 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multiobjective Hydropower Reservoir Operation Optimization with Transformer-Based Deep Reinforcement Learning
Jul 11, 2023
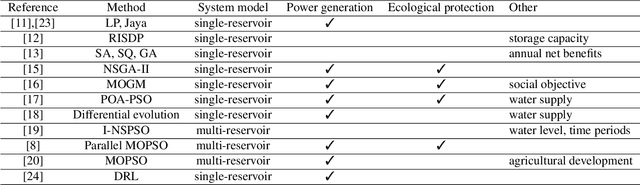
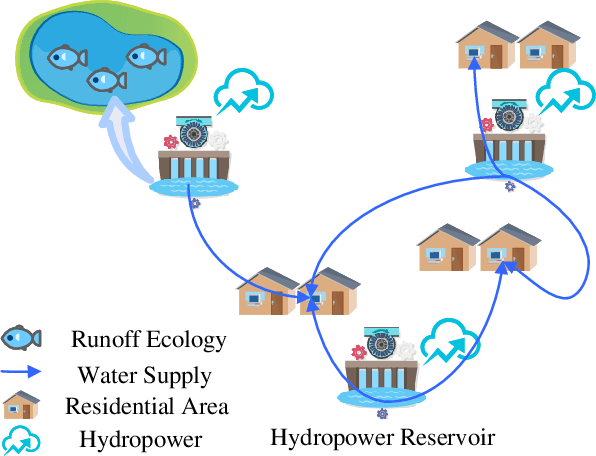


Due to shortage of water resources and increasing water demands, the joint operation of multireservoir systems for balancing power generation, ecological protection, and the residential water supply has become a critical issue in hydropower management. However, the numerous constraints and nonlinearity of multiple reservoirs make solving this problem time-consuming. To address this challenge, a deep reinforcement learning approach that incorporates a transformer framework is proposed. The multihead attention mechanism of the encoder effectively extracts information from reservoirs and residential areas, and the multireservoir attention network of the decoder generates suitable operational decisions. The proposed method is applied to Lake Mead and Lake Powell in the Colorado River Basin. The experimental results demonstrate that the transformer-based deep reinforcement learning approach can produce appropriate operational outcomes. Compared to a state-of-the-art method, the operation strategies produced by the proposed approach generate 10.11% more electricity, reduce the amended annual proportional flow deviation by 39.69%, and increase water supply revenue by 4.10%. Consequently, the proposed approach offers an effective method for the multiobjective operation of multihydropower reservoir systems.
Emotion-Guided Music Accompaniment Generation Based on Variational Autoencoder
Jul 08, 2023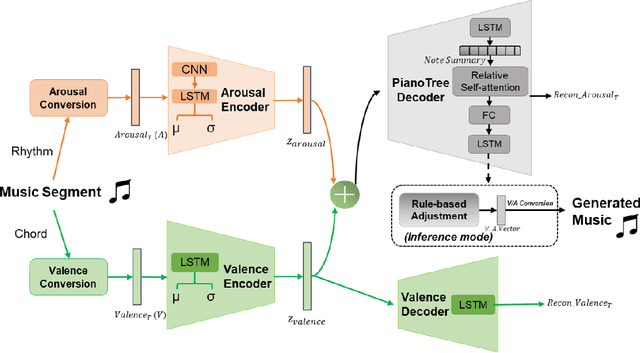
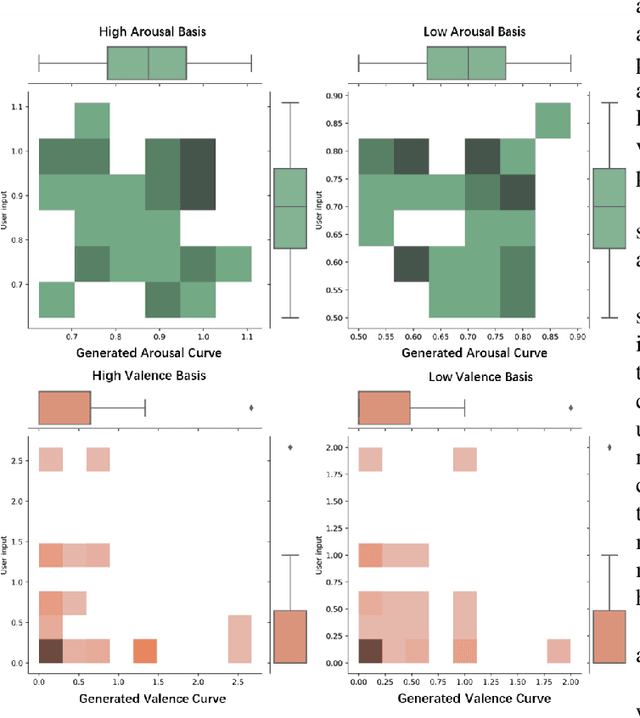
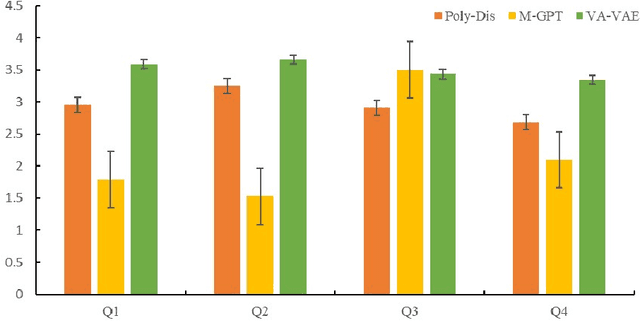
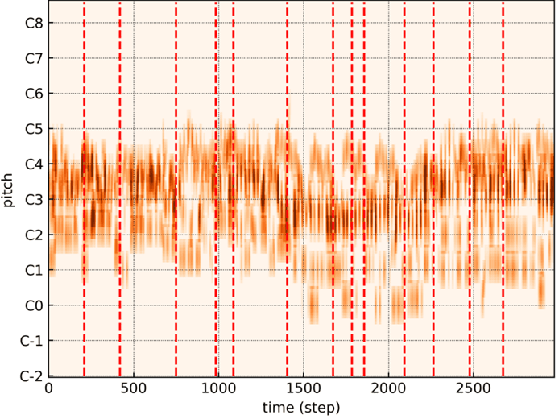
Music accompaniment generation is a crucial aspect in the composition process. Deep neural networks have made significant strides in this field, but it remains a challenge for AI to effectively incorporate human emotions to create beautiful accompaniments. Existing models struggle to effectively characterize human emotions within neural network models while composing music. To address this issue, we propose the use of an easy-to-represent emotion flow model, the Valence/Arousal Curve, which allows for the compatibility of emotional information within the model through data transformation and enhances interpretability of emotional factors by utilizing a Variational Autoencoder as the model structure. Further, we used relative self-attention to maintain the structure of the music at music phrase level and to generate a richer accompaniment when combined with the rules of music theory.
Embedding Mental Health Discourse for Community Recommendation
Jul 08, 2023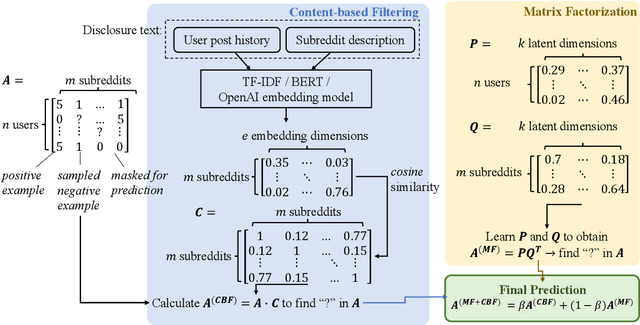
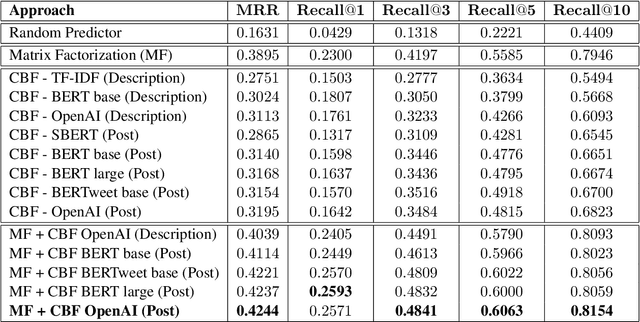

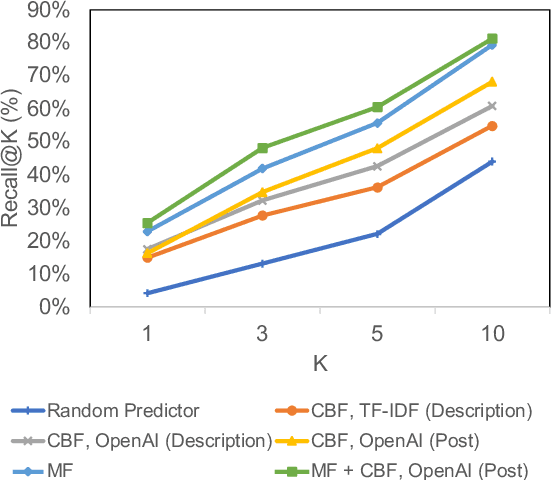
Our paper investigates the use of discourse embedding techniques to develop a community recommendation system that focuses on mental health support groups on social media. Social media platforms provide a means for users to anonymously connect with communities that cater to their specific interests. However, with the vast number of online communities available, users may face difficulties in identifying relevant groups to address their mental health concerns. To address this challenge, we explore the integration of discourse information from various subreddit communities using embedding techniques to develop an effective recommendation system. Our approach involves the use of content-based and collaborative filtering techniques to enhance the performance of the recommendation system. Our findings indicate that the proposed approach outperforms the use of each technique separately and provides interpretability in the recommendation process.
VELMA: Verbalization Embodiment of LLM Agents for Vision and Language Navigation in Street View
Jul 12, 2023
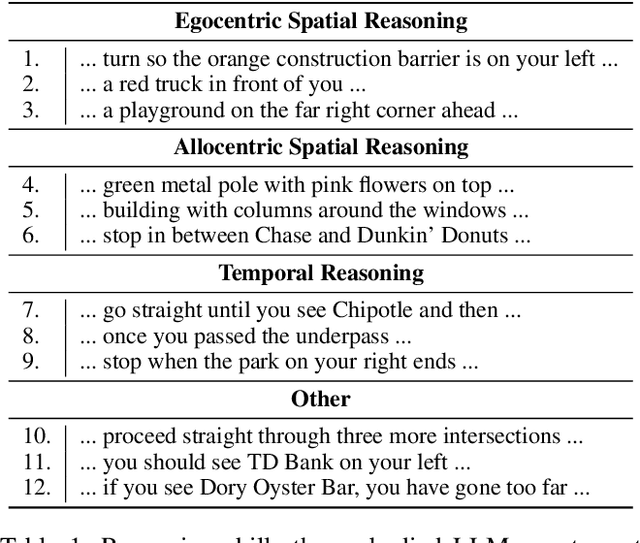
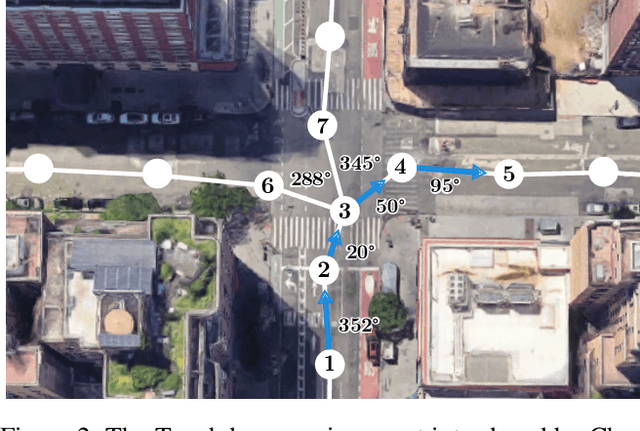
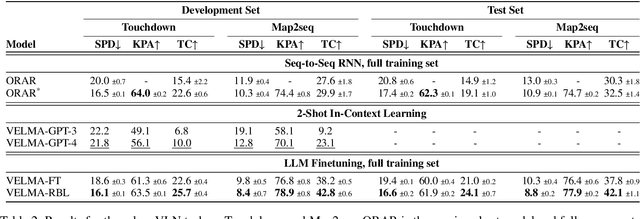
Incremental decision making in real-world environments is one of the most challenging tasks in embodied artificial intelligence. One particularly demanding scenario is Vision and Language Navigation~(VLN) which requires visual and natural language understanding as well as spatial and temporal reasoning capabilities. The embodied agent needs to ground its understanding of navigation instructions in observations of a real-world environment like Street View. Despite the impressive results of LLMs in other research areas, it is an ongoing problem of how to best connect them with an interactive visual environment. In this work, we propose VELMA, an embodied LLM agent that uses a verbalization of the trajectory and of visual environment observations as contextual prompt for the next action. Visual information is verbalized by a pipeline that extracts landmarks from the human written navigation instructions and uses CLIP to determine their visibility in the current panorama view. We show that VELMA is able to successfully follow navigation instructions in Street View with only two in-context examples. We further finetune the LLM agent on a few thousand examples and achieve 25%-30% relative improvement in task completion over the previous state-of-the-art for two datasets.
Self-Adaptive Large Language Model (LLM)-Based Multiagent Systems
Jul 12, 2023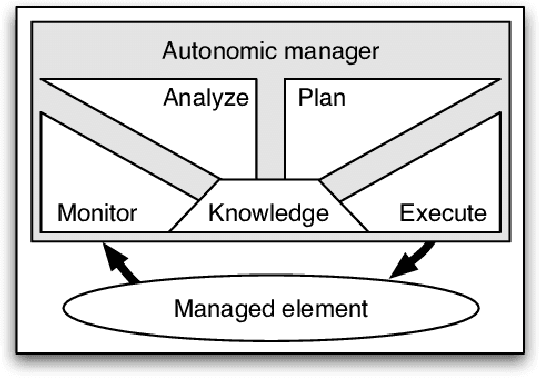
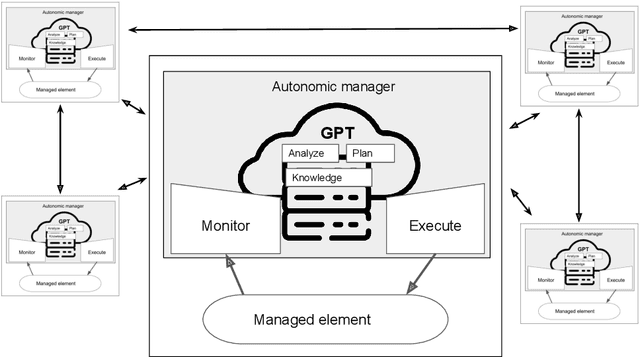
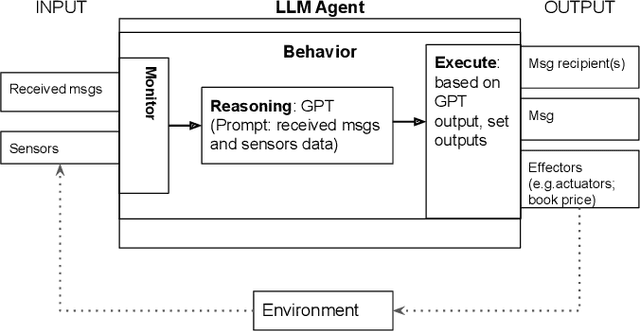
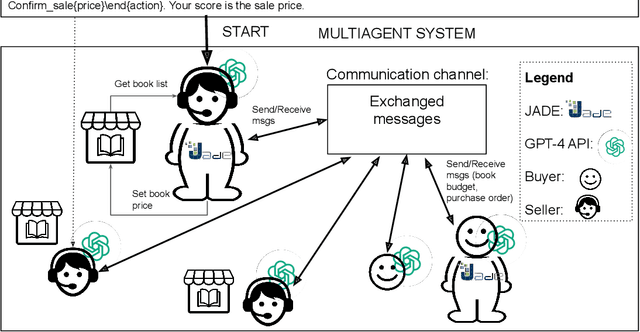
In autonomic computing, self-adaptation has been proposed as a fundamental paradigm to manage the complexity of multiagent systems (MASs). This achieved by extending a system with support to monitor and adapt itself to achieve specific concerns of interest. Communication in these systems is key given that in scenarios involving agent interaction, it enhances cooperation and reduces coordination challenges by enabling direct, clear information exchange. However, improving the expressiveness of the interaction communication with MASs is not without challenges. In this sense, the interplay between self-adaptive systems and effective communication is crucial for future MAS advancements. In this paper, we propose the integration of large language models (LLMs) such as GPT-based technologies into multiagent systems. We anchor our methodology on the MAPE-K model, which is renowned for its robust support in monitoring, analyzing, planning, and executing system adaptations in response to dynamic environments. We also present a practical illustration of the proposed approach, in which we implement and assess a basic MAS-based application. The approach significantly advances the state-of-the-art of self-adaptive systems by proposing a new paradigm for MAS self-adaptation of autonomous systems based on LLM capabilities.
Diversity-enhancing Generative Network for Few-shot Hypothesis Adaptation
Jul 12, 2023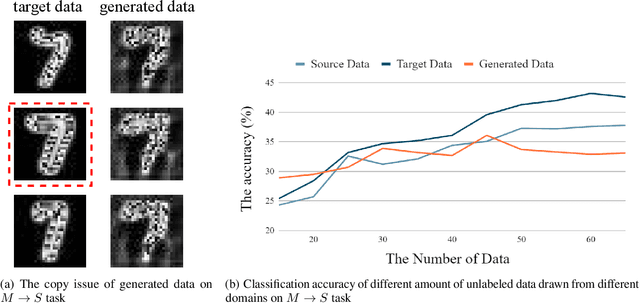
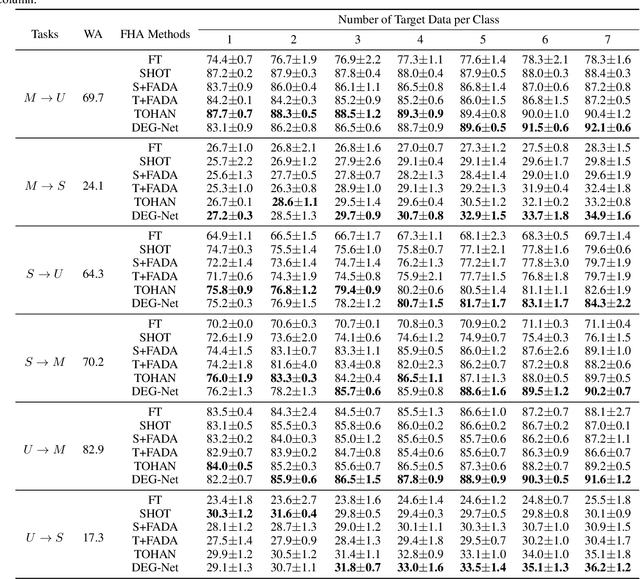
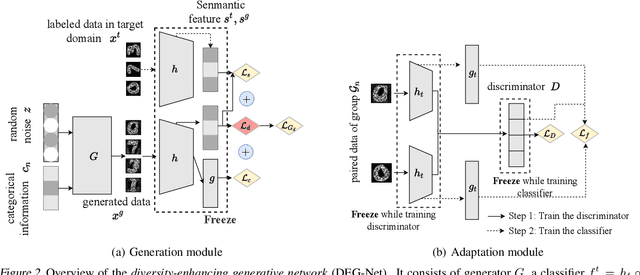

Generating unlabeled data has been recently shown to help address the few-shot hypothesis adaptation (FHA) problem, where we aim to train a classifier for the target domain with a few labeled target-domain data and a well-trained source-domain classifier (i.e., a source hypothesis), for the additional information of the highly-compatible unlabeled data. However, the generated data of the existing methods are extremely similar or even the same. The strong dependency among the generated data will lead the learning to fail. In this paper, we propose a diversity-enhancing generative network (DEG-Net) for the FHA problem, which can generate diverse unlabeled data with the help of a kernel independence measure: the Hilbert-Schmidt independence criterion (HSIC). Specifically, DEG-Net will generate data via minimizing the HSIC value (i.e., maximizing the independence) among the semantic features of the generated data. By DEG-Net, the generated unlabeled data are more diverse and more effective for addressing the FHA problem. Experimental results show that the DEG-Net outperforms existing FHA baselines and further verifies that generating diverse data plays a vital role in addressing the FHA problem
Locally Adaptive Federated Learning via Stochastic Polyak Stepsizes
Jul 12, 2023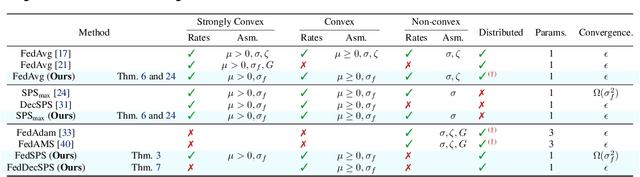
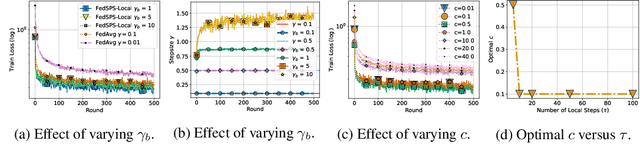
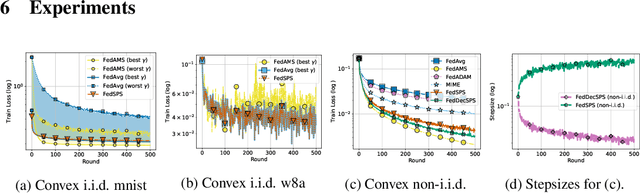

State-of-the-art federated learning algorithms such as FedAvg require carefully tuned stepsizes to achieve their best performance. The improvements proposed by existing adaptive federated methods involve tuning of additional hyperparameters such as momentum parameters, and consider adaptivity only in the server aggregation round, but not locally. These methods can be inefficient in many practical scenarios because they require excessive tuning of hyperparameters and do not capture local geometric information. In this work, we extend the recently proposed stochastic Polyak stepsize (SPS) to the federated learning setting, and propose new locally adaptive and nearly parameter-free distributed SPS variants (FedSPS and FedDecSPS). We prove that FedSPS converges linearly in strongly convex and sublinearly in convex settings when the interpolation condition (overparametrization) is satisfied, and converges to a neighborhood of the solution in the general case. We extend our proposed method to a decreasing stepsize version FedDecSPS, that converges also when the interpolation condition does not hold. We validate our theoretical claims by performing illustrative convex experiments. Our proposed algorithms match the optimization performance of FedAvg with the best tuned hyperparameters in the i.i.d. case, and outperform FedAvg in the non-i.i.d. case.
Test-Time Training on Video Streams
Jul 12, 2023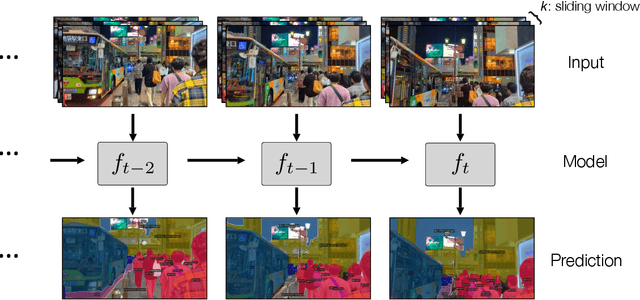
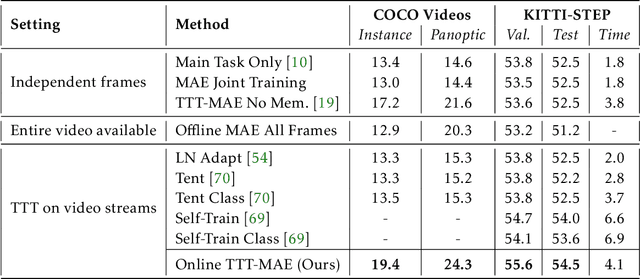
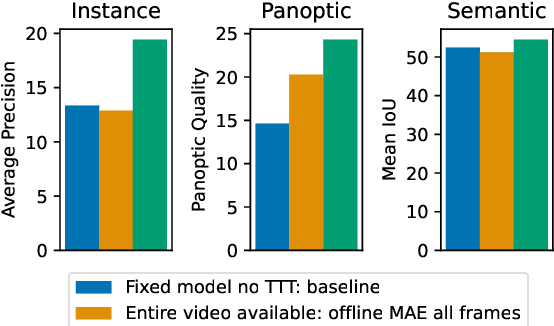
Prior work has established test-time training (TTT) as a general framework to further improve a trained model at test time. Before making a prediction on each test instance, the model is trained on the same instance using a self-supervised task, such as image reconstruction with masked autoencoders. We extend TTT to the streaming setting, where multiple test instances - video frames in our case - arrive in temporal order. Our extension is online TTT: The current model is initialized from the previous model, then trained on the current frame and a small window of frames immediately before. Online TTT significantly outperforms the fixed-model baseline for four tasks, on three real-world datasets. The relative improvement is 45% and 66% for instance and panoptic segmentation. Surprisingly, online TTT also outperforms its offline variant that accesses more information, training on all frames from the entire test video regardless of temporal order. This differs from previous findings using synthetic videos. We conceptualize locality as the advantage of online over offline TTT. We analyze the role of locality with ablations and a theory based on bias-variance trade-off.
Weakly-supervised positional contrastive learning: application to cirrhosis classification
Jul 12, 2023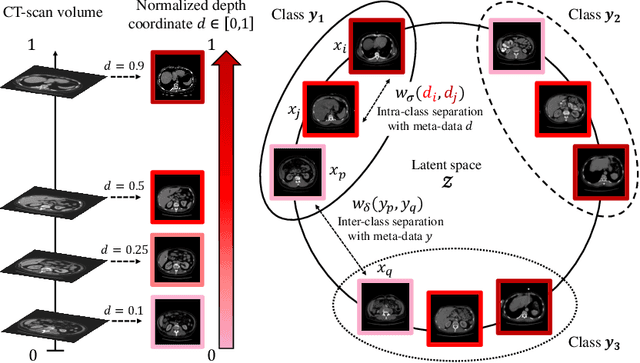
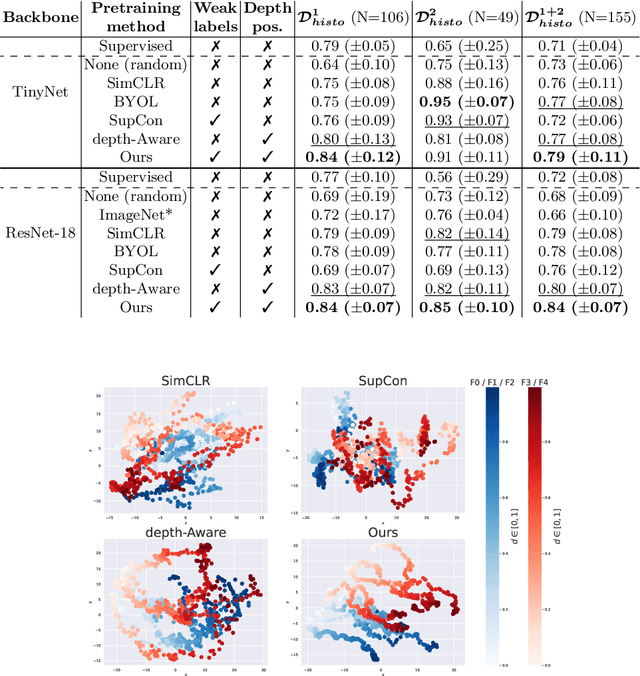
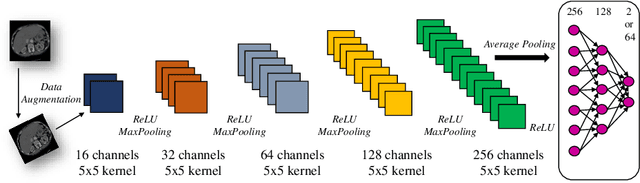
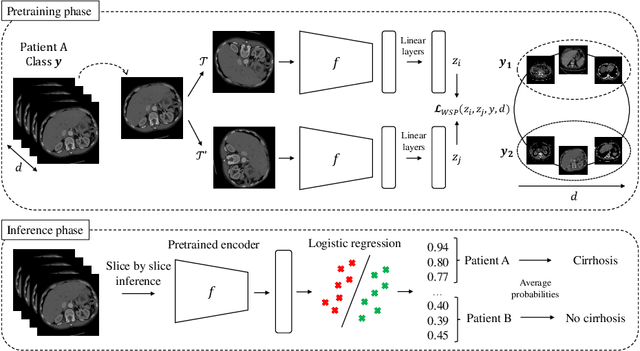
Large medical imaging datasets can be cheaply and quickly annotated with low-confidence, weak labels (e.g., radiological scores). Access to high-confidence labels, such as histology-based diagnoses, is rare and costly. Pretraining strategies, like contrastive learning (CL) methods, can leverage unlabeled or weakly-annotated datasets. These methods typically require large batch sizes, which poses a difficulty in the case of large 3D images at full resolution, due to limited GPU memory. Nevertheless, volumetric positional information about the spatial context of each 2D slice can be very important for some medical applications. In this work, we propose an efficient weakly-supervised positional (WSP) contrastive learning strategy where we integrate both the spatial context of each 2D slice and a weak label via a generic kernel-based loss function. We illustrate our method on cirrhosis prediction using a large volume of weakly-labeled images, namely radiological low-confidence annotations, and small strongly-labeled (i.e., high-confidence) datasets. The proposed model improves the classification AUC by 5% with respect to a baseline model on our internal dataset, and by 26% on the public LIHC dataset from the Cancer Genome Atlas. The code is available at: https://github.com/Guerbet-AI/wsp-contrastive.
Synthesizing Artistic Cinemagraphs from Text
Jul 12, 2023
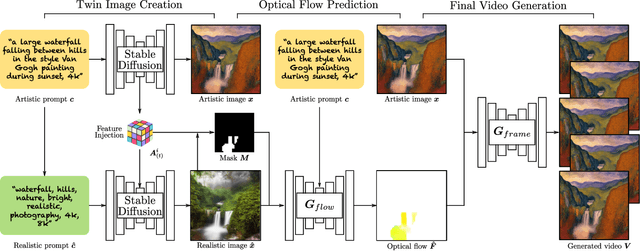


We introduce Text2Cinemagraph, a fully automated method for creating cinemagraphs from text descriptions - an especially challenging task when prompts feature imaginary elements and artistic styles, given the complexity of interpreting the semantics and motions of these images. Existing single-image animation methods fall short on artistic inputs, and recent text-based video methods frequently introduce temporal inconsistencies, struggling to keep certain regions static. To address these challenges, we propose an idea of synthesizing image twins from a single text prompt - a pair of an artistic image and its pixel-aligned corresponding natural-looking twin. While the artistic image depicts the style and appearance detailed in our text prompt, the realistic counterpart greatly simplifies layout and motion analysis. Leveraging existing natural image and video datasets, we can accurately segment the realistic image and predict plausible motion given the semantic information. The predicted motion can then be transferred to the artistic image to create the final cinemagraph. Our method outperforms existing approaches in creating cinemagraphs for natural landscapes as well as artistic and other-worldly scenes, as validated by automated metrics and user studies. Finally, we demonstrate two extensions: animating existing paintings and controlling motion directions using text.