 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semi-supervised multi-view concept decomposition
Jul 03, 2023
Concept Factorization (CF), as a novel paradigm of representation learning, has demonstrated superior performance in multi-view clustering tasks. It overcomes limitations such as the non-negativity constraint imposed by traditional matrix factorization methods and leverages kernel methods to learn latent representations that capture the underlying structure of the data, thereby improving data representation. However, existing multi-view concept factorization methods fail to consider the limited labeled information inherent in real-world multi-view data. This often leads to significant performance loss. To overcome these limitations, we propose a novel semi-supervised multi-view concept factorization model, named SMVCF. In the SMVCF model, we first extend the conventional single-view CF to a multi-view version, enabling more effective exploration of complementary information across multiple views. We then integrate multi-view CF, label propagation, and manifold learning into a unified framework to leverage and incorporate valuable information present in the data. Additionally, an adaptive weight vector is introduced to balance the importance of different views in the clustering process. We further develop targeted optimization methods specifically tailored for the SMVCF model. Finally, we conduct extensive experiments on four diverse datasets with varying label ratios to evaluate the performance of SMVCF. The experimental results demonstrate the effectiveness and superiority of our proposed approach in multi-view clustering tasks.
Enhancing LLM with Evolutionary Fine Tuning for News Summary Generation
Jul 06, 2023News summary generation is an important task in the field of intelligence analysis, which can provide accurate and comprehensive information to help people better understand and respond to complex real-world events. However, traditional news summary generation methods face some challenges, which are limited by the model itself and the amount of training data, as well as the influence of text noise, making it difficult to generate reliable information accurately. In this paper, we propose a new paradigm for news summary generation using LLM with powerful natural language understanding and generative capabilities. We use LLM to extract multiple structured event patterns from the events contained in news paragraphs, evolve the event pattern population with genetic algorithm, and select the most adaptive event pattern to input into the LLM to generate news summaries. A News Summary Generator (NSG) is designed to select and evolve the event pattern populations and generate news summaries. The experimental results show that the news summary generator is able to generate accurate and reliable news summaries with some generalization ability.
How does AI chat change search behaviors?
Jul 07, 2023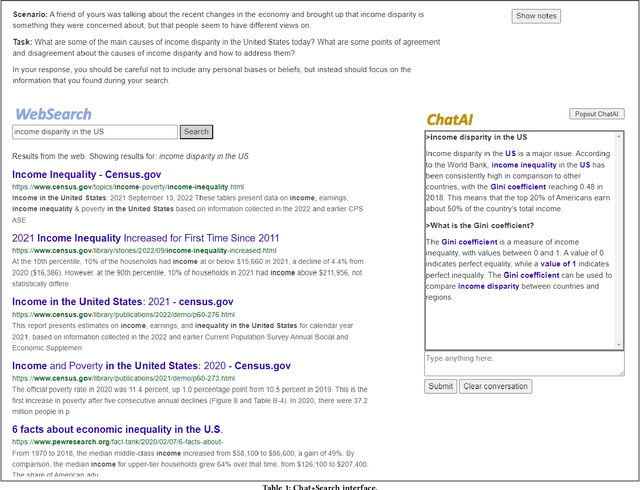
Generative AI tools such as chatGPT are poised to change the way people engage with online information. Recently, Microsoft announced their "new Bing" search system which incorporates chat and generative AI technology from OpenAI. Google has announced plans to deploy search interfaces that incorporate similar types of technology. These new technologies will transform how people can search for information. The research presented here is an early investigation into how people make use of a generative AI chat system (referred to simply as chat from here on) as part of a search process, and how the incorporation of chat systems with existing search tools may effect users search behaviors and strategies. We report on an exploratory user study with 10 participants who used a combined Chat+Search system that utilized the OpenAI GPT-3.5 API and the Bing Web Search v5 API. Participants completed three search tasks. In this pre-print paper of preliminary results, we report on ways that users integrated AI chat into their search process, things they liked and disliked about the chat system, their trust in the chat responses, and their mental models of how the chat system generated responses.
ParGANDA: Making Synthetic Pedestrians A Reality For Object Detection
Jul 21, 2023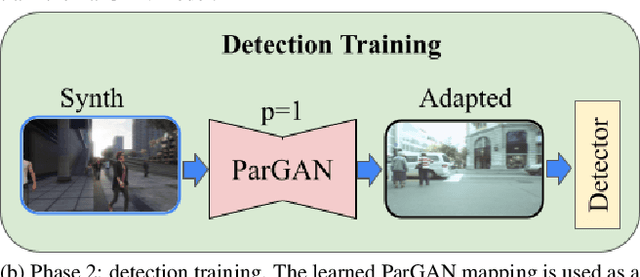



Object detection is the key technique to a number of Computer Vision applications, but it often requires large amounts of annotated data to achieve decent results. Moreover, for pedestrian detection specifically, the collected data might contain some personally identifiable information (PII), which is highly restricted in many countries. This label intensive and privacy concerning task has recently led to an increasing interest in training the detection models using synthetically generated pedestrian datasets collected with a photo-realistic video game engine. The engine is able to generate unlimited amounts of data with precise and consistent annotations, which gives potential for significant gains in the real-world applications. However, the use of synthetic data for training introduces a synthetic-to-real domain shift aggravating the final performance. To close the gap between the real and synthetic data, we propose to use a Generative Adversarial Network (GAN), which performsparameterized unpaired image-to-image translation to generate more realistic images. The key benefit of using the GAN is its intrinsic preference of low-level changes to geometric ones, which means annotations of a given synthetic image remain accurate even after domain translation is performed thus eliminating the need for labeling real data. We extensively experimented with the proposed method using MOTSynth dataset to train and MOT17 and MOT20 detection datasets to test, with experimental results demonstrating the effectiveness of this method. Our approach not only produces visually plausible samples but also does not require any labels of the real domain thus making it applicable to the variety of downstream tasks.
A Deep Learning Approach for Overall Survival Analysis with Missing Values
Jul 21, 2023One of the most challenging fields where Artificial Intelligence (AI) can be applied is lung cancer research, specifically non-small cell lung cancer (NSCLC). In particular, overall survival (OS) is a vital indicator of patient status, helping to identify subgroups with diverse survival probabilities, enabling tailored treatment and improved OS rates. In this analysis, there are two challenges to take into account. First, few studies effectively exploit the information available from each patient, leveraging both uncensored (i.e., dead) and censored (i.e., survivors) patients, considering also the death times. Second, the handling of incomplete data is a common issue in the medical field. This problem is typically tackled through the use of imputation methods. Our objective is to present an AI model able to overcome these limits, effectively learning from both censored and uncensored patients and their available features, for the prediction of OS for NSCLC patients. We present a novel approach to survival analysis in the context of NSCLC, which exploits the strengths of the transformer architecture accounting for only available features without requiring any imputation strategy. By making use of ad-hoc losses for OS, it accounts for both censored and uncensored patients, considering risks over time. We evaluated the results over a period of 6 years using different time granularities obtaining a Ct-index, a time-dependent variant of the C-index, of 71.97, 77.58 and 80.72 for time units of 1 month, 1 year and 2 years, respectively, outperforming all state-of-the-art methods regardless of the imputation method used.
Frequency Regularization: Restricting Information Redundancy of Convolutional Neural Networks
Apr 20, 2023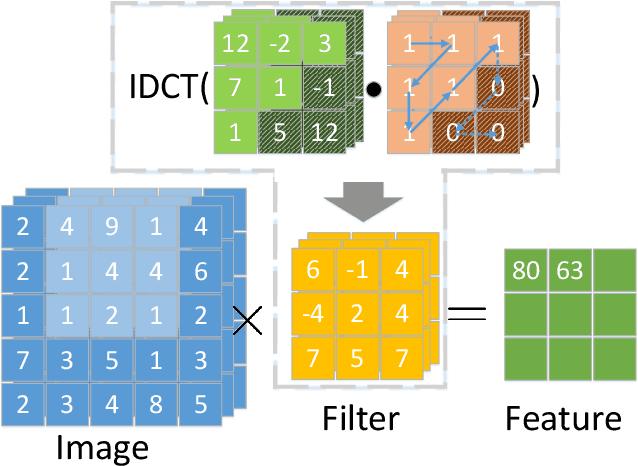
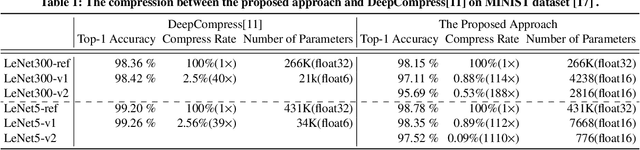
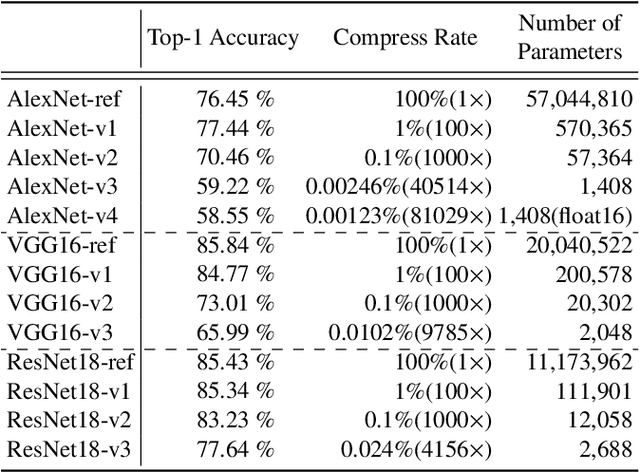

Convolutional neural networks have demonstrated impressive results in many computer vision tasks. However, the increasing size of these networks raises concerns about the information overload resulting from the large number of network parameters. In this paper, we propose Frequency Regularization to restrict the non-zero elements of the network parameters in frequency domain. The proposed approach operates at the tensor level, and can be applied to almost all network architectures. Specifically, the tensors of parameters are maintained in the frequency domain, where high frequency components can be eliminated by zigzag setting tensor elements to zero. Then, the inverse discrete cosine transform (IDCT) is used to reconstruct the spatial tensors for matrix operations during network training. Since high frequency components of images are known to be less critical, a large proportion of these parameters can be set to zero when networks are trained with the proposed frequency regularization. Comprehensive evaluations on various state-of-the-art network architectures, including LeNet, Alexnet, VGG, Resnet, ViT, UNet, GAN, and VAE, demonstrate the effectiveness of the proposed frequency regularization. Under the condition of a very small accuracy decrease (less than 2\%), a LeNet5 with 0.4M parameters can be represented by only 776 float16 numbers(over 1100$\times$), and a UNet with 34M parameters can be represented by only 759 float16 numbers (over 80000$\times$).
Impact of translation on biomedical information extraction from real-life clinical notes
Jun 03, 2023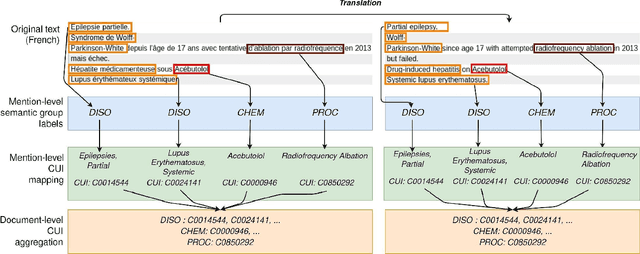
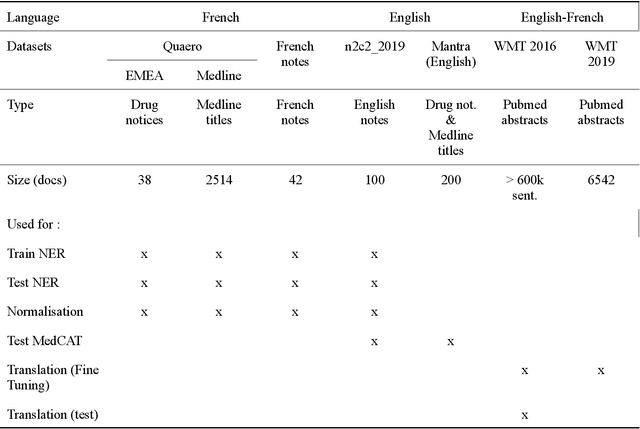
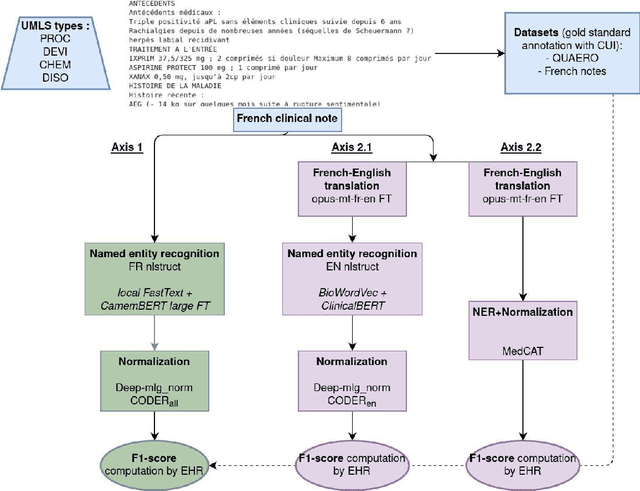
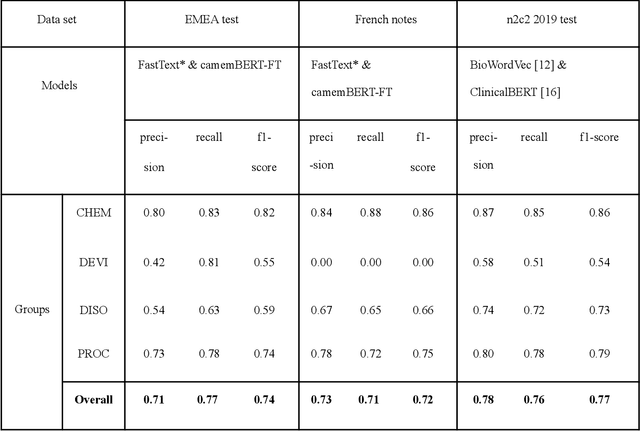
The objective of our study is to determine whether using English tools to extract and normalize French medical concepts on translations provides comparable performance to French models trained on a set of annotated French clinical notes. We compare two methods: a method involving French language models and a method involving English language models. For the native French method, the Named Entity Recognition (NER) and normalization steps are performed separately. For the translated English method, after the first translation step, we compare a two-step method and a terminology-oriented method that performs extraction and normalization at the same time. We used French, English and bilingual annotated datasets to evaluate all steps (NER, normalization and translation) of our algorithms. Concerning the results, the native French method performs better than the translated English one with a global f1 score of 0.51 [0.47;0.55] against 0.39 [0.34;0.44] and 0.38 [0.36;0.40] for the two English methods tested. In conclusion, despite the recent improvement of the translation models, there is a significant performance difference between the two approaches in favor of the native French method which is more efficient on French medical texts, even with few annotated documents.
Pyramid Deep Fusion Network for Two-Hand Reconstruction from RGB-D Images
Jul 12, 2023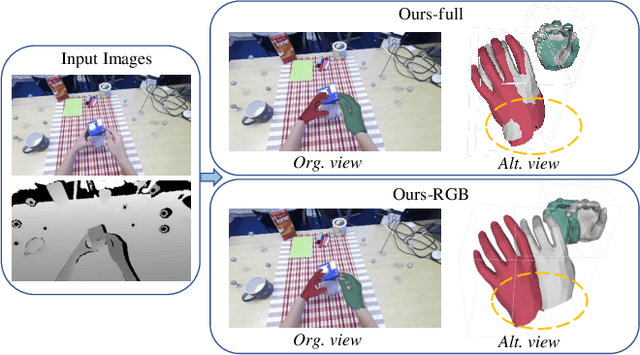
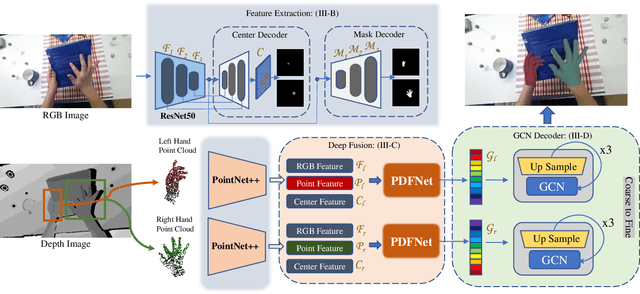
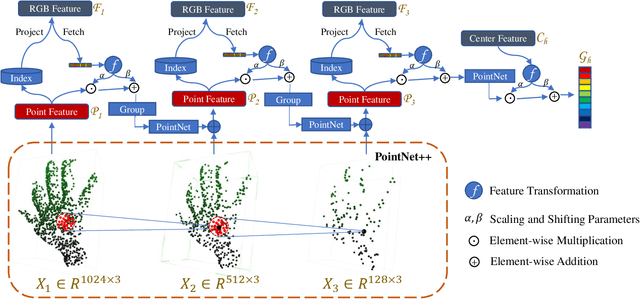

Accurately recovering the dense 3D mesh of both hands from monocular images poses considerable challenges due to occlusions and projection ambiguity. Most of the existing methods extract features from color images to estimate the root-aligned hand meshes, which neglect the crucial depth and scale information in the real world. Given the noisy sensor measurements with limited resolution, depth-based methods predict 3D keypoints rather than a dense mesh. These limitations motivate us to take advantage of these two complementary inputs to acquire dense hand meshes on a real-world scale. In this work, we propose an end-to-end framework for recovering dense meshes for both hands, which employ single-view RGB-D image pairs as input. The primary challenge lies in effectively utilizing two different input modalities to mitigate the blurring effects in RGB images and noises in depth images. Instead of directly treating depth maps as additional channels for RGB images, we encode the depth information into the unordered point cloud to preserve more geometric details. Specifically, our framework employs ResNet50 and PointNet++ to derive features from RGB and point cloud, respectively. Additionally, we introduce a novel pyramid deep fusion network (PDFNet) to aggregate features at different scales, which demonstrates superior efficacy compared to previous fusion strategies. Furthermore, we employ a GCN-based decoder to process the fused features and recover the corresponding 3D pose and dense mesh. Through comprehensive ablation experiments, we have not only demonstrated the effectiveness of our proposed fusion algorithm but also outperformed the state-of-the-art approaches on publicly available datasets. To reproduce the results, we will make our source code and models publicly available at {\url{https://github.com/zijinxuxu/PDFNet}}.
Explainable Recommender with Geometric Information Bottleneck
May 09, 2023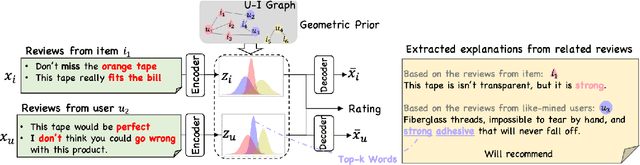
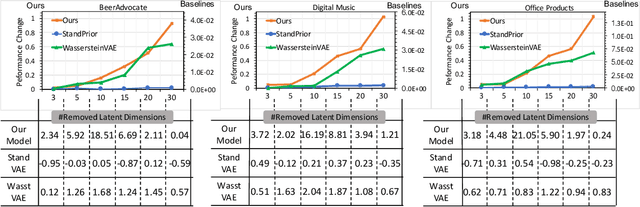

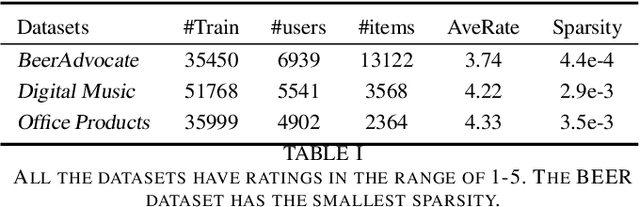
Explainable recommender systems can explain their recommendation decisions, enhancing user trust in the systems. Most explainable recommender systems either rely on human-annotated rationales to train models for explanation generation or leverage the attention mechanism to extract important text spans from reviews as explanations. The extracted rationales are often confined to an individual review and may fail to identify the implicit features beyond the review text. To avoid the expensive human annotation process and to generate explanations beyond individual reviews, we propose to incorporate a geometric prior learnt from user-item interactions into a variational network which infers latent factors from user-item reviews. The latent factors from an individual user-item pair can be used for both recommendation and explanation generation, which naturally inherit the global characteristics encoded in the prior knowledge. Experimental results on three e-commerce datasets show that our model significantly improves the interpretability of a variational recommender using the Wasserstein distance while achieving performance comparable to existing content-based recommender systems in terms of recommendation behaviours.
The Double Helix inside the NLP Transformer
Jun 23, 2023
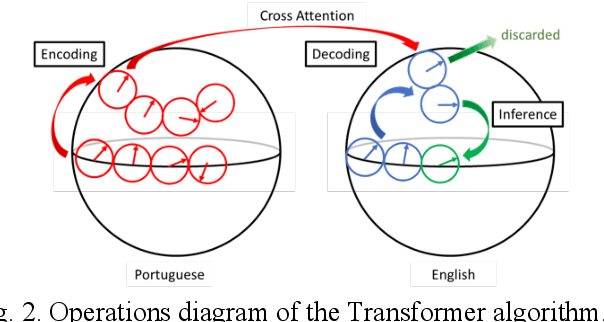
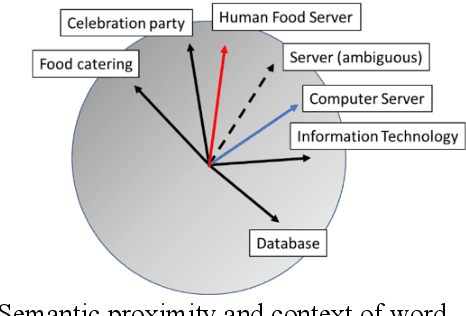
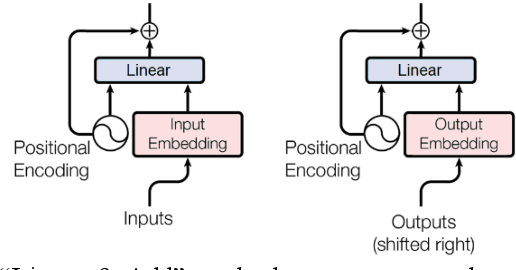
We introduce a framework for analyzing various types of information in an NLP Transformer. In this approach, we distinguish four layers of information: positional, syntactic, semantic, and contextual. We also argue that the common practice of adding positional information to semantic embedding is sub-optimal and propose instead a Linear-and-Add approach. Our analysis reveals an autogenetic separation of positional information through the deep layers. We show that the distilled positional components of the embedding vectors follow the path of a helix, both on the encoder side and on the decoder side. We additionally show that on the encoder side, the conceptual dimensions generate Part-of-Speech (PoS) clusters. On the decoder side, we show that a di-gram approach helps to reveal the PoS clusters of the next token. Our approach paves a way to elucidate the processing of information through the deep layers of an NLP Transformer.