 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What do self-supervised speech models know about words?
Jun 30, 2023

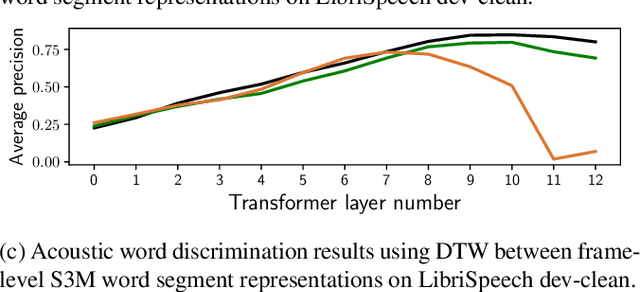

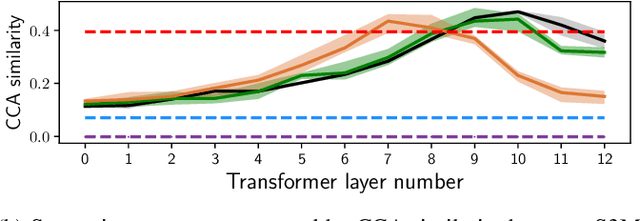
Many self-supervised speech models (S3Ms) have been introduced over the last few years, producing performance and data efficiency improvements for a variety of speech tasks. Evidence is emerging that different S3Ms encode linguistic information in different layers, and also that some S3Ms appear to learn phone-like sub-word units. However, the extent to which these models capture larger linguistic units, such as words, and where word-related information is encoded, remains unclear. In this study, we conduct several analyses of word segment representations extracted from different layers of three S3Ms: wav2vec2, HuBERT, and WavLM. We employ canonical correlation analysis (CCA), a lightweight analysis tool, to measure the similarity between these representations and word-level linguistic properties. We find that the maximal word-level linguistic content tends to be found in intermediate model layers, while some lower-level information like pronunciation is also retained in higher layers of HuBERT and WavLM. Syntactic and semantic word attributes have similar layer-wise behavior. We also find that, for all of the models tested, word identity information is concentrated near the center of each word segment. We then test the layer-wise performance of the same models, when used directly with no additional learned parameters, on several tasks: acoustic word discrimination, word segmentation, and semantic sentence similarity. We find similar layer-wise trends in performance, and furthermore, find that when using the best-performing layer of HuBERT or WavLM, it is possible to achieve performance on word segmentation and sentence similarity that rivals more complex existing approaches.
Close-up View synthesis by Interpolating Optical Flow
Jul 12, 2023
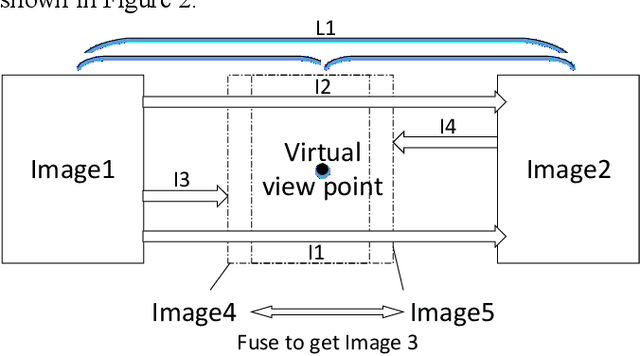


The virtual viewpoint is perceived as a new technique in virtual navigation, as yet not supported due to the lack of depth information and obscure camera parameters. In this paper, a method for achieving close-up virtual view is proposed and it only uses optical flow to build parallax effects to realize pseudo 3D projection without using depth sensor. We develop a bidirectional optical flow method to obtain any virtual viewpoint by proportional interpolation of optical flow. Moreover, with the ingenious application of the optical-flow-value, we achieve clear and visual-fidelity magnified results through lens stretching in any corner, which overcomes the visual distortion and image blur through viewpoint magnification and transition in Google Street View system.
LasUIE: Unifying Information Extraction with Latent Adaptive Structure-aware Generative Language Model
Apr 13, 2023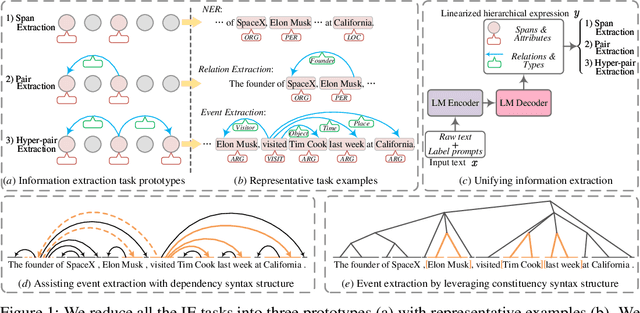
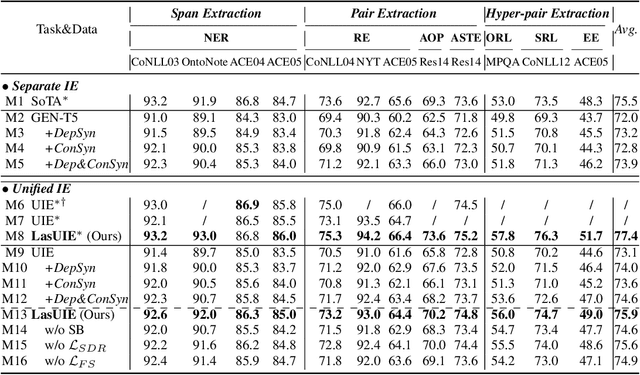
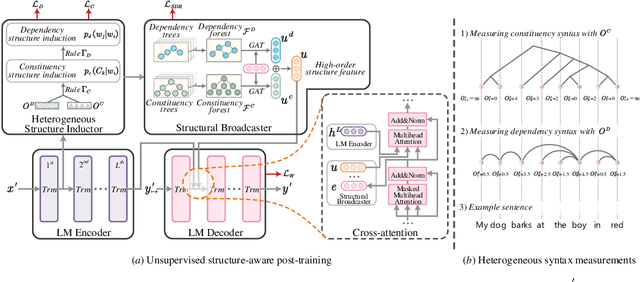
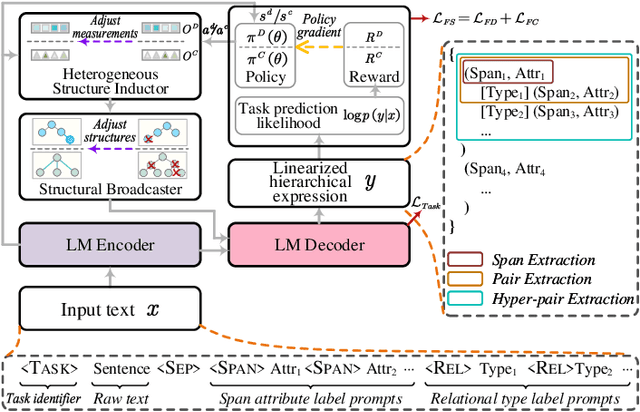
Universally modeling all typical information extraction tasks (UIE) with one generative language model (GLM) has revealed great potential by the latest study, where various IE predictions are unified into a linearized hierarchical expression under a GLM. Syntactic structure information, a type of effective feature which has been extensively utilized in IE community, should also be beneficial to UIE. In this work, we propose a novel structure-aware GLM, fully unleashing the power of syntactic knowledge for UIE. A heterogeneous structure inductor is explored to unsupervisedly induce rich heterogeneous structural representations by post-training an existing GLM. In particular, a structural broadcaster is devised to compact various latent trees into explicit high-order forests, helping to guide a better generation during decoding. We finally introduce a task-oriented structure fine-tuning mechanism, further adjusting the learned structures to most coincide with the end-task's need. Over 12 IE benchmarks across 7 tasks our system shows significant improvements over the baseline UIE system. Further in-depth analyses show that our GLM learns rich task-adaptive structural bias that greatly resolves the UIE crux, the long-range dependence issue and boundary identifying. Source codes are open at https://github.com/ChocoWu/LasUIE.
RexUIE: A Recursive Method with Explicit Schema Instructor for Universal Information Extraction
Apr 28, 2023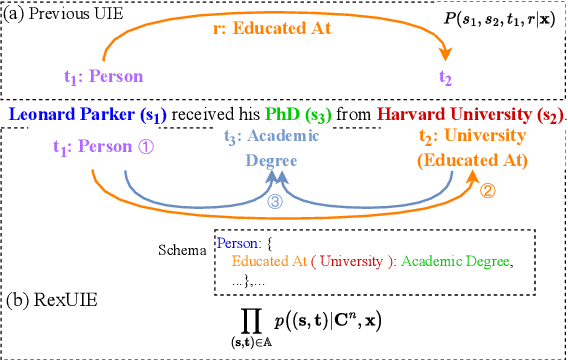
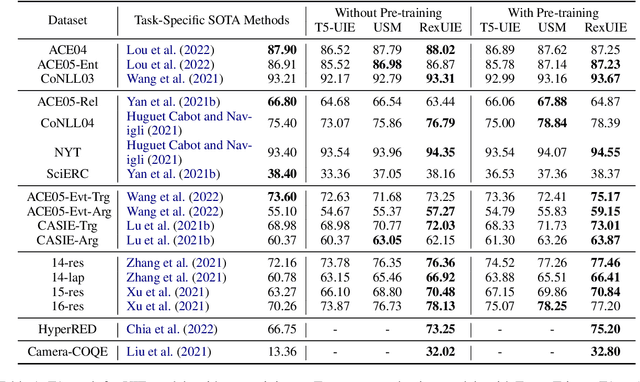
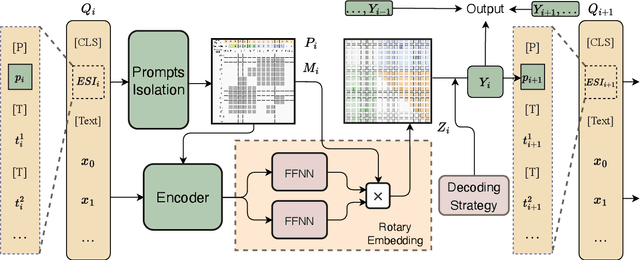
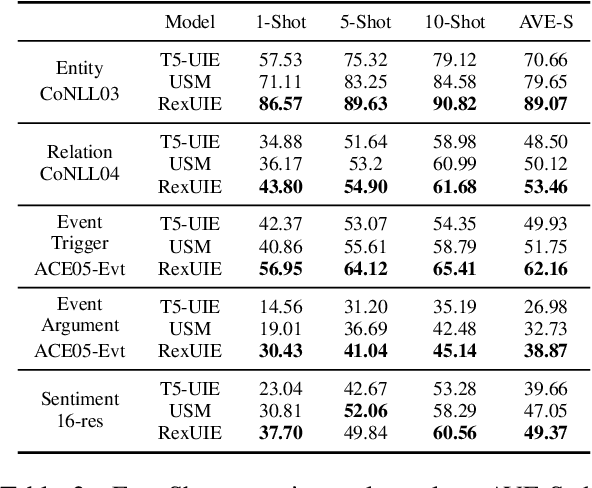
Universal Information Extraction (UIE) is an area of interest due to the challenges posed by varying targets, heterogeneous structures, and demand-specific schemas. However, previous works have only achieved limited success by unifying a few tasks, such as Named Entity Recognition (NER) and Relation Extraction (RE), which fall short of being authentic UIE models particularly when extracting other general schemas such as quadruples and quintuples. Additionally, these models used an implicit structural schema instructor, which could lead to incorrect links between types, hindering the model's generalization and performance in low-resource scenarios. In this paper, we redefine the authentic UIE with a formal formulation that encompasses almost all extraction schemas. To the best of our knowledge, we are the first to introduce UIE for any kind of schemas. In addition, we propose RexUIE, which is a Recursive Method with Explicit Schema Instructor for UIE. To avoid interference between different types, we reset the position ids and attention mask matrices. RexUIE shows strong performance under both full-shot and few-shot settings and achieves State-of-the-Art results on the tasks of extracting complex schemas.
ParGANDA: Making Synthetic Pedestrians A Reality For Object Detection
Jul 21, 2023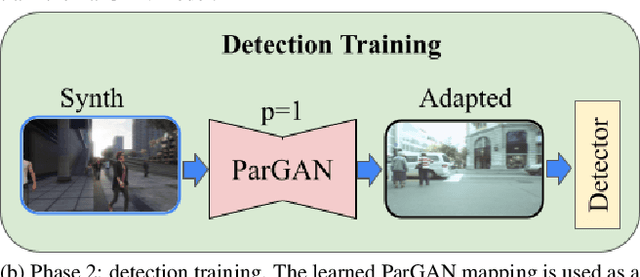



Object detection is the key technique to a number of Computer Vision applications, but it often requires large amounts of annotated data to achieve decent results. Moreover, for pedestrian detection specifically, the collected data might contain some personally identifiable information (PII), which is highly restricted in many countries. This label intensive and privacy concerning task has recently led to an increasing interest in training the detection models using synthetically generated pedestrian datasets collected with a photo-realistic video game engine. The engine is able to generate unlimited amounts of data with precise and consistent annotations, which gives potential for significant gains in the real-world applications. However, the use of synthetic data for training introduces a synthetic-to-real domain shift aggravating the final performance. To close the gap between the real and synthetic data, we propose to use a Generative Adversarial Network (GAN), which performsparameterized unpaired image-to-image translation to generate more realistic images. The key benefit of using the GAN is its intrinsic preference of low-level changes to geometric ones, which means annotations of a given synthetic image remain accurate even after domain translation is performed thus eliminating the need for labeling real data. We extensively experimented with the proposed method using MOTSynth dataset to train and MOT17 and MOT20 detection datasets to test, with experimental results demonstrating the effectiveness of this method. Our approach not only produces visually plausible samples but also does not require any labels of the real domain thus making it applicable to the variety of downstream tasks.
A Deep Learning Approach for Overall Survival Analysis with Missing Values
Jul 21, 2023One of the most challenging fields where Artificial Intelligence (AI) can be applied is lung cancer research, specifically non-small cell lung cancer (NSCLC). In particular, overall survival (OS) is a vital indicator of patient status, helping to identify subgroups with diverse survival probabilities, enabling tailored treatment and improved OS rates. In this analysis, there are two challenges to take into account. First, few studies effectively exploit the information available from each patient, leveraging both uncensored (i.e., dead) and censored (i.e., survivors) patients, considering also the death times. Second, the handling of incomplete data is a common issue in the medical field. This problem is typically tackled through the use of imputation methods. Our objective is to present an AI model able to overcome these limits, effectively learning from both censored and uncensored patients and their available features, for the prediction of OS for NSCLC patients. We present a novel approach to survival analysis in the context of NSCLC, which exploits the strengths of the transformer architecture accounting for only available features without requiring any imputation strategy. By making use of ad-hoc losses for OS, it accounts for both censored and uncensored patients, considering risks over time. We evaluated the results over a period of 6 years using different time granularities obtaining a Ct-index, a time-dependent variant of the C-index, of 71.97, 77.58 and 80.72 for time units of 1 month, 1 year and 2 years, respectively, outperforming all state-of-the-art methods regardless of the imputation method used.
A Synthetic Electrocardiogram (ECG) Image Generation Toolbox to Facilitate Deep Learning-Based Scanned ECG Digitization
Jul 04, 2023

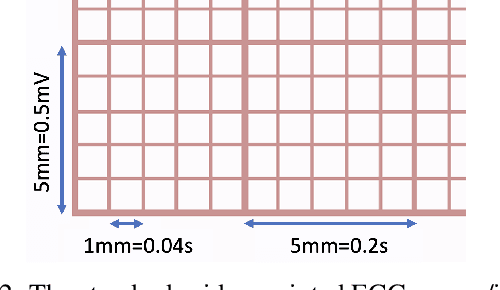
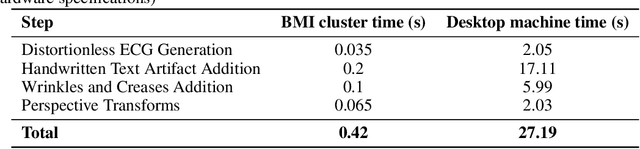
Access to medical data is often limited as it contains protected health information (PHI). There are privacy concerns regarding using records containing personally identifiable information. Recent advancements have been made in applying deep learning-based algorithms for clinical diagnosis and decision-making. However, deep learning models are data-greedy, whereas the availability of medical datasets for training and evaluating these models is relatively limited. Data augmentation with so-called \textit{digital twins} is an emerging technique to address this need. This paper presents a novel approach for generating synthetic electrocardiogram (ECG) images with realistic artifacts from time-series data for use in developing algorithms for digitization of ECG images. Synthetic data is generated in a privacy-preserving manner by generating distortionless ECG images on standard ECG paper background. Next, various distortions, including handwritten text artifacts, wrinkles, creases, and perspective transforms are applied to the ECG images. The artifacts are generated synthetically, without personally identifiable information. As a use case, we generated a large ECG image dataset of 21,801 records from the PhysioNet PTB-XL dataset, with 12 lead ECG time-series data from 18,869 patients. A deep ECG image digitization model was developed and trained on the synthetic dataset, and was employed to convert the synthetic images to time-series data for evaluation. The signal-to-noise ratio (SNR) was calculated to assess the image digitization quality vs the ground truth ECG time-series. The results show an average signal recovery SNR of 27$\pm$2.8\,dB, demonstrating the significance of the proposed synthetic ECG image dataset for training deep learning models.
Linking vision and motion for self-supervised object-centric perception
Jul 14, 2023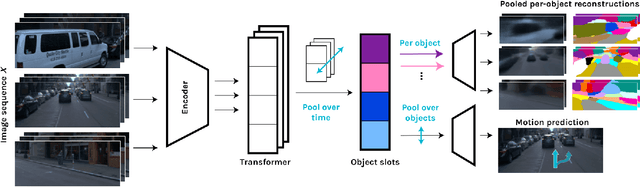
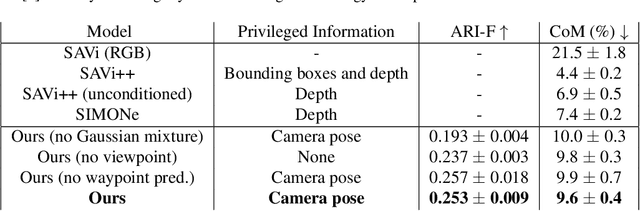


Object-centric representations enable autonomous driving algorithms to reason about interactions between many independent agents and scene features. Traditionally these representations have been obtained via supervised learning, but this decouples perception from the downstream driving task and could harm generalization. In this work we adapt a self-supervised object-centric vision model to perform object decomposition using only RGB video and the pose of the vehicle as inputs. We demonstrate that our method obtains promising results on the Waymo Open perception dataset. While object mask quality lags behind supervised methods or alternatives that use more privileged information, we find that our model is capable of learning a representation that fuses multiple camera viewpoints over time and successfully tracks many vehicles and pedestrians in the dataset. Code for our model is available at https://github.com/wayveai/SOCS.
A Quantitative Approach to Predicting Representational Learning and Performance in Neural Networks
Jul 14, 2023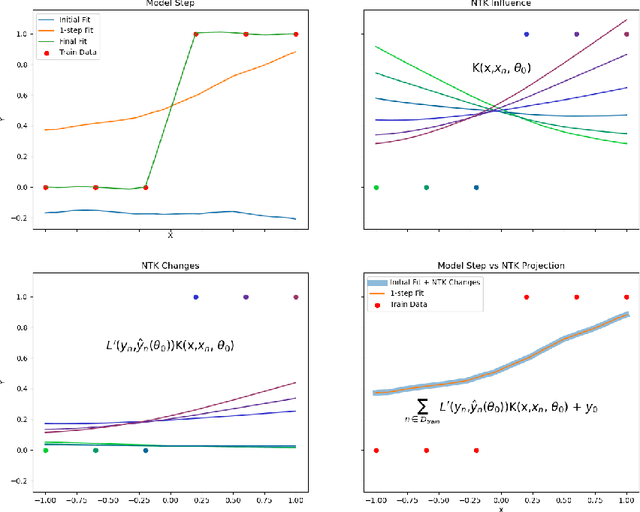
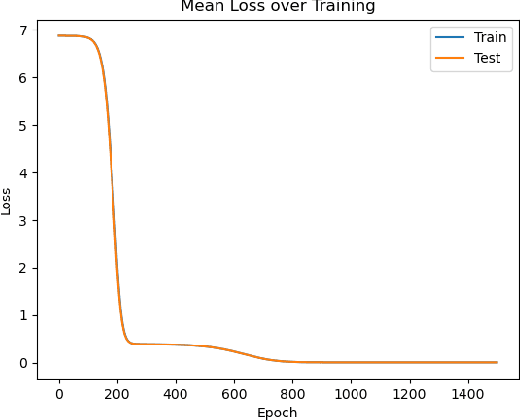
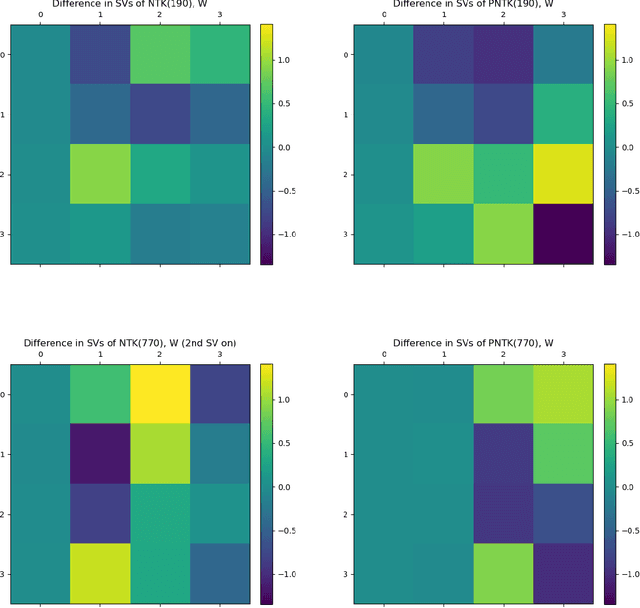
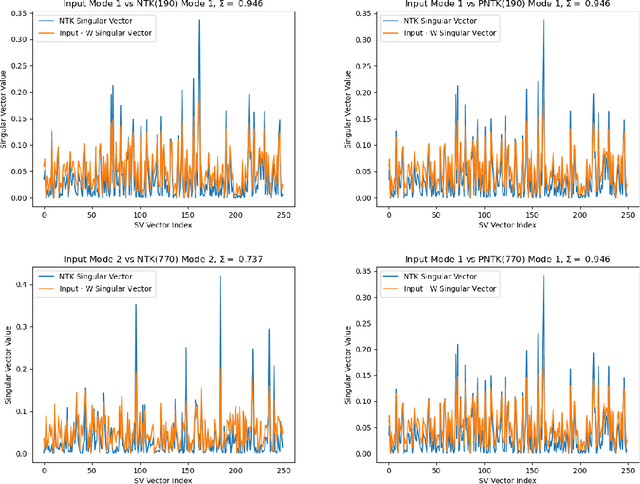
A key property of neural networks (both biological and artificial) is how they learn to represent and manipulate input information in order to solve a task. Different types of representations may be suited to different types of tasks, making identifying and understanding learned representations a critical part of understanding and designing useful networks. In this paper, we introduce a new pseudo-kernel based tool for analyzing and predicting learned representations, based only on the initial conditions of the network and the training curriculum. We validate the method on a simple test case, before demonstrating its use on a question about the effects of representational learning on sequential single versus concurrent multitask performance. We show that our method can be used to predict the effects of the scale of weight initialization and training curriculum on representational learning and downstream concurrent multitasking performance.
3D Medical Image Segmentation based on multi-scale MPU-Net
Jul 11, 2023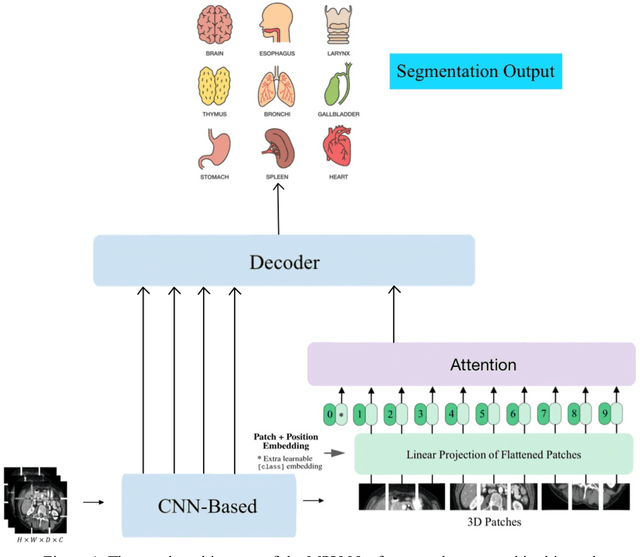
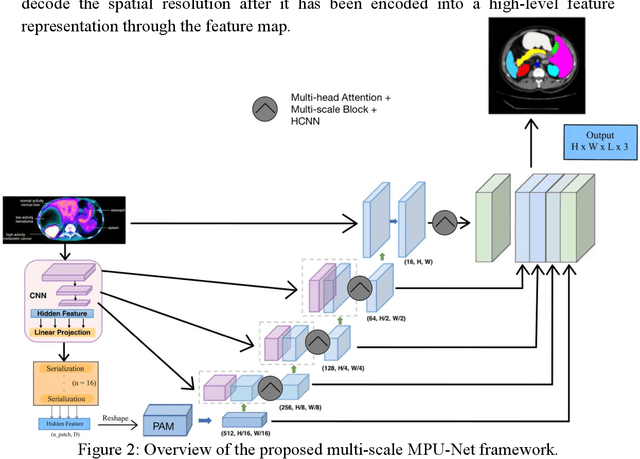
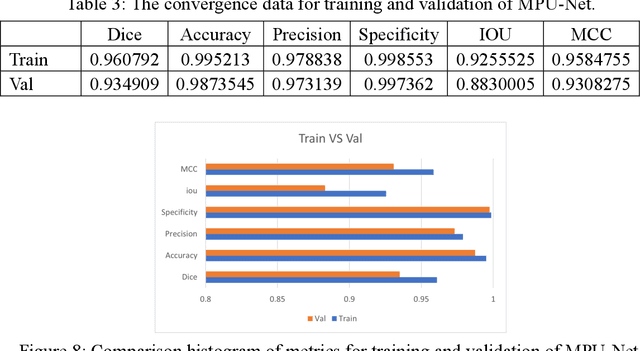
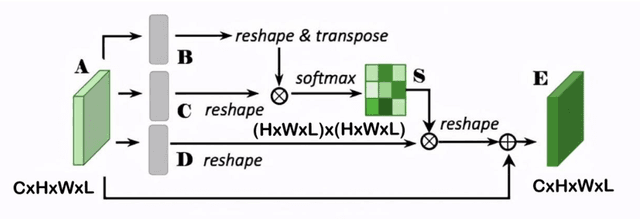
The high cure rate of cancer is inextricably linked to physicians' accuracy in diagnosis and treatment, therefore a model that can accomplish high-precision tumor segmentation has become a necessity in many applications of the medical industry. It can effectively lower the rate of misdiagnosis while considerably lessening the burden on clinicians. However, fully automated target organ segmentation is problematic due to the irregular stereo structure of 3D volume organs. As a basic model for this class of real applications, U-Net excels. It can learn certain global and local features, but still lacks the capacity to grasp spatial long-range relationships and contextual information at multiple scales. This paper proposes a tumor segmentation model MPU-Net for patient volume CT images, which is inspired by Transformer with a global attention mechanism. By combining image serialization with the Position Attention Module, the model attempts to comprehend deeper contextual dependencies and accomplish precise positioning. Each layer of the decoder is also equipped with a multi-scale module and a cross-attention mechanism. The capability of feature extraction and integration at different levels has been enhanced, and the hybrid loss function developed in this study can better exploit high-resolution characteristic information. Moreover, the suggested architecture is tested and evaluated on the Liver Tumor Segmentation Challenge 2017 (LiTS 2017) dataset. Compared with the benchmark model U-Net, MPU-Net shows excellent segmentation results. The dice, accuracy, precision, specificity, IOU, and MCC metrics for the best model segmentation results are 92.17%, 99.08%, 91.91%, 99.52%, 85.91%, and 91.74%, respectively. Outstanding indicators in various aspects illustrate the exceptional performance of this framework in automatic medical image segmentation.