 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Referring Video Object Segmentation with Inter-Frame Interaction and Cross-Modal Correlation
Jul 02, 2023
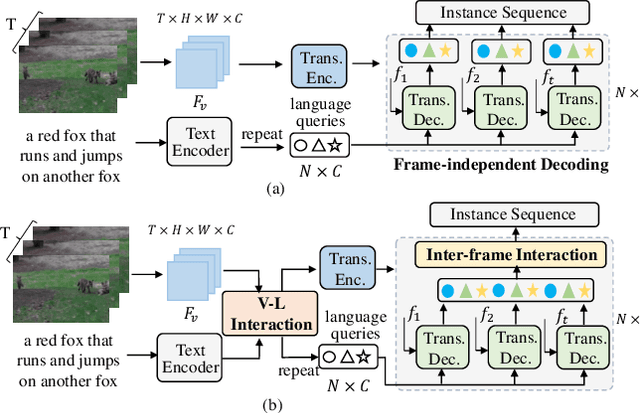
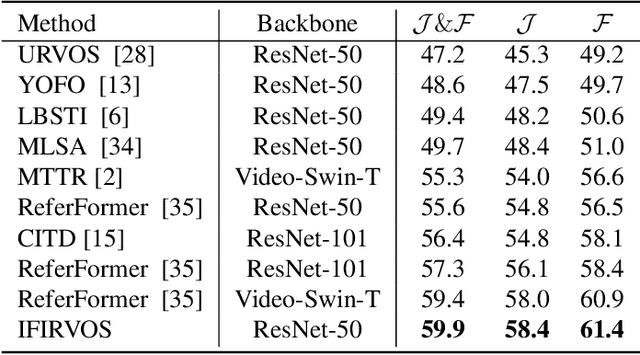
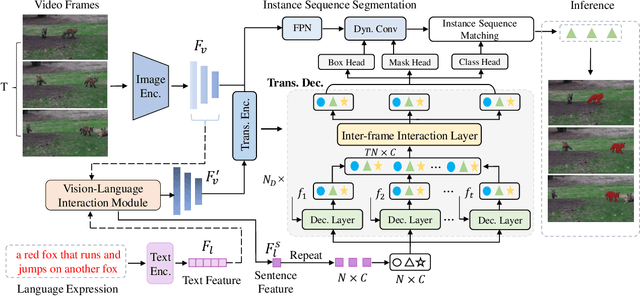
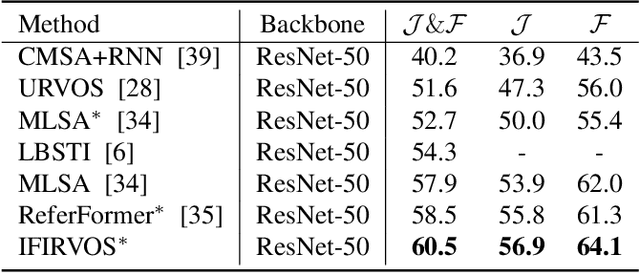
Referring video object segmentation (RVOS) aims to segment the target object in a video sequence described by a language expression. Typical query-based methods process the video sequence in a frame-independent manner to reduce the high computational cost, which however affects the performance due to the lack of inter-frame interaction for temporal coherence modeling and spatio-temporal representation learning of the referred object. Besides, they directly adopt the raw and high-level sentence feature as the language queries to decode the visual features, where the weak correlation between visual and linguistic features also increases the difficulty of decoding the target information and limits the performance of the model. In this paper, we proposes a novel RVOS framework, dubbed IFIRVOS, to address these issues. Specifically, we design a plug-and-play inter-frame interaction module in the Transformer decoder to efficiently learn the spatio-temporal features of the referred object, so as to decode the object information in the video sequence more precisely and generate more accurate segmentation results. Moreover, we devise the vision-language interaction module before the multimodal Transformer to enhance the correlation between the visual and linguistic features, thus facilitating the process of decoding object information from visual features by language queries in Transformer decoder and improving the segmentation performance. Extensive experimental results on three benchmarks validate the superiority of our IFIRVOS over state-of-the-art methods and the effectiveness of our proposed modules.
VS-TransGRU: A Novel Transformer-GRU-based Framework Enhanced by Visual-Semantic Fusion for Egocentric Action Anticipation
Jul 08, 2023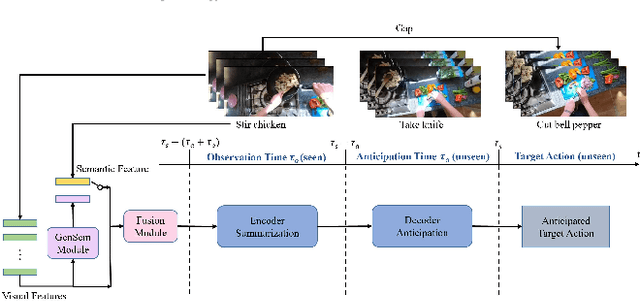
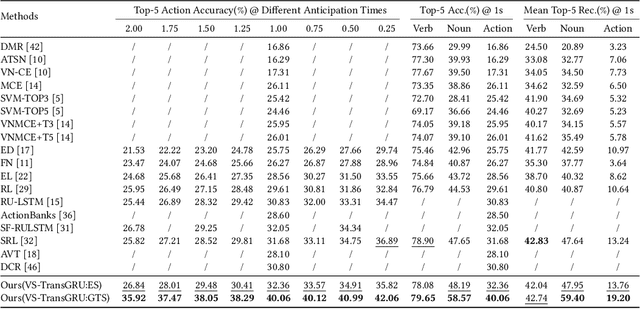

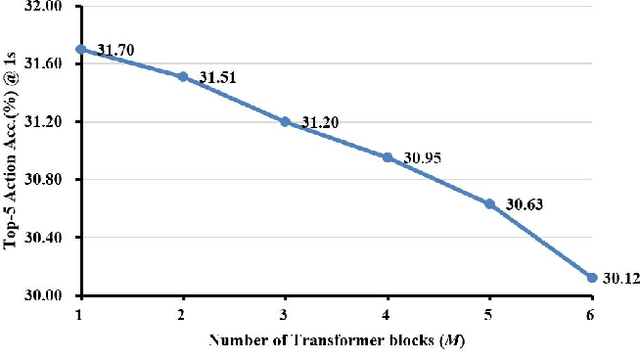
Egocentric action anticipation is a challenging task that aims to make advanced predictions of future actions from current and historical observations in the first-person view. Most existing methods focus on improving the model architecture and loss function based on the visual input and recurrent neural network to boost the anticipation performance. However, these methods, which merely consider visual information and rely on a single network architecture, gradually reach a performance plateau. In order to fully understand what has been observed and capture the dependencies between current observations and future actions well enough, we propose a novel visual-semantic fusion enhanced and Transformer GRU-based action anticipation framework in this paper. Firstly, high-level semantic information is introduced to improve the performance of action anticipation for the first time. We propose to use the semantic features generated based on the class labels or directly from the visual observations to augment the original visual features. Secondly, an effective visual-semantic fusion module is proposed to make up for the semantic gap and fully utilize the complementarity of different modalities. Thirdly, to take advantage of both the parallel and autoregressive models, we design a Transformer based encoder for long-term sequential modeling and a GRU-based decoder for flexible iteration decoding. Extensive experiments on two large-scale first-person view datasets, i.e., EPIC-Kitchens and EGTEA Gaze+, validate the effectiveness of our proposed method, which achieves new state-of-the-art performance, outperforming previous approaches by a large margin.
Enhancing Job Recommendation through LLM-based Generative Adversarial Networks
Jul 20, 2023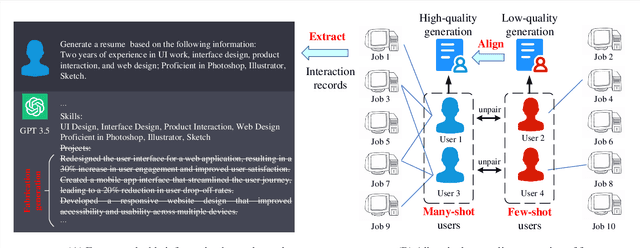
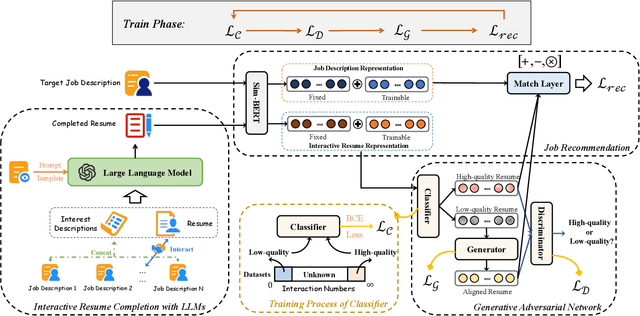
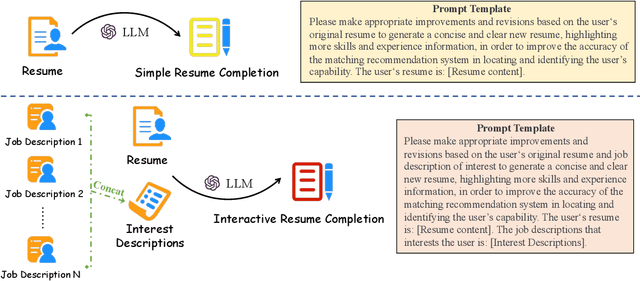
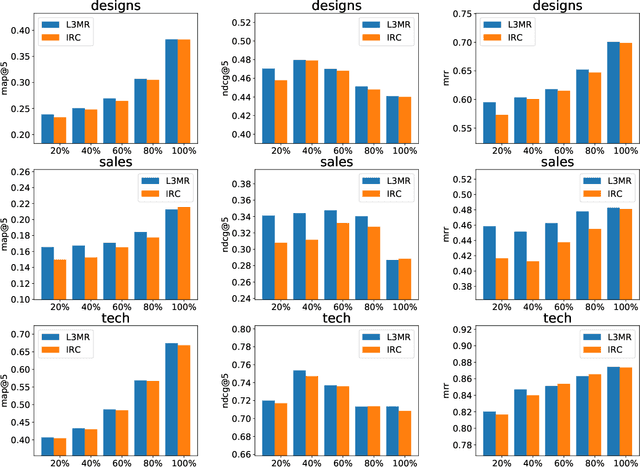
Recommending suitable jobs to users is a critical task in online recruitment platforms, as it can enhance users' satisfaction and the platforms' profitability. While existing job recommendation methods encounter challenges such as the low quality of users' resumes, which hampers their accuracy and practical effectiveness. With the rapid development of large language models (LLMs), utilizing the rich external knowledge encapsulated within them, as well as their powerful capabilities of text processing and reasoning, is a promising way to complete users' resumes for more accurate recommendations. However, directly leveraging LLMs to enhance recommendation results is not a one-size-fits-all solution, as LLMs may suffer from fabricated generation and few-shot problems, which degrade the quality of resume completion. In this paper, we propose a novel LLM-based approach for job recommendation. To alleviate the limitation of fabricated generation for LLMs, we extract accurate and valuable information beyond users' self-description, which helps the LLMs better profile users for resume completion. Specifically, we not only extract users' explicit properties (e.g., skills, interests) from their self-description but also infer users' implicit characteristics from their behaviors for more accurate and meaningful resume completion. Nevertheless, some users still suffer from few-shot problems, which arise due to scarce interaction records, leading to limited guidance for the models in generating high-quality resumes. To address this issue, we propose aligning unpaired low-quality with high-quality generated resumes by Generative Adversarial Networks (GANs), which can refine the resume representations for better recommendation results. Extensive experiments on three large real-world recruitment datasets demonstrate the effectiveness of our proposed method.
AE-RED: A Hyperspectral Unmixing Framework Powered by Deep Autoencoder and Regularization by Denoising
Jul 01, 2023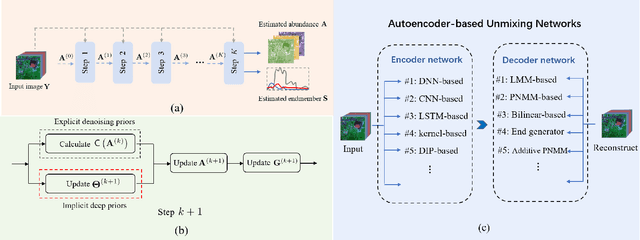
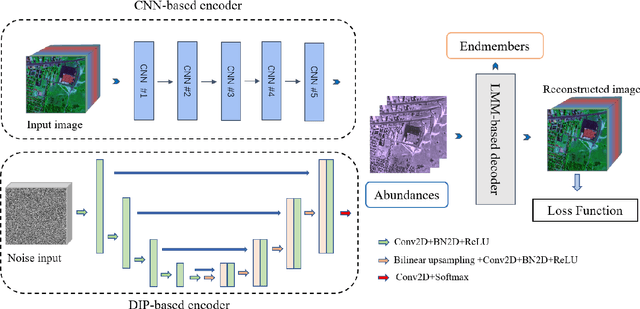
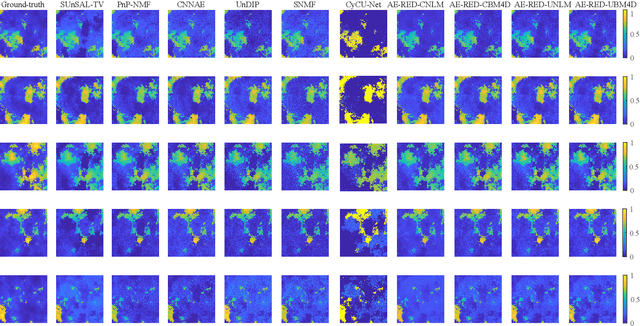
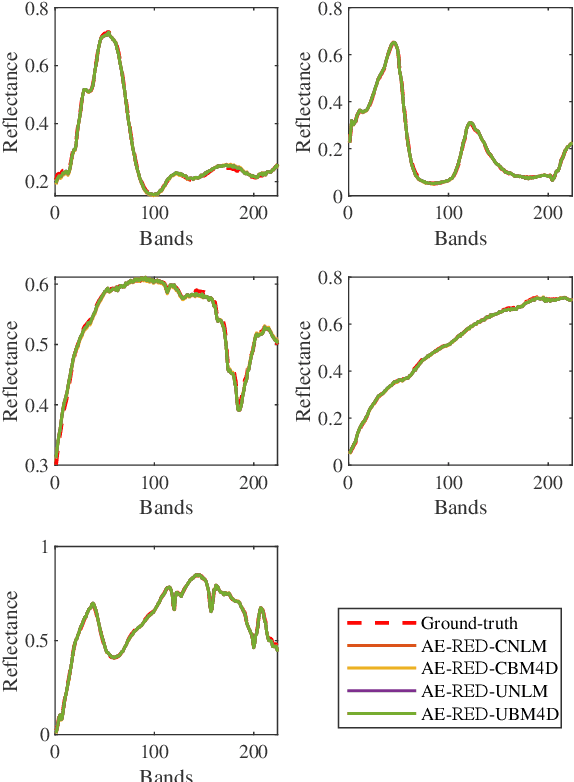
Spectral unmixing has been extensively studied with a variety of methods and used in many applications. Recently, data-driven techniques with deep learning methods have obtained great attention to spectral unmixing for its superior learning ability to automatically learn the structure information. In particular, autoencoder based architectures are elaborately designed to solve blind unmixing and model complex nonlinear mixtures. Nevertheless, these methods perform unmixing task as blackboxes and lack of interpretability. On the other hand, conventional unmixing methods carefully design the regularizer to add explicit information, in which algorithms such as plug-and-play (PnP) strategies utilize off-the-shelf denoisers to plug powerful priors. In this paper, we propose a generic unmixing framework to integrate the autoencoder network with regularization by denoising (RED), named AE-RED. More specially, we decompose the unmixing optimized problem into two subproblems. The first one is solved using deep autoencoders to implicitly regularize the estimates and model the mixture mechanism. The second one leverages the denoiser to bring in the explicit information. In this way, both the characteristics of the deep autoencoder based unmixing methods and priors provided by denoisers are merged into our well-designed framework to enhance the unmixing performance. Experiment results on both synthetic and real data sets show the superiority of our proposed framework compared with state-of-the-art unmixing approaches.
LasUIE: Unifying Information Extraction with Latent Adaptive Structure-aware Generative Language Model
Apr 13, 2023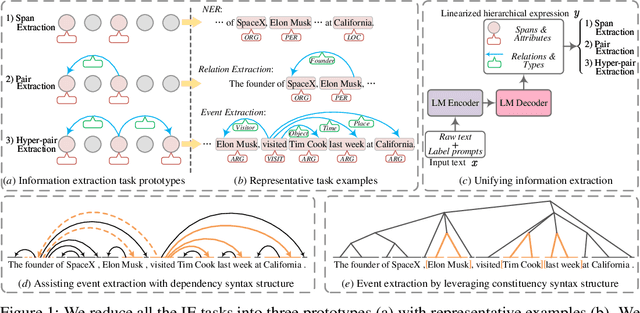
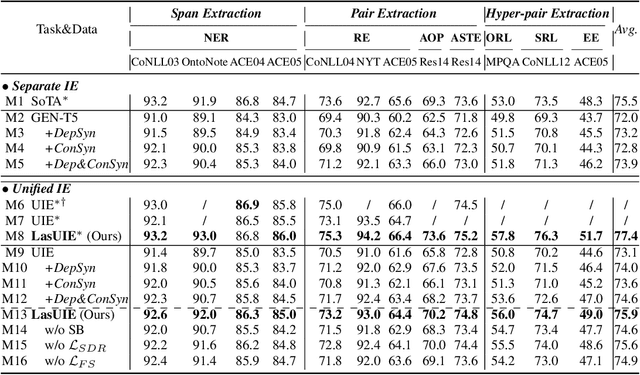
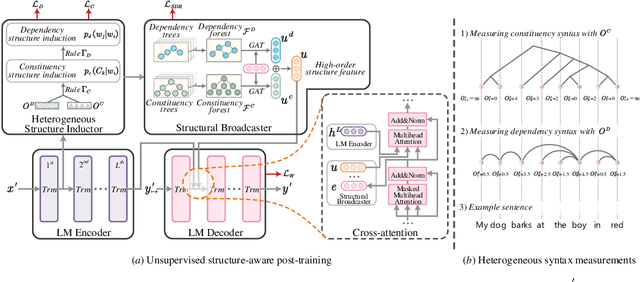
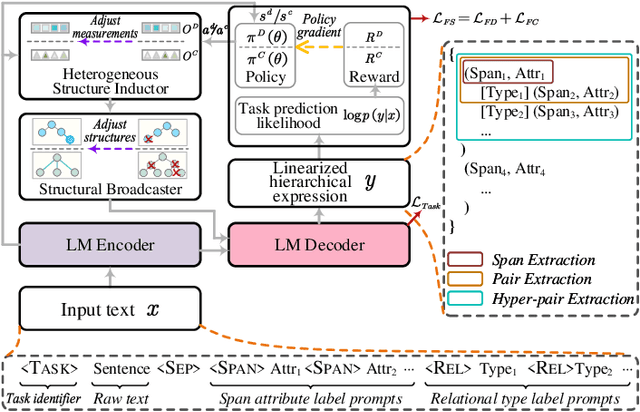
Universally modeling all typical information extraction tasks (UIE) with one generative language model (GLM) has revealed great potential by the latest study, where various IE predictions are unified into a linearized hierarchical expression under a GLM. Syntactic structure information, a type of effective feature which has been extensively utilized in IE community, should also be beneficial to UIE. In this work, we propose a novel structure-aware GLM, fully unleashing the power of syntactic knowledge for UIE. A heterogeneous structure inductor is explored to unsupervisedly induce rich heterogeneous structural representations by post-training an existing GLM. In particular, a structural broadcaster is devised to compact various latent trees into explicit high-order forests, helping to guide a better generation during decoding. We finally introduce a task-oriented structure fine-tuning mechanism, further adjusting the learned structures to most coincide with the end-task's need. Over 12 IE benchmarks across 7 tasks our system shows significant improvements over the baseline UIE system. Further in-depth analyses show that our GLM learns rich task-adaptive structural bias that greatly resolves the UIE crux, the long-range dependence issue and boundary identifying. Source codes are open at https://github.com/ChocoWu/LasUIE.
Motion Magnification in Robotic Sonography: Enabling Pulsation-Aware Artery Segmentation
Jul 07, 2023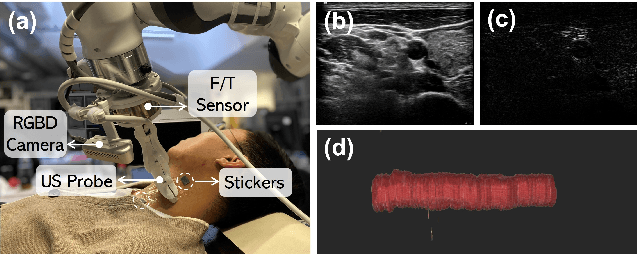
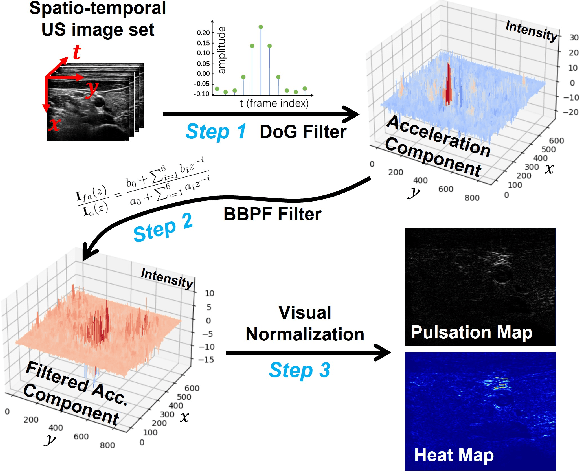
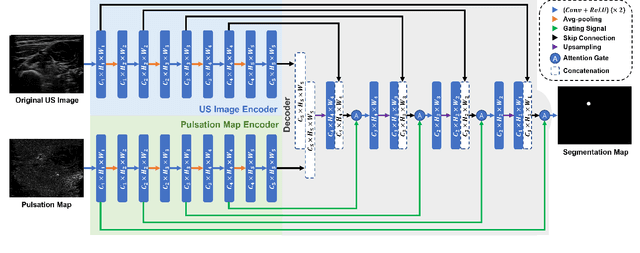
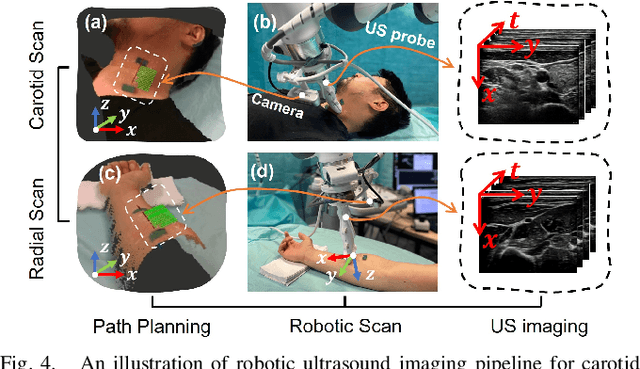
Ultrasound (US) imaging is widely used for diagnosing and monitoring arterial diseases, mainly due to the advantages of being non-invasive, radiation-free, and real-time. In order to provide additional information to assist clinicians in diagnosis, the tubular structures are often segmented from US images. To improve the artery segmentation accuracy and stability during scans, this work presents a novel pulsation-assisted segmentation neural network (PAS-NN) by explicitly taking advantage of the cardiac-induced motions. Motion magnification techniques are employed to amplify the subtle motion within the frequency band of interest to extract the pulsation signals from sequential US images. The extracted real-time pulsation information can help to locate the arteries on cross-section US images; therefore, we explicitly integrated the pulsation into the proposed PAS-NN as attention guidance. Notably, a robotic arm is necessary to provide stable movement during US imaging since magnifying the target motions from the US images captured along a scan path is not manually feasible due to the hand tremor. To validate the proposed robotic US system for imaging arteries, experiments are carried out on volunteers' carotid and radial arteries. The results demonstrated that the PAS-NN could achieve comparable results as state-of-the-art on carotid and can effectively improve the segmentation performance for small vessels (radial artery).
Incentive-Theoretic Bayesian Inference for Collaborative Science
Jul 07, 2023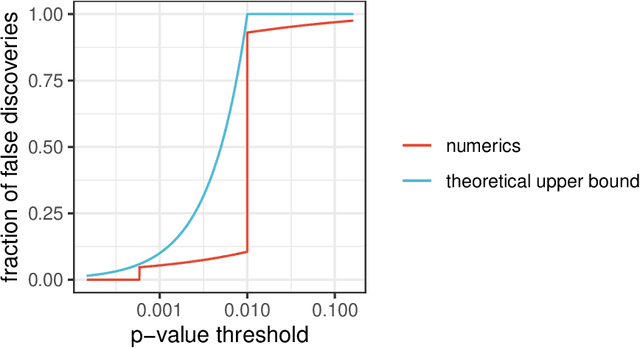

Contemporary scientific research is a distributed, collaborative endeavor, carried out by teams of researchers, regulatory institutions, funding agencies, commercial partners, and scientific bodies, all interacting with each other and facing different incentives. To maintain scientific rigor, statistical methods should acknowledge this state of affairs. To this end, we study hypothesis testing when there is an agent (e.g., a researcher or a pharmaceutical company) with a private prior about an unknown parameter and a principal (e.g., a policymaker or regulator) who wishes to make decisions based on the parameter value. The agent chooses whether to run a statistical trial based on their private prior and then the result of the trial is used by the principal to reach a decision. We show how the principal can conduct statistical inference that leverages the information that is revealed by an agent's strategic behavior -- their choice to run a trial or not. In particular, we show how the principal can design a policy to elucidate partial information about the agent's private prior beliefs and use this to control the posterior probability of the null. One implication is a simple guideline for the choice of significance threshold in clinical trials: the type-I error level should be set to be strictly less than the cost of the trial divided by the firm's profit if the trial is successful.
Making the Most Out of the Limited Context Length: Predictive Power Varies with Clinical Note Type and Note Section
Jul 13, 2023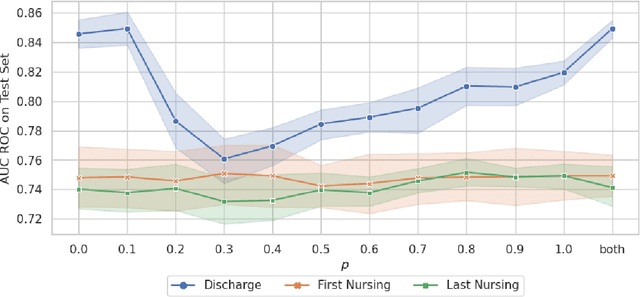
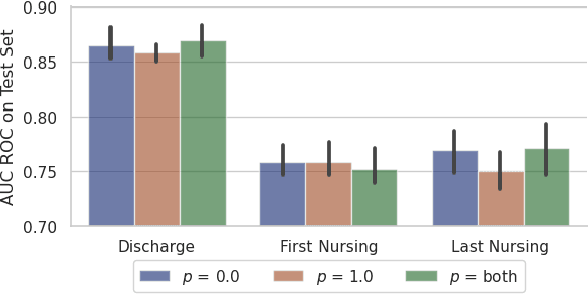
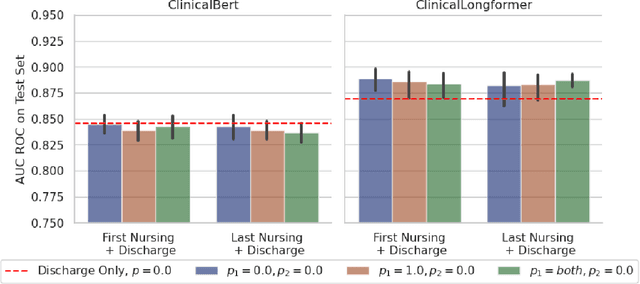
Recent advances in large language models have led to renewed interest in natural language processing in healthcare using the free text of clinical notes. One distinguishing characteristic of clinical notes is their long time span over multiple long documents. The unique structure of clinical notes creates a new design choice: when the context length for a language model predictor is limited, which part of clinical notes should we choose as the input? Existing studies either choose the inputs with domain knowledge or simply truncate them. We propose a framework to analyze the sections with high predictive power. Using MIMIC-III, we show that: 1) predictive power distribution is different between nursing notes and discharge notes and 2) combining different types of notes could improve performance when the context length is large. Our findings suggest that a carefully selected sampling function could enable more efficient information extraction from clinical notes.
* Our code is publicly available on GitHub (https://github.com/nyuolab/EfficientTransformer)
Near-Optimal Bounds for Learning Gaussian Halfspaces with Random Classification Noise
Jul 13, 2023We study the problem of learning general (i.e., not necessarily homogeneous) halfspaces with Random Classification Noise under the Gaussian distribution. We establish nearly-matching algorithmic and Statistical Query (SQ) lower bound results revealing a surprising information-computation gap for this basic problem. Specifically, the sample complexity of this learning problem is $\widetilde{\Theta}(d/\epsilon)$, where $d$ is the dimension and $\epsilon$ is the excess error. Our positive result is a computationally efficient learning algorithm with sample complexity $\tilde{O}(d/\epsilon + d/(\max\{p, \epsilon\})^2)$, where $p$ quantifies the bias of the target halfspace. On the lower bound side, we show that any efficient SQ algorithm (or low-degree test) for the problem requires sample complexity at least $\Omega(d^{1/2}/(\max\{p, \epsilon\})^2)$. Our lower bound suggests that this quadratic dependence on $1/\epsilon$ is inherent for efficient algorithms.
Graph-Ensemble Learning Model for Multi-label Skin Lesion Classification using Dermoscopy and Clinical Images
Jul 04, 2023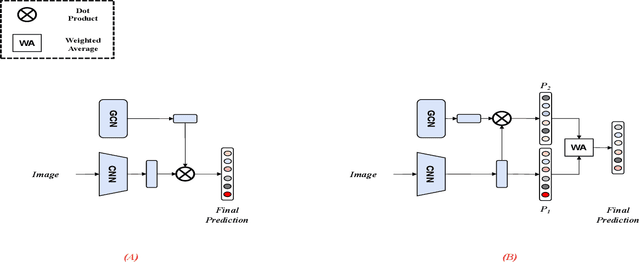
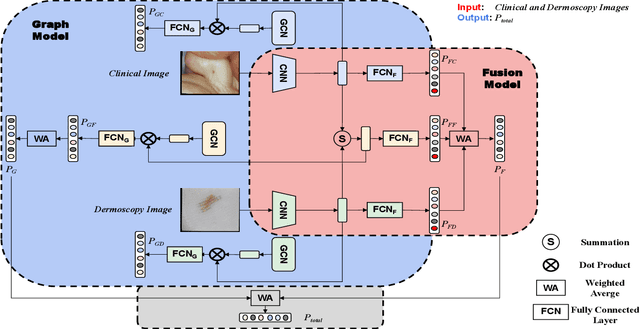
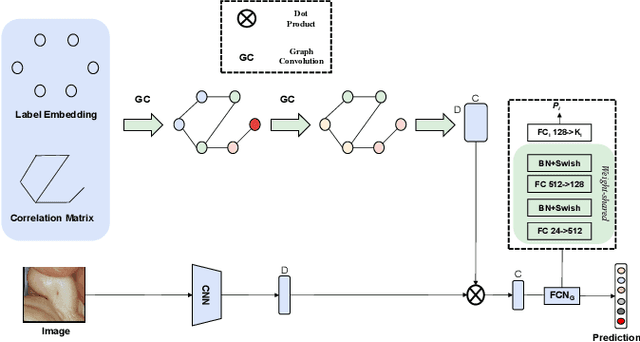
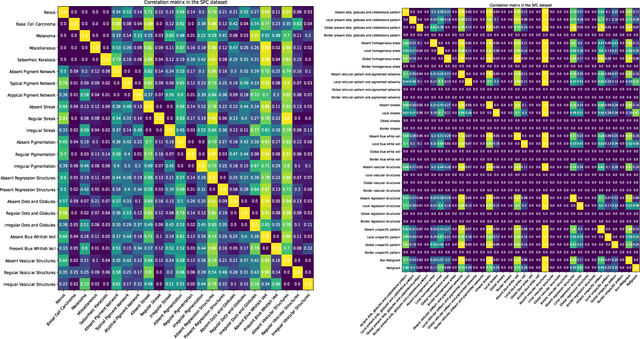
Many skin lesion analysis (SLA) methods recently focused on developing a multi-modal-based multi-label classification method due to two factors. The first is multi-modal data, i.e., clinical and dermoscopy images, which can provide complementary information to obtain more accurate results than single-modal data. The second one is that multi-label classification, i.e., seven-point checklist (SPC) criteria as an auxiliary classification task can not only boost the diagnostic accuracy of melanoma in the deep learning (DL) pipeline but also provide more useful functions to the clinical doctor as it is commonly used in clinical dermatologist's diagnosis. However, most methods only focus on designing a better module for multi-modal data fusion; few methods explore utilizing the label correlation between SPC and skin disease for performance improvement. This study fills the gap that introduces a Graph Convolution Network (GCN) to exploit prior co-occurrence between each category as a correlation matrix into the DL model for the multi-label classification. However, directly applying GCN degraded the performances in our experiments; we attribute this to the weak generalization ability of GCN in the scenario of insufficient statistical samples of medical data. We tackle this issue by proposing a Graph-Ensemble Learning Model (GELN) that views the prediction from GCN as complementary information of the predictions from the fusion model and adaptively fuses them by a weighted averaging scheme, which can utilize the valuable information from GCN while avoiding its negative influences as much as possible. To evaluate our method, we conduct experiments on public datasets. The results illustrate that our GELN can consistently improve the classification performance on different datasets and that the proposed method can achieve state-of-the-art performance in SPC and diagnosis classification.