 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Urban Radiance Field Representation with Deformable Neural Mesh Primitives
Jul 20, 2023
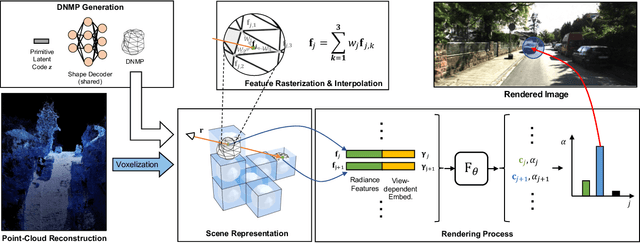
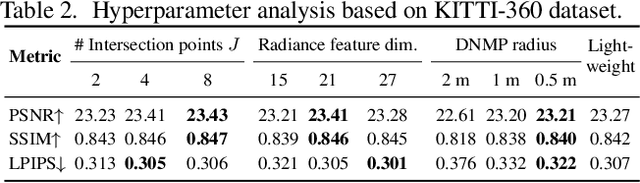
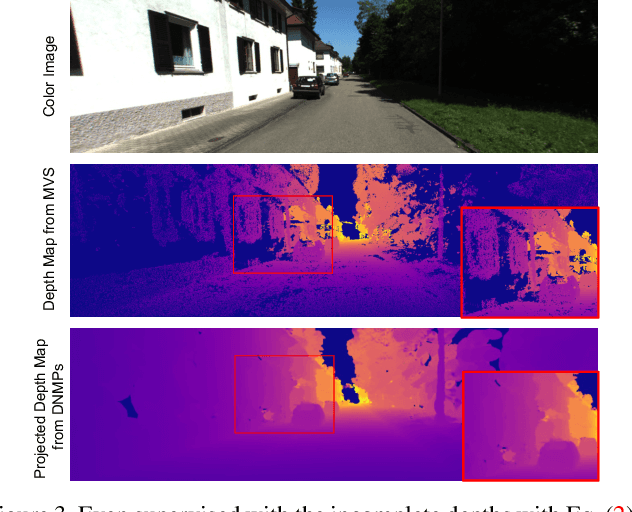

Neural Radiance Fields (NeRFs) have achieved great success in the past few years. However, most current methods still require intensive resources due to ray marching-based rendering. To construct urban-level radiance fields efficiently, we design Deformable Neural Mesh Primitive~(DNMP), and propose to parameterize the entire scene with such primitives. The DNMP is a flexible and compact neural variant of classic mesh representation, which enjoys both the efficiency of rasterization-based rendering and the powerful neural representation capability for photo-realistic image synthesis. Specifically, a DNMP consists of a set of connected deformable mesh vertices with paired vertex features to parameterize the geometry and radiance information of a local area. To constrain the degree of freedom for optimization and lower the storage budgets, we enforce the shape of each primitive to be decoded from a relatively low-dimensional latent space. The rendering colors are decoded from the vertex features (interpolated with rasterization) by a view-dependent MLP. The DNMP provides a new paradigm for urban-level scene representation with appealing properties: $(1)$ High-quality rendering. Our method achieves leading performance for novel view synthesis in urban scenarios. $(2)$ Low computational costs. Our representation enables fast rendering (2.07ms/1k pixels) and low peak memory usage (110MB/1k pixels). We also present a lightweight version that can run 33$\times$ faster than vanilla NeRFs, and comparable to the highly-optimized Instant-NGP (0.61 vs 0.71ms/1k pixels). Project page: \href{https://dnmp.github.io/}{https://dnmp.github.io/}.
Multi-objective point cloud autoencoders for explainable myocardial infarction prediction
Jul 20, 2023Myocardial infarction (MI) is one of the most common causes of death in the world. Image-based biomarkers commonly used in the clinic, such as ejection fraction, fail to capture more complex patterns in the heart's 3D anatomy and thus limit diagnostic accuracy. In this work, we present the multi-objective point cloud autoencoder as a novel geometric deep learning approach for explainable infarction prediction, based on multi-class 3D point cloud representations of cardiac anatomy and function. Its architecture consists of multiple task-specific branches connected by a low-dimensional latent space to allow for effective multi-objective learning of both reconstruction and MI prediction, while capturing pathology-specific 3D shape information in an interpretable latent space. Furthermore, its hierarchical branch design with point cloud-based deep learning operations enables efficient multi-scale feature learning directly on high-resolution anatomy point clouds. In our experiments on a large UK Biobank dataset, the multi-objective point cloud autoencoder is able to accurately reconstruct multi-temporal 3D shapes with Chamfer distances between predicted and input anatomies below the underlying images' pixel resolution. Our method outperforms multiple machine learning and deep learning benchmarks for the task of incident MI prediction by 19% in terms of Area Under the Receiver Operating Characteristic curve. In addition, its task-specific compact latent space exhibits easily separable control and MI clusters with clinically plausible associations between subject encodings and corresponding 3D shapes, thus demonstrating the explainability of the prediction.
Fisher-Rao distance and pullback SPD cone distances between multivariate normal distributions
Jul 20, 2023Data sets of multivariate normal distributions abound in many scientific areas like diffusion tensor imaging, structure tensor computer vision, radar signal processing, machine learning, just to name a few. In order to process those normal data sets for downstream tasks like filtering, classification or clustering, one needs to define proper notions of dissimilarities between normals and paths joining them. The Fisher-Rao distance defined as the Riemannian geodesic distance induced by the Fisher information metric is such a principled metric distance which however is not known in closed-form excepts for a few particular cases. In this work, we first report a fast and robust method to approximate arbitrarily finely the Fisher-Rao distance between multivariate normal distributions. Second, we introduce a class of distances based on diffeomorphic embeddings of the normal manifold into a submanifold of the higher-dimensional symmetric positive-definite cone corresponding to the manifold of centered normal distributions. We show that the projective Hilbert distance on the cone yields a metric on the embedded normal submanifold and we pullback that cone distance with its associated straight line Hilbert cone geodesics to obtain a distance and smooth paths between normal distributions. Compared to the Fisher-Rao distance approximation, the pullback Hilbert cone distance is computationally light since it requires to compute only the extreme minimal and maximal eigenvalues of matrices. Finally, we show how to use those distances in clustering tasks.
* 25 pages
Learning to Communicate using Contrastive Learning
Jul 03, 2023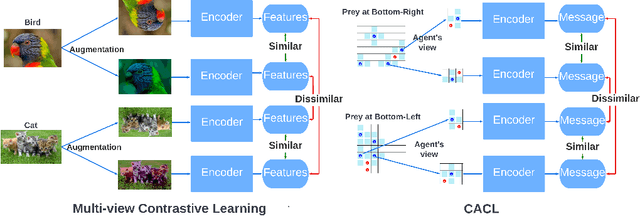

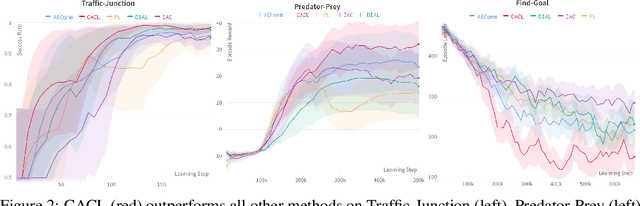

Communication is a powerful tool for coordination in multi-agent RL. But inducing an effective, common language is a difficult challenge, particularly in the decentralized setting. In this work, we introduce an alternative perspective where communicative messages sent between agents are considered as different incomplete views of the environment state. By examining the relationship between messages sent and received, we propose to learn to communicate using contrastive learning to maximize the mutual information between messages of a given trajectory. In communication-essential environments, our method outperforms previous work in both performance and learning speed. Using qualitative metrics and representation probing, we show that our method induces more symmetric communication and captures global state information from the environment. Overall, we show the power of contrastive learning and the importance of leveraging messages as encodings for effective communication.
RegExplainer: Generating Explanations for Graph Neural Networks in Regression Task
Jul 15, 2023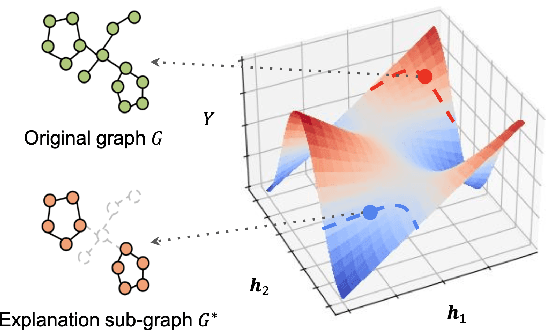
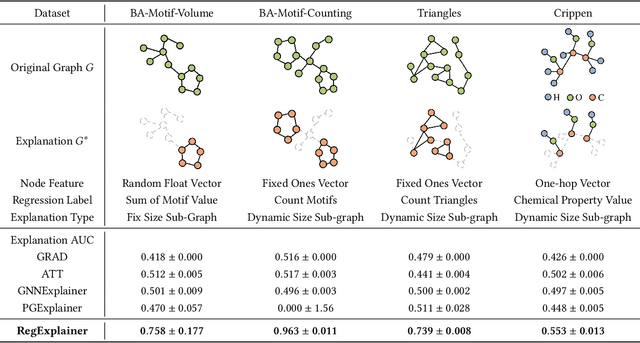
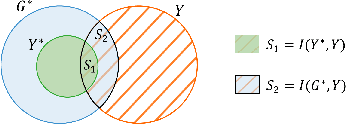
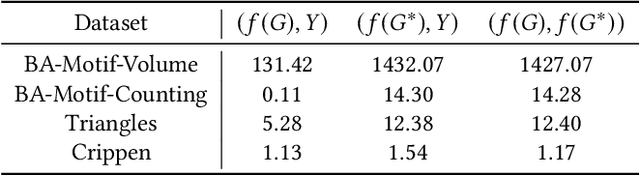
Graph regression is a fundamental task and has received increasing attention in a wide range of graph learning tasks. However, the inference process is often not interpretable. Most existing explanation techniques are limited to understanding GNN behaviors in classification tasks. In this work, we seek an explanation to interpret the graph regression models (XAIG-R). We show that existing methods overlook the distribution shifting and continuously ordered decision boundary, which hinders them away from being applied in the regression tasks. To address these challenges, we propose a novel objective based on the information bottleneck theory and introduce a new mix-up framework, which could support various GNNs in a model-agnostic manner. We further present a contrastive learning strategy to tackle the continuously ordered labels in regression task. To empirically verify the effectiveness of the proposed method, we introduce three benchmark datasets and a real-life dataset for evaluation. Extensive experiments show the effectiveness of the proposed method in interpreting GNN models in regression tasks.
Opinion mining using Double Channel CNN for Recommender System
Jul 15, 2023
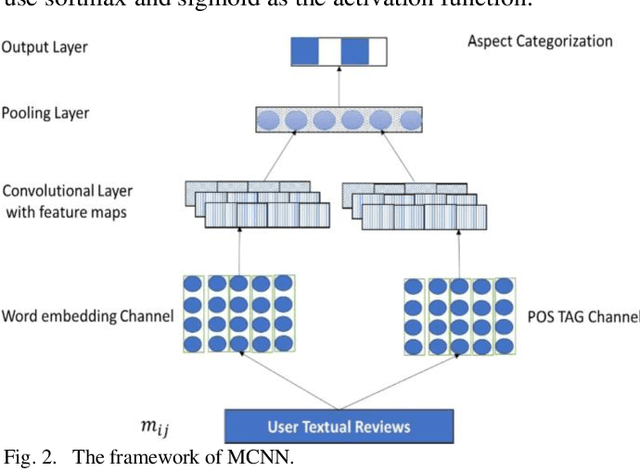
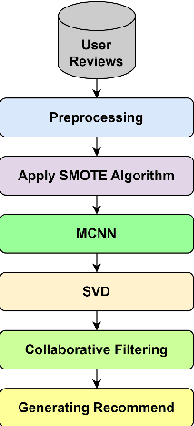
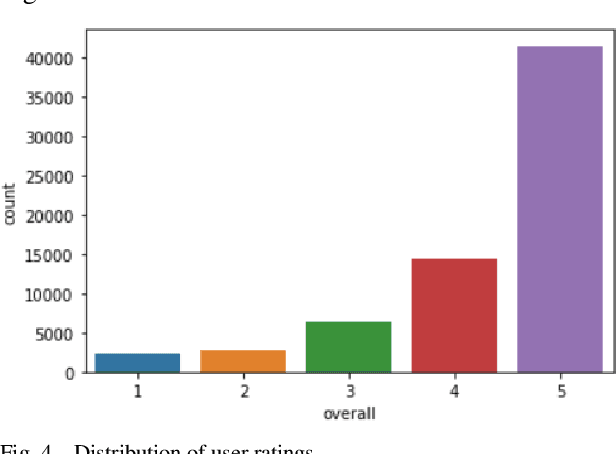
Much unstructured data has been produced with the growth of the Internet and social media. A significant volume of textual data includes users' opinions about products in online stores and social media. By exploring and categorizing them, helpful information can be acquired, including customer satisfaction, user feedback about a particular event, predicting the sale of a specific product, and other similar cases. In this paper, we present an approach for sentiment analysis with a deep learning model and use it to recommend products. A two-channel convolutional neural network model has been used for opinion mining, which has five layers and extracts essential features from the data. We increased the number of comments by applying the SMOTE algorithm to the initial dataset and balanced the data. Then we proceed to cluster the aspects. We also assign a weight to each cluster using tensor decomposition algorithms that improve the recommender system's performance. Our proposed method has reached 91.6% accuracy, significantly improved compared to previous aspect-based approaches.
Automated Knowledge Modeling for Cancer Clinical Practice Guidelines
Jul 15, 2023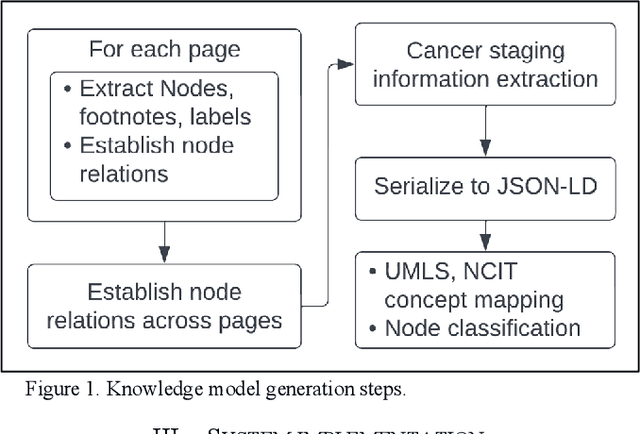
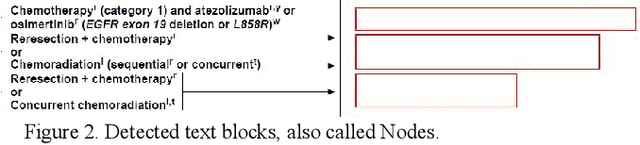
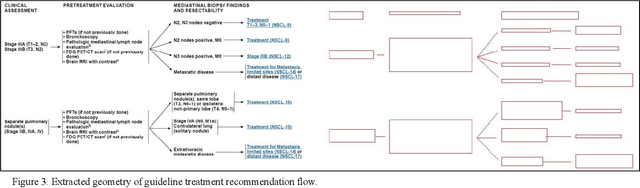

Clinical Practice Guidelines (CPGs) for cancer diseases evolve rapidly due to new evidence generated by active research. Currently, CPGs are primarily published in a document format that is ill-suited for managing this developing knowledge. A knowledge model of the guidelines document suitable for programmatic interaction is required. This work proposes an automated method for extraction of knowledge from National Comprehensive Cancer Network (NCCN) CPGs in Oncology and generating a structured model containing the retrieved knowledge. The proposed method was tested using two versions of NCCN Non-Small Cell Lung Cancer (NSCLC) CPG to demonstrate the effectiveness in faithful extraction and modeling of knowledge. Three enrichment strategies using Cancer staging information, Unified Medical Language System (UMLS) Metathesaurus & National Cancer Institute thesaurus (NCIt) concepts, and Node classification are also presented to enhance the model towards enabling programmatic traversal and querying of cancer care guidelines. The Node classification was performed using a Support Vector Machine (SVM) model, achieving a classification accuracy of 0.81 with 10-fold cross-validation.
Causal Influences over Social Learning Networks
Jul 13, 2023This paper investigates causal influences between agents linked by a social graph and interacting over time. In particular, the work examines the dynamics of social learning models and distributed decision-making protocols, and derives expressions that reveal the causal relations between pairs of agents and explain the flow of influence over the network. The results turn out to be dependent on the graph topology and the level of information that each agent has about the inference problem they are trying to solve. Using these conclusions, the paper proposes an algorithm to rank the overall influence between agents to discover highly influential agents. It also provides a method to learn the necessary model parameters from raw observational data. The results and the proposed algorithm are illustrated by considering both synthetic data and real Twitter data.
Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery
May 01, 2023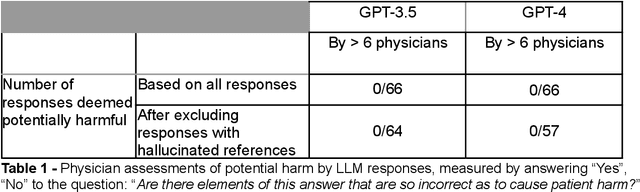
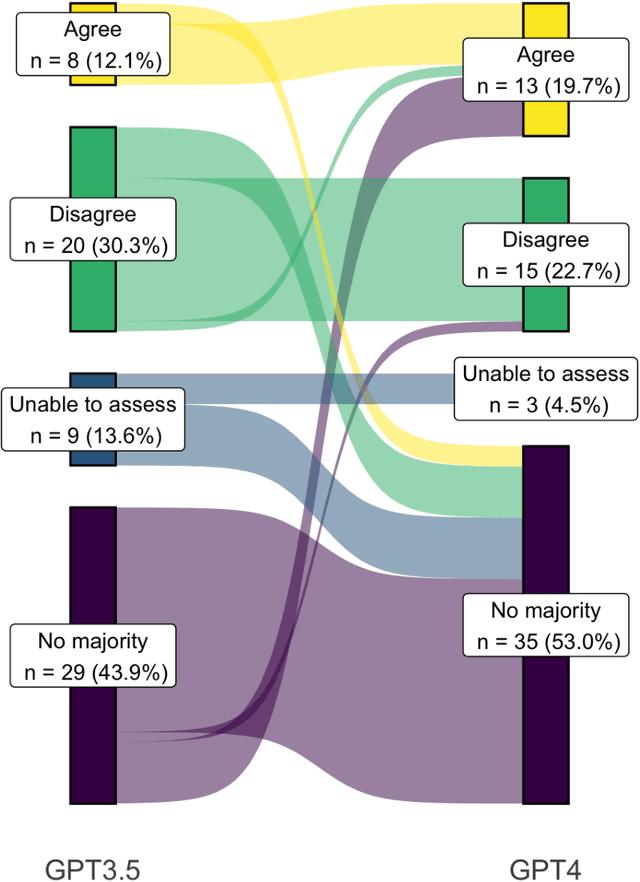
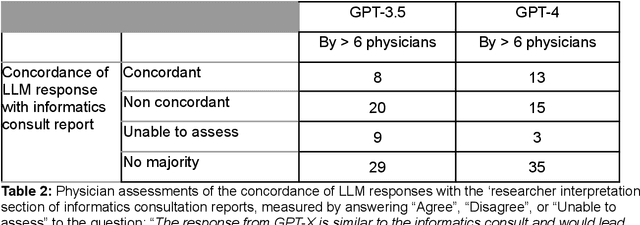
Despite growing interest in using large language models (LLMs) in healthcare, current explorations do not assess the real-world utility and safety of LLMs in clinical settings. Our objective was to determine whether two LLMs can serve information needs submitted by physicians as questions to an informatics consultation service in a safe and concordant manner. Sixty six questions from an informatics consult service were submitted to GPT-3.5 and GPT-4 via simple prompts. 12 physicians assessed the LLM responses' possibility of patient harm and concordance with existing reports from an informatics consultation service. Physician assessments were summarized based on majority vote. For no questions did a majority of physicians deem either LLM response as harmful. For GPT-3.5, responses to 8 questions were concordant with the informatics consult report, 20 discordant, and 9 were unable to be assessed. There were 29 responses with no majority on "Agree", "Disagree", and "Unable to assess". For GPT-4, responses to 13 questions were concordant, 15 discordant, and 3 were unable to be assessed. There were 35 responses with no majority. Responses from both LLMs were largely devoid of overt harm, but less than 20% of the responses agreed with an answer from an informatics consultation service, responses contained hallucinated references, and physicians were divided on what constitutes harm. These results suggest that while general purpose LLMs are able to provide safe and credible responses, they often do not meet the specific information need of a given question. A definitive evaluation of the usefulness of LLMs in healthcare settings will likely require additional research on prompt engineering, calibration, and custom-tailoring of general purpose models.
Semantic-Aware Dual Contrastive Learning for Multi-label Image Classification
Jul 19, 2023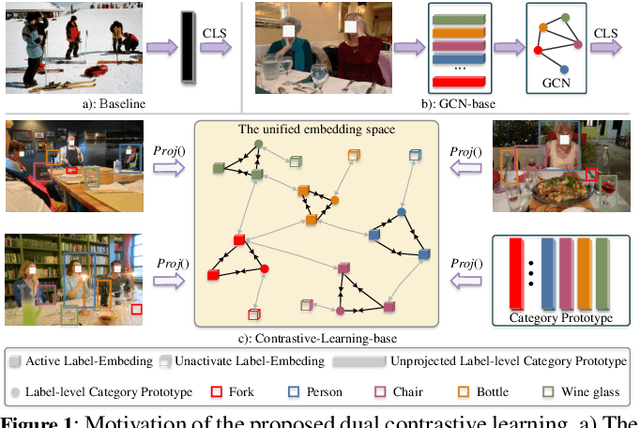
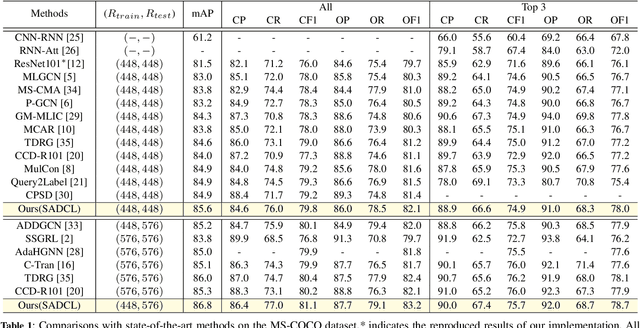
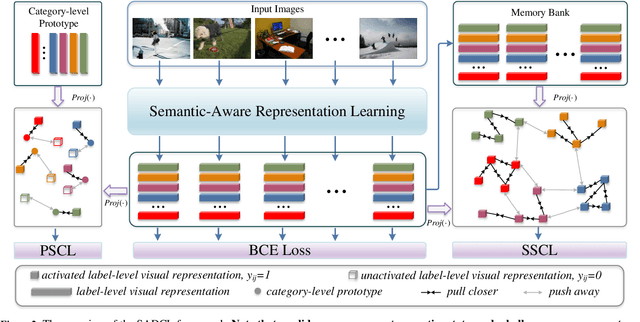
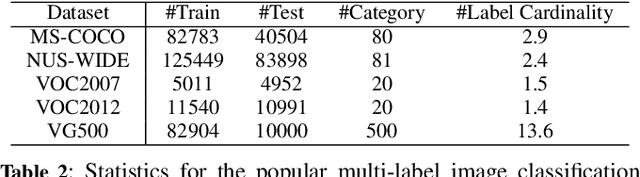
Extracting image semantics effectively and assigning corresponding labels to multiple objects or attributes for natural images is challenging due to the complex scene contents and confusing label dependencies. Recent works have focused on modeling label relationships with graph and understanding object regions using class activation maps (CAM). However, these methods ignore the complex intra- and inter-category relationships among specific semantic features, and CAM is prone to generate noisy information. To this end, we propose a novel semantic-aware dual contrastive learning framework that incorporates sample-to-sample contrastive learning (SSCL) as well as prototype-to-sample contrastive learning (PSCL). Specifically, we leverage semantic-aware representation learning to extract category-related local discriminative features and construct category prototypes. Then based on SSCL, label-level visual representations of the same category are aggregated together, and features belonging to distinct categories are separated. Meanwhile, we construct a novel PSCL module to narrow the distance between positive samples and category prototypes and push negative samples away from the corresponding category prototypes. Finally, the discriminative label-level features related to the image content are accurately captured by the joint training of the above three parts. Experiments on five challenging large-scale public datasets demonstrate that our proposed method is effective and outperforms the state-of-the-art methods. Code and supplementary materials are released on https://github.com/yu-gi-oh-leilei/SADCL.