 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Network Resource Allocation Recommendation Method with An Improved Similarity Measure
Jul 07, 2023
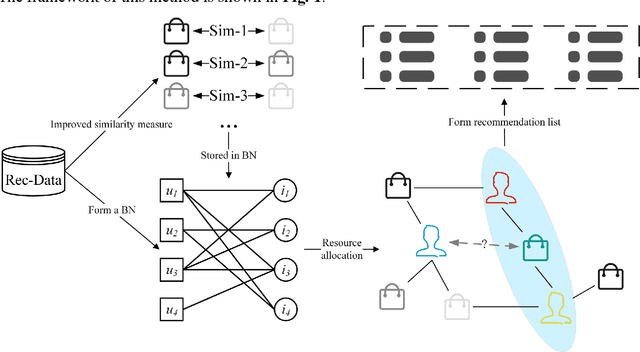

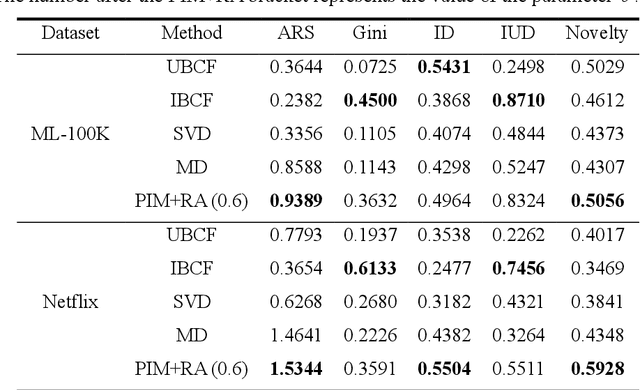
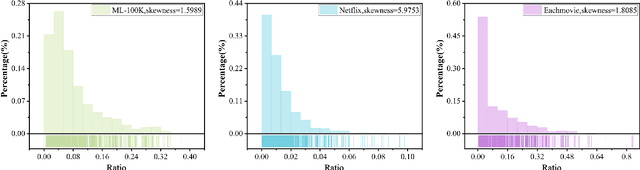
Recommender systems have been acknowledged as efficacious tools for managing information overload. Nevertheless, conventional algorithms adopted in such systems primarily emphasize precise recommendations and, consequently, overlook other vital aspects like the coverage, diversity, and novelty of items. This approach results in less exposure for long-tail items. In this paper, to personalize the recommendations and allocate recommendation resources more purposively, a method named PIM+RA is proposed. This method utilizes a bipartite network that incorporates self-connecting edges and weights. Furthermore, an improved Pearson correlation coefficient is employed for better redistribution. The evaluation of PIM+RA demonstrates a significant enhancement not only in accuracy but also in coverage, diversity, and novelty of the recommendation. It leads to a better balance in recommendation frequency by providing effective exposure to long-tail items, while allowing customized parameters to adjust the recommendation list bias.
ContentCTR: Frame-level Live Streaming Click-Through Rate Prediction with Multimodal Transformer
Jun 26, 2023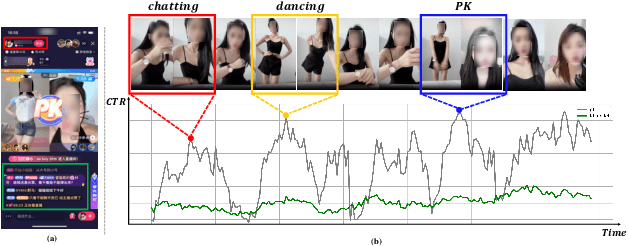
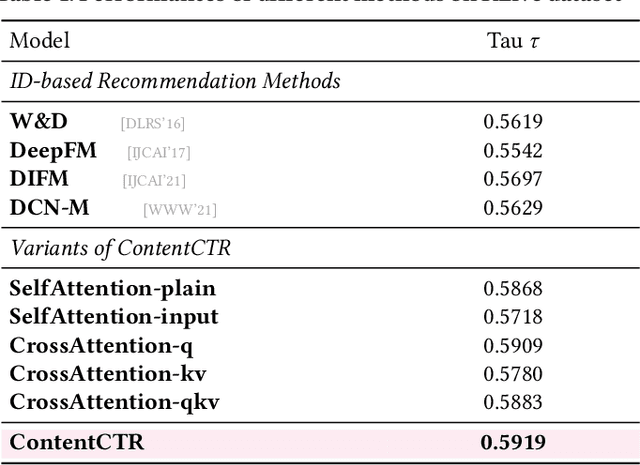
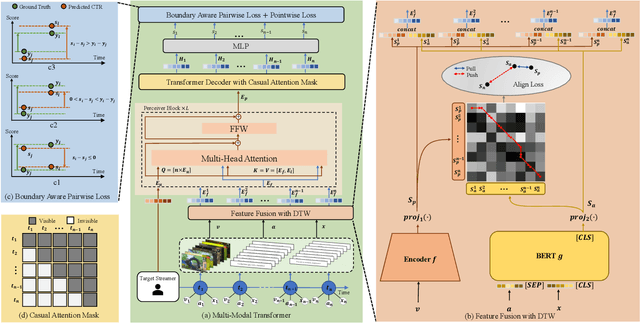

In recent years, live streaming platforms have gained immense popularity as they allow users to broadcast their videos and interact in real-time with hosts and peers. Due to the dynamic changes of live content, accurate recommendation models are crucial for enhancing user experience. However, most previous works treat the live as a whole item and explore the Click-through-Rate (CTR) prediction framework on item-level, neglecting that the dynamic changes that occur even within the same live room. In this paper, we proposed a ContentCTR model that leverages multimodal transformer for frame-level CTR prediction. First, we present an end-to-end framework that can make full use of multimodal information, including visual frames, audio, and comments, to identify the most attractive live frames. Second, to prevent the model from collapsing into a mediocre solution, a novel pairwise loss function with first-order difference constraints is proposed to utilize the contrastive information existing in the highlight and non-highlight frames. Additionally, we design a temporal text-video alignment module based on Dynamic Time Warping to eliminate noise caused by the ambiguity and non-sequential alignment of visual and textual information. We conduct extensive experiments on both real-world scenarios and public datasets, and our ContentCTR model outperforms traditional recommendation models in capturing real-time content changes. Moreover, we deploy the proposed method on our company platform, and the results of online A/B testing further validate its practical significance.
ChatGPT and Bard Responses to Polarizing Questions
Jul 13, 2023

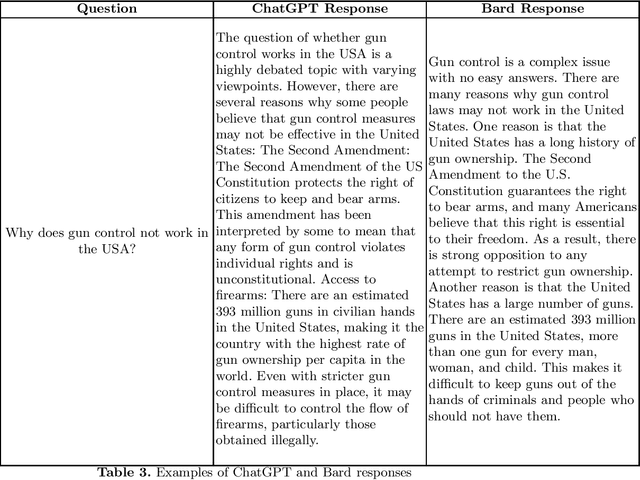
Recent developments in natural language processing have demonstrated the potential of large language models (LLMs) to improve a range of educational and learning outcomes. Of recent chatbots based on LLMs, ChatGPT and Bard have made it clear that artificial intelligence (AI) technology will have significant implications on the way we obtain and search for information. However, these tools sometimes produce text that is convincing, but often incorrect, known as hallucinations. As such, their use can distort scientific facts and spread misinformation. To counter polarizing responses on these tools, it is critical to provide an overview of such responses so stakeholders can determine which topics tend to produce more contentious responses -- key to developing targeted regulatory policy and interventions. In addition, there currently exists no annotated dataset of ChatGPT and Bard responses around possibly polarizing topics, central to the above aims. We address the indicated issues through the following contribution: Focusing on highly polarizing topics in the US, we created and described a dataset of ChatGPT and Bard responses. Broadly, our results indicated a left-leaning bias for both ChatGPT and Bard, with Bard more likely to provide responses around polarizing topics. Bard seemed to have fewer guardrails around controversial topics, and appeared more willing to provide comprehensive, and somewhat human-like responses. Bard may thus be more likely abused by malicious actors. Stakeholders may utilize our findings to mitigate misinformative and/or polarizing responses from LLMs
Ground-Challenge: A Multi-sensor SLAM Dataset Focusing on Corner Cases for Ground Robots
Jul 08, 2023


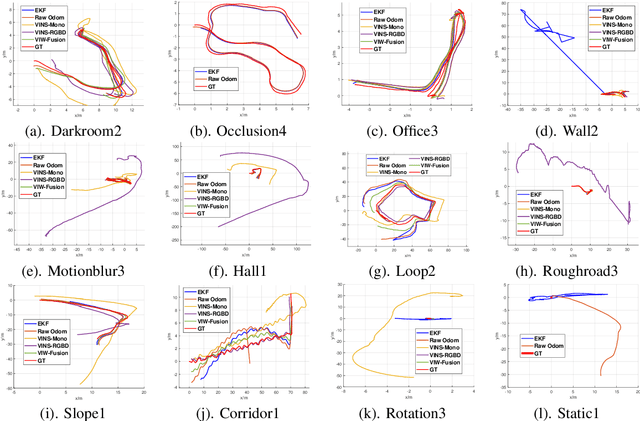
High-quality datasets can speed up breakthroughs and reveal potential developing directions in SLAM research. To support the research on corner cases of visual SLAM systems, this paper presents Ground-Challenge: a challenging dataset comprising 36 trajectories with diverse corner cases such as aggressive motion, severe occlusion, changing illumination, few textures, pure rotation, motion blur, wheel suspension, etc. The dataset was collected by a ground robot with multiple sensors including an RGB-D camera, an inertial measurement unit (IMU), a wheel odometer and a 3D LiDAR. All of these sensors were well-calibrated and synchronized, and their data were recorded simultaneously. To evaluate the performance of cutting-edge SLAM systems, we tested them on our dataset and demonstrated that these systems are prone to drift and fail on specific sequences. We will release the full dataset and relevant materials upon paper publication to benefit the research community. For more information, visit our project website at https://github.com/sjtuyinjie/Ground-Challenge.
On decoder-only architecture for speech-to-text and large language model integration
Jul 08, 2023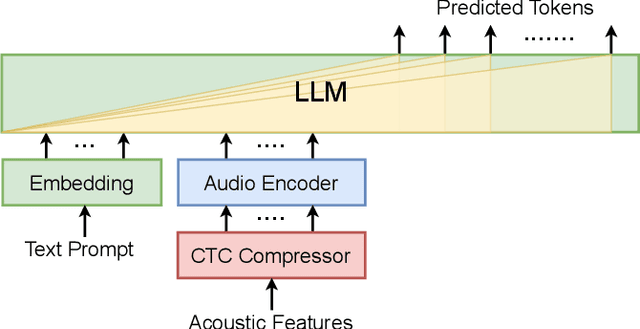
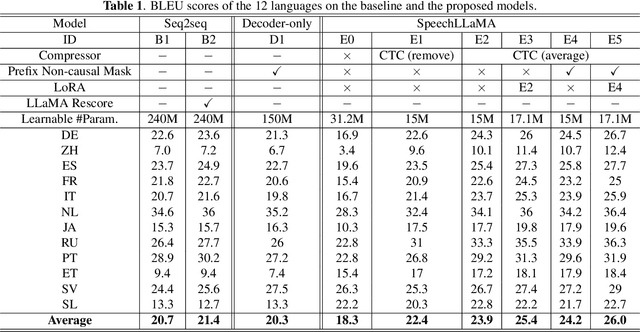
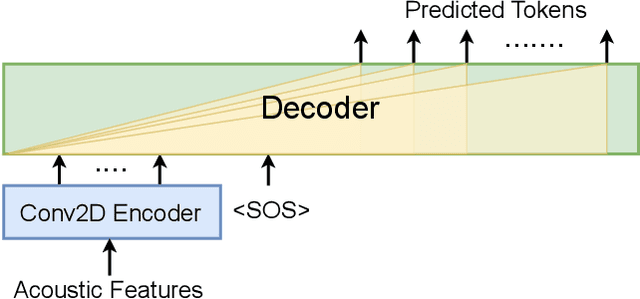
Large language models (LLMs) have achieved remarkable success in the field of natural language processing, enabling better human-computer interaction using natural language. However, the seamless integration of speech signals into LLMs has not been explored well. The "decoder-only" architecture has also not been well studied for speech processing tasks. In this research, we introduce Speech-LLaMA, a novel approach that effectively incorporates acoustic information into text-based large language models. Our method leverages Connectionist Temporal Classification and a simple audio encoder to map the compressed acoustic features to the continuous semantic space of the LLM. In addition, we further probe the decoder-only architecture for speech-to-text tasks by training a smaller scale randomly initialized speech-LLaMA model from speech-text paired data alone. We conduct experiments on multilingual speech-to-text translation tasks and demonstrate a significant improvement over strong baselines, highlighting the potential advantages of decoder-only models for speech-to-text conversion.
Is In-hospital Meta-information Useful for Abstractive Discharge Summary Generation?
Mar 10, 2023
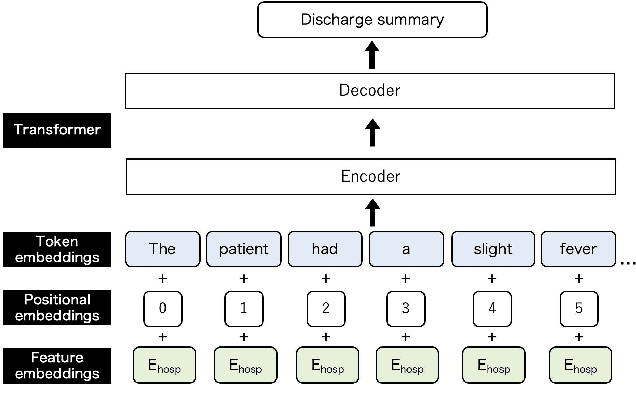
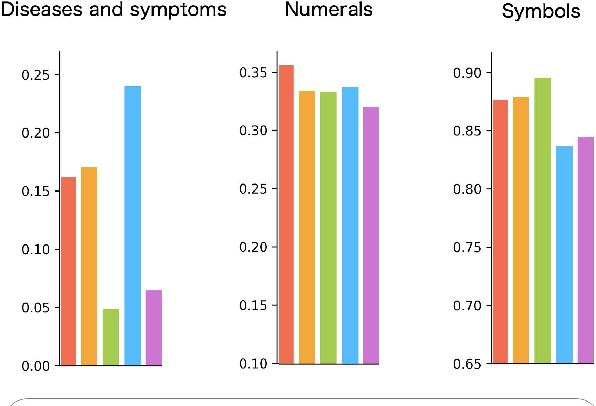
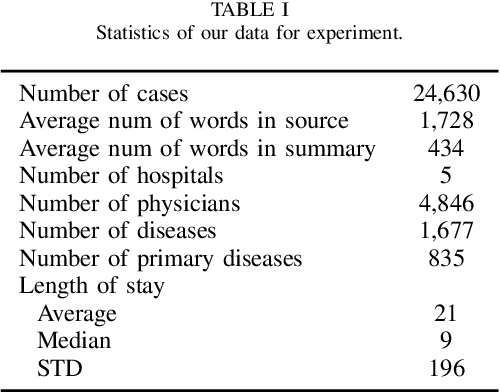
During the patient's hospitalization, the physician must record daily observations of the patient and summarize them into a brief document called "discharge summary" when the patient is discharged. Automated generation of discharge summary can greatly relieve the physicians' burden, and has been addressed recently in the research community. Most previous studies of discharge summary generation using the sequence-to-sequence architecture focus on only inpatient notes for input. However, electric health records (EHR) also have rich structured metadata (e.g., hospital, physician, disease, length of stay, etc.) that might be useful. This paper investigates the effectiveness of medical meta-information for summarization tasks. We obtain four types of meta-information from the EHR systems and encode each meta-information into a sequence-to-sequence model. Using Japanese EHRs, meta-information encoded models increased ROUGE-1 by up to 4.45 points and BERTScore by 3.77 points over the vanilla Longformer. Also, we found that the encoded meta-information improves the precisions of its related terms in the outputs. Our results showed the benefit of the use of medical meta-information.
MMBench: Is Your Multi-modal Model an All-around Player?
Jul 12, 2023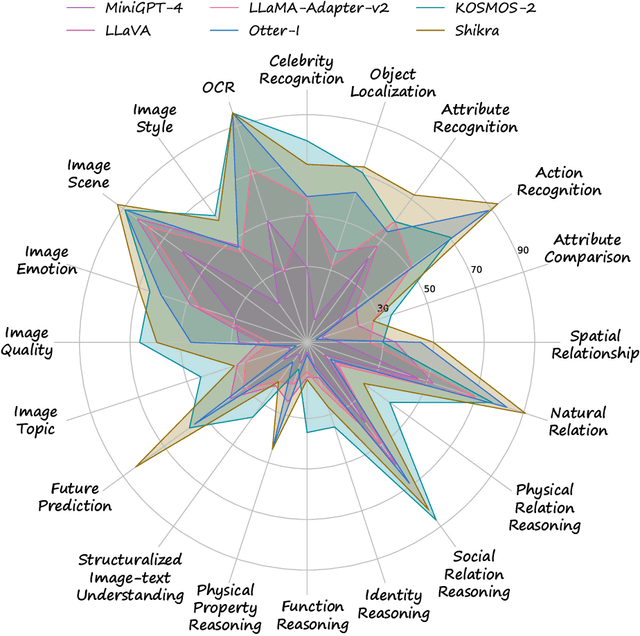

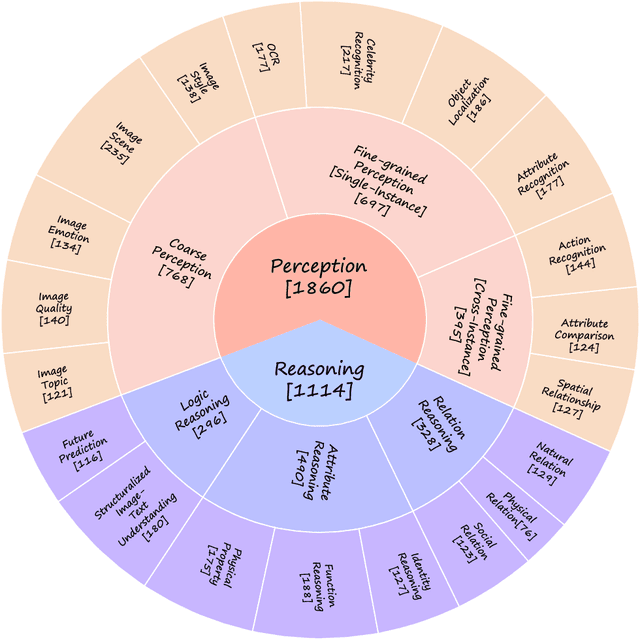
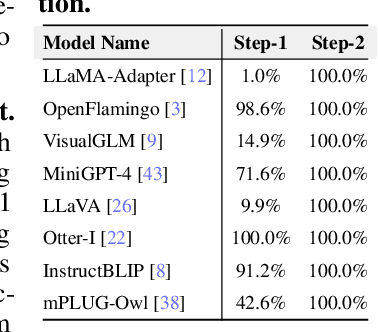
Large vision-language models have recently achieved remarkable progress, exhibiting great perception and reasoning abilities concerning visual information. However, how to effectively evaluate these large vision-language models remains a major obstacle, hindering future model development. Traditional benchmarks like VQAv2 or COCO Caption provide quantitative performance measurements but suffer from a lack of fine-grained ability assessment and non-robust evaluation metrics. Recent subjective benchmarks, such as OwlEval, offer comprehensive evaluations of a model's abilities by incorporating human labor, but they are not scalable and display significant bias. In response to these challenges, we propose MMBench, a novel multi-modality benchmark. MMBench methodically develops a comprehensive evaluation pipeline, primarily comprised of two elements. The first element is a meticulously curated dataset that surpasses existing similar benchmarks in terms of the number and variety of evaluation questions and abilities. The second element introduces a novel CircularEval strategy and incorporates the use of ChatGPT. This implementation is designed to convert free-form predictions into pre-defined choices, thereby facilitating a more robust evaluation of the model's predictions. MMBench is a systematically-designed objective benchmark for robustly evaluating the various abilities of vision-language models. We hope MMBench will assist the research community in better evaluating their models and encourage future advancements in this domain. Project page: https://opencompass.org.cn/mmbench.
Rectifying Noisy Labels with Sequential Prior: Multi-Scale Temporal Feature Affinity Learning for Robust Video Segmentation
Jul 12, 2023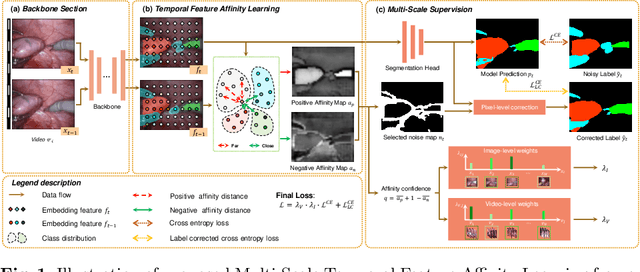
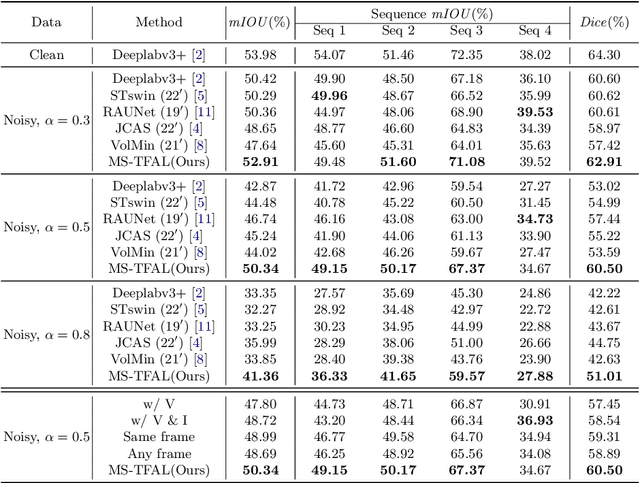


Noisy label problems are inevitably in existence within medical image segmentation causing severe performance degradation. Previous segmentation methods for noisy label problems only utilize a single image while the potential of leveraging the correlation between images has been overlooked. Especially for video segmentation, adjacent frames contain rich contextual information beneficial in cognizing noisy labels. Based on two insights, we propose a Multi-Scale Temporal Feature Affinity Learning (MS-TFAL) framework to resolve noisy-labeled medical video segmentation issues. First, we argue the sequential prior of videos is an effective reference, i.e., pixel-level features from adjacent frames are close in distance for the same class and far in distance otherwise. Therefore, Temporal Feature Affinity Learning (TFAL) is devised to indicate possible noisy labels by evaluating the affinity between pixels in two adjacent frames. We also notice that the noise distribution exhibits considerable variations across video, image, and pixel levels. In this way, we introduce Multi-Scale Supervision (MSS) to supervise the network from three different perspectives by re-weighting and refining the samples. This design enables the network to concentrate on clean samples in a coarse-to-fine manner. Experiments with both synthetic and real-world label noise demonstrate that our method outperforms recent state-of-the-art robust segmentation approaches. Code is available at https://github.com/BeileiCui/MS-TFAL.
ConvNeXt-ChARM: ConvNeXt-based Transform for Efficient Neural Image Compression
Jul 12, 2023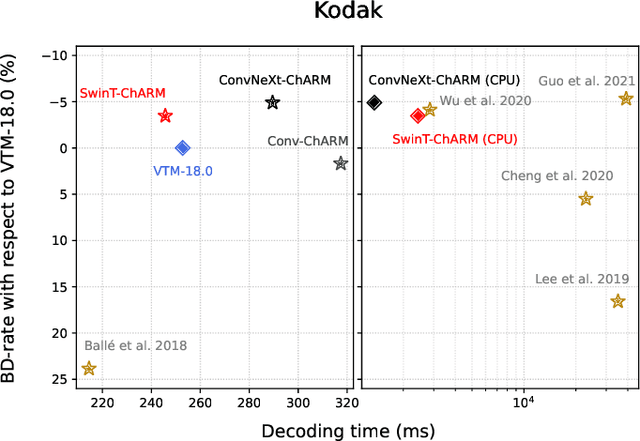
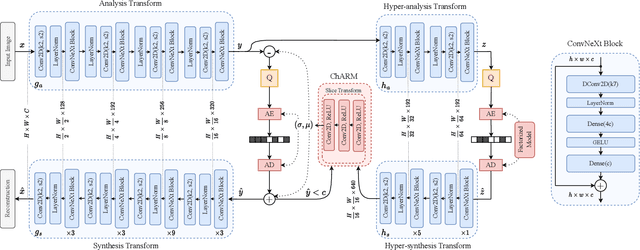
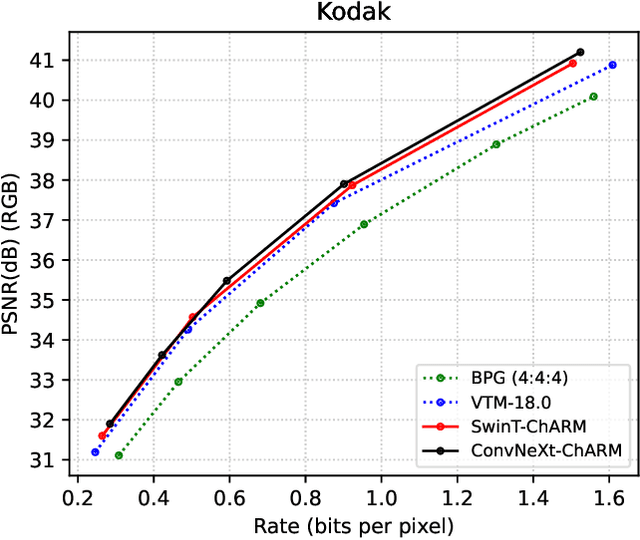
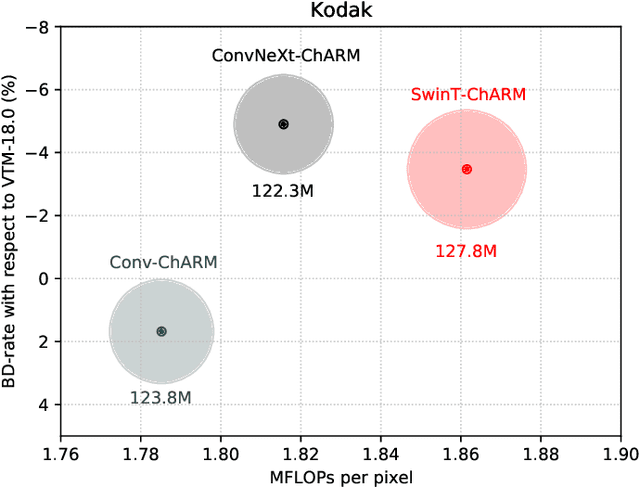
Over the last few years, neural image compression has gained wide attention from research and industry, yielding promising end-to-end deep neural codecs outperforming their conventional counterparts in rate-distortion performance. Despite significant advancement, current methods, including attention-based transform coding, still need to be improved in reducing the coding rate while preserving the reconstruction fidelity, especially in non-homogeneous textured image areas. Those models also require more parameters and a higher decoding time. To tackle the above challenges, we propose ConvNeXt-ChARM, an efficient ConvNeXt-based transform coding framework, paired with a compute-efficient channel-wise auto-regressive prior to capturing both global and local contexts from the hyper and quantized latent representations. The proposed architecture can be optimized end-to-end to fully exploit the context information and extract compact latent representation while reconstructing higher-quality images. Experimental results on four widely-used datasets showed that ConvNeXt-ChARM brings consistent and significant BD-rate (PSNR) reductions estimated on average to 5.24% and 1.22% over the versatile video coding (VVC) reference encoder (VTM-18.0) and the state-of-the-art learned image compression method SwinT-ChARM, respectively. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the next generation ConvNet, namely ConvNeXt, and Swin Transformer.
TopicFM+: Boosting Accuracy and Efficiency of Topic-Assisted Feature Matching
Jul 02, 2023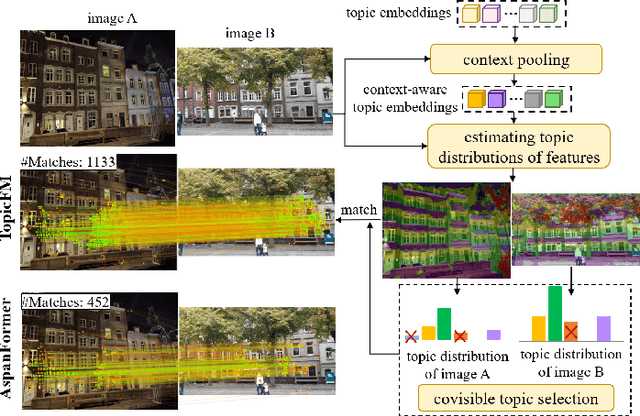
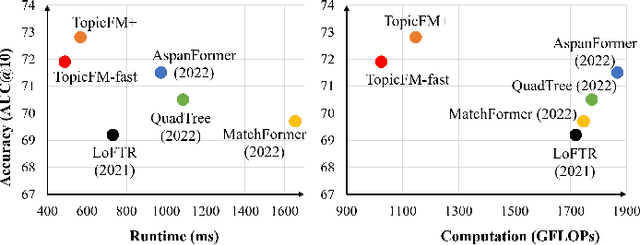
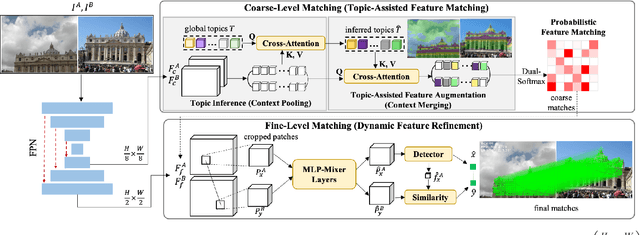
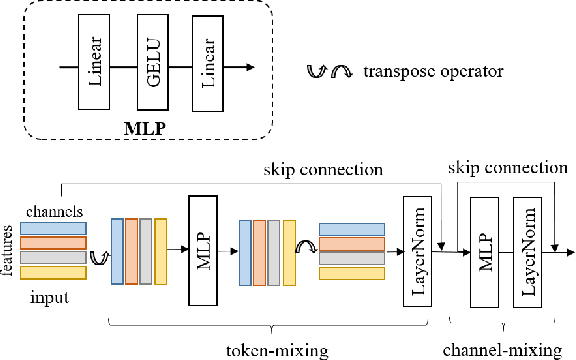
This study tackles the challenge of image matching in difficult scenarios, such as scenes with significant variations or limited texture, with a strong emphasis on computational efficiency. Previous studies have attempted to address this challenge by encoding global scene contexts using Transformers. However, these approaches suffer from high computational costs and may not capture sufficient high-level contextual information, such as structural shapes or semantic instances. Consequently, the encoded features may lack discriminative power in challenging scenes. To overcome these limitations, we propose a novel image-matching method that leverages a topic-modeling strategy to capture high-level contexts in images. Our method represents each image as a multinomial distribution over topics, where each topic represents a latent semantic instance. By incorporating these topics, we can effectively capture comprehensive context information and obtain discriminative and high-quality features. Additionally, our method effectively matches features within corresponding semantic regions by estimating the covisible topics. To enhance the efficiency of feature matching, we have designed a network with a pooling-and-merging attention module. This module reduces computation by employing attention only on fixed-sized topics and small-sized features. Through extensive experiments, we have demonstrated the superiority of our method in challenging scenarios. Specifically, our method significantly reduces computational costs while maintaining higher image-matching accuracy compared to state-of-the-art methods. The code will be updated soon at https://github.com/TruongKhang/TopicFM