 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A First Order Meta Stackelberg Method for Robust Federated Learning
Jul 16, 2023
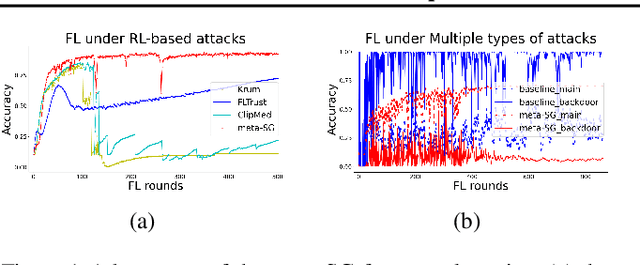
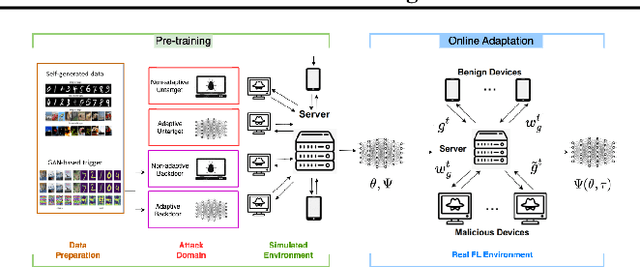

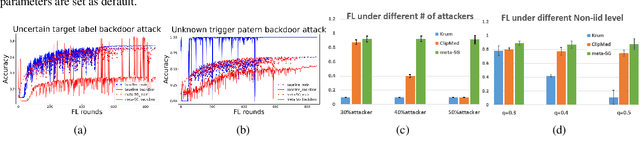
Previous research has shown that federated learning (FL) systems are exposed to an array of security risks. Despite the proposal of several defensive strategies, they tend to be non-adaptive and specific to certain types of attacks, rendering them ineffective against unpredictable or adaptive threats. This work models adversarial federated learning as a Bayesian Stackelberg Markov game (BSMG) to capture the defender's incomplete information of various attack types. We propose meta-Stackelberg learning (meta-SL), a provably efficient meta-learning algorithm, to solve the equilibrium strategy in BSMG, leading to an adaptable FL defense. We demonstrate that meta-SL converges to the first-order $\varepsilon$-equilibrium point in $O(\varepsilon^{-2})$ gradient iterations, with $O(\varepsilon^{-4})$ samples needed per iteration, matching the state of the art. Empirical evidence indicates that our meta-Stackelberg framework performs exceptionally well against potent model poisoning and backdoor attacks of an uncertain nature.
For One-Shot Decoding: Unsupervised Deep Learning-Based Polar Decoder
Jul 16, 2023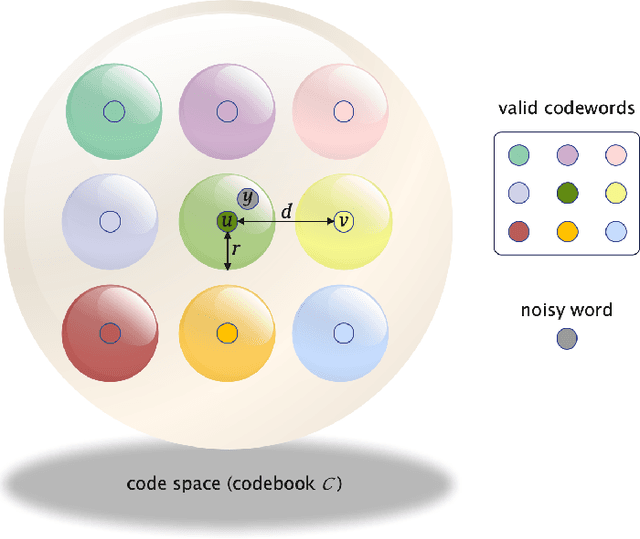
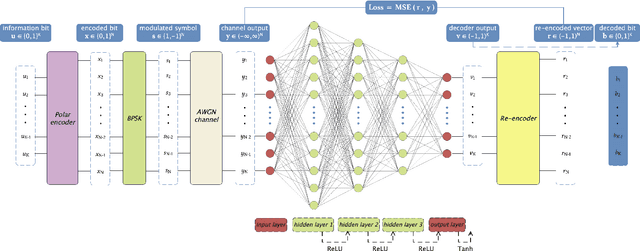
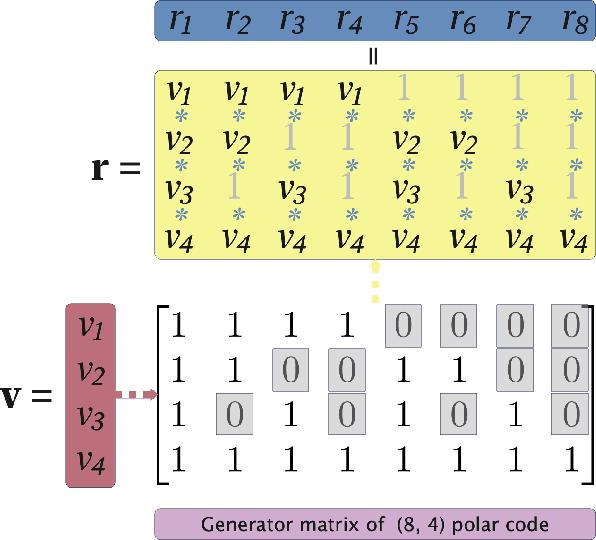
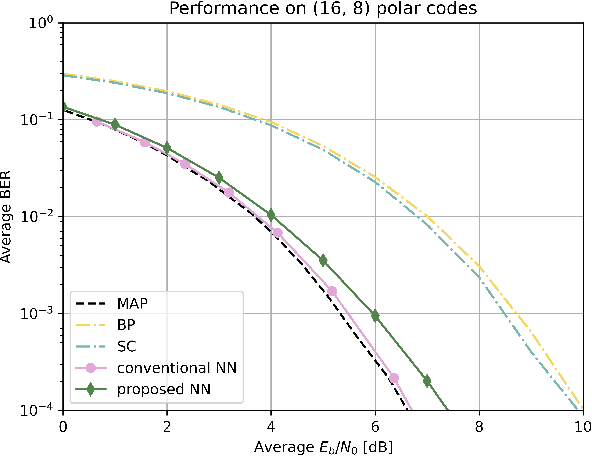
We propose an unsupervised deep learning-based decoding scheme that enables one-shot decoding of polar codes. In the proposed scheme, rather than using the information bit vectors as labels for training the neural network (NN) through supervised learning as the conventional scheme did, the NN is trained to function as a bounded distance decoder by leveraging the generator matrix of polar codes through self-supervised learning. This approach eliminates the reliance on predefined labels, empowering the potential to train directly on the actual data within communication systems and thereby enhancing the applicability. Furthermore, computer simulations demonstrate that (i) the bit error rate (BER) and block error rate (BLER) performances of the proposed scheme can approach those of the maximum a posteriori (MAP) decoder for very short packets and (ii) the proposed NN decoder exhibits much superior generalization ability compared to the conventional one.
MoTIF: Learning Motion Trajectories with Local Implicit Neural Functions for Continuous Space-Time Video Super-Resolution
Jul 16, 2023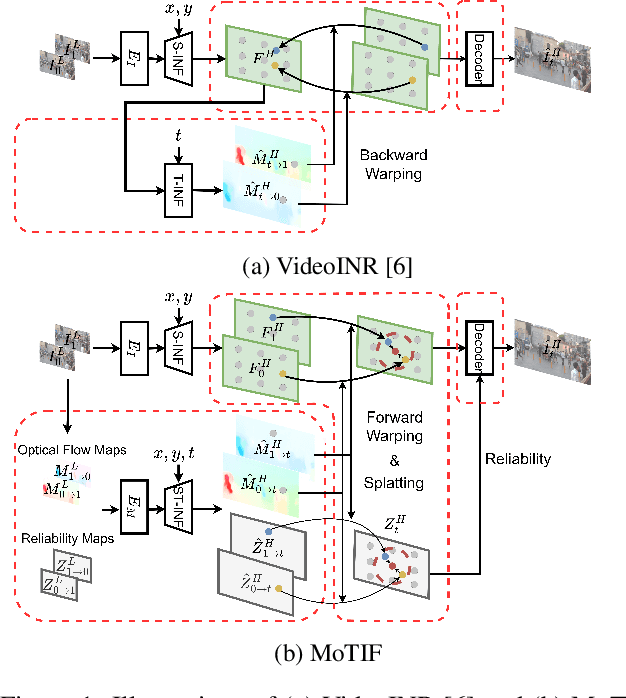
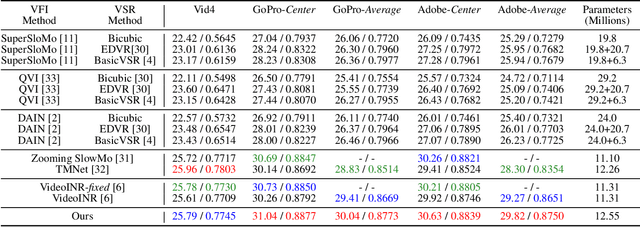
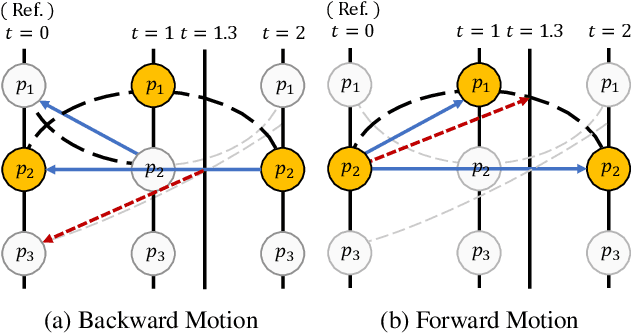
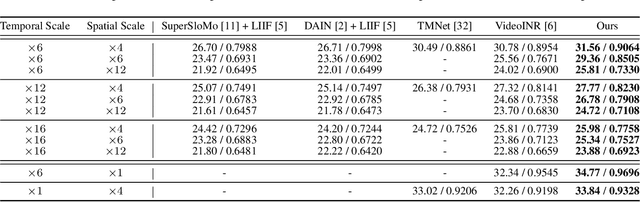
This work addresses continuous space-time video super-resolution (C-STVSR) that aims to up-scale an input video both spatially and temporally by any scaling factors. One key challenge of C-STVSR is to propagate information temporally among the input video frames. To this end, we introduce a space-time local implicit neural function. It has the striking feature of learning forward motion for a continuum of pixels. We motivate the use of forward motion from the perspective of learning individual motion trajectories, as opposed to learning a mixture of motion trajectories with backward motion. To ease motion interpolation, we encode sparsely sampled forward motion extracted from the input video as the contextual input. Along with a reliability-aware splatting and decoding scheme, our framework, termed MoTIF, achieves the state-of-the-art performance on C-STVSR. The source code of MoTIF is available at https://github.com/sichun233746/MoTIF.
DBFed: Debiasing Federated Learning Framework based on Domain-Independent
Jul 10, 2023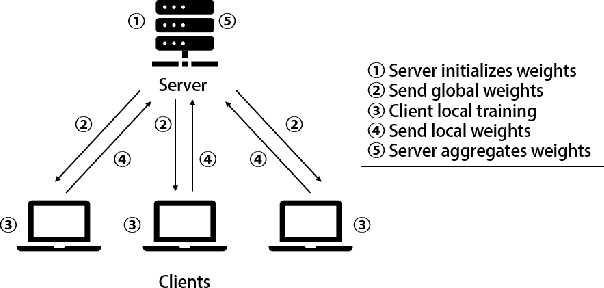
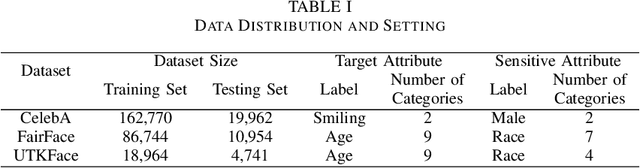
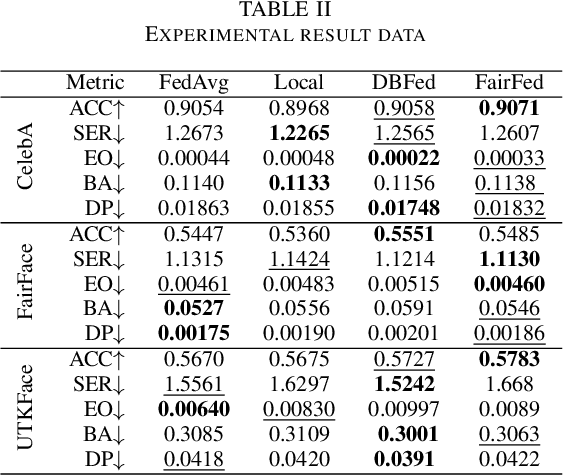
As digital transformation continues, enterprises are generating, managing, and storing vast amounts of data, while artificial intelligence technology is rapidly advancing. However, it brings challenges in information security and data security. Data security refers to the protection of digital information from unauthorized access, damage, theft, etc. throughout its entire life cycle. With the promulgation and implementation of data security laws and the emphasis on data security and data privacy by organizations and users, Privacy-preserving technology represented by federated learning has a wide range of application scenarios. Federated learning is a distributed machine learning computing framework that allows multiple subjects to train joint models without sharing data to protect data privacy and solve the problem of data islands. However, the data among multiple subjects are independent of each other, and the data differences in quality may cause fairness issues in federated learning modeling, such as data bias among multiple subjects, resulting in biased and discriminatory models. Therefore, we propose DBFed, a debiasing federated learning framework based on domain-independent, which mitigates model bias by explicitly encoding sensitive attributes during client-side training. This paper conducts experiments on three real datasets and uses five evaluation metrics of accuracy and fairness to quantify the effect of the model. Most metrics of DBFed exceed those of the other three comparative methods, fully demonstrating the debiasing effect of DBFed.
The Role of Transparency in Repeated First-Price Auctions with Unknown Valuations
Jul 14, 2023
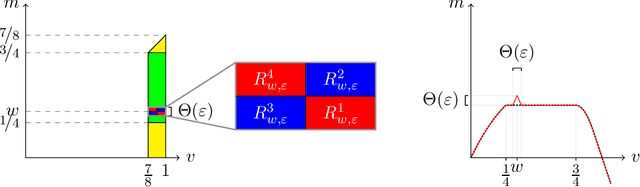
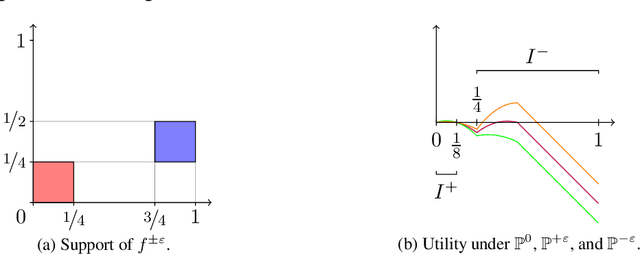

We study the problem of regret minimization for a single bidder in a sequence of first-price auctions where the bidder knows the item's value only if the auction is won. Our main contribution is a complete characterization, up to logarithmic factors, of the minimax regret in terms of the auction's transparency, which regulates the amount of information on competing bids disclosed by the auctioneer at the end of each auction. Our results hold under different assumptions (stochastic, adversarial, and their smoothed variants) on the environment generating the bidder's valuations and competing bids. These minimax rates reveal how the interplay between transparency and the nature of the environment affects how fast one can learn to bid optimally in first-price auctions.
Similarity-based Memory Enhanced Joint Entity and Relation Extraction
Jul 14, 2023Document-level joint entity and relation extraction is a challenging information extraction problem that requires a unified approach where a single neural network performs four sub-tasks: mention detection, coreference resolution, entity classification, and relation extraction. Existing methods often utilize a sequential multi-task learning approach, in which the arbitral decomposition causes the current task to depend only on the previous one, missing the possible existence of the more complex relationships between them. In this paper, we present a multi-task learning framework with bidirectional memory-like dependency between tasks to address those drawbacks and perform the joint problem more accurately. Our empirical studies show that the proposed approach outperforms the existing methods and achieves state-of-the-art results on the BioCreative V CDR corpus.
Learn to Compress (LtC): Efficient Learning-based Streaming Video Analytics
Jul 22, 2023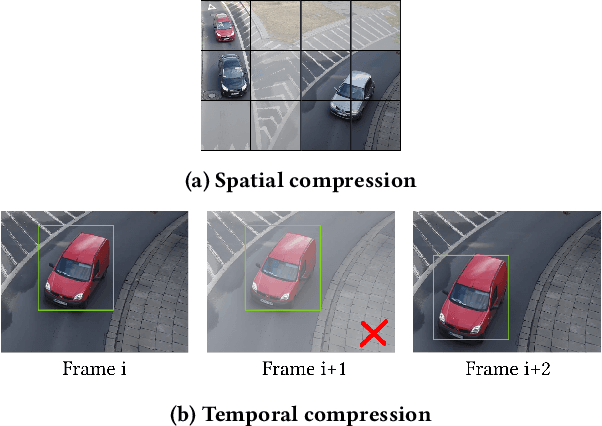
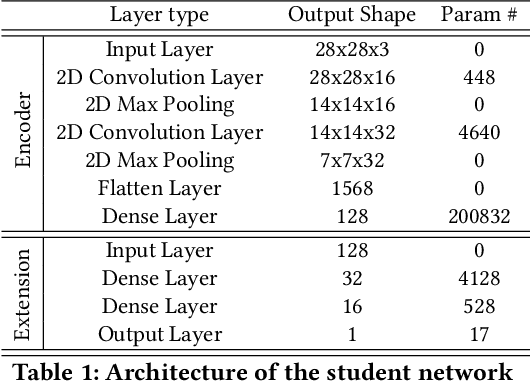
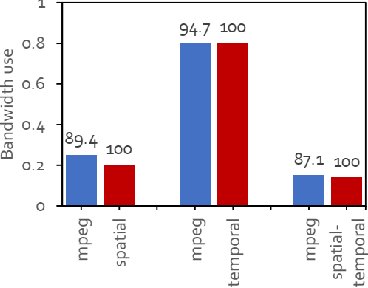

Video analytics are often performed as cloud services in edge settings, mainly to offload computation, and also in situations where the results are not directly consumed at the video sensors. Sending high-quality video data from the edge devices can be expensive both in terms of bandwidth and power use. In order to build a streaming video analytics pipeline that makes efficient use of these resources, it is therefore imperative to reduce the size of the video stream. Traditional video compression algorithms are unaware of the semantics of the video, and can be both inefficient and harmful for the analytics performance. In this paper, we introduce LtC, a collaborative framework between the video source and the analytics server, that efficiently learns to reduce the video streams within an analytics pipeline. Specifically, LtC uses the full-fledged analytics algorithm at the server as a teacher to train a lightweight student neural network, which is then deployed at the video source. The student network is trained to comprehend the semantic significance of various regions within the videos, which is used to differentially preserve the crucial regions in high quality while the remaining regions undergo aggressive compression. Furthermore, LtC also incorporates a novel temporal filtering algorithm based on feature-differencing to omit transmitting frames that do not contribute new information. Overall, LtC is able to use 28-35% less bandwidth and has up to 45% shorter response delay compared to recently published state of the art streaming frameworks while achieving similar analytics performance.
Iterative Reconstruction Based on Latent Diffusion Model for Sparse Data Reconstruction
Jul 22, 2023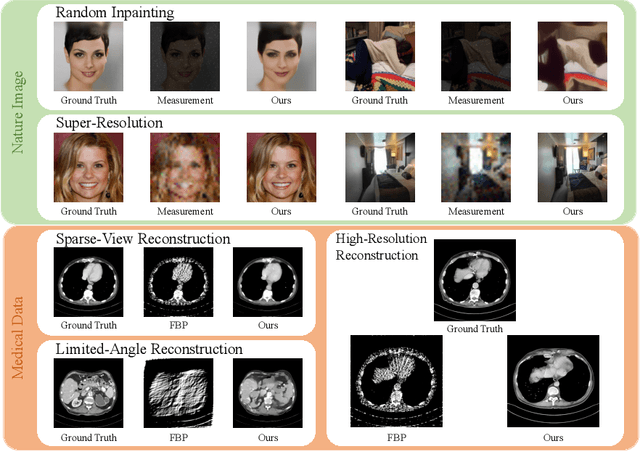
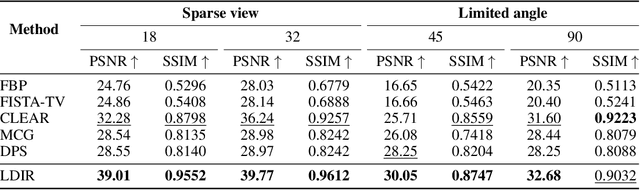
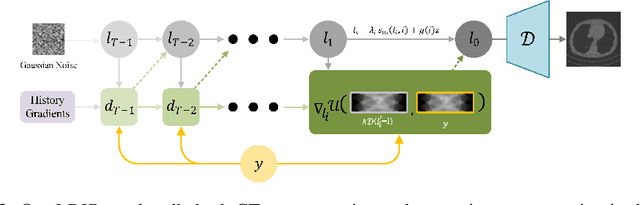
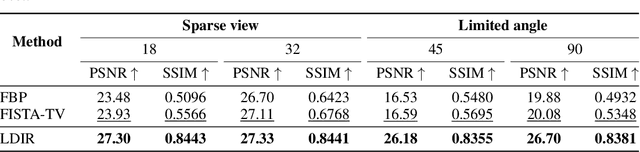
Reconstructing Computed tomography (CT) images from sparse measurement is a well-known ill-posed inverse problem. The Iterative Reconstruction (IR) algorithm is a solution to inverse problems. However, recent IR methods require paired data and the approximation of the inverse projection matrix. To address those problems, we present Latent Diffusion Iterative Reconstruction (LDIR), a pioneering zero-shot method that extends IR with a pre-trained Latent Diffusion Model (LDM) as a accurate and efficient data prior. By approximating the prior distribution with an unconditional latent diffusion model, LDIR is the first method to successfully integrate iterative reconstruction and LDM in an unsupervised manner. LDIR makes the reconstruction of high-resolution images more efficient. Moreover, LDIR utilizes the gradient from the data-fidelity term to guide the sampling process of the LDM, therefore, LDIR does not need the approximation of the inverse projection matrix and can solve various CT reconstruction tasks with a single model. Additionally, for enhancing the sample consistency of the reconstruction, we introduce a novel approach that uses historical gradient information to guide the gradient. Our experiments on extremely sparse CT data reconstruction tasks show that LDIR outperforms other state-of-the-art unsupervised and even exceeds supervised methods, establishing it as a leading technique in terms of both quantity and quality. Furthermore, LDIR also achieves competitive performance on nature image tasks. It is worth noting that LDIR also exhibits significantly faster execution times and lower memory consumption compared to methods with similar network settings. Our code will be publicly available.
Multi-representations Space Separation based Graph-level Anomaly-aware Detection
Jul 22, 2023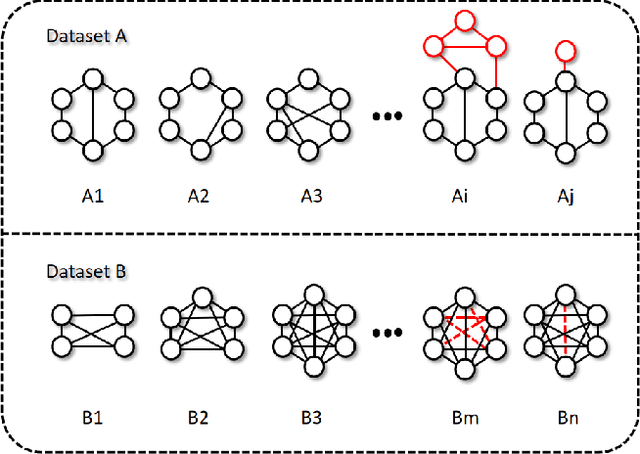

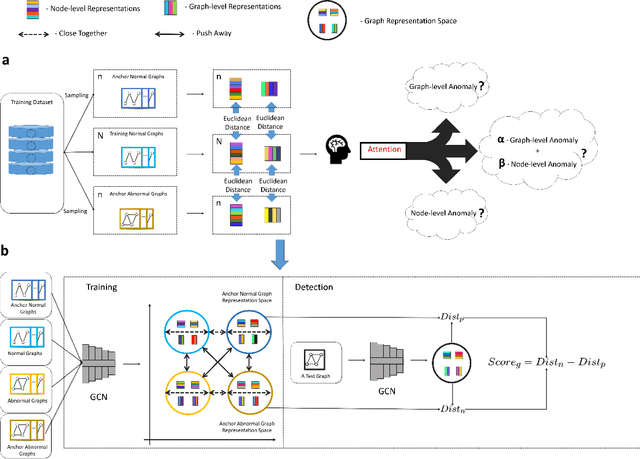
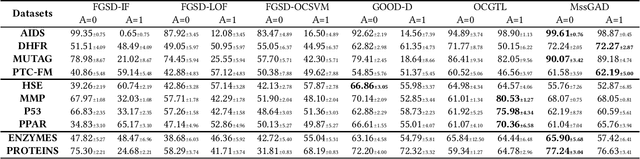
Graph structure patterns are widely used to model different area data recently. How to detect anomalous graph information on these graph data has become a popular research problem. The objective of this research is centered on the particular issue that how to detect abnormal graphs within a graph set. The previous works have observed that abnormal graphs mainly show node-level and graph-level anomalies, but these methods equally treat two anomaly forms above in the evaluation of abnormal graphs, which is contrary to the fact that different types of abnormal graph data have different degrees in terms of node-level and graph-level anomalies. Furthermore, abnormal graphs that have subtle differences from normal graphs are easily escaped detection by the existing methods. Thus, we propose a multi-representations space separation based graph-level anomaly-aware detection framework in this paper. To consider the different importance of node-level and graph-level anomalies, we design an anomaly-aware module to learn the specific weight between them in the abnormal graph evaluation process. In addition, we learn strictly separate normal and abnormal graph representation spaces by four types of weighted graph representations against each other including anchor normal graphs, anchor abnormal graphs, training normal graphs, and training abnormal graphs. Based on the distance error between the graph representations of the test graph and both normal and abnormal graph representation spaces, we can accurately determine whether the test graph is anomalous. Our approach has been extensively evaluated against baseline methods using ten public graph datasets, and the results demonstrate its effectiveness.
* 11 pages, 12 figures
Distributed fusion filter over lossy wireless sensor networks with the presence of non-Gaussian noise
Jul 07, 2023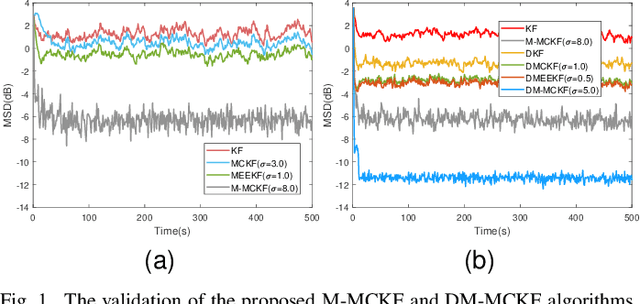
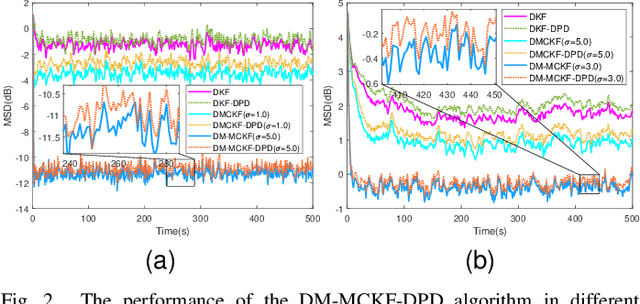
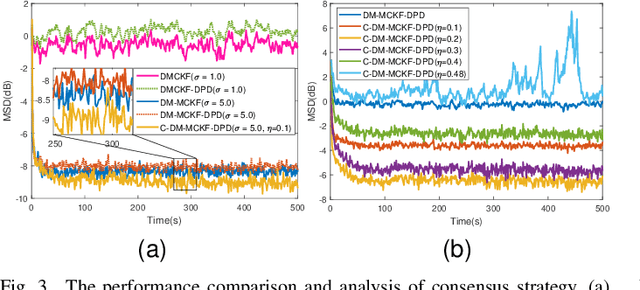
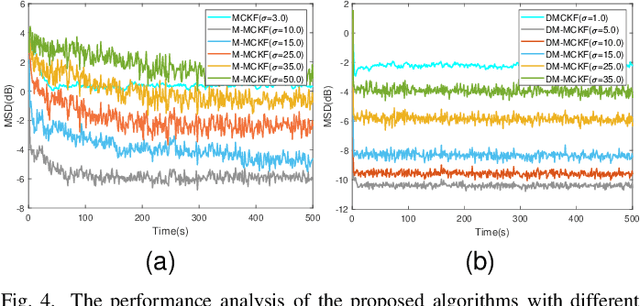
The information transmission between nodes in a wireless sensor networks (WSNs) often causes packet loss due to denial-of-service (DoS) attack, energy limitations, and environmental factors, and the information that is successfully transmitted can also be contaminated by non-Gaussian noise. The presence of these two factors poses a challenge for distributed state estimation (DSE) over WSNs. In this paper, a generalized packet drop model is proposed to describe the packet loss phenomenon caused by DoS attacks and other factors. Moreover, a modified maximum correntropy Kalman filter is given, and it is extended to distributed form (DM-MCKF). In addition, a distributed modified maximum correntropy Kalman filter incorporating the generalized data packet drop (DM-MCKF-DPD) algorithm is provided to implement DSE with the presence of both non-Gaussian noise pollution and packet drop. A sufficient condition to ensure the convergence of the fixed-point iterative process of the DM-MCKF-DPD algorithm is presented and the computational complexity of the DM-MCKF-DPD algorithm is analyzed. Finally, the effectiveness and feasibility of the proposed algorithms are verified by simulations.