 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The mapKurator System: A Complete Pipeline for Extracting and Linking Text from Historical Maps
Jun 29, 2023
Documents hold spatial focus and valuable locality characteristics. For example, descriptions of listings in real estate or travel blogs contain information about specific local neighborhoods. This information is valuable to characterize how humans perceive their environment. However, the first step to making use of this information is to identify the spatial focus (e.g., a city) of a document. Traditional approaches for identifying the spatial focus of a document rely on detecting and disambiguating toponyms from the document. This approach requires a vocabulary set of location phrases and ad-hoc rules, which ignore important words related to location. Recent topic modeling approaches using large language models often consider a few topics, each with broad coverage. In contrast, the spatial focus of a document can be a country, a city, or even a neighborhood, which together, is much larger than the number of topics considered in these approaches. Additionally, topic modeling methods are often applied to broad topics of news articles where context is easily distinguishable. To identify the geographic focus of a document effectively, we present a simple but effective Joint Embedding of multi-LocaLitY (JELLY), which jointly learns representations with separate encoders of document and location. JELLY significantly outperforms state-of-the-art methods for identifying spatial focus from documents from a number of sources. We also demonstrate case studies on the arithmetic of the learned representations, including identifying cities with similar locality characteristics and zero-shot learning to identify document spatial focus.
BHEISR: Nudging from Bias to Balance -- Promoting Belief Harmony by Eliminating Ideological Segregation in Knowledge-based Recommendations
Jul 06, 2023
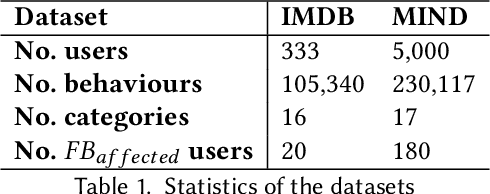
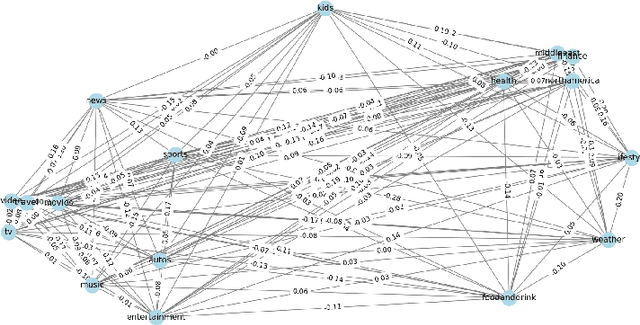
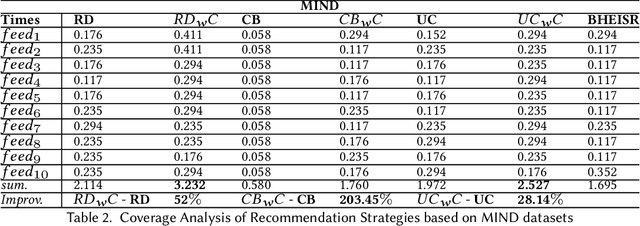
In the realm of personalized recommendation systems, the increasing concern is the amplification of belief imbalance and user biases, a phenomenon primarily attributed to the filter bubble. Addressing this critical issue, we introduce an innovative intermediate agency (BHEISR) between users and existing recommendation systems to attenuate the negative repercussions of the filter bubble effect in extant recommendation systems. The main objective is to strike a belief balance for users while minimizing the detrimental influence caused by filter bubbles. The BHEISR model amalgamates principles from nudge theory while upholding democratic and transparent principles. It harnesses user-specific category information to stimulate curiosity, even in areas users might initially deem uninteresting. By progressively stimulating interest in novel categories, the model encourages users to broaden their belief horizons and explore the information they typically overlook. Our model is time-sensitive and operates on a user feedback loop. It utilizes the existing recommendation algorithm of the model and incorporates user feedback from the prior time frame. This approach endeavors to transcend the constraints of the filter bubble, enrich recommendation diversity, and strike a belief balance among users while also catering to user preferences and system-specific business requirements. To validate the effectiveness and reliability of the BHEISR model, we conducted a series of comprehensive experiments with real-world datasets. These experiments compared the performance of the BHEISR model against several baseline models using nearly 200 filter bubble-impacted users as test subjects. Our experimental results conclusively illustrate the superior performance of the BHEISR model in mitigating filter bubbles and balancing user perspectives.
Computable Stability for Persistence Rank Function Machine Learning
Jul 06, 2023
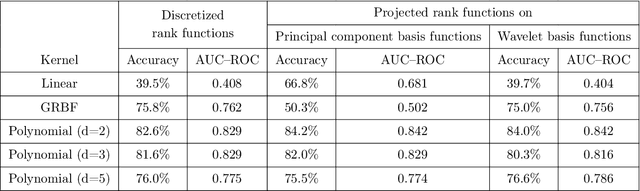
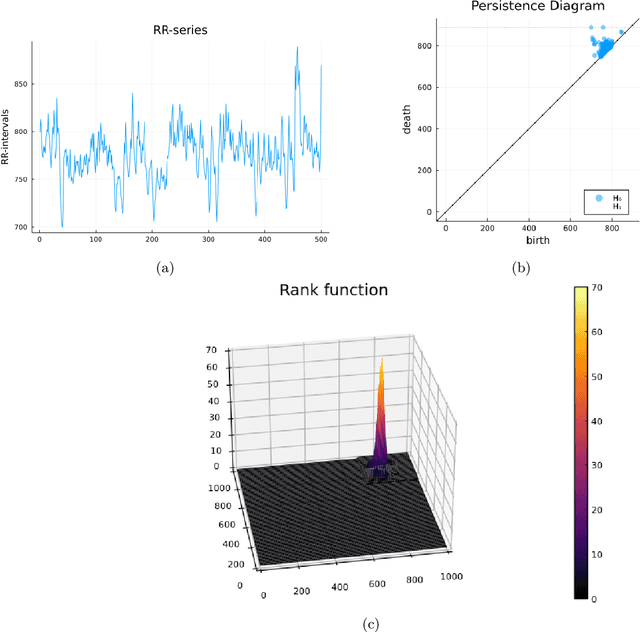

Persistent homology barcodes and diagrams are a cornerstone of topological data analysis. Widely used in many real data settings, they relate variation in topological information (as measured by cellular homology) with variation in data, however, they are challenging to use in statistical settings due to their complex geometric structure. In this paper, we revisit the persistent homology rank function -- an invariant measure of ``shape" that was introduced before barcodes and persistence diagrams and captures the same information in a form that is more amenable to data and computation. In particular, since they are functions, techniques from functional data analysis -- a domain of statistics adapted for functions -- apply directly to persistent homology when represented by rank functions. Rank functions, however, have been less popular than barcodes because they face the challenge that stability -- a property that is crucial to validate their use in data analysis -- is difficult to guarantee, mainly due to metric concerns on rank function space. However, rank functions extend more naturally to the increasingly popular and important case of multiparameter persistent homology. In this paper, we study the performance of rank functions in functional inferential statistics and machine learning on both simulated and real data, and in both single and multiparameter persistent homology. We find that the use of persistent homology captured by rank functions offers a clear improvement over existing approaches. We then provide theoretical justification for our numerical experiments and applications to data by deriving several stability results for single- and multiparameter persistence rank functions under various metrics with the underlying aim of computational feasibility and interpretability.
Medical ministrations through web scraping
Jun 21, 2023Web scraping is a technique that allows us to extract data from websites automatically. in the field of medicine, web scraping can be used to collect information about medical procedures, treatments, and healthcare providers. this information can be used to improve patient care, monitor the quality of healthcare services, and identify areas for improvement. one area where web scraping can be particularly useful is in medical ministrations. medical ministrations are the actions taken to provide medical care to patients, and web scraping can help healthcare providers identify the most effective ministrations for their patients. for example, healthcare providers can use web scraping to collect data about the symptoms and medical histories of their patients, and then use this information to determine the most appropriate ministrations. they can also use web scraping to gather information about the latest medical research and clinical trials, which can help them stay up-to-date with the latest treatments and procedures.
Modeling Entities as Semantic Points for Visual Information Extraction in the Wild
Mar 23, 2023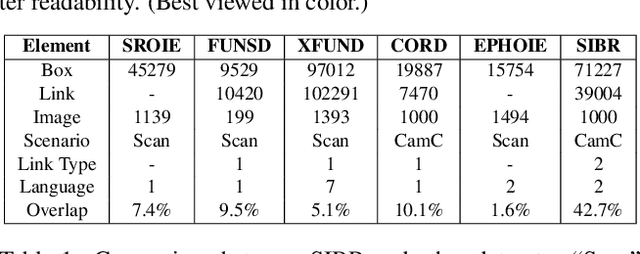
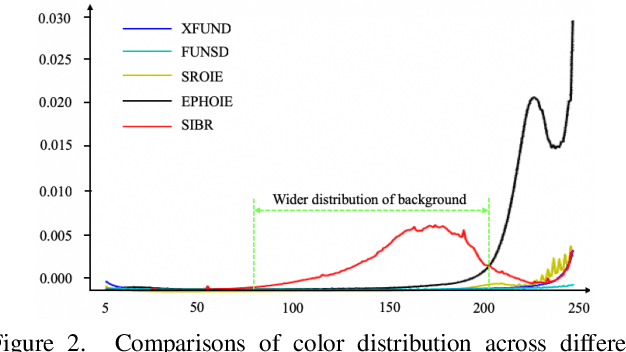
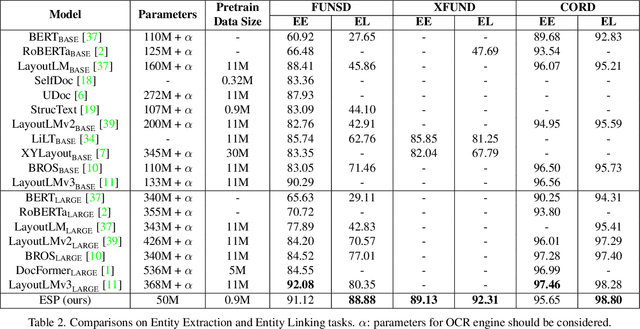
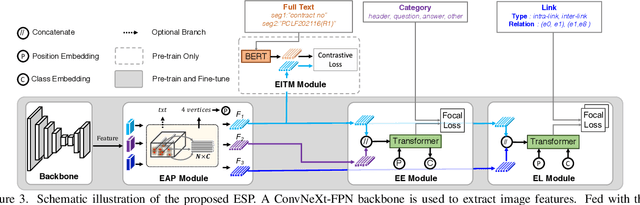
Recently, Visual Information Extraction (VIE) has been becoming increasingly important in both the academia and industry, due to the wide range of real-world applications. Previously, numerous works have been proposed to tackle this problem. However, the benchmarks used to assess these methods are relatively plain, i.e., scenarios with real-world complexity are not fully represented in these benchmarks. As the first contribution of this work, we curate and release a new dataset for VIE, in which the document images are much more challenging in that they are taken from real applications, and difficulties such as blur, partial occlusion, and printing shift are quite common. All these factors may lead to failures in information extraction. Therefore, as the second contribution, we explore an alternative approach to precisely and robustly extract key information from document images under such tough conditions. Specifically, in contrast to previous methods, which usually either incorporate visual information into a multi-modal architecture or train text spotting and information extraction in an end-to-end fashion, we explicitly model entities as semantic points, i.e., center points of entities are enriched with semantic information describing the attributes and relationships of different entities, which could largely benefit entity labeling and linking. Extensive experiments on standard benchmarks in this field as well as the proposed dataset demonstrate that the proposed method can achieve significantly enhanced performance on entity labeling and linking, compared with previous state-of-the-art models. Dataset is available at https://www.modelscope.cn/datasets/damo/SIBR/summary.
Multitemporal SAR images change detection and visualization using RABASAR and simplified GLR
Jul 15, 2023
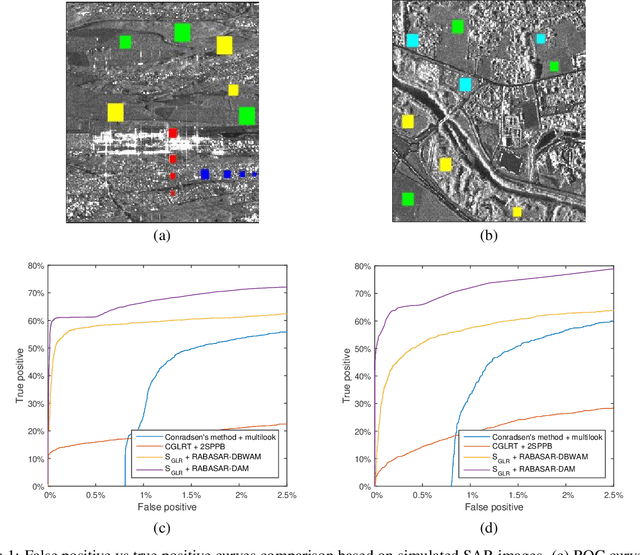


Understanding the state of changed areas requires that precise information be given about the changes. Thus, detecting different kinds of changes is important for land surface monitoring. SAR sensors are ideal to fulfil this task, because of their all-time and all-weather capabilities, with good accuracy of the acquisition geometry and without effects of atmospheric constituents for amplitude data. In this study, we propose a simplified generalized likelihood ratio ($S_{GLR}$) method assuming that corresponding temporal pixels have the same equivalent number of looks (ENL). Thanks to the denoised data provided by a ratio-based multitemporal SAR image denoising method (RABASAR), we successfully applied this similarity test approach to compute the change areas. A new change magnitude index method and an improved spectral clustering-based change classification method are also developed. In addition, we apply the simplified generalized likelihood ratio to detect the maximum change magnitude time, and the change starting and ending times. Then, we propose to use an adaptation of the REACTIV method to visualize the detection results vividly. The effectiveness of the proposed methods is demonstrated through the processing of simulated and SAR images, and the comparison with classical techniques. In particular, numerical experiments proved that the developed method has good performances in detecting farmland area changes, building area changes, harbour area changes and flooding area changes.
ExposureDiffusion: Learning to Expose for Low-light Image Enhancement
Jul 15, 2023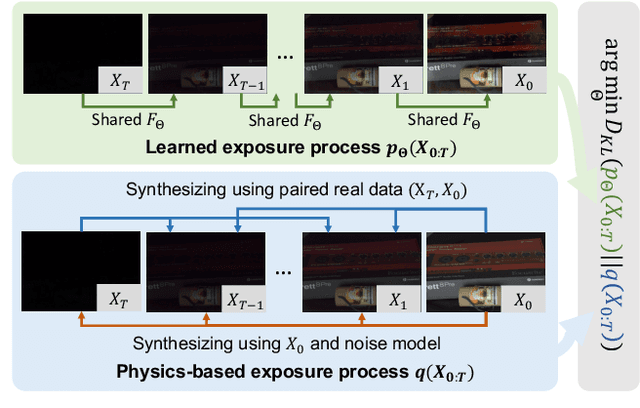

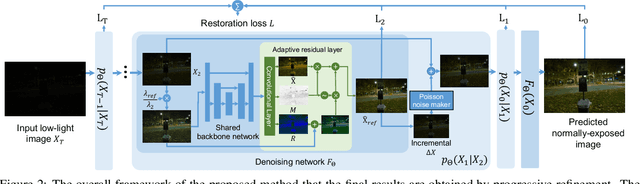
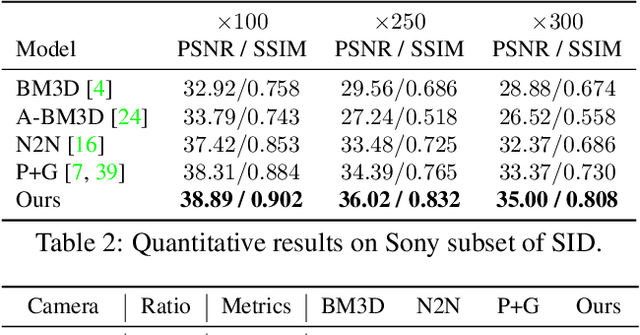
Previous raw image-based low-light image enhancement methods predominantly relied on feed-forward neural networks to learn deterministic mappings from low-light to normally-exposed images. However, they failed to capture critical distribution information, leading to visually undesirable results. This work addresses the issue by seamlessly integrating a diffusion model with a physics-based exposure model. Different from a vanilla diffusion model that has to perform Gaussian denoising, with the injected physics-based exposure model, our restoration process can directly start from a noisy image instead of pure noise. As such, our method obtains significantly improved performance and reduced inference time compared with vanilla diffusion models. To make full use of the advantages of different intermediate steps, we further propose an adaptive residual layer that effectively screens out the side-effect in the iterative refinement when the intermediate results have been already well-exposed. The proposed framework can work with both real-paired datasets, SOTA noise models, and different backbone networks. Note that, the proposed framework is compatible with real-paired datasets, real/synthetic noise models, and different backbone networks. We evaluate the proposed method on various public benchmarks, achieving promising results with consistent improvements using different exposure models and backbones. Besides, the proposed method achieves better generalization capacity for unseen amplifying ratios and better performance than a larger feedforward neural model when few parameters are adopted.
Open Scene Understanding: Grounded Situation Recognition Meets Segment Anything for Helping People with Visual Impairments
Jul 15, 2023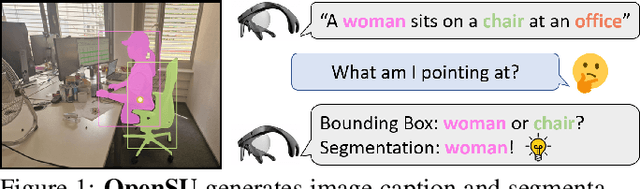
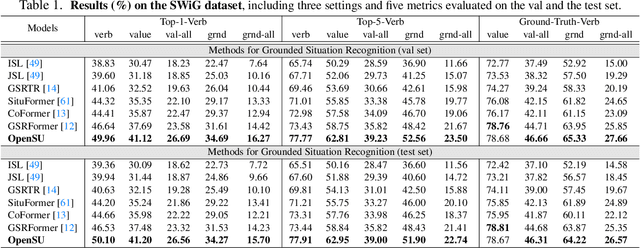
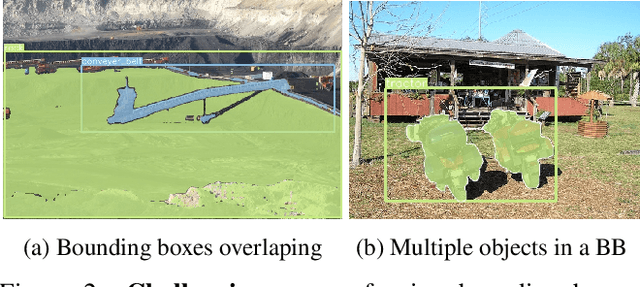

Grounded Situation Recognition (GSR) is capable of recognizing and interpreting visual scenes in a contextually intuitive way, yielding salient activities (verbs) and the involved entities (roles) depicted in images. In this work, we focus on the application of GSR in assisting people with visual impairments (PVI). However, precise localization information of detected objects is often required to navigate their surroundings confidently and make informed decisions. For the first time, we propose an Open Scene Understanding (OpenSU) system that aims to generate pixel-wise dense segmentation masks of involved entities instead of bounding boxes. Specifically, we build our OpenSU system on top of GSR by additionally adopting an efficient Segment Anything Model (SAM). Furthermore, to enhance the feature extraction and interaction between the encoder-decoder structure, we construct our OpenSU system using a solid pure transformer backbone to improve the performance of GSR. In order to accelerate the convergence, we replace all the activation functions within the GSR decoders with GELU, thereby reducing the training duration. In quantitative analysis, our model achieves state-of-the-art performance on the SWiG dataset. Moreover, through field testing on dedicated assistive technology datasets and application demonstrations, the proposed OpenSU system can be used to enhance scene understanding and facilitate the independent mobility of people with visual impairments. Our code will be available at https://github.com/RuipingL/OpenSU.
SINC: Self-Supervised In-Context Learning for Vision-Language Tasks
Jul 15, 2023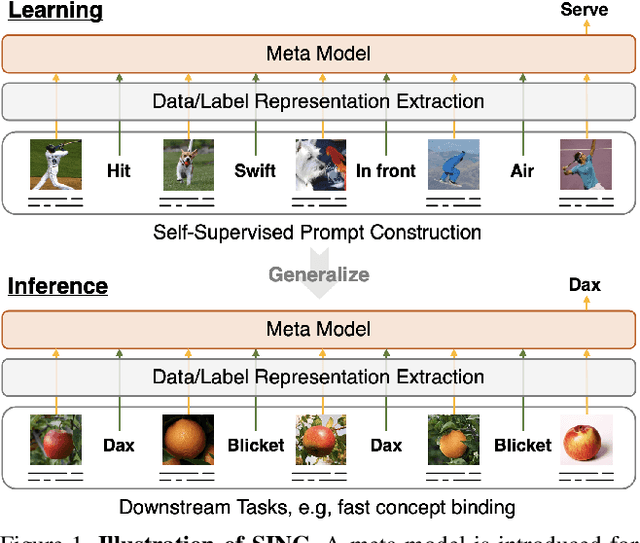
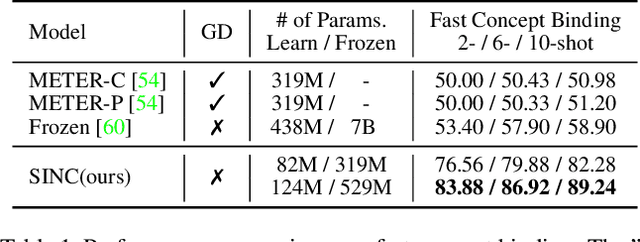
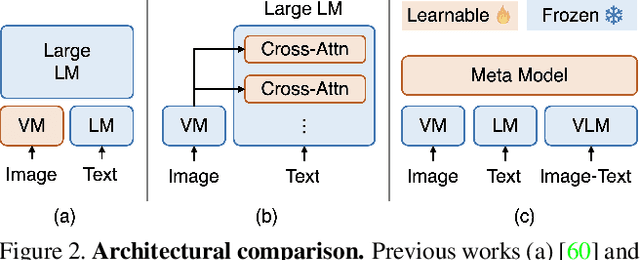
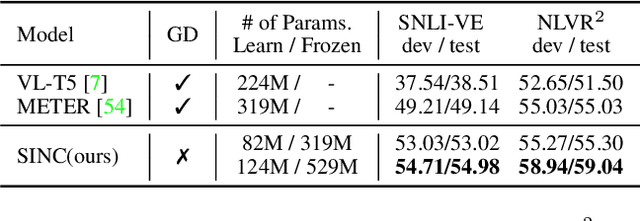
Large Pre-trained Transformers exhibit an intriguing capacity for in-context learning. Without gradient updates, these models can rapidly construct new predictors from demonstrations presented in the inputs. Recent works promote this ability in the vision-language domain by incorporating visual information into large language models that can already make in-context predictions. However, these methods could inherit issues in the language domain, such as template sensitivity and hallucination. Also, the scale of these language models raises a significant demand for computations, making learning and operating these models resource-intensive. To this end, we raise a question: ``How can we enable in-context learning for general models without being constrained on large language models?". To answer it, we propose a succinct and general framework, Self-supervised IN-Context learning (SINC), that introduces a meta-model to learn on self-supervised prompts consisting of tailored demonstrations. The learned models can be transferred to downstream tasks for making in-context predictions on-the-fly. Extensive experiments show that SINC outperforms gradient-based methods in various vision-language tasks under few-shot settings. Furthermore, the designs of SINC help us investigate the benefits of in-context learning across different tasks, and the analysis further reveals the essential components for the emergence of in-context learning in the vision-language domain.
Identification of Stochasticity by Matrix-decomposition: Applied on Black Hole Data
Jul 15, 2023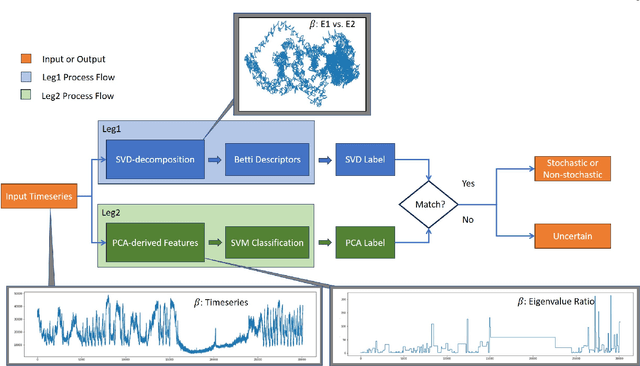
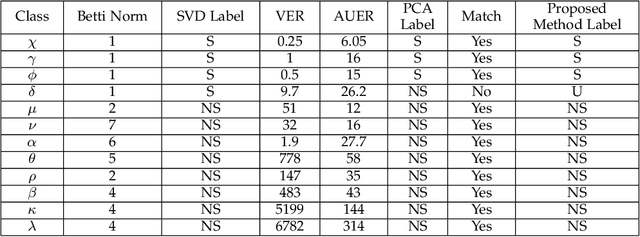
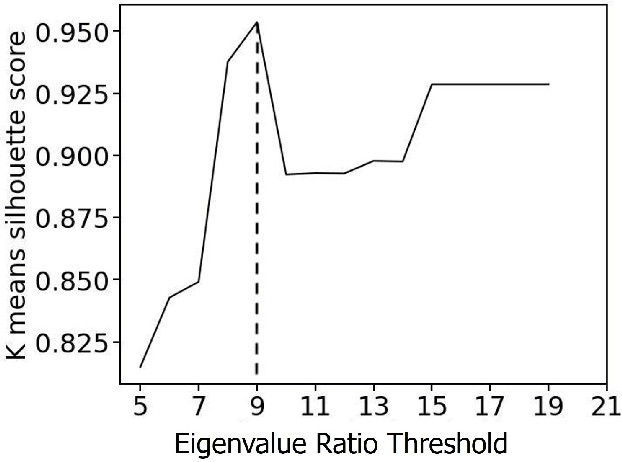
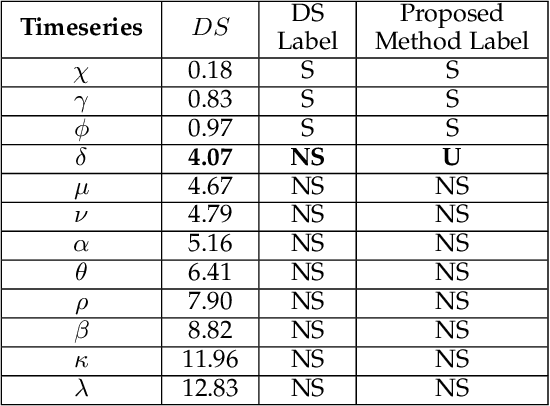
Timeseries classification as stochastic (noise-like) or non-stochastic (structured), helps understand the underlying dynamics, in several domains. Here we propose a two-legged matrix decomposition-based algorithm utilizing two complementary techniques for classification. In Singular Value Decomposition (SVD) based analysis leg, we perform topological analysis (Betti numbers) on singular vectors containing temporal information, leading to SVD-label. Parallely, temporal-ordering agnostic Principal Component Analysis (PCA) is performed, and the proposed PCA-derived features are computed. These features, extracted from synthetic timeseries of the two labels, are observed to map the timeseries to a linearly separable feature space. Support Vector Machine (SVM) is used to produce PCA-label. The proposed methods have been applied to synthetic data, comprising 41 realisations of white-noise, pink-noise (stochastic), Logistic-map at growth-rate 4 and Lorentz-system (non-stochastic), as proof-of-concept. Proposed algorithm is applied on astronomical data: 12 temporal-classes of timeseries of black hole GRS 1915+105, obtained from RXTE satellite with average length 25000. For a given timeseries, if SVD-label and PCA-label concur, then the label is retained; else deemed "Uncertain". Comparison of obtained results with those in literature are presented. It's found that out of 12 temporal classes of GRS 1915+105, concurrence between SVD-label and PCA-label is obtained on 11 of them.