 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
STTracker: Spatio-Temporal Tracker for 3D Single Object Tracking
Jun 30, 2023

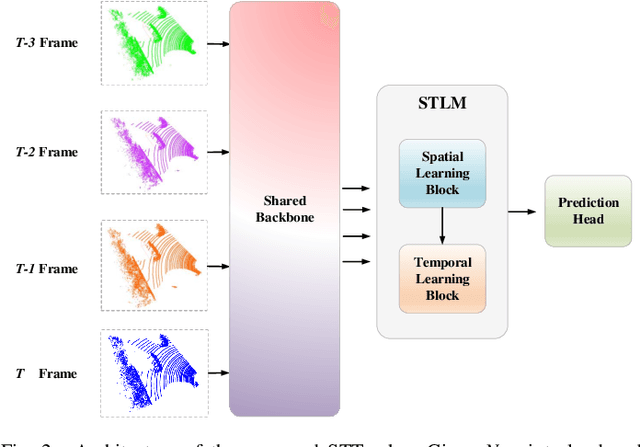
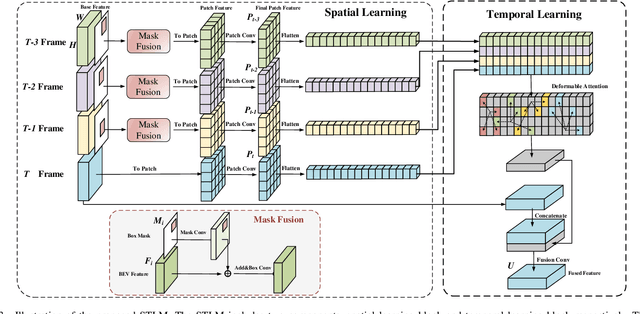

3D single object tracking with point clouds is a critical task in 3D computer vision. Previous methods usually input the last two frames and use the predicted box to get the template point cloud in previous frame and the search area point cloud in the current frame respectively, then use similarity-based or motion-based methods to predict the current box. Although these methods achieved good tracking performance, they ignore the historical information of the target, which is important for tracking. In this paper, compared to inputting two frames of point clouds, we input multi-frame of point clouds to encode the spatio-temporal information of the target and learn the motion information of the target implicitly, which could build the correlations among different frames to track the target in the current frame efficiently. Meanwhile, rather than directly using the point feature for feature fusion, we first crop the point cloud features into many patches and then use sparse attention mechanism to encode the patch-level similarity and finally fuse the multi-frame features. Extensive experiments show that our method achieves competitive results on challenging large-scale benchmarks (62.6% in KITTI and 49.66% in NuScenes).
Augmenting Holistic Review in University Admission using Natural Language Processing for Essays and Recommendation Letters
Jun 30, 2023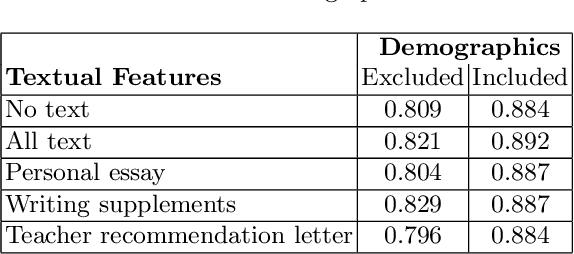
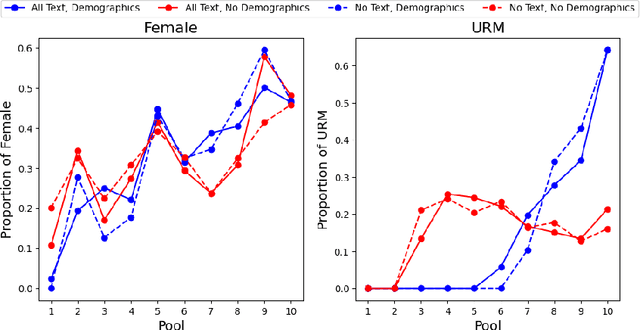
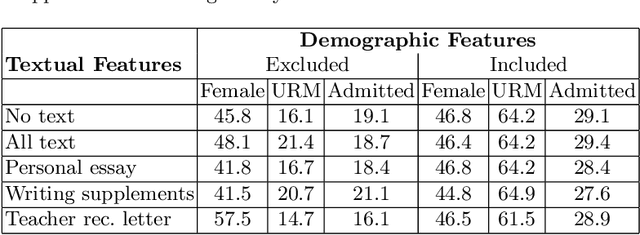
University admission at many highly selective institutions uses a holistic review process, where all aspects of the application, including protected attributes (e.g., race, gender), grades, essays, and recommendation letters are considered, to compose an excellent and diverse class. In this study, we empirically evaluate how influential protected attributes are for predicting admission decisions using a machine learning (ML) model, and in how far textual information (e.g., personal essay, teacher recommendation) may substitute for the loss of protected attributes in the model. Using data from 14,915 applicants to an undergraduate admission office at a selective U.S. institution in the 2022-2023 cycle, we find that the exclusion of protected attributes from the ML model leads to substantially reduced admission-prediction performance. The inclusion of textual information via both a TF-IDF representation and a Latent Dirichlet allocation (LDA) model partially restores model performance, but does not appear to provide a full substitute for admitting a similarly diverse class. In particular, while the text helps with gender diversity, the proportion of URM applicants is severely impacted by the exclusion of protected attributes, and the inclusion of new attributes generated from the textual information does not recover this performance loss.
An Information-Theoretic Perspective on Variance-Invariance-Covariance Regularization
Mar 06, 2023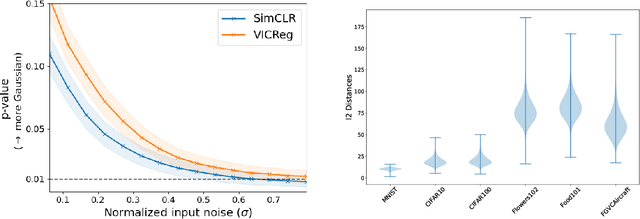

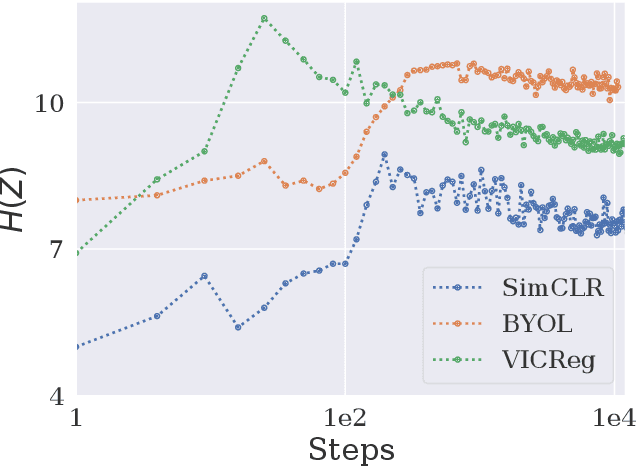
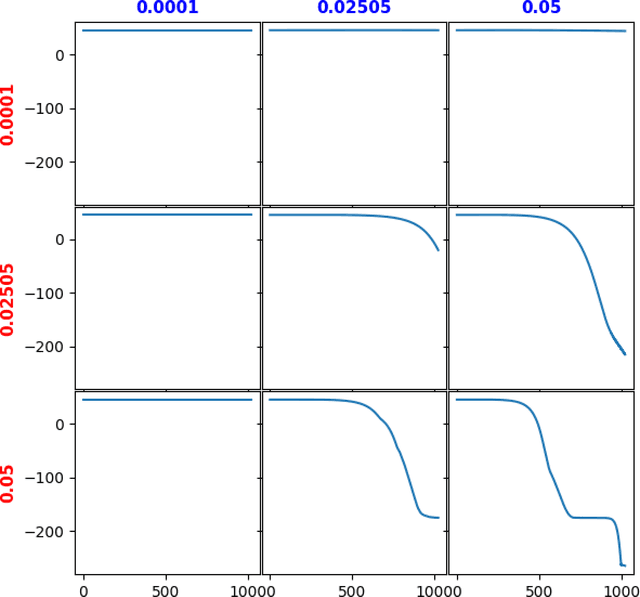
In this paper, we provide an information-theoretic perspective on Variance-Invariance-Covariance Regularization (VICReg) for self-supervised learning. To do so, we first demonstrate how information-theoretic quantities can be obtained for deterministic networks as an alternative to the commonly used unrealistic stochastic networks assumption. Next, we relate the VICReg objective to mutual information maximization and use it to highlight the underlying assumptions of the objective. Based on this relationship, we derive a generalization bound for VICReg, providing generalization guarantees for downstream supervised learning tasks and present new self-supervised learning methods, derived from a mutual information maximization objective, that outperform existing methods in terms of performance. This work provides a new information-theoretic perspective on self-supervised learning and Variance-Invariance-Covariance Regularization in particular and guides the way for improved transfer learning via information-theoretic self-supervised learning objectives.
GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
Jun 27, 2023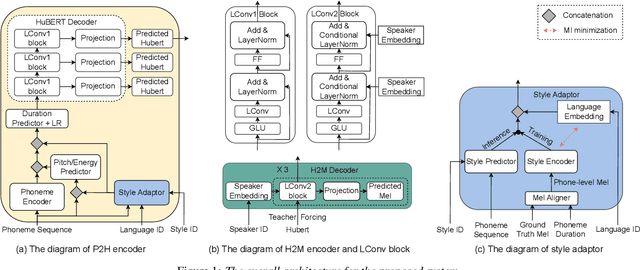

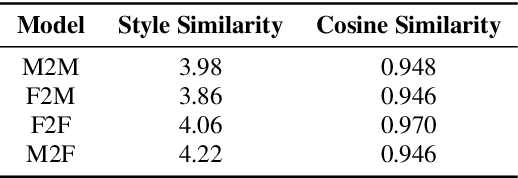
Cross-lingual timbre and style generalizable text-to-speech (TTS) aims to synthesize speech with a specific reference timbre or style that is never trained in the target language. It encounters the following challenges: 1) timbre and pronunciation are correlated since multilingual speech of a specific speaker is usually hard to obtain; 2) style and pronunciation are mixed because the speech style contains language-agnostic and language-specific parts. To address these challenges, we propose GenerTTS, which mainly includes the following works: 1) we elaborately design a HuBERT-based information bottleneck to disentangle timbre and pronunciation/style; 2) we minimize the mutual information between style and language to discard the language-specific information in the style embedding. The experiments indicate that GenerTTS outperforms baseline systems in terms of style similarity and pronunciation accuracy, and enables cross-lingual timbre and style generalization.
Prompt Ensemble Self-training for Open-Vocabulary Domain Adaptation
Jun 29, 2023Traditional domain adaptation assumes the same vocabulary across source and target domains, which often struggles with limited transfer flexibility and efficiency while handling target domains with different vocabularies. Inspired by recent vision-language models (VLMs) that enable open-vocabulary visual recognition by reasoning on both images and texts, we study open-vocabulary domain adaptation (OVDA), a new unsupervised domain adaptation framework that positions a pre-trained VLM as the source model and transfers it towards arbitrary unlabelled target domains. To this end, we design a Prompt Ensemble Self-training (PEST) technique that exploits the synergy between vision and language to mitigate the domain discrepancies in image and text distributions simultaneously. Specifically, PEST makes use of the complementary property of multiple prompts within and across vision and language modalities, which enables joint exploitation of vision and language information and effective learning of image-text correspondences in the unlabelled target domains. Additionally, PEST captures temporal information via temporal prompt ensemble which helps memorize previously learnt target information. Extensive experiments show that PEST outperforms the state-of-the-art consistently across 10 image recognition tasks.
Deep Equilibrium Multimodal Fusion
Jun 29, 2023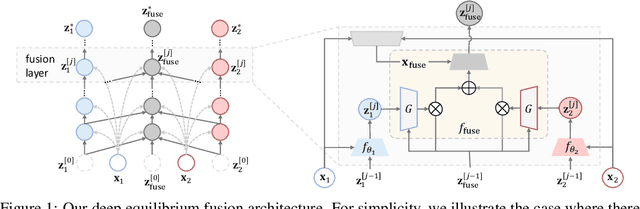
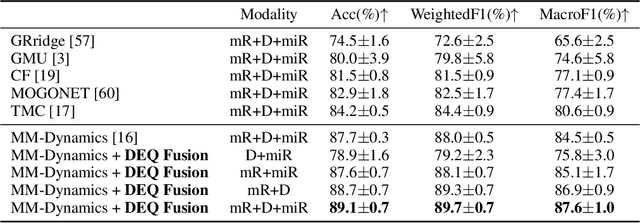

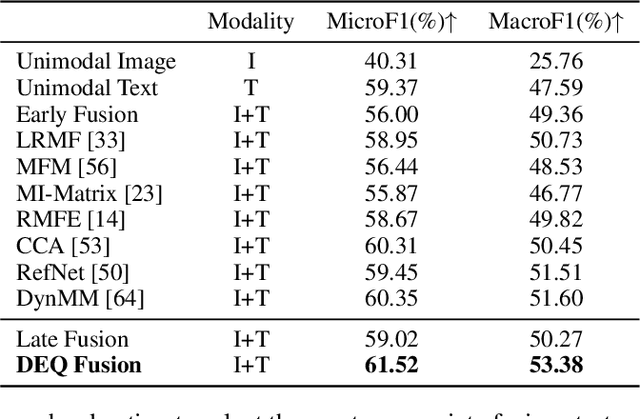
Multimodal fusion integrates the complementary information present in multiple modalities and has gained much attention recently. Most existing fusion approaches either learn a fixed fusion strategy during training and inference, or are only capable of fusing the information to a certain extent. Such solutions may fail to fully capture the dynamics of interactions across modalities especially when there are complex intra- and inter-modality correlations to be considered for informative multimodal fusion. In this paper, we propose a novel deep equilibrium (DEQ) method towards multimodal fusion via seeking a fixed point of the dynamic multimodal fusion process and modeling the feature correlations in an adaptive and recursive manner. This new way encodes the rich information within and across modalities thoroughly from low level to high level for efficacious downstream multimodal learning and is readily pluggable to various multimodal frameworks. Extensive experiments on BRCA, MM-IMDB, CMU-MOSI, SUN RGB-D, and VQA-v2 demonstrate the superiority of our DEQ fusion. More remarkably, DEQ fusion consistently achieves state-of-the-art performance on multiple multimodal benchmarks. The code will be released.
Are words equally surprising in audio and audio-visual comprehension?
Jul 14, 2023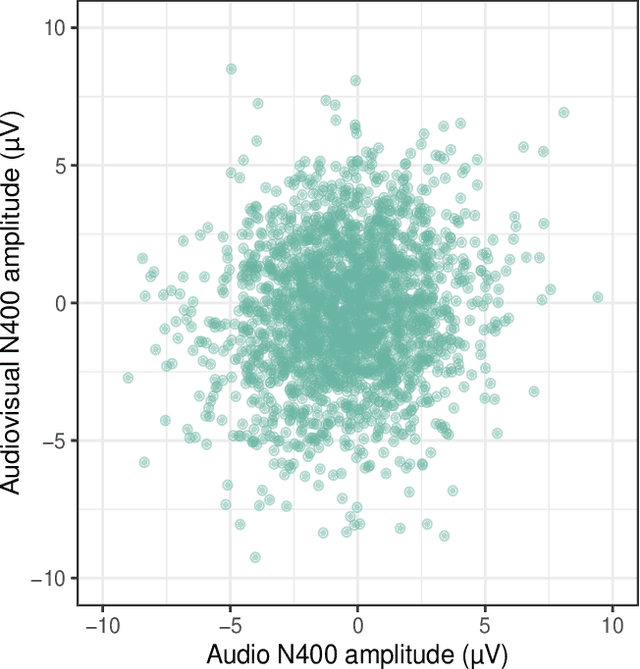
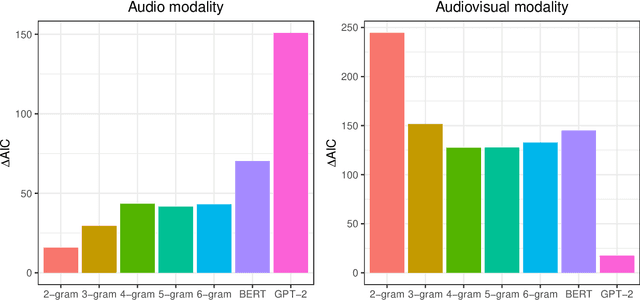
We report a controlled study investigating the effect of visual information (i.e., seeing the speaker) on spoken language comprehension. We compare the ERP signature (N400) associated with each word in audio-only and audio-visual presentations of the same verbal stimuli. We assess the extent to which surprisal measures (which quantify the predictability of words in their lexical context) are generated on the basis of different types of language models (specifically n-gram and Transformer models) that predict N400 responses for each word. Our results indicate that cognitive effort differs significantly between multimodal and unimodal settings. In addition, our findings suggest that while Transformer-based models, which have access to a larger lexical context, provide a better fit in the audio-only setting, 2-gram language models are more effective in the multimodal setting. This highlights the significant impact of local lexical context on cognitive processing in a multimodal environment.
FMT: Removing Backdoor Feature Maps via Feature Map Testing in Deep Neural Networks
Jul 21, 2023Deep neural networks have been widely used in many critical applications, such as autonomous vehicles and medical diagnosis. However, their security is threatened by backdoor attack, which is achieved by adding artificial patterns to specific training data. Existing defense strategies primarily focus on using reverse engineering to reproduce the backdoor trigger generated by attackers and subsequently repair the DNN model by adding the trigger into inputs and fine-tuning the model with ground-truth labels. However, once the trigger generated by the attackers is complex and invisible, the defender can not successfully reproduce the trigger. Consequently, the DNN model will not be repaired since the trigger is not effectively removed. In this work, we propose Feature Map Testing~(FMT). Different from existing defense strategies, which focus on reproducing backdoor triggers, FMT tries to detect the backdoor feature maps, which are trained to extract backdoor information from the inputs. After detecting these backdoor feature maps, FMT will erase them and then fine-tune the model with a secure subset of training data. Our experiments demonstrate that, compared to existing defense strategies, FMT can effectively reduce the Attack Success Rate (ASR) even against the most complex and invisible attack triggers. Second, unlike conventional defense methods that tend to exhibit low Robust Accuracy (i.e., the model's accuracy on the poisoned data), FMT achieves higher RA, indicating its superiority in maintaining model performance while mitigating the effects of backdoor attacks~(e.g., FMT obtains 87.40\% RA in CIFAR10). Third, compared to existing feature map pruning techniques, FMT can cover more backdoor feature maps~(e.g., FMT removes 83.33\% of backdoor feature maps from the model in the CIFAR10 \& BadNet scenario).
Exact Diffusion Inversion via Bi-directional Integration Approximation
Jul 21, 2023

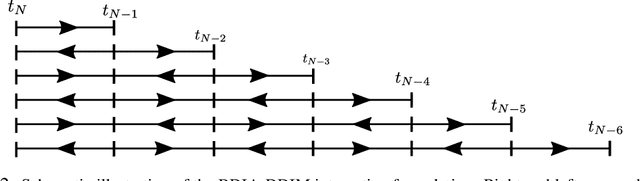

Recently, different methods have been proposed to address the inconsistency issue of DDIM inversion to enable image editing, such as EDICT \cite{Wallace23EDICT} and Null-text inversion \cite{Mokady23NullTestInv}. However, the above methods introduce considerable computational overhead. In this paper, we propose a new technique, named \emph{bi-directional integration approximation} (BDIA), to perform exact diffusion inversion with neglible computational overhead. Suppose we would like to estimate the next diffusion state $\boldsymbol{z}_{i-1}$ at timestep $t_i$ with the historical information $(i,\boldsymbol{z}_i)$ and $(i+1,\boldsymbol{z}_{i+1})$. We first obtain the estimated Gaussian noise $\hat{\boldsymbol{\epsilon}}(\boldsymbol{z}_i,i)$, and then apply the DDIM update procedure twice for approximating the ODE integration over the next time-slot $[t_i, t_{i-1}]$ in the forward manner and the previous time-slot $[t_i, t_{t+1}]$ in the backward manner. The DDIM step for the previous time-slot is used to refine the integration approximation made earlier when computing $\boldsymbol{z}_i$. One nice property with BDIA-DDIM is that the update expression for $\boldsymbol{z}_{i-1}$ is a linear combination of $(\boldsymbol{z}_{i+1}, \boldsymbol{z}_i, \hat{\boldsymbol{\epsilon}}(\boldsymbol{z}_i,i))$. This allows for exact backward computation of $\boldsymbol{z}_{i+1}$ given $(\boldsymbol{z}_i, \boldsymbol{z}_{i-1})$, thus leading to exact diffusion inversion. Experiments on both image reconstruction and image editing were conducted, confirming our statement. BDIA can also be applied to improve the performance of other ODE solvers in addition to DDIM. In our work, it is found that applying BDIA to the EDM sampling procedure produces slightly better FID score over CIFAR10.
LIMITR: Leveraging Local Information for Medical Image-Text Representation
Mar 21, 2023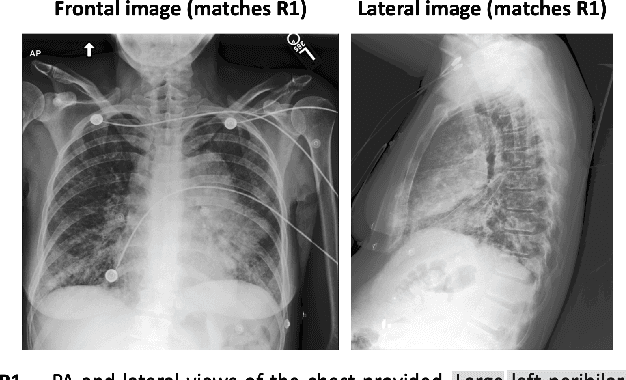
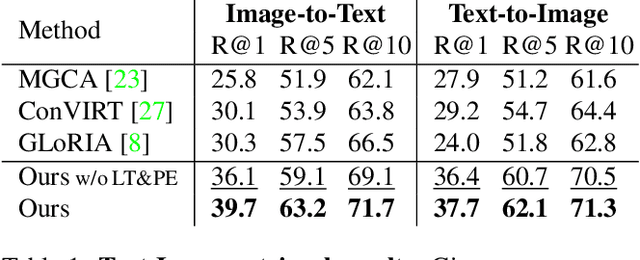
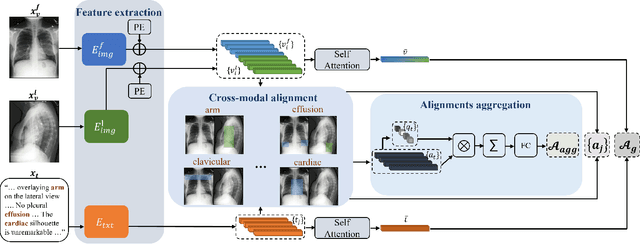

Medical imaging analysis plays a critical role in the diagnosis and treatment of various medical conditions. This paper focuses on chest X-ray images and their corresponding radiological reports. It presents a new model that learns a joint X-ray image & report representation. The model is based on a novel alignment scheme between the visual data and the text, which takes into account both local and global information. Furthermore, the model integrates domain-specific information of two types -- lateral images and the consistent visual structure of chest images. Our representation is shown to benefit three types of retrieval tasks: text-image retrieval, class-based retrieval, and phrase-grounding.