 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Bayesian Future Fusion for Self-Supervised, High-Resolution, Off-Road Mapping
Mar 18, 2024

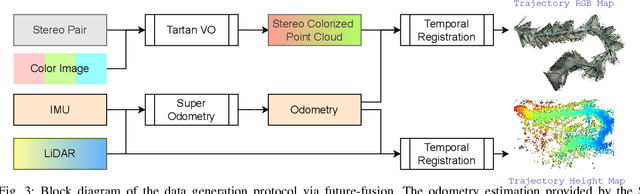

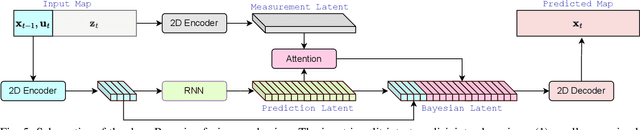
The limited sensing resolution of resource-constrained off-road vehicles poses significant challenges towards reliable off-road autonomy. To overcome this limitation, we propose a general framework based on fusing the future information (i.e. future fusion) for self-supervision. Recent approaches exploit this future information alongside the hand-crafted heuristics to directly supervise the targeted downstream tasks (e.g. traversability estimation). However, in this paper, we opt for a more general line of development - time-efficient completion of the highest resolution (i.e. 2cm per pixel) BEV map in a self-supervised manner via future fusion, which can be used for any downstream tasks for better longer range prediction. To this end, first, we create a high-resolution future-fusion dataset containing pairs of (RGB / height) raw sparse and noisy inputs and map-based dense labels. Next, to accommodate the noise and sparsity of the sensory information, especially in the distal regions, we design an efficient realization of the Bayes filter onto the vanilla convolutional network via the recurrent mechanism. Equipped with the ideas from SOTA generative models, our Bayesian structure effectively predicts high-quality BEV maps in the distal regions. Extensive evaluation on both the quality of completion and downstream task on our future-fusion dataset demonstrates the potential of our approach.
Sebastian, Basti, Wastl?! Recognizing Named Entities in Bavarian Dialectal Data
Mar 19, 2024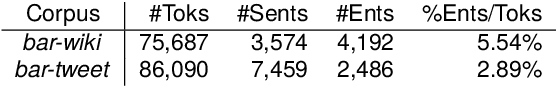
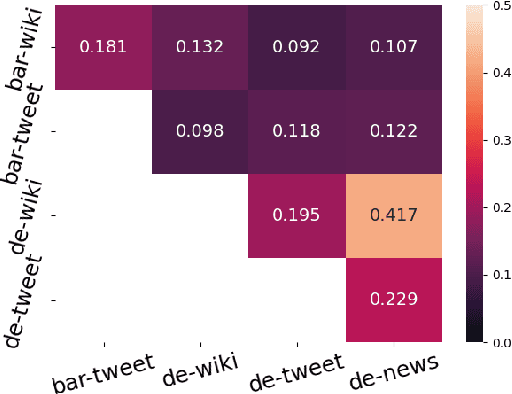
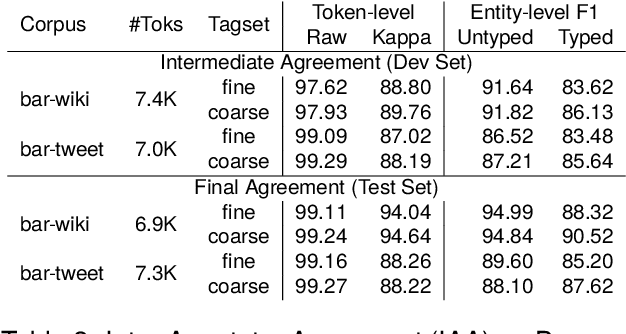
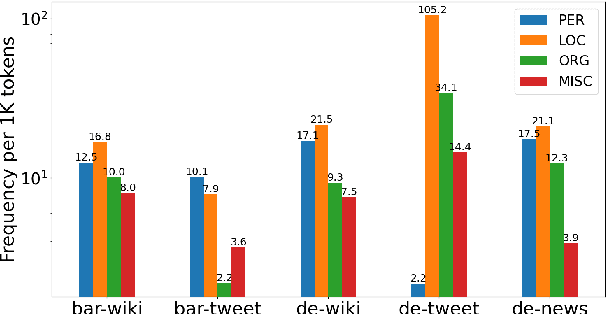
Named Entity Recognition (NER) is a fundamental task to extract key information from texts, but annotated resources are scarce for dialects. This paper introduces the first dialectal NER dataset for German, BarNER, with 161K tokens annotated on Bavarian Wikipedia articles (bar-wiki) and tweets (bar-tweet), using a schema adapted from German CoNLL 2006 and GermEval. The Bavarian dialect differs from standard German in lexical distribution, syntactic construction, and entity information. We conduct in-domain, cross-domain, sequential, and joint experiments on two Bavarian and three German corpora and present the first comprehensive NER results on Bavarian. Incorporating knowledge from the larger German NER (sub-)datasets notably improves on bar-wiki and moderately on bar-tweet. Inversely, training first on Bavarian contributes slightly to the seminal German CoNLL 2006 corpus. Moreover, with gold dialect labels on Bavarian tweets, we assess multi-task learning between five NER and two Bavarian-German dialect identification tasks and achieve NER SOTA on bar-wiki. We substantiate the necessity of our low-resource BarNER corpus and the importance of diversity in dialects, genres, and topics in enhancing model performance.
AlphaFin: Benchmarking Financial Analysis with Retrieval-Augmented Stock-Chain Framework
Mar 19, 2024
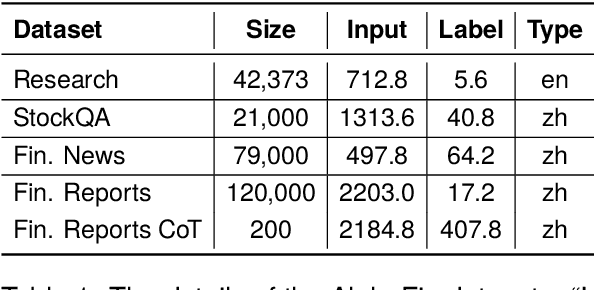
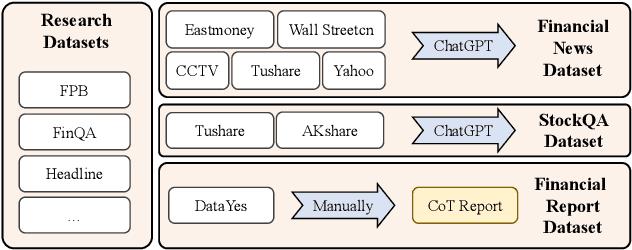
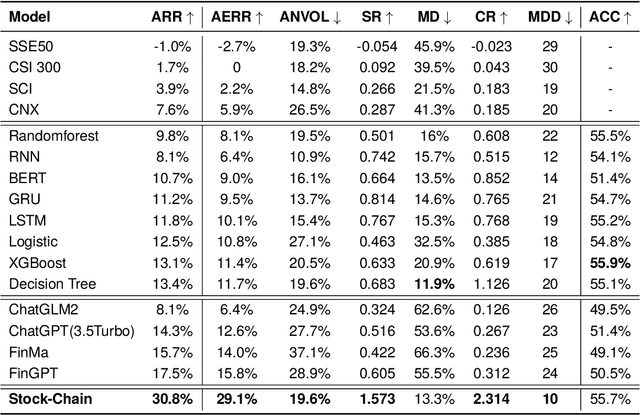
The task of financial analysis primarily encompasses two key areas: stock trend prediction and the corresponding financial question answering. Currently, machine learning and deep learning algorithms (ML&DL) have been widely applied for stock trend predictions, leading to significant progress. However, these methods fail to provide reasons for predictions, lacking interpretability and reasoning processes. Also, they can not integrate textual information such as financial news or reports. Meanwhile, large language models (LLMs) have remarkable textual understanding and generation ability. But due to the scarcity of financial training datasets and limited integration with real-time knowledge, LLMs still suffer from hallucinations and are unable to keep up with the latest information. To tackle these challenges, we first release AlphaFin datasets, combining traditional research datasets, real-time financial data, and handwritten chain-of-thought (CoT) data. It has a positive impact on training LLMs for completing financial analysis. We then use AlphaFin datasets to benchmark a state-of-the-art method, called Stock-Chain, for effectively tackling the financial analysis task, which integrates retrieval-augmented generation (RAG) techniques. Extensive experiments are conducted to demonstrate the effectiveness of our framework on financial analysis.
DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM
Mar 19, 2024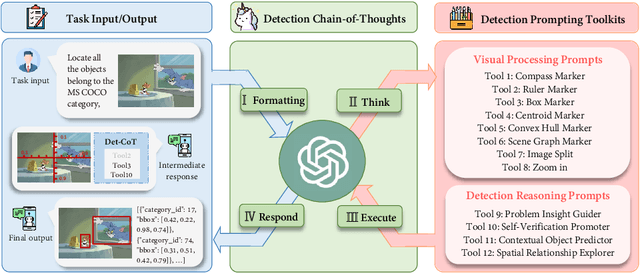

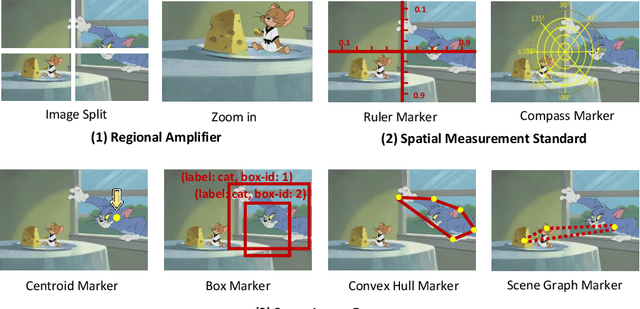
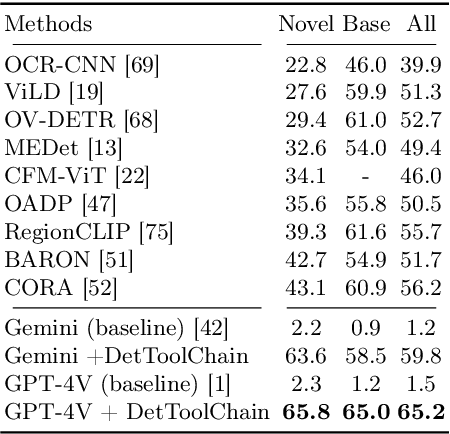
We present DetToolChain, a novel prompting paradigm, to unleash the zero-shot object detection ability of multimodal large language models (MLLMs), such as GPT-4V and Gemini. Our approach consists of a detection prompting toolkit inspired by high-precision detection priors and a new Chain-of-Thought to implement these prompts. Specifically, the prompts in the toolkit are designed to guide the MLLM to focus on regional information (e.g., zooming in), read coordinates according to measure standards (e.g., overlaying rulers and compasses), and infer from the contextual information (e.g., overlaying scene graphs). Building upon these tools, the new detection chain-of-thought can automatically decompose the task into simple subtasks, diagnose the predictions, and plan for progressive box refinements. The effectiveness of our framework is demonstrated across a spectrum of detection tasks, especially hard cases. Compared to existing state-of-the-art methods, GPT-4V with our DetToolChain improves state-of-the-art object detectors by +21.5% AP50 on MS COCO Novel class set for open-vocabulary detection, +24.23% Acc on RefCOCO val set for zero-shot referring expression comprehension, +14.5% AP on D-cube describe object detection FULL setting.
A Deep Reinforcement Learning Approach for Autonomous Reconfigurable Intelligent Surfaces
Mar 19, 2024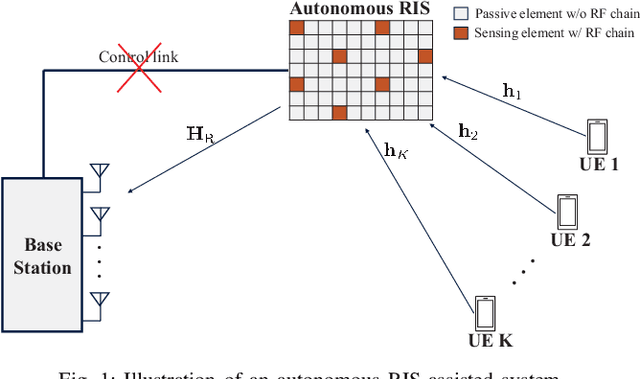
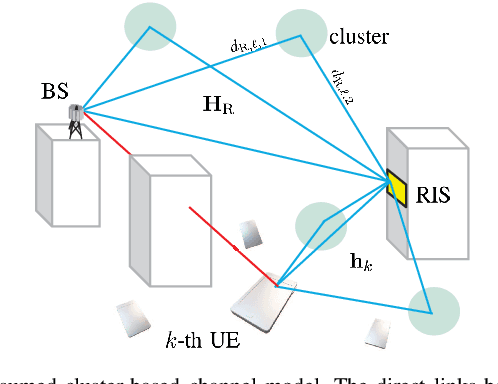
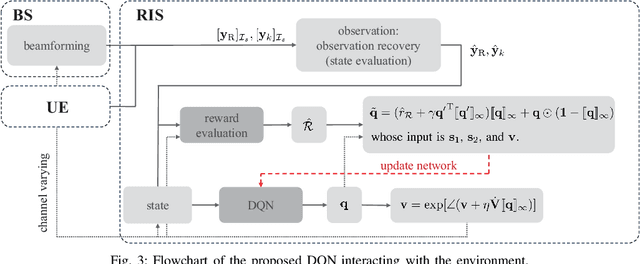
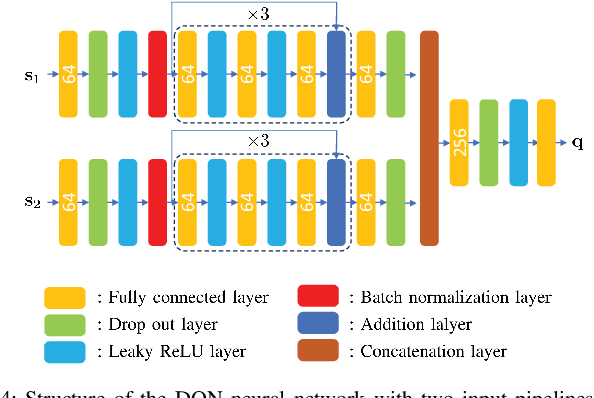
A reconfigurable intelligent surface (RIS) is a prospective wireless technology that enhances wireless channel quality. An RIS is often equipped with passive array of elements and provides cost and power-efficient solutions for coverage extension of wireless communication systems. Without any radio frequency (RF) chains or computing resources, however, the RIS requires control information to be sent to it from an external unit, e.g., a base station (BS). The control information can be delivered by wired or wireless channels, and the BS must be aware of the RIS and the RIS-related channel conditions in order to effectively configure its behavior. Recent works have introduced hybrid RIS structures possessing a few active elements that can sense and digitally process received data. Here, we propose the operation of an entirely autonomous RIS that operates without a control link between the RIS and BS. Using a few sensing elements, the autonomous RIS employs a deep Q network (DQN) based on reinforcement learning in order to enhance the sum rate of the network. Our results illustrate the potential of deploying autonomous RISs in wireless networks with essentially no network overhead.
Locomotion Generation for a Rat Robot based on Environmental Changes via Reinforcement Learning
Mar 19, 2024
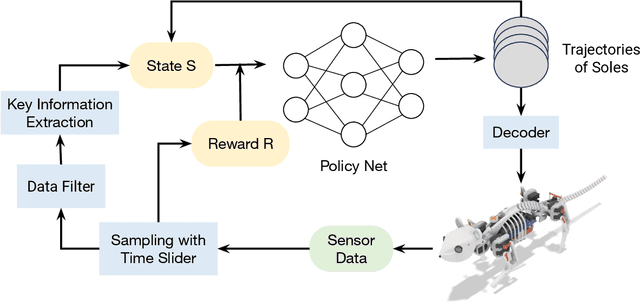
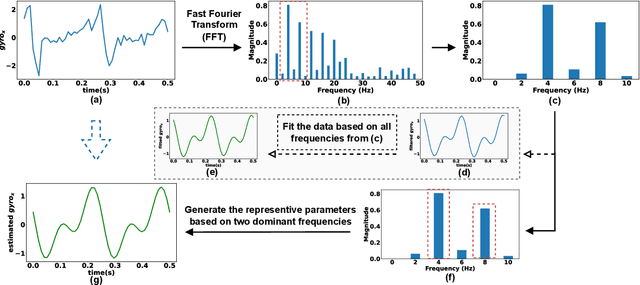
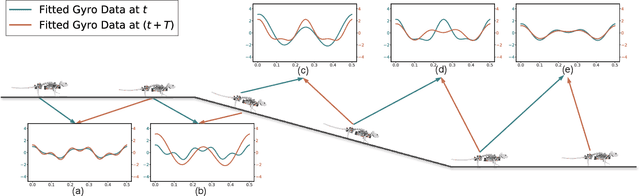
This research focuses on developing reinforcement learning approaches for the locomotion generation of small-size quadruped robots. The rat robot NeRmo is employed as the experimental platform. Due to the constrained volume, small-size quadruped robots typically possess fewer and weaker sensors, resulting in difficulty in accurately perceiving and responding to environmental changes. In this context, insufficient and imprecise feedback data from sensors makes it difficult to generate adaptive locomotion based on reinforcement learning. To overcome these challenges, this paper proposes a novel reinforcement learning approach that focuses on extracting effective perceptual information to enhance the environmental adaptability of small-size quadruped robots. According to the frequency of a robot's gait stride, key information of sensor data is analyzed utilizing sinusoidal functions derived from Fourier transform results. Additionally, a multifunctional reward mechanism is proposed to generate adaptive locomotion in different tasks. Extensive simulations are conducted to assess the effectiveness of the proposed reinforcement learning approach in generating rat robot locomotion in various environments. The experiment results illustrate the capability of the proposed approach to maintain stable locomotion of a rat robot across different terrains, including ramps, stairs, and spiral stairs.
Visibility-Aware Keypoint Localization for 6DoF Object Pose Estimation
Mar 21, 2024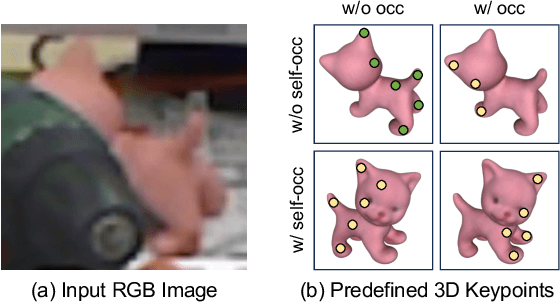
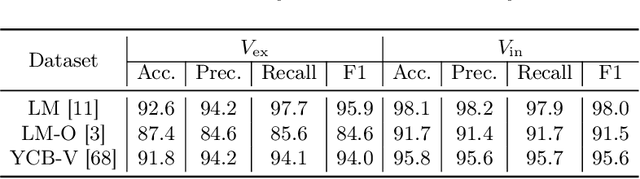
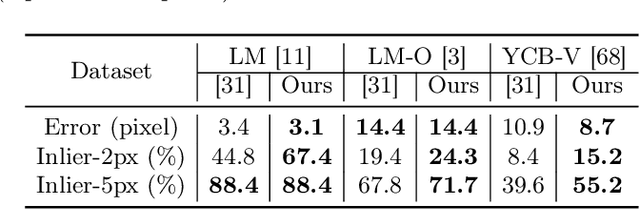
Localizing predefined 3D keypoints in a 2D image is an effective way to establish 3D-2D correspondences for 6DoF object pose estimation. However, unreliable localization results of invisible keypoints degrade the quality of correspondences. In this paper, we address this issue by localizing the important keypoints in terms of visibility. Since keypoint visibility information is currently missing in dataset collection process, we propose an efficient way to generate binary visibility labels from available object-level annotations, for keypoints of both asymmetric objects and symmetric objects. We further derive real-valued visibility-aware importance from binary labels based on PageRank algorithm. Taking advantage of the flexibility of our visibility-aware importance, we construct VAPO (Visibility-Aware POse estimator) by integrating the visibility-aware importance with a state-of-the-art pose estimation algorithm, along with additional positional encoding. Extensive experiments are conducted on popular pose estimation benchmarks including Linemod, Linemod-Occlusion, and YCB-V. The results show that, VAPO improves both the keypoint correspondences and final estimated poses, and clearly achieves state-of-the-art performances.
Exosense: A Vision-Centric Scene Understanding System For Safe Exoskeleton Navigation
Mar 21, 2024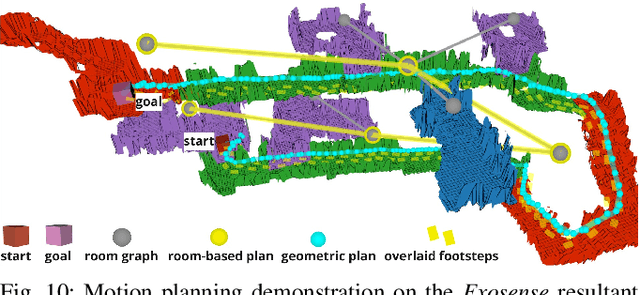

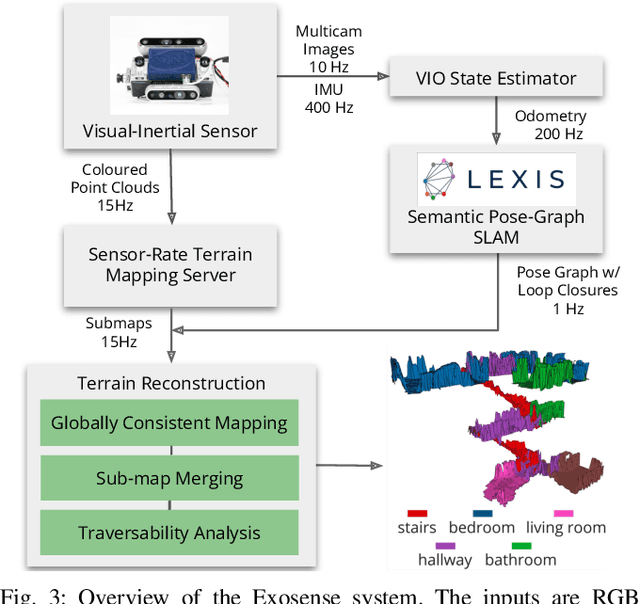
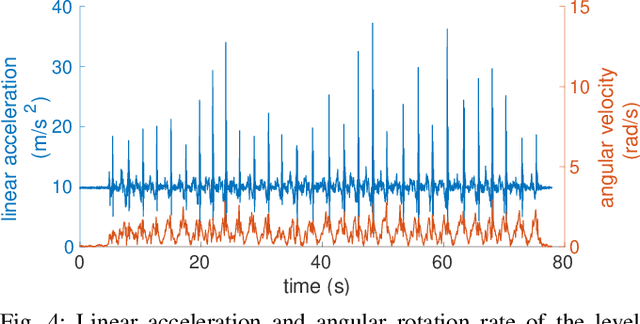
Exoskeletons for daily use by those with mobility impairments are being developed. They will require accurate and robust scene understanding systems. Current research has used vision to identify immediate terrain and geometric obstacles, however these approaches are constrained to detections directly in front of the user and are limited to classifying a finite range of terrain types (e.g., stairs, ramps and level-ground). This paper presents Exosense, a vision-centric scene understanding system which is capable of generating rich, globally-consistent elevation maps, incorporating both semantic and terrain traversability information. It features an elastic Atlas mapping framework associated with a visual SLAM pose graph, embedded with open-vocabulary room labels from a Vision-Language Model (VLM). The device's design includes a wide field-of-view (FoV) fisheye multi-camera system to mitigate the challenges introduced by the exoskeleton walking pattern. We demonstrate the system's robustness to the challenges of typical periodic walking gaits, and its ability to construct accurate semantically-rich maps in indoor settings. Additionally, we showcase its potential for motion planning -- providing a step towards safe navigation for exoskeletons.
Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation
Mar 21, 2024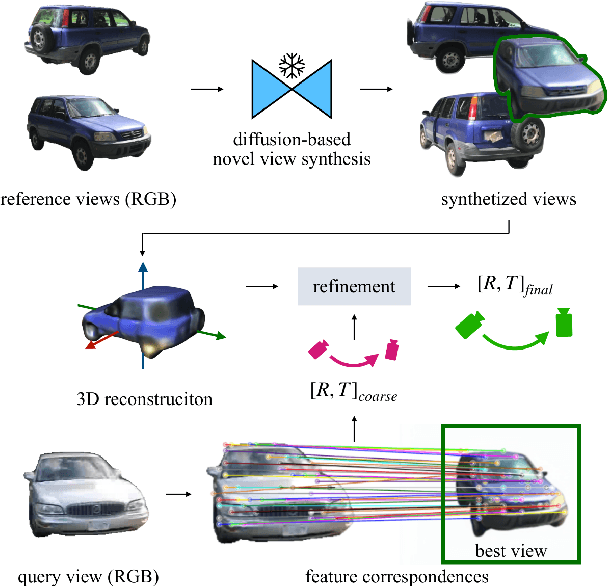
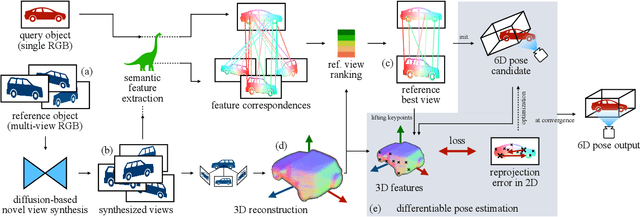


Estimating the pose of objects through vision is essential to make robotic platforms interact with the environment. Yet, it presents many challenges, often related to the lack of flexibility and generalizability of state-of-the-art solutions. Diffusion models are a cutting-edge neural architecture transforming 2D and 3D computer vision, outlining remarkable performances in zero-shot novel-view synthesis. Such a use case is particularly intriguing for reconstructing 3D objects. However, localizing objects in unstructured environments is rather unexplored. To this end, this work presents Zero123-6D to demonstrate the utility of Diffusion Model-based novel-view-synthesizers in enhancing RGB 6D pose estimation at category-level by integrating them with feature extraction techniques. The outlined method exploits such a novel view synthesizer to expand a sparse set of RGB-only reference views for the zero-shot 6D pose estimation task. Experiments are quantitatively analyzed on the CO3D dataset, showcasing increased performance over baselines, a substantial reduction in data requirements, and the removal of the necessity of depth information.
PECI-Net: Bolus segmentation from video fluoroscopic swallowing study images using preprocessing ensemble and cascaded inference
Mar 21, 2024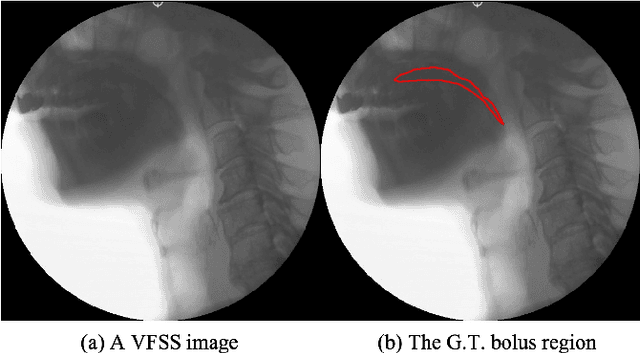

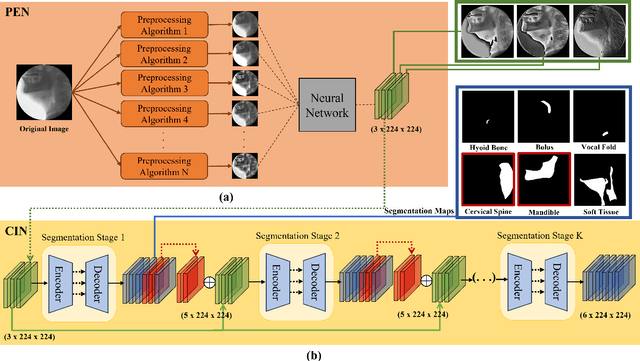
Bolus segmentation is crucial for the automated detection of swallowing disorders in videofluoroscopic swallowing studies (VFSS). However, it is difficult for the model to accurately segment a bolus region in a VFSS image because VFSS images are translucent, have low contrast and unclear region boundaries, and lack color information. To overcome these challenges, we propose PECI-Net, a network architecture for VFSS image analysis that combines two novel techniques: the preprocessing ensemble network (PEN) and the cascaded inference network (CIN). PEN enhances the sharpness and contrast of the VFSS image by combining multiple preprocessing algorithms in a learnable way. CIN reduces ambiguity in bolus segmentation by using context from other regions through cascaded inference. Moreover, CIN prevents undesirable side effects from unreliably segmented regions by referring to the context in an asymmetric way. In experiments, PECI-Net exhibited higher performance than four recently developed baseline models, outperforming TernausNet, the best among the baseline models, by 4.54\% and the widely used UNet by 10.83\%. The results of the ablation studies confirm that CIN and PEN are effective in improving bolus segmentation performance.
* 20 pages, 8 figures,