 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
3D-Speaker: A Large-Scale Multi-Device, Multi-Distance, and Multi-Dialect Corpus for Speech Representation Disentanglement
Jun 28, 2023

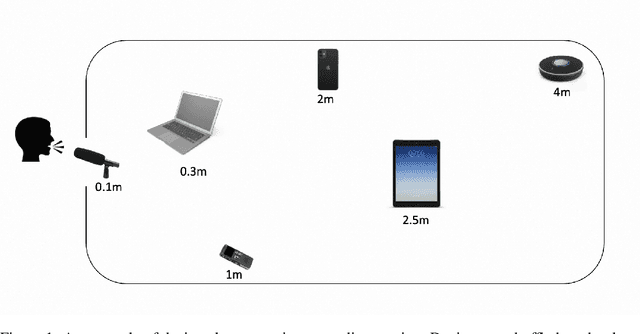
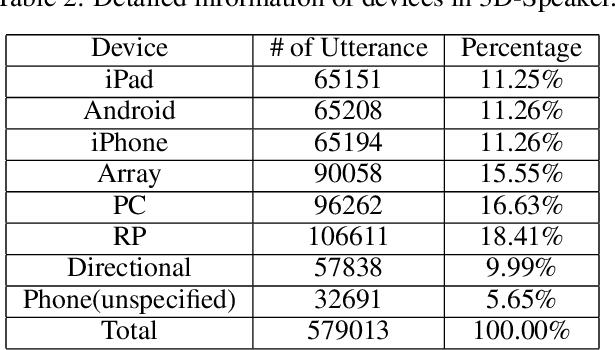
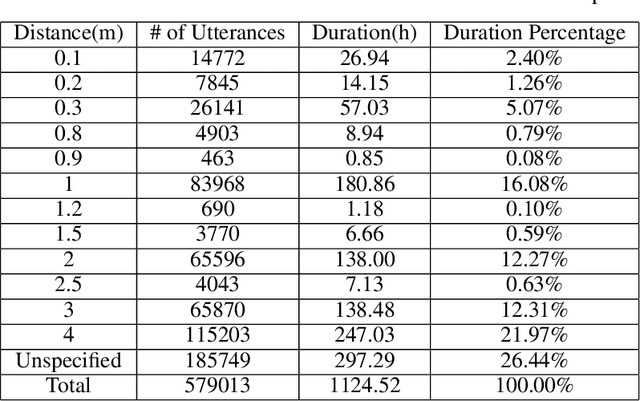
Disentangling uncorrelated information in speech utterances is a crucial research topic within speech community. Different speech-related tasks focus on extracting distinct speech representations while minimizing the affects of other uncorrelated information. We present a large-scale speech corpus to facilitate the research of speech representation disentanglement. 3D-Speaker contains over 10,000 speakers, each of whom are simultaneously recorded by multiple Devices, locating at different Distances, and some speakers are speaking multiple Dialects. The controlled combinations of multi-dimensional audio data yield a matrix of a diverse blend of speech representation entanglement, thereby motivating intriguing methods to untangle them. The multi-domain nature of 3D-Speaker also makes it a suitable resource to evaluate large universal speech models and experiment methods of out-of-domain learning and self-supervised learning. https://3dspeaker.github.io/
Task-Oriented Semantics-Aware Communication for Wireless UAV Control and Command Transmission
Jun 25, 2023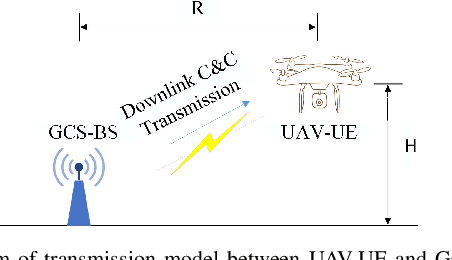
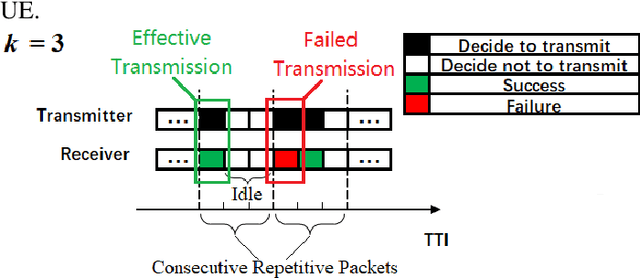
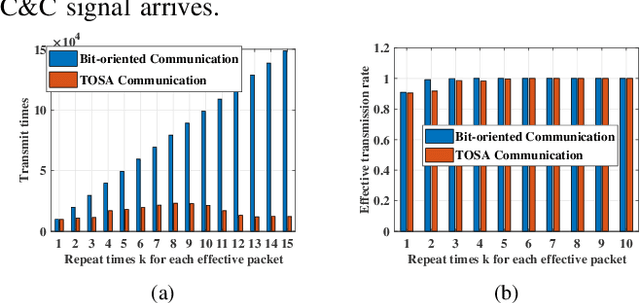
To guarantee the safety and smooth control of Unmanned Aerial Vehicle (UAV) operation, the new control and command (C&C) data type imposes stringent quality of service (QoS) requirements on the cellular network. However, the existing bit-oriented communication framework is already approaching the Shannon capacity limit, which can hardly guarantee the ultra-reliable low latency communications (URLLC) service for C&C transmission. To solve the problem, task-oriented semantics-aware (TOSA) communication has been proposed recently by jointly exploiting the context of data and its importance to the UAV control task. However, to the best of our knowledge, an explicit and systematic TOSA communication framework for emerging C&C data type remains unknown. Therefore, in this paper, we propose a TOSA communication framework for C&C transmission and define its value of information based on both the similarity and age of information (AoI) of C&C signals. We also propose a deep reinforcement learning (DRL) algorithm to maximize the TOSA information. Last but not least, we present the simulation results to validate the effectiveness of our proposed TOSA communication framework.
Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery
Apr 26, 2023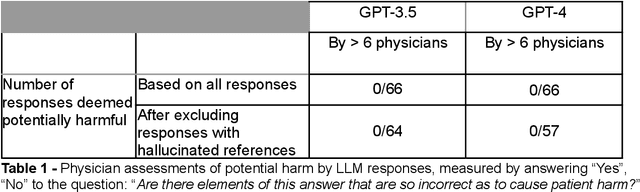
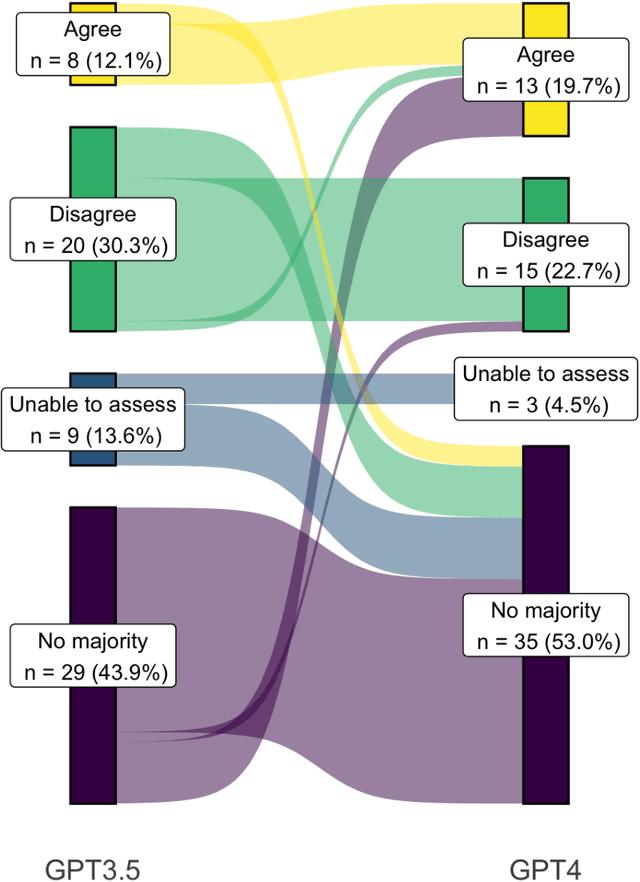
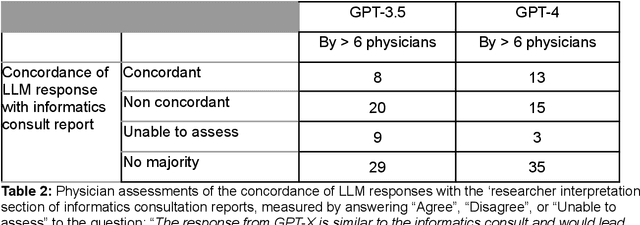
Despite growing interest in using large language models (LLMs) in healthcare, current explorations do not assess the real-world utility and safety of LLMs in clinical settings. Our objective was to determine whether two LLMs can serve information needs submitted by physicians as questions to an informatics consultation service in a safe and concordant manner. Sixty six questions from an informatics consult service were submitted to GPT-3.5 and GPT-4 via simple prompts. 12 physicians assessed the LLM responses' possibility of patient harm and concordance with existing reports from an informatics consultation service. Physician assessments were summarized based on majority vote. For no questions did a majority of physicians deem either LLM response as harmful. For GPT-3.5, responses to 8 questions were concordant with the informatics consult report, 20 discordant, and 9 were unable to be assessed. There were 29 responses with no majority on "Agree", "Disagree", and "Unable to assess". For GPT-4, responses to 13 questions were concordant, 15 discordant, and 3 were unable to be assessed. There were 35 responses with no majority. Responses from both LLMs were largely devoid of overt harm, but less than 20% of the responses agreed with an answer from an informatics consultation service, responses contained hallucinated references, and physicians were divided on what constitutes harm. These results suggest that while general purpose LLMs are able to provide safe and credible responses, they often do not meet the specific information need of a given question. A definitive evaluation of the usefulness of LLMs in healthcare settings will likely require additional research on prompt engineering, calibration, and custom-tailoring of general purpose models.
ChatGPT vs. Google: A Comparative Study of Search Performance and User Experience
Jul 03, 2023
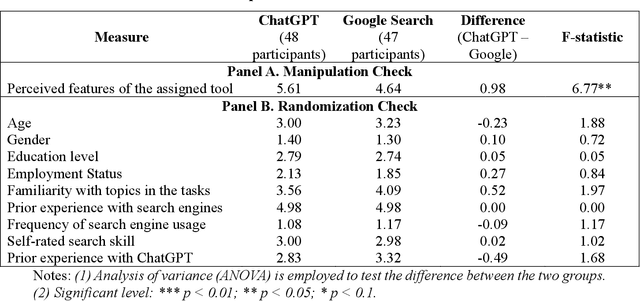
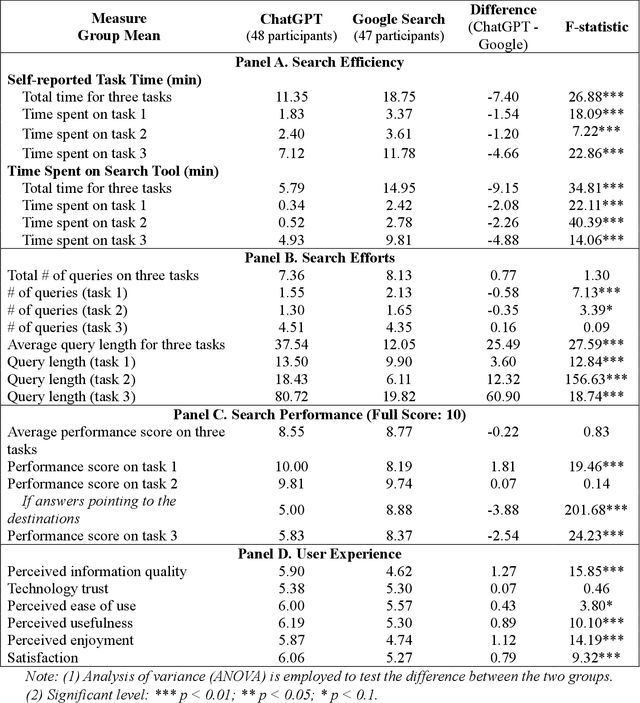
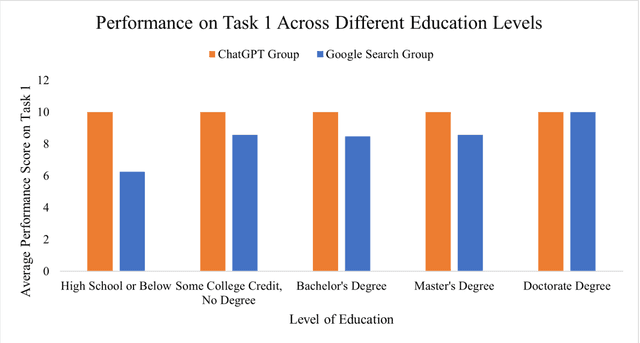
The advent of ChatGPT, a large language model-powered chatbot, has prompted questions about its potential implications for traditional search engines. In this study, we investigate the differences in user behavior when employing search engines and chatbot tools for information-seeking tasks. We carry out a randomized online experiment, dividing participants into two groups: one using a ChatGPT-like tool and the other using a Google Search-like tool. Our findings reveal that the ChatGPT group consistently spends less time on all tasks, with no significant difference in overall task performance between the groups. Notably, ChatGPT levels user search performance across different education levels and excels in answering straightforward questions and providing general solutions but falls short in fact-checking tasks. Users perceive ChatGPT's responses as having higher information quality compared to Google Search, despite displaying a similar level of trust in both tools. Furthermore, participants using ChatGPT report significantly better user experiences in terms of usefulness, enjoyment, and satisfaction, while perceived ease of use remains comparable between the two tools. However, ChatGPT may also lead to overreliance and generate or replicate misinformation, yielding inconsistent results. Our study offers valuable insights for search engine management and highlights opportunities for integrating chatbot technologies into search engine designs.
UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding
Jul 03, 2023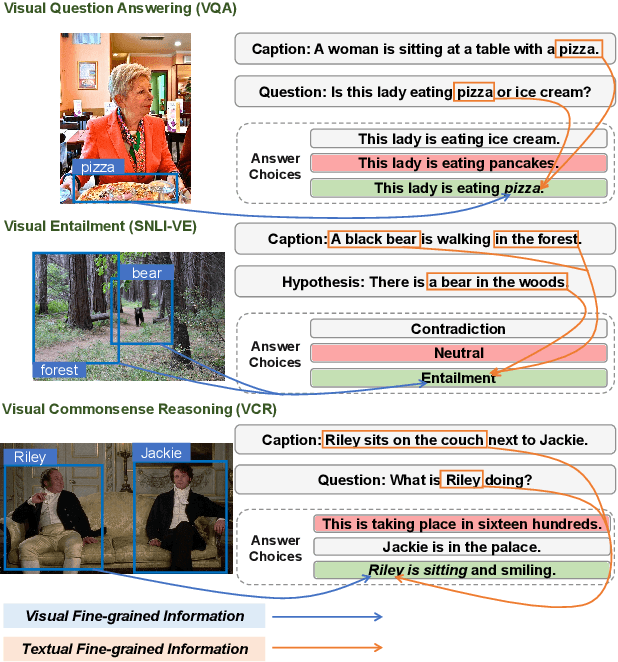
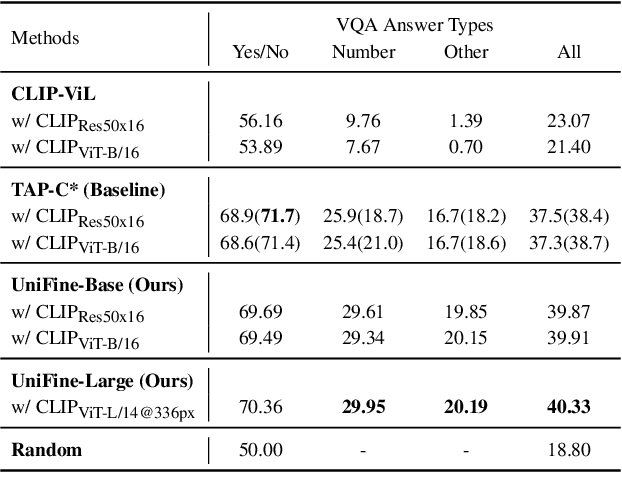
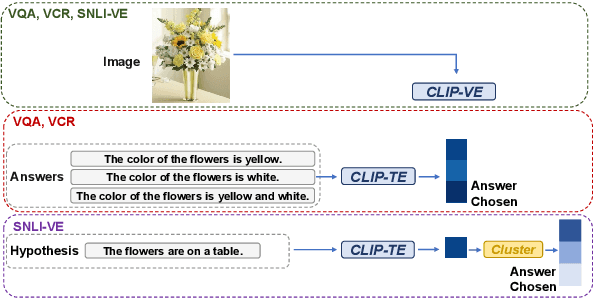
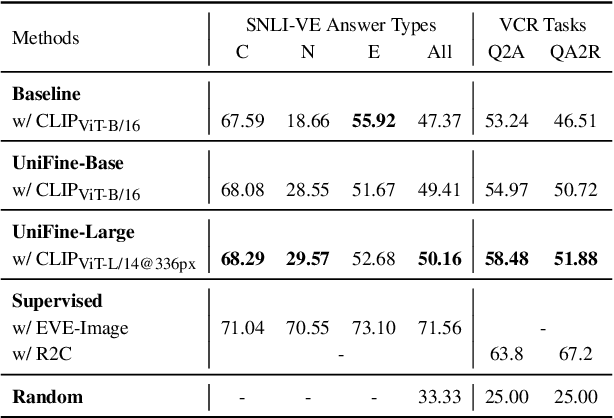
Vision-language tasks, such as VQA, SNLI-VE, and VCR are challenging because they require the model's reasoning ability to understand the semantics of the visual world and natural language. Supervised methods working for vision-language tasks have been well-studied. However, solving these tasks in a zero-shot setting is less explored. Since Contrastive Language-Image Pre-training (CLIP) has shown remarkable zero-shot performance on image-text matching, previous works utilized its strong zero-shot ability by converting vision-language tasks into an image-text matching problem, and they mainly consider global-level matching (e.g., the whole image or sentence). However, we find visual and textual fine-grained information, e.g., keywords in the sentence and objects in the image, can be fairly informative for semantics understanding. Inspired by this, we propose a unified framework to take advantage of the fine-grained information for zero-shot vision-language learning, covering multiple tasks such as VQA, SNLI-VE, and VCR. Our experiments show that our framework outperforms former zero-shot methods on VQA and achieves substantial improvement on SNLI-VE and VCR. Furthermore, our ablation studies confirm the effectiveness and generalizability of our proposed method. Code will be available at https://github.com/ThreeSR/UniFine
Efficient Visual Fault Detection for Freight Train Braking System via Heterogeneous Self Distillation in the Wild
Jul 03, 2023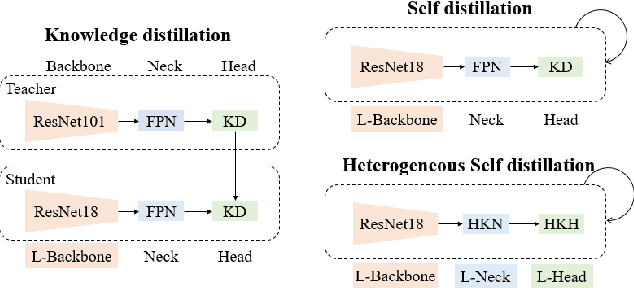
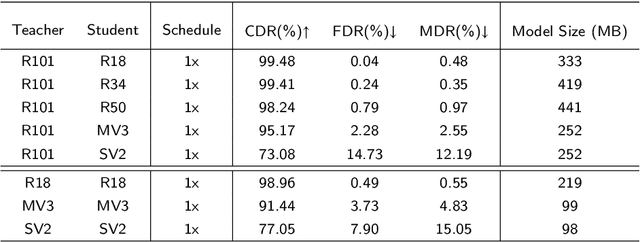
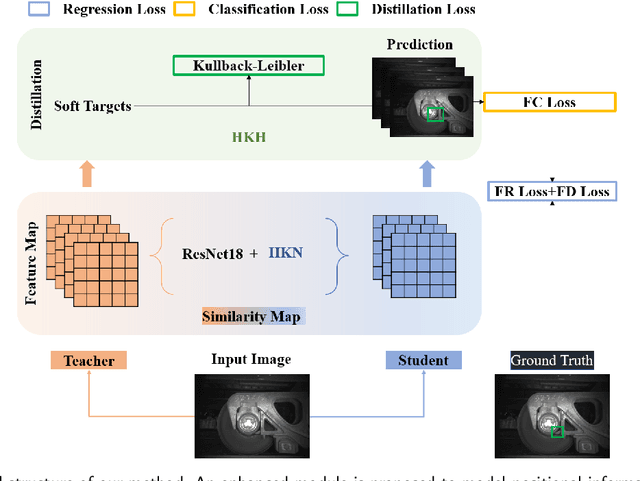
Efficient visual fault detection of freight trains is a critical part of ensuring the safe operation of railways under the restricted hardware environment. Although deep learning-based approaches have excelled in object detection, the efficiency of freight train fault detection is still insufficient to apply in real-world engineering. This paper proposes a heterogeneous self-distillation framework to ensure detection accuracy and speed while satisfying low resource requirements. The privileged information in the output feature knowledge can be transferred from the teacher to the student model through distillation to boost performance. We first adopt a lightweight backbone to extract features and generate a new heterogeneous knowledge neck. Such neck models positional information and long-range dependencies among channels through parallel encoding to optimize feature extraction capabilities. Then, we utilize the general distribution to obtain more credible and accurate bounding box estimates. Finally, we employ a novel loss function that makes the network easily concentrate on values near the label to improve learning efficiency. Experiments on four fault datasets reveal that our framework can achieve over 37 frames per second and maintain the highest accuracy in comparison with traditional distillation approaches. Moreover, compared to state-of-the-art methods, our framework demonstrates more competitive performance with lower memory usage and the smallest model size.
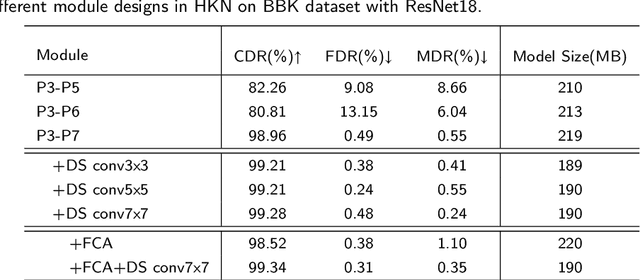
Complementary Frequency-Varying Awareness Network for Open-Set Fine-Grained Image Recognition
Jul 14, 2023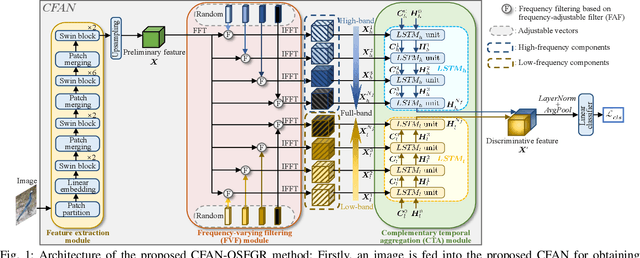
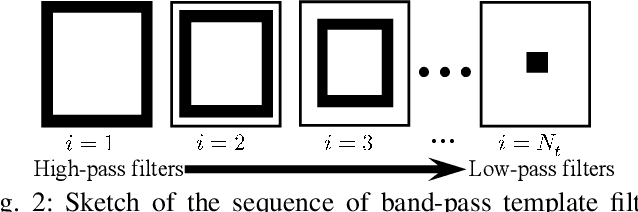
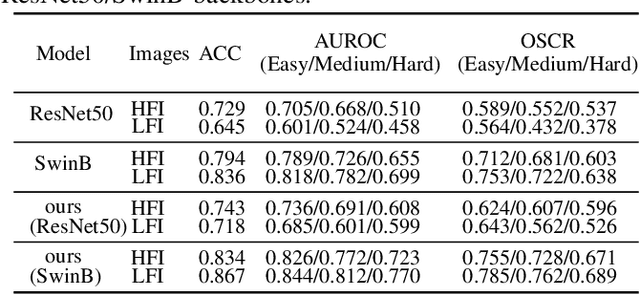
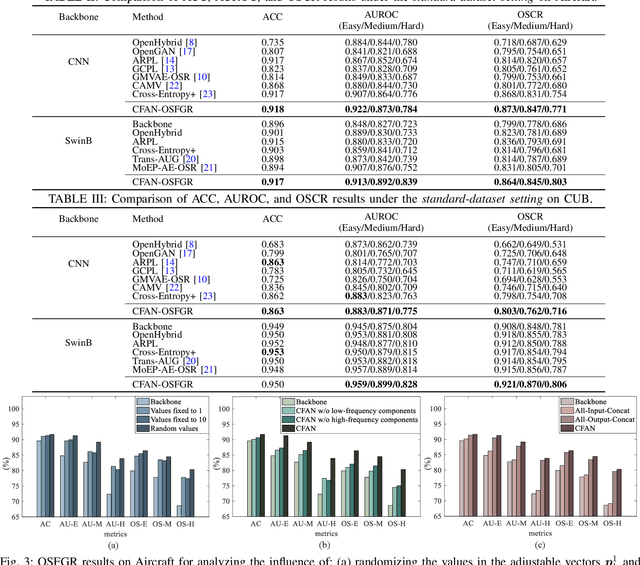
Open-set image recognition is a challenging topic in computer vision. Most of the existing works in literature focus on learning more discriminative features from the input images, however, they are usually insensitive to the high- or low-frequency components in features, resulting in a decreasing performance on fine-grained image recognition. To address this problem, we propose a Complementary Frequency-varying Awareness Network that could better capture both high-frequency and low-frequency information, called CFAN. The proposed CFAN consists of three sequential modules: (i) a feature extraction module is introduced for learning preliminary features from the input images; (ii) a frequency-varying filtering module is designed to separate out both high- and low-frequency components from the preliminary features in the frequency domain via a frequency-adjustable filter; (iii) a complementary temporal aggregation module is designed for aggregating the high- and low-frequency components via two Long Short-Term Memory networks into discriminative features. Based on CFAN, we further propose an open-set fine-grained image recognition method, called CFAN-OSFGR, which learns image features via CFAN and classifies them via a linear classifier. Experimental results on 3 fine-grained datasets and 2 coarse-grained datasets demonstrate that CFAN-OSFGR performs significantly better than 9 state-of-the-art methods in most cases.
Learning Sparse Neural Networks with Identity Layers
Jul 14, 2023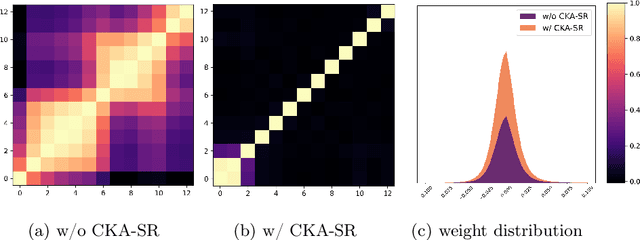
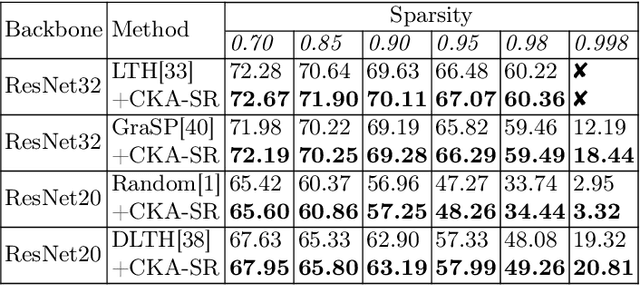
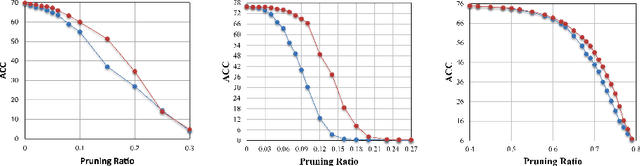
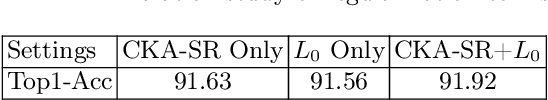
The sparsity of Deep Neural Networks is well investigated to maximize the performance and reduce the size of overparameterized networks as possible. Existing methods focus on pruning parameters in the training process by using thresholds and metrics. Meanwhile, feature similarity between different layers has not been discussed sufficiently before, which could be rigorously proved to be highly correlated to the network sparsity in this paper. Inspired by interlayer feature similarity in overparameterized models, we investigate the intrinsic link between network sparsity and interlayer feature similarity. Specifically, we prove that reducing interlayer feature similarity based on Centered Kernel Alignment (CKA) improves the sparsity of the network by using information bottleneck theory. Applying such theory, we propose a plug-and-play CKA-based Sparsity Regularization for sparse network training, dubbed CKA-SR, which utilizes CKA to reduce feature similarity between layers and increase network sparsity. In other words, layers of our sparse network tend to have their own identity compared to each other. Experimentally, we plug the proposed CKA-SR into the training process of sparse network training methods and find that CKA-SR consistently improves the performance of several State-Of-The-Art sparse training methods, especially at extremely high sparsity. Code is included in the supplementary materials.
SubT-MRS: A Subterranean, Multi-Robot, Multi-Spectral and Multi-Degraded Dataset for Robust SLAM
Jul 14, 2023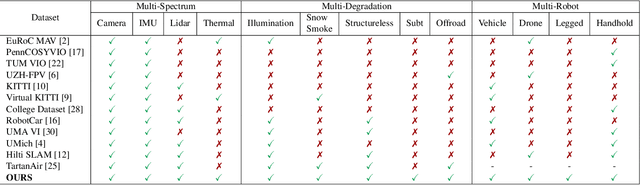

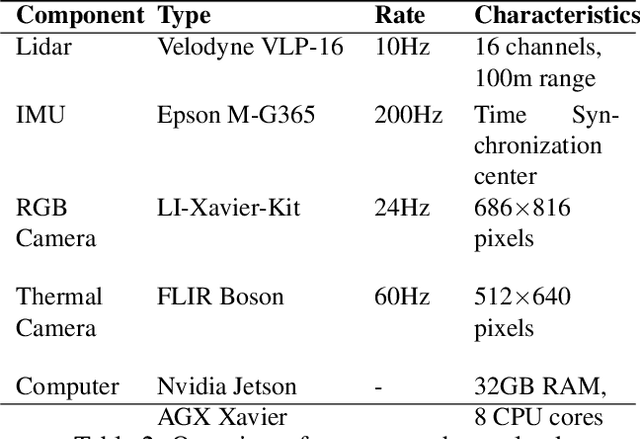

In recent years, significant progress has been made in the field of simultaneous localization and mapping (SLAM) research. However, current state-of-the-art solutions still struggle with limited accuracy and robustness in real-world applications. One major reason is the lack of datasets that fully capture the conditions faced by robots in the wild. To address this problem, we present SubT-MRS, an extremely challenging real-world dataset designed to push the limits of SLAM and perception algorithms. SubT-MRS is a multi-modal, multi-robot dataset collected mainly from subterranean environments having multi-degraded conditions including structureless corridors, varying lighting conditions, and perceptual obscurants such as smoke and dust. Furthermore, the dataset packages information from a diverse range of time-synchronized sensors, including LiDAR, visual cameras, thermal cameras, and IMUs captured using varied vehicular motions like aerial, legged, and wheeled, to support research in sensor fusion, which is essential for achieving accurate and robust robotic perception in complex environments. To evaluate the accuracy of SLAM systems, we also provide a dense 3D model with sub-centimeter-level accuracy, as well as accurate 6DoF ground truth. Our benchmarking approach includes several state-of-the-art methods to demonstrate the challenges our datasets introduce, particularly in the case of multi-degraded environments.
WaterScenes: A Multi-Task 4D Radar-Camera Fusion Dataset and Benchmark for Autonomous Driving on Water Surfaces
Jul 13, 2023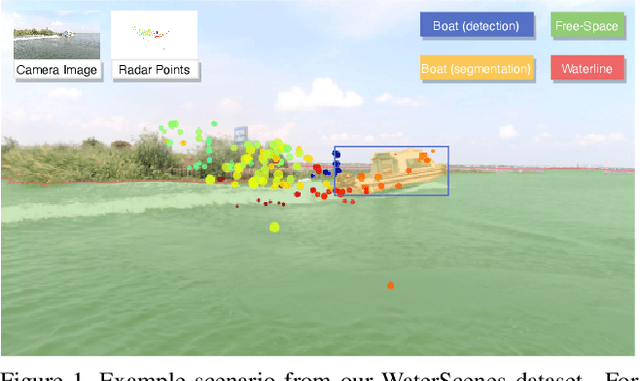
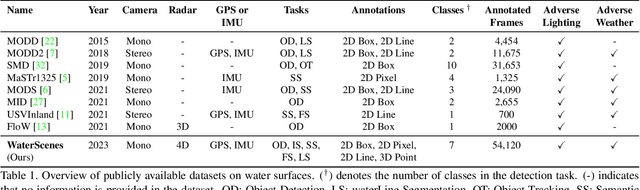


Autonomous driving on water surfaces plays an essential role in executing hazardous and time-consuming missions, such as maritime surveillance, survivors rescue, environmental monitoring, hydrography mapping and waste cleaning. This work presents WaterScenes, the first multi-task 4D radar-camera fusion dataset for autonomous driving on water surfaces. Equipped with a 4D radar and a monocular camera, our Unmanned Surface Vehicle (USV) proffers all-weather solutions for discerning object-related information, including color, shape, texture, range, velocity, azimuth, and elevation. Focusing on typical static and dynamic objects on water surfaces, we label the camera images and radar point clouds at pixel-level and point-level, respectively. In addition to basic perception tasks, such as object detection, instance segmentation and semantic segmentation, we also provide annotations for free-space segmentation and waterline segmentation. Leveraging the multi-task and multi-modal data, we conduct numerous experiments on the single modality of radar and camera, as well as the fused modalities. Results demonstrate that 4D radar-camera fusion can considerably enhance the robustness of perception on water surfaces, especially in adverse lighting and weather conditions. WaterScenes dataset is public on https://waterscenes.github.io.