 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mitigating Negative Transfer with Task Awareness for Sexism, Hate Speech, and Toxic Language Detection
Jul 07, 2023
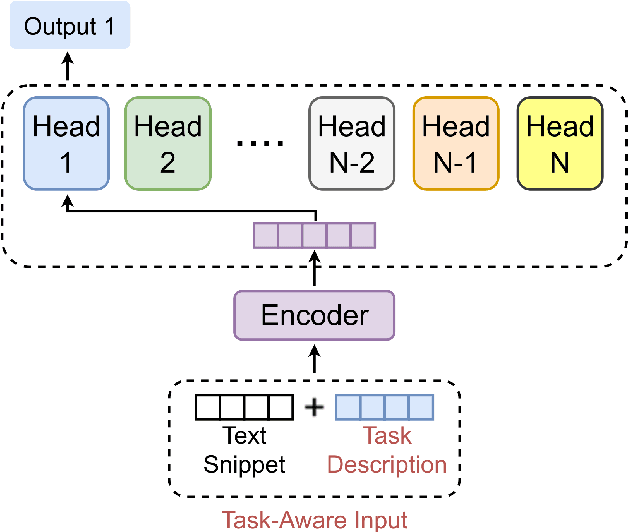
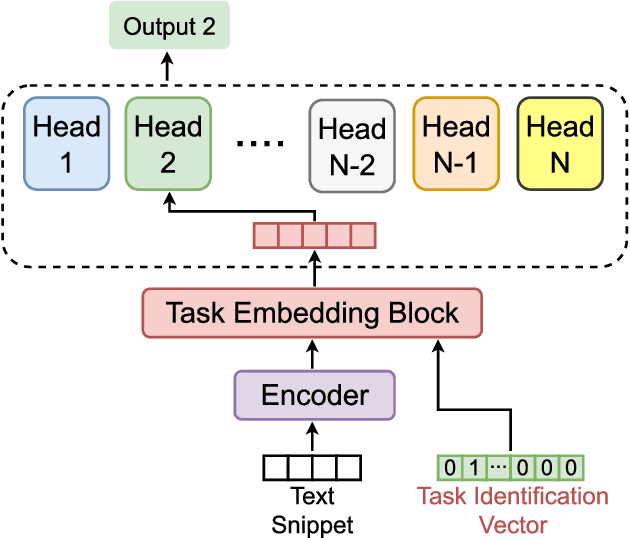
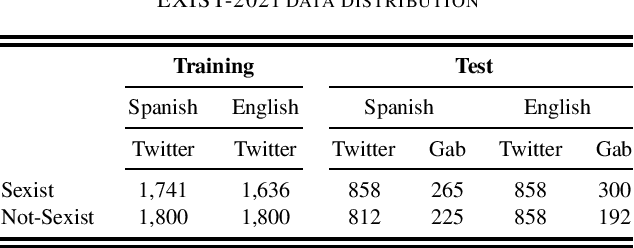
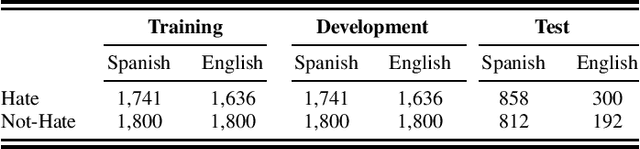
This paper proposes a novelty approach to mitigate the negative transfer problem. In the field of machine learning, the common strategy is to apply the Single-Task Learning approach in order to train a supervised model to solve a specific task. Training a robust model requires a lot of data and a significant amount of computational resources, making this solution unfeasible in cases where data are unavailable or expensive to gather. Therefore another solution, based on the sharing of information between tasks, has been developed: Multi-Task Learning (MTL). Despite the recent developments regarding MTL, the problem of negative transfer has still to be solved. Negative transfer is a phenomenon that occurs when noisy information is shared between tasks, resulting in a drop in performance. This paper proposes a new approach to mitigate the negative transfer problem based on the task awareness concept. The proposed approach results in diminishing the negative transfer together with an improvement of performance over classic MTL solution. Moreover, the proposed approach has been implemented in two unified architectures to detect Sexism, Hate Speech, and Toxic Language in text comments. The proposed architectures set a new state-of-the-art both in EXIST-2021 and HatEval-2019 benchmarks.
Multi-Scale Prototypical Transformer for Whole Slide Image Classification
Jul 05, 2023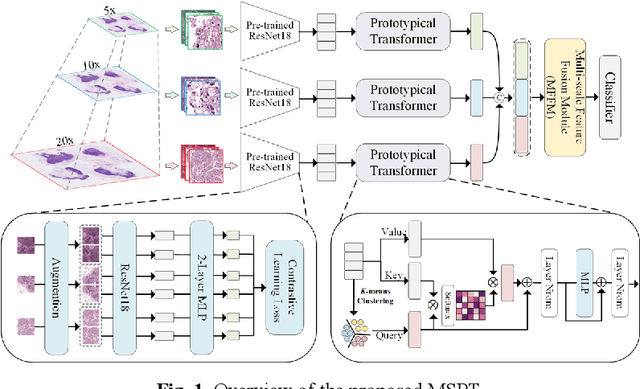
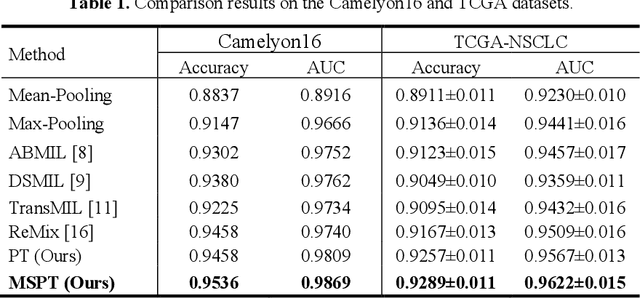
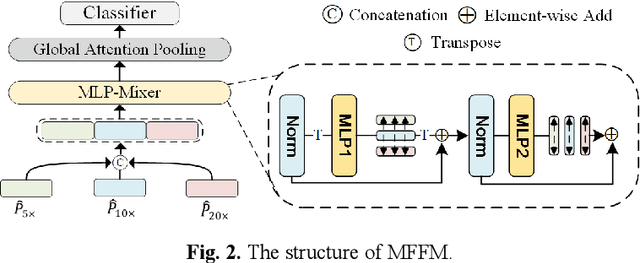
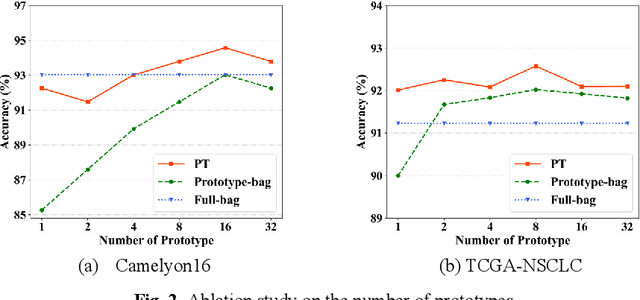
Whole slide image (WSI) classification is an essential task in computational pathology. Despite the recent advances in multiple instance learning (MIL) for WSI classification, accurate classification of WSIs remains challenging due to the extreme imbalance between the positive and negative instances in bags, and the complicated pre-processing to fuse multi-scale information of WSI. To this end, we propose a novel multi-scale prototypical Transformer (MSPT) for WSI classification, which includes a prototypical Transformer (PT) module and a multi-scale feature fusion module (MFFM). The PT is developed to reduce redundant instances in bags by integrating prototypical learning into the Transformer architecture. It substitutes all instances with cluster prototypes, which are then re-calibrated through the self-attention mechanism of the Trans-former. Thereafter, an MFFM is proposed to fuse the clustered prototypes of different scales, which employs MLP-Mixer to enhance the information communication between prototypes. The experimental results on two public WSI datasets demonstrate that the proposed MSPT outperforms all the compared algorithms, suggesting its potential applications.
Interactive Image Segmentation with Cross-Modality Vision Transformers
Jul 05, 2023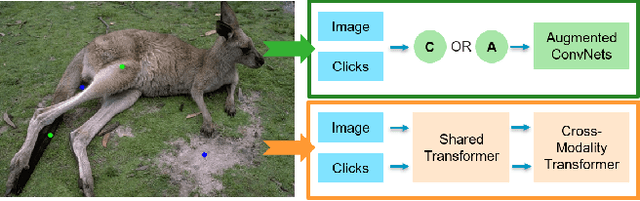
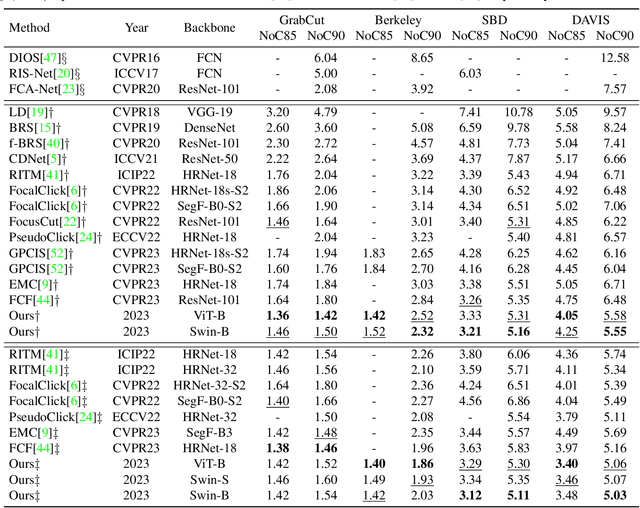
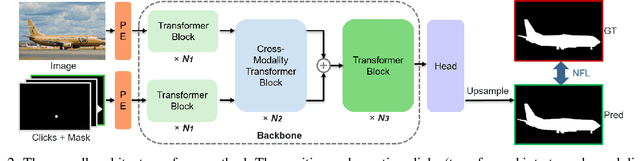
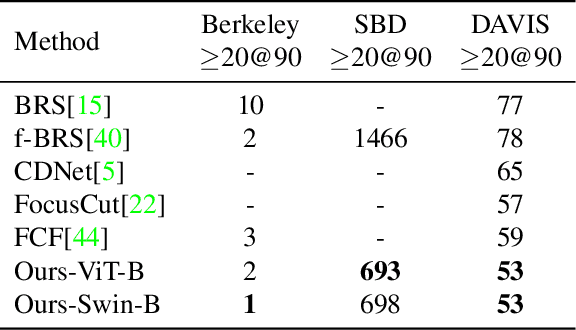
Interactive image segmentation aims to segment the target from the background with the manual guidance, which takes as input multimodal data such as images, clicks, scribbles, and bounding boxes. Recently, vision transformers have achieved a great success in several downstream visual tasks, and a few efforts have been made to bring this powerful architecture to interactive segmentation task. However, the previous works neglect the relations between two modalities and directly mock the way of processing purely visual information with self-attentions. In this paper, we propose a simple yet effective network for click-based interactive segmentation with cross-modality vision transformers. Cross-modality transformers exploits mutual information to better guide the learning process. The experiments on several benchmarks show that the proposed method achieves superior performance in comparison to the previous state-of-the-art models. The stability of our method in term of avoiding failure cases shows its potential to be a practical annotation tool. The code and pretrained models will be released under https://github.com/lik1996/iCMFormer.
Enhancing Multiple Reliability Measures via Nuisance-extended Information Bottleneck
Mar 24, 2023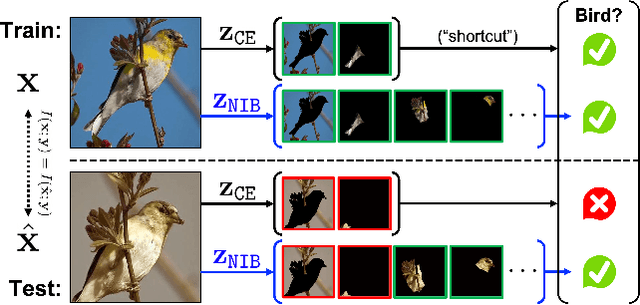
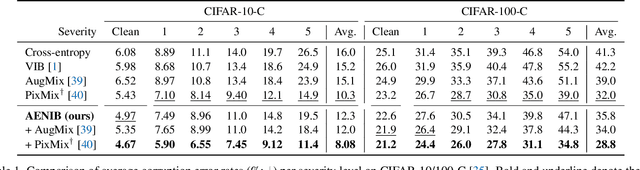
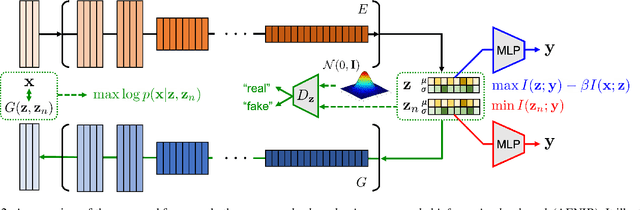
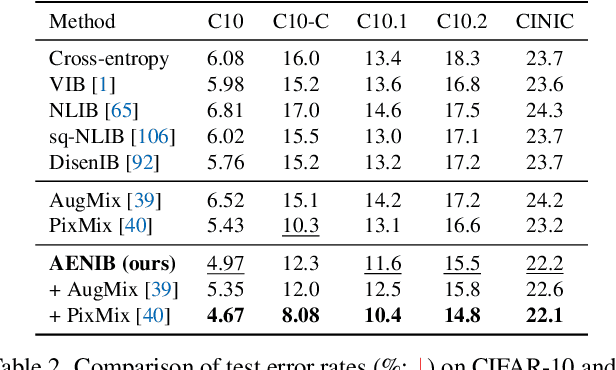
In practical scenarios where training data is limited, many predictive signals in the data can be rather from some biases in data acquisition (i.e., less generalizable), so that one cannot prevent a model from co-adapting on such (so-called) "shortcut" signals: this makes the model fragile in various distribution shifts. To bypass such failure modes, we consider an adversarial threat model under a mutual information constraint to cover a wider class of perturbations in training. This motivates us to extend the standard information bottleneck to additionally model the nuisance information. We propose an autoencoder-based training to implement the objective, as well as practical encoder designs to facilitate the proposed hybrid discriminative-generative training concerning both convolutional- and Transformer-based architectures. Our experimental results show that the proposed scheme improves robustness of learned representations (remarkably without using any domain-specific knowledge), with respect to multiple challenging reliability measures. For example, our model could advance the state-of-the-art on a recent challenging OBJECTS benchmark in novelty detection by $78.4\% \rightarrow 87.2\%$ in AUROC, while simultaneously enjoying improved corruption, background and (certified) adversarial robustness. Code is available at https://github.com/jh-jeong/nuisance_ib.
A Causal Ordering Prior for Unsupervised Representation Learning
Jul 11, 2023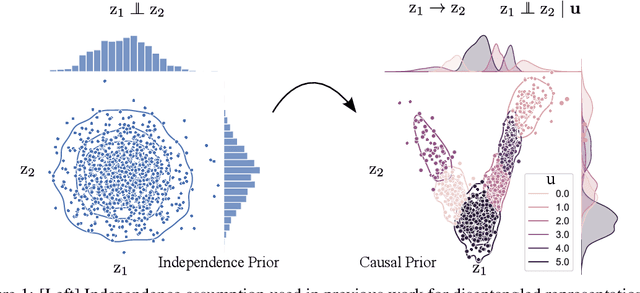

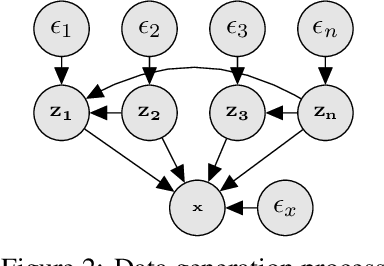
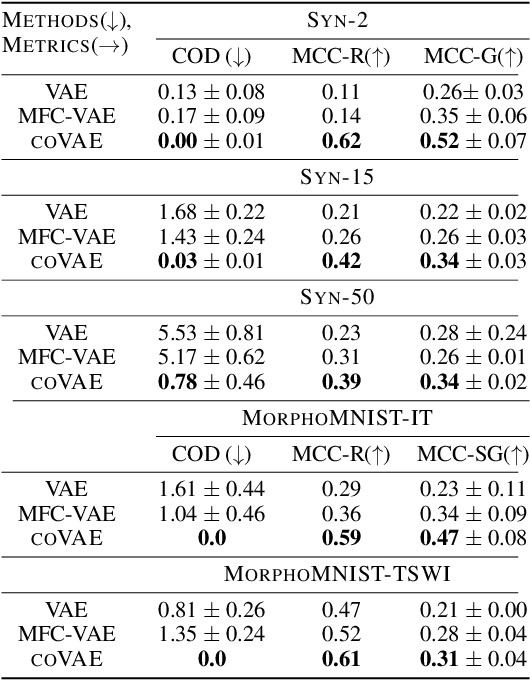
Unsupervised representation learning with variational inference relies heavily on independence assumptions over latent variables. Causal representation learning (CRL), however, argues that factors of variation in a dataset are, in fact, causally related. Allowing latent variables to be correlated, as a consequence of causal relationships, is more realistic and generalisable. So far, provably identifiable methods rely on: auxiliary information, weak labels, and interventional or even counterfactual data. Inspired by causal discovery with functional causal models, we propose a fully unsupervised representation learning method that considers a data generation process with a latent additive noise model (ANM). We encourage the latent space to follow a causal ordering via loss function based on the Hessian of the latent distribution.
Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing
Jun 30, 2023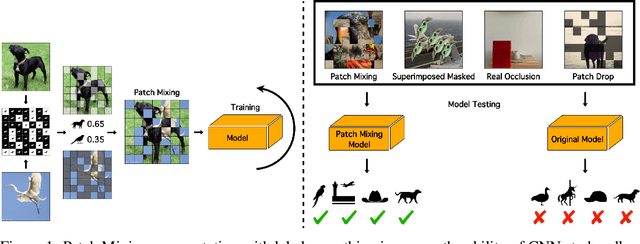
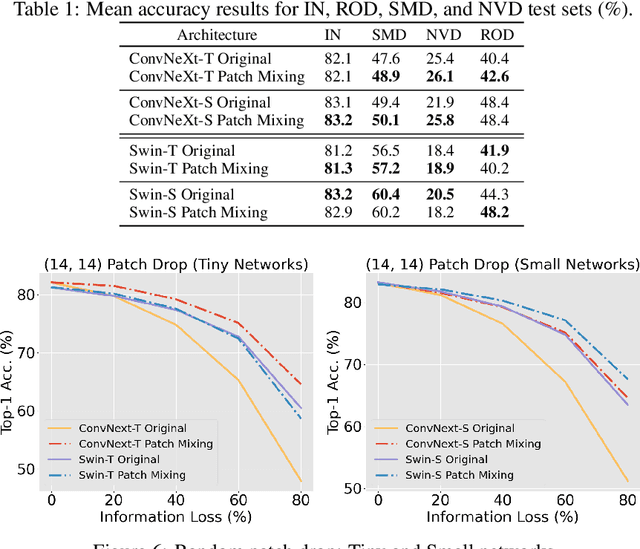
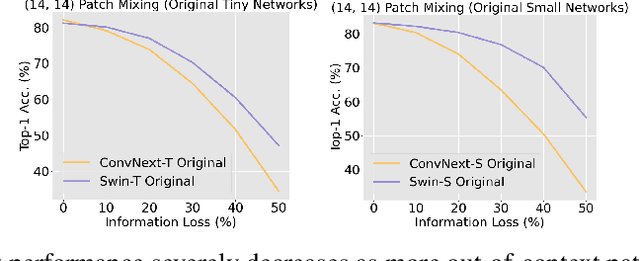
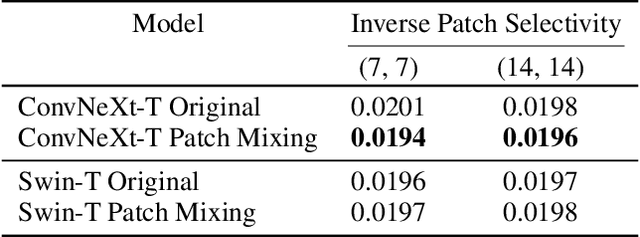
Vision transformers (ViTs) have significantly changed the computer vision landscape and have periodically exhibited superior performance in vision tasks compared to convolutional neural networks (CNNs). Although the jury is still out on which model type is superior, each has unique inductive biases that shape their learning and generalization performance. For example, ViTs have interesting properties with respect to early layer non-local feature dependence, as well as self-attention mechanisms which enhance learning flexibility, enabling them to ignore out-of-context image information more effectively. We hypothesize that this power to ignore out-of-context information (which we name $\textit{patch selectivity}$), while integrating in-context information in a non-local manner in early layers, allows ViTs to more easily handle occlusion. In this study, our aim is to see whether we can have CNNs $\textit{simulate}$ this ability of patch selectivity by effectively hardwiring this inductive bias using Patch Mixing data augmentation, which consists of inserting patches from another image onto a training image and interpolating labels between the two image classes. Specifically, we use Patch Mixing to train state-of-the-art ViTs and CNNs, assessing its impact on their ability to ignore out-of-context patches and handle natural occlusions. We find that ViTs do not improve nor degrade when trained using Patch Mixing, but CNNs acquire new capabilities to ignore out-of-context information and improve on occlusion benchmarks, leaving us to conclude that this training method is a way of simulating in CNNs the abilities that ViTs already possess. We will release our Patch Mixing implementation and proposed datasets for public use. Project page: https://arielnlee.github.io/PatchMixing/
Artificial Intelligence for Drug Discovery: Are We There Yet?
Jul 13, 2023
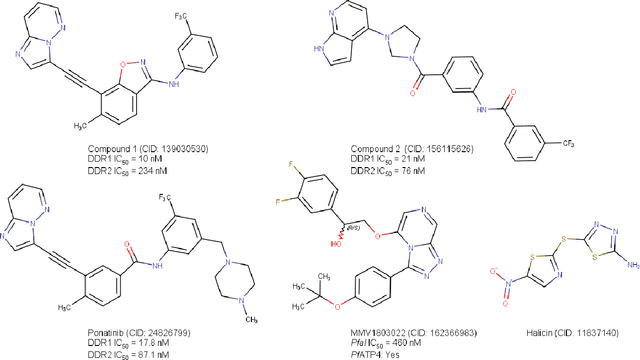
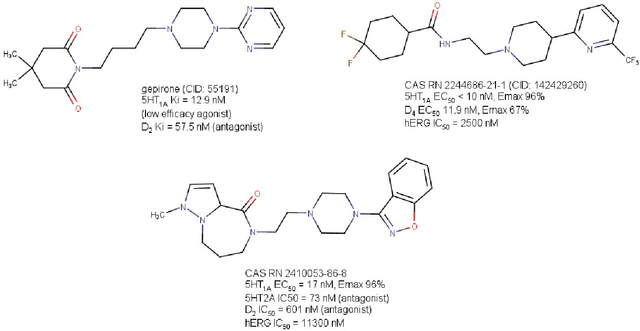
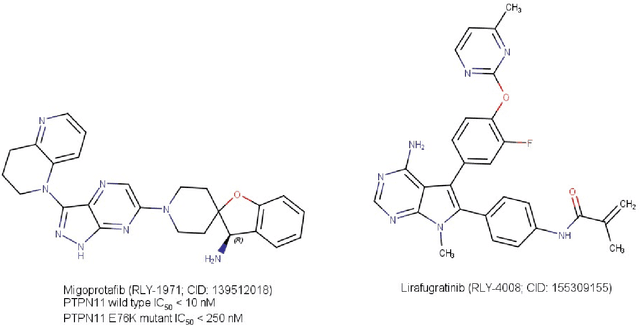
Drug discovery is adapting to novel technologies such as data science, informatics, and artificial intelligence (AI) to accelerate effective treatment development while reducing costs and animal experiments. AI is transforming drug discovery, as indicated by increasing interest from investors, industrial and academic scientists, and legislators. Successful drug discovery requires optimizing properties related to pharmacodynamics, pharmacokinetics, and clinical outcomes. This review discusses the use of AI in the three pillars of drug discovery: diseases, targets, and therapeutic modalities, with a focus on small molecule drugs. AI technologies, such as generative chemistry, machine learning, and multi-property optimization, have enabled several compounds to enter clinical trials. The scientific community must carefully vet known information to address the reproducibility crisis. The full potential of AI in drug discovery can only be realized with sufficient ground truth and appropriate human intervention at later pipeline stages.
PIGEON: Predicting Image Geolocations
Jul 13, 2023We introduce PIGEON, a multi-task end-to-end system for planet-scale image geolocalization that achieves state-of-the-art performance on both external benchmarks and in human evaluation. Our work incorporates semantic geocell creation with label smoothing, conducts pretraining of a vision transformer on images with geographic information, and refines location predictions with ProtoNets across a candidate set of geocells. The contributions of PIGEON are three-fold: first, we design a semantic geocells creation and splitting algorithm based on open-source data which can be adapted to any geospatial dataset. Second, we show the effectiveness of intra-geocell refinement and the applicability of unsupervised clustering and ProtNets to the task. Finally, we make our pre-trained CLIP transformer model, StreetCLIP, publicly available for use in adjacent domains with applications to fighting climate change and urban and rural scene understanding.
STTracker: Spatio-Temporal Tracker for 3D Single Object Tracking
Jun 30, 2023
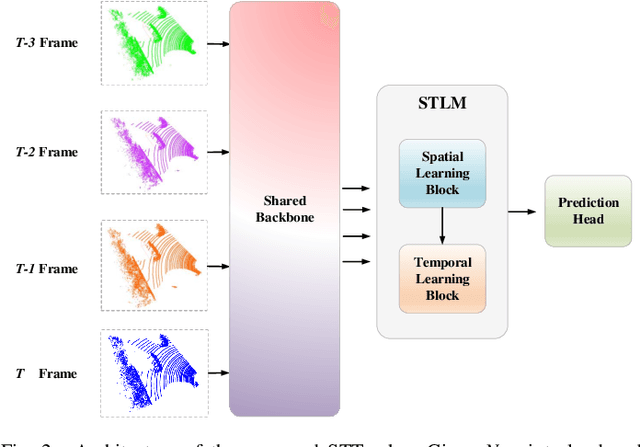
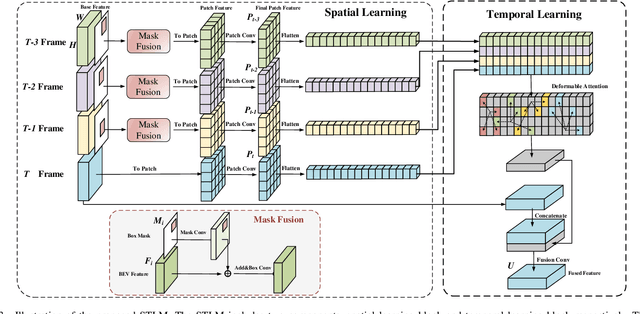

3D single object tracking with point clouds is a critical task in 3D computer vision. Previous methods usually input the last two frames and use the predicted box to get the template point cloud in previous frame and the search area point cloud in the current frame respectively, then use similarity-based or motion-based methods to predict the current box. Although these methods achieved good tracking performance, they ignore the historical information of the target, which is important for tracking. In this paper, compared to inputting two frames of point clouds, we input multi-frame of point clouds to encode the spatio-temporal information of the target and learn the motion information of the target implicitly, which could build the correlations among different frames to track the target in the current frame efficiently. Meanwhile, rather than directly using the point feature for feature fusion, we first crop the point cloud features into many patches and then use sparse attention mechanism to encode the patch-level similarity and finally fuse the multi-frame features. Extensive experiments show that our method achieves competitive results on challenging large-scale benchmarks (62.6% in KITTI and 49.66% in NuScenes).
Augmenting Holistic Review in University Admission using Natural Language Processing for Essays and Recommendation Letters
Jun 30, 2023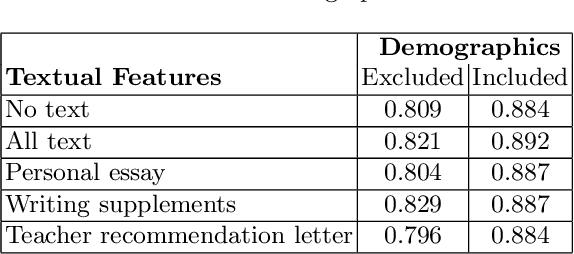
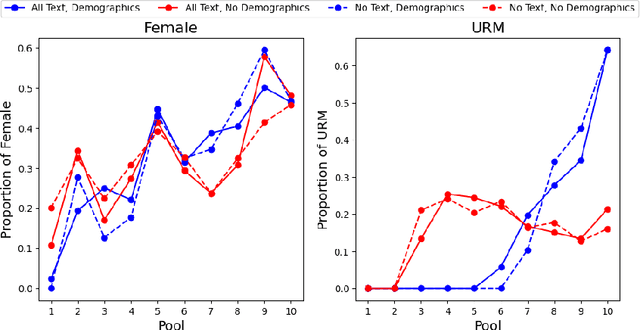
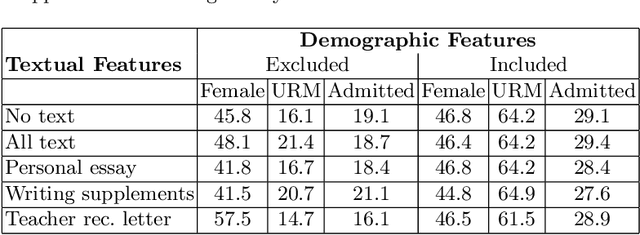
University admission at many highly selective institutions uses a holistic review process, where all aspects of the application, including protected attributes (e.g., race, gender), grades, essays, and recommendation letters are considered, to compose an excellent and diverse class. In this study, we empirically evaluate how influential protected attributes are for predicting admission decisions using a machine learning (ML) model, and in how far textual information (e.g., personal essay, teacher recommendation) may substitute for the loss of protected attributes in the model. Using data from 14,915 applicants to an undergraduate admission office at a selective U.S. institution in the 2022-2023 cycle, we find that the exclusion of protected attributes from the ML model leads to substantially reduced admission-prediction performance. The inclusion of textual information via both a TF-IDF representation and a Latent Dirichlet allocation (LDA) model partially restores model performance, but does not appear to provide a full substitute for admitting a similarly diverse class. In particular, while the text helps with gender diversity, the proportion of URM applicants is severely impacted by the exclusion of protected attributes, and the inclusion of new attributes generated from the textual information does not recover this performance loss.