 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DoseDiff: Distance-aware Diffusion Model for Dose Prediction in Radiotherapy
Jun 28, 2023
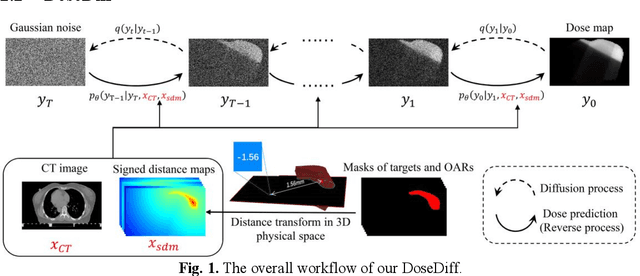
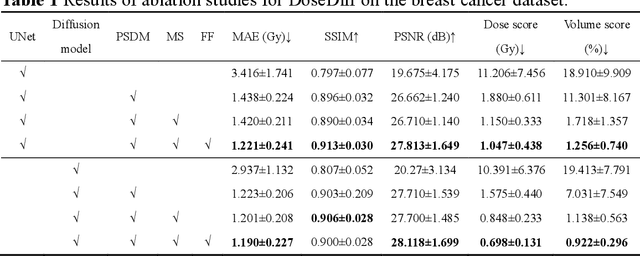
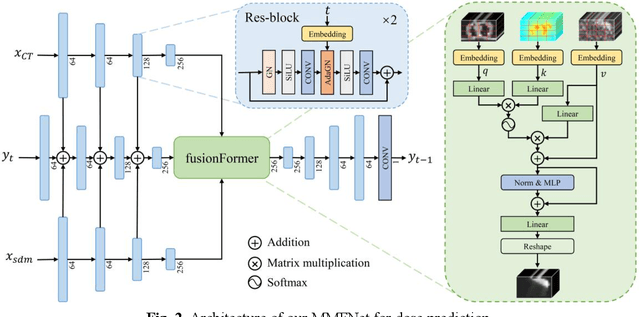
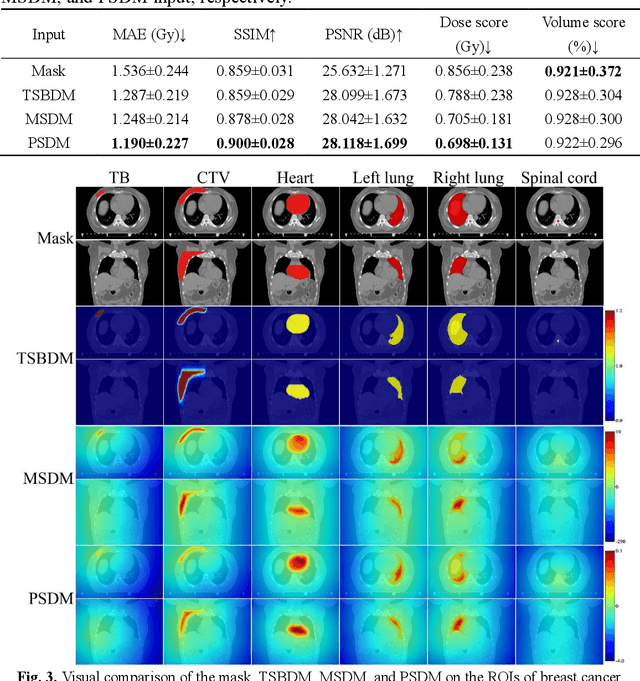
Treatment planning is a critical component of the radiotherapy workflow, typically carried out by a medical physicist using a time-consuming trial-and-error manner. Previous studies have proposed knowledge-based or deep learning-based methods for predicting dose distribution maps to assist medical physicists in improving the efficiency of treatment planning. However, these dose prediction methods usuallylack the effective utilization of distance information between surrounding tissues andtargets or organs-at-risk (OARs). Moreover, they are poor in maintaining the distribution characteristics of ray paths in the predicted dose distribution maps, resulting in a loss of valuable information obtained by medical physicists. In this paper, we propose a distance-aware diffusion model (DoseDiff) for precise prediction of dose distribution. We define dose prediction as a sequence of denoising steps, wherein the predicted dose distribution map is generated with the conditions of the CT image and signed distance maps (SDMs). The SDMs are obtained by a distance transformation from the masks of targets or OARs, which provide the distance information from each pixel in the image to the outline of the targets or OARs. Besides, we propose a multiencoder and multi-scale fusion network (MMFNet) that incorporates a multi-scale fusion and a transformer-based fusion module to enhance information fusion between the CT image and SDMs at the feature level. Our model was evaluated on two datasets collected from patients with breast cancer and nasopharyngeal cancer, respectively. The results demonstrate that our DoseDiff outperforms the state-of-the-art dose prediction methods in terms of both quantitative and visual quality.
A Gated Cross-domain Collaborative Network for Underwater Object Detection
Jun 25, 2023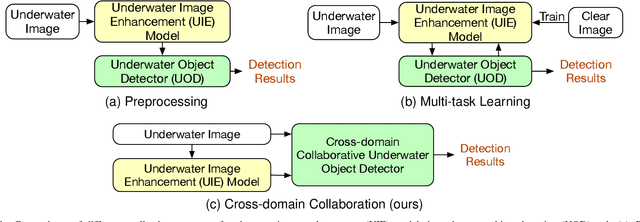
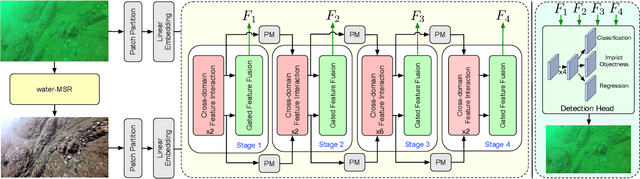
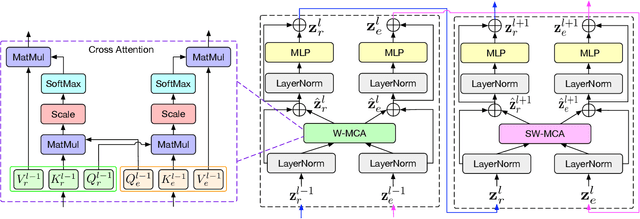

Underwater object detection (UOD) plays a significant role in aquaculture and marine environmental protection. Considering the challenges posed by low contrast and low-light conditions in underwater environments, several underwater image enhancement (UIE) methods have been proposed to improve the quality of underwater images. However, only using the enhanced images does not improve the performance of UOD, since it may unavoidably remove or alter critical patterns and details of underwater objects. In contrast, we believe that exploring the complementary information from the two domains is beneficial for UOD. The raw image preserves the natural characteristics of the scene and texture information of the objects, while the enhanced image improves the visibility of underwater objects. Based on this perspective, we propose a Gated Cross-domain Collaborative Network (GCC-Net) to address the challenges of poor visibility and low contrast in underwater environments, which comprises three dedicated components. Firstly, a real-time UIE method is employed to generate enhanced images, which can improve the visibility of objects in low-contrast areas. Secondly, a cross-domain feature interaction module is introduced to facilitate the interaction and mine complementary information between raw and enhanced image features. Thirdly, to prevent the contamination of unreliable generated results, a gated feature fusion module is proposed to adaptively control the fusion ratio of cross-domain information. Our method presents a new UOD paradigm from the perspective of cross-domain information interaction and fusion. Experimental results demonstrate that the proposed GCC-Net achieves state-of-the-art performance on four underwater datasets.
A Novel Dual-pooling Attention Module for UAV Vehicle Re-identification
Jun 25, 2023
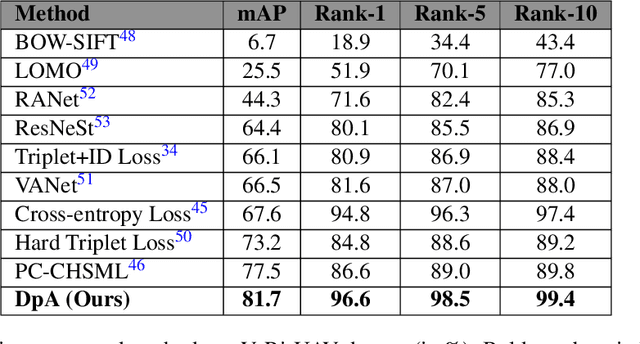
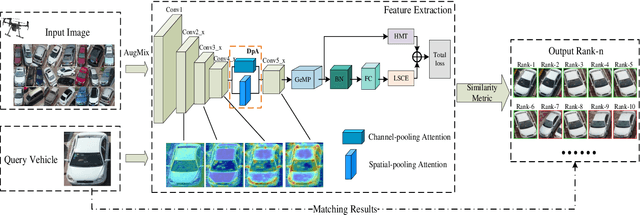
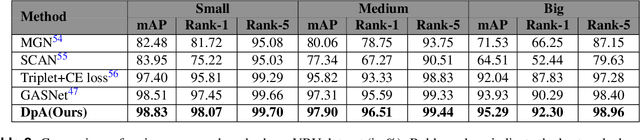
Vehicle re-identification (Re-ID) involves identifying the same vehicle captured by other cameras, given a vehicle image. It plays a crucial role in the development of safe cities and smart cities. With the rapid growth and implementation of unmanned aerial vehicles (UAVs) technology, vehicle Re-ID in UAV aerial photography scenes has garnered significant attention from researchers. However, due to the high altitude of UAVs, the shooting angle of vehicle images sometimes approximates vertical, resulting in fewer local features for Re-ID. Therefore, this paper proposes a novel dual-pooling attention (DpA) module, which achieves the extraction and enhancement of locally important information about vehicles from both channel and spatial dimensions by constructing two branches of channel-pooling attention (CpA) and spatial-pooling attention (SpA), and employing multiple pooling operations to enhance the attention to fine-grained information of vehicles. Specifically, the CpA module operates between the channels of the feature map and splices features by combining four pooling operations so that vehicle regions containing discriminative information are given greater attention. The SpA module uses the same pooling operations strategy to identify discriminative representations and merge vehicle features in image regions in a weighted manner. The feature information of both dimensions is finally fused and trained jointly using label smoothing cross-entropy loss and hard mining triplet loss, thus solving the problem of missing detail information due to the high height of UAV shots. The proposed method's effectiveness is demonstrated through extensive experiments on the UAV-based vehicle datasets VeRi-UAV and VRU.
Enlarging Instance-specific and Class-specific Information for Open-set Action Recognition
Mar 25, 2023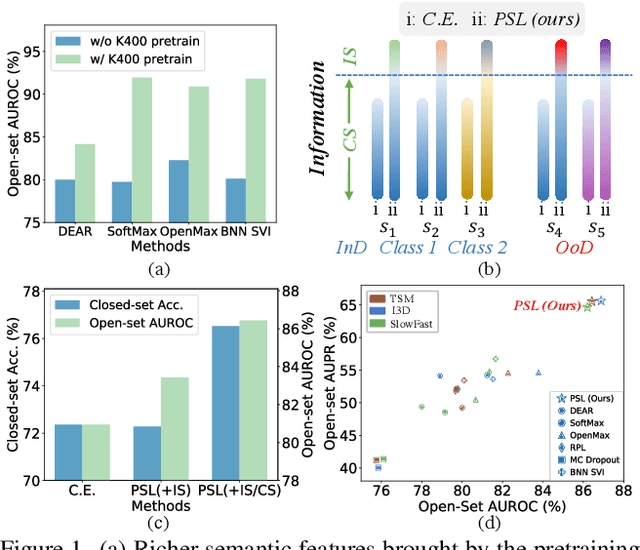
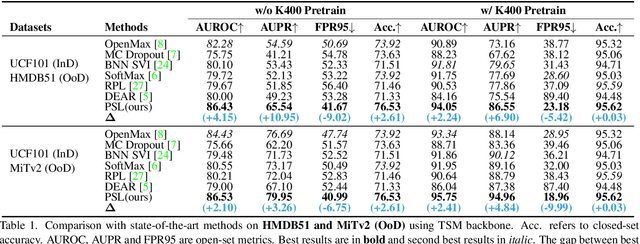
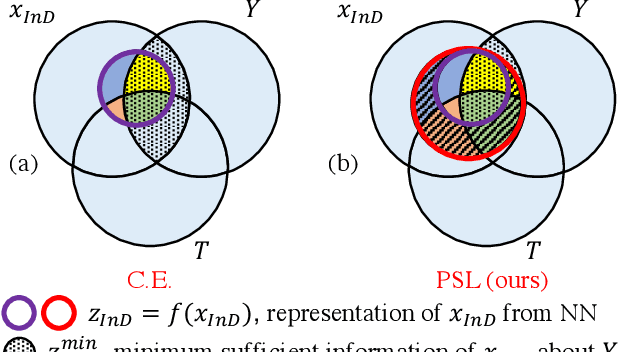
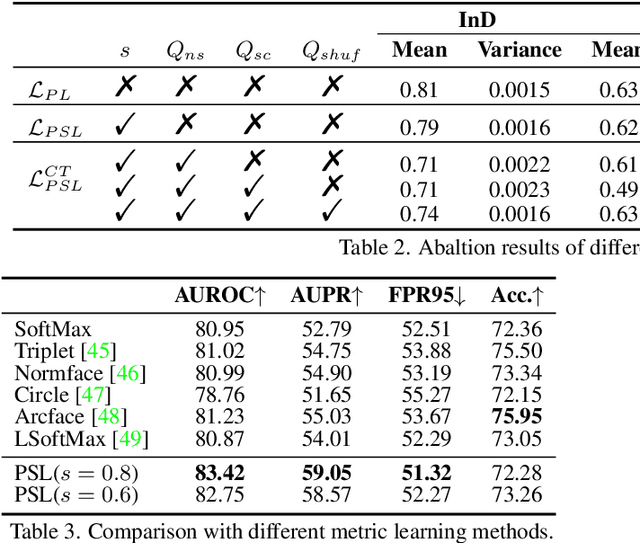
Open-set action recognition is to reject unknown human action cases which are out of the distribution of the training set. Existing methods mainly focus on learning better uncertainty scores but dismiss the importance of feature representations. We find that features with richer semantic diversity can significantly improve the open-set performance under the same uncertainty scores. In this paper, we begin with analyzing the feature representation behavior in the open-set action recognition (OSAR) problem based on the information bottleneck (IB) theory, and propose to enlarge the instance-specific (IS) and class-specific (CS) information contained in the feature for better performance. To this end, a novel Prototypical Similarity Learning (PSL) framework is proposed to keep the instance variance within the same class to retain more IS information. Besides, we notice that unknown samples sharing similar appearances to known samples are easily misclassified as known classes. To alleviate this issue, video shuffling is further introduced in our PSL to learn distinct temporal information between original and shuffled samples, which we find enlarges the CS information. Extensive experiments demonstrate that the proposed PSL can significantly boost both the open-set and closed-set performance and achieves state-of-the-art results on multiple benchmarks. Code is available at https://github.com/Jun-CEN/PSL.
Pathway toward prior knowledge-integrated machine learning in engineering
Jul 10, 2023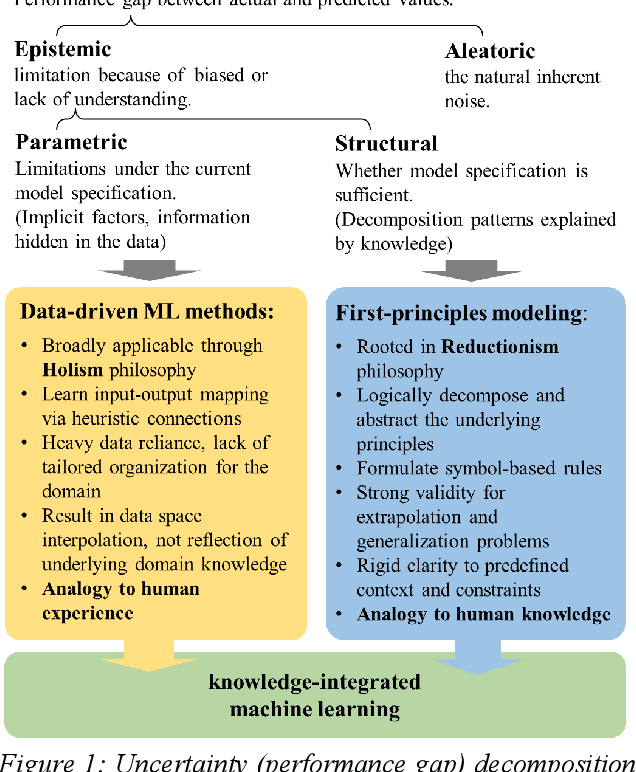
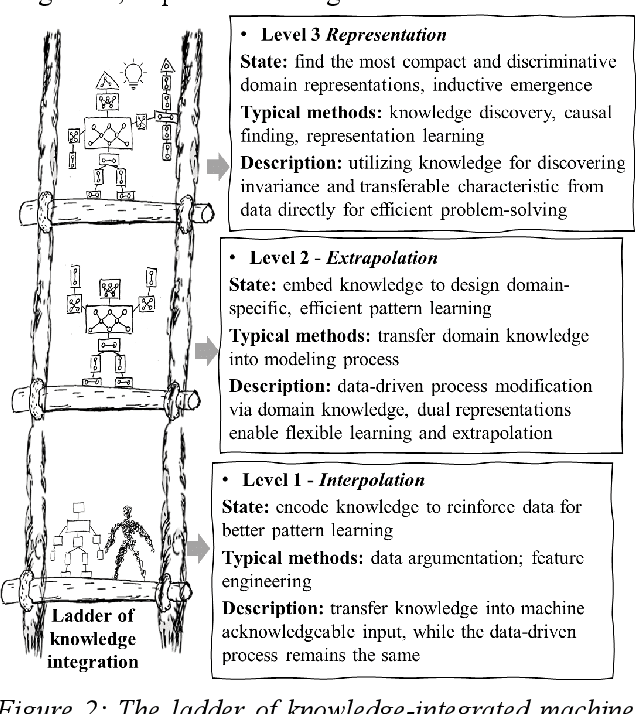
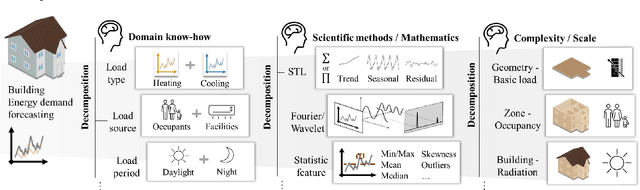
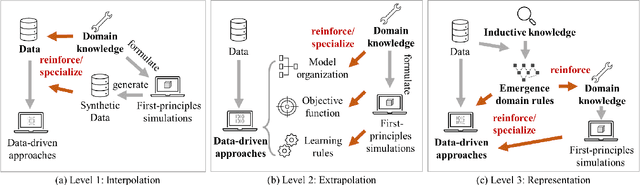
Despite the digitalization trend and data volume surge, first-principles models (also known as logic-driven, physics-based, rule-based, or knowledge-based models) and data-driven approaches have existed in parallel, mirroring the ongoing AI debate on symbolism versus connectionism. Research for process development to integrate both sides to transfer and utilize domain knowledge in the data-driven process is rare. This study emphasizes efforts and prevailing trends to integrate multidisciplinary domain professions into machine acknowledgeable, data-driven processes in a two-fold organization: examining information uncertainty sources in knowledge representation and exploring knowledge decomposition with a three-tier knowledge-integrated machine learning paradigm. This approach balances holist and reductionist perspectives in the engineering domain.
Deep learning for dynamic graphs: models and benchmarks
Jul 12, 2023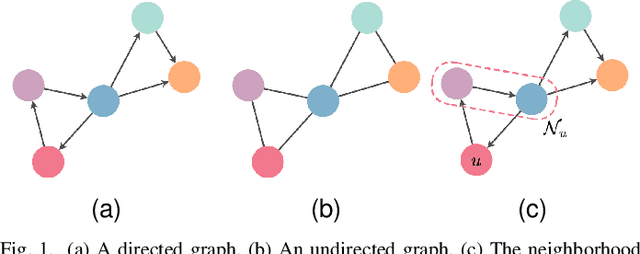
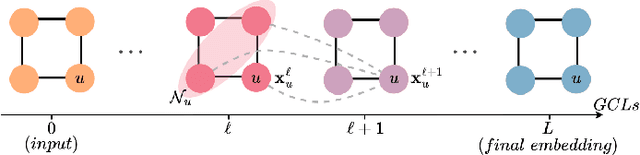
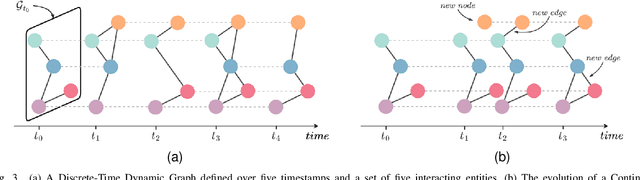
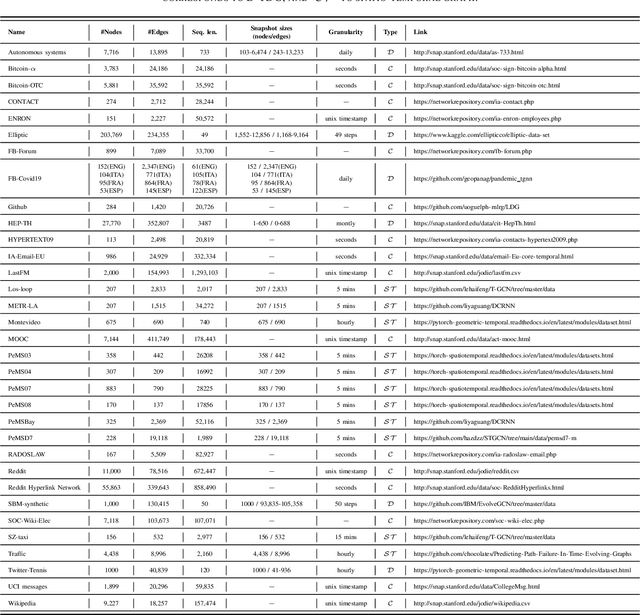
Recent progress in research on Deep Graph Networks (DGNs) has led to a maturation of the domain of learning on graphs. Despite the growth of this research field, there are still important challenges that are yet unsolved. Specifically, there is an urge of making DGNs suitable for predictive tasks on realworld systems of interconnected entities, which evolve over time. With the aim of fostering research in the domain of dynamic graphs, at first, we survey recent advantages in learning both temporal and spatial information, providing a comprehensive overview of the current state-of-the-art in the domain of representation learning for dynamic graphs. Secondly, we conduct a fair performance comparison among the most popular proposed approaches, leveraging rigorous model selection and assessment for all the methods, thus establishing a sound baseline for evaluating new architectures and approaches
Accurate deep learning sub-grid scale models for large eddy simulations
Jul 19, 2023We present two families of sub-grid scale (SGS) turbulence models developed for large-eddy simulation (LES) purposes. Their development required the formulation of physics-informed robust and efficient Deep Learning (DL) algorithms which, unlike state-of-the-art analytical modeling techniques can produce high-order complex non-linear relations between inputs and outputs. Explicit filtering of data from direct simulations of the canonical channel flow at two friction Reynolds numbers $Re_\tau\approx 395$ and 590 provided accurate data for training and testing. The two sets of models use different network architectures. One of the architectures uses tensor basis neural networks (TBNN) and embeds the simplified analytical model form of the general effective-viscosity hypothesis, thus incorporating the Galilean, rotational and reflectional invariances. The other architecture is that of a relatively simple network, that is able to incorporate the Galilean invariance only. However, this simpler architecture has better feature extraction capacity owing to its ability to establish relations between and extract information from cross-components of the integrity basis tensors and the SGS stresses. Both sets of models are used to predict the SGS stresses for feature datasets generated with different filter widths, and at different Reynolds numbers. It is shown that due to the simpler model's better feature learning capabilities, it outperforms the invariance embedded model in statistical performance metrics. In a priori tests, both sets of models provide similar levels of dissipation and backscatter. Based on the test results, both sets of models should be usable in a posteriori actual LESs.
A Personalized Reinforcement Learning Summarization Service for Learning Structure from Unstructured Data
Jul 09, 2023The exponential growth of textual data has created a crucial need for tools that assist users in extracting meaningful insights. Traditional document summarization approaches often fail to meet individual user requirements and lack structure for efficient information processing. To address these limitations, we propose Summation, a hierarchical personalized concept-based summarization approach. It synthesizes documents into a concise hierarchical concept map and actively engages users by learning and adapting to their preferences. Using a Reinforcement Learning algorithm, Summation generates personalized summaries for unseen documents on specific topics. This framework enhances comprehension, enables effective navigation, and empowers users to extract meaningful insights from large document collections aligned with their unique requirements.
Membership Inference Attacks on DNNs using Adversarial Perturbations
Jul 11, 2023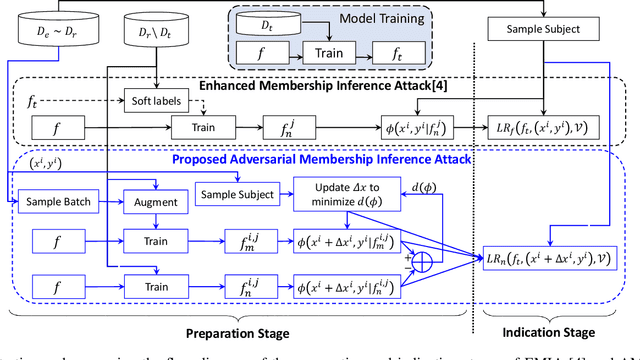
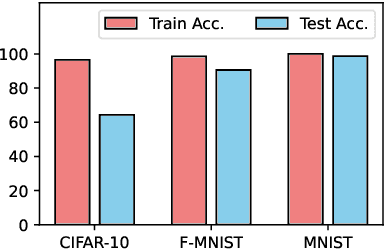
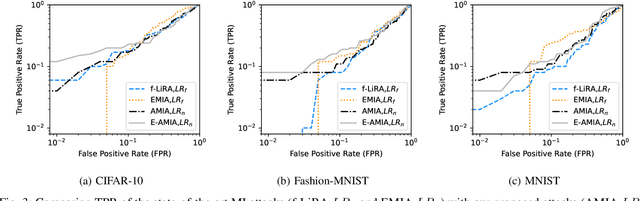
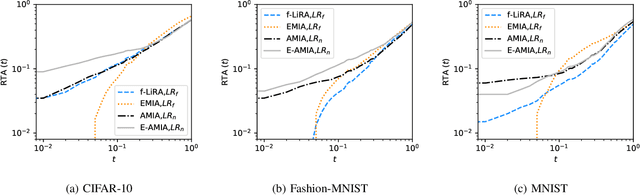
Several membership inference (MI) attacks have been proposed to audit a target DNN. Given a set of subjects, MI attacks tell which subjects the target DNN has seen during training. This work focuses on the post-training MI attacks emphasizing high confidence membership detection -- True Positive Rates (TPR) at low False Positive Rates (FPR). Current works in this category -- likelihood ratio attack (LiRA) and enhanced MI attack (EMIA) -- only perform well on complex datasets (e.g., CIFAR-10 and Imagenet) where the target DNN overfits its train set, but perform poorly on simpler datasets (0% TPR by both attacks on Fashion-MNIST, 2% and 0% TPR respectively by LiRA and EMIA on MNIST at 1% FPR). To address this, firstly, we unify current MI attacks by presenting a framework divided into three stages -- preparation, indication and decision. Secondly, we utilize the framework to propose two novel attacks: (1) Adversarial Membership Inference Attack (AMIA) efficiently utilizes the membership and the non-membership information of the subjects while adversarially minimizing a novel loss function, achieving 6% TPR on both Fashion-MNIST and MNIST datasets; and (2) Enhanced AMIA (E-AMIA) combines EMIA and AMIA to achieve 8% and 4% TPRs on Fashion-MNIST and MNIST datasets respectively, at 1% FPR. Thirdly, we introduce two novel augmented indicators that positively leverage the loss information in the Gaussian neighborhood of a subject. This improves TPR of all four attacks on average by 2.5% and 0.25% respectively on Fashion-MNIST and MNIST datasets at 1% FPR. Finally, we propose simple, yet novel, evaluation metric, the running TPR average (RTA) at a given FPR, that better distinguishes different MI attacks in the low FPR region. We also show that AMIA and E-AMIA are more transferable to the unknown DNNs (other than the target DNN) and are more robust to DP-SGD training as compared to LiRA and EMIA.
DRAGON: A Dialogue-Based Robot for Assistive Navigation with Visual Language Grounding
Jul 13, 2023
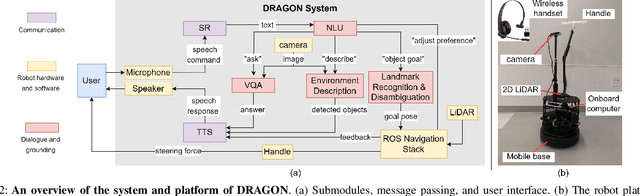
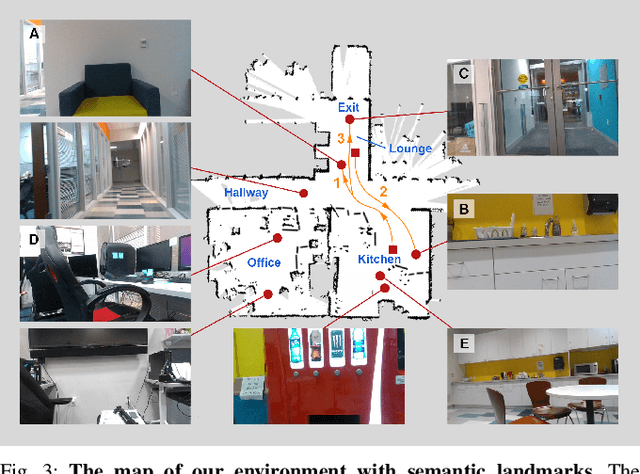

Persons with visual impairments (PwVI) have difficulties understanding and navigating spaces around them. Current wayfinding technologies either focus solely on navigation or provide limited communication about the environment. Motivated by recent advances in visual-language grounding and semantic navigation, we propose DRAGON, a guiding robot powered by a dialogue system and the ability to associate the environment with natural language. By understanding the commands from the user, DRAGON is able to guide the user to the desired landmarks on the map, describe the environment, and answer questions from visual observations. Through effective utilization of dialogue, the robot can ground the user's free-form descriptions to landmarks in the environment, and give the user semantic information through spoken language. We conduct a user study with blindfolded participants in an everyday indoor environment. Our results demonstrate that DRAGON is able to communicate with the user smoothly, provide a good guiding experience, and connect users with their surrounding environment in an intuitive manner.