 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data-driven Piecewise Affine Decision Rules for Stochastic Programming with Covariate Information
Apr 26, 2023

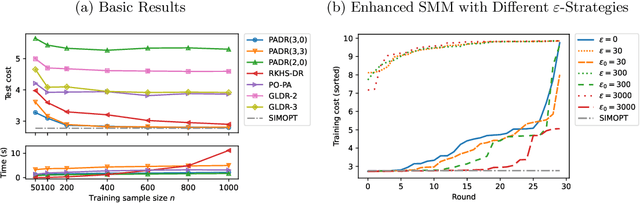

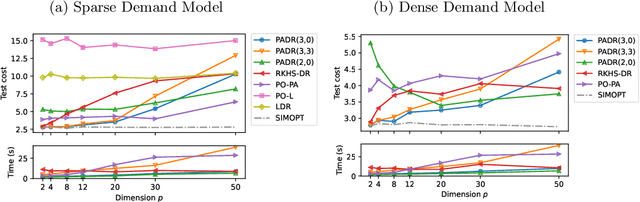
Focusing on stochastic programming (SP) with covariate information, this paper proposes an empirical risk minimization (ERM) method embedded within a nonconvex piecewise affine decision rule (PADR), which aims to learn the direct mapping from features to optimal decisions. We establish the nonasymptotic consistency result of our PADR-based ERM model for unconstrained problems and asymptotic consistency result for constrained ones. To solve the nonconvex and nondifferentiable ERM problem, we develop an enhanced stochastic majorization-minimization algorithm and establish the asymptotic convergence to (composite strong) directional stationarity along with complexity analysis. We show that the proposed PADR-based ERM method applies to a broad class of nonconvex SP problems with theoretical consistency guarantees and computational tractability. Our numerical study demonstrates the superior performance of PADR-based ERM methods compared to state-of-the-art approaches under various settings, with significantly lower costs, less computation time, and robustness to feature dimensions and nonlinearity of the underlying dependency.
Semantic-Aware Dual Contrastive Learning for Multi-label Image Classification
Jul 19, 2023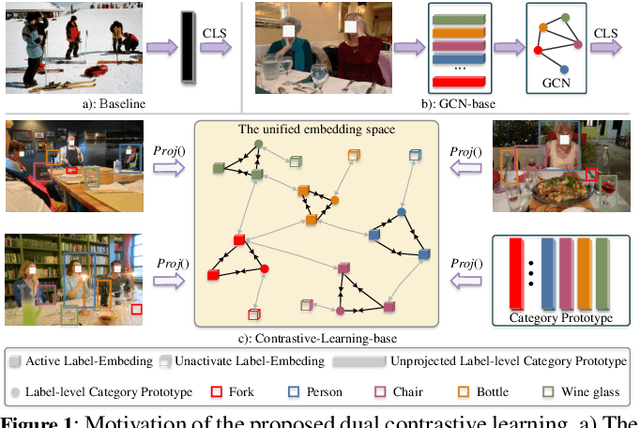
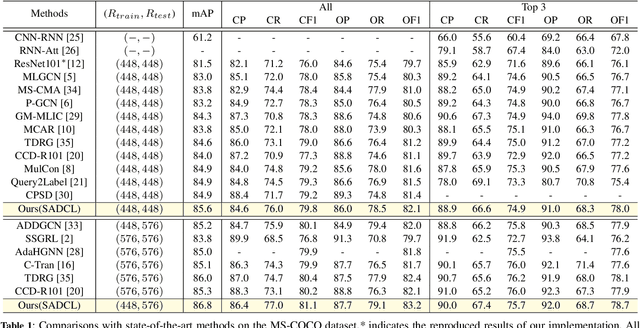
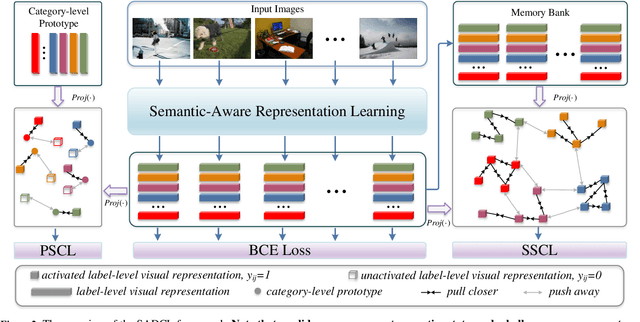
Extracting image semantics effectively and assigning corresponding labels to multiple objects or attributes for natural images is challenging due to the complex scene contents and confusing label dependencies. Recent works have focused on modeling label relationships with graph and understanding object regions using class activation maps (CAM). However, these methods ignore the complex intra- and inter-category relationships among specific semantic features, and CAM is prone to generate noisy information. To this end, we propose a novel semantic-aware dual contrastive learning framework that incorporates sample-to-sample contrastive learning (SSCL) as well as prototype-to-sample contrastive learning (PSCL). Specifically, we leverage semantic-aware representation learning to extract category-related local discriminative features and construct category prototypes. Then based on SSCL, label-level visual representations of the same category are aggregated together, and features belonging to distinct categories are separated. Meanwhile, we construct a novel PSCL module to narrow the distance between positive samples and category prototypes and push negative samples away from the corresponding category prototypes. Finally, the discriminative label-level features related to the image content are accurately captured by the joint training of the above three parts. Experiments on five challenging large-scale public datasets demonstrate that our proposed method is effective and outperforms the state-of-the-art methods. Code and supplementary materials are released on https://github.com/yu-gi-oh-leilei/SADCL.
Source-Free Domain Adaptation for Medical Image Segmentation via Prototype-Anchored Feature Alignment and Contrastive Learning
Jul 19, 2023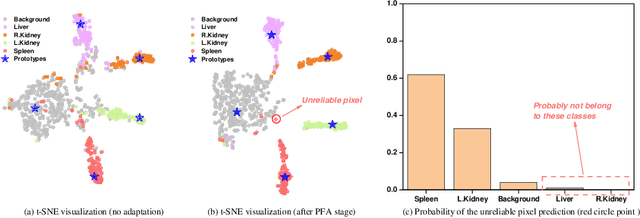
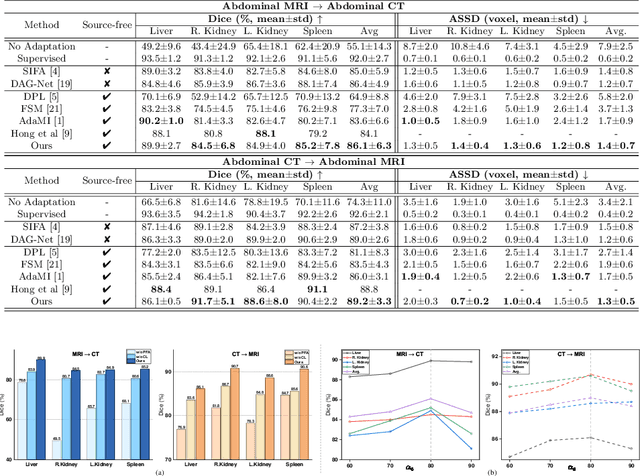
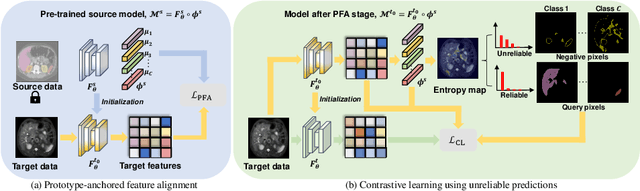
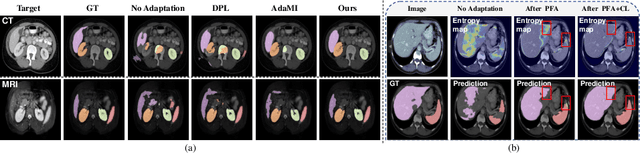
Unsupervised domain adaptation (UDA) has increasingly gained interests for its capacity to transfer the knowledge learned from a labeled source domain to an unlabeled target domain. However, typical UDA methods require concurrent access to both the source and target domain data, which largely limits its application in medical scenarios where source data is often unavailable due to privacy concern. To tackle the source data-absent problem, we present a novel two-stage source-free domain adaptation (SFDA) framework for medical image segmentation, where only a well-trained source segmentation model and unlabeled target data are available during domain adaptation. Specifically, in the prototype-anchored feature alignment stage, we first utilize the weights of the pre-trained pixel-wise classifier as source prototypes, which preserve the information of source features. Then, we introduce the bi-directional transport to align the target features with class prototypes by minimizing its expected cost. On top of that, a contrastive learning stage is further devised to utilize those pixels with unreliable predictions for a more compact target feature distribution. Extensive experiments on a cross-modality medical segmentation task demonstrate the superiority of our method in large domain discrepancy settings compared with the state-of-the-art SFDA approaches and even some UDA methods. Code is available at https://github.com/CSCYQJ/MICCAI23-ProtoContra-SFDA.
Boosting 3-DoF Ground-to-Satellite Camera Localization Accuracy via Geometry-Guided Cross-View Transformer
Jul 19, 2023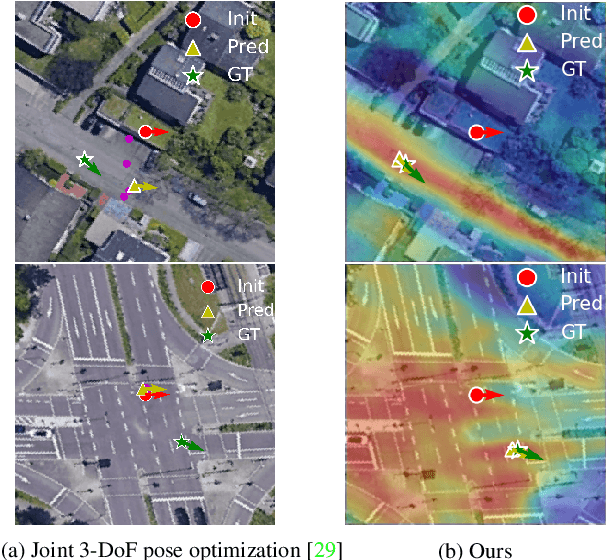
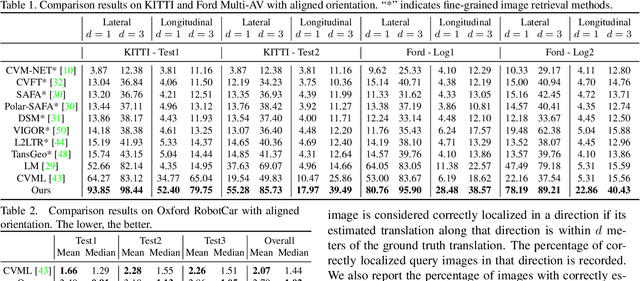
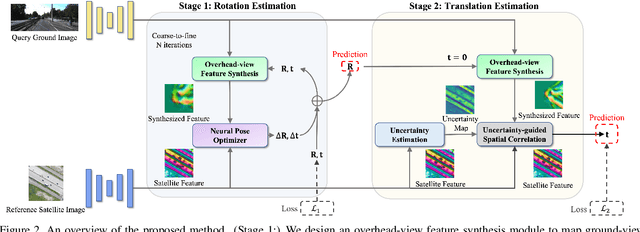
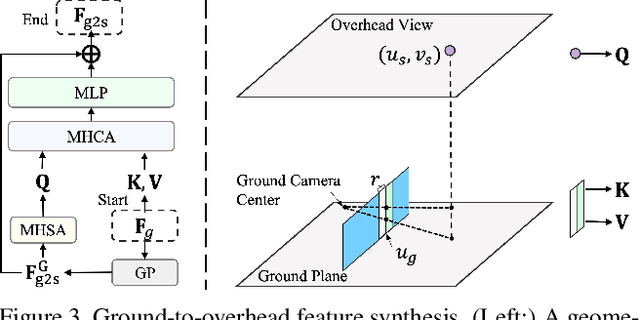
Image retrieval-based cross-view localization methods often lead to very coarse camera pose estimation, due to the limited sampling density of the database satellite images. In this paper, we propose a method to increase the accuracy of a ground camera's location and orientation by estimating the relative rotation and translation between the ground-level image and its matched/retrieved satellite image. Our approach designs a geometry-guided cross-view transformer that combines the benefits of conventional geometry and learnable cross-view transformers to map the ground-view observations to an overhead view. Given the synthesized overhead view and observed satellite feature maps, we construct a neural pose optimizer with strong global information embedding ability to estimate the relative rotation between them. After aligning their rotations, we develop an uncertainty-guided spatial correlation to generate a probability map of the vehicle locations, from which the relative translation can be determined. Experimental results demonstrate that our method significantly outperforms the state-of-the-art. Notably, the likelihood of restricting the vehicle lateral pose to be within 1m of its Ground Truth (GT) value on the cross-view KITTI dataset has been improved from $35.54\%$ to $76.44\%$, and the likelihood of restricting the vehicle orientation to be within $1^{\circ}$ of its GT value has been improved from $19.64\%$ to $99.10\%$.
Opinion mining using Double Channel CNN for Recommender System
Jul 15, 2023
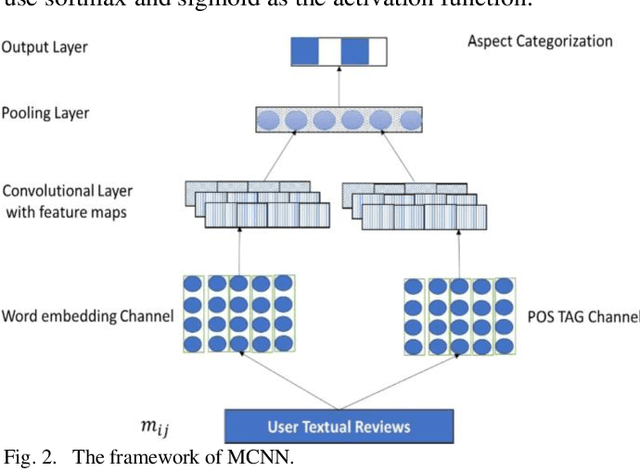
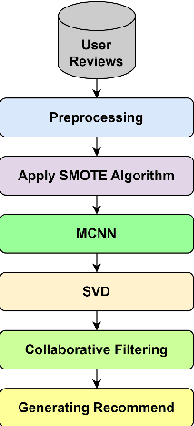
Much unstructured data has been produced with the growth of the Internet and social media. A significant volume of textual data includes users' opinions about products in online stores and social media. By exploring and categorizing them, helpful information can be acquired, including customer satisfaction, user feedback about a particular event, predicting the sale of a specific product, and other similar cases. In this paper, we present an approach for sentiment analysis with a deep learning model and use it to recommend products. A two-channel convolutional neural network model has been used for opinion mining, which has five layers and extracts essential features from the data. We increased the number of comments by applying the SMOTE algorithm to the initial dataset and balanced the data. Then we proceed to cluster the aspects. We also assign a weight to each cluster using tensor decomposition algorithms that improve the recommender system's performance. Our proposed method has reached 91.6% accuracy, significantly improved compared to previous aspect-based approaches.
RegExplainer: Generating Explanations for Graph Neural Networks in Regression Task
Jul 15, 2023
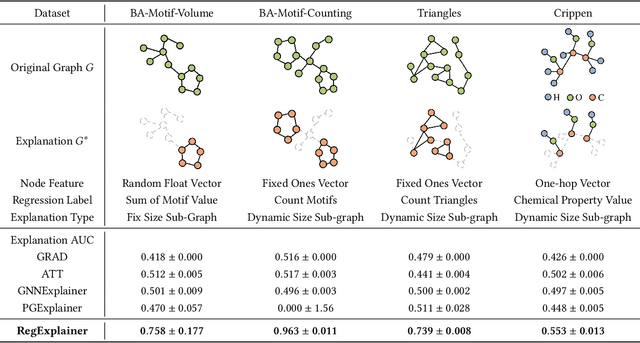
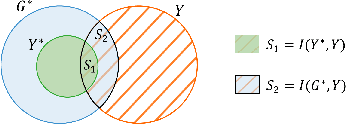
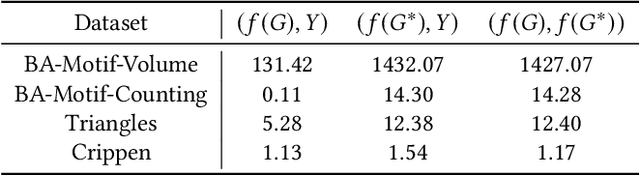
Graph regression is a fundamental task and has received increasing attention in a wide range of graph learning tasks. However, the inference process is often not interpretable. Most existing explanation techniques are limited to understanding GNN behaviors in classification tasks. In this work, we seek an explanation to interpret the graph regression models (XAIG-R). We show that existing methods overlook the distribution shifting and continuously ordered decision boundary, which hinders them away from being applied in the regression tasks. To address these challenges, we propose a novel objective based on the information bottleneck theory and introduce a new mix-up framework, which could support various GNNs in a model-agnostic manner. We further present a contrastive learning strategy to tackle the continuously ordered labels in regression task. To empirically verify the effectiveness of the proposed method, we introduce three benchmark datasets and a real-life dataset for evaluation. Extensive experiments show the effectiveness of the proposed method in interpreting GNN models in regression tasks.
Automated Knowledge Modeling for Cancer Clinical Practice Guidelines
Jul 15, 2023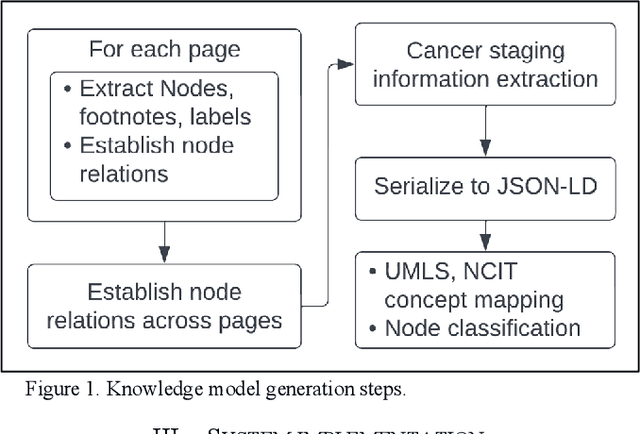
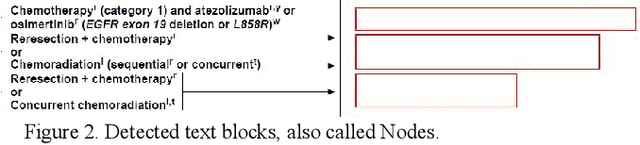
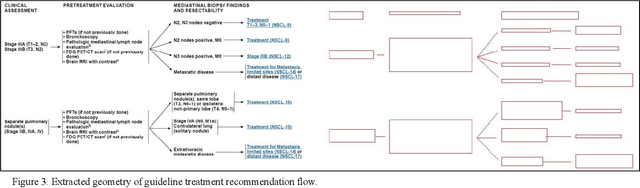

Clinical Practice Guidelines (CPGs) for cancer diseases evolve rapidly due to new evidence generated by active research. Currently, CPGs are primarily published in a document format that is ill-suited for managing this developing knowledge. A knowledge model of the guidelines document suitable for programmatic interaction is required. This work proposes an automated method for extraction of knowledge from National Comprehensive Cancer Network (NCCN) CPGs in Oncology and generating a structured model containing the retrieved knowledge. The proposed method was tested using two versions of NCCN Non-Small Cell Lung Cancer (NSCLC) CPG to demonstrate the effectiveness in faithful extraction and modeling of knowledge. Three enrichment strategies using Cancer staging information, Unified Medical Language System (UMLS) Metathesaurus & National Cancer Institute thesaurus (NCIt) concepts, and Node classification are also presented to enhance the model towards enabling programmatic traversal and querying of cancer care guidelines. The Node classification was performed using a Support Vector Machine (SVM) model, achieving a classification accuracy of 0.81 with 10-fold cross-validation.
A Synthetic Electrocardiogram (ECG) Image Generation Toolbox to Facilitate Deep Learning-Based Scanned ECG Digitization
Jul 04, 2023

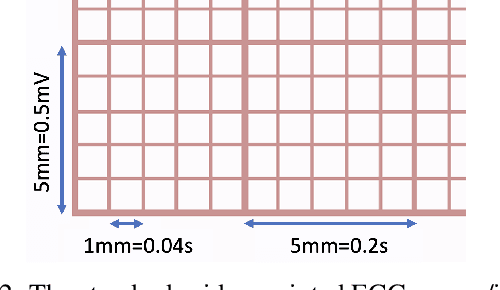
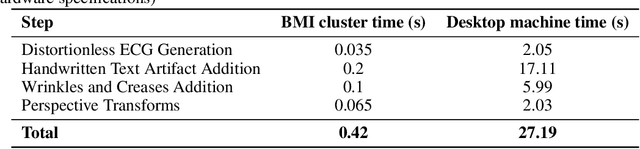
Access to medical data is often limited as it contains protected health information (PHI). There are privacy concerns regarding using records containing personally identifiable information. Recent advancements have been made in applying deep learning-based algorithms for clinical diagnosis and decision-making. However, deep learning models are data-greedy, whereas the availability of medical datasets for training and evaluating these models is relatively limited. Data augmentation with so-called \textit{digital twins} is an emerging technique to address this need. This paper presents a novel approach for generating synthetic electrocardiogram (ECG) images with realistic artifacts from time-series data for use in developing algorithms for digitization of ECG images. Synthetic data is generated in a privacy-preserving manner by generating distortionless ECG images on standard ECG paper background. Next, various distortions, including handwritten text artifacts, wrinkles, creases, and perspective transforms are applied to the ECG images. The artifacts are generated synthetically, without personally identifiable information. As a use case, we generated a large ECG image dataset of 21,801 records from the PhysioNet PTB-XL dataset, with 12 lead ECG time-series data from 18,869 patients. A deep ECG image digitization model was developed and trained on the synthetic dataset, and was employed to convert the synthetic images to time-series data for evaluation. The signal-to-noise ratio (SNR) was calculated to assess the image digitization quality vs the ground truth ECG time-series. The results show an average signal recovery SNR of 27$\pm$2.8\,dB, demonstrating the significance of the proposed synthetic ECG image dataset for training deep learning models.
What do self-supervised speech models know about words?
Jun 30, 2023
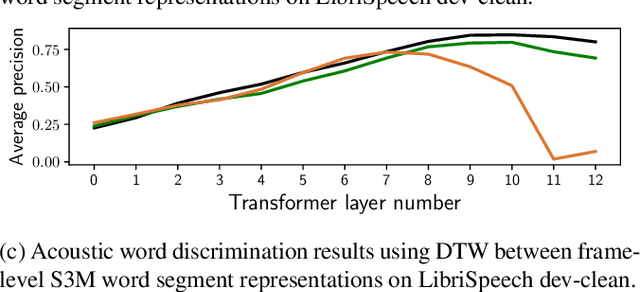

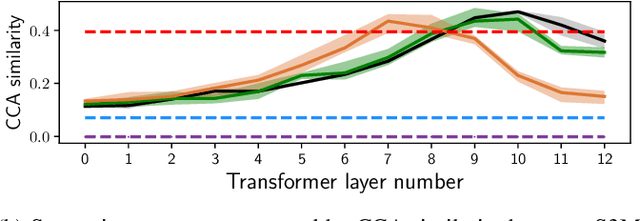
Many self-supervised speech models (S3Ms) have been introduced over the last few years, producing performance and data efficiency improvements for a variety of speech tasks. Evidence is emerging that different S3Ms encode linguistic information in different layers, and also that some S3Ms appear to learn phone-like sub-word units. However, the extent to which these models capture larger linguistic units, such as words, and where word-related information is encoded, remains unclear. In this study, we conduct several analyses of word segment representations extracted from different layers of three S3Ms: wav2vec2, HuBERT, and WavLM. We employ canonical correlation analysis (CCA), a lightweight analysis tool, to measure the similarity between these representations and word-level linguistic properties. We find that the maximal word-level linguistic content tends to be found in intermediate model layers, while some lower-level information like pronunciation is also retained in higher layers of HuBERT and WavLM. Syntactic and semantic word attributes have similar layer-wise behavior. We also find that, for all of the models tested, word identity information is concentrated near the center of each word segment. We then test the layer-wise performance of the same models, when used directly with no additional learned parameters, on several tasks: acoustic word discrimination, word segmentation, and semantic sentence similarity. We find similar layer-wise trends in performance, and furthermore, find that when using the best-performing layer of HuBERT or WavLM, it is possible to achieve performance on word segmentation and sentence similarity that rivals more complex existing approaches.
Enhancing Multiple Reliability Measures via Nuisance-extended Information Bottleneck
Mar 24, 2023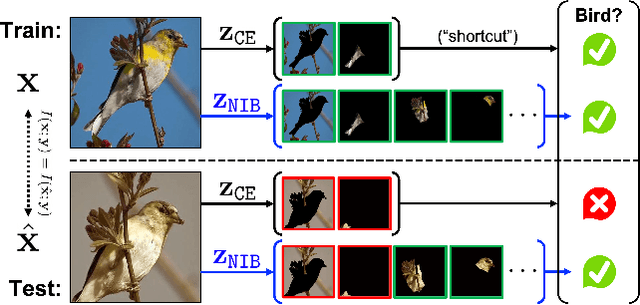
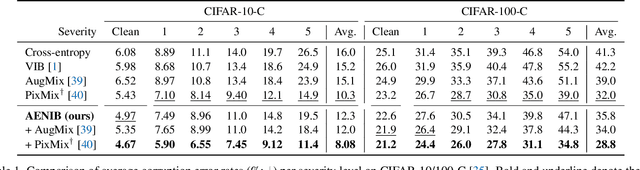
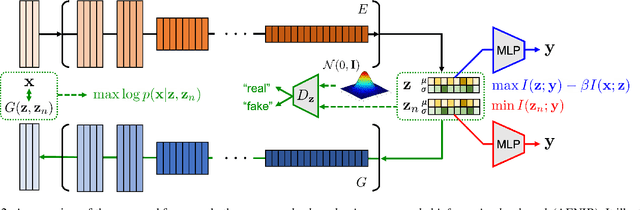
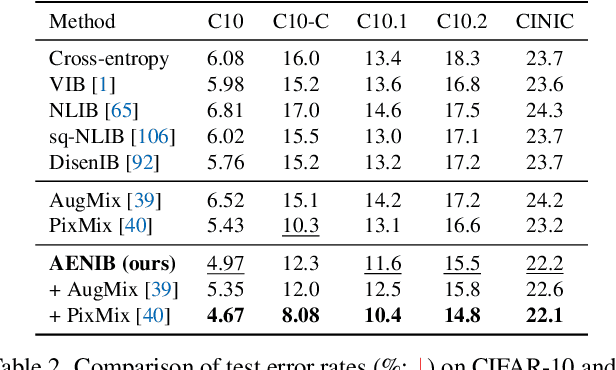
In practical scenarios where training data is limited, many predictive signals in the data can be rather from some biases in data acquisition (i.e., less generalizable), so that one cannot prevent a model from co-adapting on such (so-called) "shortcut" signals: this makes the model fragile in various distribution shifts. To bypass such failure modes, we consider an adversarial threat model under a mutual information constraint to cover a wider class of perturbations in training. This motivates us to extend the standard information bottleneck to additionally model the nuisance information. We propose an autoencoder-based training to implement the objective, as well as practical encoder designs to facilitate the proposed hybrid discriminative-generative training concerning both convolutional- and Transformer-based architectures. Our experimental results show that the proposed scheme improves robustness of learned representations (remarkably without using any domain-specific knowledge), with respect to multiple challenging reliability measures. For example, our model could advance the state-of-the-art on a recent challenging OBJECTS benchmark in novelty detection by $78.4\% \rightarrow 87.2\%$ in AUROC, while simultaneously enjoying improved corruption, background and (certified) adversarial robustness. Code is available at https://github.com/jh-jeong/nuisance_ib.