 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LUCID-GAN: Conditional Generative Models to Locate Unfairness
Jul 28, 2023
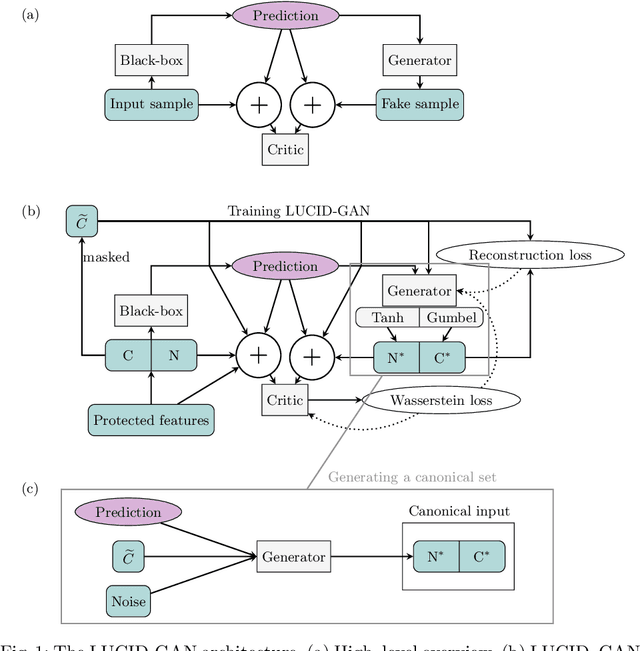
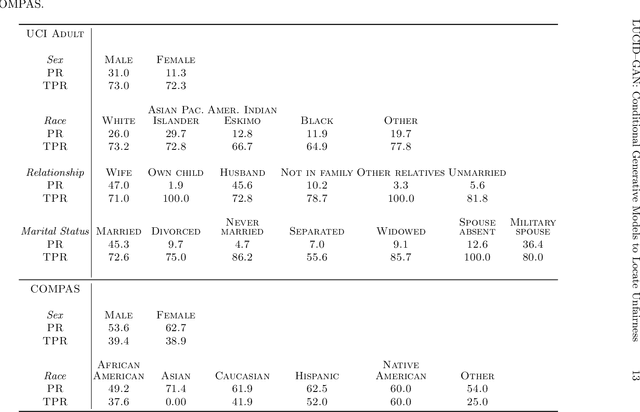
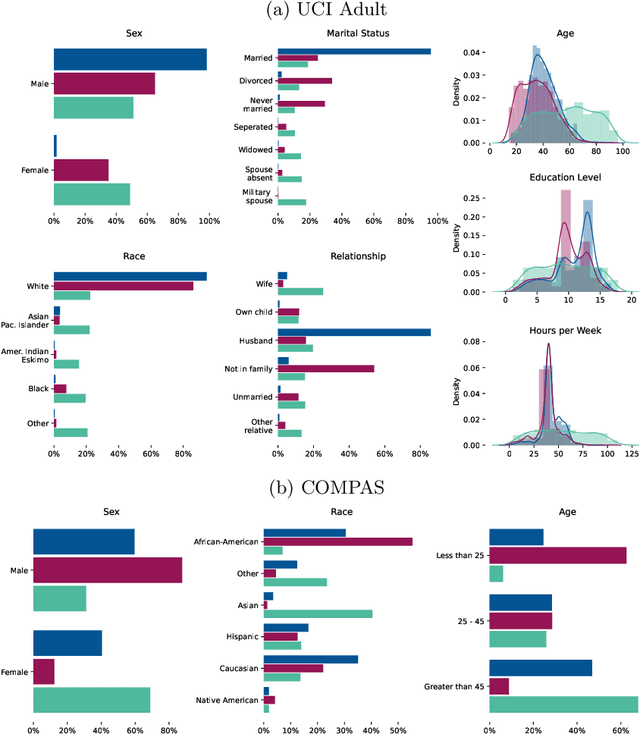
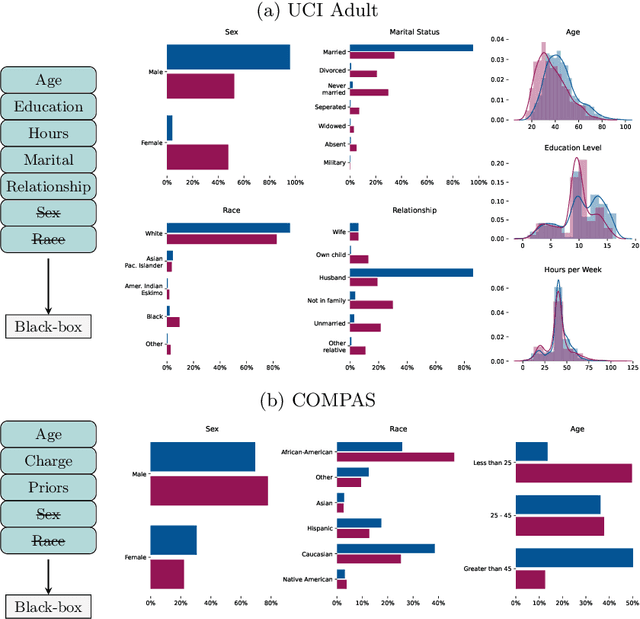
Most group fairness notions detect unethical biases by computing statistical parity metrics on a model's output. However, this approach suffers from several shortcomings, such as philosophical disagreement, mutual incompatibility, and lack of interpretability. These shortcomings have spurred the research on complementary bias detection methods that offer additional transparency into the sources of discrimination and are agnostic towards an a priori decision on the definition of fairness and choice of protected features. A recent proposal in this direction is LUCID (Locating Unfairness through Canonical Inverse Design), where canonical sets are generated by performing gradient descent on the input space, revealing a model's desired input given a preferred output. This information about the model's mechanisms, i.e., which feature values are essential to obtain specific outputs, allows exposing potential unethical biases in its internal logic. Here, we present LUCID-GAN, which generates canonical inputs via a conditional generative model instead of gradient-based inverse design. LUCID-GAN has several benefits, including that it applies to non-differentiable models, ensures that canonical sets consist of realistic inputs, and allows to assess proxy and intersectional discrimination. We empirically evaluate LUCID-GAN on the UCI Adult and COMPAS data sets and show that it allows for detecting unethical biases in black-box models without requiring access to the training data.
3D Skeletonization of Complex Grapevines for Robotic Pruning
Jul 21, 2023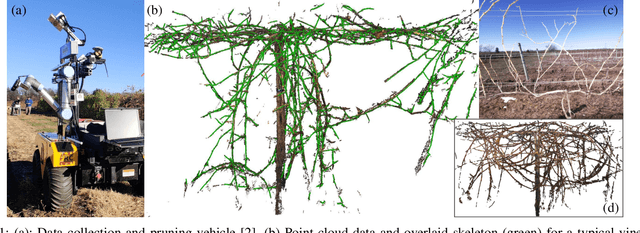
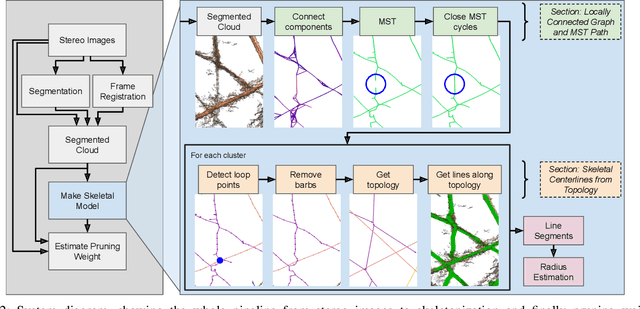
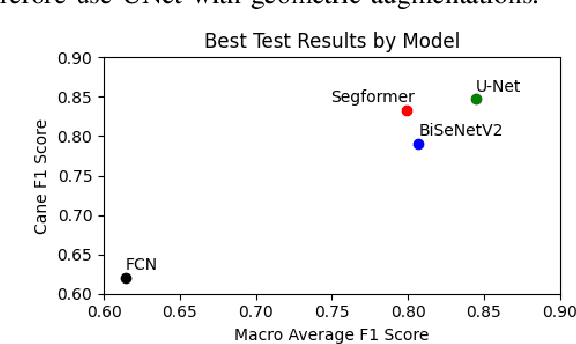
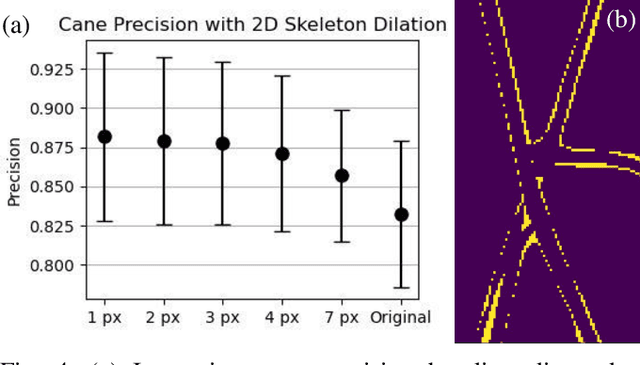
Robotic pruning of dormant grapevines is an area of active research in order to promote vine balance and grape quality, but so far robotic efforts have largely focused on planar, simplified vines not representative of commercial vineyards. This paper aims to advance the robotic perception capabilities necessary for pruning in denser and more complex vine structures by extending plant skeletonization techniques. The proposed pipeline generates skeletal grapevine models that have lower reprojection error and higher connectivity than baseline algorithms. We also show how 3D and skeletal information enables prediction accuracy of pruning weight for dense vines surpassing prior work, where pruning weight is an important vine metric influencing pruning site selection.
ECL: Class-Enhancement Contrastive Learning for Long-tailed Skin Lesion Classification
Jul 09, 2023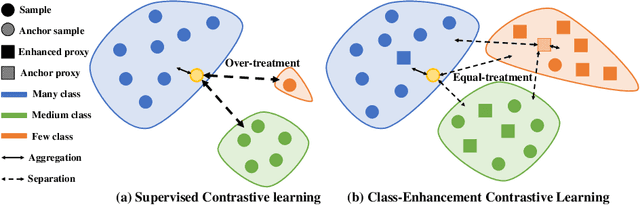
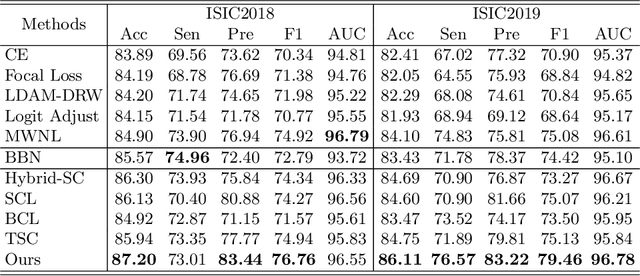
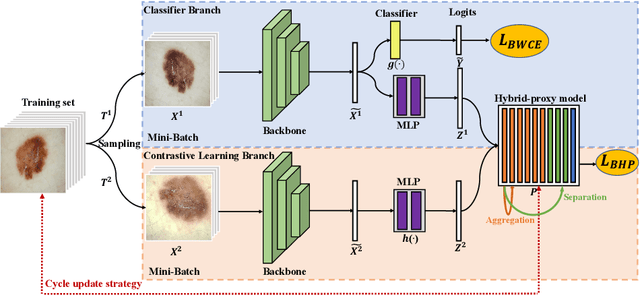
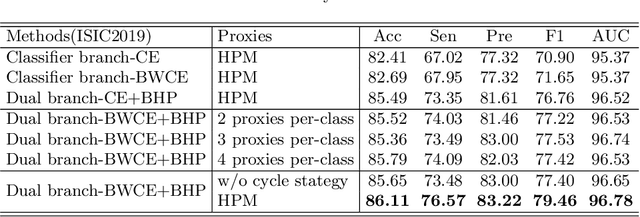
Skin image datasets often suffer from imbalanced data distribution, exacerbating the difficulty of computer-aided skin disease diagnosis. Some recent works exploit supervised contrastive learning (SCL) for this long-tailed challenge. Despite achieving significant performance, these SCL-based methods focus more on head classes, yet ignoring the utilization of information in tail classes. In this paper, we propose class-Enhancement Contrastive Learning (ECL), which enriches the information of minority classes and treats different classes equally. For information enhancement, we design a hybrid-proxy model to generate class-dependent proxies and propose a cycle update strategy for parameters optimization. A balanced-hybrid-proxy loss is designed to exploit relations between samples and proxies with different classes treated equally. Taking both "imbalanced data" and "imbalanced diagnosis difficulty" into account, we further present a balanced-weighted cross-entropy loss following curriculum learning schedule. Experimental results on the classification of imbalanced skin lesion data have demonstrated the superiority and effectiveness of our method.
PNT-Edge: Towards Robust Edge Detection with Noisy Labels by Learning Pixel-level Noise Transitions
Jul 26, 2023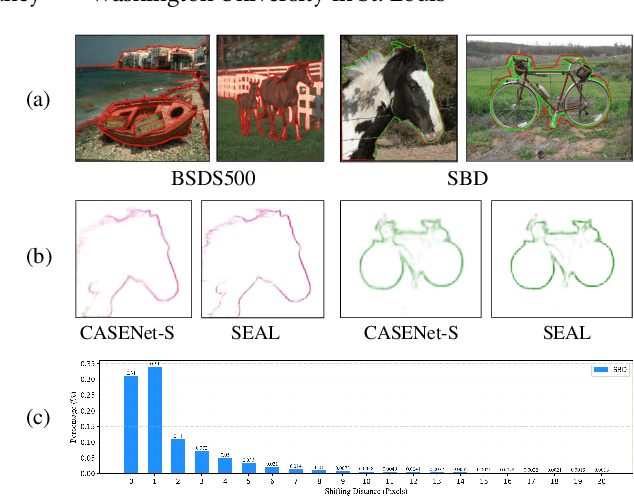
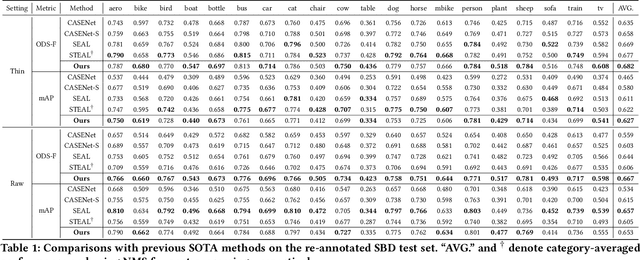
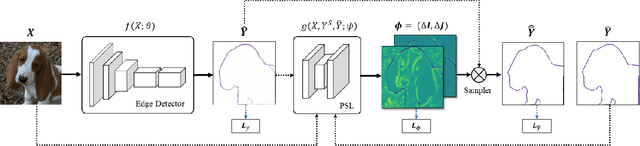
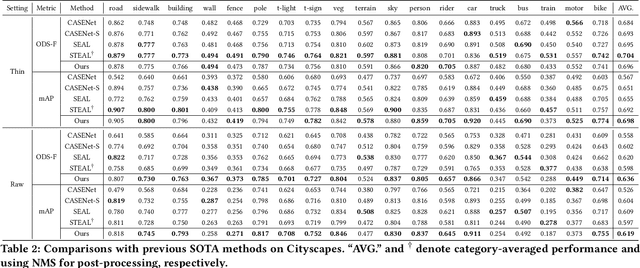
Relying on large-scale training data with pixel-level labels, previous edge detection methods have achieved high performance. However, it is hard to manually label edges accurately, especially for large datasets, and thus the datasets inevitably contain noisy labels. This label-noise issue has been studied extensively for classification, while still remaining under-explored for edge detection. To address the label-noise issue for edge detection, this paper proposes to learn Pixel-level NoiseTransitions to model the label-corruption process. To achieve it, we develop a novel Pixel-wise Shift Learning (PSL) module to estimate the transition from clean to noisy labels as a displacement field. Exploiting the estimated noise transitions, our model, named PNT-Edge, is able to fit the prediction to clean labels. In addition, a local edge density regularization term is devised to exploit local structure information for better transition learning. This term encourages learning large shifts for the edges with complex local structures. Experiments on SBD and Cityscapes demonstrate the effectiveness of our method in relieving the impact of label noise. Codes will be available at github.
Controllable Guide-Space for Generalizable Face Forgery Detection
Jul 26, 2023
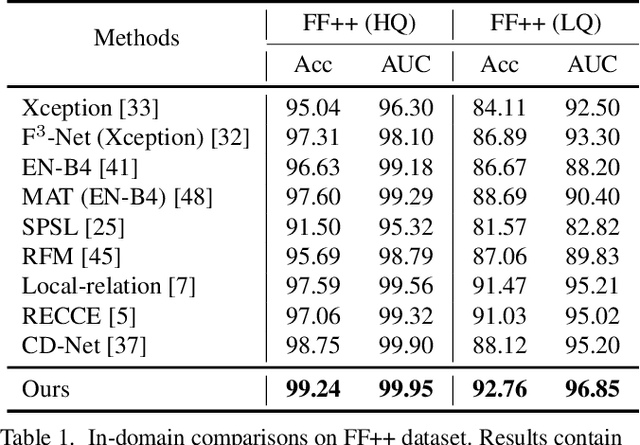
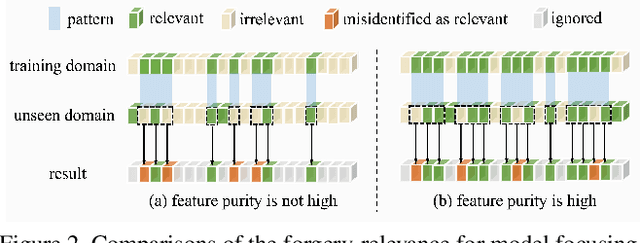
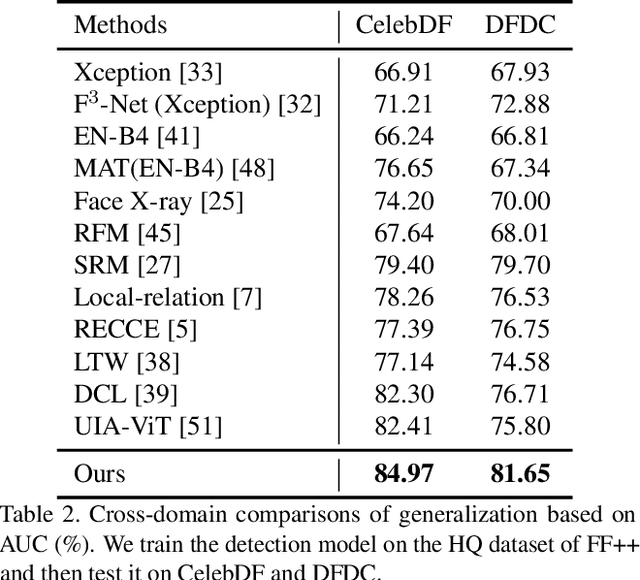
Recent studies on face forgery detection have shown satisfactory performance for methods involved in training datasets, but are not ideal enough for unknown domains. This motivates many works to improve the generalization, but forgery-irrelevant information, such as image background and identity, still exists in different domain features and causes unexpected clustering, limiting the generalization. In this paper, we propose a controllable guide-space (GS) method to enhance the discrimination of different forgery domains, so as to increase the forgery relevance of features and thereby improve the generalization. The well-designed guide-space can simultaneously achieve both the proper separation of forgery domains and the large distance between real-forgery domains in an explicit and controllable manner. Moreover, for better discrimination, we use a decoupling module to weaken the interference of forgery-irrelevant correlations between domains. Furthermore, we make adjustments to the decision boundary manifold according to the clustering degree of the same domain features within the neighborhood. Extensive experiments in multiple in-domain and cross-domain settings confirm that our method can achieve state-of-the-art generalization.
Rethinking Voice-Face Correlation: A Geometry View
Jul 26, 2023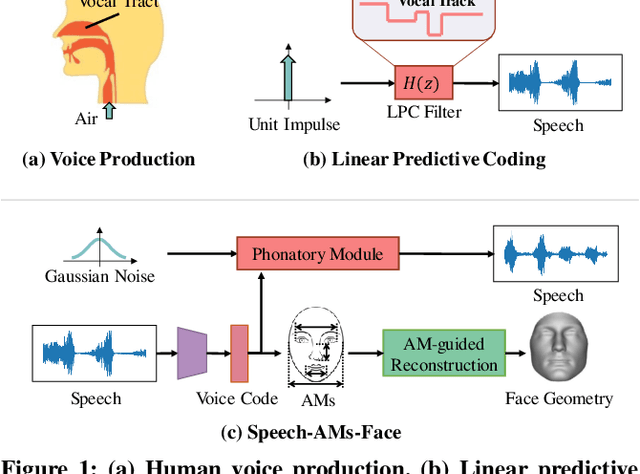

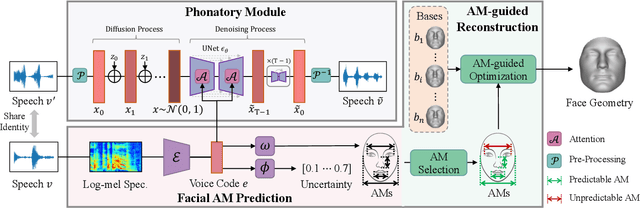

Previous works on voice-face matching and voice-guided face synthesis demonstrate strong correlations between voice and face, but mainly rely on coarse semantic cues such as gender, age, and emotion. In this paper, we aim to investigate the capability of reconstructing the 3D facial shape from voice from a geometry perspective without any semantic information. We propose a voice-anthropometric measurement (AM)-face paradigm, which identifies predictable facial AMs from the voice and uses them to guide 3D face reconstruction. By leveraging AMs as a proxy to link the voice and face geometry, we can eliminate the influence of unpredictable AMs and make the face geometry tractable. Our approach is evaluated on our proposed dataset with ground-truth 3D face scans and corresponding voice recordings, and we find significant correlations between voice and specific parts of the face geometry, such as the nasal cavity and cranium. Our work offers a new perspective on voice-face correlation and can serve as a good empirical study for anthropometry science.
A semantics-driven methodology for high-quality image annotation
Jul 26, 2023Recent work in Machine Learning and Computer Vision has highlighted the presence of various types of systematic flaws inside ground truth object recognition benchmark datasets. Our basic tenet is that these flaws are rooted in the many-to-many mappings which exist between the visual information encoded in images and the intended semantics of the labels annotating them. The net consequence is that the current annotation process is largely under-specified, thus leaving too much freedom to the subjective judgment of annotators. In this paper, we propose vTelos, an integrated Natural Language Processing, Knowledge Representation, and Computer Vision methodology whose main goal is to make explicit the (otherwise implicit) intended annotation semantics, thus minimizing the number and role of subjective choices. A key element of vTelos is the exploitation of the WordNet lexico-semantic hierarchy as the main means for providing the meaning of natural language labels and, as a consequence, for driving the annotation of images based on the objects and the visual properties they depict. The methodology is validated on images populating a subset of the ImageNet hierarchy.
Physical Layer Secret Key Agreement Using One-Bit Quantization and Low-Density Parity-Check Codes
Jul 08, 2023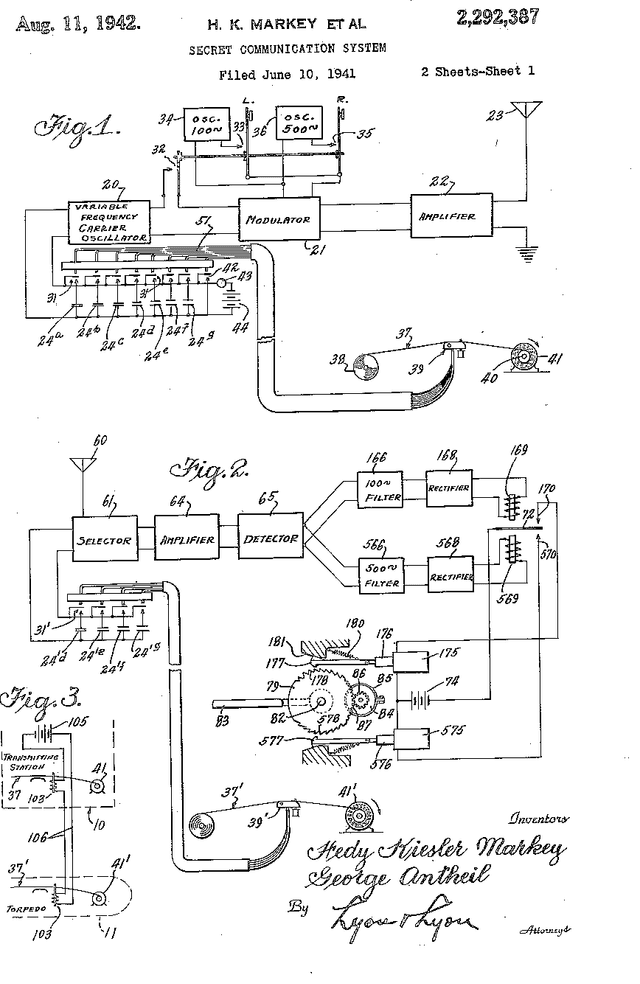
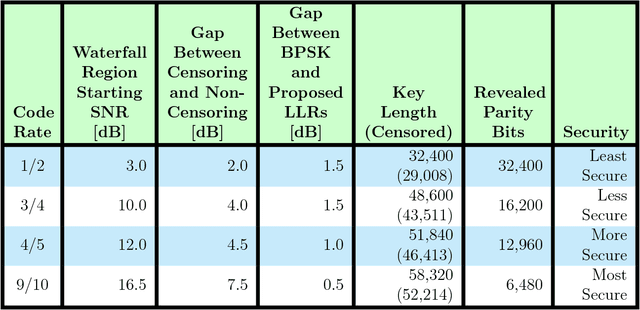
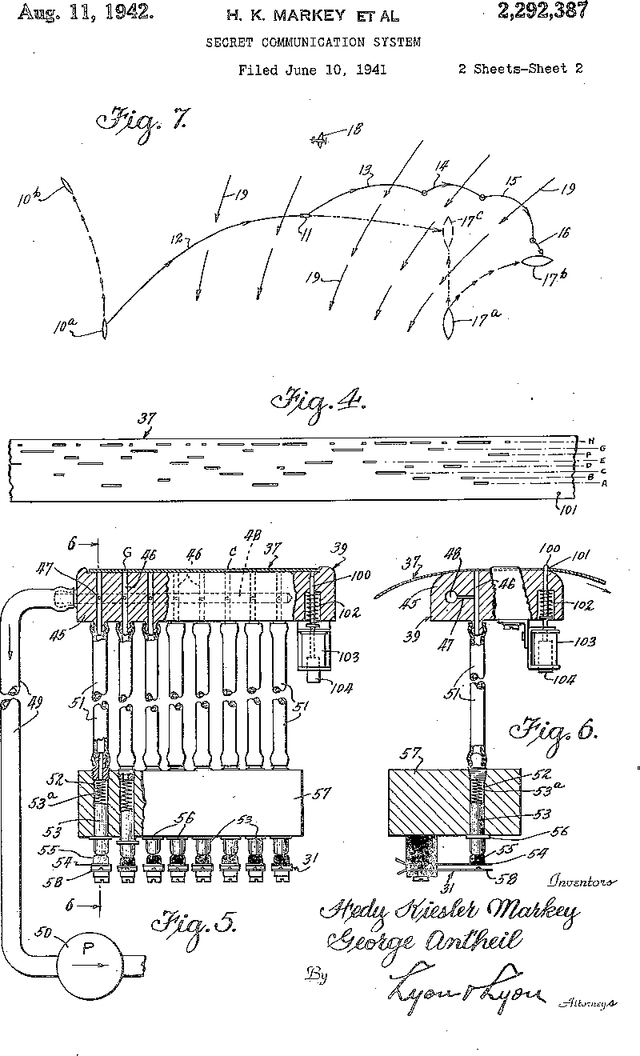
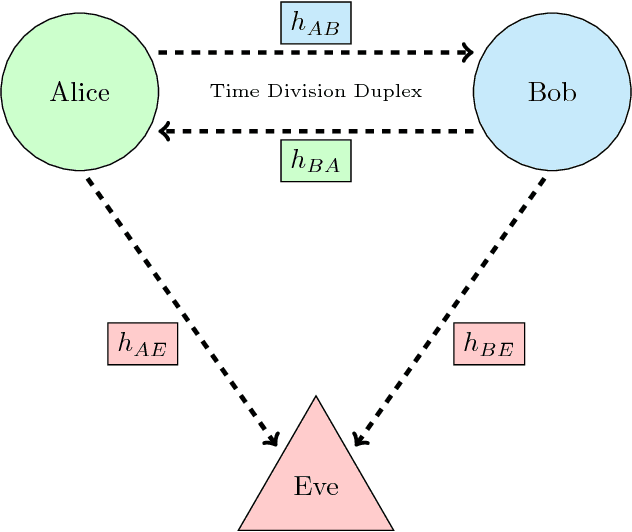
Physical layer approaches for generating secret encryption keys for wireless systems using channel information have attracted increased interest from researchers in recent years. This paper presents a new approach for calculating log-likelihood ratios (LLRs) for secret key generation that is based on one-bit quantization of channel measurements and the difference between channel estimates at legitimate reciprocal nodes. The studied secret key agreement approach, which implements advantage distillation along with information reconciliation using Slepian-Wolf low-density parity-check (LDPC) codes, is discussed and illustrated with numerical results obtained from simulations. These results show the probability of bit disagreement for keys generated using the proposed LLR calculations compared with alternative LLR calculation methods for key generation based on channel state information. The proposed LLR calculations are shown to be an improvement to the studied approach of physical layer secret key agreement.
Fair Machine Unlearning: Data Removal while Mitigating Disparities
Jul 27, 2023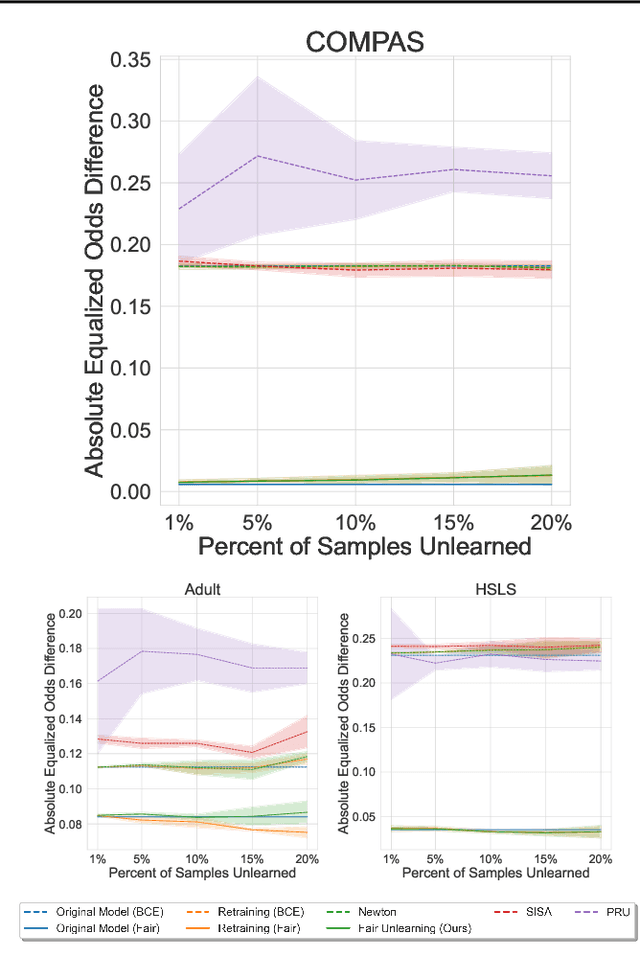
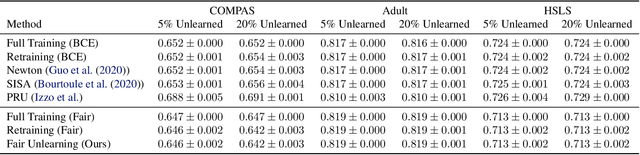
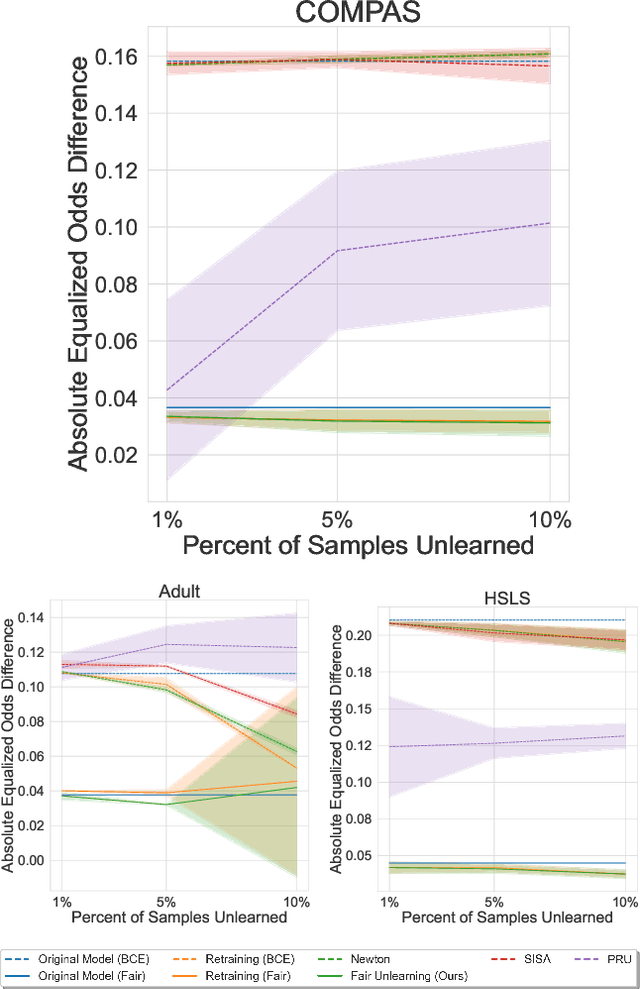
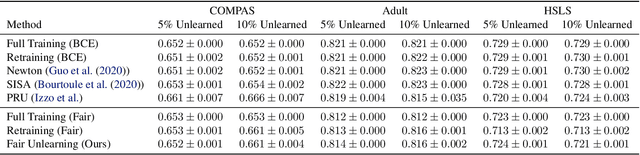
As public consciousness regarding the collection and use of personal information by corporations grows, it is of increasing importance that consumers be active participants in the curation of corporate datasets. In light of this, data governance frameworks such as the General Data Protection Regulation (GDPR) have outlined the right to be forgotten as a key principle allowing individuals to request that their personal data be deleted from the databases and models used by organizations. To achieve forgetting in practice, several machine unlearning methods have been proposed to address the computational inefficiencies of retraining a model from scratch with each unlearning request. While efficient online alternatives to retraining, it is unclear how these methods impact other properties critical to real-world applications, such as fairness. In this work, we propose the first fair machine unlearning method that can provably and efficiently unlearn data instances while preserving group fairness. We derive theoretical results which demonstrate that our method can provably unlearn data instances while maintaining fairness objectives. Extensive experimentation with real-world datasets highlight the efficacy of our method at unlearning data instances while preserving fairness.
BubbleML: A Multi-Physics Dataset and Benchmarks for Machine Learning
Jul 27, 2023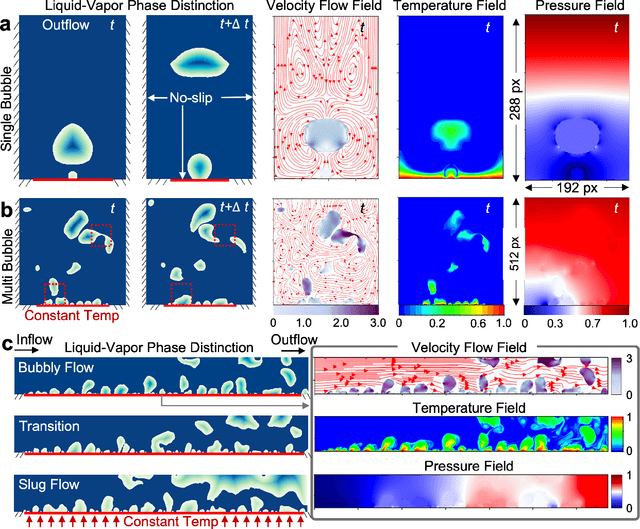
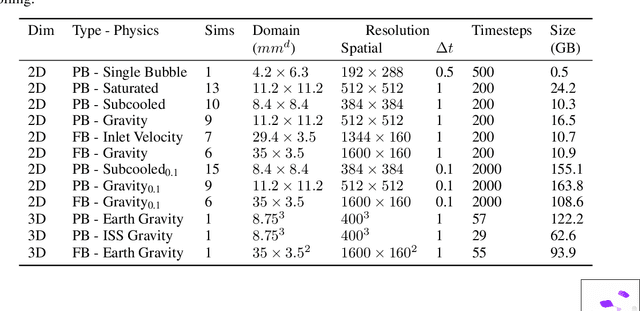
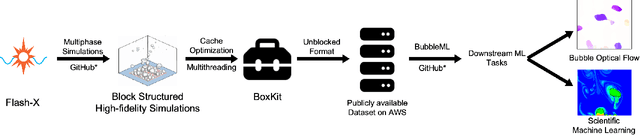
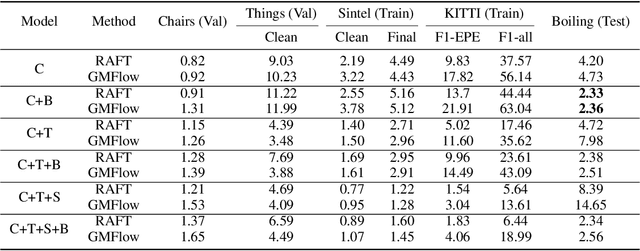
In the field of phase change phenomena, the lack of accessible and diverse datasets suitable for machine learning (ML) training poses a significant challenge. Existing experimental datasets are often restricted, with limited availability and sparse ground truth data, impeding our understanding of this complex multi-physics phenomena. To bridge this gap, we present the BubbleML Dataset(https://github.com/HPCForge/BubbleML) which leverages physics-driven simulations to provide accurate ground truth information for various boiling scenarios, encompassing nucleate pool boiling, flow boiling, and sub-cooled boiling. This extensive dataset covers a wide range of parameters, including varying gravity conditions, flow rates, sub-cooling levels, and wall superheat, comprising 51 simulations. BubbleML is validated against experimental observations and trends, establishing it as an invaluable resource for ML research. Furthermore, we showcase its potential to facilitate exploration of diverse downstream tasks by introducing two benchmarks: (a) optical flow analysis to capture bubble dynamics, and (b) operator networks for learning temperature dynamics. The BubbleML dataset and its benchmarks serve as a catalyst for advancements in ML-driven research on multi-physics phase change phenomena, enabling the development and comparison of state-of-the-art techniques and models.