 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Feature Matching via Matchable Keypoint-Assisted Graph Neural Network
Jul 04, 2023
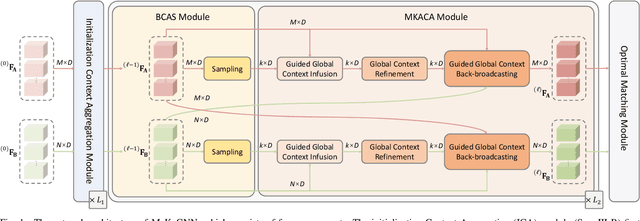
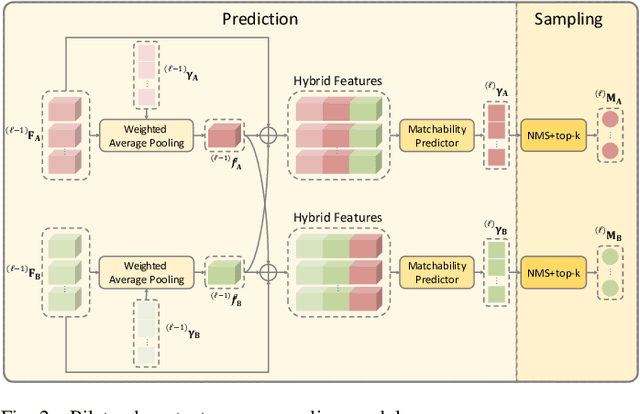
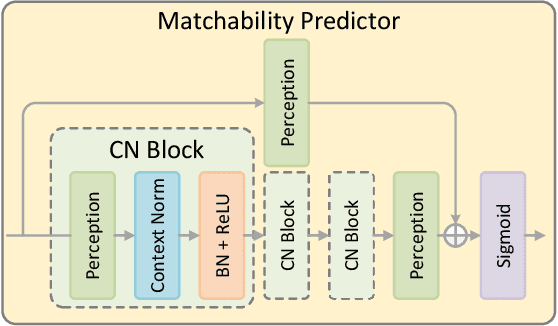
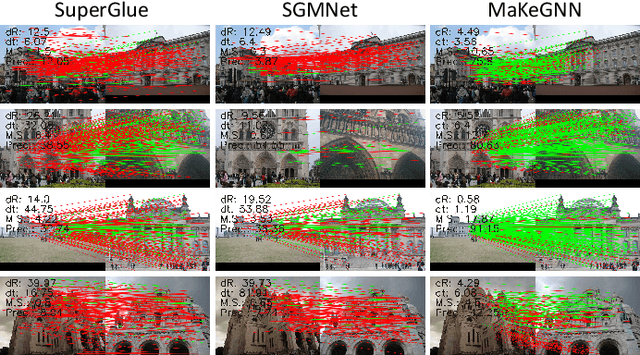
Accurately matching local features between a pair of images is a challenging computer vision task. Previous studies typically use attention based graph neural networks (GNNs) with fully-connected graphs over keypoints within/across images for visual and geometric information reasoning. However, in the context of feature matching, considerable keypoints are non-repeatable due to occlusion and failure of the detector, and thus irrelevant for message passing. The connectivity with non-repeatable keypoints not only introduces redundancy, resulting in limited efficiency, but also interferes with the representation aggregation process, leading to limited accuracy. Targeting towards high accuracy and efficiency, we propose MaKeGNN, a sparse attention-based GNN architecture which bypasses non-repeatable keypoints and leverages matchable ones to guide compact and meaningful message passing. More specifically, our Bilateral Context-Aware Sampling Module first dynamically samples two small sets of well-distributed keypoints with high matchability scores from the image pair. Then, our Matchable Keypoint-Assisted Context Aggregation Module regards sampled informative keypoints as message bottlenecks and thus constrains each keypoint only to retrieve favorable contextual information from intra- and inter- matchable keypoints, evading the interference of irrelevant and redundant connectivity with non-repeatable ones. Furthermore, considering the potential noise in initial keypoints and sampled matchable ones, the MKACA module adopts a matchability-guided attentional aggregation operation for purer data-dependent context propagation. By these means, we achieve the state-of-the-art performance on relative camera estimation, fundamental matrix estimation, and visual localization, while significantly reducing computational and memory complexity compared to typical attentional GNNs.
Feature Adversarial Distillation for Point Cloud Classification
Jun 27, 2023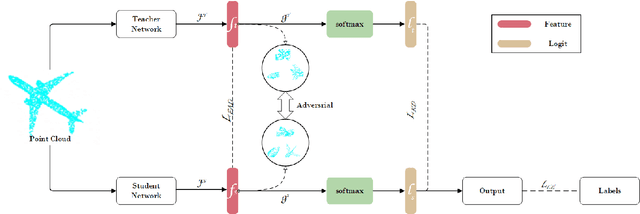
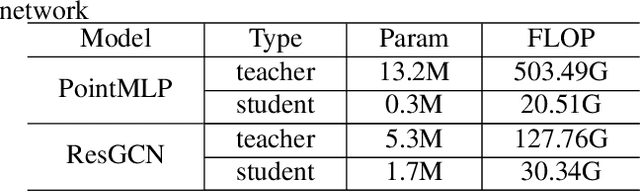
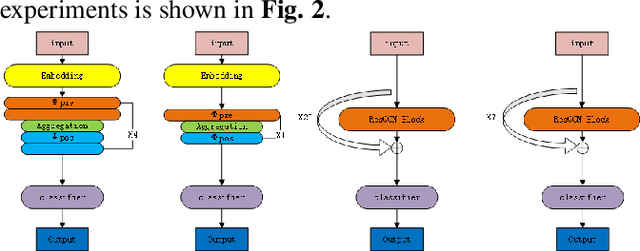
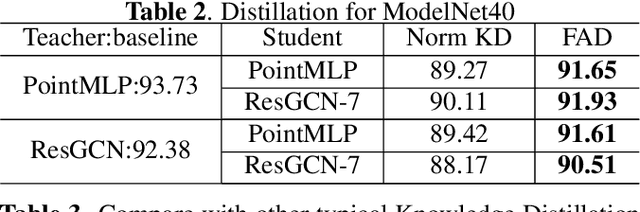
Due to the point cloud's irregular and unordered geometry structure, conventional knowledge distillation technology lost a lot of information when directly used on point cloud tasks. In this paper, we propose Feature Adversarial Distillation (FAD) method, a generic adversarial loss function in point cloud distillation, to reduce loss during knowledge transfer. In the feature extraction stage, the features extracted by the teacher are used as the discriminator, and the students continuously generate new features in the training stage. The feature of the student is obtained by attacking the feedback from the teacher and getting a score to judge whether the student has learned the knowledge well or not. In experiments on standard point cloud classification on ModelNet40 and ScanObjectNN datasets, our method reduced the information loss of knowledge transfer in distillation in 40x model compression while maintaining competitive performance.
Real-time Percussive Technique Recognition and Embedding Learning for the Acoustic Guitar
Jul 13, 2023Real-time music information retrieval (RT-MIR) has much potential to augment the capabilities of traditional acoustic instruments. We develop RT-MIR techniques aimed at augmenting percussive fingerstyle, which blends acoustic guitar playing with guitar body percussion. We formulate several design objectives for RT-MIR systems for augmented instrument performance: (i) causal constraint, (ii) perceptually negligible action-to-sound latency, (iii) control intimacy support, (iv) synthesis control support. We present and evaluate real-time guitar body percussion recognition and embedding learning techniques based on convolutional neural networks (CNNs) and CNNs jointly trained with variational autoencoders (VAEs). We introduce a taxonomy of guitar body percussion based on hand part and location. We follow a cross-dataset evaluation approach by collecting three datasets labelled according to the taxonomy. The embedding quality of the models is assessed using KL-Divergence across distributions corresponding to different taxonomic classes. Results indicate that the networks are strong classifiers especially in a simplified 2-class recognition task, and the VAEs yield improved class separation compared to CNNs as evidenced by increased KL-Divergence across distributions. We argue that the VAE embedding quality could support control intimacy and rich interaction when the latent space's parameters are used to control an external synthesis engine. Further design challenges around generalisation to different datasets have been identified.
An Improved Metric of Informational Masking for Perceptual Audio Quality Measurement
Jul 13, 2023Perceptual audio quality measurement systems algorithmically analyze the output of audio processing systems to estimate possible perceived quality degradation using perceptual models of human audition. In this manner, they save the time and resources associated with the design and execution of listening tests (LTs). Models of disturbance audibility predicting peripheral auditory masking in quality measurement systems have considerably increased subjective quality prediction performance of signals processed by perceptual audio codecs. Additionally, cognitive effects have also been known to regulate perceived distortion severity by influencing their salience. However, the performance gains due to cognitive effect models in quality measurement systems were inconsistent so far, particularly for music signals. Firstly, this paper presents an improved model of informational masking (IM) -- an important cognitive effect in quality perception -- that considers disturbance information complexity around the masking threshold. Secondly, we incorporate the proposed IM metric into a quality measurement systems using a novel interaction analysis procedure between cognitive effects and distortion metrics. The procedure establishes interactions between cognitive effects and distortion metrics using LT data. The proposed IM metric is shown to outperform previously proposed IM metrics in a validation task against subjective quality scores from large and diverse LT databases. Particularly, the proposed system showed an increased quality prediction of music signals coded with bandwidth extension techniques, where other models frequently fail.
Student Assessment in Cybersecurity Training Automated by Pattern Mining and Clustering
Jul 13, 2023Hands-on cybersecurity training allows students and professionals to practice various tools and improve their technical skills. The training occurs in an interactive learning environment that enables completing sophisticated tasks in full-fledged operating systems, networks, and applications. During the training, the learning environment allows collecting data about trainees' interactions with the environment, such as their usage of command-line tools. These data contain patterns indicative of trainees' learning processes, and revealing them allows to assess the trainees and provide feedback to help them learn. However, automated analysis of these data is challenging. The training tasks feature complex problem-solving, and many different solution approaches are possible. Moreover, the trainees generate vast amounts of interaction data. This paper explores a dataset from 18 cybersecurity training sessions using data mining and machine learning techniques. We employed pattern mining and clustering to analyze 8834 commands collected from 113 trainees, revealing their typical behavior, mistakes, solution strategies, and difficult training stages. Pattern mining proved suitable in capturing timing information and tool usage frequency. Clustering underlined that many trainees often face the same issues, which can be addressed by targeted scaffolding. Our results show that data mining methods are suitable for analyzing cybersecurity training data. Educational researchers and practitioners can apply these methods in their contexts to assess trainees, support them, and improve the training design. Artifacts associated with this research are publicly available.
* Published in Springer Education and Information Technologies, see https://link.springer.com/article/10.1007/s10639-022-10954-4
Action-State Dependent Dynamic Model Selection
Jul 07, 2023
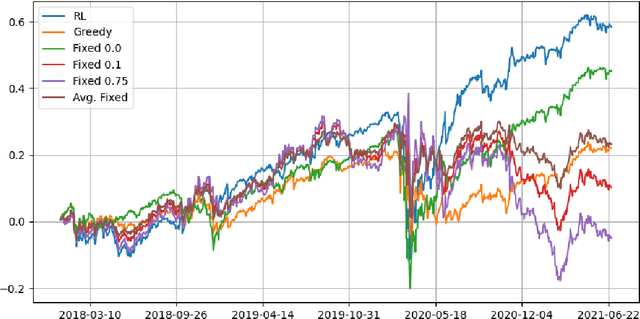
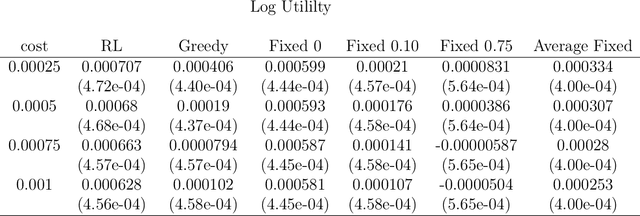
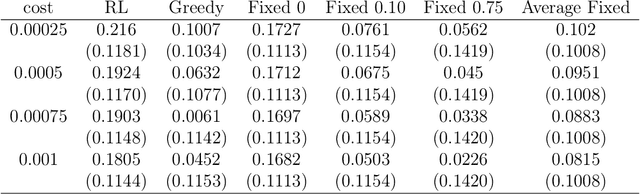
A model among many may only be best under certain states of the world. Switching from a model to another can also be costly. Finding a procedure to dynamically choose a model in these circumstances requires to solve a complex estimation procedure and a dynamic programming problem. A Reinforcement learning algorithm is used to approximate and estimate from the data the optimal solution to this dynamic programming problem. The algorithm is shown to consistently estimate the optimal policy that may choose different models based on a set of covariates. A typical example is the one of switching between different portfolio models under rebalancing costs, using macroeconomic information. Using a set of macroeconomic variables and price data, an empirical application to the aforementioned portfolio problem shows superior performance to choosing the best portfolio model with hindsight.
SimpleMTOD: A Simple Language Model for Multimodal Task-Oriented Dialogue with Symbolic Scene Representation
Jul 10, 2023
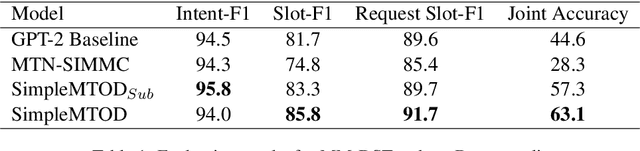
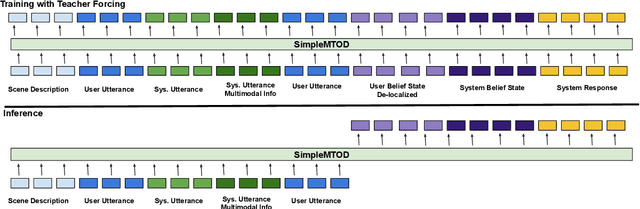

SimpleMTOD is a simple language model which recasts several sub-tasks in multimodal task-oriented dialogues as sequence prediction tasks. SimpleMTOD is built on a large-scale transformer-based auto-regressive architecture, which has already proven to be successful in uni-modal task-oriented dialogues, and effectively leverages transfer learning from pre-trained GPT-2. In-order to capture the semantics of visual scenes, we introduce both local and de-localized tokens for objects within a scene. De-localized tokens represent the type of an object rather than the specific object itself and so possess a consistent meaning across the dataset. SimpleMTOD achieves a state-of-the-art BLEU score (0.327) in the Response Generation sub-task of the SIMMC 2.0 test-std dataset while performing on par in other multimodal sub-tasks: Disambiguation, Coreference Resolution, and Dialog State Tracking. This is despite taking a minimalist approach for extracting visual (and non-visual) information. In addition the model does not rely on task-specific architectural changes such as classification heads.
Fairness and Diversity in Recommender Systems: A Survey
Jul 10, 2023Recommender systems are effective tools for mitigating information overload and have seen extensive applications across various domains. However, the single focus on utility goals proves to be inadequate in addressing real-world concerns, leading to increasing attention to fairness-aware and diversity-aware recommender systems. While most existing studies explore fairness and diversity independently, we identify strong connections between these two domains. In this survey, we first discuss each of them individually and then dive into their connections. Additionally, motivated by the concepts of user-level and item-level fairness, we broaden the understanding of diversity to encompass not only the item level but also the user level. With this expanded perspective on user and item-level diversity, we re-interpret fairness studies from the viewpoint of diversity. This fresh perspective enhances our understanding of fairness-related work and paves the way for potential future research directions. Papers discussed in this survey along with public code links are available at https://github.com/YuyingZhao/Awesome-Fairness-and-Diversity-Papers-in-Recommender-Systems .
Unveiling the Potential of Spike Streams for Foreground Occlusion Removal from Densely Continuous Views
Jul 03, 2023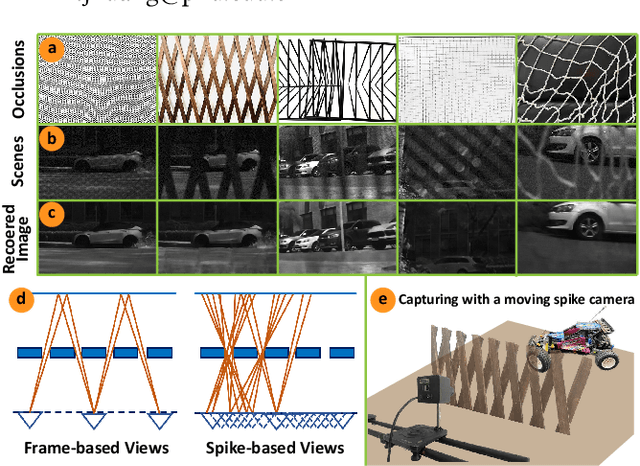
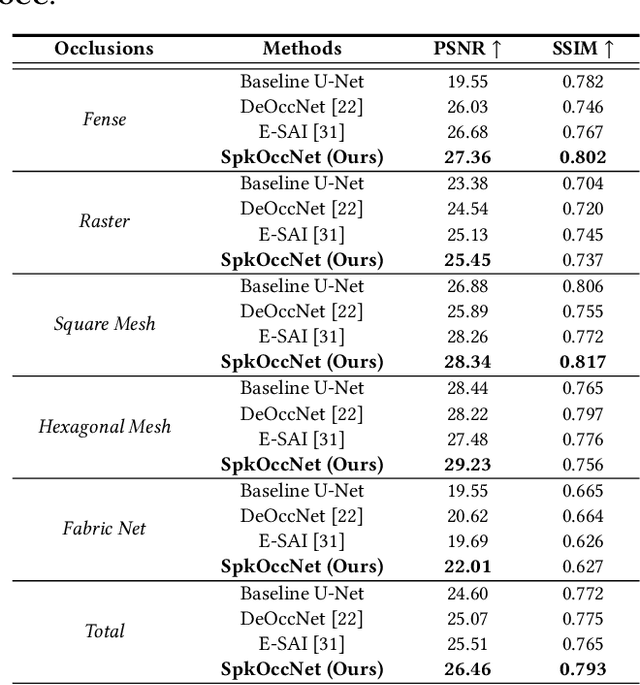
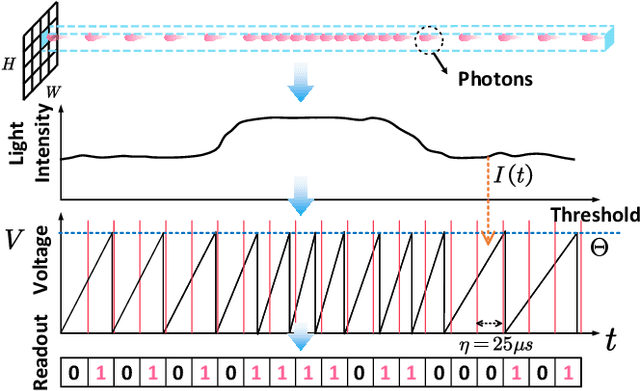
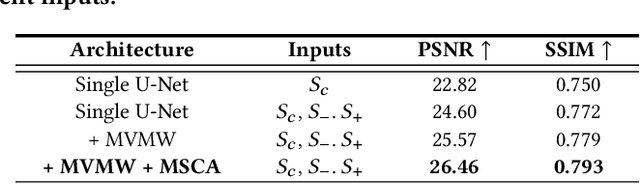
The extraction of a clean background image by removing foreground occlusion holds immense practical significance, but it also presents several challenges. Presently, the majority of de-occlusion research focuses on addressing this issue through the extraction and synthesis of discrete images from calibrated camera arrays. Nonetheless, the restoration quality tends to suffer when faced with dense occlusions or high-speed motions due to limited perspectives and motion blur. To successfully remove dense foreground occlusion, an effective multi-view visual information integration approach is required. Introducing the spike camera as a novel type of neuromorphic sensor offers promising capabilities with its ultra-high temporal resolution and high dynamic range. In this paper, we propose an innovative solution for tackling the de-occlusion problem through continuous multi-view imaging using only one spike camera without any prior knowledge of camera intrinsic parameters and camera poses. By rapidly moving the spike camera, we continually capture the dense stream of spikes from the occluded scene. To process the spikes, we build a novel model \textbf{SpkOccNet}, in which we integrate information of spikes from continuous viewpoints within multi-windows, and propose a novel cross-view mutual attention mechanism for effective fusion and refinement. In addition, we contribute the first real-world spike-based dataset \textbf{S-OCC} for occlusion removal. The experimental results demonstrate that our proposed model efficiently removes dense occlusions in diverse scenes while exhibiting strong generalization.
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
Jul 12, 2023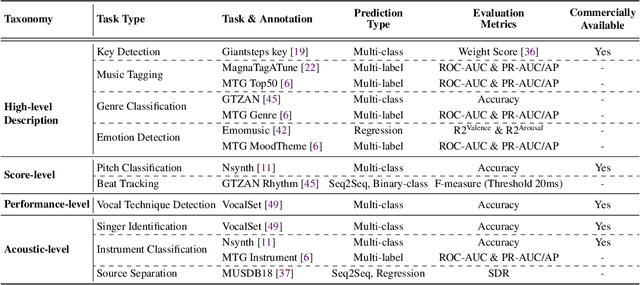
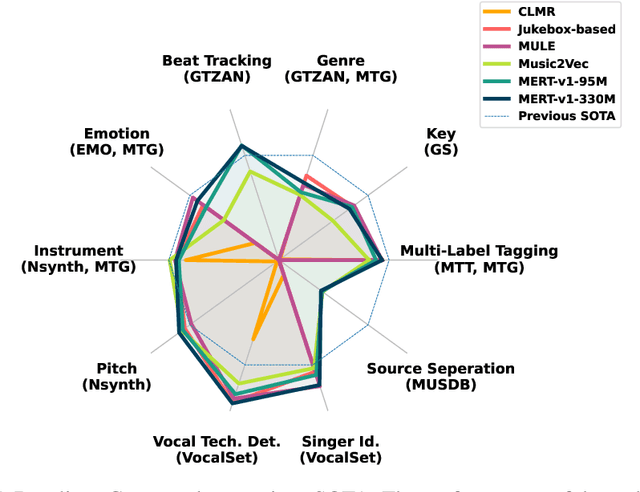
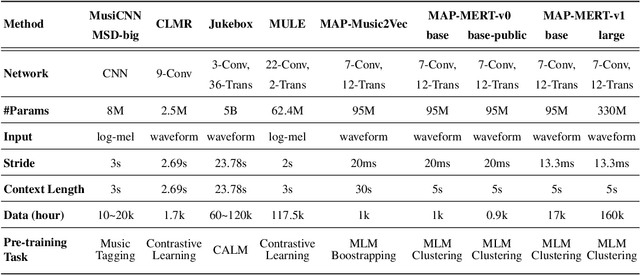
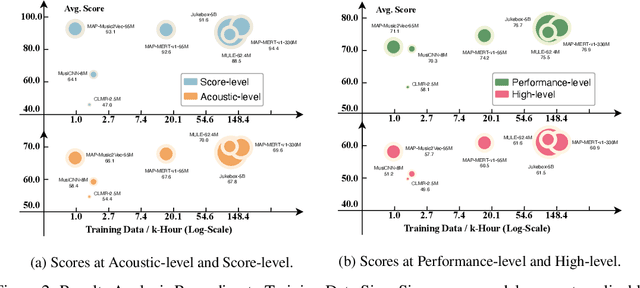
In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.