 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Radar-STDA: A High-Performance Spatial-Temporal Denoising Autoencoder for Interference Mitigation of FMCW Radars
Jul 18, 2023
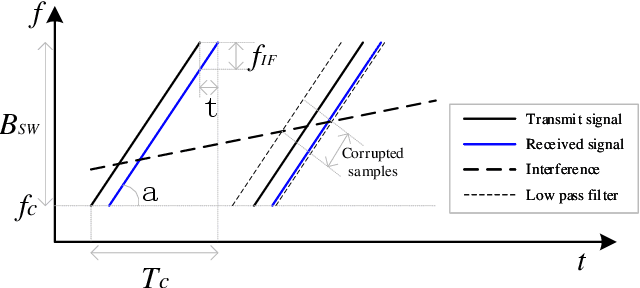
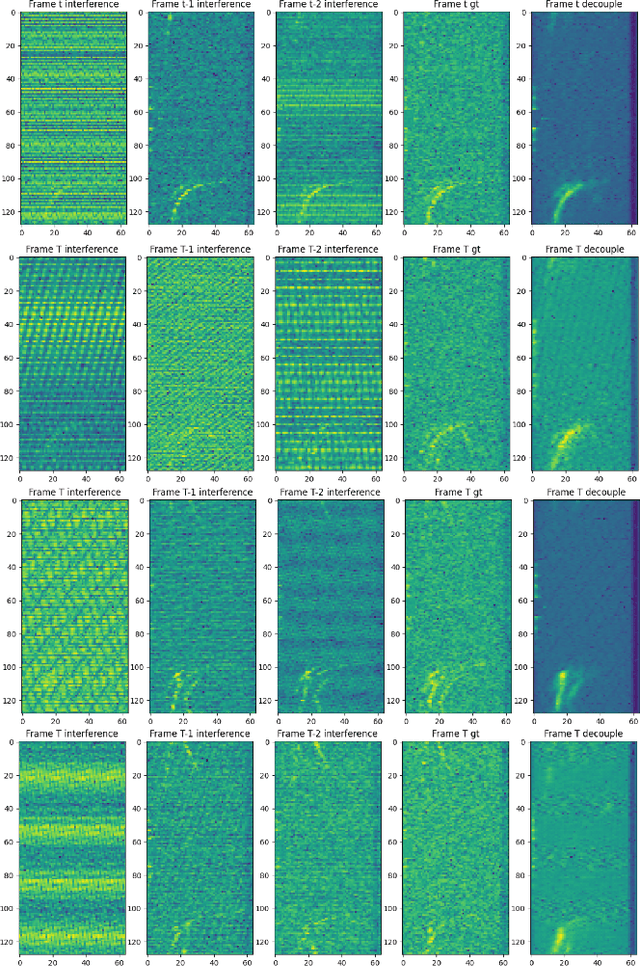
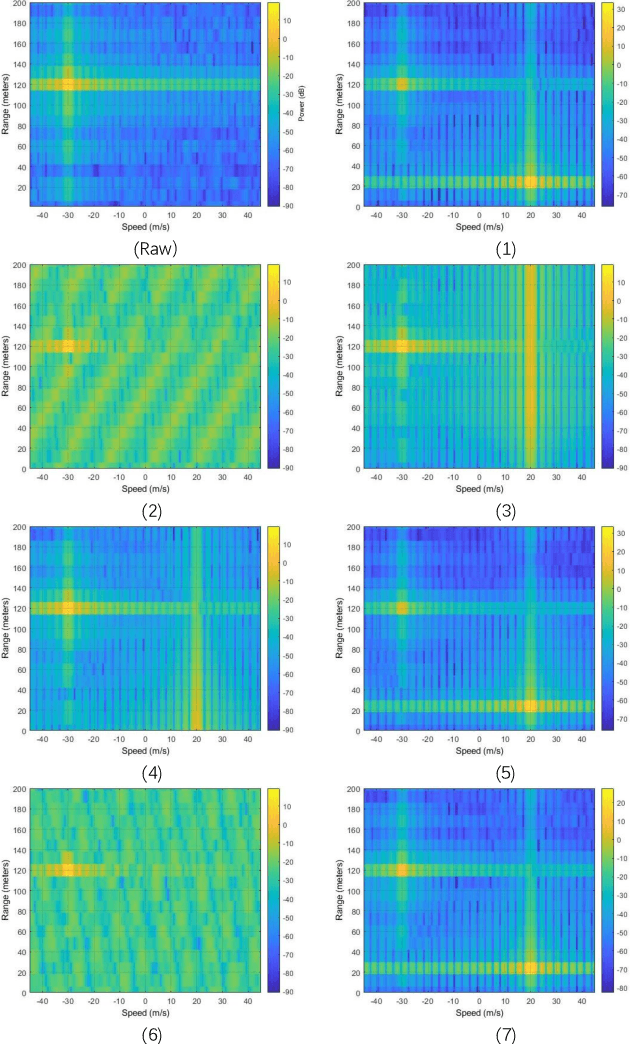
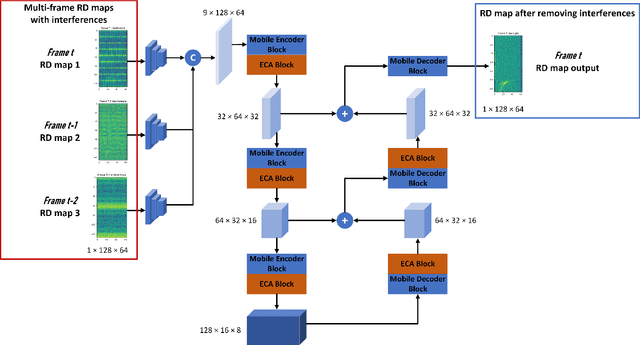
With its small size, low cost and all-weather operation, millimeter-wave radar can accurately measure the distance, azimuth and radial velocity of a target compared to other traffic sensors. However, in practice, millimeter-wave radars are plagued by various interferences, leading to a drop in target detection accuracy or even failure to detect targets. This is undesirable in autonomous vehicles and traffic surveillance, as it is likely to threaten human life and cause property damage. Therefore, interference mitigation is of great significance for millimeter-wave radar-based target detection. Currently, the development of deep learning is rapid, but existing deep learning-based interference mitigation models still have great limitations in terms of model size and inference speed. For these reasons, we propose Radar-STDA, a Radar-Spatial Temporal Denoising Autoencoder. Radar-STDA is an efficient nano-level denoising autoencoder that takes into account both spatial and temporal information of range-Doppler maps. Among other methods, it achieves a maximum SINR of 17.08 dB with only 140,000 parameters. It obtains 207.6 FPS on an RTX A4000 GPU and 56.8 FPS on an NVIDIA Jetson AGXXavier respectively when denoising range-Doppler maps for three consecutive frames. Moreover, we release a synthetic data set called Ra-inf for the task, which involves 384,769 range-Doppler maps with various clutters from objects of no interest and receiver noise in realistic scenarios. To the best of our knowledge, Ra-inf is the first synthetic dataset of radar interference. To support the community, our research is open-source via the link \url{https://github.com/GuanRunwei/rd_map_temporal_spatial_denoising_autoencoder}.
3D-SeqMOS: A Novel Sequential 3D Moving Object Segmentation in Autonomous Driving
Jul 18, 2023

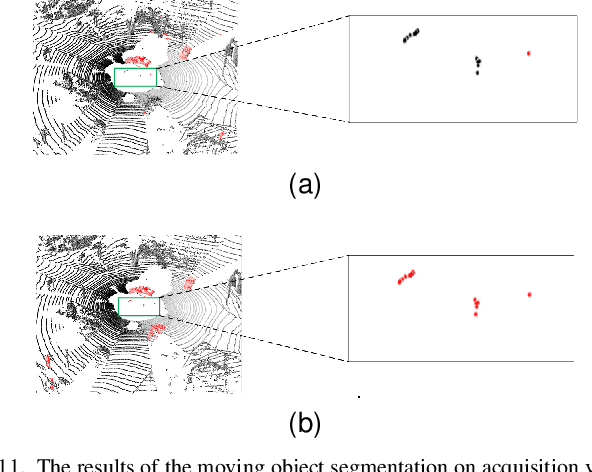
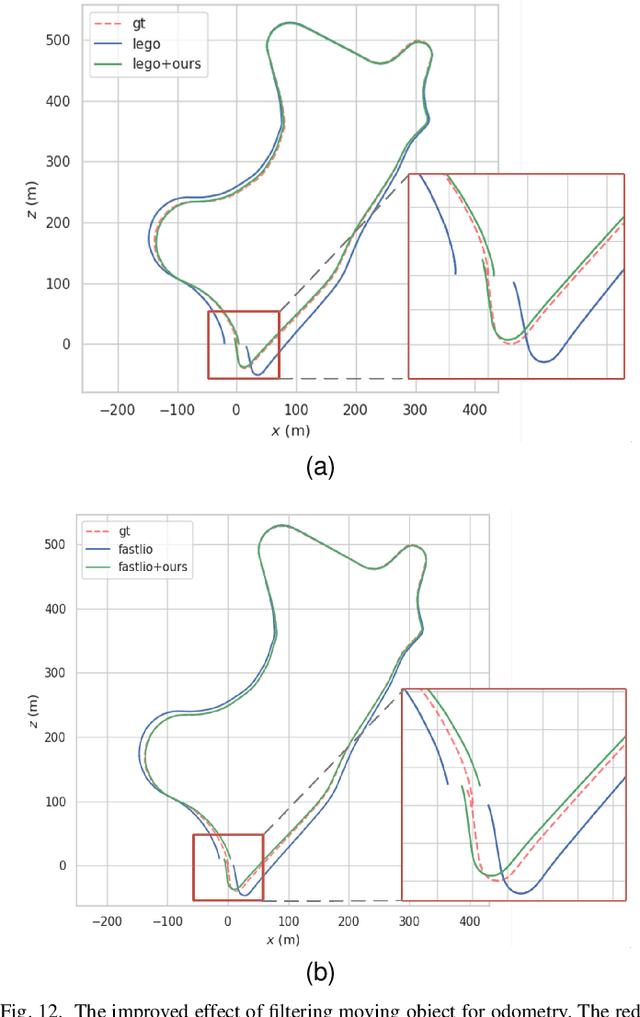
For the SLAM system in robotics and autonomous driving, the accuracy of front-end odometry and back-end loop-closure detection determine the whole intelligent system performance. But the LiDAR-SLAM could be disturbed by current scene moving objects, resulting in drift errors and even loop-closure failure. Thus, the ability to detect and segment moving objects is essential for high-precision positioning and building a consistent map. In this paper, we address the problem of moving object segmentation from 3D LiDAR scans to improve the odometry and loop-closure accuracy of SLAM. We propose a novel 3D Sequential Moving-Object-Segmentation (3D-SeqMOS) method that can accurately segment the scene into moving and static objects, such as moving and static cars. Different from the existing projected-image method, we process the raw 3D point cloud and build a 3D convolution neural network for MOS task. In addition, to make full use of the spatio-temporal information of point cloud, we propose a point cloud residual mechanism using the spatial features of current scan and the temporal features of previous residual scans. Besides, we build a complete SLAM framework to verify the effectiveness and accuracy of 3D-SeqMOS. Experiments on SemanticKITTI dataset show that our proposed 3D-SeqMOS method can effectively detect moving objects and improve the accuracy of LiDAR odometry and loop-closure detection. The test results show our 3D-SeqMOS outperforms the state-of-the-art method by 12.4%. We extend the proposed method to the SemanticKITTI: Moving Object Segmentation competition and achieve the 2nd in the leaderboard, showing its effectiveness.
Exploiting Asymmetry in Logic Puzzles: Using ZDDs for Symbolic Model Checking Dynamic Epistemic Logic
Jul 11, 2023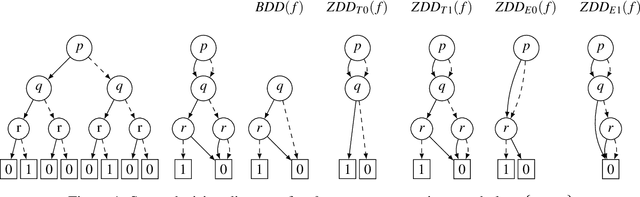
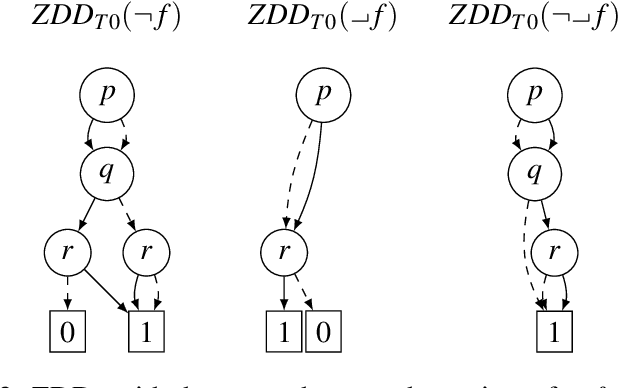
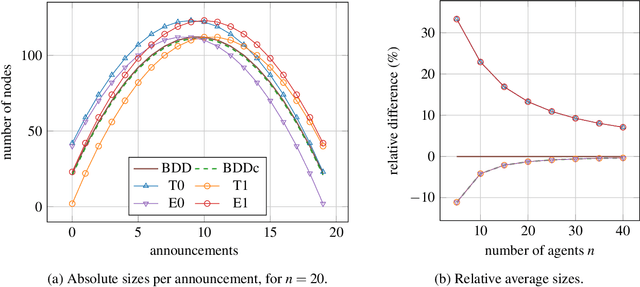
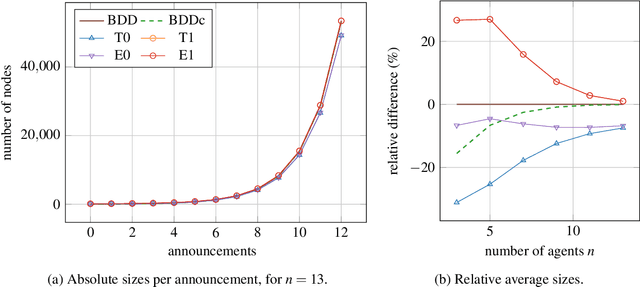
Binary decision diagrams (BDDs) are widely used to mitigate the state-explosion problem in model checking. A variation of BDDs are Zero-suppressed Decision Diagrams (ZDDs) which omit variables that must be false, instead of omitting variables that do not matter. We use ZDDs to symbolically encode Kripke models used in Dynamic Epistemic Logic, a framework to reason about knowledge and information dynamics in multi-agent systems. We compare the memory usage of different ZDD variants for three well-known examples from the literature: the Muddy Children, the Sum and Product puzzle and the Dining Cryptographers. Our implementation is based on the existing model checker SMCDEL and the CUDD library. Our results show that replacing BDDs with the right variant of ZDDs can significantly reduce memory usage. This suggests that ZDDs are a useful tool for model checking multi-agent systems.
* In Proceedings TARK 2023, arXiv:2307.04005
A Hierarchical Transformer Encoder to Improve Entire Neoplasm Segmentation on Whole Slide Image of Hepatocellular Carcinoma
Jul 11, 2023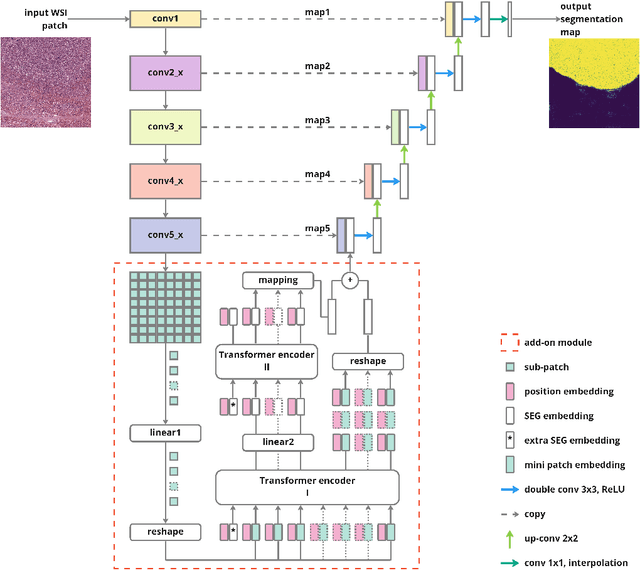
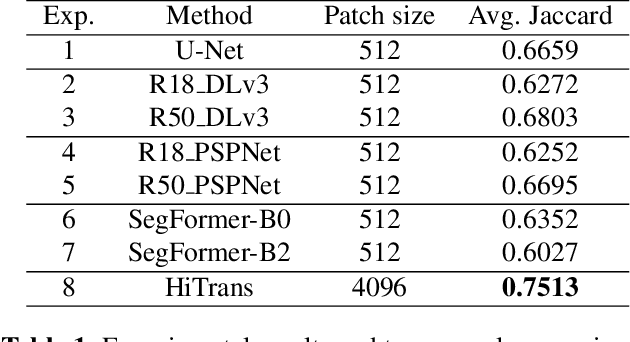
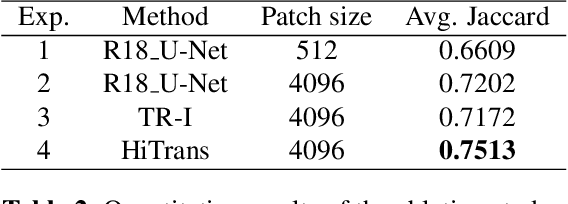

In digital histopathology, entire neoplasm segmentation on Whole Slide Image (WSI) of Hepatocellular Carcinoma (HCC) plays an important role, especially as a preprocessing filter to automatically exclude healthy tissue, in histological molecular correlations mining and other downstream histopathological tasks. The segmentation task remains challenging due to HCC's inherent high-heterogeneity and the lack of dependency learning in large field of view. In this article, we propose a novel deep learning architecture with a hierarchical Transformer encoder, HiTrans, to learn the global dependencies within expanded 4096$\times$4096 WSI patches. HiTrans is designed to encode and decode the patches with larger reception fields and the learned global dependencies, compared to the state-of-the-art Fully Convolutional Neural networks (FCNN). Empirical evaluations verified that HiTrans leads to better segmentation performance by taking into account regional and global dependency information.
Self-Supervised Learning with Lie Symmetries for Partial Differential Equations
Jul 11, 2023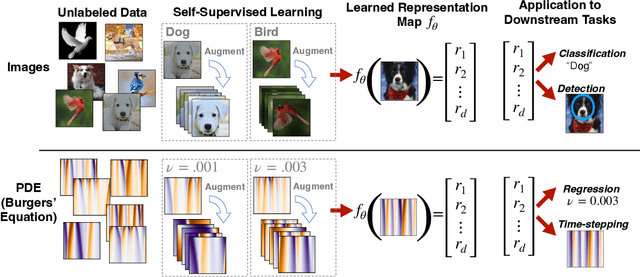
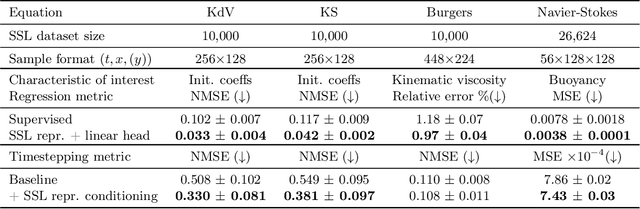
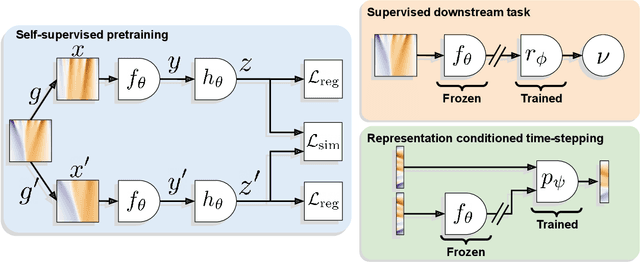

Machine learning for differential equations paves the way for computationally efficient alternatives to numerical solvers, with potentially broad impacts in science and engineering. Though current algorithms typically require simulated training data tailored to a given setting, one may instead wish to learn useful information from heterogeneous sources, or from real dynamical systems observations that are messy or incomplete. In this work, we learn general-purpose representations of PDEs from heterogeneous data by implementing joint embedding methods for self-supervised learning (SSL), a framework for unsupervised representation learning that has had notable success in computer vision. Our representation outperforms baseline approaches to invariant tasks, such as regressing the coefficients of a PDE, while also improving the time-stepping performance of neural solvers. We hope that our proposed methodology will prove useful in the eventual development of general-purpose foundation models for PDEs.
Mao-Zedong At SemEval-2023 Task 4: Label Represention Multi-Head Attention Model With Contrastive Learning-Enhanced Nearest Neighbor Mechanism For Multi-Label Text Classification
Jul 11, 2023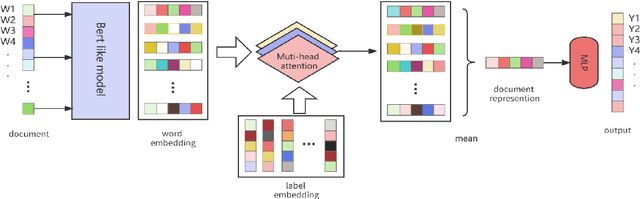
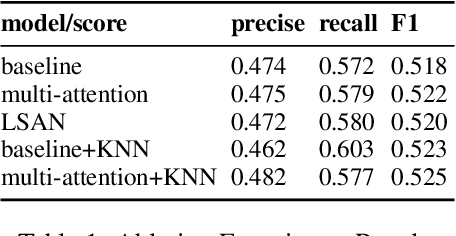
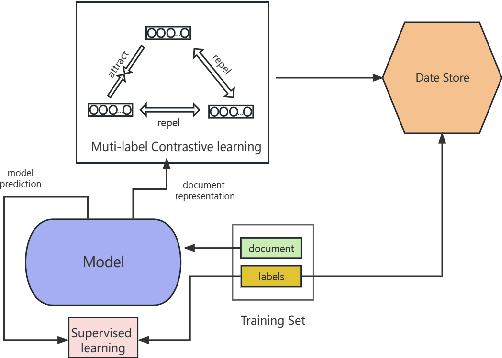
The study of human values is essential in both practical and theoretical domains. With the development of computational linguistics, the creation of large-scale datasets has made it possible to automatically recognize human values accurately. SemEval 2023 Task 4\cite{kiesel:2023} provides a set of arguments and 20 types of human values that are implicitly expressed in each argument. In this paper, we present our team's solution. We use the Roberta\cite{liu_roberta_2019} model to obtain the word vector encoding of the document and propose a multi-head attention mechanism to establish connections between specific labels and semantic components. Furthermore, we use a contrastive learning-enhanced K-nearest neighbor mechanism\cite{su_contrastive_2022} to leverage existing instance information for prediction. Our approach achieved an F1 score of 0.533 on the test set and ranked fourth on the leaderboard.
Box-DETR: Understanding and Boxing Conditional Spatial Queries
Jul 17, 2023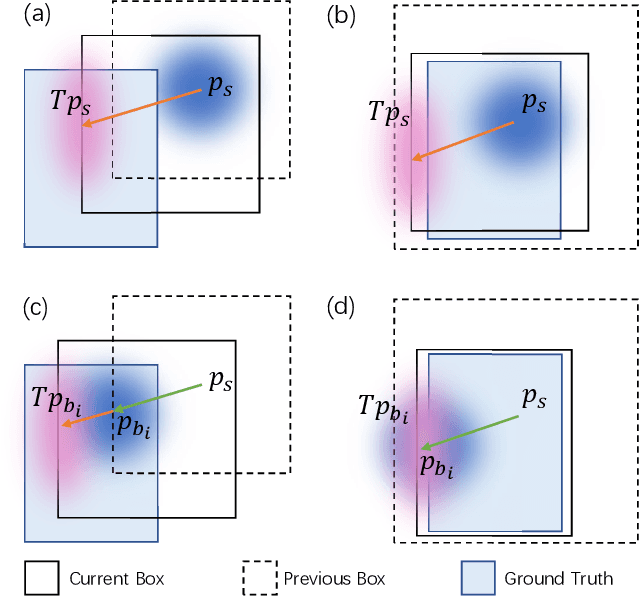
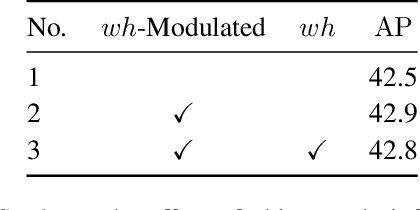

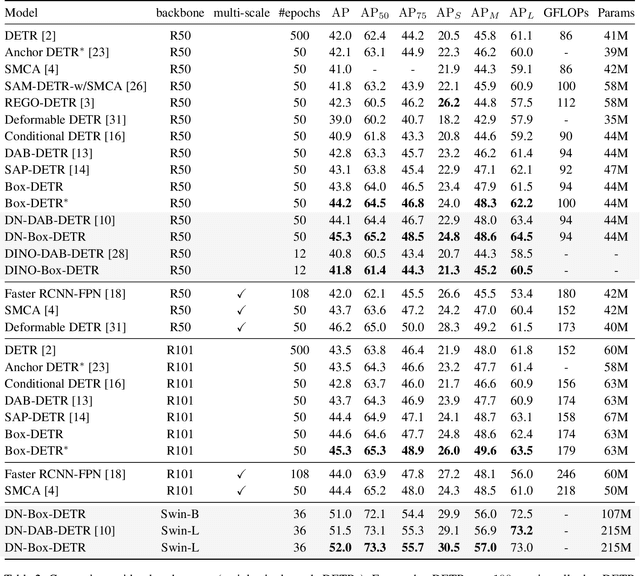
Conditional spatial queries are recently introduced into DEtection TRansformer (DETR) to accelerate convergence. In DAB-DETR, such queries are modulated by the so-called conditional linear projection at each decoder stage, aiming to search for positions of interest such as the four extremities of the box. Each decoder stage progressively updates the box by predicting the anchor box offsets, while in cross-attention only the box center is informed as the reference point. The use of only box center, however, leaves the width and height of the previous box unknown to the current stage, which hinders accurate prediction of offsets. We argue that the explicit use of the entire box information in cross-attention matters. In this work, we propose Box Agent to condense the box into head-specific agent points. By replacing the box center with the agent point as the reference point in each head, the conditional cross-attention can search for positions from a more reasonable starting point by considering the full scope of the previous box, rather than always from the previous box center. This significantly reduces the burden of the conditional linear projection. Experimental results show that the box agent leads to not only faster convergence but also improved detection performance, e.g., our single-scale model achieves $44.2$ AP with ResNet-50 based on DAB-DETR. Our Box Agent requires minor modifications to the code and has negligible computational workload. Code is available at https://github.com/tiny-smart/box-detr.
Large-Scale Person Detection and Localization using Overhead Fisheye Cameras
Jul 17, 2023Location determination finds wide applications in daily life. Instead of existing efforts devoted to localizing tourist photos captured by perspective cameras, in this article, we focus on devising person positioning solutions using overhead fisheye cameras. Such solutions are advantageous in large field of view (FOV), low cost, anti-occlusion, and unaggressive work mode (without the necessity of cameras carried by persons). However, related studies are quite scarce, due to the paucity of data. To stimulate research in this exciting area, we present LOAF, the first large-scale overhead fisheye dataset for person detection and localization. LOAF is built with many essential features, e.g., i) the data cover abundant diversities in scenes, human pose, density, and location; ii) it contains currently the largest number of annotated pedestrian, i.e., 457K bounding boxes with groundtruth location information; iii) the body-boxes are labeled as radius-aligned so as to fully address the positioning challenge. To approach localization, we build a fisheye person detection network, which exploits the fisheye distortions by a rotation-equivariant training strategy and predict radius-aligned human boxes end-to-end. Then, the actual locations of the detected persons are calculated by a numerical solution on the fisheye model and camera altitude data. Extensive experiments on LOAF validate the superiority of our fisheye detector w.r.t. previous methods, and show that our whole fisheye positioning solution is able to locate all persons in FOV with an accuracy of 0.5 m, within 0.1 s.
Enlarging Instance-specific and Class-specific Information for Open-set Action Recognition
Mar 25, 2023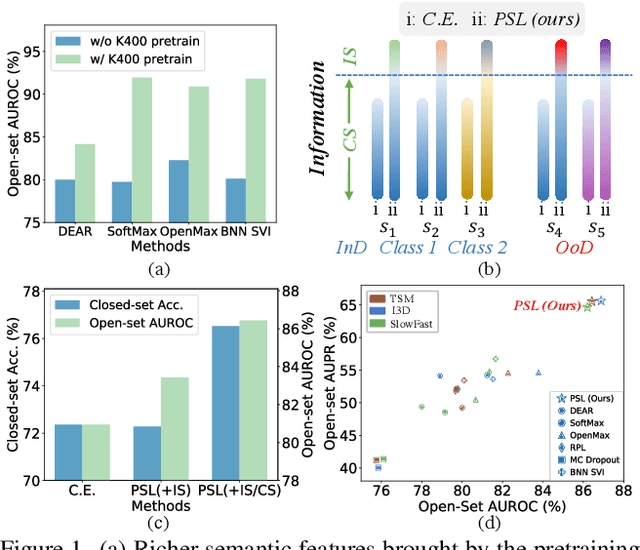
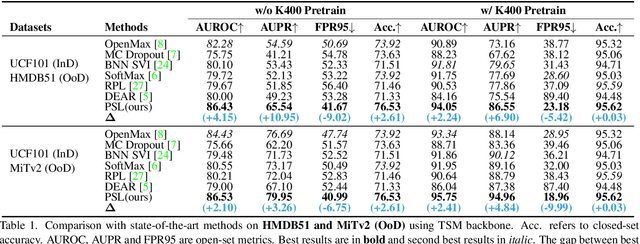
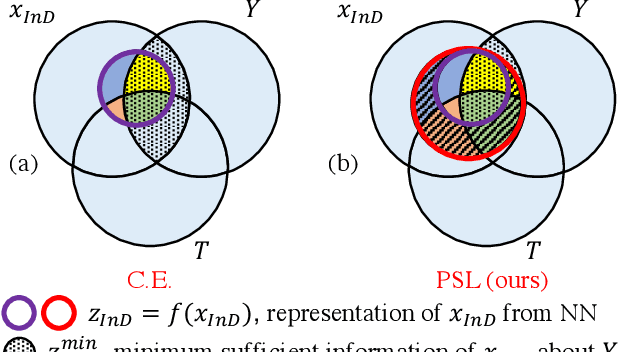
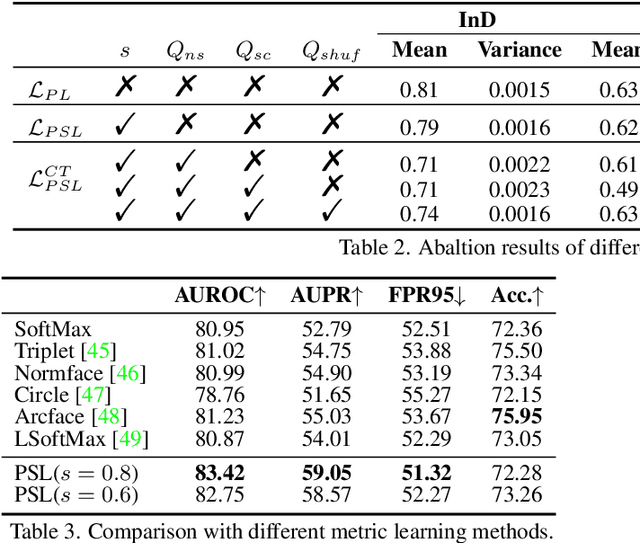
Open-set action recognition is to reject unknown human action cases which are out of the distribution of the training set. Existing methods mainly focus on learning better uncertainty scores but dismiss the importance of feature representations. We find that features with richer semantic diversity can significantly improve the open-set performance under the same uncertainty scores. In this paper, we begin with analyzing the feature representation behavior in the open-set action recognition (OSAR) problem based on the information bottleneck (IB) theory, and propose to enlarge the instance-specific (IS) and class-specific (CS) information contained in the feature for better performance. To this end, a novel Prototypical Similarity Learning (PSL) framework is proposed to keep the instance variance within the same class to retain more IS information. Besides, we notice that unknown samples sharing similar appearances to known samples are easily misclassified as known classes. To alleviate this issue, video shuffling is further introduced in our PSL to learn distinct temporal information between original and shuffled samples, which we find enlarges the CS information. Extensive experiments demonstrate that the proposed PSL can significantly boost both the open-set and closed-set performance and achieves state-of-the-art results on multiple benchmarks. Code is available at https://github.com/Jun-CEN/PSL.
Fast Empirical Scenarios
Jul 08, 2023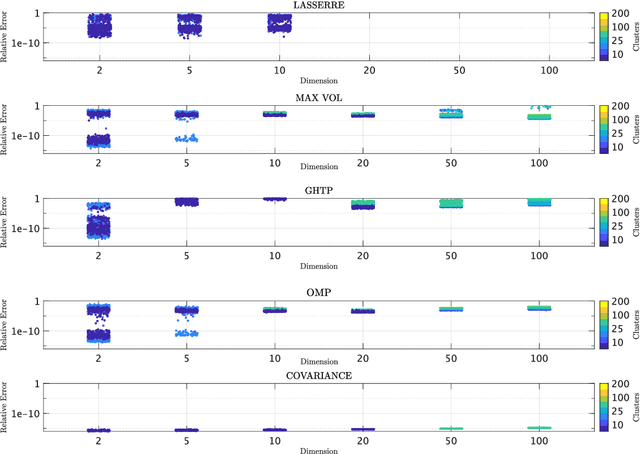
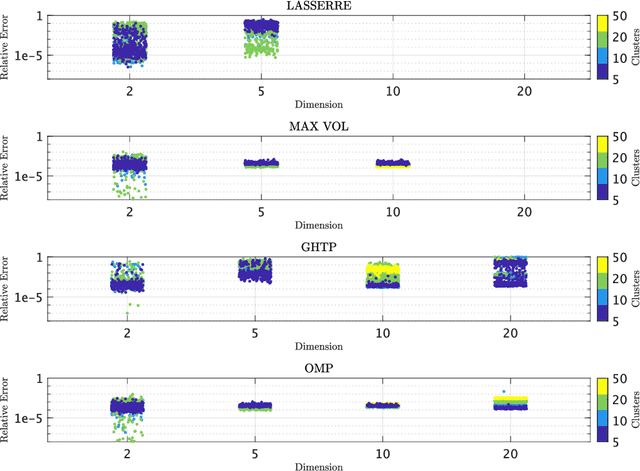
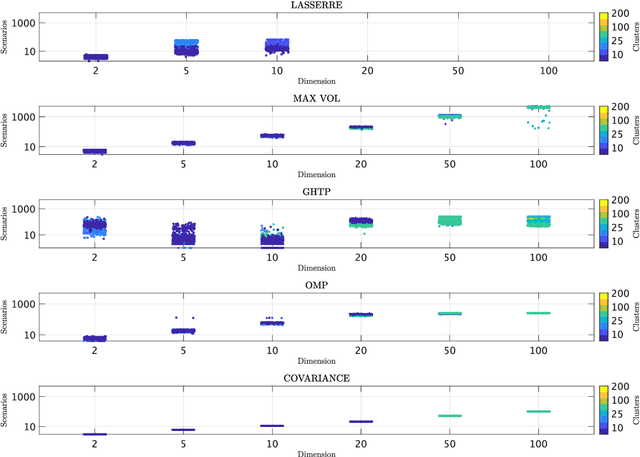
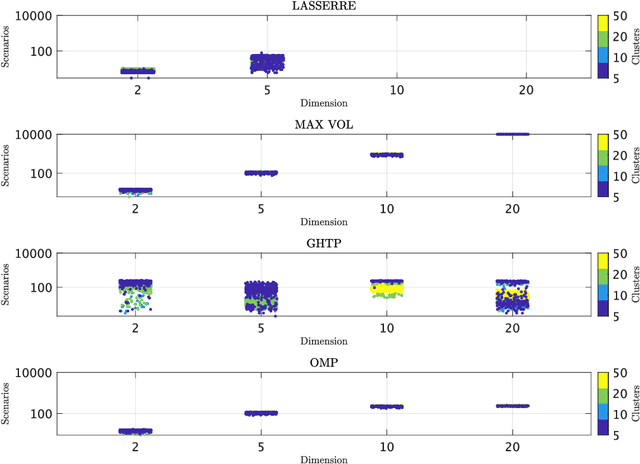
We seek to extract a small number of representative scenarios from large and high-dimensional panel data that are consistent with sample moments. Among two novel algorithms, the first identifies scenarios that have not been observed before, and comes with a scenario-based representation of covariance matrices. The second proposal picks important data points from states of the world that have already realized, and are consistent with higher-order sample moment information. Both algorithms are efficient to compute, and lend themselves to consistent scenario-based modeling and high-dimensional numerical integration. Extensive numerical benchmarking studies and an application in portfolio optimization favor the proposed algorithms.