 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Radar Odometry for Autonomous Ground Vehicles: A Survey of Methods and Datasets
Jul 15, 2023
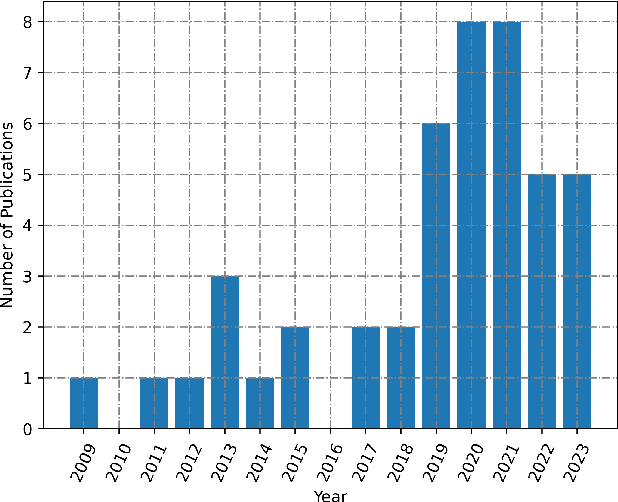
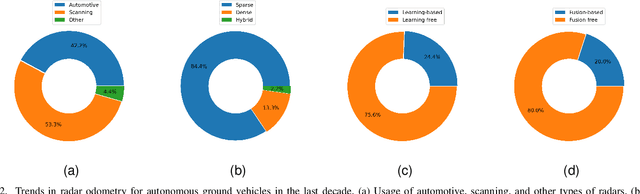

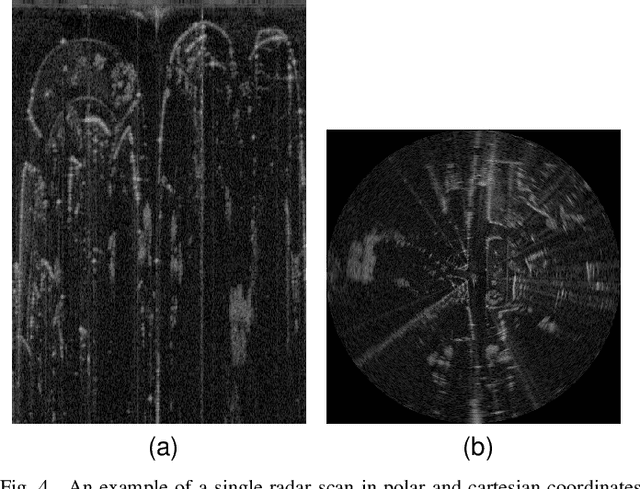
Radar odometry has been gaining attention in the last decade. It stands as one of the best solutions for robotic state estimation in unfavorable conditions; conditions where other interoceptive and exteroceptive sensors may fall short. Radars are widely adopted, resilient to weather and illumination, and provide Doppler information which make them very attractive for such tasks. This article presents an extensive survey of the latest work on ground-based radar odometry for autonomous robots. It covers technologies, datasets, metrics, and approaches that have been developed in the last decade in addition to in-depth analysis and categorization of the various methods and techniques applied to tackle this problem. This article concludes with challenges and future recommendations to advance the field of radar odometry making it a great starting point for newcomers and a valuable reference for experienced researchers.
Energy optimization for Full-Duplex Wireless-Powered IoT Networks using Rotary-Wing UAV with Multiple Antennas
Jul 05, 2023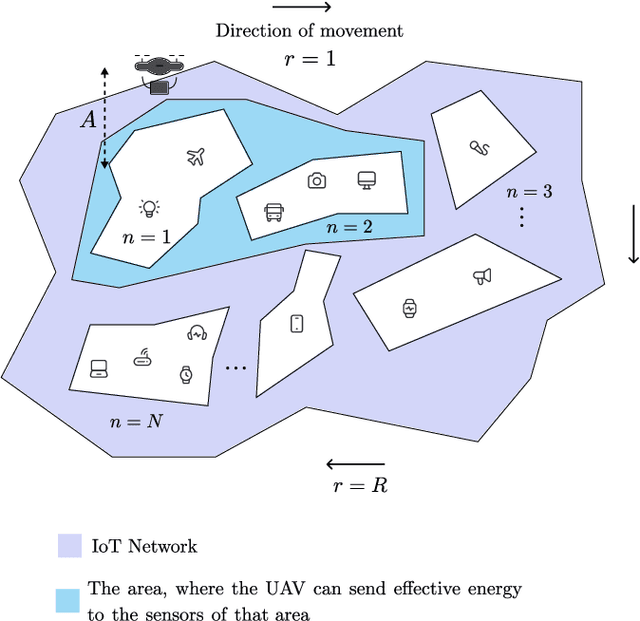
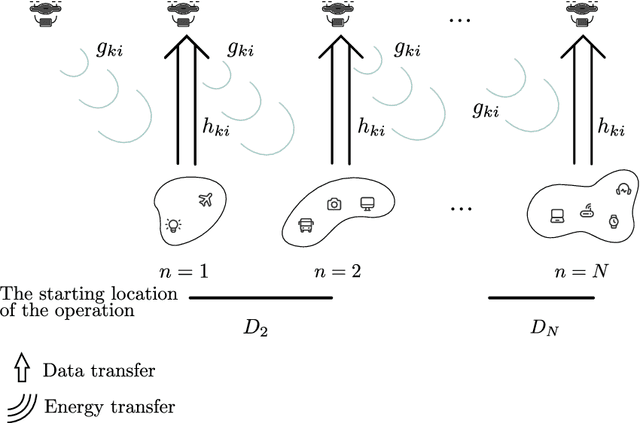
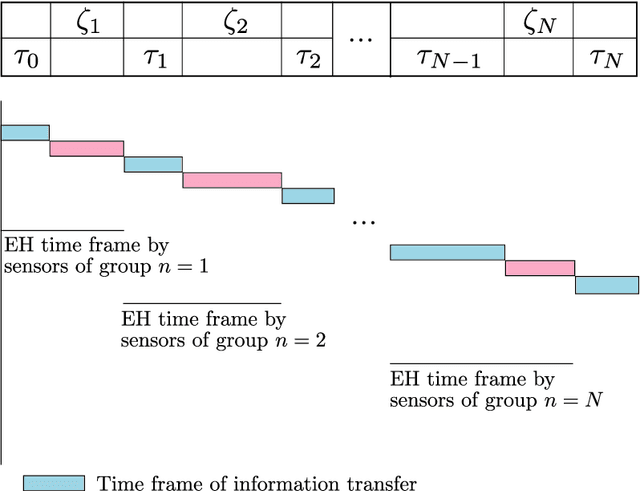
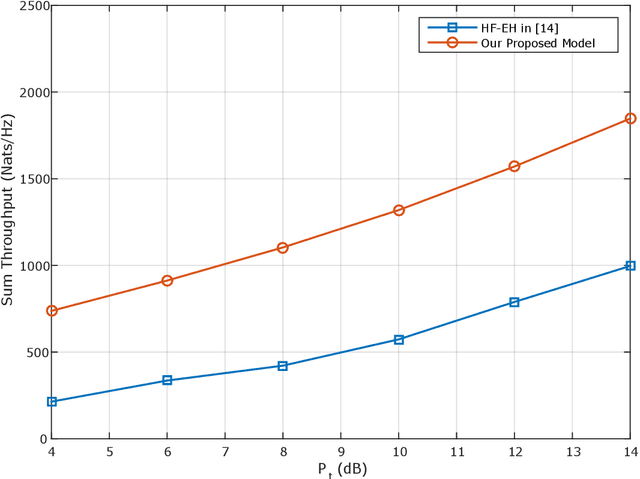
In this paper, we propose a novel design for the rotary-wing unmanned aerial vehicle (UAV)-enabled full-duplex (FD) wireless-powered Internet of Things (IoT) networks. In this network, the UAV is equipped with an antenna array, and the $K$ IoT sensors, which are distributed randomly, use single-antenna to communicate. By sending the energy, the UAV as a hybrid access point, charges the sensors and collects information from them. Then, to manage the time and optimize the energy, the sensors are divided into N groups, so that the UAV equipped with multi-input multi-output (MIMO) technology can serve the sensors in a group, during the total time $T$. We provide a simple implementation of the wireless power transfer protocol in the sensors by using the time division multiple access (TDMA) scheme to receive information from the users. In other words, the sensors of each group receive energy from the UAV, when it hovers over the sensors of the previous group, and also when the UAV flies over the previous group to the current group. The sensors of each group send their information to the UAV, when the UAV is hovering over their group. Under these assumptions, we formulate two optimization problems: a sum throughput maximization problem, and a total time minimization problem. Numerical results show that our proposed optimal network provides better performance than the existing networks. In fact, our novel design can serve more sensors at the cost of using more antennas compared to that of the conventional networks.
Learning World Models with Identifiable Factorization
Jun 27, 2023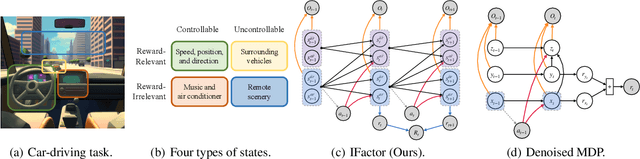
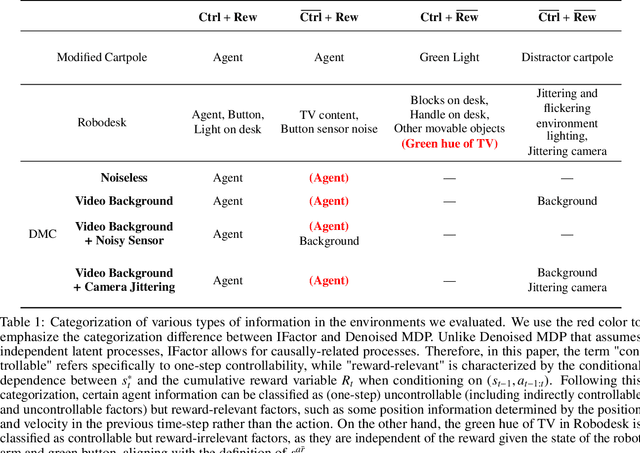
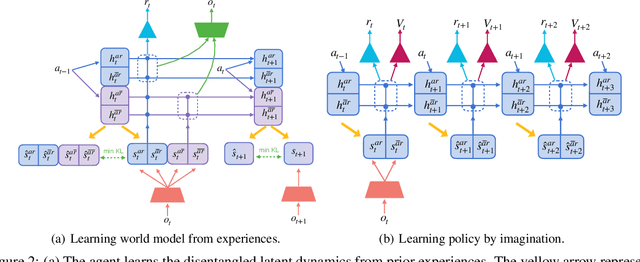
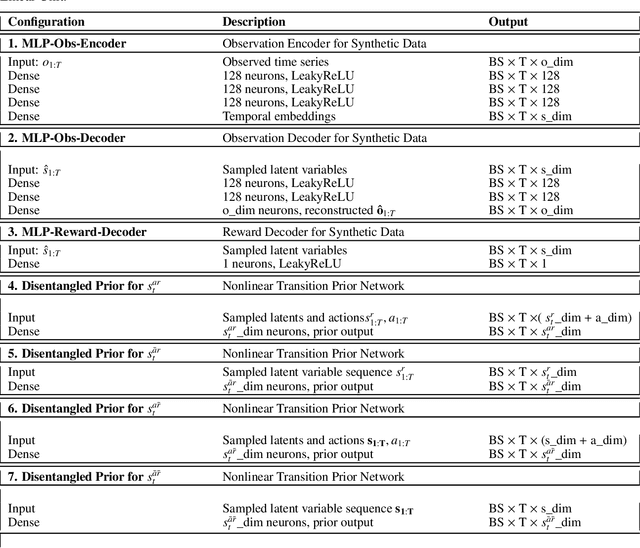
Extracting a stable and compact representation of the environment is crucial for efficient reinforcement learning in high-dimensional, noisy, and non-stationary environments. Different categories of information coexist in such environments -- how to effectively extract and disentangle these information remains a challenging problem. In this paper, we propose IFactor, a general framework to model four distinct categories of latent state variables that capture various aspects of information within the RL system, based on their interactions with actions and rewards. Our analysis establishes block-wise identifiability of these latent variables, which not only provides a stable and compact representation but also discloses that all reward-relevant factors are significant for policy learning. We further present a practical approach to learning the world model with identifiable blocks, ensuring the removal of redundants but retaining minimal and sufficient information for policy optimization. Experiments in synthetic worlds demonstrate that our method accurately identifies the ground-truth latent variables, substantiating our theoretical findings. Moreover, experiments in variants of the DeepMind Control Suite and RoboDesk showcase the superior performance of our approach over baselines.
INFLECT-DGNN: Influencer Prediction with Dynamic Graph Neural Networks
Jul 16, 2023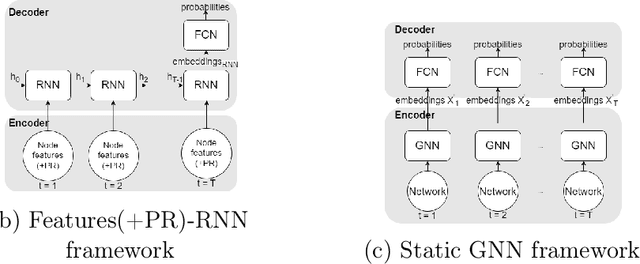
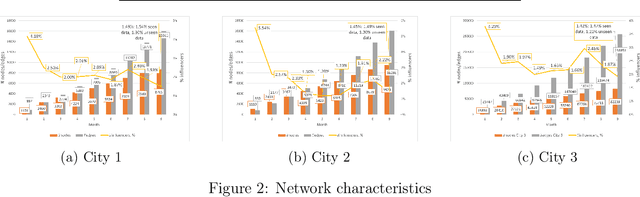
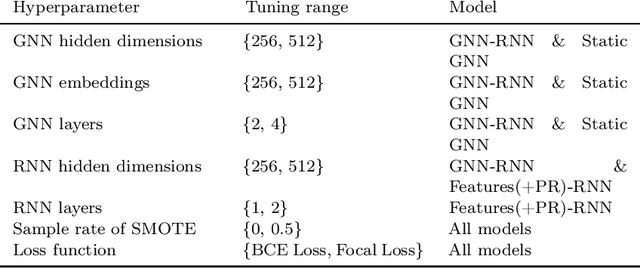
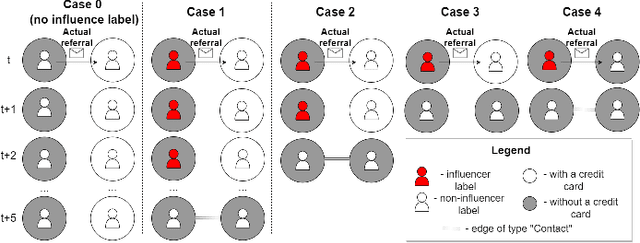
Leveraging network information for predictive modeling has become widespread in many domains. Within the realm of referral and targeted marketing, influencer detection stands out as an area that could greatly benefit from the incorporation of dynamic network representation due to the ongoing development of customer-brand relationships. To elaborate this idea, we introduce INFLECT-DGNN, a new framework for INFLuencer prEdiCTion with Dynamic Graph Neural Networks that combines Graph Neural Networks (GNN) and Recurrent Neural Networks (RNN) with weighted loss functions, the Synthetic Minority Oversampling TEchnique (SMOTE) adapted for graph data, and a carefully crafted rolling-window strategy. To evaluate predictive performance, we utilize a unique corporate data set with networks of three cities and derive a profit-driven evaluation methodology for influencer prediction. Our results show how using RNN to encode temporal attributes alongside GNNs significantly improves predictive performance. We compare the results of various models to demonstrate the importance of capturing graph representation, temporal dependencies, and using a profit-driven methodology for evaluation.
Frequency Regularization: Restricting Information Redundancy of Convolutional Neural Networks
Apr 20, 2023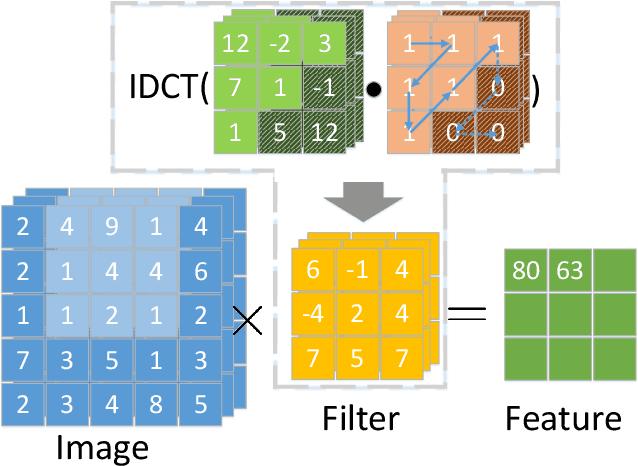
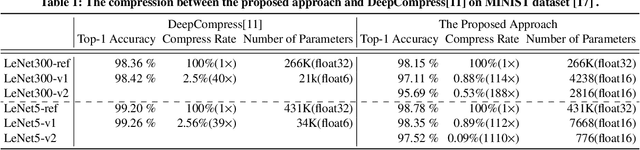
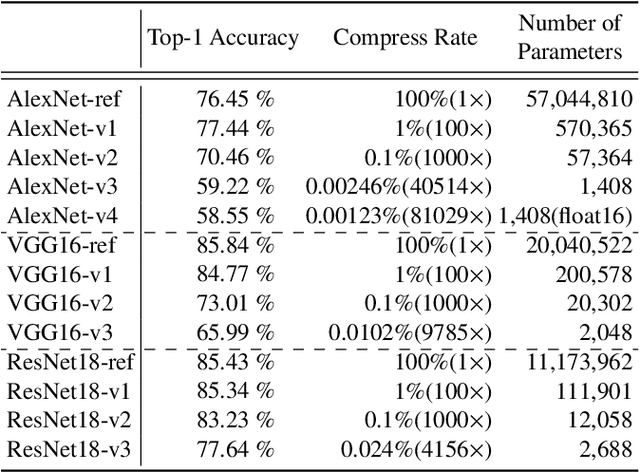

Convolutional neural networks have demonstrated impressive results in many computer vision tasks. However, the increasing size of these networks raises concerns about the information overload resulting from the large number of network parameters. In this paper, we propose Frequency Regularization to restrict the non-zero elements of the network parameters in frequency domain. The proposed approach operates at the tensor level, and can be applied to almost all network architectures. Specifically, the tensors of parameters are maintained in the frequency domain, where high frequency components can be eliminated by zigzag setting tensor elements to zero. Then, the inverse discrete cosine transform (IDCT) is used to reconstruct the spatial tensors for matrix operations during network training. Since high frequency components of images are known to be less critical, a large proportion of these parameters can be set to zero when networks are trained with the proposed frequency regularization. Comprehensive evaluations on various state-of-the-art network architectures, including LeNet, Alexnet, VGG, Resnet, ViT, UNet, GAN, and VAE, demonstrate the effectiveness of the proposed frequency regularization. Under the condition of a very small accuracy decrease (less than 2\%), a LeNet5 with 0.4M parameters can be represented by only 776 float16 numbers(over 1100$\times$), and a UNet with 34M parameters can be represented by only 759 float16 numbers (over 80000$\times$).
Impatient Bandits: Optimizing Recommendations for the Long-Term Without Delay
Jul 20, 2023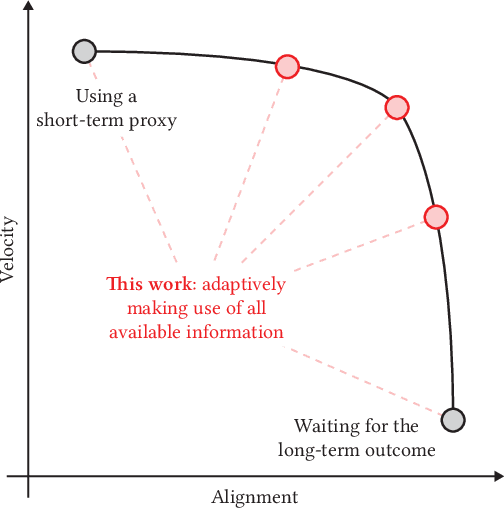

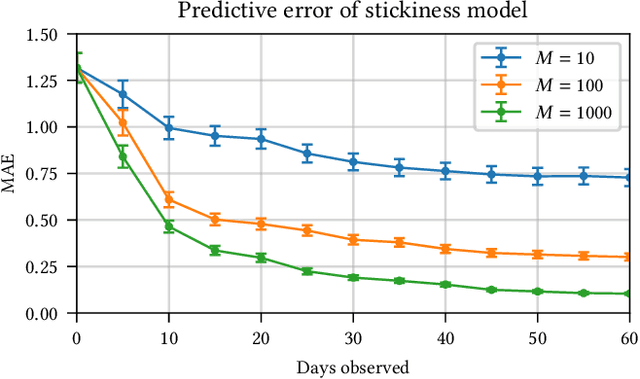
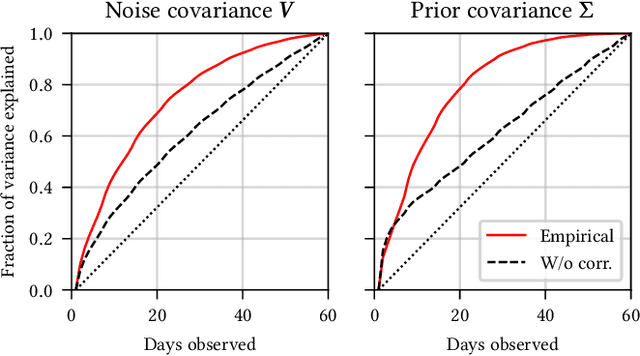
Recommender systems are a ubiquitous feature of online platforms. Increasingly, they are explicitly tasked with increasing users' long-term satisfaction. In this context, we study a content exploration task, which we formalize as a multi-armed bandit problem with delayed rewards. We observe that there is an apparent trade-off in choosing the learning signal: Waiting for the full reward to become available might take several weeks, hurting the rate at which learning happens, whereas measuring short-term proxy rewards reflects the actual long-term goal only imperfectly. We address this challenge in two steps. First, we develop a predictive model of delayed rewards that incorporates all information obtained to date. Full observations as well as partial (short or medium-term) outcomes are combined through a Bayesian filter to obtain a probabilistic belief. Second, we devise a bandit algorithm that takes advantage of this new predictive model. The algorithm quickly learns to identify content aligned with long-term success by carefully balancing exploration and exploitation. We apply our approach to a podcast recommendation problem, where we seek to identify shows that users engage with repeatedly over two months. We empirically validate that our approach results in substantially better performance compared to approaches that either optimize for short-term proxies, or wait for the long-term outcome to be fully realized.
Ensemble Learning based Anomaly Detection for IoT Cybersecurity via Bayesian Hyperparameters Sensitivity Analysis
Jul 20, 2023The Internet of Things (IoT) integrates more than billions of intelligent devices over the globe with the capability of communicating with other connected devices with little to no human intervention. IoT enables data aggregation and analysis on a large scale to improve life quality in many domains. In particular, data collected by IoT contain a tremendous amount of information for anomaly detection. The heterogeneous nature of IoT is both a challenge and an opportunity for cybersecurity. Traditional approaches in cybersecurity monitoring often require different kinds of data pre-processing and handling for various data types, which might be problematic for datasets that contain heterogeneous features. However, heterogeneous types of network devices can often capture a more diverse set of signals than a single type of device readings, which is particularly useful for anomaly detection. In this paper, we present a comprehensive study on using ensemble machine learning methods for enhancing IoT cybersecurity via anomaly detection. Rather than using one single machine learning model, ensemble learning combines the predictive power from multiple models, enhancing their predictive accuracy in heterogeneous datasets rather than using one single machine learning model. We propose a unified framework with ensemble learning that utilises Bayesian hyperparameter optimisation to adapt to a network environment that contains multiple IoT sensor readings. Experimentally, we illustrate their high predictive power when compared to traditional methods.
General Debiasing for Multimodal Sentiment Analysis
Jul 20, 2023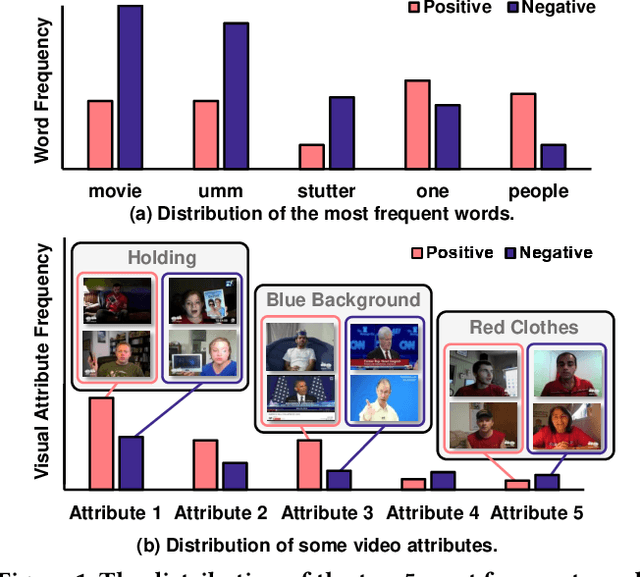

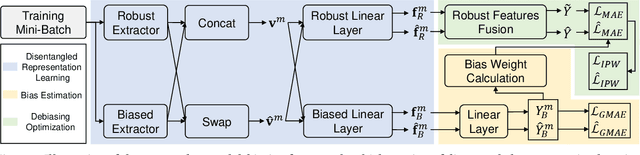
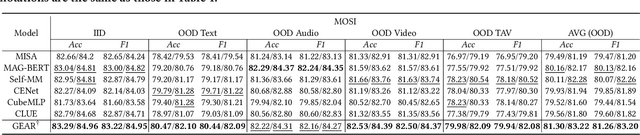
Existing work on Multimodal Sentiment Analysis (MSA) utilizes multimodal information for prediction yet unavoidably suffers from fitting the spurious correlations between multimodal features and sentiment labels. For example, if most videos with a blue background have positive labels in a dataset, the model will rely on such correlations for prediction, while ``blue background'' is not a sentiment-related feature. To address this problem, we define a general debiasing MSA task, which aims to enhance the Out-Of-Distribution (OOD) generalization ability of MSA models by reducing their reliance on spurious correlations. To this end, we propose a general debiasing framework based on Inverse Probability Weighting (IPW), which adaptively assigns small weights to the samples with larger bias i.e., the severer spurious correlations). The key to this debiasing framework is to estimate the bias of each sample, which is achieved by two steps: 1) disentangling the robust features and biased features in each modality, and 2) utilizing the biased features to estimate the bias. Finally, we employ IPW to reduce the effects of large-biased samples, facilitating robust feature learning for sentiment prediction. To examine the model's generalization ability, we keep the original testing sets on two benchmarks and additionally construct multiple unimodal and multimodal OOD testing sets. The empirical results demonstrate the superior generalization ability of our proposed framework. We have released the code and data to facilitate the reproduction.
Boosting 3-DoF Ground-to-Satellite Camera Localization Accuracy via Geometry-Guided Cross-View Transformer
Jul 20, 2023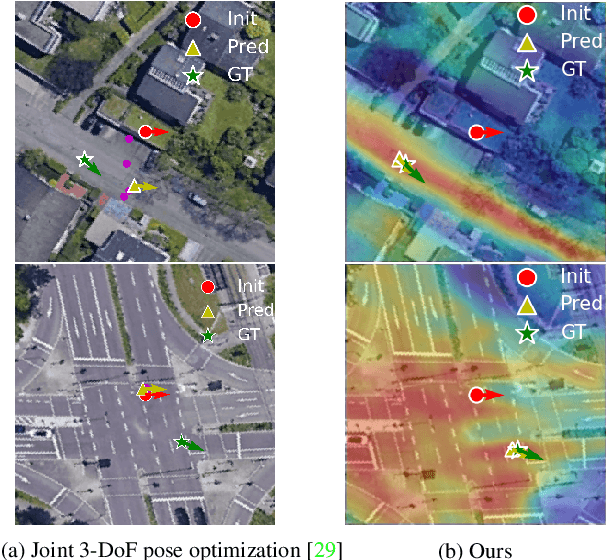
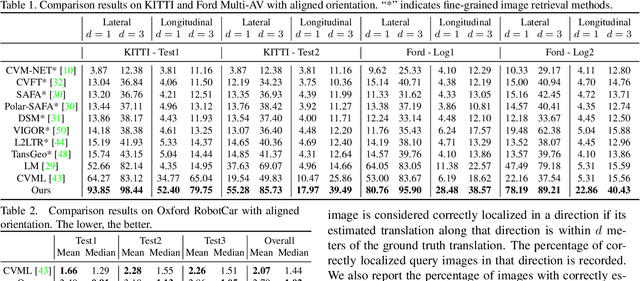
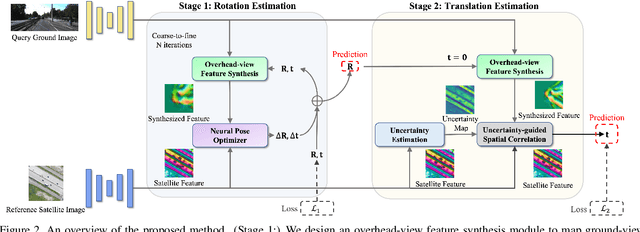
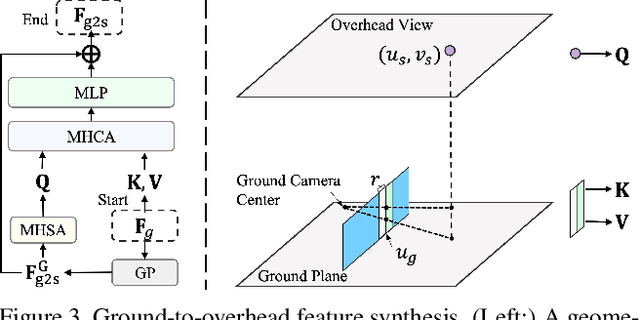
Image retrieval-based cross-view localization methods often lead to very coarse camera pose estimation, due to the limited sampling density of the database satellite images. In this paper, we propose a method to increase the accuracy of a ground camera's location and orientation by estimating the relative rotation and translation between the ground-level image and its matched/retrieved satellite image. Our approach designs a geometry-guided cross-view transformer that combines the benefits of conventional geometry and learnable cross-view transformers to map the ground-view observations to an overhead view. Given the synthesized overhead view and observed satellite feature maps, we construct a neural pose optimizer with strong global information embedding ability to estimate the relative rotation between them. After aligning their rotations, we develop an uncertainty-guided spatial correlation to generate a probability map of the vehicle locations, from which the relative translation can be determined. Experimental results demonstrate that our method significantly outperforms the state-of-the-art. Notably, the likelihood of restricting the vehicle lateral pose to be within 1m of its Ground Truth (GT) value on the cross-view KITTI dataset has been improved from $35.54\%$ to $76.44\%$, and the likelihood of restricting the vehicle orientation to be within $1^{\circ}$ of its GT value has been improved from $19.64\%$ to $99.10\%$.
Natural Language Instructions for Intuitive Human Interaction with Robotic Assistants in Field Construction Work
Jul 11, 2023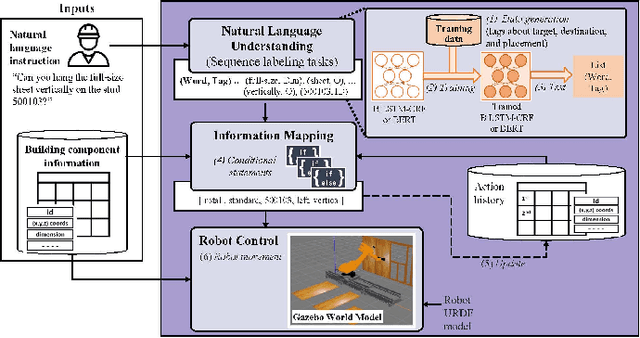
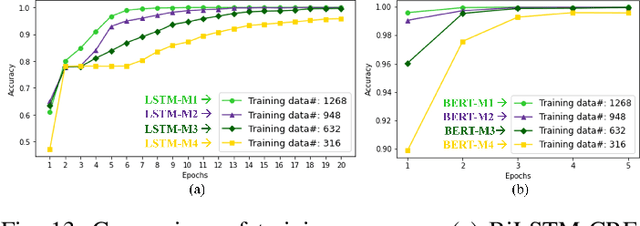

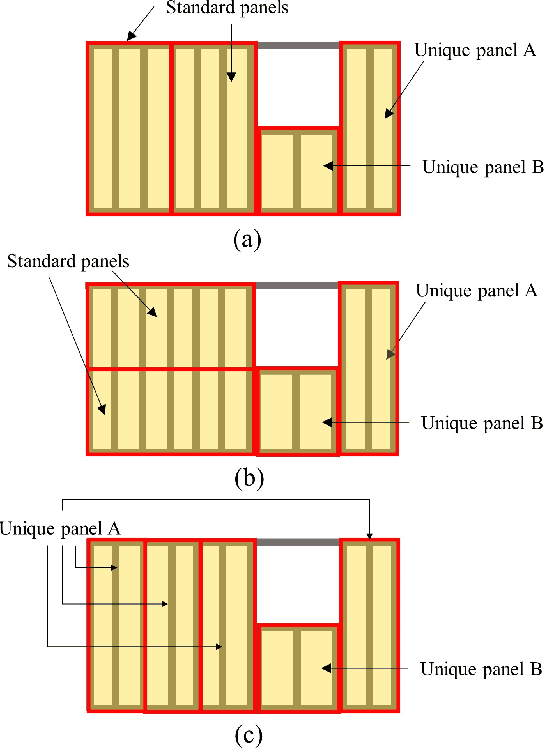
The introduction of robots is widely considered to have significant potential of alleviating the issues of worker shortage and stagnant productivity that afflict the construction industry. However, it is challenging to use fully automated robots in complex and unstructured construction sites. Human-Robot Collaboration (HRC) has shown promise of combining human workers' flexibility and robot assistants' physical abilities to jointly address the uncertainties inherent in construction work. When introducing HRC in construction, it is critical to recognize the importance of teamwork and supervision in field construction and establish a natural and intuitive communication system for the human workers and robotic assistants. Natural language-based interaction can enable intuitive and familiar communication with robots for human workers who are non-experts in robot programming. However, limited research has been conducted on this topic in construction. This paper proposes a framework to allow human workers to interact with construction robots based on natural language instructions. The proposed method consists of three stages: Natural Language Understanding (NLU), Information Mapping (IM), and Robot Control (RC). Natural language instructions are input to a language model to predict a tag for each word in the NLU module. The IM module uses the result of the NLU module and building component information to generate the final instructional output essential for a robot to acknowledge and perform the construction task. A case study for drywall installation is conducted to evaluate the proposed approach. The obtained results highlight the potential of using natural language-based interaction to replicate the communication that occurs between human workers within the context of human-robot teams.