 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Translation Invariance in Convolutional Neural Networks with Peripheral Prediction Padding
Jul 15, 2023
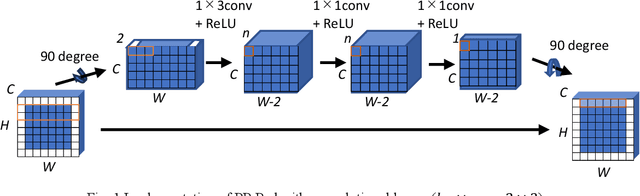
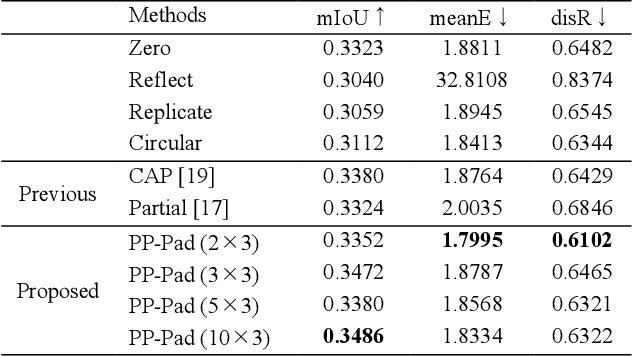
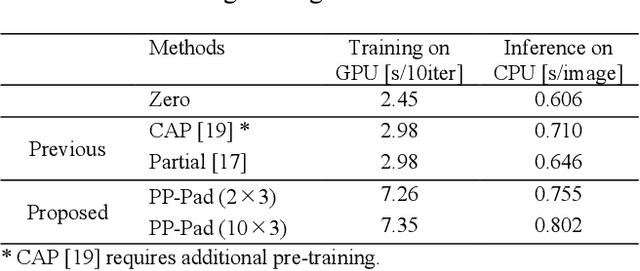

Zero padding is often used in convolutional neural networks to prevent the feature map size from decreasing with each layer. However, recent studies have shown that zero padding promotes encoding of absolute positional information, which may adversely affect the performance of some tasks. In this work, a novel padding method called Peripheral Prediction Padding (PP-Pad) method is proposed, which enables end-to-end training of padding values suitable for each task instead of zero padding. Moreover, novel metrics to quantitatively evaluate the translation invariance of the model are presented. By evaluating with these metrics, it was confirmed that the proposed method achieved higher accuracy and translation invariance than the previous methods in a semantic segmentation task.
Estimation of an Order Book Dependent Hawkes Process for Large Datasets
Jul 18, 2023A point process for event arrivals in high frequency trading is presented. The intensity is the product of a Hawkes process and high dimensional functions of covariates derived from the order book. Conditions for stationarity of the process are stated. An algorithm is presented to estimate the model even in the presence of billions of data points, possibly mapping covariates into a high dimensional space. The large sample size can be common for high frequency data applications using multiple liquid instruments. Convergence of the algorithm is shown, consistency results under weak conditions is established, and a test statistic to assess out of sample performance of different model specifications is suggested. The methodology is applied to the study of four stocks that trade on the New York Stock Exchange (NYSE). The out of sample testing procedure suggests that capturing the nonlinearity of the order book information adds value to the self exciting nature of high frequency trading events.
ActionPrompt: Action-Guided 3D Human Pose Estimation With Text and Pose Prompting
Jul 18, 2023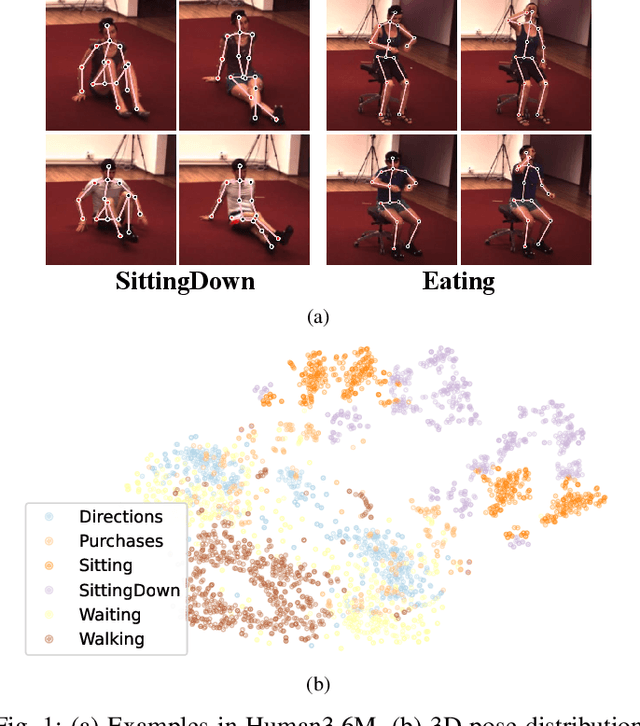
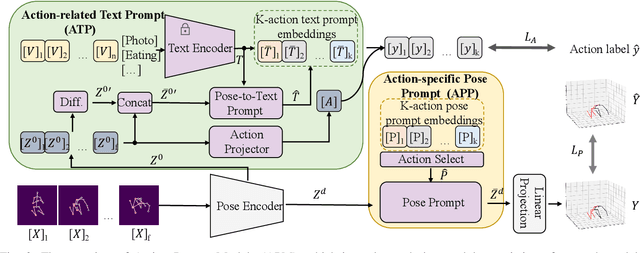
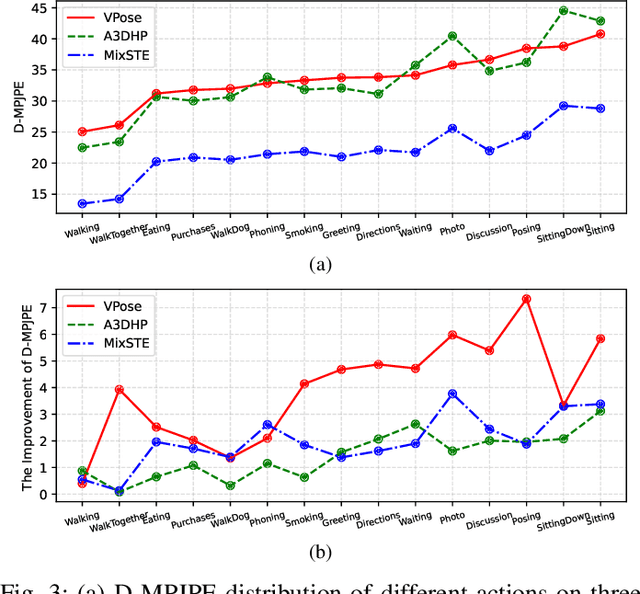
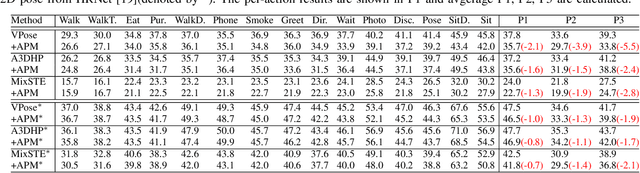
Recent 2D-to-3D human pose estimation (HPE) utilizes temporal consistency across sequences to alleviate the depth ambiguity problem but ignore the action related prior knowledge hidden in the pose sequence. In this paper, we propose a plug-and-play module named Action Prompt Module (APM) that effectively mines different kinds of action clues for 3D HPE. The highlight is that, the mining scheme of APM can be widely adapted to different frameworks and bring consistent benefits. Specifically, we first present a novel Action-related Text Prompt module (ATP) that directly embeds action labels and transfers the rich language information in the label to the pose sequence. Besides, we further introduce Action-specific Pose Prompt module (APP) to mine the position-aware pose pattern of each action, and exploit the correlation between the mined patterns and input pose sequence for further pose refinement. Experiments show that APM can improve the performance of most video-based 2D-to-3D HPE frameworks by a large margin.
Overthinking the Truth: Understanding how Language Models Process False Demonstrations
Jul 18, 2023Modern language models can imitate complex patterns through few-shot learning, enabling them to complete challenging tasks without fine-tuning. However, imitation can also lead models to reproduce inaccuracies or harmful content if present in the context. We study harmful imitation through the lens of a model's internal representations, and identify two related phenomena: overthinking and false induction heads. The first phenomenon, overthinking, appears when we decode predictions from intermediate layers, given correct vs. incorrect few-shot demonstrations. At early layers, both demonstrations induce similar model behavior, but the behavior diverges sharply at some "critical layer", after which the accuracy given incorrect demonstrations progressively decreases. The second phenomenon, false induction heads, are a possible mechanistic cause of overthinking: these are heads in late layers that attend to and copy false information from previous demonstrations, and whose ablation reduces overthinking. Beyond scientific understanding, our results suggest that studying intermediate model computations could be a promising avenue for understanding and guarding against harmful model behaviors.
MLF-DET: Multi-Level Fusion for Cross-Modal 3D Object Detection
Jul 18, 2023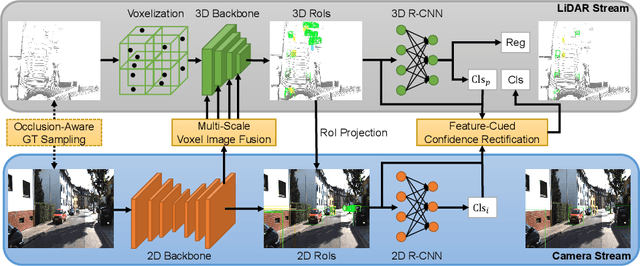
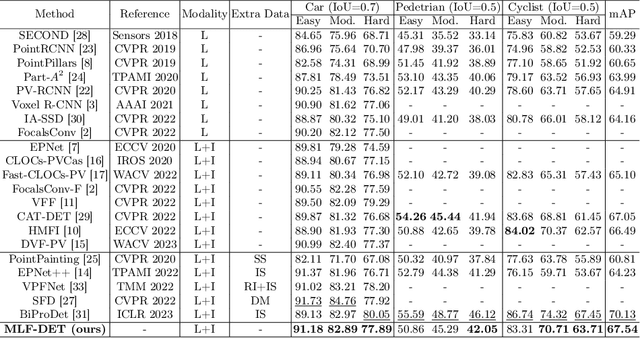
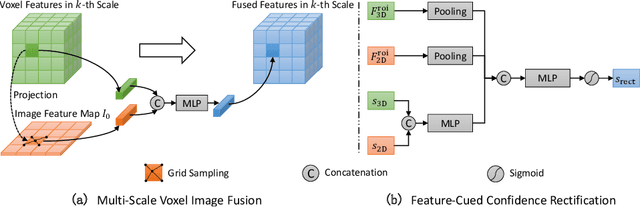
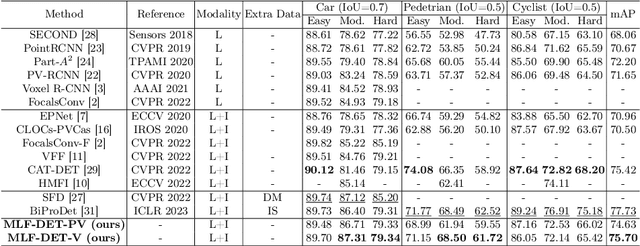
In this paper, we propose a novel and effective Multi-Level Fusion network, named as MLF-DET, for high-performance cross-modal 3D object DETection, which integrates both the feature-level fusion and decision-level fusion to fully utilize the information in the image. For the feature-level fusion, we present the Multi-scale Voxel Image fusion (MVI) module, which densely aligns multi-scale voxel features with image features. For the decision-level fusion, we propose the lightweight Feature-cued Confidence Rectification (FCR) module which further exploits image semantics to rectify the confidence of detection candidates. Besides, we design an effective data augmentation strategy termed Occlusion-aware GT Sampling (OGS) to reserve more sampled objects in the training scenes, so as to reduce overfitting. Extensive experiments on the KITTI dataset demonstrate the effectiveness of our method. Notably, on the extremely competitive KITTI car 3D object detection benchmark, our method reaches 82.89% moderate AP and achieves state-of-the-art performance without bells and whistles.
Text vectorization via transformer-based language models and n-gram perplexities
Jul 18, 2023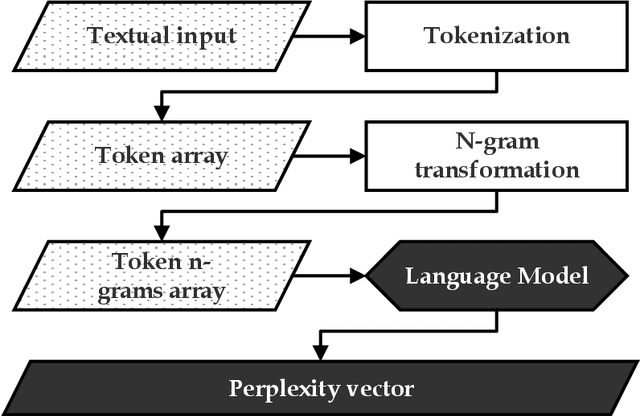

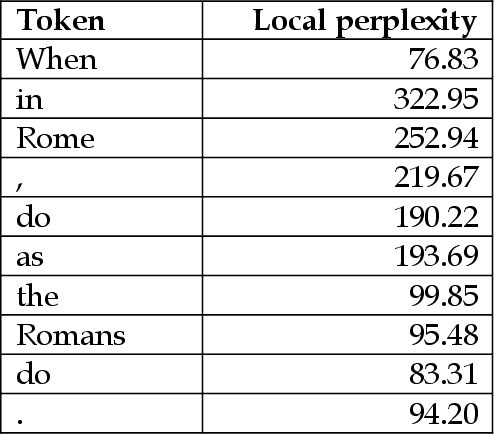
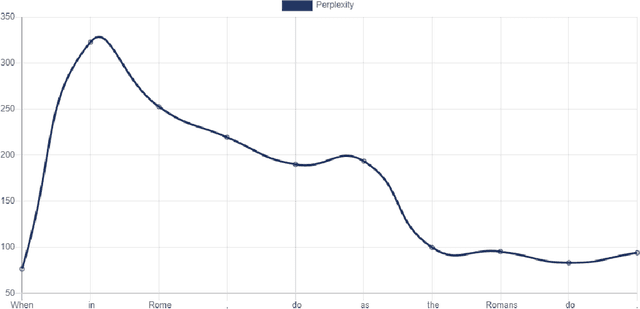
As the probability (and thus perplexity) of a text is calculated based on the product of the probabilities of individual tokens, it may happen that one unlikely token significantly reduces the probability (i.e., increase the perplexity) of some otherwise highly probable input, while potentially representing a simple typographical error. Also, given that perplexity is a scalar value that refers to the entire input, information about the probability distribution within it is lost in the calculation (a relatively good text that has one unlikely token and another text in which each token is equally likely they can have the same perplexity value), especially for longer texts. As an alternative to scalar perplexity this research proposes a simple algorithm used to calculate vector values based on n-gram perplexities within the input. Such representations consider the previously mentioned aspects, and instead of a unique value, the relative perplexity of each text token is calculated, and these values are combined into a single vector representing the input.
Siamese Networks for Weakly Supervised Human Activity Recognition
Jul 18, 2023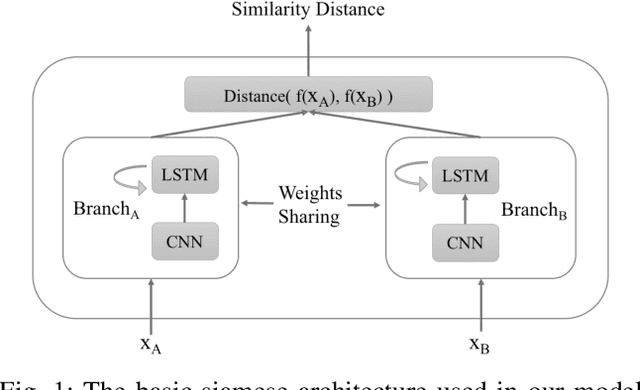
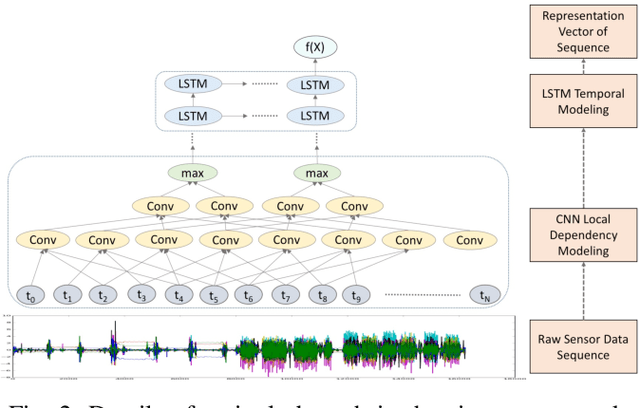
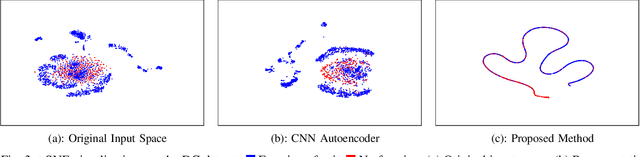
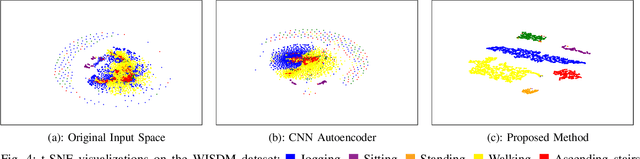
Deep learning has been successfully applied to human activity recognition. However, training deep neural networks requires explicitly labeled data which is difficult to acquire. In this paper, we present a model with multiple siamese networks that are trained by using only the information about the similarity between pairs of data samples without knowing the explicit labels. The trained model maps the activity data samples into fixed size representation vectors such that the distance between the vectors in the representation space approximates the similarity of the data samples in the input space. Thus, the trained model can work as a metric for a wide range of different clustering algorithms. The training process minimizes a similarity loss function that forces the distance metric to be small for pairs of samples from the same kind of activity, and large for pairs of samples from different kinds of activities. We evaluate the model on three datasets to verify its effectiveness in segmentation and recognition of continuous human activity sequences.
MarS3D: A Plug-and-Play Motion-Aware Model for Semantic Segmentation on Multi-Scan 3D Point Clouds
Jul 18, 2023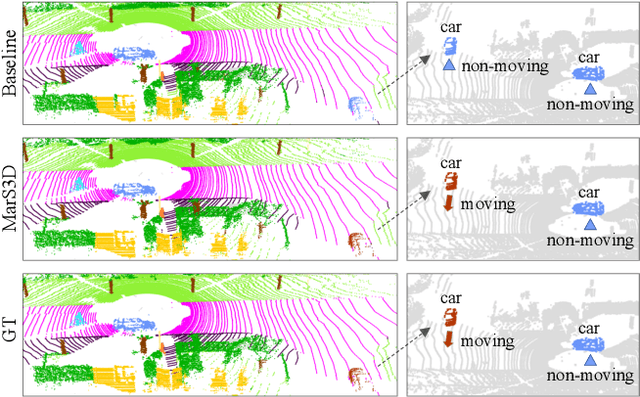
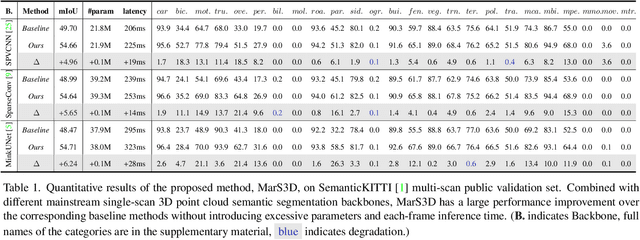
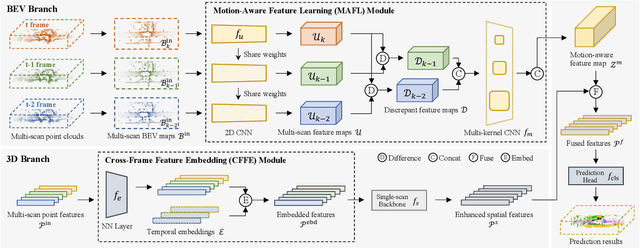
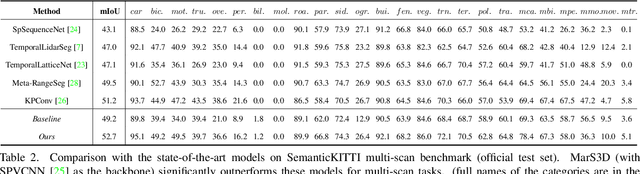
3D semantic segmentation on multi-scan large-scale point clouds plays an important role in autonomous systems. Unlike the single-scan-based semantic segmentation task, this task requires distinguishing the motion states of points in addition to their semantic categories. However, methods designed for single-scan-based segmentation tasks perform poorly on the multi-scan task due to the lacking of an effective way to integrate temporal information. We propose MarS3D, a plug-and-play motion-aware module for semantic segmentation on multi-scan 3D point clouds. This module can be flexibly combined with single-scan models to allow them to have multi-scan perception abilities. The model encompasses two key designs: the Cross-Frame Feature Embedding module for enriching representation learning and the Motion-Aware Feature Learning module for enhancing motion awareness. Extensive experiments show that MarS3D can improve the performance of the baseline model by a large margin. The code is available at https://github.com/CVMI-Lab/MarS3D.
Arbitrary point cloud upsampling via Dual Back-Projection Network
Jul 18, 2023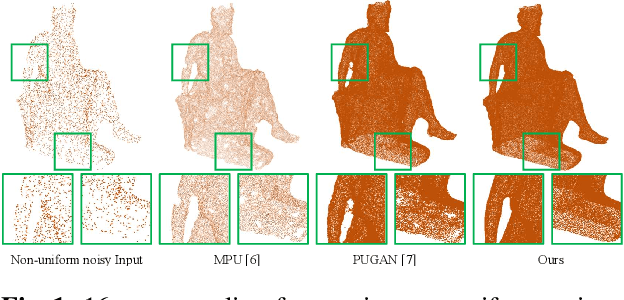
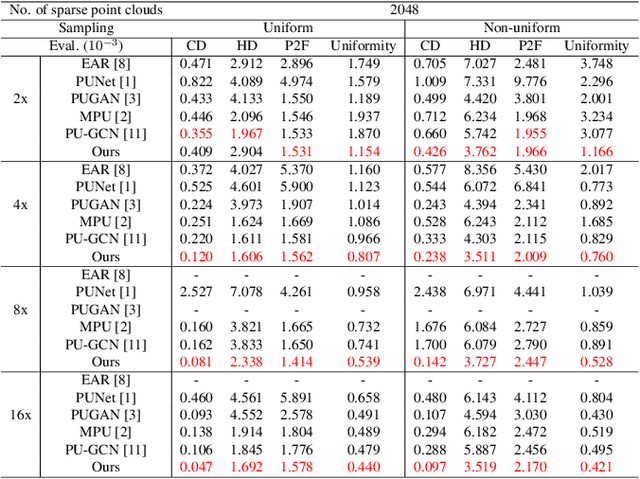
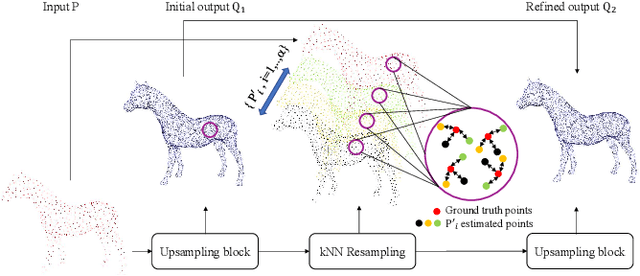
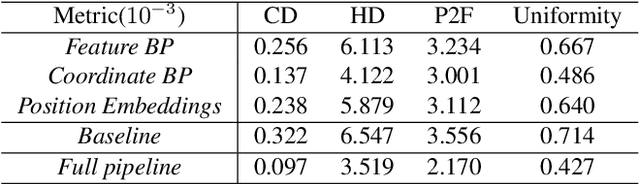
Point clouds acquired from 3D sensors are usually sparse and noisy. Point cloud upsampling is an approach to increase the density of the point cloud so that detailed geometric information can be restored. In this paper, we propose a Dual Back-Projection network for point cloud upsampling (DBPnet). A Dual Back-Projection is formulated in an up-down-up manner for point cloud upsampling. It not only back projects feature residues but also coordinates residues so that the network better captures the point correlations in the feature and space domains, achieving lower reconstruction errors on both uniform and non-uniform sparse point clouds. Our proposed method is also generalizable for arbitrary upsampling tasks (e.g. 4x, 5.5x). Experimental results show that the proposed method achieves the lowest point set matching losses with respect to the benchmark. In addition, the success of our approach demonstrates that generative networks are not necessarily needed for non-uniform point clouds.
* 5 pages, 5 figures
EsaNet: Environment Semantics Enabled Physical Layer Authentication
Jul 18, 2023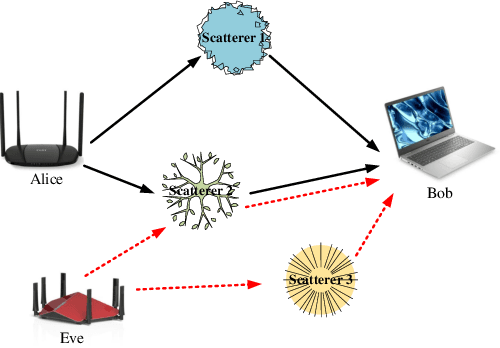
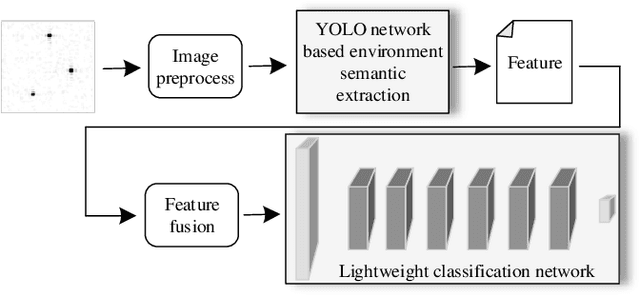
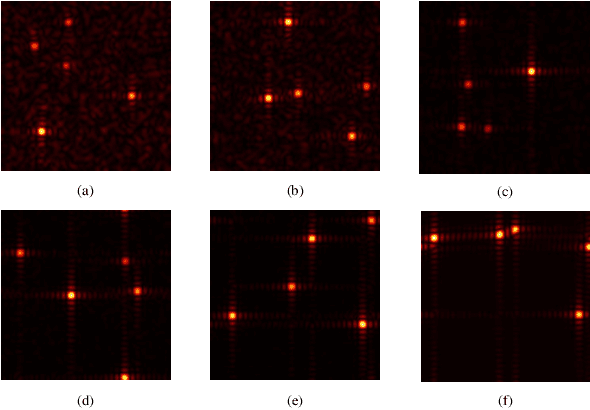
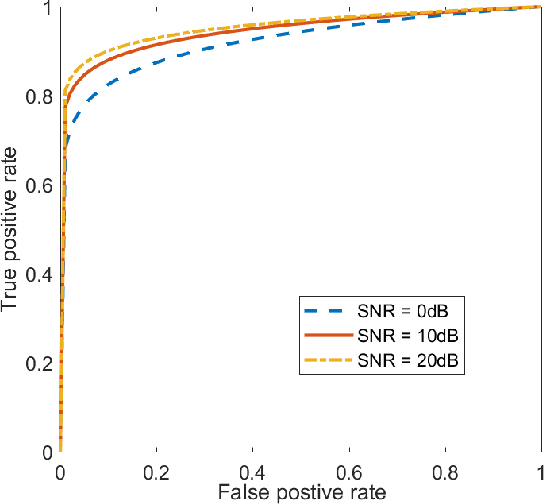
Wireless networks are vulnerable to physical layer spoofing attacks due to the wireless broadcast nature, thus, integrating communications and security (ICAS) is urgently needed for 6G endogenous security. In this letter, we propose an environment semantics enabled physical layer authentication network based on deep learning, namely EsaNet, to authenticate the spoofing from the underlying wireless protocol. Specifically, the frequency independent wireless channel fingerprint (FiFP) is extracted from the channel state information (CSI) of a massive multi-input multi-output (MIMO) system based on environment semantics knowledge. Then, we transform the received signal into a two-dimensional red green blue (RGB) image and apply the you only look once (YOLO), a single-stage object detection network, to quickly capture the FiFP. Next, a lightweight classification network is designed to distinguish the legitimate from the illegitimate users. Finally, the experimental results show that the proposed EsaNet can effectively detect physical layer spoofing attacks and is robust in time-varying wireless environments.