 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evade ChatGPT Detectors via A Single Space
Jul 05, 2023
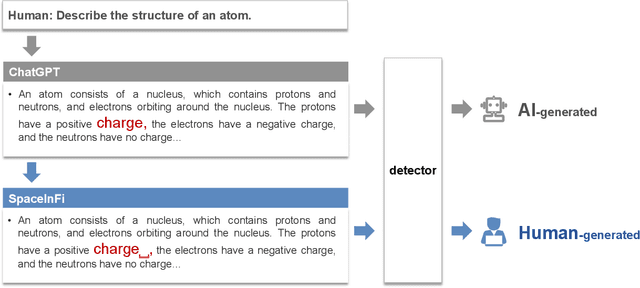
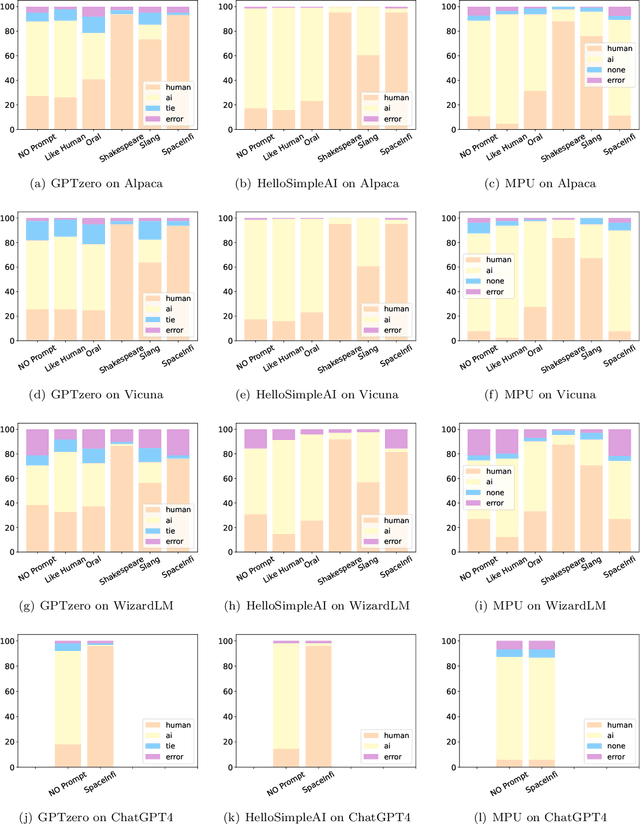
ChatGPT brings revolutionary social value but also raises concerns about the misuse of AI-generated content. Consequently, an important question is how to detect whether content is generated by ChatGPT or by human. Existing detectors are built upon the assumption that there are distributional gaps between human-generated and AI-generated content. These gaps are typically identified using statistical information or classifiers. Our research challenges the distributional gap assumption in detectors. We find that detectors do not effectively discriminate the semantic and stylistic gaps between human-generated and AI-generated content. Instead, the "subtle differences", such as an extra space, become crucial for detection. Based on this discovery, we propose the SpaceInfi strategy to evade detection. Experiments demonstrate the effectiveness of this strategy across multiple benchmarks and detectors. We also provide a theoretical explanation for why SpaceInfi is successful in evading perplexity-based detection. Our findings offer new insights and challenges for understanding and constructing more applicable ChatGPT detectors.
Object Recognition System on a Tactile Device for Visually Impaired
Jul 05, 2023People with visual impairments face numerous challenges when interacting with their environment. Our objective is to develop a device that facilitates communication between individuals with visual impairments and their surroundings. The device will convert visual information into auditory feedback, enabling users to understand their environment in a way that suits their sensory needs. Initially, an object detection model is selected from existing machine learning models based on its accuracy and cost considerations, including time and power consumption. The chosen model is then implemented on a Raspberry Pi, which is connected to a specifically designed tactile device. When the device is touched at a specific position, it provides an audio signal that communicates the identification of the object present in the scene at that corresponding position to the visually impaired individual. Conducted tests have demonstrated the effectiveness of this device in scene understanding, encompassing static or dynamic objects, as well as screen contents such as TVs, computers, and mobile phones.
Remote Sensing Image Change Detection with Graph Interaction
Jul 05, 2023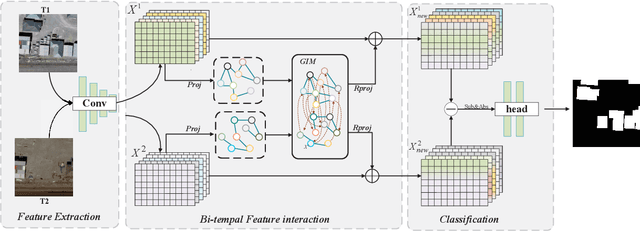
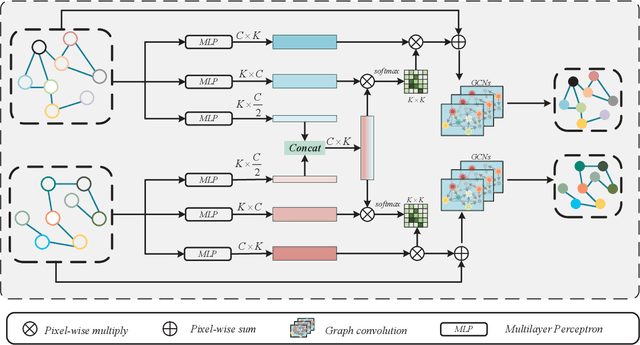

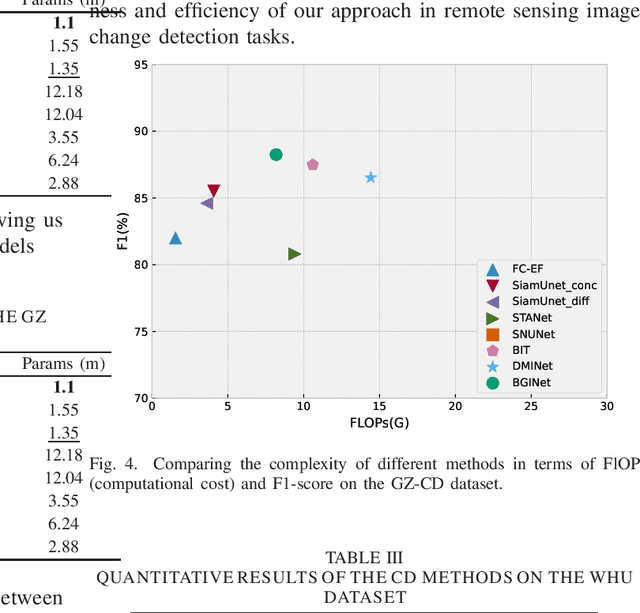
Modern remote sensing image change detection has witnessed substantial advancements by harnessing the potent feature extraction capabilities of CNNs and Transforms.Yet,prevailing change detection techniques consistently prioritize extracting semantic features related to significant alterations,overlooking the viability of directly interacting with bitemporal image features.In this letter,we propose a bitemporal image graph Interaction network for remote sensing change detection,namely BGINet-CD. More specifically,by leveraging the concept of non-local operations and mapping the features obtained from the backbone network to the graph structure space,we propose a unified self-focus mechanism for bitemporal images.This approach enhances the information coupling between the two temporal images while effectively suppressing task-irrelevant interference,Based on a streamlined backbone architecture,namely ResNet18,our model demonstrates superior performance compared to other state-of-the-art methods (SOTA) on the GZ CD dataset. Moreover,the model exhibits an enhanced trade-off between accuracy and computational efficiency,further improving its overall effectiveness
NOMA-Assisted Grant-Free Transmission: How to Design Pre-Configured SNR Levels?
Jul 03, 2023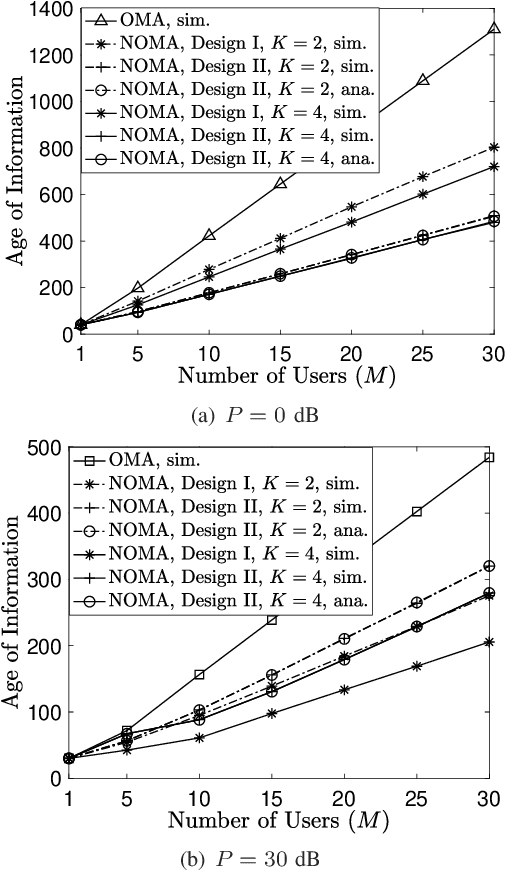
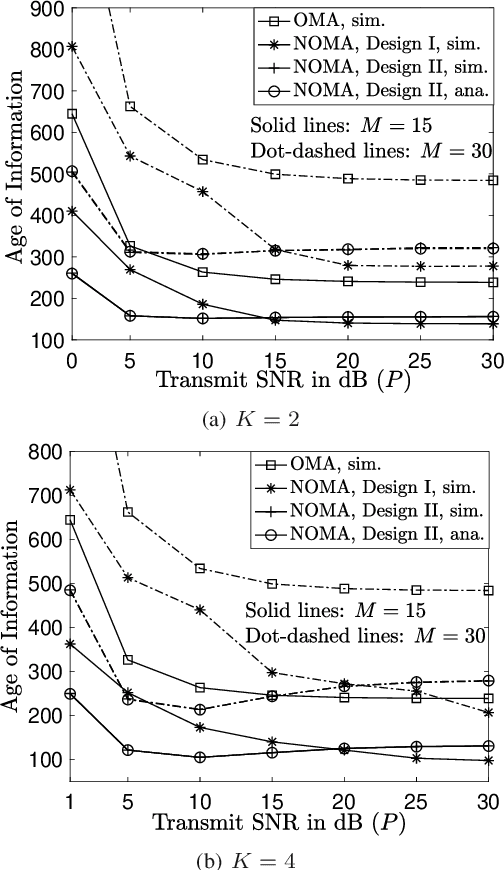
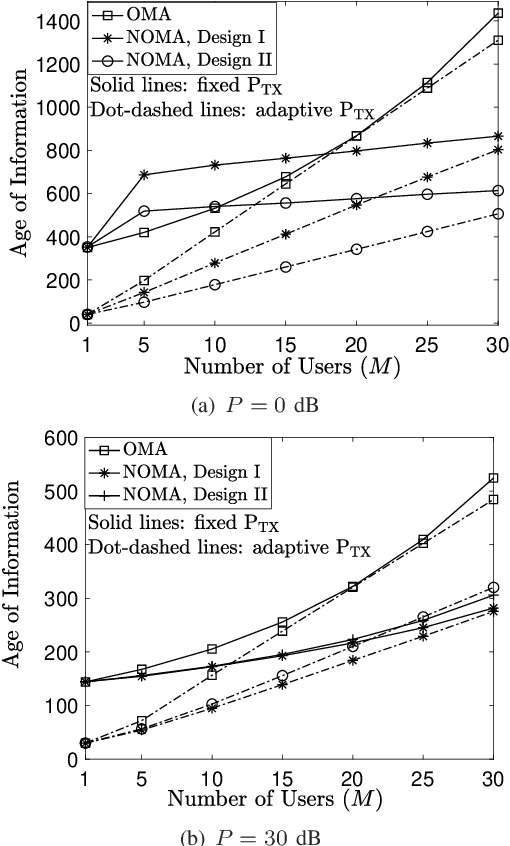

An effective way to realize non-orthogonal multiple access (NOMA) assisted grant-free transmission is to first create multiple receive signal-to-noise ratio (SNR) levels and then serve multiple grant-free users by employing these SNR levels as bandwidth resources. These SNR levels need to be pre-configured prior to the grant-free transmission and have great impact on the performance of grant-free networks. The aim of this letter is to illustrate different designs for configuring the SNR levels and investigate their impact on the performance of grant-free transmission, where age-of-information is used as the performance metric. The presented analytical and simulation results demonstrate the performance gain achieved by NOMA over orthogonal multiple access, and also reveal the relative merits of the considered designs for pre-configured SNR levels.
Spiking Neural Network for Ultra-low-latency and High-accurate Object Detection
Jun 27, 2023
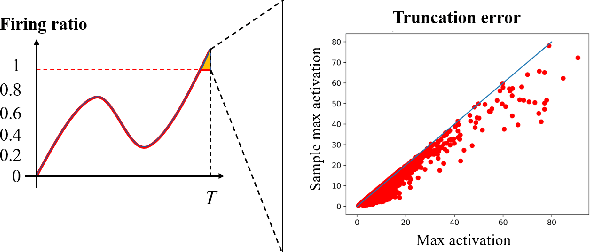
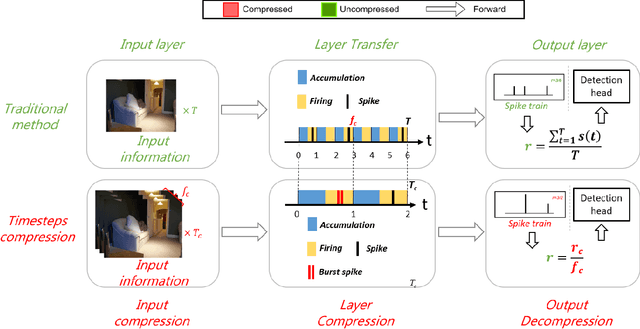
Spiking Neural Networks (SNNs) have garnered widespread interest for their energy efficiency and brain-inspired event-driven properties. While recent methods like Spiking-YOLO have expanded the SNNs to more challenging object detection tasks, they often suffer from high latency and low detection accuracy, making them difficult to deploy on latency sensitive mobile platforms. Furthermore, the conversion method from Artificial Neural Networks (ANNs) to SNNs is hard to maintain the complete structure of the ANNs, resulting in poor feature representation and high conversion errors. To address these challenges, we propose two methods: timesteps compression and spike-time-dependent integrated (STDI) coding. The former reduces the timesteps required in ANN-SNN conversion by compressing information, while the latter sets a time-varying threshold to expand the information holding capacity. We also present a SNN-based ultra-low latency and high accurate object detection model (SUHD) that achieves state-of-the-art performance on nontrivial datasets like PASCAL VOC and MS COCO, with about remarkable 750x fewer timesteps and 30% mean average precision (mAP) improvement, compared to the Spiking-YOLO on MS COCO datasets. To the best of our knowledge, SUHD is the deepest spike-based object detection model to date that achieves ultra low timesteps to complete the lossless conversion.
A Novel Point-based Algorithm for Multi-agent Control Using the Common Information Approach
Apr 10, 2023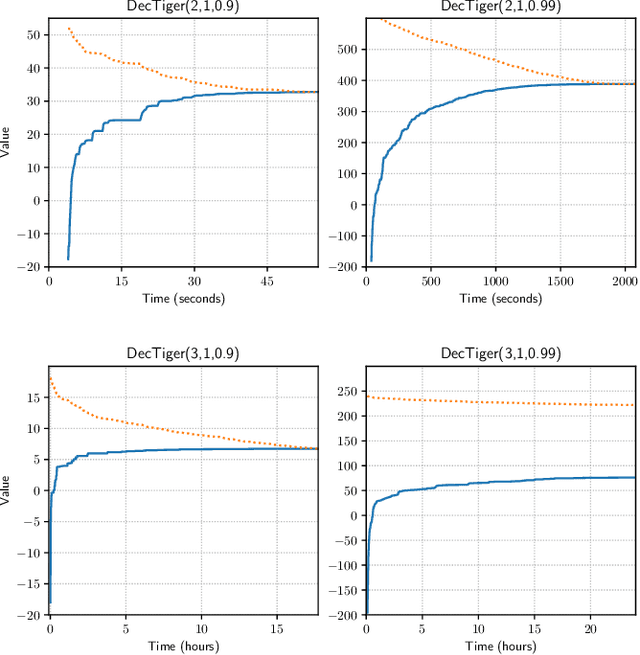
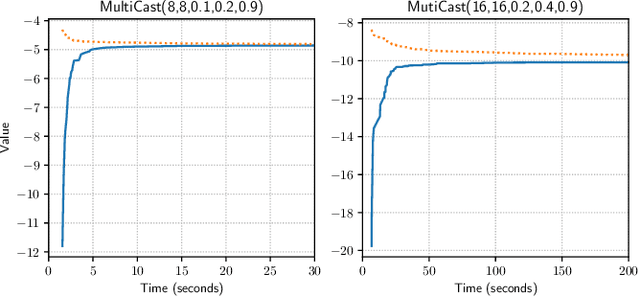
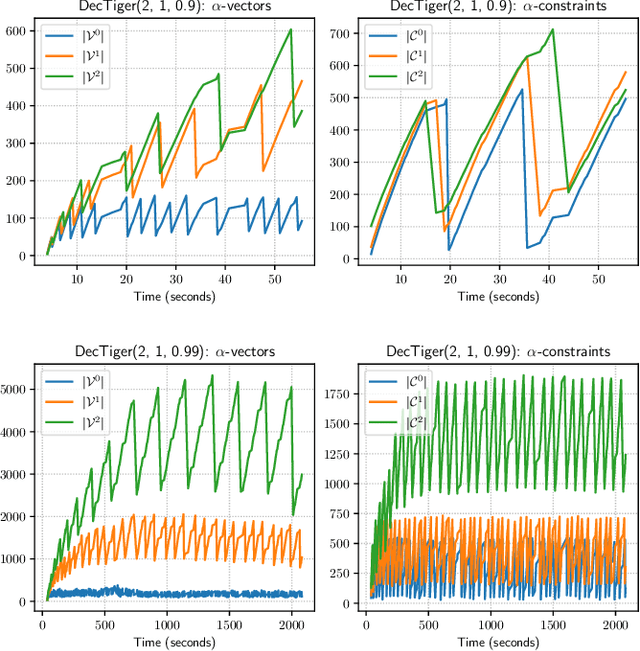

The Common Information (CI) approach provides a systematic way to transform a multi-agent stochastic control problem to a single-agent partially observed Markov decision problem (POMDP) called the coordinator's POMDP. However, such a POMDP can be hard to solve due to its extraordinarily large action space. We propose a new algorithm for multi-agent stochastic control problems, called coordinator's heuristic search value iteration (CHSVI), that combines the CI approach and point-based POMDP algorithms for large action spaces. We demonstrate the algorithm through optimally solving several benchmark problems.
Optimal Execution Using Reinforcement Learning
Jun 19, 2023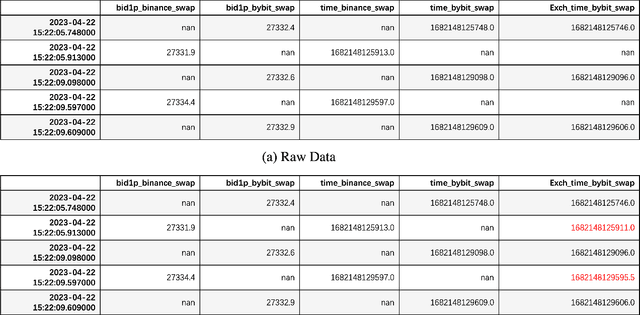
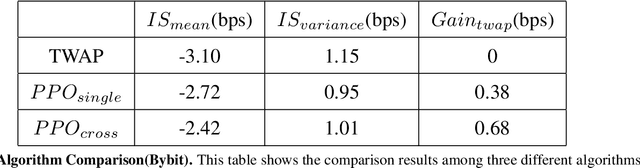
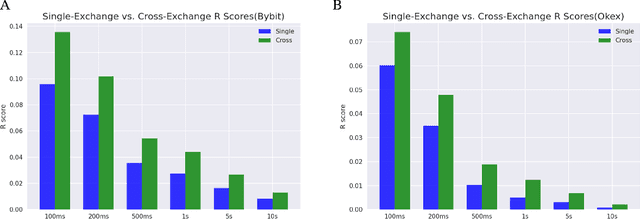
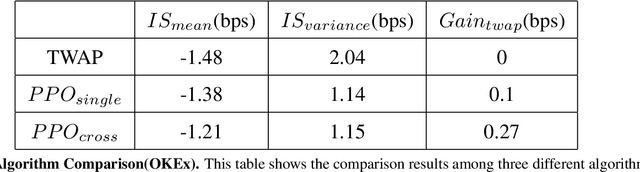
This work is about optimal order execution, where a large order is split into several small orders to maximize the implementation shortfall. Based on the diversity of cryptocurrency exchanges, we attempt to extract cross-exchange signals by aligning data from multiple exchanges for the first time. Unlike most previous studies that focused on using single-exchange information, we discuss the impact of cross-exchange signals on the agent's decision-making in the optimal execution problem. Experimental results show that cross-exchange signals can provide additional information for the optimal execution of cryptocurrency to facilitate the optimal execution process.
Dual Arbitrary Scale Super-Resolution for Multi-Contrast MRI
Jul 10, 2023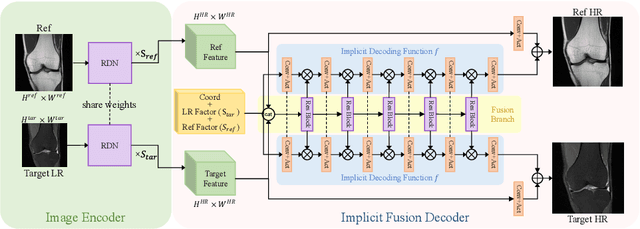
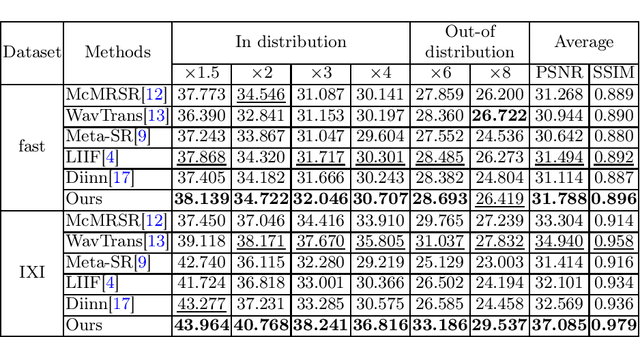
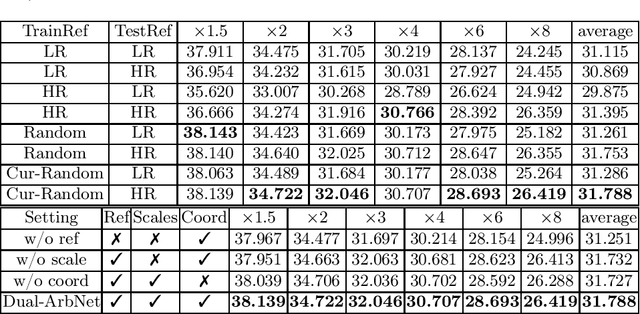
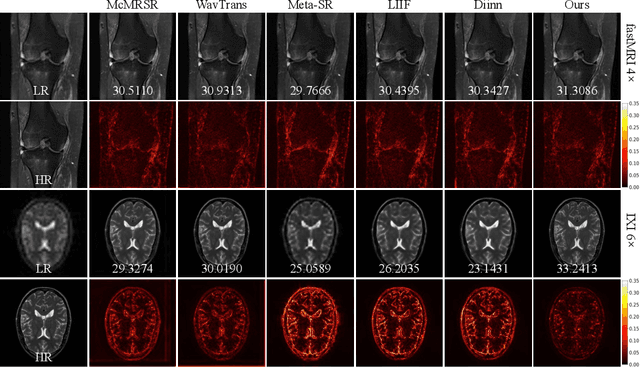
Limited by imaging systems, the reconstruction of Magnetic Resonance Imaging (MRI) images from partial measurement is essential to medical imaging research. Benefiting from the diverse and complementary information of multi-contrast MR images in different imaging modalities, multi-contrast Super-Resolution (SR) reconstruction is promising to yield SR images with higher quality. In the medical scenario, to fully visualize the lesion, radiologists are accustomed to zooming the MR images at arbitrary scales rather than using a fixed scale, as used by most MRI SR methods. In addition, existing multi-contrast MRI SR methods often require a fixed resolution for the reference image, which makes acquiring reference images difficult and imposes limitations on arbitrary scale SR tasks. To address these issues, we proposed an implicit neural representations based dual-arbitrary multi-contrast MRI super-resolution method, called Dual-ArbNet. First, we decouple the resolution of the target and reference images by a feature encoder, enabling the network to input target and reference images at arbitrary scales. Then, an implicit fusion decoder fuses the multi-contrast features and uses an Implicit Decoding Function~(IDF) to obtain the final MRI SR results. Furthermore, we introduce a curriculum learning strategy to train our network, which improves the generalization and performance of our Dual-ArbNet. Extensive experiments in two public MRI datasets demonstrate that our method outperforms state-of-the-art approaches under different scale factors and has great potential in clinical practice.
DiffInfinite: Large Mask-Image Synthesis via Parallel Random Patch Diffusion in Histopathology
Jun 23, 2023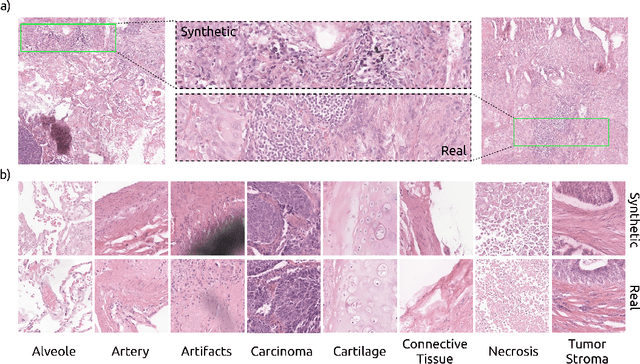
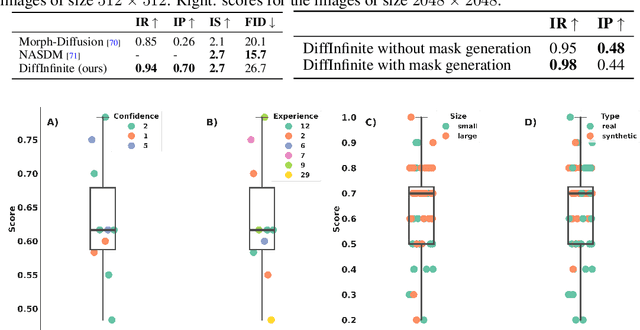
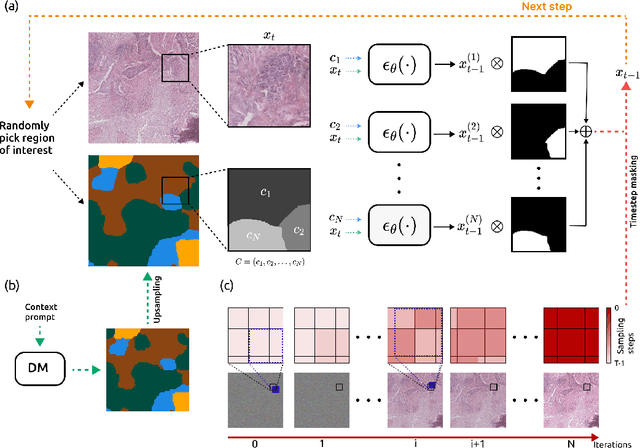

We present DiffInfinite, a hierarchical diffusion model that generates arbitrarily large histological images while preserving long-range correlation structural information. Our approach first generates synthetic segmentation masks, subsequently used as conditions for the high-fidelity generative diffusion process. The proposed sampling method can be scaled up to any desired image size while only requiring small patches for fast training. Moreover, it can be parallelized more efficiently than previous large-content generation methods while avoiding tiling artefacts. The training leverages classifier-free guidance to augment a small, sparsely annotated dataset with unlabelled data. Our method alleviates unique challenges in histopathological imaging practice: large-scale information, costly manual annotation, and protective data handling. The biological plausibility of DiffInfinite data is validated in a survey by ten experienced pathologists as well as a downstream segmentation task. Furthermore, the model scores strongly on anti-copying metrics which is beneficial for the protection of patient data.
Reorganizing Educational Institutional Domain using Faceted Ontological Principles
Jun 17, 2023
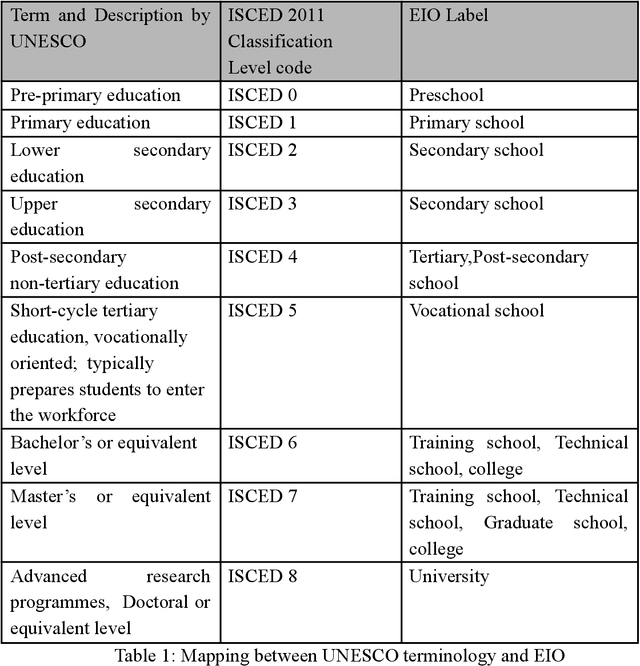
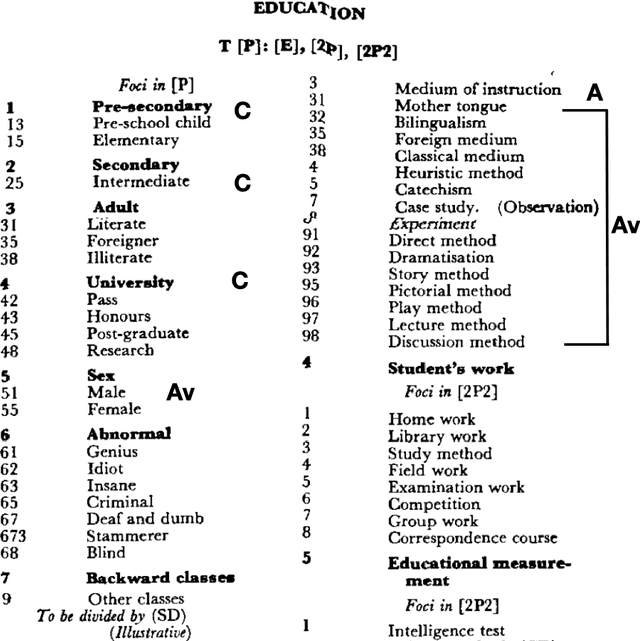

The purpose of this work is to find out how different library classification systems and linguistic ontologies arrange a particular domain of interest and what are the limitations for information retrieval. We use knowledge representation techniques and languages for construction of a domain specific ontology. This ontology would help not only in problem solving, but it would demonstrate the ease with which complex queries can be handled using principles of domain ontology, thereby facilitating better information retrieval.
* 26 pages, 12 figures, KNOWLEDGE ORGANIZATION Journal Paper