 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the tightness of information-theoretic bounds on generalization error of learning algorithms
Mar 26, 2023
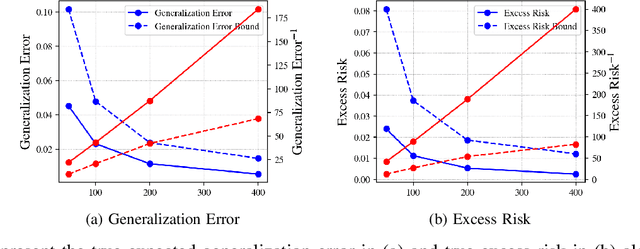

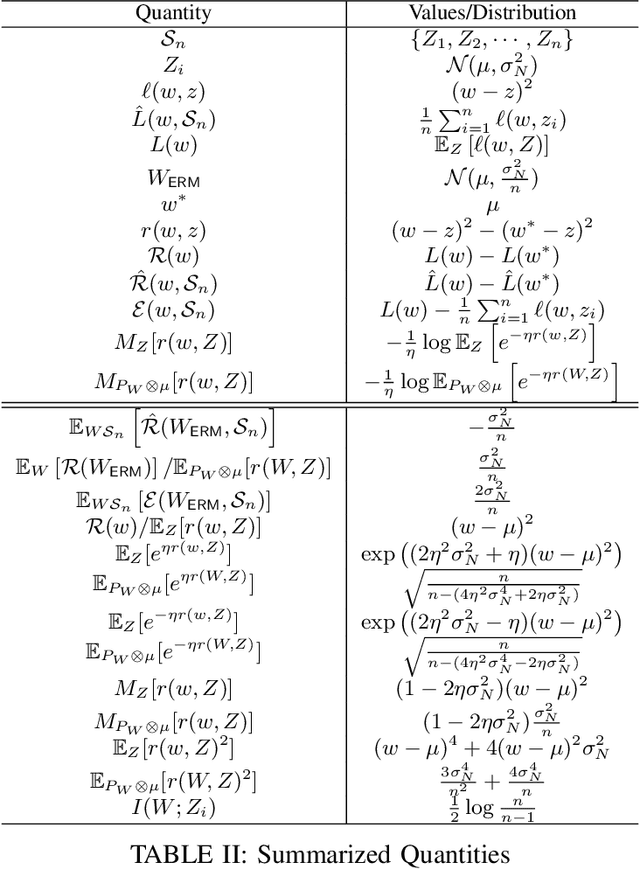
A recent line of works, initiated by Russo and Xu, has shown that the generalization error of a learning algorithm can be upper bounded by information measures. In most of the relevant works, the convergence rate of the expected generalization error is in the form of $O(\sqrt{\lambda/n})$ where $\lambda$ is some information-theoretic quantities such as the mutual information or conditional mutual information between the data and the learned hypothesis. However, such a learning rate is typically considered to be ``slow", compared to a ``fast rate" of $O(\lambda/n)$ in many learning scenarios. In this work, we first show that the square root does not necessarily imply a slow rate, and a fast rate result can still be obtained using this bound under appropriate assumptions. Furthermore, we identify the critical conditions needed for the fast rate generalization error, which we call the $(\eta,c)$-central condition. Under this condition, we give information-theoretic bounds on the generalization error and excess risk, with a fast convergence rate for specific learning algorithms such as empirical risk minimization and its regularized version. Finally, several analytical examples are given to show the effectiveness of the bounds.
DeepTagger: Knowledge Enhanced Named Entity Recognition for Web-Based Ads Queries
Jun 30, 2023

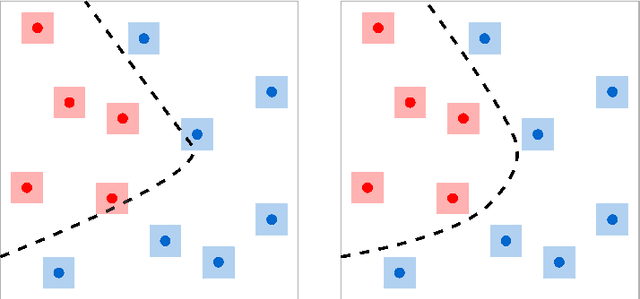
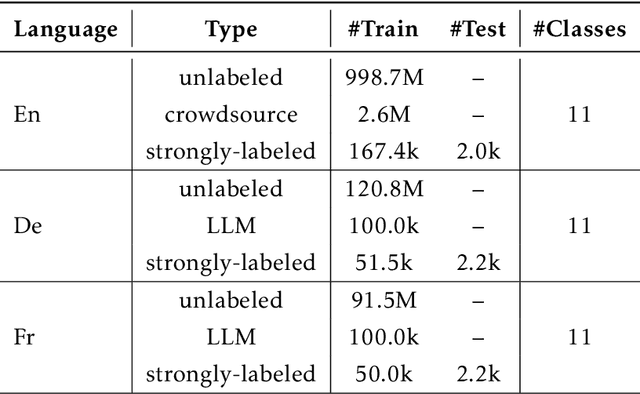
Named entity recognition (NER) is a crucial task for online advertisement. State-of-the-art solutions leverage pre-trained language models for this task. However, three major challenges remain unresolved: web queries differ from natural language, on which pre-trained models are trained; web queries are short and lack contextual information; and labeled data for NER is scarce. We propose DeepTagger, a knowledge-enhanced NER model for web-based ads queries. The proposed knowledge enhancement framework leverages both model-free and model-based approaches. For model-free enhancement, we collect unlabeled web queries to augment domain knowledge; and we collect web search results to enrich the information of ads queries. We further leverage effective prompting methods to automatically generate labels using large language models such as ChatGPT. Additionally, we adopt a model-based knowledge enhancement method based on adversarial data augmentation. We employ a three-stage training framework to train DeepTagger models. Empirical results in various NER tasks demonstrate the effectiveness of the proposed framework.
Removing confounding information from fetal ultrasound images
Mar 24, 2023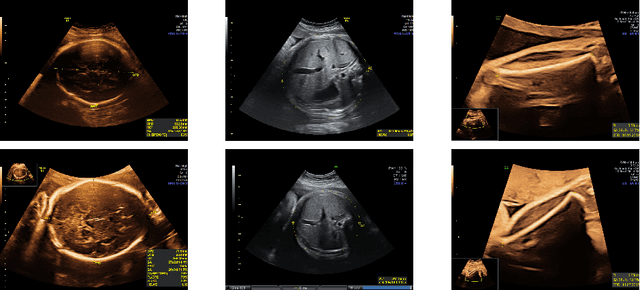
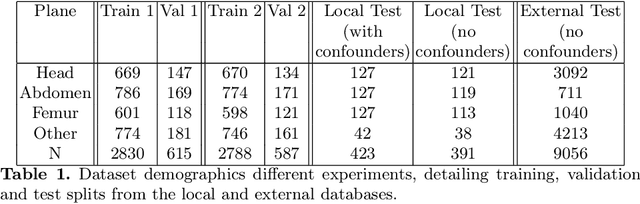

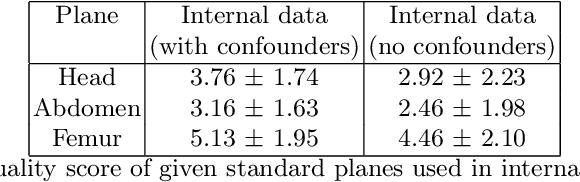
Confounding information in the form of text or markings embedded in medical images can severely affect the training of diagnostic deep learning algorithms. However, data collected for clinical purposes often have such markings embedded in them. In dermatology, known examples include drawings or rulers that are overrepresented in images of malignant lesions. In this paper, we encounter text and calipers placed on the images found in national databases containing fetal screening ultrasound scans, which correlate with standard planes to be predicted. In order to utilize the vast amounts of data available in these databases, we develop and validate a series of methods for minimizing the confounding effects of embedded text and calipers on deep learning algorithms designed for ultrasound, using standard plane classification as a test case.
Effective Matching of Patients to Clinical Trials using Entity Extraction and Neural Re-ranking
Jul 01, 2023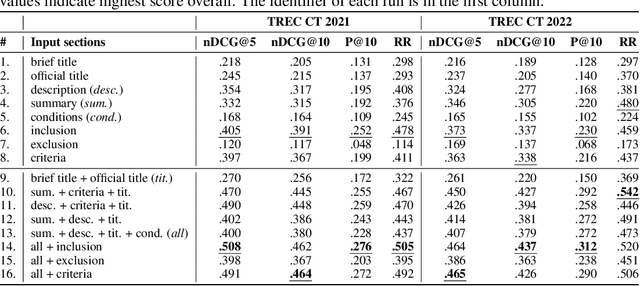
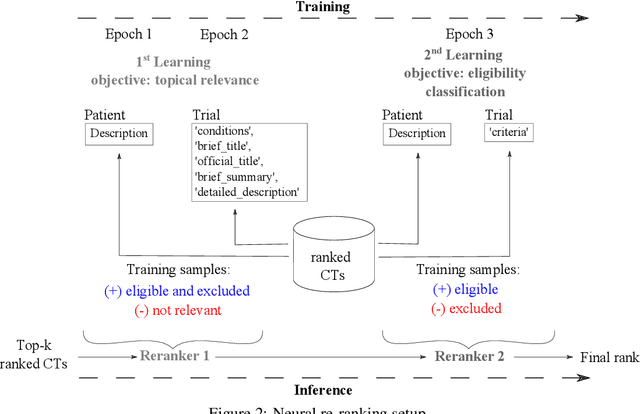
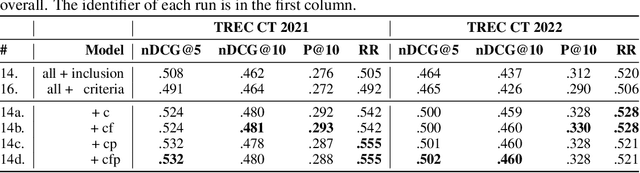
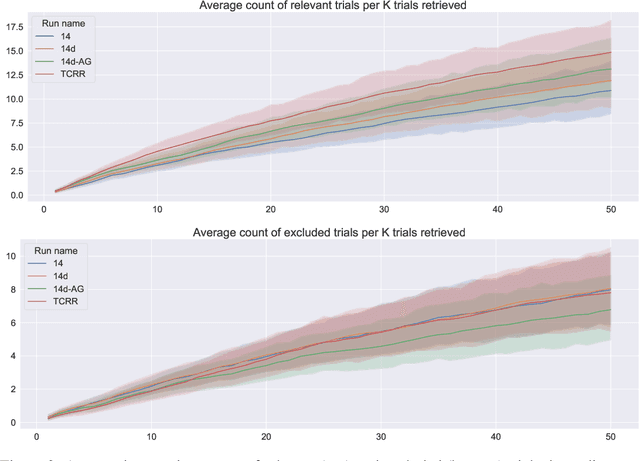
Clinical trials (CTs) often fail due to inadequate patient recruitment. This paper tackles the challenges of CT retrieval by presenting an approach that addresses the patient-to-trials paradigm. Our approach involves two key components in a pipeline-based model: (i) a data enrichment technique for enhancing both queries and documents during the first retrieval stage, and (ii) a novel re-ranking schema that uses a Transformer network in a setup adapted to this task by leveraging the structure of the CT documents. We use named entity recognition and negation detection in both patient description and the eligibility section of CTs. We further classify patient descriptions and CT eligibility criteria into current, past, and family medical conditions. This extracted information is used to boost the importance of disease and drug mentions in both query and index for lexical retrieval. Furthermore, we propose a two-step training schema for the Transformer network used to re-rank the results from the lexical retrieval. The first step focuses on matching patient information with the descriptive sections of trials, while the second step aims to determine eligibility by matching patient information with the criteria section. Our findings indicate that the inclusion criteria section of the CT has a great influence on the relevance score in lexical models, and that the enrichment techniques for queries and documents improve the retrieval of relevant trials. The re-ranking strategy, based on our training schema, consistently enhances CT retrieval and shows improved performance by 15\% in terms of precision at retrieving eligible trials. The results of our experiments suggest the benefit of making use of extracted entities. Moreover, our proposed re-ranking schema shows promising effectiveness compared to larger neural models, even with limited training data.
Multi-Channel Feature Extraction for Virtual Histological Staining of Photon Absorption Remote Sensing Images
Jul 04, 2023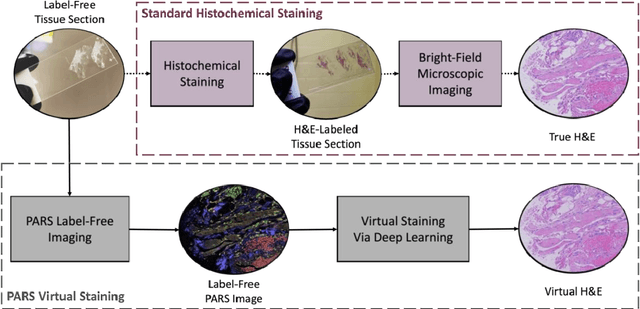
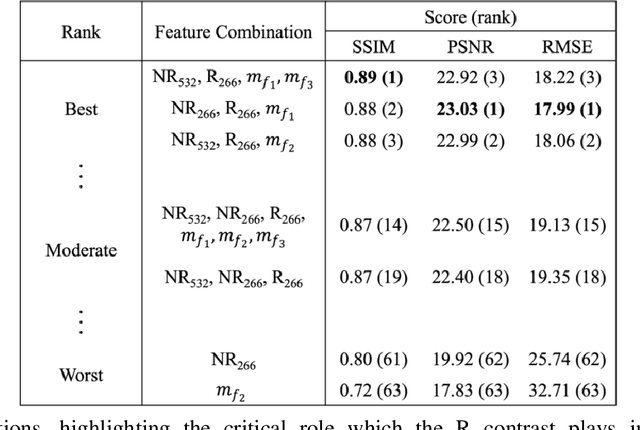
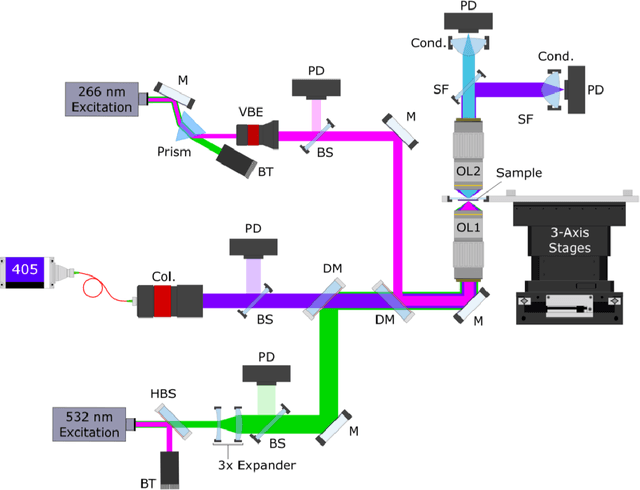
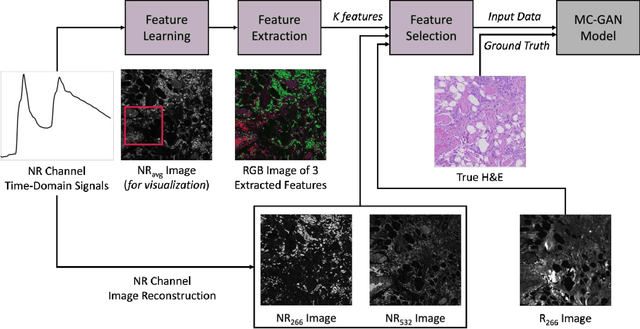
Accurate and fast histological staining is crucial in histopathology, impacting diagnostic precision and reliability. Traditional staining methods are time-consuming and subjective, causing delays in diagnosis. Digital pathology plays a vital role in advancing and optimizing histology processes to improve efficiency and reduce turnaround times. This study introduces a novel deep learning-based framework for virtual histological staining using photon absorption remote sensing (PARS) images. By extracting features from PARS time-resolved signals using a variant of the K-means method, valuable multi-modal information is captured. The proposed multi-channel cycleGAN (MC-GAN) model expands on the traditional cycleGAN framework, allowing the inclusion of additional features. Experimental results reveal that specific combinations of features outperform the conventional channels by improving the labeling of tissue structures prior to model training. Applied to human skin and mouse brain tissue, the results underscore the significance of choosing the optimal combination of features, as it reveals a substantial visual and quantitative concurrence between the virtually stained and the gold standard chemically stained hematoxylin and eosin (H&E) images, surpassing the performance of other feature combinations. Accurate virtual staining is valuable for reliable diagnostic information, aiding pathologists in disease classification, grading, and treatment planning. This study aims to advance label-free histological imaging and opens doors for intraoperative microscopy applications.
TablEye: Seeing small Tables through the Lens of Images
Jul 04, 2023The exploration of few-shot tabular learning becomes imperative. Tabular data is a versatile representation that captures diverse information, yet it is not exempt from limitations, property of data and model size. Labeling extensive tabular data can be challenging, and it may not be feasible to capture every important feature. Few-shot tabular learning, however, remains relatively unexplored, primarily due to scarcity of shared information among independent datasets and the inherent ambiguity in defining boundaries within tabular data. To the best of our knowledge, no meaningful and unrestricted few-shot tabular learning techniques have been developed without imposing constraints on the dataset. In this paper, we propose an innovative framework called TablEye, which aims to overcome the limit of forming prior knowledge for tabular data by adopting domain transformation. It facilitates domain transformation by generating tabular images, which effectively conserve the intrinsic semantics of the original tabular data. This approach harnesses rigorously tested few-shot learning algorithms and embedding functions to acquire and apply prior knowledge. Leveraging shared data domains allows us to utilize this prior knowledge, originally learned from the image domain. Specifically, TablEye demonstrated a superior performance by outstripping the TabLLM in a 4-shot task with a maximum 0.11 AUC and a STUNT in a 1- shot setting, where it led on average by 3.17% accuracy.
An Interpretable Constructive Algorithm for Incremental Random Weight Neural Networks and Its Application
Jul 01, 2023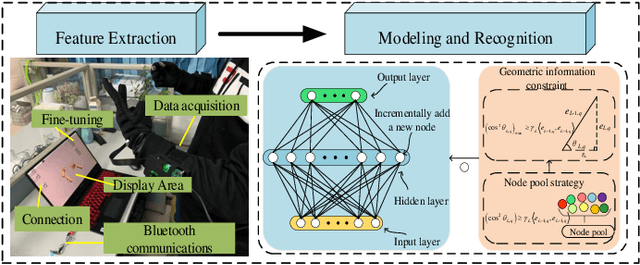
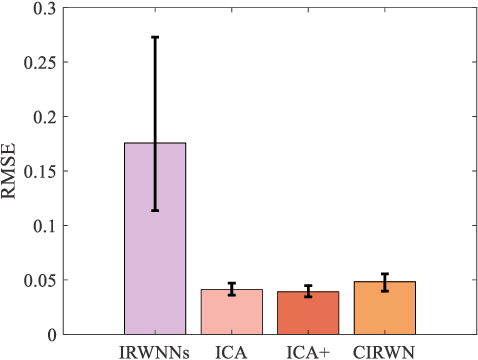
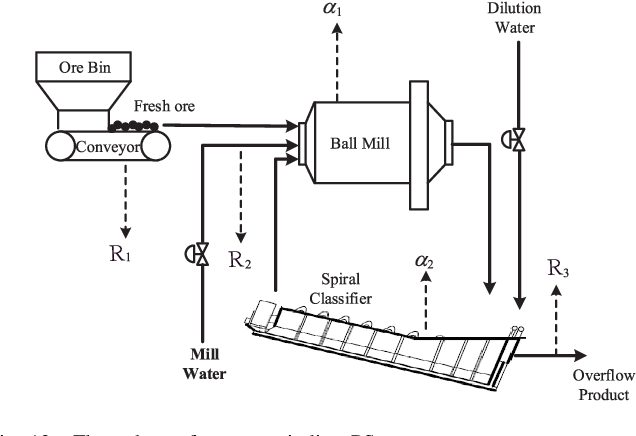
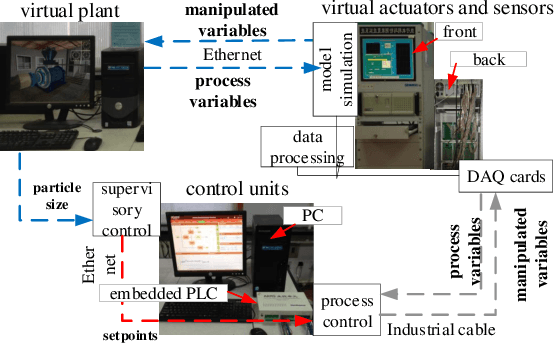
Incremental random weight neural networks (IRWNNs) have gained attention in view of its easy implementation and fast learning. However, a significant drawback of IRWNNs is that the elationship between the hidden parameters (node)and the residual error (model performance) is difficult to be interpreted. To address the above issue, this article proposes an interpretable constructive algorithm (ICA) with geometric information constraint. First, based on the geometric relationship between the hidden parameters and the residual error, an interpretable geometric information constraint is proposed to randomly assign the hidden parameters. Meanwhile, a node pool strategy is employed to obtain hidden parameters that is more conducive to convergence from hidden parameters satisfying the proposed constraint. Furthermore, the universal approximation property of the ICA is proved. Finally, a lightweight version of ICA is presented for large-scale data modeling tasks. Experimental results on six benchmark datasets and a numerical simulation dataset demonstrate that the ICA outperforms other constructive algorithms in terms of modeling speed, model accuracy, and model network structure. Besides, two practical industrial application case are used to validate the effectiveness of ICA in practical applications.
One-step Multi-view Clustering with Diverse Representation
Jun 27, 2023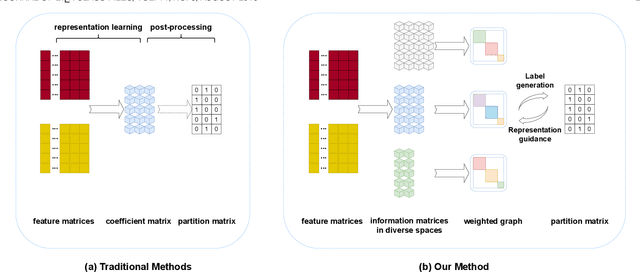
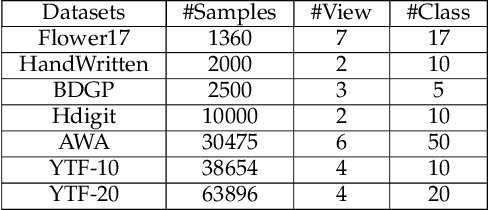
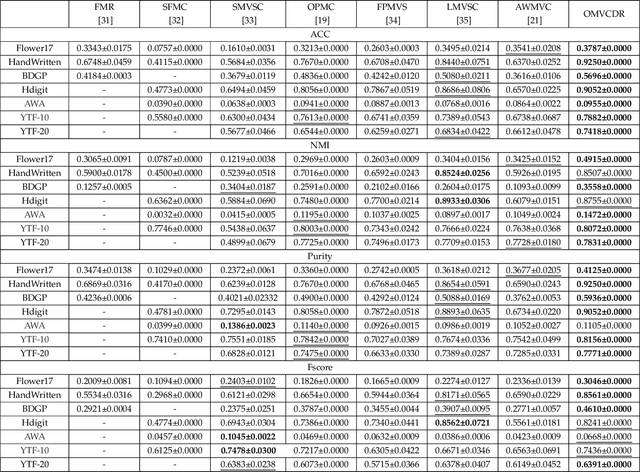
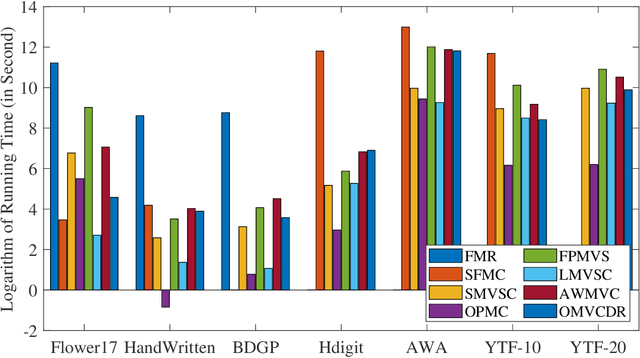
Multi-view clustering has attracted broad attention due to its capacity to utilize consistent and complementary information among views. Although tremendous progress has been made recently, most existing methods undergo high complexity, preventing them from being applied to large-scale tasks. Multi-view clustering via matrix factorization is a representative to address this issue. However, most of them map the data matrices into a fixed dimension, limiting the model's expressiveness. Moreover, a range of methods suffers from a two-step process, i.e., multimodal learning and the subsequent $k$-means, inevitably causing a sub-optimal clustering result. In light of this, we propose a one-step multi-view clustering with diverse representation method, which incorporates multi-view learning and $k$-means into a unified framework. Specifically, we first project original data matrices into various latent spaces to attain comprehensive information and auto-weight them in a self-supervised manner. Then we directly use the information matrices under diverse dimensions to obtain consensus discrete clustering labels. The unified work of representation learning and clustering boosts the quality of the final results. Furthermore, we develop an efficient optimization algorithm with proven convergence to solve the resultant problem. Comprehensive experiments on various datasets demonstrate the promising clustering performance of our proposed method.
Symbol emergence as interpersonal cross-situational learning: the emergence of lexical knowledge with combinatoriality
Jun 27, 2023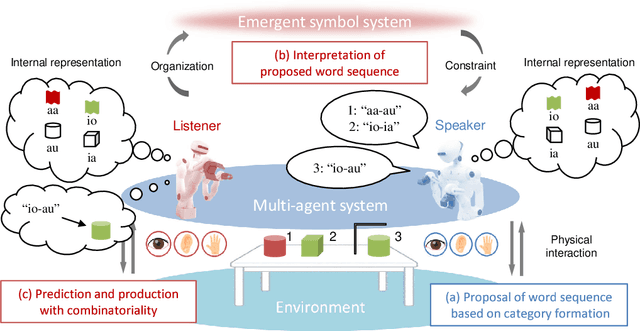

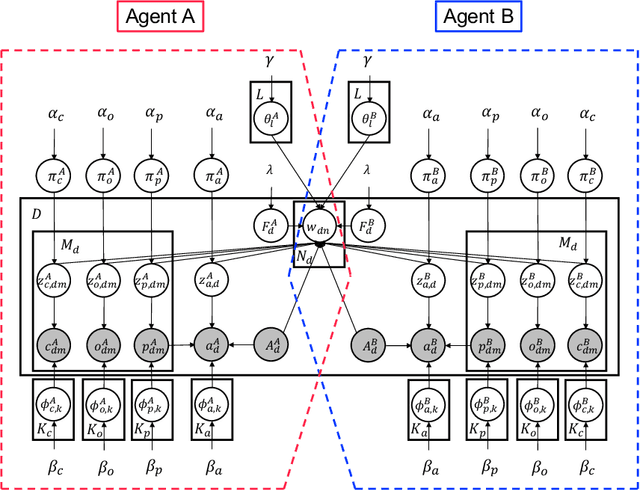
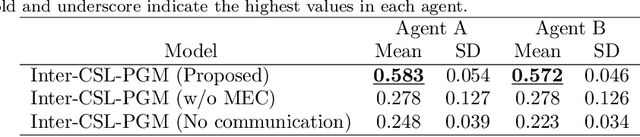
We present a computational model for a symbol emergence system that enables the emergence of lexical knowledge with combinatoriality among agents through a Metropolis-Hastings naming game and cross-situational learning. Many computational models have been proposed to investigate combinatoriality in emergent communication and symbol emergence in cognitive and developmental robotics. However, existing models do not sufficiently address category formation based on sensory-motor information and semiotic communication through the exchange of word sequences within a single integrated model. Our proposed model facilitates the emergence of lexical knowledge with combinatoriality by performing category formation using multimodal sensory-motor information and enabling semiotic communication through the exchange of word sequences among agents in a unified model. Furthermore, the model enables an agent to predict sensory-motor information for unobserved situations by combining words associated with categories in each modality. We conducted two experiments with two humanoid robots in a simulated environment to evaluate our proposed model. The results demonstrated that the agents can acquire lexical knowledge with combinatoriality through interpersonal cross-situational learning based on the Metropolis-Hastings naming game and cross-situational learning. Furthermore, our results indicate that the lexical knowledge developed using our proposed model exhibits generalization performance for novel situations through interpersonal cross-modal inference.
ChatGPT vs. Google: A Comparative Study of Search Performance and User Experience
Jul 03, 2023
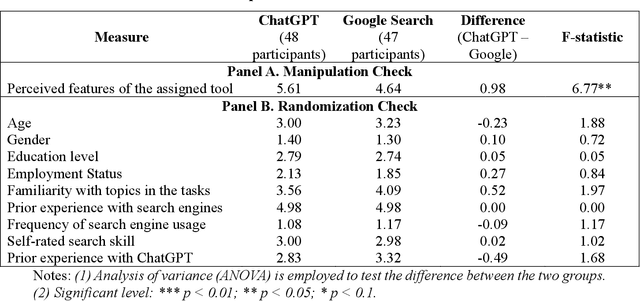
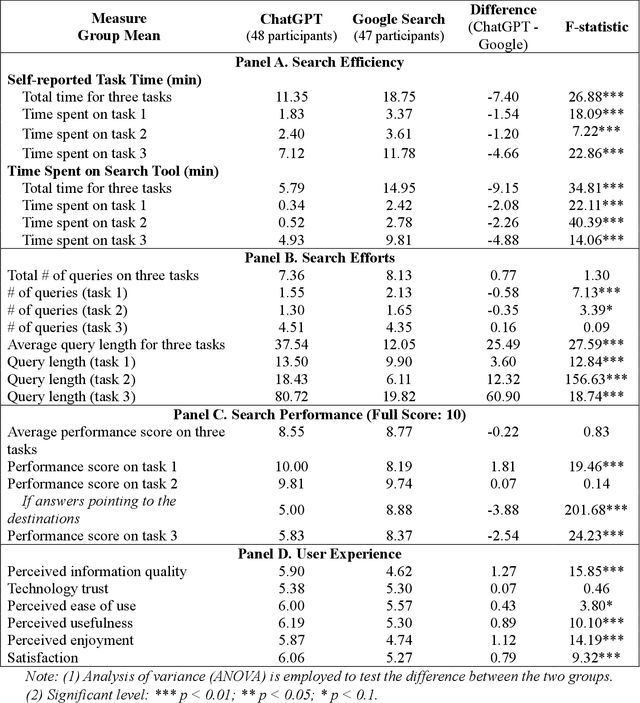
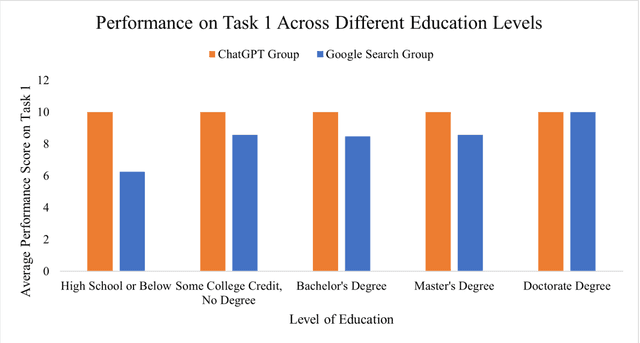
The advent of ChatGPT, a large language model-powered chatbot, has prompted questions about its potential implications for traditional search engines. In this study, we investigate the differences in user behavior when employing search engines and chatbot tools for information-seeking tasks. We carry out a randomized online experiment, dividing participants into two groups: one using a ChatGPT-like tool and the other using a Google Search-like tool. Our findings reveal that the ChatGPT group consistently spends less time on all tasks, with no significant difference in overall task performance between the groups. Notably, ChatGPT levels user search performance across different education levels and excels in answering straightforward questions and providing general solutions but falls short in fact-checking tasks. Users perceive ChatGPT's responses as having higher information quality compared to Google Search, despite displaying a similar level of trust in both tools. Furthermore, participants using ChatGPT report significantly better user experiences in terms of usefulness, enjoyment, and satisfaction, while perceived ease of use remains comparable between the two tools. However, ChatGPT may also lead to overreliance and generate or replicate misinformation, yielding inconsistent results. Our study offers valuable insights for search engine management and highlights opportunities for integrating chatbot technologies into search engine designs.