 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SSVEP-Based BCI Wheelchair Control System
Jul 12, 2023

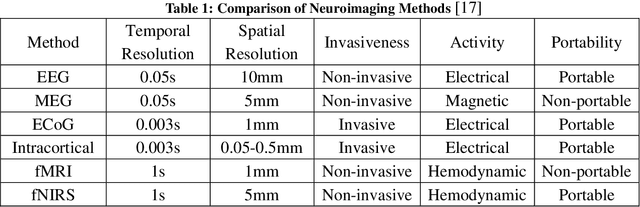
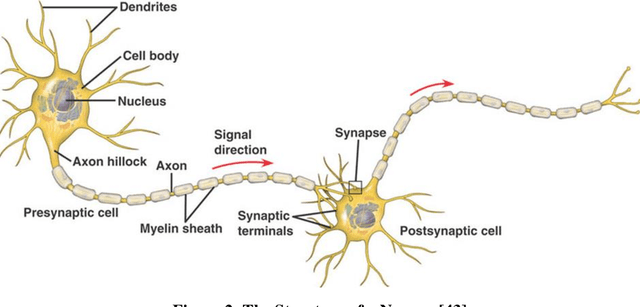

A brain-computer interface (BCI) is a system that allows a person to communicate or control the surroundings without depending on the brain's normal output pathways of peripheral nerves and muscles. A lot of successful applications have arisen utilizing the advantages of BCI to assist disabled people with so-called assistive technology. Considering using BCI has fewer limitations and huge potential, this project has been proposed to control the movement of an electronic wheelchair via brain signals. The goal of this project is to help disabled people, especially paralyzed people suffering from motor disabilities, improve their life qualities. In order to realize the project stated above, Steady-State Visual Evoked Potential (SSVEP) is involved. It can be easily elicited in the visual cortical with the same frequency as the one is being focused by the subject. There are two important parts in this project. One is to process the EEG signals and another one is to make a visual stimulator using hardware. The EEG signals are processed in Matlab using the algorithm of Butterworth Infinite Impulse Response (IIR) bandpass filter (for preprocessing) and Fast Fourier Transform (FFT) (for feature extraction). Besides, a harmonics-based classification method is proposed and applied in the classification part. Moreover, the design of the visual stimulator combines LEDs as flickers and LCDs as information displayers on one panel. Microcontrollers are employed to control the SSVEP visual stimuli panel. This project is evaluated by subjects with different races and ages. Experimental results show the system is easy to be operated and it can achieve approximately a minimum 1-second time delay. So it demonstrates that this SSVEP-based BCI-controlled wheelchair has a huge potential to be applied to disabled people in the future.
IRS-Aided Overloaded Multi-Antenna Systems: Joint User Grouping and Resource Allocation
Jul 01, 2023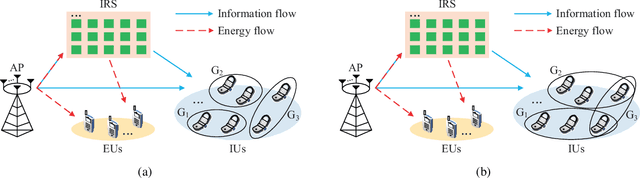
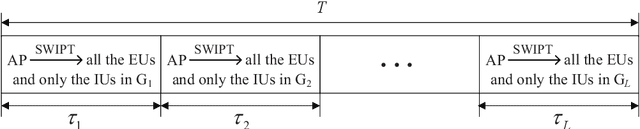
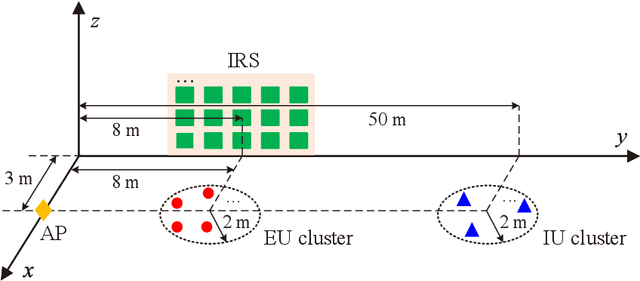
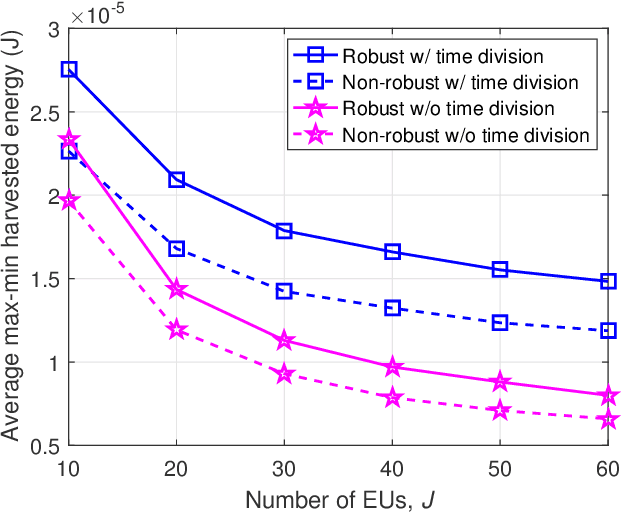
This paper studies an intelligent reflecting surface (IRS)-aided multi-antenna simultaneous wireless information and power transfer (SWIPT) system where an $M$-antenna access point (AP) serves $K$ single-antenna information users (IUs) and $J$ single-antenna energy users (EUs) with the aid of an IRS with phase errors. We explicitly concentrate on overloaded scenarios where $K + J > M$ and $K \geq M$. Our goal is to maximize the minimum throughput among all the IUs by optimizing the allocation of resources (including time, transmit beamforming at the AP, and reflect beamforming at the IRS), while guaranteeing the minimum amount of harvested energy at each EU. Towards this goal, we propose two user grouping (UG) schemes, namely, the non-overlapping UG scheme and the overlapping UG scheme, where the difference lies in whether identical IUs can exist in multiple groups. Different IU groups are served in orthogonal time dimensions, while the IUs in the same group are served simultaneously with all the EUs via spatial multiplexing. The two problems corresponding to the two UG schemes are mixed-integer non-convex optimization problems and difficult to solve optimally. We propose efficient algorithms for these two problems based on the big-M formulation, the penalty method, the block coordinate descent, and the successive convex approximation. Simulation results show that: 1) the non-robust counterparts of the proposed robust designs are unsuitable for practical IRS-aided SWIPT systems with phase errors since the energy harvesting constraints cannot be satisfied; 2) the proposed UG strategies can significantly improve the max-min throughput over the benchmark schemes without UG or adopting random UG; 3) the overlapping UG scheme performs much better than its non-overlapping counterpart when the absolute difference between $K$ and $M$ is small and the EH constraints are not stringent.
TACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning
Jun 22, 2023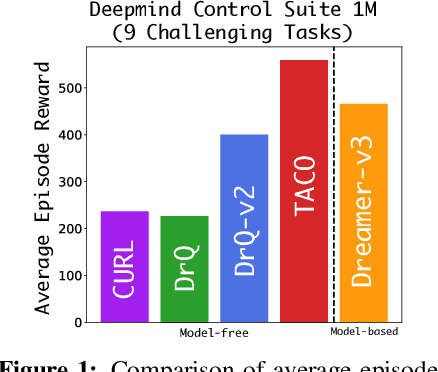
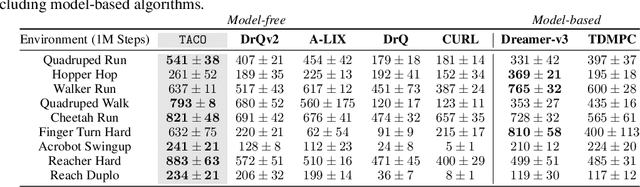
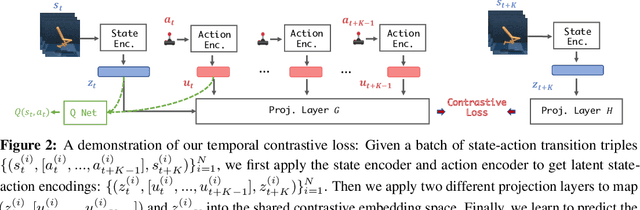
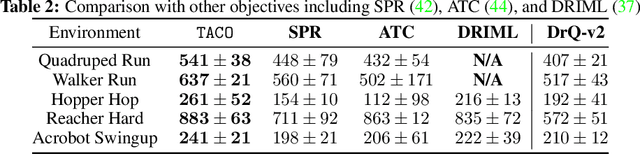
Despite recent progress in reinforcement learning (RL) from raw pixel data, sample inefficiency continues to present a substantial obstacle. Prior works have attempted to address this challenge by creating self-supervised auxiliary tasks, aiming to enrich the agent's learned representations with control-relevant information for future state prediction. However, these objectives are often insufficient to learn representations that can represent the optimal policy or value function, and they often consider tasks with small, abstract discrete action spaces and thus overlook the importance of action representation learning in continuous control. In this paper, we introduce TACO: Temporal Action-driven Contrastive Learning, a simple yet powerful temporal contrastive learning approach that facilitates the concurrent acquisition of latent state and action representations for agents. TACO simultaneously learns a state and an action representation by optimizing the mutual information between representations of current states paired with action sequences and representations of the corresponding future states. Theoretically, TACO can be shown to learn state and action representations that encompass sufficient information for control, thereby improving sample efficiency. For online RL, TACO achieves 40% performance boost after one million environment interaction steps on average across nine challenging visual continuous control tasks from Deepmind Control Suite. In addition, we show that TACO can also serve as a plug-and-play module adding to existing offline visual RL methods to establish the new state-of-the-art performance for offline visual RL across offline datasets with varying quality.
Reduction of Class Activation Uncertainty with Background Information
May 05, 2023Multitask learning is a popular approach to training high-performing neural networks with improved generalization. In this paper, we propose a background class to achieve improved generalization at a lower computation compared to multitask learning to help researchers and organizations with limited computation power. We also present a methodology for selecting background images and discuss potential future improvements. We apply our approach to several datasets and achieved improved generalization with much lower computation. We also investigate class activation mappings (CAMs) of the trained model and observed the tendency towards looking at a bigger picture in a few class classification problems with the proposed model training methodology. Example scripts are available in the `CAM' folder of the following GitHub Repository: github.com/dipuk0506/UQ
Learning Unseen Modality Interaction
Jun 22, 2023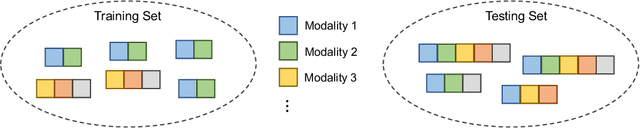

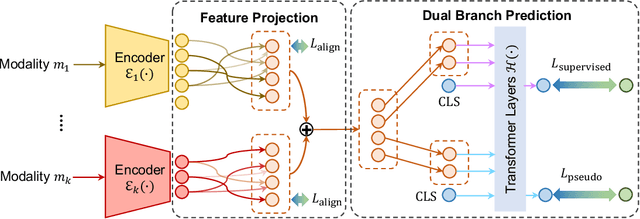
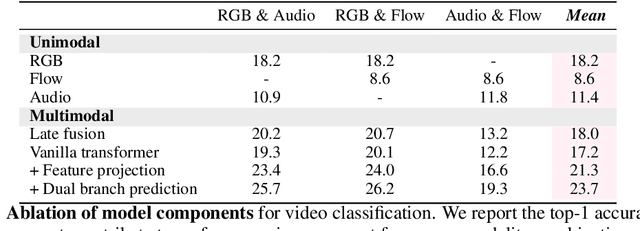
Multimodal learning assumes all modality combinations of interest are available during training to learn cross-modal correspondences. In this paper, we challenge this modality-complete assumption for multimodal learning and instead strive for generalization to unseen modality combinations during inference. We pose the problem of unseen modality interaction and introduce a first solution. It exploits a feature projection module to project the multidimensional features of different modalities into a common space with rich information reserved. This allows the information to be accumulated with a simple summation operation across available modalities. To reduce overfitting to unreliable modality combinations during training, we further improve the model learning with pseudo-supervision indicating the reliability of a modality's prediction. We demonstrate that our approach is effective for diverse tasks and modalities by evaluating it for multimodal video classification, robot state regression, and multimedia retrieval.
ChatGPT as the Transportation Equity Information Source for Scientific Writing
Mar 10, 2023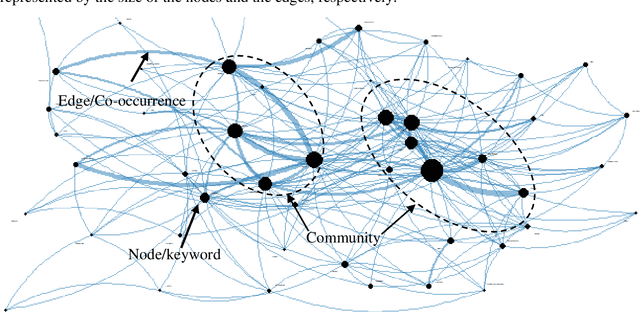

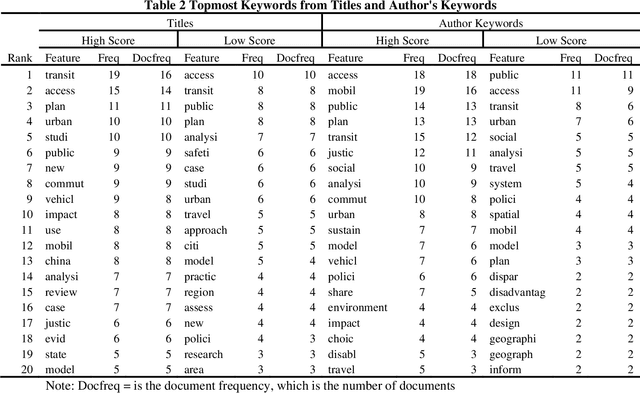
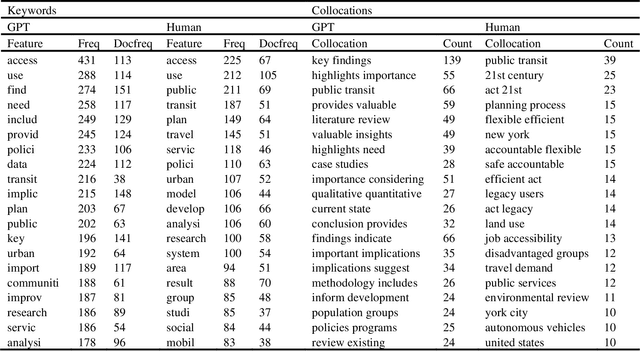
Transportation equity is an interdisciplinary agenda that requires both transportation and social inputs. Traditionally, transportation equity information are sources from public libraries, conferences, televisions, social media, among other. Artificial intelligence (AI) tools including advanced language models such as ChatGPT are becoming favorite information sources. However, their credibility has not been well explored. This study explored the content and usefulness of ChatGPT-generated information related to transportation equity. It utilized 152 papers retrieved through the Web of Science (WoS) repository. The prompt was crafted for ChatGPT to provide an abstract given the title of the paper. The ChatGPT-based abstracts were then compared to human-written abstracts using statistical tools and unsupervised text mining. The results indicate that a weak similarity between ChatGPT and human-written abstracts. On average, the human-written abstracts and ChatGPT generated abstracts were about 58% similar, with a maximum and minimum of 97% and 1.4%, respectively. The keywords from the abstracts of papers with over the mean similarity score were more likely to be similar whereas those from below the average score were less likely to be similar. Themes with high similarity scores include access, public transit, and policy, among others. Further, clear differences in the key pattern of clusters for high and low similarity score abstracts was observed. Contrarily, the findings from collocated keywords were inconclusive. The study findings suggest that ChatGPT has the potential to be a source of transportation equity information. However, currently, a great amount of attention is needed before a user can utilize materials from ChatGPT
GlobalNER: Incorporating Non-local Information into Named Entity Recognition
Mar 06, 2023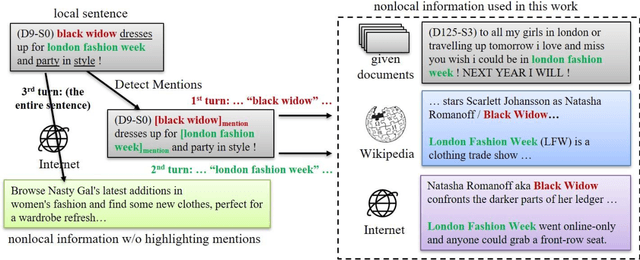
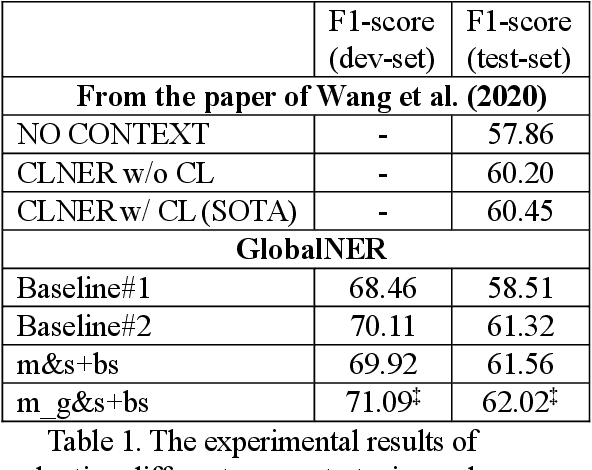
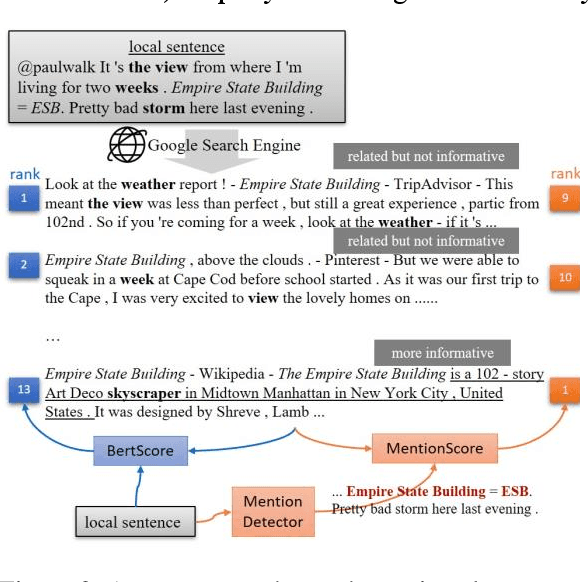
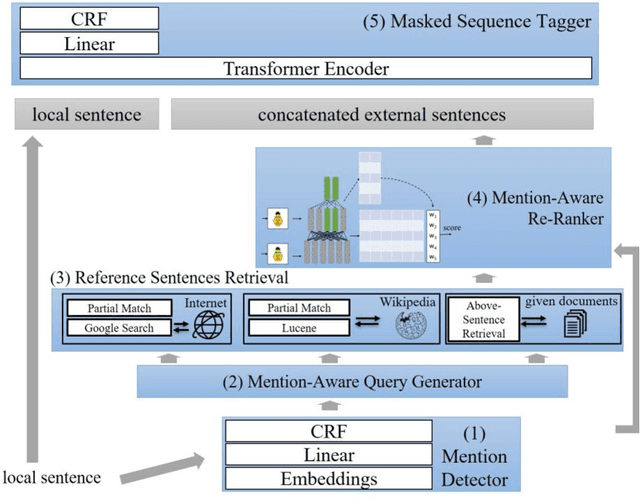
Nowadays, many Natural Language Processing (NLP) tasks see the demand for incorporating knowledge external to the local information to further improve the performance. However, there is little related work on Named Entity Recognition (NER), which is one of the foundations of NLP. Specifically, no studies were conducted on the query generation and re-ranking for retrieving the related information for the purpose of improving NER. This work demonstrates the effectiveness of a DNN-based query generation method and a mention-aware re-ranking architecture based on BERTScore particularly for NER. In the end, a state-of-the-art performance of 61.56 micro-f1 score on WNUT17 dataset is achieved.
ReadProbe: A Demo of Retrieval-Enhanced Large Language Models to Support Lateral Reading
Jun 13, 2023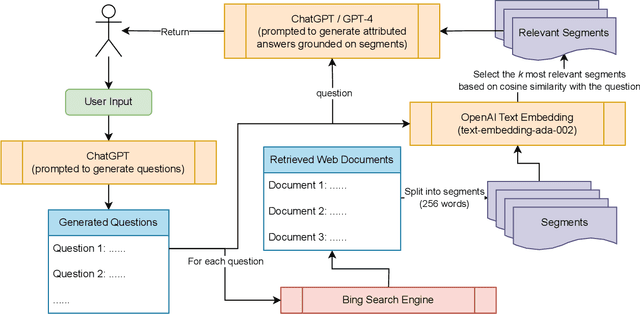

With the rapid growth and spread of online misinformation, people need tools to help them evaluate the credibility and accuracy of online information. Lateral reading, a strategy that involves cross-referencing information with multiple sources, may be an effective approach to achieving this goal. In this paper, we present ReadProbe, a tool to support lateral reading, powered by generative large language models from OpenAI and the Bing search engine. Our tool is able to generate useful questions for lateral reading, scour the web for relevant documents, and generate well-attributed answers to help people better evaluate online information. We made a web-based application to demonstrate how ReadProbe can help reduce the risk of being misled by false information. The code is available at https://github.com/DakeZhang1998/ReadProbe. An earlier version of our tool won the first prize in a national AI misinformation hackathon.
HIDFlowNet: A Flow-Based Deep Network for Hyperspectral Image Denoising
Jun 20, 2023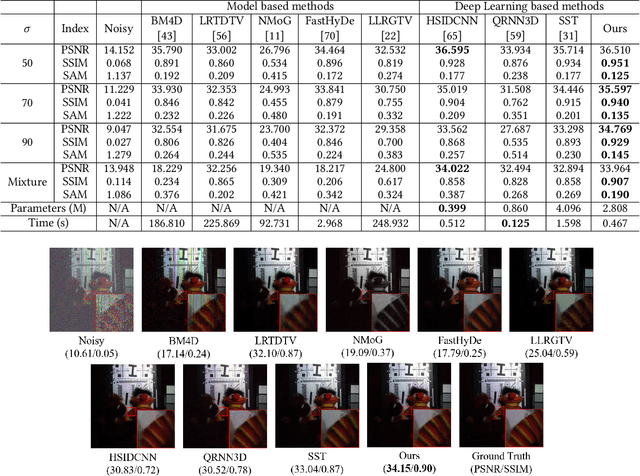
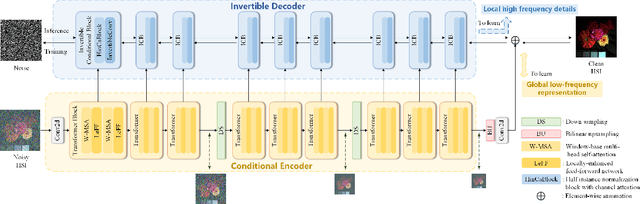
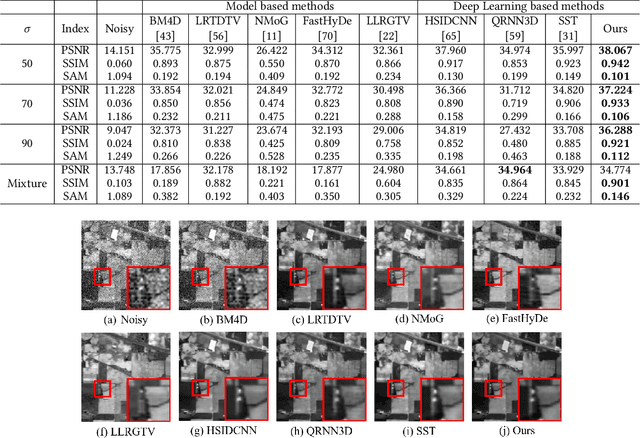
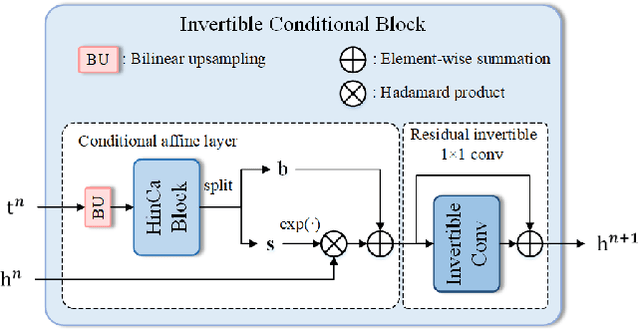
Hyperspectral image (HSI) denoising is essentially ill-posed since a noisy HSI can be degraded from multiple clean HSIs. However, current deep learning-based approaches ignore this fact and restore the clean image with deterministic mapping (i.e., the network receives a noisy HSI and outputs a clean HSI). To alleviate this issue, this paper proposes a flow-based HSI denoising network (HIDFlowNet) to directly learn the conditional distribution of the clean HSI given the noisy HSI and thus diverse clean HSIs can be sampled from the conditional distribution. Overall, our HIDFlowNet is induced from the flow methodology and contains an invertible decoder and a conditional encoder, which can fully decouple the learning of low-frequency and high-frequency information of HSI. Specifically, the invertible decoder is built by staking a succession of invertible conditional blocks (ICBs) to capture the local high-frequency details since the invertible network is information-lossless. The conditional encoder utilizes down-sampling operations to obtain low-resolution images and uses transformers to capture correlations over a long distance so that global low-frequency information can be effectively extracted. Extensive experimental results on simulated and real HSI datasets verify the superiority of our proposed HIDFlowNet compared with other state-of-the-art methods both quantitatively and visually.
Knowledge Distillation via Token-level Relationship Graph
Jun 20, 2023Knowledge distillation is a powerful technique for transferring knowledge from a pre-trained teacher model to a student model. However, the true potential of knowledge transfer has not been fully explored. Existing approaches primarily focus on distilling individual information or instance-level relationships, overlooking the valuable information embedded in token-level relationships, which may be particularly affected by the long-tail effects. To address the above limitations, we propose a novel method called Knowledge Distillation with Token-level Relationship Graph (TRG) that leverages the token-wise relational knowledge to enhance the performance of knowledge distillation. By employing TRG, the student model can effectively emulate higher-level semantic information from the teacher model, resulting in improved distillation results. To further enhance the learning process, we introduce a token-wise contextual loss called contextual loss, which encourages the student model to capture the inner-instance semantic contextual of the teacher model. We conduct experiments to evaluate the effectiveness of the proposed method against several state-of-the-art approaches. Empirical results demonstrate the superiority of TRG across various visual classification tasks, including those involving imbalanced data. Our method consistently outperforms the existing baselines, establishing a new state-of-the-art performance in the field of knowledge distillation.