 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multilingual Controllable Transformer-Based Lexical Simplification
Jul 05, 2023
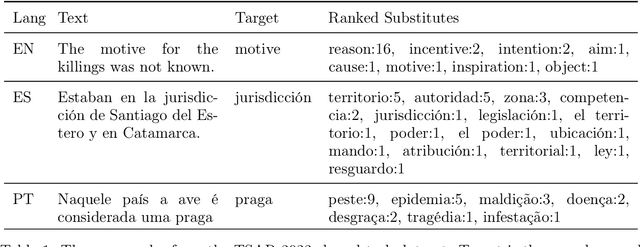

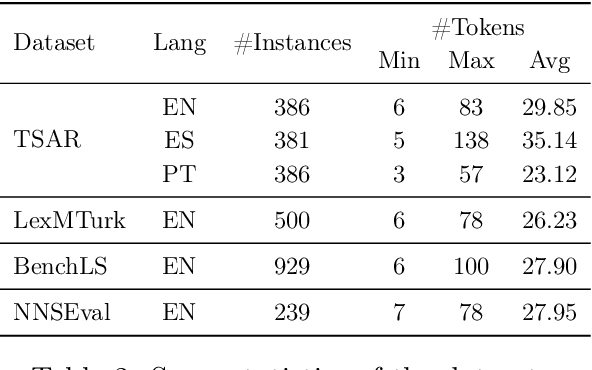

Text is by far the most ubiquitous source of knowledge and information and should be made easily accessible to as many people as possible; however, texts often contain complex words that hinder reading comprehension and accessibility. Therefore, suggesting simpler alternatives for complex words without compromising meaning would help convey the information to a broader audience. This paper proposes mTLS, a multilingual controllable Transformer-based Lexical Simplification (LS) system fined-tuned with the T5 model. The novelty of this work lies in the use of language-specific prefixes, control tokens, and candidates extracted from pre-trained masked language models to learn simpler alternatives for complex words. The evaluation results on three well-known LS datasets -- LexMTurk, BenchLS, and NNSEval -- show that our model outperforms the previous state-of-the-art models like LSBert and ConLS. Moreover, further evaluation of our approach on the part of the recent TSAR-2022 multilingual LS shared-task dataset shows that our model performs competitively when compared with the participating systems for English LS and even outperforms the GPT-3 model on several metrics. Moreover, our model obtains performance gains also for Spanish and Portuguese.
SegNetr: Rethinking the local-global interactions and skip connections in U-shaped networks
Jul 06, 2023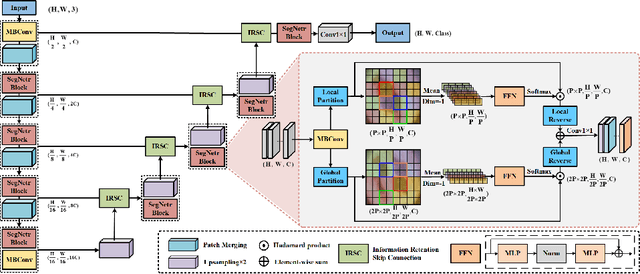
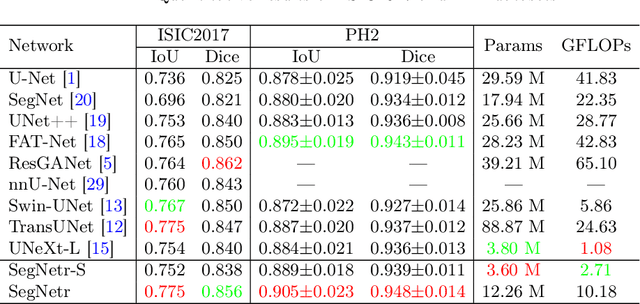
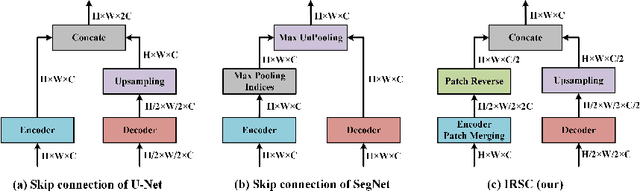
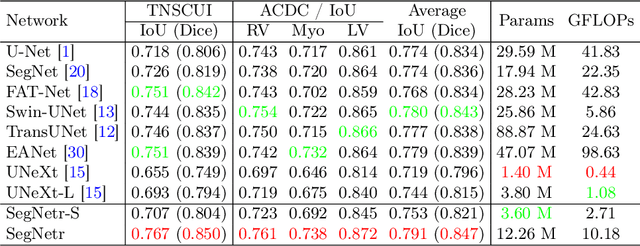
Recently, U-shaped networks have dominated the field of medical image segmentation due to their simple and easily tuned structure. However, existing U-shaped segmentation networks: 1) mostly focus on designing complex self-attention modules to compensate for the lack of long-term dependence based on convolution operation, which increases the overall number of parameters and computational complexity of the network; 2) simply fuse the features of encoder and decoder, ignoring the connection between their spatial locations. In this paper, we rethink the above problem and build a lightweight medical image segmentation network, called SegNetr. Specifically, we introduce a novel SegNetr block that can perform local-global interactions dynamically at any stage and with only linear complexity. At the same time, we design a general information retention skip connection (IRSC) to preserve the spatial location information of encoder features and achieve accurate fusion with the decoder features. We validate the effectiveness of SegNetr on four mainstream medical image segmentation datasets, with 59\% and 76\% fewer parameters and GFLOPs than vanilla U-Net, while achieving segmentation performance comparable to state-of-the-art methods. Notably, the components proposed in this paper can be applied to other U-shaped networks to improve their segmentation performance.
Recognition and Estimation of Human Finger Pointing with an RGB Camera for Robot Directive
Jul 06, 2023

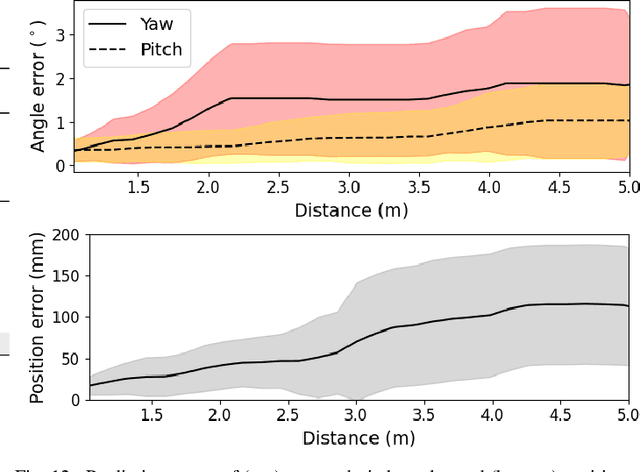
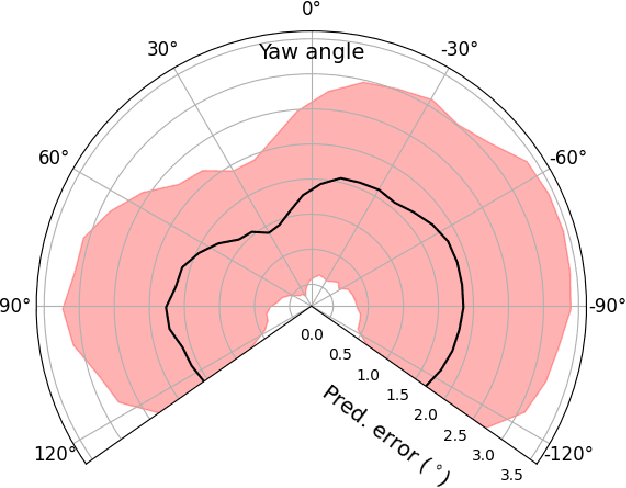
In communication between humans, gestures are often preferred or complementary to verbal expression since the former offers better spatial referral. Finger pointing gesture conveys vital information regarding some point of interest in the environment. In human-robot interaction, a user can easily direct a robot to a target location, for example, in search and rescue or factory assistance. State-of-the-art approaches for visual pointing estimation often rely on depth cameras, are limited to indoor environments and provide discrete predictions between limited targets. In this paper, we explore the learning of models for robots to understand pointing directives in various indoor and outdoor environments solely based on a single RGB camera. A novel framework is proposed which includes a designated model termed PointingNet. PointingNet recognizes the occurrence of pointing followed by approximating the position and direction of the index finger. The model relies on a novel segmentation model for masking any lifted arm. While state-of-the-art human pose estimation models provide poor pointing angle estimation accuracy of 28deg, PointingNet exhibits mean accuracy of less than 2deg. With the pointing information, the target is computed followed by planning and motion of the robot. The framework is evaluated on two robotic systems yielding accurate target reaching.
Abstractive Text Summarization for Resumes With Cutting Edge NLP Transformers and LSTM
Jun 23, 2023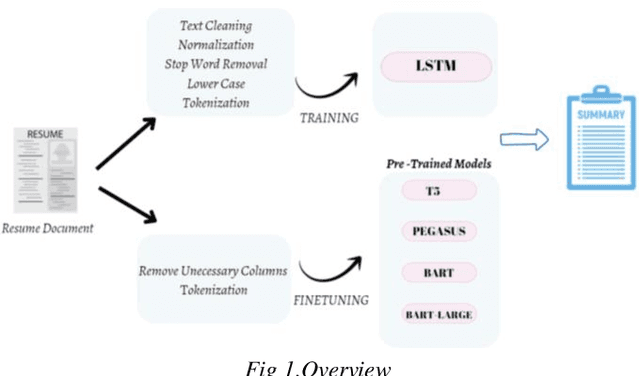
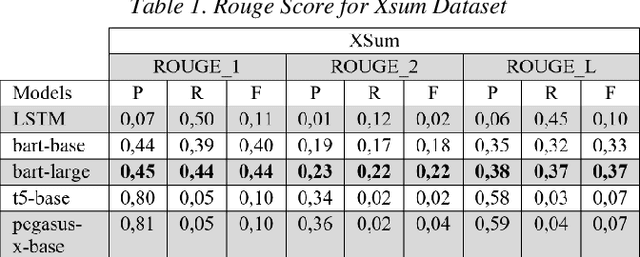
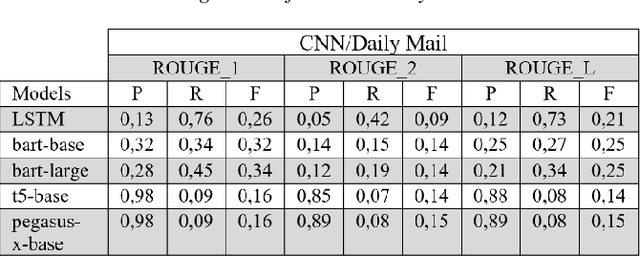
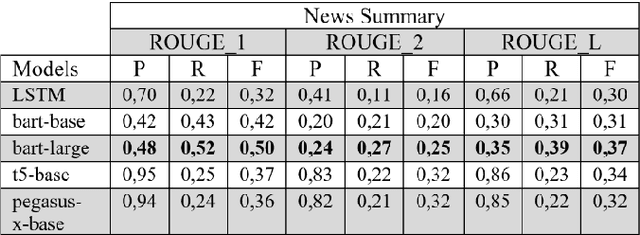
Text summarization is a fundamental task in natural language processing that aims to condense large amounts of textual information into concise and coherent summaries. With the exponential growth of content and the need to extract key information efficiently, text summarization has gained significant attention in recent years. In this study, LSTM and pre-trained T5, Pegasus, BART and BART-Large model performances were evaluated on the open source dataset (Xsum, CNN/Daily Mail, Amazon Fine Food Review and News Summary) and the prepared resume dataset. This resume dataset consists of many information such as language, education, experience, personal information, skills, and this data includes 75 resumes. The primary objective of this research was to classify resume text. Various techniques such as LSTM, pre-trained models, and fine-tuned models were assessed using a dataset of resumes. The BART-Large model fine-tuned with the resume dataset gave the best performance.
OptMSM: Optimizing Multi-Scenario Modeling for Click-Through Rate Prediction
Jun 23, 2023A large-scale industrial recommendation platform typically consists of multiple associated scenarios, requiring a unified click-through rate (CTR) prediction model to serve them simultaneously. Existing approaches for multi-scenario CTR prediction generally consist of two main modules: i) a scenario-aware learning module that learns a set of multi-functional representations with scenario-shared and scenario-specific information from input features, and ii) a scenario-specific prediction module that serves each scenario based on these representations. However, most of these approaches primarily focus on improving the former module and neglect the latter module. This can result in challenges such as increased model parameter size, training difficulty, and performance bottlenecks for each scenario. To address these issues, we propose a novel framework called OptMSM (\textbf{Opt}imizing \textbf{M}ulti-\textbf{S}cenario \textbf{M}odeling). First, we introduce a simplified yet effective scenario-enhanced learning module to alleviate the aforementioned challenges. Specifically, we partition the input features into scenario-specific and scenario-shared features, which are mapped to specific information embedding encodings and a set of shared information embeddings, respectively. By imposing an orthogonality constraint on the shared information embeddings to facilitate the disentanglement of shared information corresponding to each scenario, we combine them with the specific information embeddings to obtain multi-functional representations. Second, we introduce a scenario-specific hypernetwork in the scenario-specific prediction module to capture interactions within each scenario more effectively, thereby alleviating the performance bottlenecks. Finally, we conduct extensive offline experiments and an online A/B test to demonstrate the effectiveness of OptMSM.
CareFall: Automatic Fall Detection through Wearable Devices and AI Methods
Jul 11, 2023
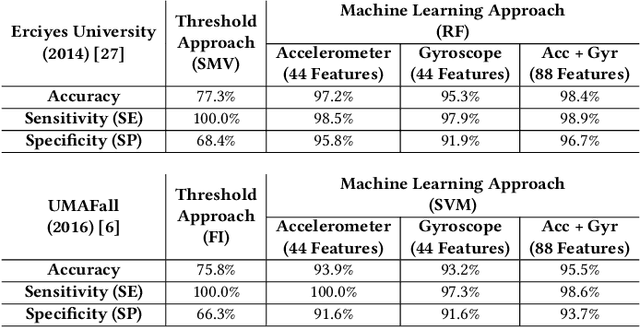
The aging population has led to a growing number of falls in our society, affecting global public health worldwide. This paper presents CareFall, an automatic Fall Detection System (FDS) based on wearable devices and Artificial Intelligence (AI) methods. CareFall considers the accelerometer and gyroscope time signals extracted from a smartwatch. Two different approaches are used for feature extraction and classification: i) threshold-based, and ii) machine learning-based. Experimental results on two public databases show that the machine learning-based approach, which combines accelerometer and gyroscope information, outperforms the threshold-based approach in terms of accuracy, sensitivity, and specificity. This research contributes to the design of smart and user-friendly solutions to mitigate the negative consequences of falls among older people.
Making the Most Out of the Limited Context Length: Predictive Power Varies with Clinical Note Type and Note Section
Jul 13, 2023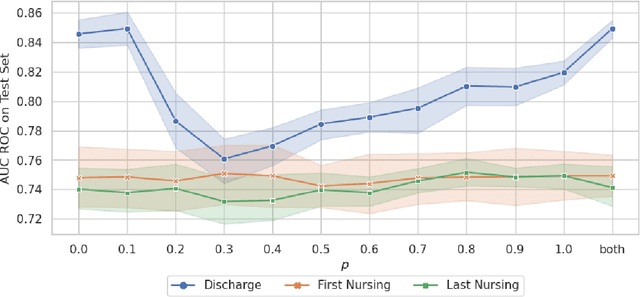
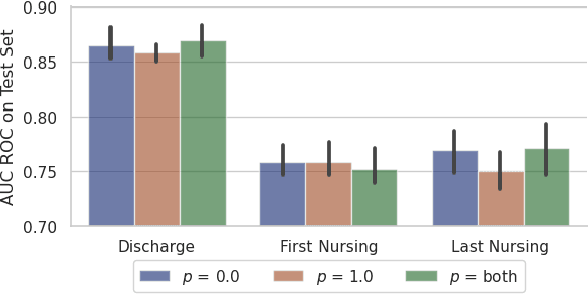
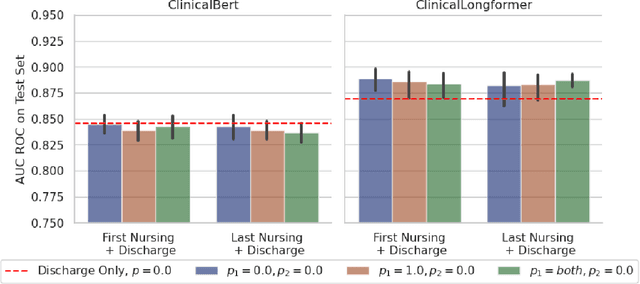
Recent advances in large language models have led to renewed interest in natural language processing in healthcare using the free text of clinical notes. One distinguishing characteristic of clinical notes is their long time span over multiple long documents. The unique structure of clinical notes creates a new design choice: when the context length for a language model predictor is limited, which part of clinical notes should we choose as the input? Existing studies either choose the inputs with domain knowledge or simply truncate them. We propose a framework to analyze the sections with high predictive power. Using MIMIC-III, we show that: 1) predictive power distribution is different between nursing notes and discharge notes and 2) combining different types of notes could improve performance when the context length is large. Our findings suggest that a carefully selected sampling function could enable more efficient information extraction from clinical notes.
* Our code is publicly available on GitHub (https://github.com/nyuolab/EfficientTransformer)
Near-Optimal Bounds for Learning Gaussian Halfspaces with Random Classification Noise
Jul 13, 2023We study the problem of learning general (i.e., not necessarily homogeneous) halfspaces with Random Classification Noise under the Gaussian distribution. We establish nearly-matching algorithmic and Statistical Query (SQ) lower bound results revealing a surprising information-computation gap for this basic problem. Specifically, the sample complexity of this learning problem is $\widetilde{\Theta}(d/\epsilon)$, where $d$ is the dimension and $\epsilon$ is the excess error. Our positive result is a computationally efficient learning algorithm with sample complexity $\tilde{O}(d/\epsilon + d/(\max\{p, \epsilon\})^2)$, where $p$ quantifies the bias of the target halfspace. On the lower bound side, we show that any efficient SQ algorithm (or low-degree test) for the problem requires sample complexity at least $\Omega(d^{1/2}/(\max\{p, \epsilon\})^2)$. Our lower bound suggests that this quadratic dependence on $1/\epsilon$ is inherent for efficient algorithms.
GraSS: Contrastive Learning with Gradient Guided Sampling Strategy for Remote Sensing Image Semantic Segmentation
Jul 03, 2023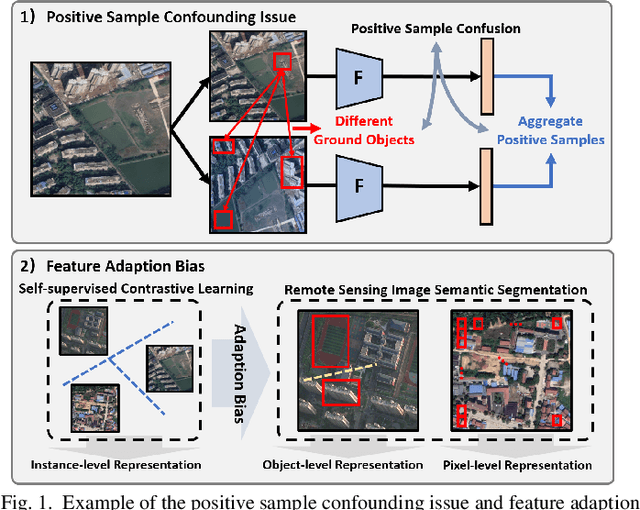
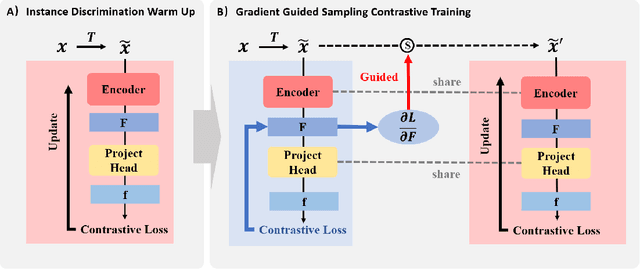
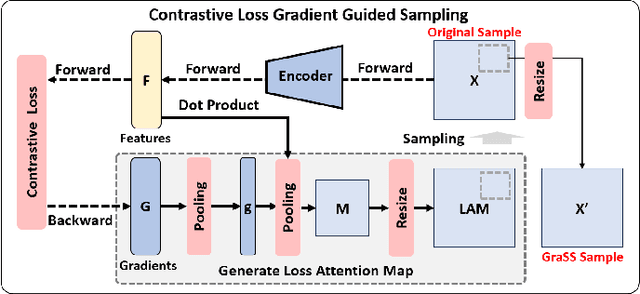
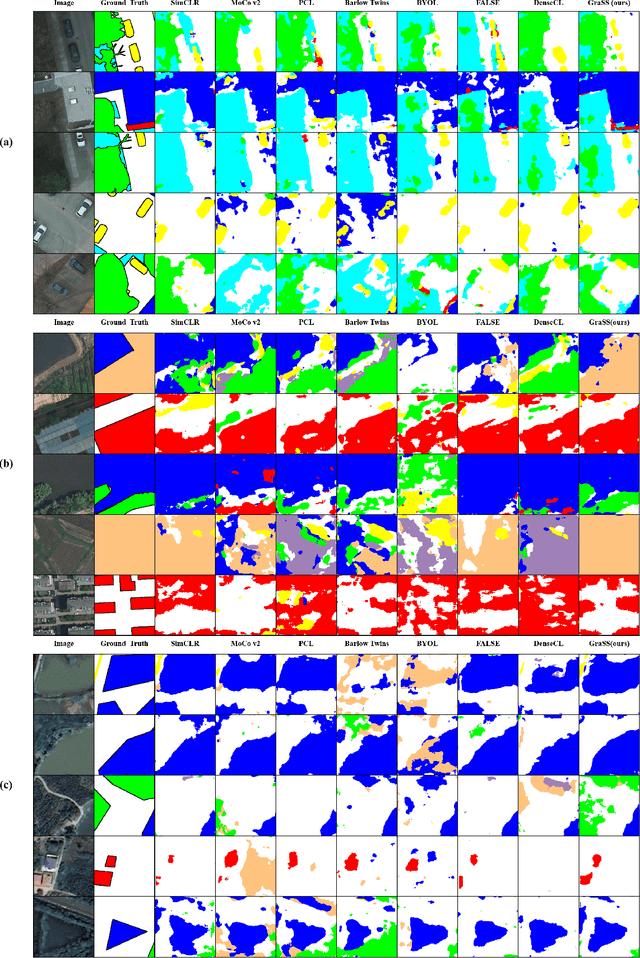
Self-supervised contrastive learning (SSCL) has achieved significant milestones in remote sensing image (RSI) understanding. Its essence lies in designing an unsupervised instance discrimination pretext task to extract image features from a large number of unlabeled images that are beneficial for downstream tasks. However, existing instance discrimination based SSCL suffer from two limitations when applied to the RSI semantic segmentation task: 1) Positive sample confounding issue; 2) Feature adaptation bias. It introduces a feature adaptation bias when applied to semantic segmentation tasks that require pixel-level or object-level features. In this study, We observed that the discrimination information can be mapped to specific regions in RSI through the gradient of unsupervised contrastive loss, these specific regions tend to contain singular ground objects. Based on this, we propose contrastive learning with Gradient guided Sampling Strategy (GraSS) for RSI semantic segmentation. GraSS consists of two stages: Instance Discrimination warm-up (ID warm-up) and Gradient guided Sampling contrastive training (GS training). The ID warm-up aims to provide initial discrimination information to the contrastive loss gradients. The GS training stage aims to utilize the discrimination information contained in the contrastive loss gradients and adaptively select regions in RSI patches that contain more singular ground objects, in order to construct new positive and negative samples. Experimental results on three open datasets demonstrate that GraSS effectively enhances the performance of SSCL in high-resolution RSI semantic segmentation. Compared to seven baseline methods from five different types of SSCL, GraSS achieves an average improvement of 1.57\% and a maximum improvement of 3.58\% in terms of mean intersection over the union. The source code is available at https://github.com/GeoX-Lab/GraSS
Stress Testing BERT Anaphora Resolution Models for Reaction Extraction in Chemical Patents
Jun 23, 2023
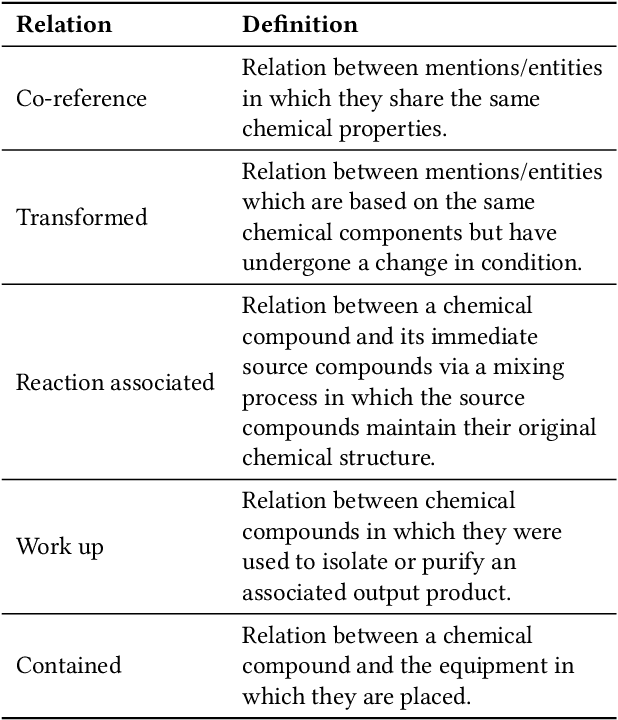
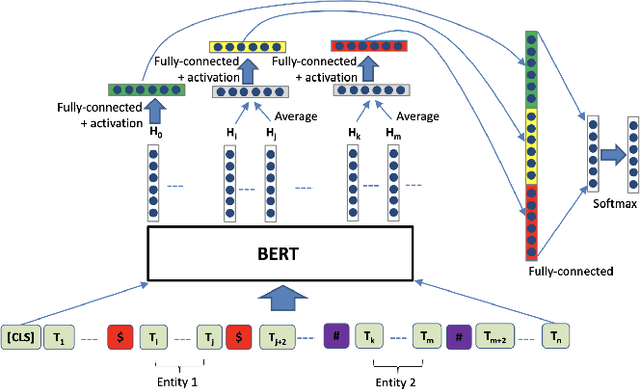
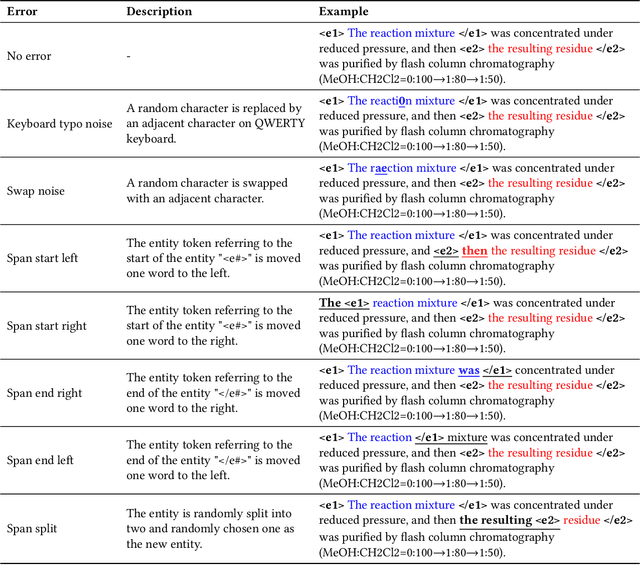
The high volume of published chemical patents and the importance of a timely acquisition of their information gives rise to automating information extraction from chemical patents. Anaphora resolution is an important component of comprehensive information extraction, and is critical for extracting reactions. In chemical patents, there are five anaphoric relations of interest: co-reference, transformed, reaction associated, work up, and contained. Our goal is to investigate how the performance of anaphora resolution models for reaction texts in chemical patents differs in a noise-free and noisy environment and to what extent we can improve the robustness against noise of the model.