 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph-Ensemble Learning Model for Multi-label Skin Lesion Classification using Dermoscopy and Clinical Images
Jul 04, 2023
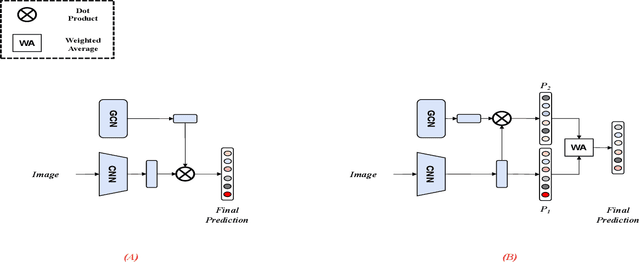
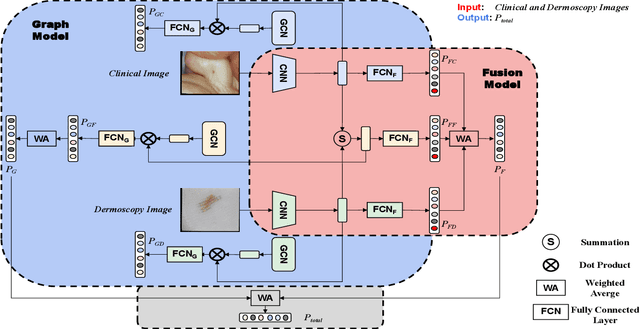
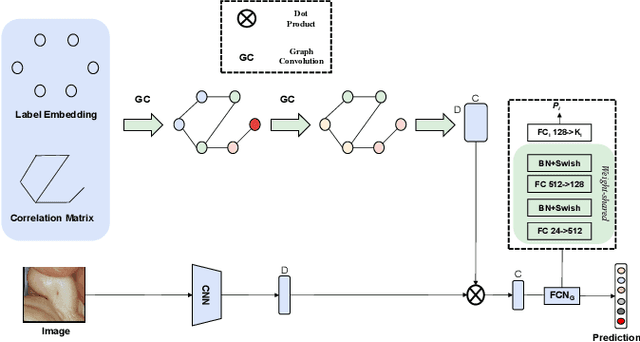
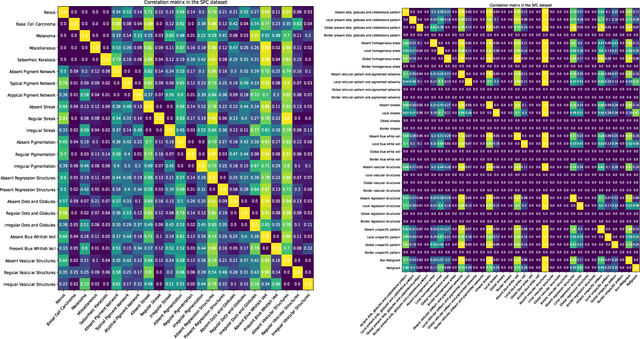
Many skin lesion analysis (SLA) methods recently focused on developing a multi-modal-based multi-label classification method due to two factors. The first is multi-modal data, i.e., clinical and dermoscopy images, which can provide complementary information to obtain more accurate results than single-modal data. The second one is that multi-label classification, i.e., seven-point checklist (SPC) criteria as an auxiliary classification task can not only boost the diagnostic accuracy of melanoma in the deep learning (DL) pipeline but also provide more useful functions to the clinical doctor as it is commonly used in clinical dermatologist's diagnosis. However, most methods only focus on designing a better module for multi-modal data fusion; few methods explore utilizing the label correlation between SPC and skin disease for performance improvement. This study fills the gap that introduces a Graph Convolution Network (GCN) to exploit prior co-occurrence between each category as a correlation matrix into the DL model for the multi-label classification. However, directly applying GCN degraded the performances in our experiments; we attribute this to the weak generalization ability of GCN in the scenario of insufficient statistical samples of medical data. We tackle this issue by proposing a Graph-Ensemble Learning Model (GELN) that views the prediction from GCN as complementary information of the predictions from the fusion model and adaptively fuses them by a weighted averaging scheme, which can utilize the valuable information from GCN while avoiding its negative influences as much as possible. To evaluate our method, we conduct experiments on public datasets. The results illustrate that our GELN can consistently improve the classification performance on different datasets and that the proposed method can achieve state-of-the-art performance in SPC and diagnosis classification.
SegNetr: Rethinking the local-global interactions and skip connections in U-shaped networks
Jul 06, 2023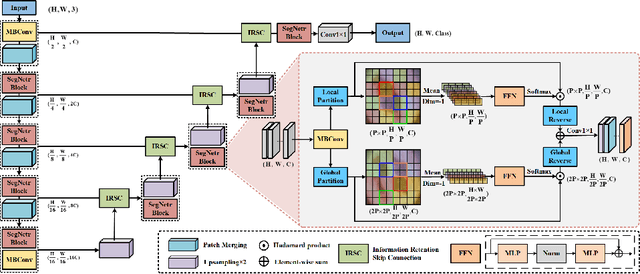
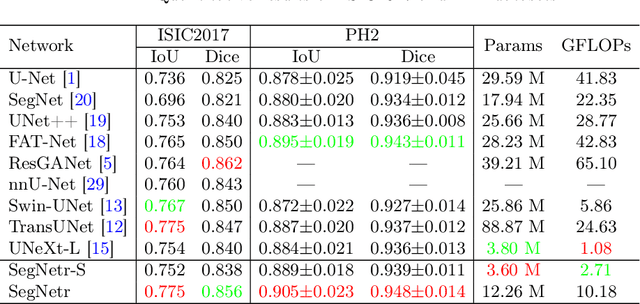
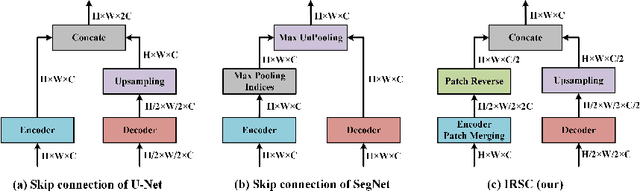
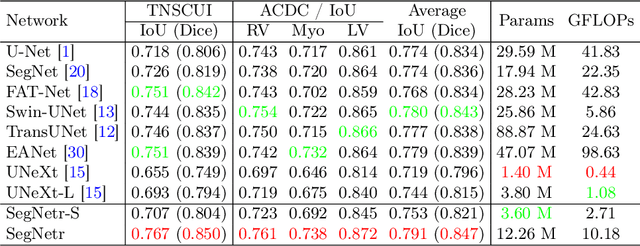
Recently, U-shaped networks have dominated the field of medical image segmentation due to their simple and easily tuned structure. However, existing U-shaped segmentation networks: 1) mostly focus on designing complex self-attention modules to compensate for the lack of long-term dependence based on convolution operation, which increases the overall number of parameters and computational complexity of the network; 2) simply fuse the features of encoder and decoder, ignoring the connection between their spatial locations. In this paper, we rethink the above problem and build a lightweight medical image segmentation network, called SegNetr. Specifically, we introduce a novel SegNetr block that can perform local-global interactions dynamically at any stage and with only linear complexity. At the same time, we design a general information retention skip connection (IRSC) to preserve the spatial location information of encoder features and achieve accurate fusion with the decoder features. We validate the effectiveness of SegNetr on four mainstream medical image segmentation datasets, with 59\% and 76\% fewer parameters and GFLOPs than vanilla U-Net, while achieving segmentation performance comparable to state-of-the-art methods. Notably, the components proposed in this paper can be applied to other U-shaped networks to improve their segmentation performance.
Recognition and Estimation of Human Finger Pointing with an RGB Camera for Robot Directive
Jul 06, 2023

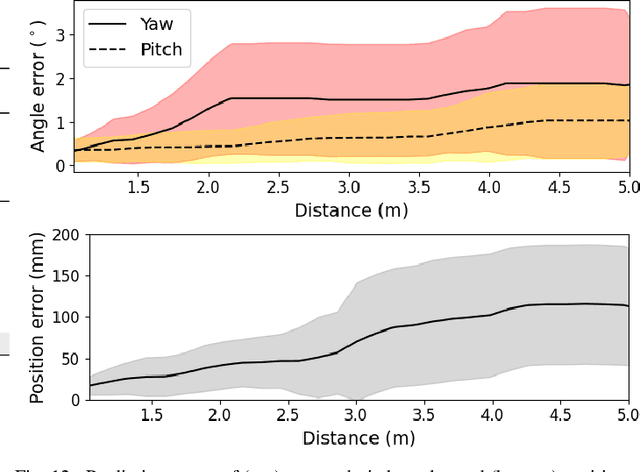
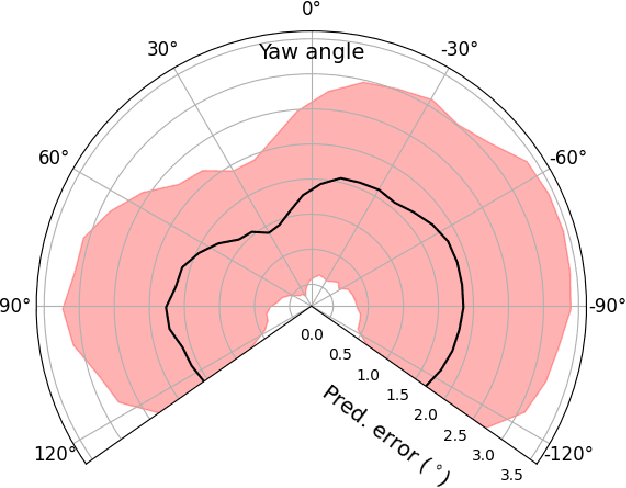
In communication between humans, gestures are often preferred or complementary to verbal expression since the former offers better spatial referral. Finger pointing gesture conveys vital information regarding some point of interest in the environment. In human-robot interaction, a user can easily direct a robot to a target location, for example, in search and rescue or factory assistance. State-of-the-art approaches for visual pointing estimation often rely on depth cameras, are limited to indoor environments and provide discrete predictions between limited targets. In this paper, we explore the learning of models for robots to understand pointing directives in various indoor and outdoor environments solely based on a single RGB camera. A novel framework is proposed which includes a designated model termed PointingNet. PointingNet recognizes the occurrence of pointing followed by approximating the position and direction of the index finger. The model relies on a novel segmentation model for masking any lifted arm. While state-of-the-art human pose estimation models provide poor pointing angle estimation accuracy of 28deg, PointingNet exhibits mean accuracy of less than 2deg. With the pointing information, the target is computed followed by planning and motion of the robot. The framework is evaluated on two robotic systems yielding accurate target reaching.
Distributed fusion filter over lossy wireless sensor networks with the presence of non-Gaussian noise
Jul 04, 2023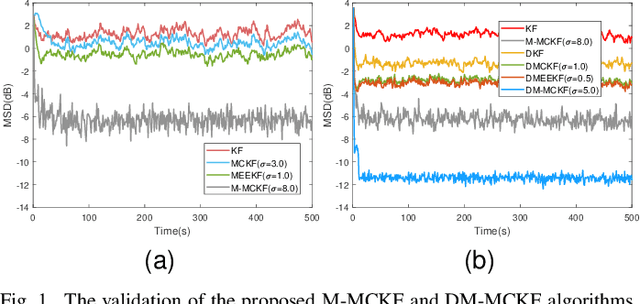
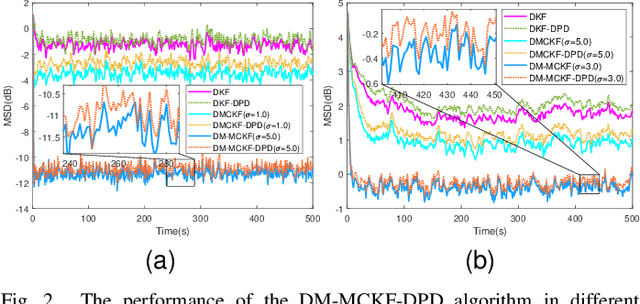
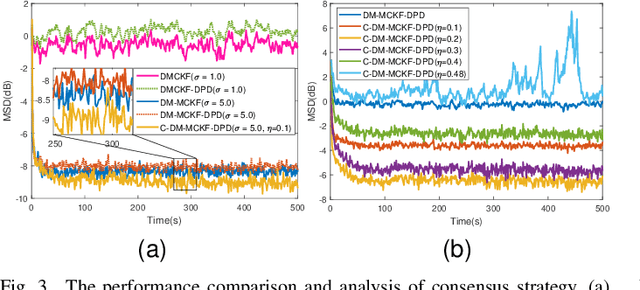
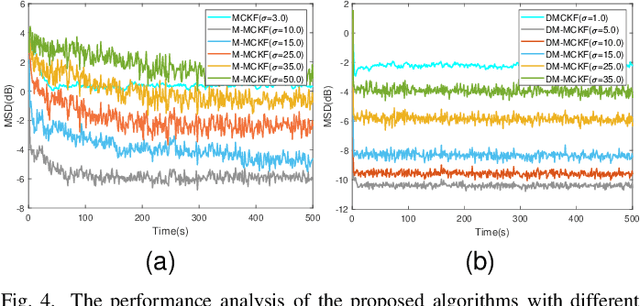
The information transmission between nodes in a wireless sensor networks (WSNs) often causes packet loss due to denial-of-service (DoS) attack, energy limitations, and environmental factors, and the information that is successfully transmitted can also be contaminated by non-Gaussian noise. The presence of these two factors poses a challenge for distributed state estimation (DSE) over WSNs. In this paper, a generalized packet drop model is proposed to describe the packet loss phenomenon caused by DoS attacks and other factors. Moreover, a modified maximum correntropy Kalman filter is given, and it is extended to distributed form (DM-MCKF). In addition, a distributed modified maximum correntropy Kalman filter incorporating the generalized data packet drop (DM-MCKF-DPD) algorithm is provided to implement DSE with the presence of both non-Gaussian noise pollution and packet drop. A sufficient condition to ensure the convergence of the fixed-point iterative process of the DM-MCKF-DPD algorithm is presented and the computational complexity of the DM-MCKF-DPD algorithm is analyzed. Finally, the effectiveness and feasibility of the proposed algorithms are verified by simulations.
Multilingual Controllable Transformer-Based Lexical Simplification
Jul 05, 2023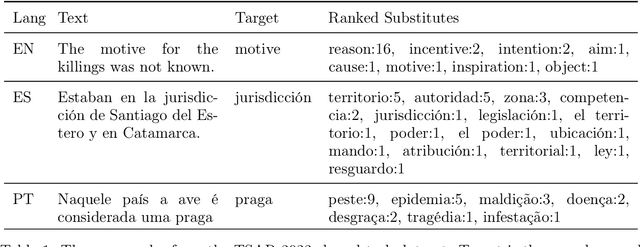

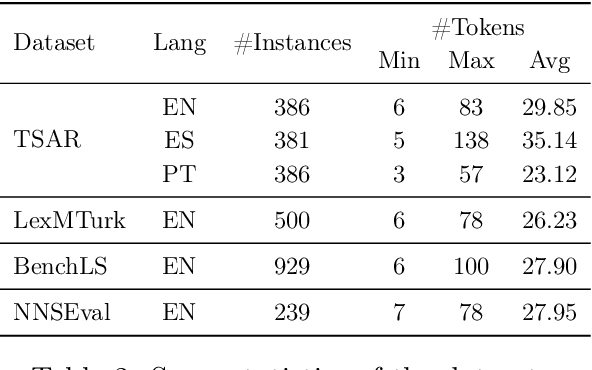

Text is by far the most ubiquitous source of knowledge and information and should be made easily accessible to as many people as possible; however, texts often contain complex words that hinder reading comprehension and accessibility. Therefore, suggesting simpler alternatives for complex words without compromising meaning would help convey the information to a broader audience. This paper proposes mTLS, a multilingual controllable Transformer-based Lexical Simplification (LS) system fined-tuned with the T5 model. The novelty of this work lies in the use of language-specific prefixes, control tokens, and candidates extracted from pre-trained masked language models to learn simpler alternatives for complex words. The evaluation results on three well-known LS datasets -- LexMTurk, BenchLS, and NNSEval -- show that our model outperforms the previous state-of-the-art models like LSBert and ConLS. Moreover, further evaluation of our approach on the part of the recent TSAR-2022 multilingual LS shared-task dataset shows that our model performs competitively when compared with the participating systems for English LS and even outperforms the GPT-3 model on several metrics. Moreover, our model obtains performance gains also for Spanish and Portuguese.
Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery
May 01, 2023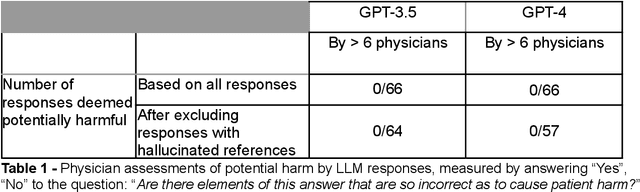
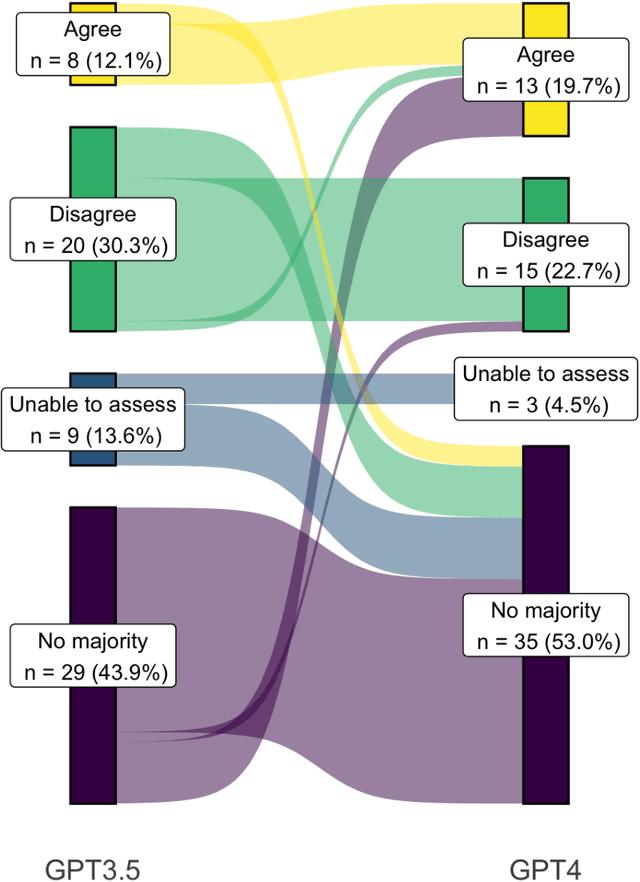
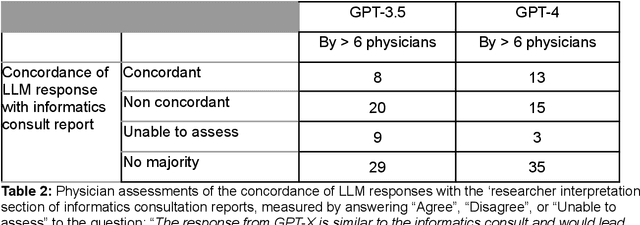
Despite growing interest in using large language models (LLMs) in healthcare, current explorations do not assess the real-world utility and safety of LLMs in clinical settings. Our objective was to determine whether two LLMs can serve information needs submitted by physicians as questions to an informatics consultation service in a safe and concordant manner. Sixty six questions from an informatics consult service were submitted to GPT-3.5 and GPT-4 via simple prompts. 12 physicians assessed the LLM responses' possibility of patient harm and concordance with existing reports from an informatics consultation service. Physician assessments were summarized based on majority vote. For no questions did a majority of physicians deem either LLM response as harmful. For GPT-3.5, responses to 8 questions were concordant with the informatics consult report, 20 discordant, and 9 were unable to be assessed. There were 29 responses with no majority on "Agree", "Disagree", and "Unable to assess". For GPT-4, responses to 13 questions were concordant, 15 discordant, and 3 were unable to be assessed. There were 35 responses with no majority. Responses from both LLMs were largely devoid of overt harm, but less than 20% of the responses agreed with an answer from an informatics consultation service, responses contained hallucinated references, and physicians were divided on what constitutes harm. These results suggest that while general purpose LLMs are able to provide safe and credible responses, they often do not meet the specific information need of a given question. A definitive evaluation of the usefulness of LLMs in healthcare settings will likely require additional research on prompt engineering, calibration, and custom-tailoring of general purpose models.
Accurate deep learning sub-grid scale models for large eddy simulations
Jul 19, 2023We present two families of sub-grid scale (SGS) turbulence models developed for large-eddy simulation (LES) purposes. Their development required the formulation of physics-informed robust and efficient Deep Learning (DL) algorithms which, unlike state-of-the-art analytical modeling techniques can produce high-order complex non-linear relations between inputs and outputs. Explicit filtering of data from direct simulations of the canonical channel flow at two friction Reynolds numbers $Re_\tau\approx 395$ and 590 provided accurate data for training and testing. The two sets of models use different network architectures. One of the architectures uses tensor basis neural networks (TBNN) and embeds the simplified analytical model form of the general effective-viscosity hypothesis, thus incorporating the Galilean, rotational and reflectional invariances. The other architecture is that of a relatively simple network, that is able to incorporate the Galilean invariance only. However, this simpler architecture has better feature extraction capacity owing to its ability to establish relations between and extract information from cross-components of the integrity basis tensors and the SGS stresses. Both sets of models are used to predict the SGS stresses for feature datasets generated with different filter widths, and at different Reynolds numbers. It is shown that due to the simpler model's better feature learning capabilities, it outperforms the invariance embedded model in statistical performance metrics. In a priori tests, both sets of models provide similar levels of dissipation and backscatter. Based on the test results, both sets of models should be usable in a posteriori actual LESs.
Pathway toward prior knowledge-integrated machine learning in engineering
Jul 10, 2023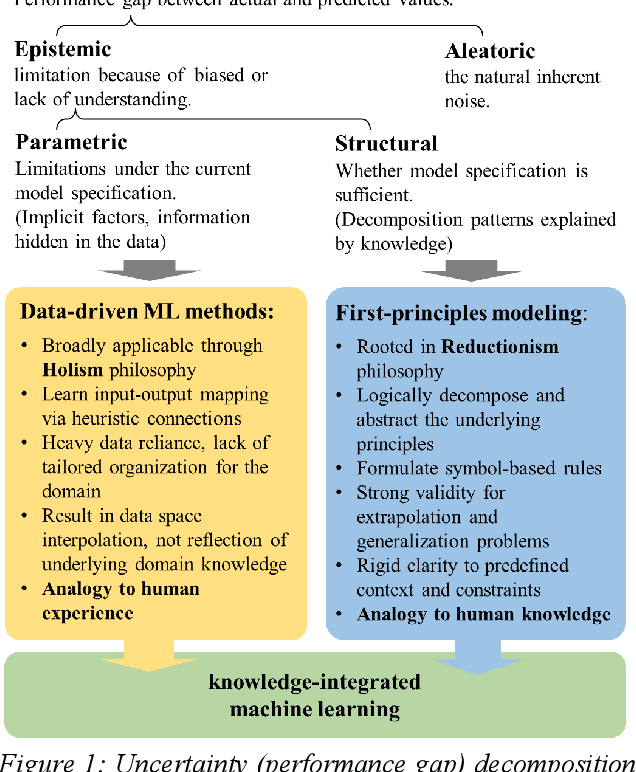
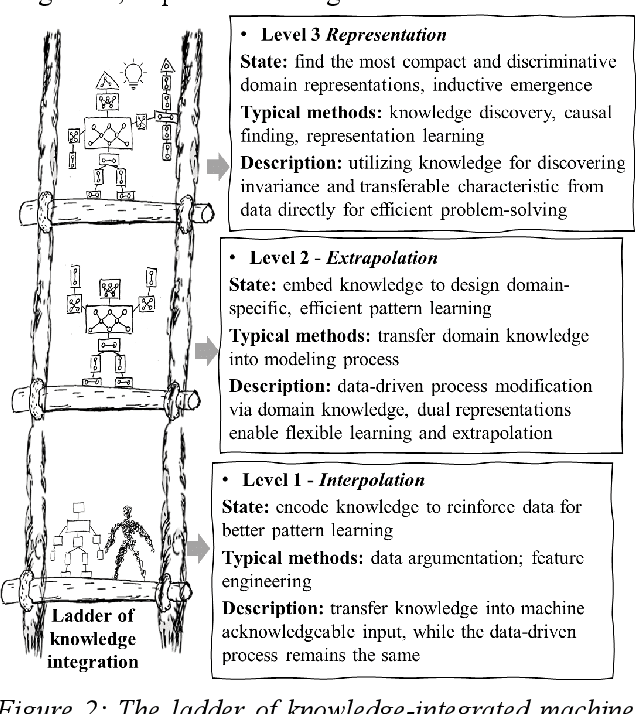
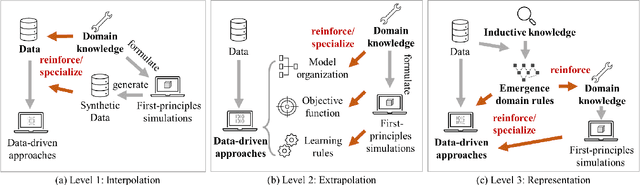
Despite the digitalization trend and data volume surge, first-principles models (also known as logic-driven, physics-based, rule-based, or knowledge-based models) and data-driven approaches have existed in parallel, mirroring the ongoing AI debate on symbolism versus connectionism. Research for process development to integrate both sides to transfer and utilize domain knowledge in the data-driven process is rare. This study emphasizes efforts and prevailing trends to integrate multidisciplinary domain professions into machine acknowledgeable, data-driven processes in a two-fold organization: examining information uncertainty sources in knowledge representation and exploring knowledge decomposition with a three-tier knowledge-integrated machine learning paradigm. This approach balances holist and reductionist perspectives in the engineering domain.
GraSS: Contrastive Learning with Gradient Guided Sampling Strategy for Remote Sensing Image Semantic Segmentation
Jul 03, 2023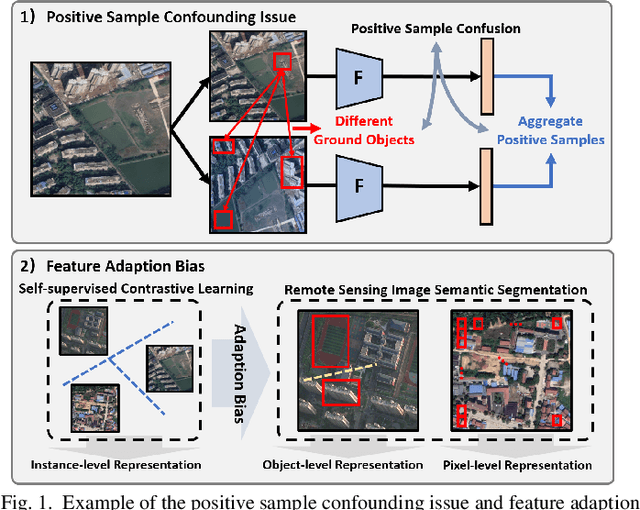
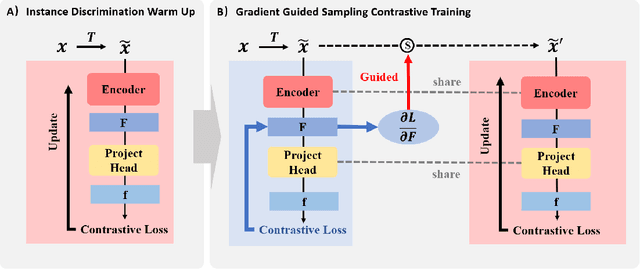
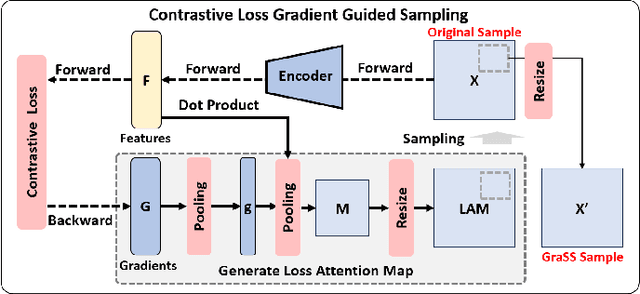
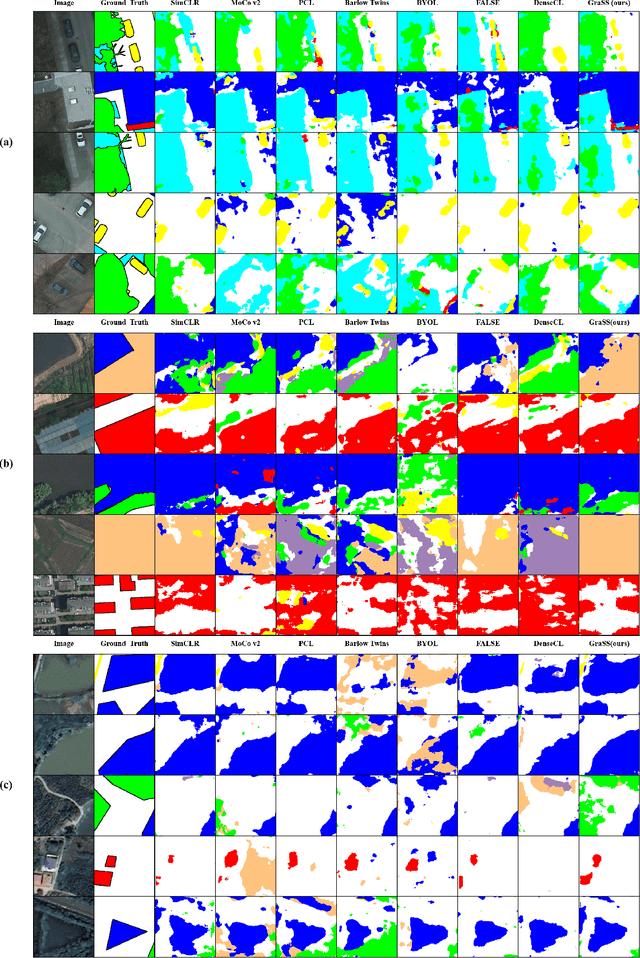
Self-supervised contrastive learning (SSCL) has achieved significant milestones in remote sensing image (RSI) understanding. Its essence lies in designing an unsupervised instance discrimination pretext task to extract image features from a large number of unlabeled images that are beneficial for downstream tasks. However, existing instance discrimination based SSCL suffer from two limitations when applied to the RSI semantic segmentation task: 1) Positive sample confounding issue; 2) Feature adaptation bias. It introduces a feature adaptation bias when applied to semantic segmentation tasks that require pixel-level or object-level features. In this study, We observed that the discrimination information can be mapped to specific regions in RSI through the gradient of unsupervised contrastive loss, these specific regions tend to contain singular ground objects. Based on this, we propose contrastive learning with Gradient guided Sampling Strategy (GraSS) for RSI semantic segmentation. GraSS consists of two stages: Instance Discrimination warm-up (ID warm-up) and Gradient guided Sampling contrastive training (GS training). The ID warm-up aims to provide initial discrimination information to the contrastive loss gradients. The GS training stage aims to utilize the discrimination information contained in the contrastive loss gradients and adaptively select regions in RSI patches that contain more singular ground objects, in order to construct new positive and negative samples. Experimental results on three open datasets demonstrate that GraSS effectively enhances the performance of SSCL in high-resolution RSI semantic segmentation. Compared to seven baseline methods from five different types of SSCL, GraSS achieves an average improvement of 1.57\% and a maximum improvement of 3.58\% in terms of mean intersection over the union. The source code is available at https://github.com/GeoX-Lab/GraSS
Deep learning for dynamic graphs: models and benchmarks
Jul 12, 2023
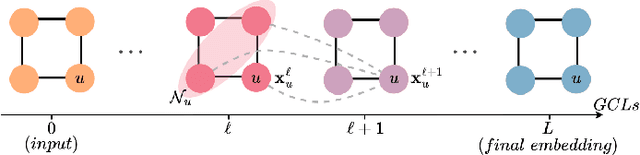
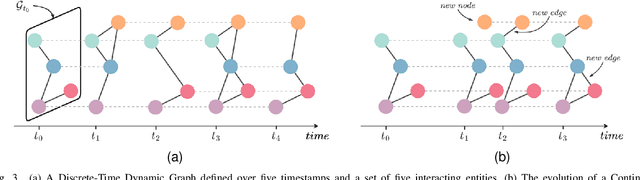
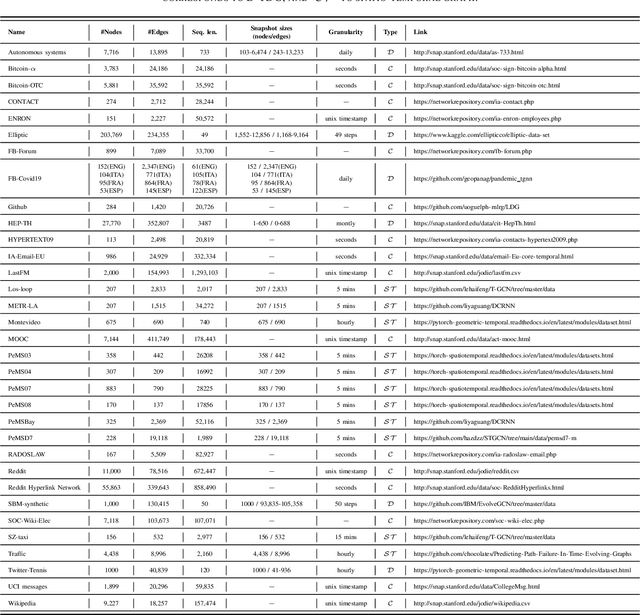
Recent progress in research on Deep Graph Networks (DGNs) has led to a maturation of the domain of learning on graphs. Despite the growth of this research field, there are still important challenges that are yet unsolved. Specifically, there is an urge of making DGNs suitable for predictive tasks on realworld systems of interconnected entities, which evolve over time. With the aim of fostering research in the domain of dynamic graphs, at first, we survey recent advantages in learning both temporal and spatial information, providing a comprehensive overview of the current state-of-the-art in the domain of representation learning for dynamic graphs. Secondly, we conduct a fair performance comparison among the most popular proposed approaches, leveraging rigorous model selection and assessment for all the methods, thus establishing a sound baseline for evaluating new architectures and approaches