 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Measuring Faithfulness in Chain-of-Thought Reasoning
Jul 17, 2023


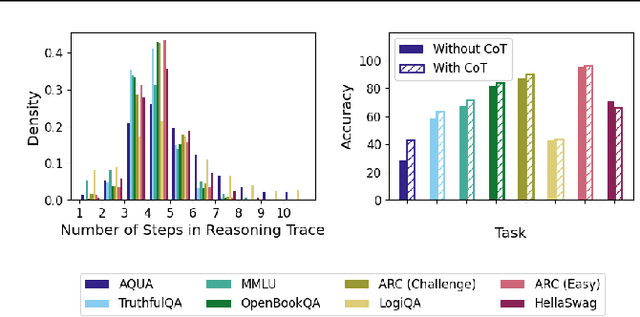
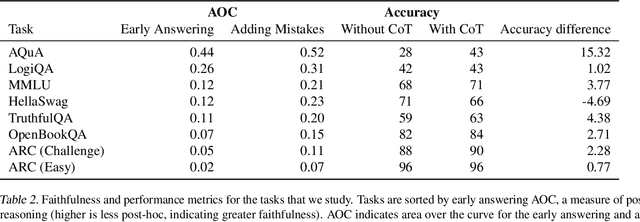
Large language models (LLMs) perform better when they produce step-by-step, "Chain-of-Thought" (CoT) reasoning before answering a question, but it is unclear if the stated reasoning is a faithful explanation of the model's actual reasoning (i.e., its process for answering the question). We investigate hypotheses for how CoT reasoning may be unfaithful, by examining how the model predictions change when we intervene on the CoT (e.g., by adding mistakes or paraphrasing it). Models show large variation across tasks in how strongly they condition on the CoT when predicting their answer, sometimes relying heavily on the CoT and other times primarily ignoring it. CoT's performance boost does not seem to come from CoT's added test-time compute alone or from information encoded via the particular phrasing of the CoT. As models become larger and more capable, they produce less faithful reasoning on most tasks we study. Overall, our results suggest that CoT can be faithful if the circumstances such as the model size and task are carefully chosen.
Hierarchical Spatio-Temporal Representation Learning for Gait Recognition
Jul 19, 2023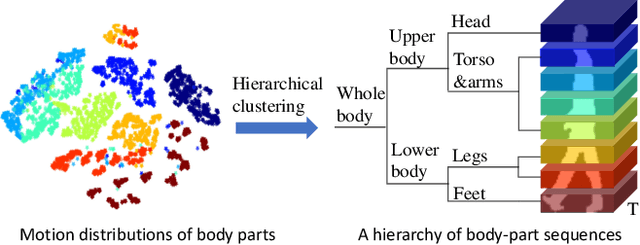
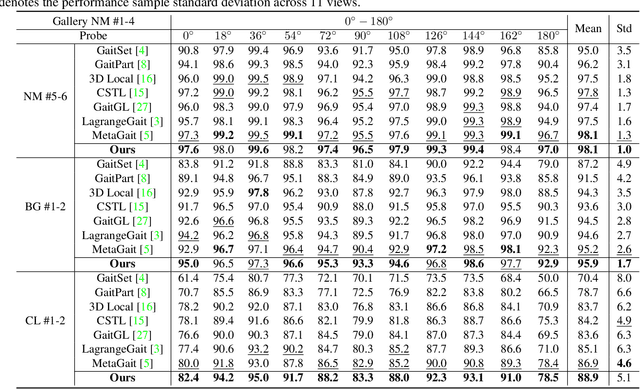
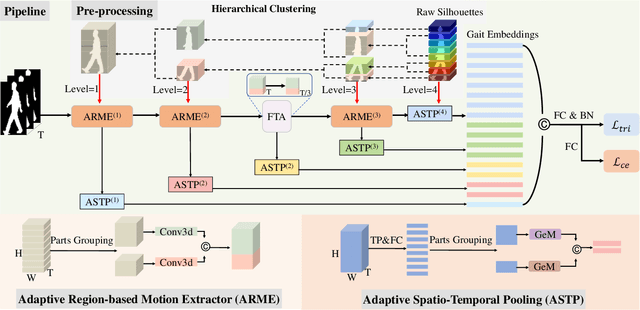
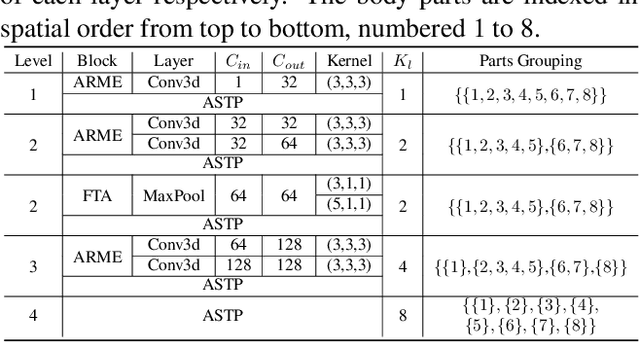
Gait recognition is a biometric technique that identifies individuals by their unique walking styles, which is suitable for unconstrained environments and has a wide range of applications. While current methods focus on exploiting body part-based representations, they often neglect the hierarchical dependencies between local motion patterns. In this paper, we propose a hierarchical spatio-temporal representation learning (HSTL) framework for extracting gait features from coarse to fine. Our framework starts with a hierarchical clustering analysis to recover multi-level body structures from the whole body to local details. Next, an adaptive region-based motion extractor (ARME) is designed to learn region-independent motion features. The proposed HSTL then stacks multiple ARMEs in a top-down manner, with each ARME corresponding to a specific partition level of the hierarchy. An adaptive spatio-temporal pooling (ASTP) module is used to capture gait features at different levels of detail to perform hierarchical feature mapping. Finally, a frame-level temporal aggregation (FTA) module is employed to reduce redundant information in gait sequences through multi-scale temporal downsampling. Extensive experiments on CASIA-B, OUMVLP, GREW, and Gait3D datasets demonstrate that our method outperforms the state-of-the-art while maintaining a reasonable balance between model accuracy and complexity.
What can we learn from Data Leakage and Unlearning for Law?
Jul 19, 2023Large Language Models (LLMs) have a privacy concern because they memorize training data (including personally identifiable information (PII) like emails and phone numbers) and leak it during inference. A company can train an LLM on its domain-customized data which can potentially also include their users' PII. In order to comply with privacy laws such as the "right to be forgotten", the data points of users that are most vulnerable to extraction could be deleted. We find that once the most vulnerable points are deleted, a new set of points become vulnerable to extraction. So far, little attention has been given to understanding memorization for fine-tuned models. In this work, we also show that not only do fine-tuned models leak their training data but they also leak the pre-training data (and PII) memorized during the pre-training phase. The property of new data points becoming vulnerable to extraction after unlearning and leakage of pre-training data through fine-tuned models can pose significant privacy and legal concerns for companies that use LLMs to offer services. We hope this work will start an interdisciplinary discussion within AI and law communities regarding the need for policies to tackle these issues.
Probabilistic Forecasting with Coherent Aggregation
Jul 19, 2023Obtaining accurate probabilistic forecasts while respecting hierarchical information is an important operational challenge in many applications, perhaps most obviously in energy management, supply chain planning, and resource allocation. The basic challenge, especially for multivariate forecasting, is that forecasts are often required to be coherent with respect to the hierarchical structure. In this paper, we propose a new model which leverages a factor model structure to produce coherent forecasts by construction. This is a consequence of a simple (exchangeability) observation: permuting \textit{}base-level series in the hierarchy does not change their aggregates. Our model uses a convolutional neural network to produce parameters for the factors, their loadings and base-level distributions; it produces samples which can be differentiated with respect to the model's parameters; and it can therefore optimize for any sample-based loss function, including the Continuous Ranked Probability Score and quantile losses. We can choose arbitrary continuous distributions for the factor and the base-level distributions. We compare our method to two previous methods which can be optimized end-to-end, while enforcing coherent aggregation. Our model achieves significant improvements: between $11.8-41.4\%$ on three hierarchical forecasting datasets. We also analyze the influence of parameters in our model with respect to base-level distribution and number of factors.
Bidirectionally Deformable Motion Modulation For Video-based Human Pose Transfer
Jul 18, 2023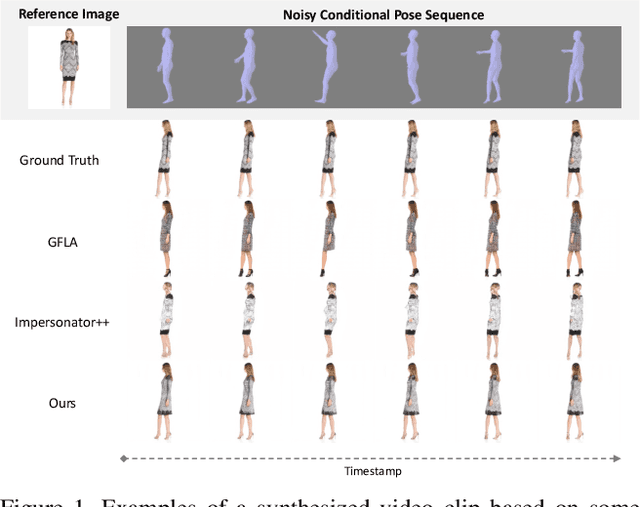


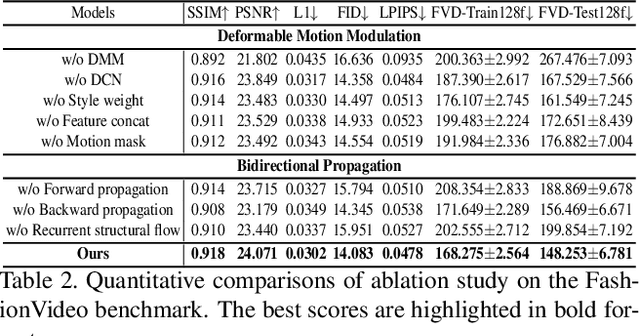
Video-based human pose transfer is a video-to-video generation task that animates a plain source human image based on a series of target human poses. Considering the difficulties in transferring highly structural patterns on the garments and discontinuous poses, existing methods often generate unsatisfactory results such as distorted textures and flickering artifacts. To address these issues, we propose a novel Deformable Motion Modulation (DMM) that utilizes geometric kernel offset with adaptive weight modulation to simultaneously perform feature alignment and style transfer. Different from normal style modulation used in style transfer, the proposed modulation mechanism adaptively reconstructs smoothed frames from style codes according to the object shape through an irregular receptive field of view. To enhance the spatio-temporal consistency, we leverage bidirectional propagation to extract the hidden motion information from a warped image sequence generated by noisy poses. The proposed feature propagation significantly enhances the motion prediction ability by forward and backward propagation. Both quantitative and qualitative experimental results demonstrate superiority over the state-of-the-arts in terms of image fidelity and visual continuity. The source code is publicly available at github.com/rocketappslab/bdmm.
Balancing Privacy and Progress in Artificial Intelligence: Anonymization in Histopathology for Biomedical Research and Education
Jul 18, 2023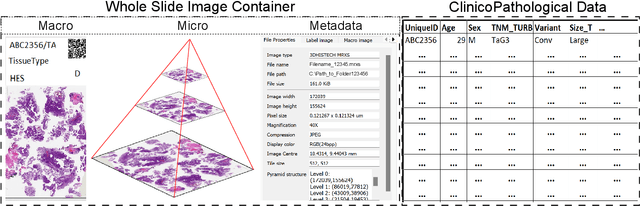
The advancement of biomedical research heavily relies on access to large amounts of medical data. In the case of histopathology, Whole Slide Images (WSI) and clinicopathological information are valuable for developing Artificial Intelligence (AI) algorithms for Digital Pathology (DP). Transferring medical data "as open as possible" enhances the usability of the data for secondary purposes but poses a risk to patient privacy. At the same time, existing regulations push towards keeping medical data "as closed as necessary" to avoid re-identification risks. Generally, these legal regulations require the removal of sensitive data but do not consider the possibility of data linkage attacks due to modern image-matching algorithms. In addition, the lack of standardization in DP makes it harder to establish a single solution for all formats of WSIs. These challenges raise problems for bio-informatics researchers in balancing privacy and progress while developing AI algorithms. This paper explores the legal regulations and terminologies for medical data-sharing. We review existing approaches and highlight challenges from the histopathological perspective. We also present a data-sharing guideline for histological data to foster multidisciplinary research and education.
Zero-shot Query Reformulation for Conversational Search
Jul 18, 2023
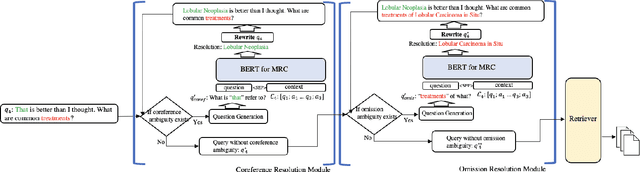
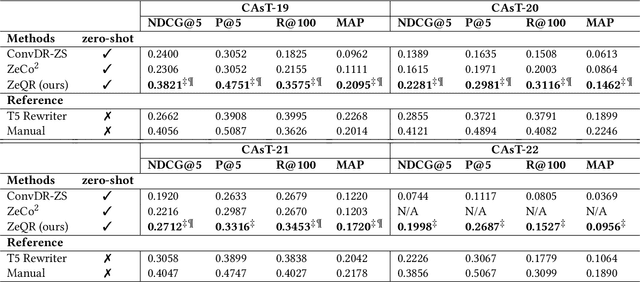
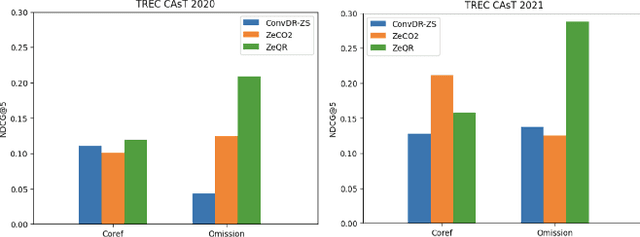
As the popularity of voice assistants continues to surge, conversational search has gained increased attention in Information Retrieval. However, data sparsity issues in conversational search significantly hinder the progress of supervised conversational search methods. Consequently, researchers are focusing more on zero-shot conversational search approaches. Nevertheless, existing zero-shot methods face three primary limitations: they are not universally applicable to all retrievers, their effectiveness lacks sufficient explainability, and they struggle to resolve common conversational ambiguities caused by omission. To address these limitations, we introduce a novel Zero-shot Query Reformulation (ZeQR) framework that reformulates queries based on previous dialogue contexts without requiring supervision from conversational search data. Specifically, our framework utilizes language models designed for machine reading comprehension tasks to explicitly resolve two common ambiguities: coreference and omission, in raw queries. In comparison to existing zero-shot methods, our approach is universally applicable to any retriever without additional adaptation or indexing. It also provides greater explainability and effectively enhances query intent understanding because ambiguities are explicitly and proactively resolved. Through extensive experiments on four TREC conversational datasets, we demonstrate the effectiveness of our method, which consistently outperforms state-of-the-art baselines.
Linearized Relative Positional Encoding
Jul 18, 2023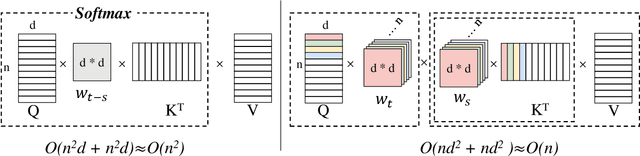
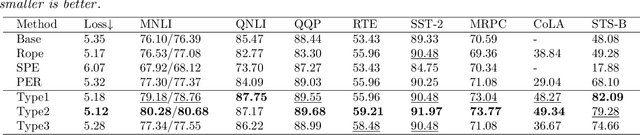

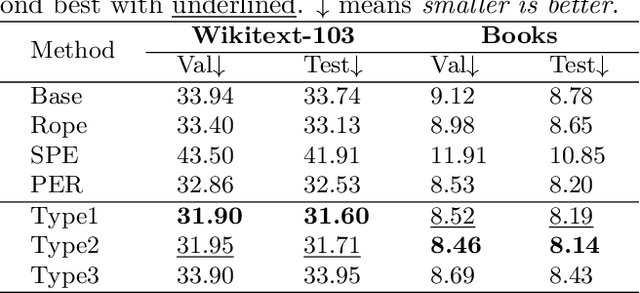
Relative positional encoding is widely used in vanilla and linear transformers to represent positional information. However, existing encoding methods of a vanilla transformer are not always directly applicable to a linear transformer, because the latter requires a decomposition of the query and key representations into separate kernel functions. Nevertheless, principles for designing encoding methods suitable for linear transformers remain understudied. In this work, we put together a variety of existing linear relative positional encoding approaches under a canonical form and further propose a family of linear relative positional encoding algorithms via unitary transformation. Our formulation leads to a principled framework that can be used to develop new relative positional encoding methods that preserve linear space-time complexity. Equipped with different models, the proposed linearized relative positional encoding (LRPE) family derives effective encoding for various applications. Experiments show that compared with existing methods, LRPE achieves state-of-the-art performance in language modeling, text classification, and image classification. Meanwhile, it emphasizes a general paradigm for designing broadly more relative positional encoding methods that are applicable to linear transformers. The code is available at https://github.com/OpenNLPLab/Lrpe.
Proceedings Nineteenth conference on Theoretical Aspects of Rationality and Knowledge
Jul 18, 2023The TARK conference (Theoretical Aspects of Rationality and Knowledge) is a conference that aims to bring together researchers from a wide variety of fields, including computer science, artificial intelligence, game theory, decision theory, philosophy, logic, linguistics, and cognitive science. Its goal is to further our understanding of interdisciplinary issues involving reasoning about rationality and knowledge. Previous conferences have been held biennially around the world since 1986, on the initiative of Joe Halpern (Cornell University). Topics of interest include, but are not limited to, semantic models for knowledge, belief, awareness and uncertainty, bounded rationality and resource-bounded reasoning, commonsense epistemic reasoning, epistemic logic, epistemic game theory, knowledge and action, applications of reasoning about knowledge and other mental states, belief revision, computational social choice, algorithmic game theory, and foundations of multi-agent systems. Information about TARK, including conference proceedings, is available at http://www.tark.org/ These proceedings contain the papers that have been accepted for presentation at the Nineteenth Conference on Theoretical Aspects of Rationality and Knowledge (TARK 2023), held between June 28 and June 30, 2023, at the University of Oxford, United Kingdom. The conference website can be found at https://sites.google.com/view/tark-2023
CSSL-RHA: Contrastive Self-Supervised Learning for Robust Handwriting Authentication
Jul 18, 2023Handwriting authentication is a valuable tool used in various fields, such as fraud prevention and cultural heritage protection. However, it remains a challenging task due to the complex features, severe damage, and lack of supervision. In this paper, we propose a novel Contrastive Self-Supervised Learning framework for Robust Handwriting Authentication (CSSL-RHA) to address these issues. It can dynamically learn complex yet important features and accurately predict writer identities. Specifically, to remove the negative effects of imperfections and redundancy, we design an information-theoretic filter for pre-processing and propose a novel adaptive matching scheme to represent images as patches of local regions dominated by more important features. Through online optimization at inference time, the most informative patch embeddings are identified as the "most important" elements. Furthermore, we employ contrastive self-supervised training with a momentum-based paradigm to learn more general statistical structures of handwritten data without supervision. We conduct extensive experiments on five benchmark datasets and our manually annotated dataset EN-HA, which demonstrate the superiority of our CSSL-RHA compared to baselines. Additionally, we show that our proposed model can still effectively achieve authentication even under abnormal circumstances, such as data falsification and corruption.