 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ChatGPT and Bard Responses to Polarizing Questions
Jul 13, 2023


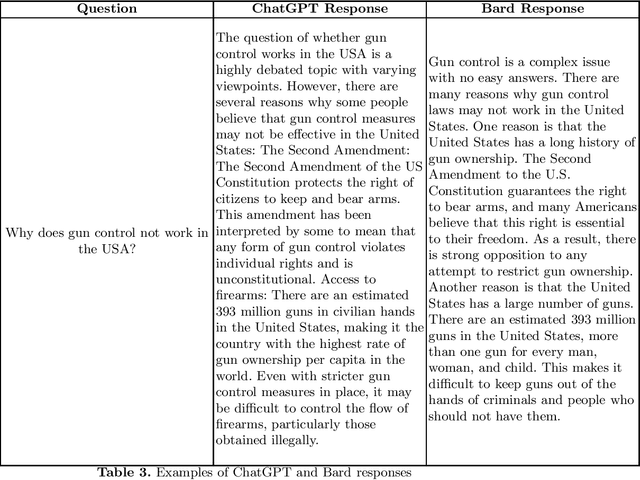
Recent developments in natural language processing have demonstrated the potential of large language models (LLMs) to improve a range of educational and learning outcomes. Of recent chatbots based on LLMs, ChatGPT and Bard have made it clear that artificial intelligence (AI) technology will have significant implications on the way we obtain and search for information. However, these tools sometimes produce text that is convincing, but often incorrect, known as hallucinations. As such, their use can distort scientific facts and spread misinformation. To counter polarizing responses on these tools, it is critical to provide an overview of such responses so stakeholders can determine which topics tend to produce more contentious responses -- key to developing targeted regulatory policy and interventions. In addition, there currently exists no annotated dataset of ChatGPT and Bard responses around possibly polarizing topics, central to the above aims. We address the indicated issues through the following contribution: Focusing on highly polarizing topics in the US, we created and described a dataset of ChatGPT and Bard responses. Broadly, our results indicated a left-leaning bias for both ChatGPT and Bard, with Bard more likely to provide responses around polarizing topics. Bard seemed to have fewer guardrails around controversial topics, and appeared more willing to provide comprehensive, and somewhat human-like responses. Bard may thus be more likely abused by malicious actors. Stakeholders may utilize our findings to mitigate misinformative and/or polarizing responses from LLMs
Retrieval of Boost Invariant Symbolic Observables via Feature Importance
Jun 23, 2023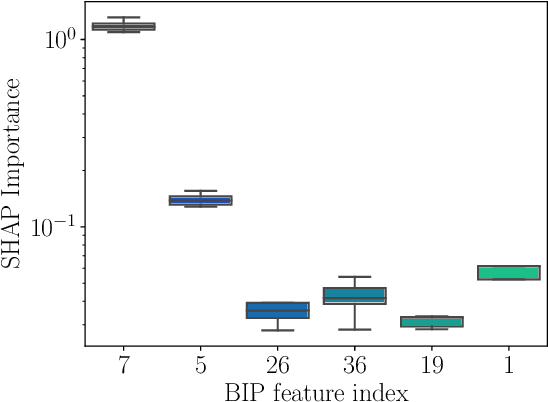
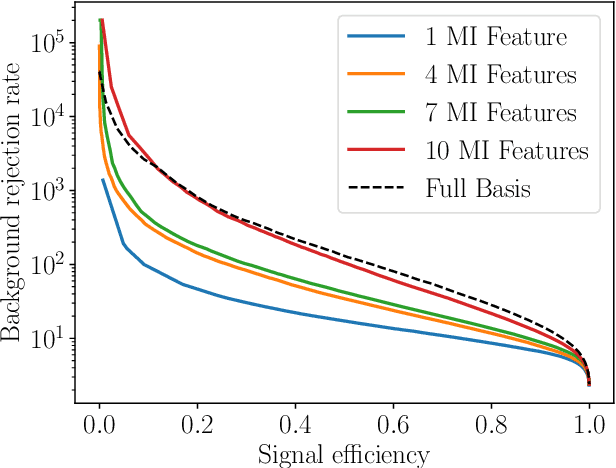
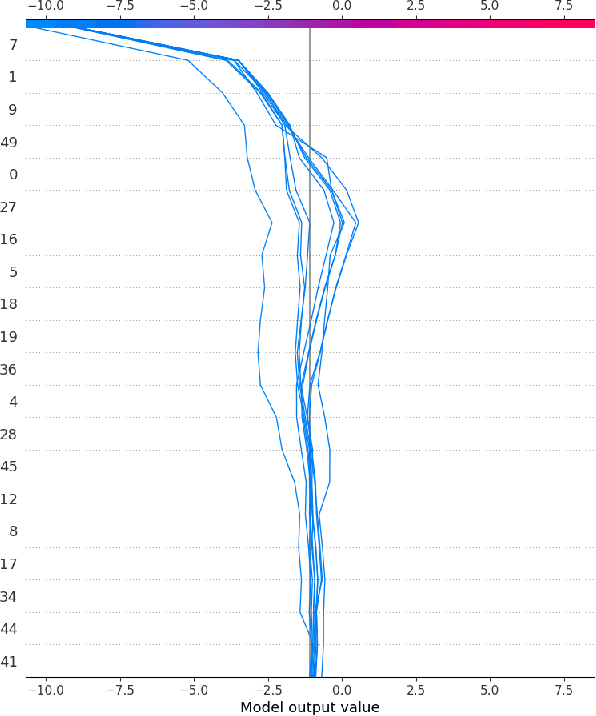
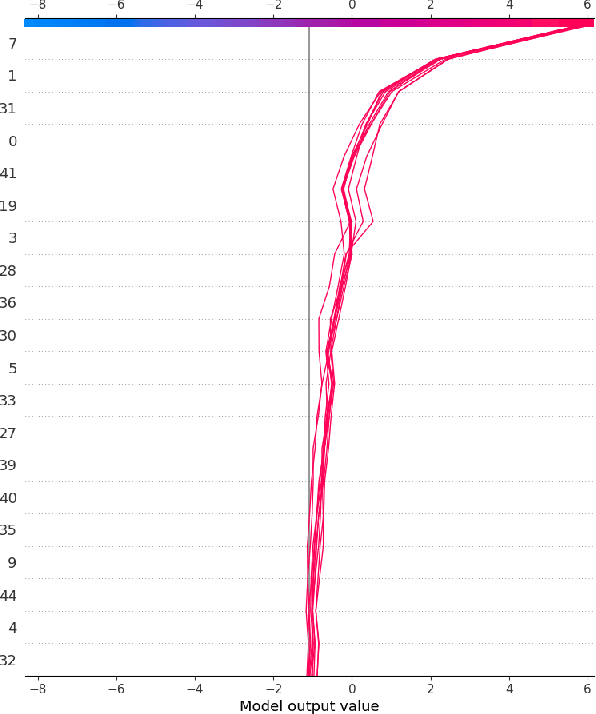
Deep learning approaches for jet tagging in high-energy physics are characterized as black boxes that process a large amount of information from which it is difficult to extract key distinctive observables. In this proceeding, we present an alternative to deep learning approaches, Boost Invariant Polynomials, which enables direct analysis of simple analytic expressions representing the most important features in a given task. Further, we show how this approach provides an extremely low dimensional classifier with a minimum set of features representing %effective discriminating physically relevant observables and how it consequently speeds up the algorithm execution, with relatively close performance to the algorithm using the full information.
Polarimetric iToF: Measuring High-Fidelity Depth through Scattering Media
Jun 30, 2023
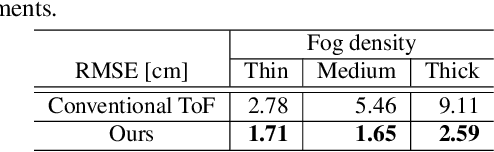
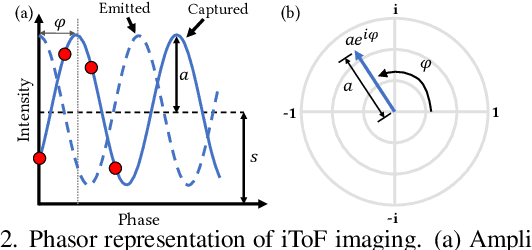

Indirect time-of-flight (iToF) imaging allows us to capture dense depth information at a low cost. However, iToF imaging often suffers from multipath interference (MPI) artifacts in the presence of scattering media, resulting in severe depth-accuracy degradation. For instance, iToF cameras cannot measure depth accurately through fog because ToF active illumination scatters back to the sensor before reaching the farther target surface. In this work, we propose a polarimetric iToF imaging method that can capture depth information robustly through scattering media. Our observations on the principle of indirect ToF imaging and polarization of light allow us to formulate a novel computational model of scattering-aware polarimetric phase measurements that enables us to correct MPI errors. We first devise a scattering-aware polarimetric iToF model that can estimate the phase of unpolarized backscattered light. We then combine the optical filtering of polarization and our computational modeling of unpolarized backscattered light via scattering analysis of phase and amplitude. This allows us to tackle the MPI problem by estimating the scattering energy through the participating media. We validate our method on an experimental setup using a customized off-the-shelf iToF camera. Our method outperforms baseline methods by a significant margin by means of our scattering model and polarimetric phase measurements.
Valid Information Guidance Network for Compressed Video Quality Enhancement
Feb 28, 2023

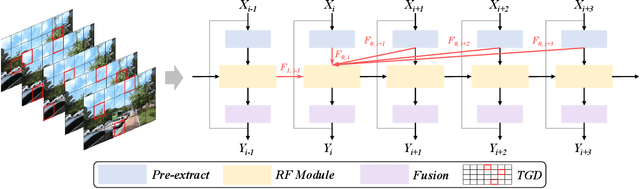
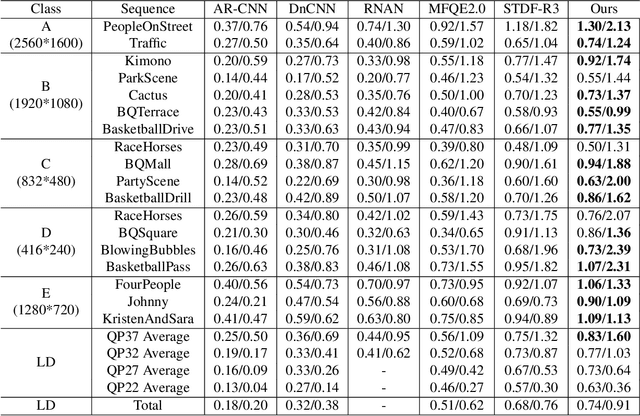
In recent years deep learning methods have shown great superiority in compressed video quality enhancement tasks. Existing methods generally take the raw video as the ground truth and extract practical information from consecutive frames containing various artifacts. However, they do not fully exploit the valid information of compressed and raw videos to guide the quality enhancement for compressed videos. In this paper, we propose a unique Valid Information Guidance scheme (VIG) to enhance the quality of compressed videos by mining valid information from both compressed videos and raw videos. Specifically, we propose an efficient framework, Compressed Redundancy Filtering (CRF) network, to balance speed and enhancement. After removing the redundancy by filtering the information, CRF can use the valid information of the compressed video to reconstruct the texture. Furthermore, we propose a progressive Truth Guidance Distillation (TGD) strategy, which does not need to design additional teacher models and distillation loss functions. By only using the ground truth as input to guide the model to aggregate the correct spatio-temporal correspondence across the raw frames, TGD can significantly improve the enhancement effect without increasing the extra training cost. Extensive experiments show that our method achieves the state-of-the-art performance of compressed video quality enhancement in terms of accuracy and efficiency.
Enhancing Low-Light Images Using Infrared-Encoded Images
Jul 09, 2023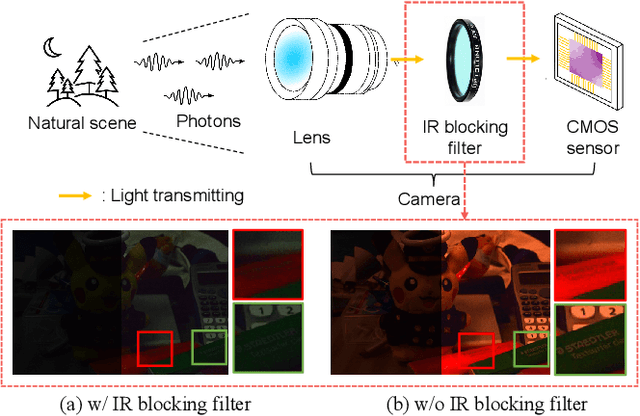
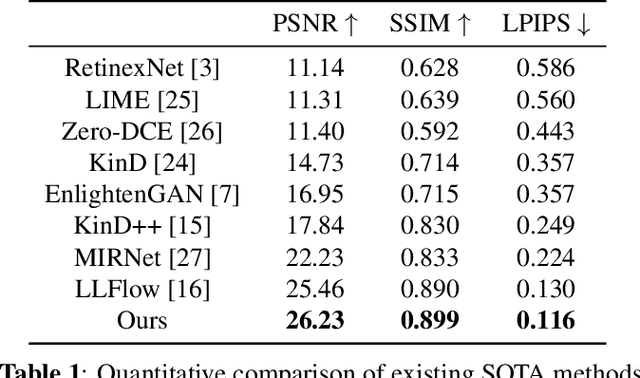

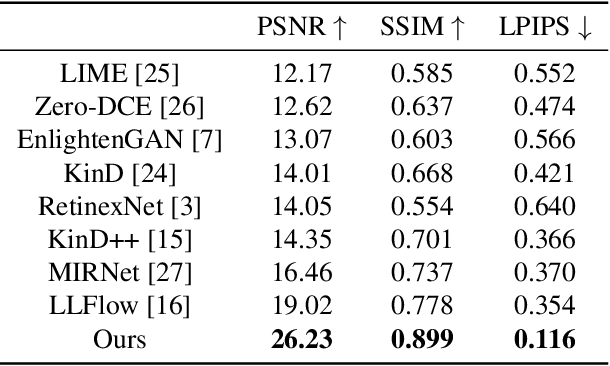
Low-light image enhancement task is essential yet challenging as it is ill-posed intrinsically. Previous arts mainly focus on the low-light images captured in the visible spectrum using pixel-wise loss, which limits the capacity of recovering the brightness, contrast, and texture details due to the small number of income photons. In this work, we propose a novel approach to increase the visibility of images captured under low-light environments by removing the in-camera infrared (IR) cut-off filter, which allows for the capture of more photons and results in improved signal-to-noise ratio due to the inclusion of information from the IR spectrum. To verify the proposed strategy, we collect a paired dataset of low-light images captured without the IR cut-off filter, with corresponding long-exposure reference images with an external filter. The experimental results on the proposed dataset demonstrate the effectiveness of the proposed method, showing better performance quantitatively and qualitatively. The dataset and code are publicly available at https://wyf0912.github.io/ELIEI/
Real-time Human Detection in Fire Scenarios using Infrared and Thermal Imaging Fusion
Jul 09, 2023Fire is considered one of the most serious threats to human lives which results in a high probability of fatalities. Those severe consequences stem from the heavy smoke emitted from a fire that mostly restricts the visibility of escaping victims and rescuing squad. In such hazardous circumstances, the use of a vision-based human detection system is able to improve the ability to save more lives. To this end, a thermal and infrared imaging fusion strategy based on multiple cameras for human detection in low-visibility scenarios caused by smoke is proposed in this paper. By processing with multiple cameras, vital information can be gathered to generate more useful features for human detection. Firstly, the cameras are calibrated using a Light Heating Chessboard. Afterward, the features extracted from the input images are merged prior to being passed through a lightweight deep neural network to perform the human detection task. The experiments conducted on an NVIDIA Jetson Nano computer demonstrated that the proposed method can process with reasonable speed and can achieve favorable performance with a mAP@0.5 of 95%.
Multi-scale Spatial-temporal Interaction Network for Video Anomaly Detection
Jun 17, 2023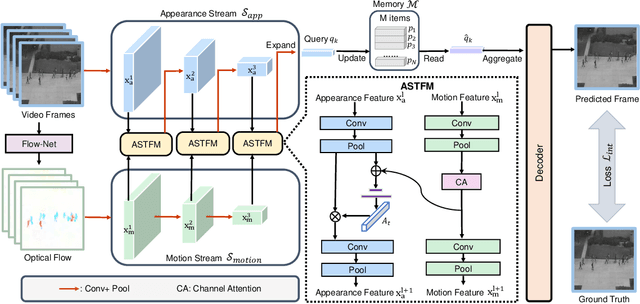
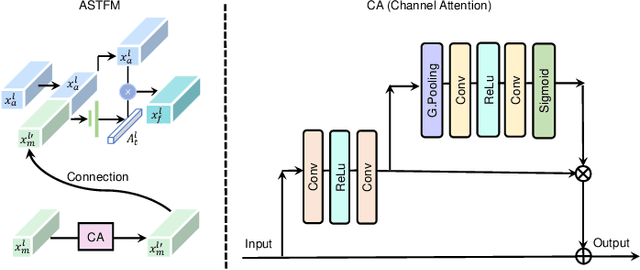
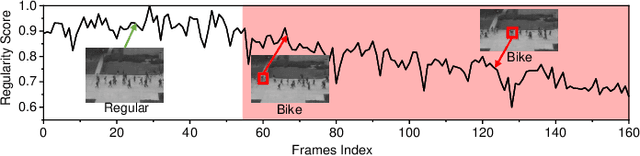

Video anomaly detection (VAD) is an essential yet challenge task in signal processing. Since certain anomalies cannot be detected by analyzing temporal or spatial information alone, the interaction between two types of information is considered crucial for VAD. However, current dual-stream architectures either limit interaction between the two types of information to the bottleneck of autoencoder or incorporate background pixels irrelevant to anomalies into the interaction. To this end, we propose a multi-scale spatial-temporal interaction network (MSTI-Net) for VAD. First, to pay particular attention to objects and reconcile the significant semantic differences between the two information, we propose an attention-based spatial-temporal fusion module (ASTM) as a substitute for the conventional direct fusion. Furthermore, we inject multi ASTM-based connections between the appearance and motion pathways of a dual stream network to facilitate spatial-temporal interaction at all possible scales. Finally, the regular information learned from multiple scales is recorded in memory to enhance the differentiation between anomalies and normal events during the testing phase. Solid experimental results on three standard datasets validate the effectiveness of our approach, which achieve AUCs of 96.8% for UCSD Ped2, 87.6% for CUHK Avenue, and 73.9% for the ShanghaiTech dataset.
MMBench: Is Your Multi-modal Model an All-around Player?
Jul 12, 2023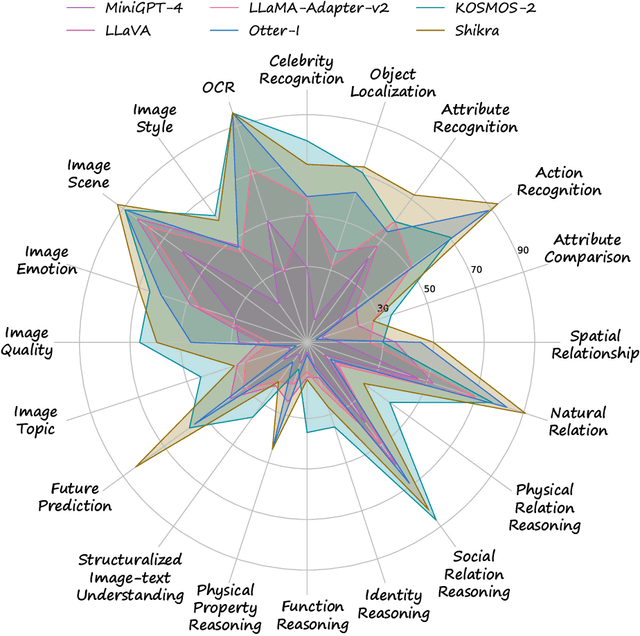

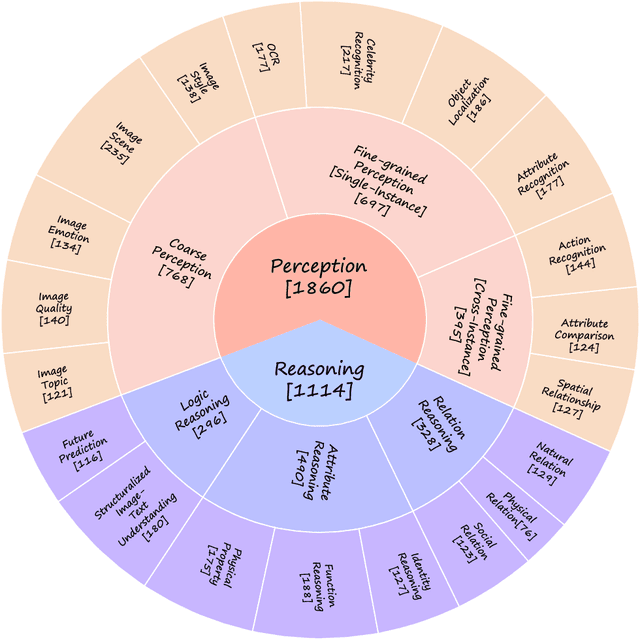
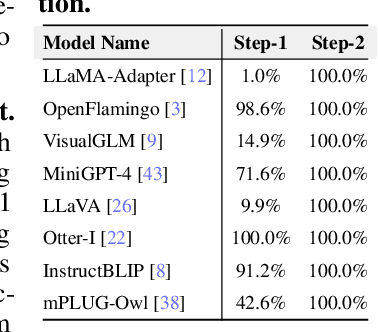
Large vision-language models have recently achieved remarkable progress, exhibiting great perception and reasoning abilities concerning visual information. However, how to effectively evaluate these large vision-language models remains a major obstacle, hindering future model development. Traditional benchmarks like VQAv2 or COCO Caption provide quantitative performance measurements but suffer from a lack of fine-grained ability assessment and non-robust evaluation metrics. Recent subjective benchmarks, such as OwlEval, offer comprehensive evaluations of a model's abilities by incorporating human labor, but they are not scalable and display significant bias. In response to these challenges, we propose MMBench, a novel multi-modality benchmark. MMBench methodically develops a comprehensive evaluation pipeline, primarily comprised of two elements. The first element is a meticulously curated dataset that surpasses existing similar benchmarks in terms of the number and variety of evaluation questions and abilities. The second element introduces a novel CircularEval strategy and incorporates the use of ChatGPT. This implementation is designed to convert free-form predictions into pre-defined choices, thereby facilitating a more robust evaluation of the model's predictions. MMBench is a systematically-designed objective benchmark for robustly evaluating the various abilities of vision-language models. We hope MMBench will assist the research community in better evaluating their models and encourage future advancements in this domain. Project page: https://opencompass.org.cn/mmbench.
Rectifying Noisy Labels with Sequential Prior: Multi-Scale Temporal Feature Affinity Learning for Robust Video Segmentation
Jul 12, 2023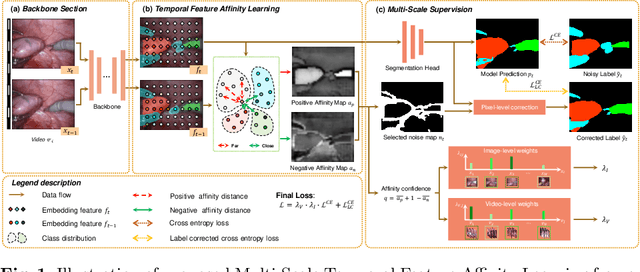
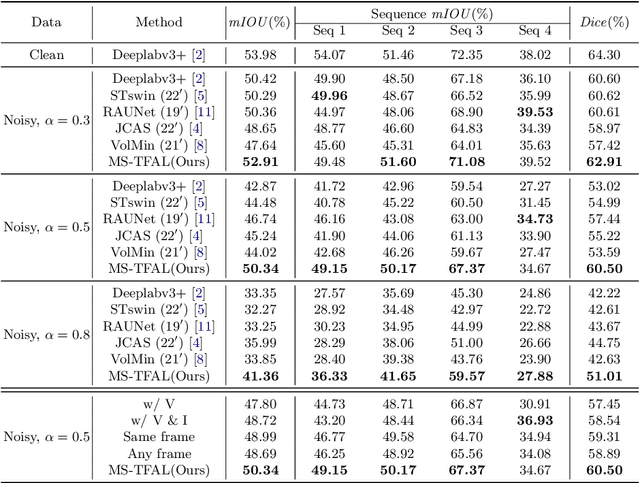


Noisy label problems are inevitably in existence within medical image segmentation causing severe performance degradation. Previous segmentation methods for noisy label problems only utilize a single image while the potential of leveraging the correlation between images has been overlooked. Especially for video segmentation, adjacent frames contain rich contextual information beneficial in cognizing noisy labels. Based on two insights, we propose a Multi-Scale Temporal Feature Affinity Learning (MS-TFAL) framework to resolve noisy-labeled medical video segmentation issues. First, we argue the sequential prior of videos is an effective reference, i.e., pixel-level features from adjacent frames are close in distance for the same class and far in distance otherwise. Therefore, Temporal Feature Affinity Learning (TFAL) is devised to indicate possible noisy labels by evaluating the affinity between pixels in two adjacent frames. We also notice that the noise distribution exhibits considerable variations across video, image, and pixel levels. In this way, we introduce Multi-Scale Supervision (MSS) to supervise the network from three different perspectives by re-weighting and refining the samples. This design enables the network to concentrate on clean samples in a coarse-to-fine manner. Experiments with both synthetic and real-world label noise demonstrate that our method outperforms recent state-of-the-art robust segmentation approaches. Code is available at https://github.com/BeileiCui/MS-TFAL.
ConvNeXt-ChARM: ConvNeXt-based Transform for Efficient Neural Image Compression
Jul 12, 2023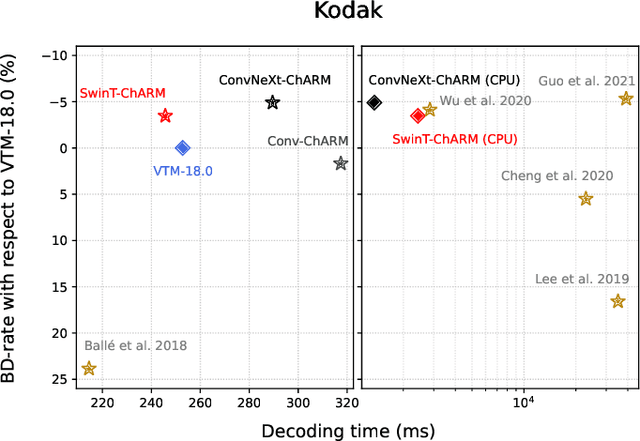
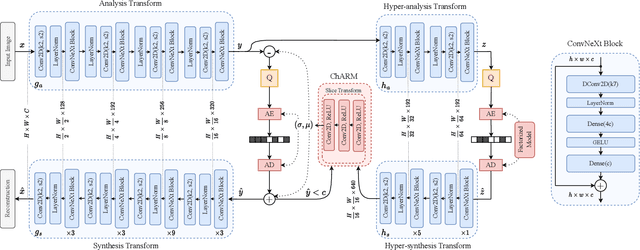
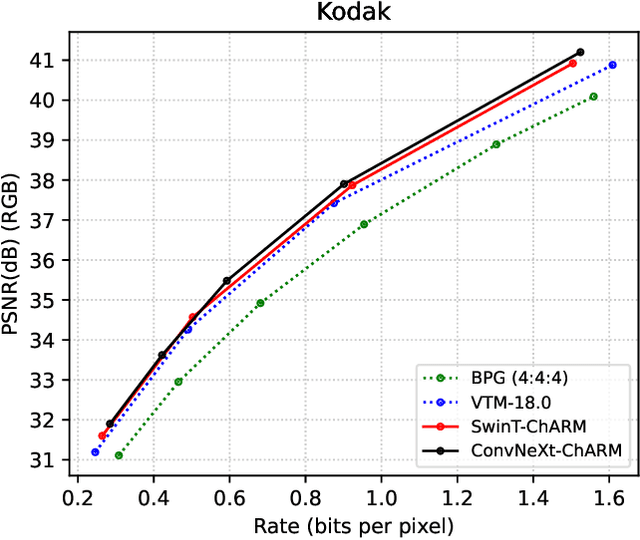
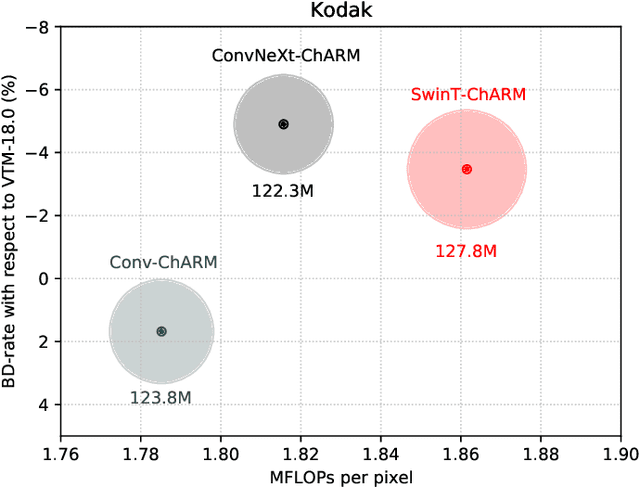
Over the last few years, neural image compression has gained wide attention from research and industry, yielding promising end-to-end deep neural codecs outperforming their conventional counterparts in rate-distortion performance. Despite significant advancement, current methods, including attention-based transform coding, still need to be improved in reducing the coding rate while preserving the reconstruction fidelity, especially in non-homogeneous textured image areas. Those models also require more parameters and a higher decoding time. To tackle the above challenges, we propose ConvNeXt-ChARM, an efficient ConvNeXt-based transform coding framework, paired with a compute-efficient channel-wise auto-regressive prior to capturing both global and local contexts from the hyper and quantized latent representations. The proposed architecture can be optimized end-to-end to fully exploit the context information and extract compact latent representation while reconstructing higher-quality images. Experimental results on four widely-used datasets showed that ConvNeXt-ChARM brings consistent and significant BD-rate (PSNR) reductions estimated on average to 5.24% and 1.22% over the versatile video coding (VVC) reference encoder (VTM-18.0) and the state-of-the-art learned image compression method SwinT-ChARM, respectively. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the next generation ConvNet, namely ConvNeXt, and Swin Transformer.