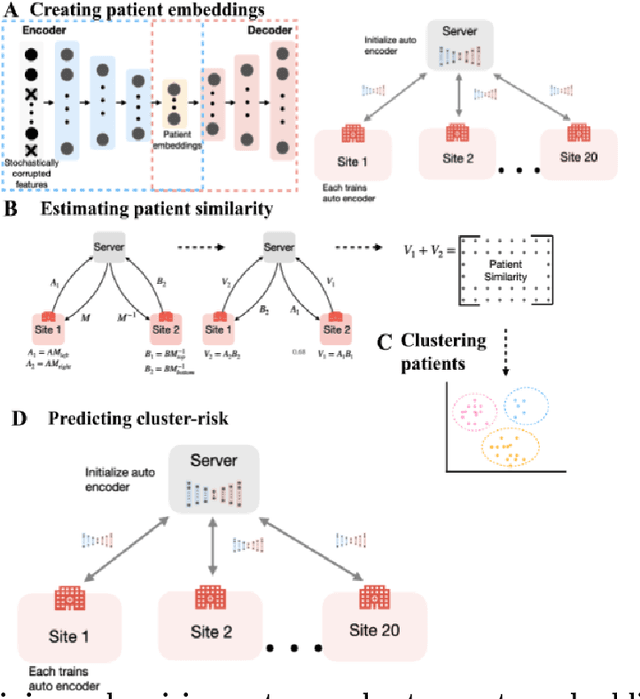
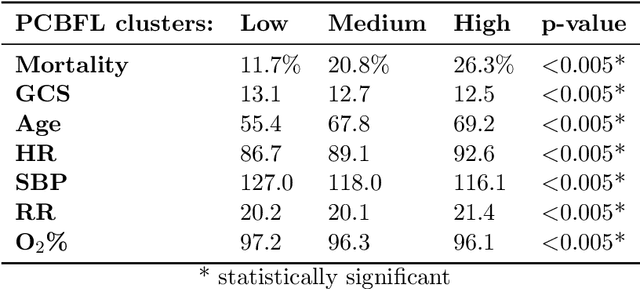
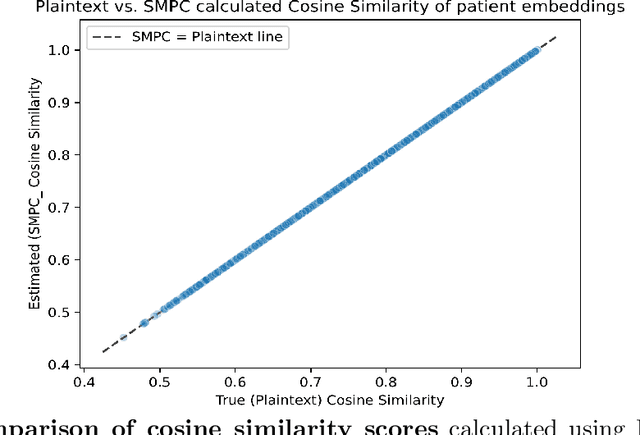

Federated Learning (FL) is a machine learning framework that enables multiple organizations to train a model without sharing their data with a central server. However, it experiences significant performance degradation if the data is non-identically independently distributed (non-IID). This is a problem in medical settings, where variations in the patient population contribute significantly to distribution differences across hospitals. Personalized FL addresses this issue by accounting for site-specific distribution differences. Clustered FL, a Personalized FL variant, was used to address this problem by clustering patients into groups across hospitals and training separate models on each group. However, privacy concerns remained as a challenge as the clustering process requires exchange of patient-level information. This was previously solved by forming clusters using aggregated data, which led to inaccurate groups and performance degradation. In this study, we propose Privacy-preserving Community-Based Federated machine Learning (PCBFL), a novel Clustered FL framework that can cluster patients using patient-level data while protecting privacy. PCBFL uses Secure Multiparty Computation, a cryptographic technique, to securely calculate patient-level similarity scores across hospitals. We then evaluate PCBFL by training a federated mortality prediction model using 20 sites from the eICU dataset. We compare the performance gain from PCBFL against traditional and existing Clustered FL frameworks. Our results show that PCBFL successfully forms clinically meaningful cohorts of low, medium, and high-risk patients. PCBFL outperforms traditional and existing Clustered FL frameworks with an average AUC improvement of 4.3% and AUPRC improvement of 7.8%.
Learning for Counterfactual Fairness from Observational Data
Jul 17, 2023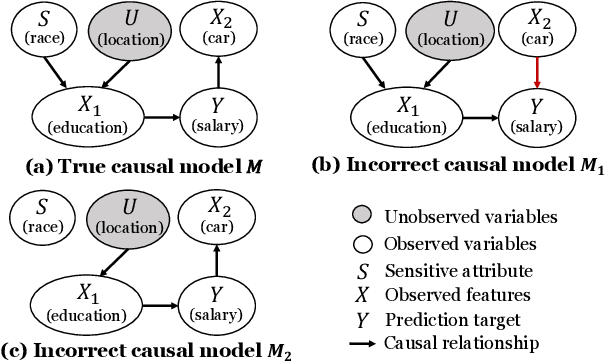
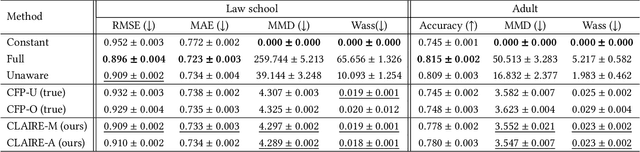

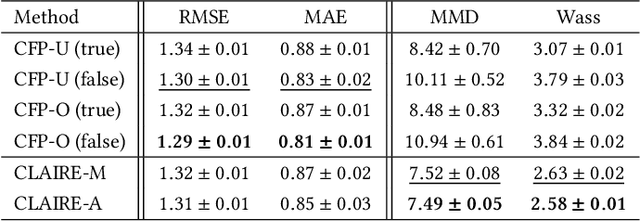
Fairness-aware machine learning has attracted a surge of attention in many domains, such as online advertising, personalized recommendation, and social media analysis in web applications. Fairness-aware machine learning aims to eliminate biases of learning models against certain subgroups described by certain protected (sensitive) attributes such as race, gender, and age. Among many existing fairness notions, counterfactual fairness is a popular notion defined from a causal perspective. It measures the fairness of a predictor by comparing the prediction of each individual in the original world and that in the counterfactual worlds in which the value of the sensitive attribute is modified. A prerequisite for existing methods to achieve counterfactual fairness is the prior human knowledge of the causal model for the data. However, in real-world scenarios, the underlying causal model is often unknown, and acquiring such human knowledge could be very difficult. In these scenarios, it is risky to directly trust the causal models obtained from information sources with unknown reliability and even causal discovery methods, as incorrect causal models can consequently bring biases to the predictor and lead to unfair predictions. In this work, we address the problem of counterfactually fair prediction from observational data without given causal models by proposing a novel framework CLAIRE. Specifically, under certain general assumptions, CLAIRE effectively mitigates the biases from the sensitive attribute with a representation learning framework based on counterfactual data augmentation and an invariant penalty. Experiments conducted on both synthetic and real-world datasets validate the superiority of CLAIRE in both counterfactual fairness and prediction performance.
Improving Data Efficiency for Plant Cover Prediction with Label Interpolation and Monte-Carlo Cropping
Jul 17, 2023
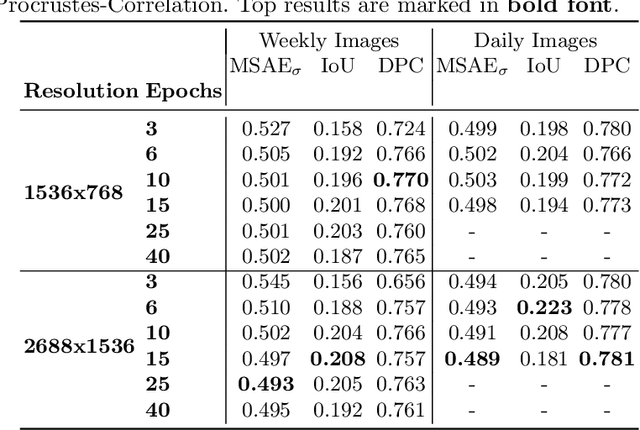

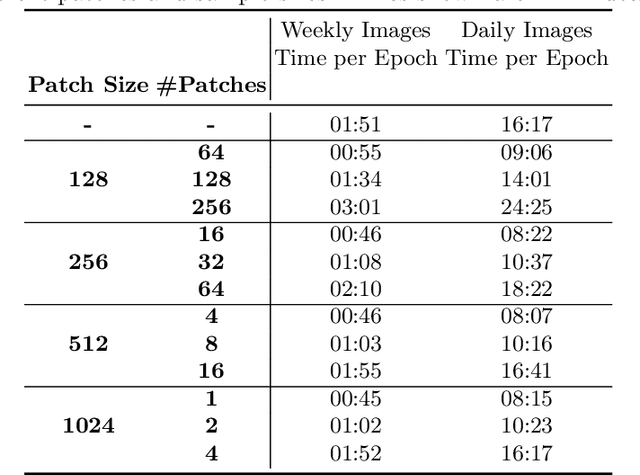
The plant community composition is an essential indicator of environmental changes and is, for this reason, usually analyzed in ecological field studies in terms of the so-called plant cover. The manual acquisition of this kind of data is time-consuming, laborious, and prone to human error. Automated camera systems can collect high-resolution images of the surveyed vegetation plots at a high frequency. In combination with subsequent algorithmic analysis, it is possible to objectively extract information on plant community composition quickly and with little human effort. An automated camera system can easily collect the large amounts of image data necessary to train a Deep Learning system for automatic analysis. However, due to the amount of work required to annotate vegetation images with plant cover data, only few labeled samples are available. As automated camera systems can collect many pictures without labels, we introduce an approach to interpolate the sparse labels in the collected vegetation plot time series down to the intermediate dense and unlabeled images to artificially increase our training dataset to seven times its original size. Moreover, we introduce a new method we call Monte-Carlo Cropping. This approach trains on a collection of cropped parts of the training images to deal with high-resolution images efficiently, implicitly augment the training images, and speed up training. We evaluate both approaches on a plant cover dataset containing images of herbaceous plant communities and find that our methods lead to improvements in the species, community, and segmentation metrics investigated.