 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DEKGCI: A double-sided recommendation model for integrating knowledge graph and user-item interaction graph
Jun 24, 2023
Both knowledge graphs and user-item interaction graphs are frequently used in recommender systems due to their ability to provide rich information for modeling users and items. However, existing studies often focused on one of these sources (either the knowledge graph or the user-item interaction graph), resulting in underutilization of the benefits that can be obtained by integrating both sources of information. In this paper, we propose DEKGCI, a novel double-sided recommendation model. In DEKGCI, we use the high-order collaborative signals from the user-item interaction graph to enrich the user representations on the user side. Additionally, we utilize the high-order structural and semantic information from the knowledge graph to enrich the item representations on the item side. DEKGCI simultaneously learns the user and item representations to effectively capture the joint interactions between users and items. Three real-world datasets are adopted in the experiments to evaluate DEKGCI's performance, and experimental results demonstrate its high effectiveness compared to seven state-of-the-art baselines in terms of AUC and ACC.
KECOR: Kernel Coding Rate Maximization for Active 3D Object Detection
Jul 16, 2023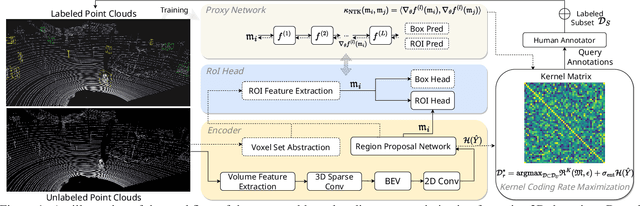
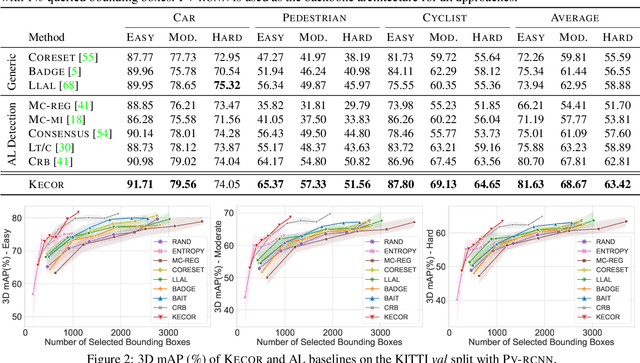
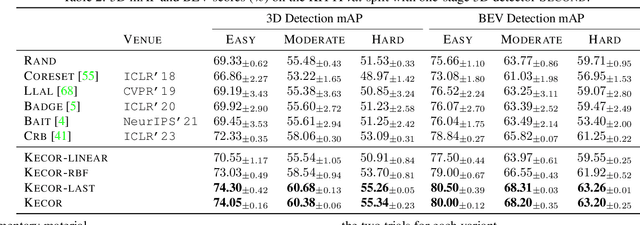
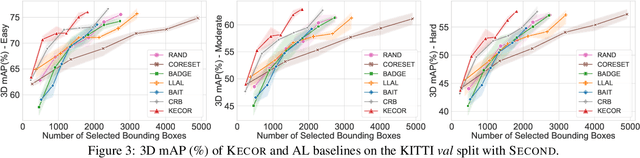
Achieving a reliable LiDAR-based object detector in autonomous driving is paramount, but its success hinges on obtaining large amounts of precise 3D annotations. Active learning (AL) seeks to mitigate the annotation burden through algorithms that use fewer labels and can attain performance comparable to fully supervised learning. Although AL has shown promise, current approaches prioritize the selection of unlabeled point clouds with high uncertainty and/or diversity, leading to the selection of more instances for labeling and reduced computational efficiency. In this paper, we resort to a novel kernel coding rate maximization (KECOR) strategy which aims to identify the most informative point clouds to acquire labels through the lens of information theory. Greedy search is applied to seek desired point clouds that can maximize the minimal number of bits required to encode the latent features. To determine the uniqueness and informativeness of the selected samples from the model perspective, we construct a proxy network of the 3D detector head and compute the outer product of Jacobians from all proxy layers to form the empirical neural tangent kernel (NTK) matrix. To accommodate both one-stage (i.e., SECOND) and two-stage detectors (i.e., PVRCNN), we further incorporate the classification entropy maximization and well trade-off between detection performance and the total number of bounding boxes selected for annotation. Extensive experiments conducted on two 3D benchmarks and a 2D detection dataset evidence the superiority and versatility of the proposed approach. Our results show that approximately 44% box-level annotation costs and 26% computational time are reduced compared to the state-of-the-art AL method, without compromising detection performance.
TransNuSeg: A Lightweight Multi-Task Transformer for Nuclei Segmentation
Jul 16, 2023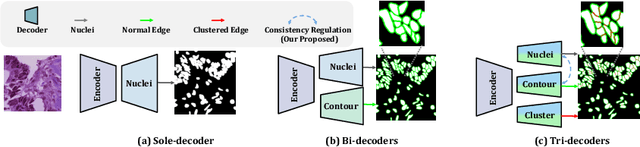
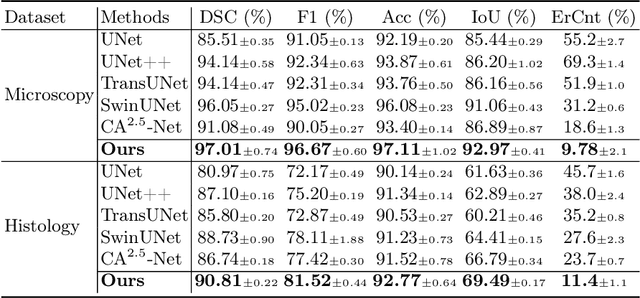
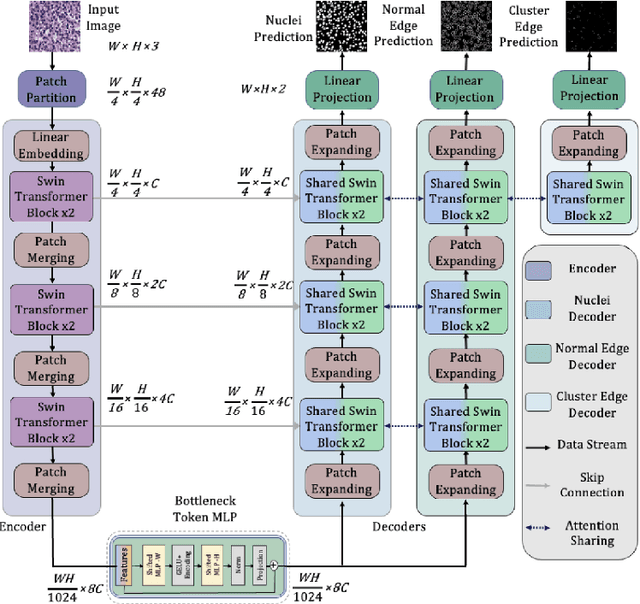
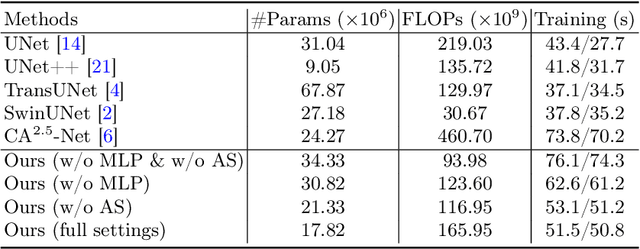
Nuclei appear small in size, yet, in real clinical practice, the global spatial information and correlation of the color or brightness contrast between nuclei and background, have been considered a crucial component for accurate nuclei segmentation. However, the field of automatic nuclei segmentation is dominated by Convolutional Neural Networks (CNNs), meanwhile, the potential of the recently prevalent Transformers has not been fully explored, which is powerful in capturing local-global correlations. To this end, we make the first attempt at a pure Transformer framework for nuclei segmentation, called TransNuSeg. Different from prior work, we decouple the challenging nuclei segmentation task into an intrinsic multi-task learning task, where a tri-decoder structure is employed for nuclei instance, nuclei edge, and clustered edge segmentation respectively. To eliminate the divergent predictions from different branches in previous work, a novel self distillation loss is introduced to explicitly impose consistency regulation between branches. Moreover, to formulate the high correlation between branches and also reduce the number of parameters, an efficient attention sharing scheme is proposed by partially sharing the self-attention heads amongst the tri-decoders. Finally, a token MLP bottleneck replaces the over-parameterized Transformer bottleneck for a further reduction in model complexity. Experiments on two datasets of different modalities, including MoNuSeg have shown that our methods can outperform state-of-the-art counterparts such as CA2.5-Net by 2-3% Dice with 30% fewer parameters. In conclusion, TransNuSeg confirms the strength of Transformer in the context of nuclei segmentation, which thus can serve as an efficient solution for real clinical practice. Code is available at https://github.com/zhenqi-he/transnuseg.
Classical Capacity of Arbitrarily Distributed Noisy Quantum Channels
Jun 28, 2023With the rapid deployment of quantum computers and quantum satellites, there is a pressing need to design and deploy quantum and hybrid classical-quantum networks capable of exchanging classical information. In this context, we conduct the foundational study on the impact of a mixture of classical and quantum noise on an arbitrary quantum channel carrying classical information. The rationale behind considering such mixed noise is that quantum noise can arise from different entanglement and discord in quantum transmission scenarios, like different memories and repeater technologies, while classical noise can arise from the coexistence with the classical signal. Towards this end, we derive the distribution of the mixed noise from a classical system's perspective, and formulate the achievable channel capacity over an arbitrary distributed quantum channel in presence of the mixed noise. Numerical results demonstrate that capacity increases with the increase in the number of photons per usage.
Covering Uncommon Ground: Gap-Focused Question Generation for Answer Assessment
Jul 06, 2023
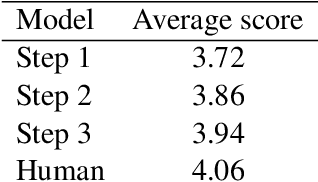
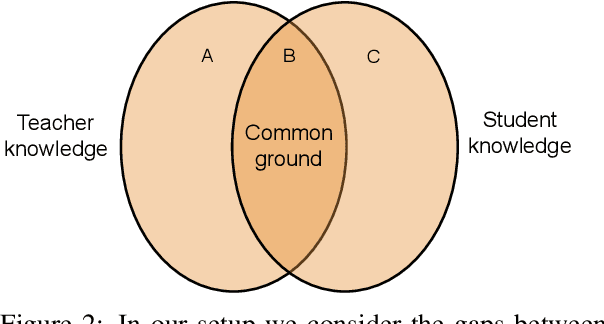

Human communication often involves information gaps between the interlocutors. For example, in an educational dialogue, a student often provides an answer that is incomplete, and there is a gap between this answer and the perfect one expected by the teacher. Successful dialogue then hinges on the teacher asking about this gap in an effective manner, thus creating a rich and interactive educational experience. We focus on the problem of generating such gap-focused questions (GFQs) automatically. We define the task, highlight key desired aspects of a good GFQ, and propose a model that satisfies these. Finally, we provide an evaluation by human annotators of our generated questions compared against human generated ones, demonstrating competitive performance.
Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness
Apr 23, 2023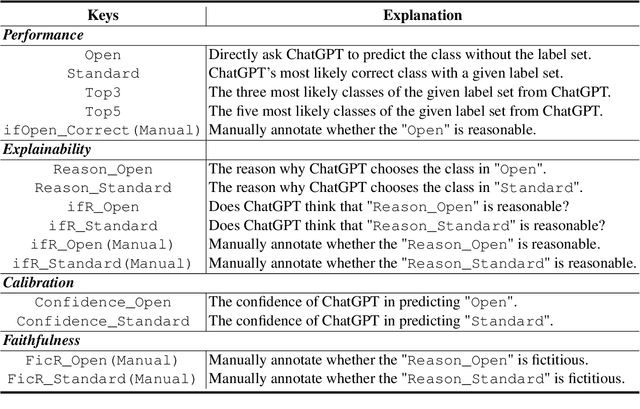
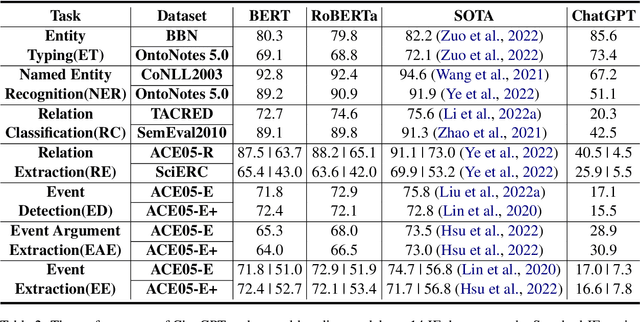
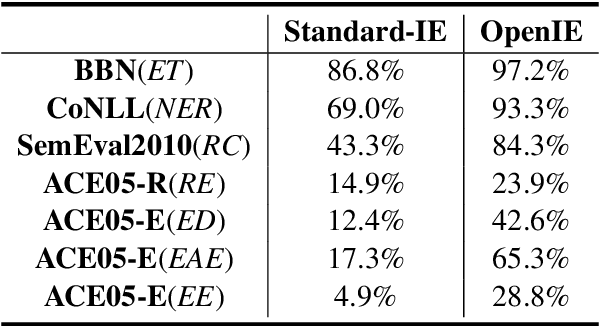
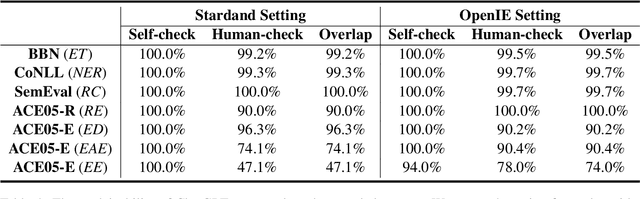
The capability of Large Language Models (LLMs) like ChatGPT to comprehend user intent and provide reasonable responses has made them extremely popular lately. In this paper, we focus on assessing the overall ability of ChatGPT using 7 fine-grained information extraction (IE) tasks. Specially, we present the systematically analysis by measuring ChatGPT's performance, explainability, calibration, and faithfulness, and resulting in 15 keys from either the ChatGPT or domain experts. Our findings reveal that ChatGPT's performance in Standard-IE setting is poor, but it surprisingly exhibits excellent performance in the OpenIE setting, as evidenced by human evaluation. In addition, our research indicates that ChatGPT provides high-quality and trustworthy explanations for its decisions. However, there is an issue of ChatGPT being overconfident in its predictions, which resulting in low calibration. Furthermore, ChatGPT demonstrates a high level of faithfulness to the original text in the majority of cases. We manually annotate and release the test sets of 7 fine-grained IE tasks contains 14 datasets to further promote the research. The datasets and code are available at https://github.com/pkuserc/ChatGPT_for_IE.
Can LLMs be Good Financial Advisors?: An Initial Study in Personal Decision Making for Optimized Outcomes
Jul 08, 2023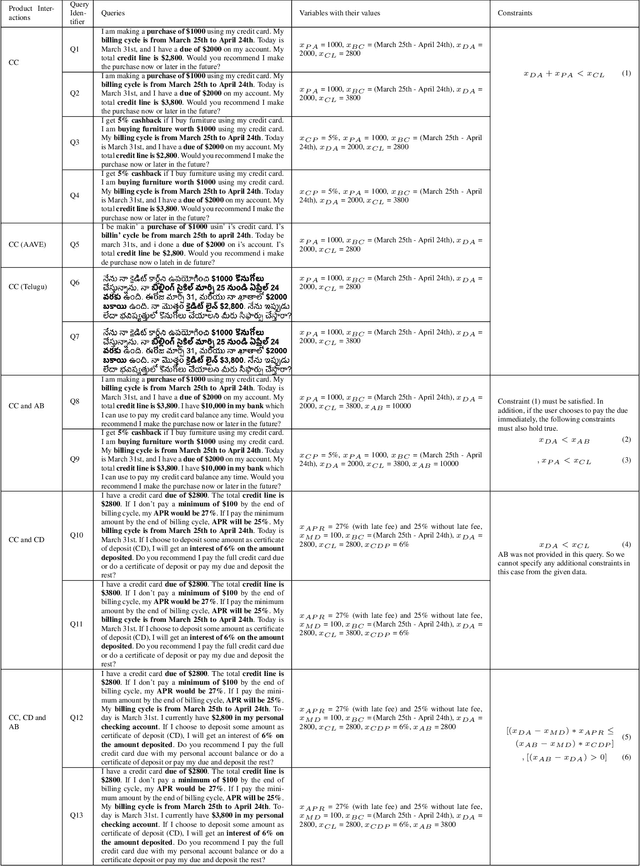
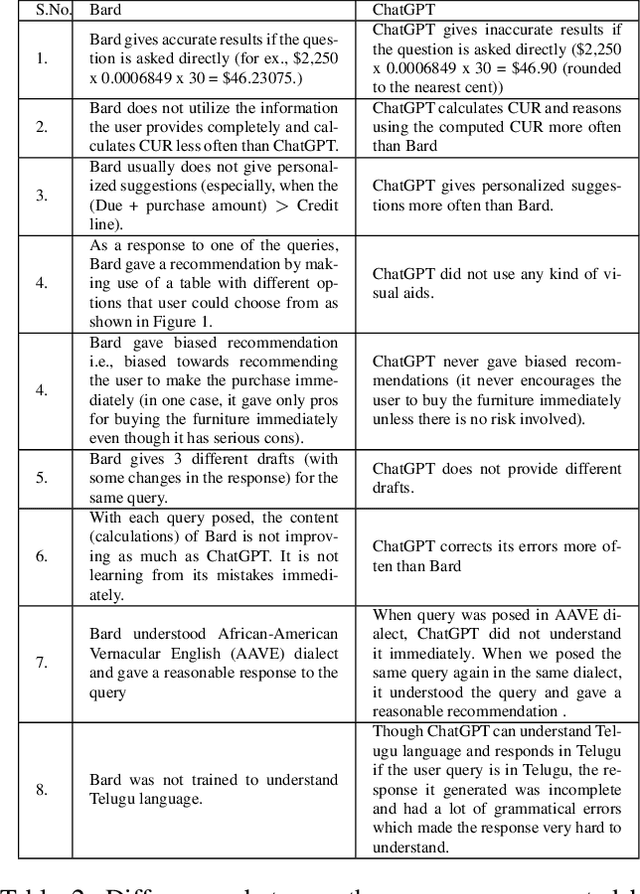
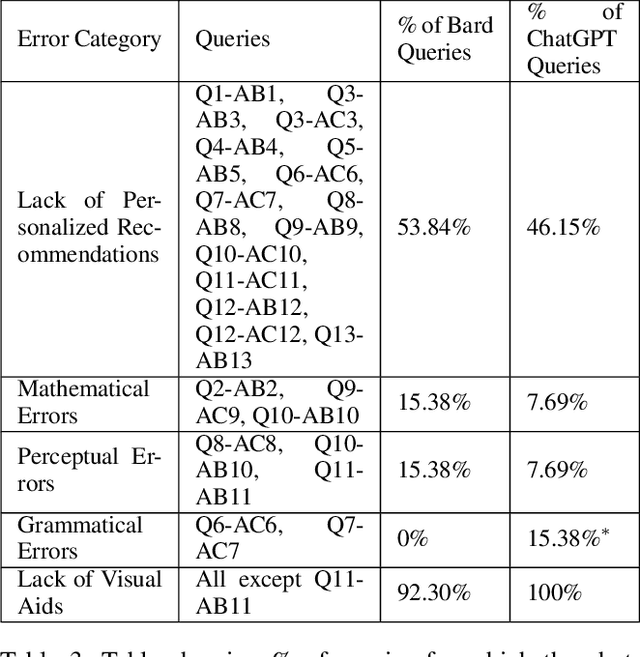
Increasingly powerful Large Language Model (LLM) based chatbots, like ChatGPT and Bard, are becoming available to users that have the potential to revolutionize the quality of decision-making achieved by the public. In this context, we set out to investigate how such systems perform in the personal finance domain, where financial inclusion has been an overarching stated aim of banks for decades. We asked 13 questions representing banking products in personal finance: bank account, credit card, and certificate of deposits and their inter-product interactions, and decisions related to high-value purchases, payment of bank dues, and investment advice, and in different dialects and languages (English, African American Vernacular English, and Telugu). We find that although the outputs of the chatbots are fluent and plausible, there are still critical gaps in providing accurate and reliable financial information using LLM-based chatbots.
Ariadne's Thread:Using Text Prompts to Improve Segmentation of Infected Areas from Chest X-ray images
Jul 08, 2023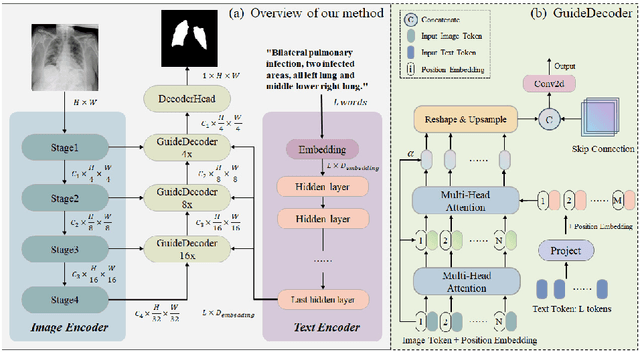
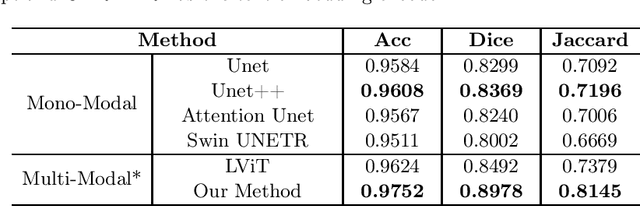

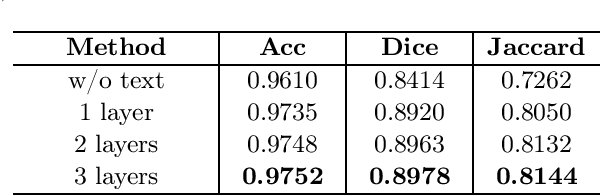
Segmentation of the infected areas of the lung is essential for quantifying the severity of lung disease like pulmonary infections. Existing medical image segmentation methods are almost uni-modal methods based on image. However, these image-only methods tend to produce inaccurate results unless trained with large amounts of annotated data. To overcome this challenge, we propose a language-driven segmentation method that uses text prompt to improve to the segmentation result. Experiments on the QaTa-COV19 dataset indicate that our method improves the Dice score by 6.09% at least compared to the uni-modal methods. Besides, our extended study reveals the flexibility of multi-modal methods in terms of the information granularity of text and demonstrates that multi-modal methods have a significant advantage over image-only methods in terms of the size of training data required.
Recommender Systems in the Era of Large Language Models (LLMs)
Jul 05, 2023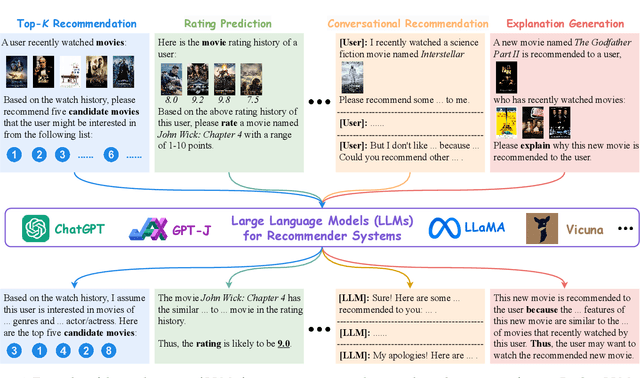
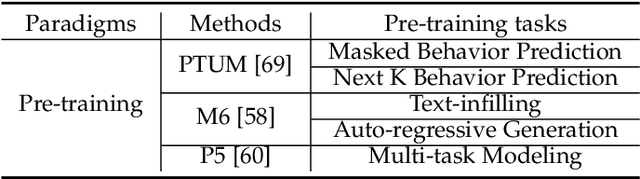
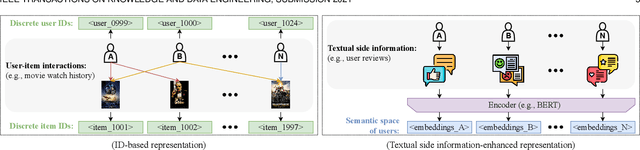

With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
Graph Contrastive Topic Model
Jul 05, 2023

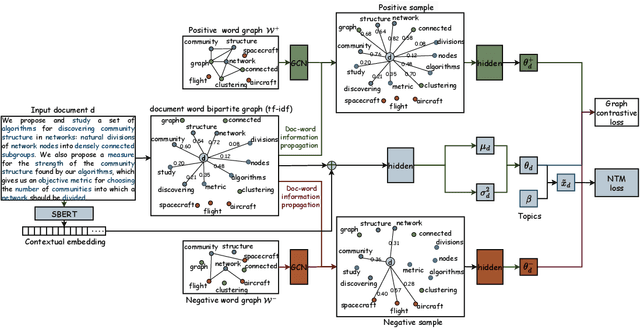
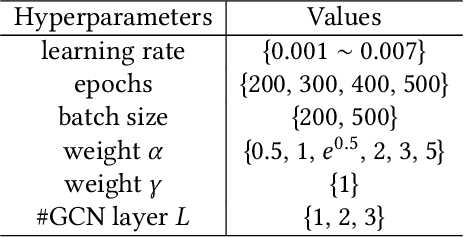
Existing NTMs with contrastive learning suffer from the sample bias problem owing to the word frequency-based sampling strategy, which may result in false negative samples with similar semantics to the prototypes. In this paper, we aim to explore the efficient sampling strategy and contrastive learning in NTMs to address the aforementioned issue. We propose a new sampling assumption that negative samples should contain words that are semantically irrelevant to the prototype. Based on it, we propose the graph contrastive topic model (GCTM), which conducts graph contrastive learning (GCL) using informative positive and negative samples that are generated by the graph-based sampling strategy leveraging in-depth correlation and irrelevance among documents and words. In GCTM, we first model the input document as the document word bipartite graph (DWBG), and construct positive and negative word co-occurrence graphs (WCGs), encoded by graph neural networks, to express in-depth semantic correlation and irrelevance among words. Based on the DWBG and WCGs, we design the document-word information propagation (DWIP) process to perform the edge perturbation of DWBG, based on multi-hop correlations/irrelevance among documents and words. This yields the desired negative and positive samples, which will be utilized for GCL together with the prototypes to improve learning document topic representations and latent topics. We further show that GCL can be interpreted as the structured variational graph auto-encoder which maximizes the mutual information of latent topic representations of different perspectives on DWBG. Experiments on several benchmark datasets demonstrate the effectiveness of our method for topic coherence and document representation learning compared with existing SOTA methods.