 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Online Lane Graph Extraction by Object-Lane Clustering
Jul 20, 2023
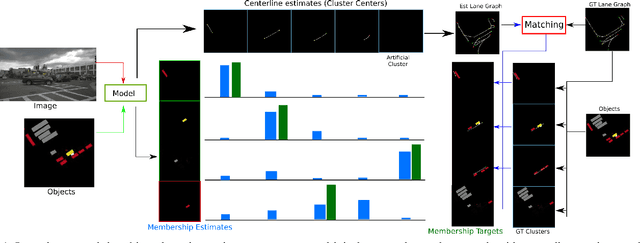
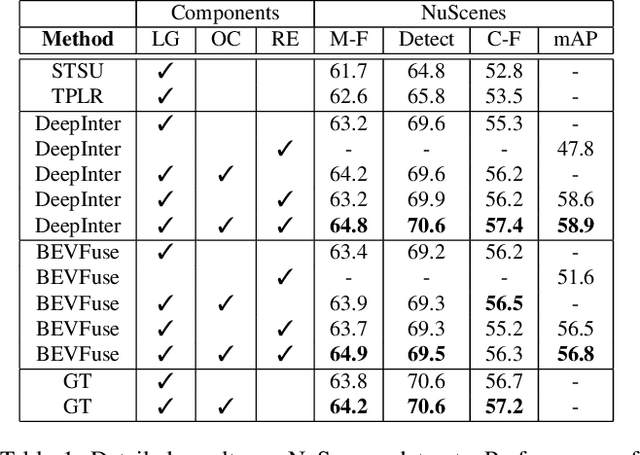
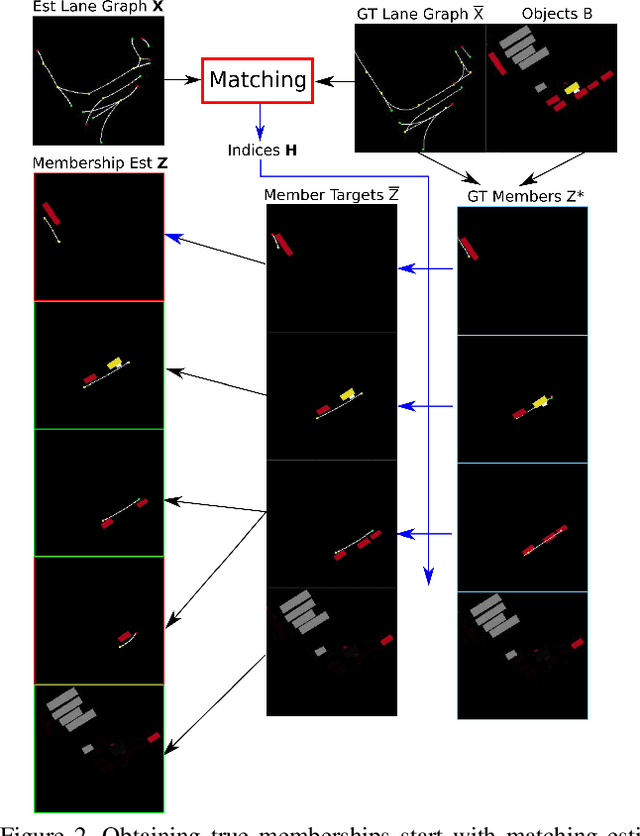
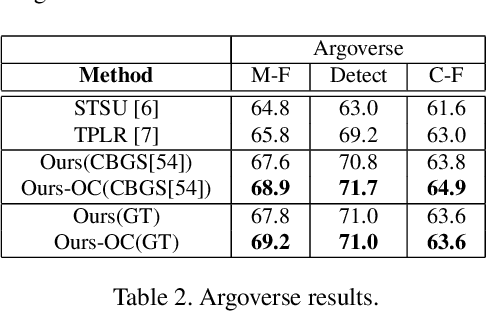
Autonomous driving requires accurate local scene understanding information. To this end, autonomous agents deploy object detection and online BEV lane graph extraction methods as a part of their perception stack. In this work, we propose an architecture and loss formulation to improve the accuracy of local lane graph estimates by using 3D object detection outputs. The proposed method learns to assign the objects to centerlines by considering the centerlines as cluster centers and the objects as data points to be assigned a probability distribution over the cluster centers. This training scheme ensures direct supervision on the relationship between lanes and objects, thus leading to better performance. The proposed method improves lane graph estimation substantially over state-of-the-art methods. The extensive ablations show that our method can achieve significant performance improvements by using the outputs of existing 3D object detection methods. Since our method uses the detection outputs rather than detection method intermediate representations, a single model of our method can use any detection method at test time.
Event Blob Tracking: An Asynchronous Real-Time Algorithm
Jul 20, 2023
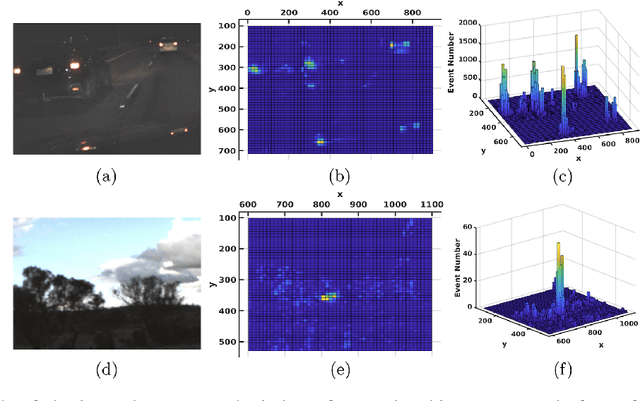
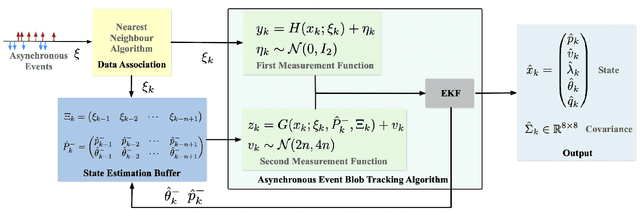
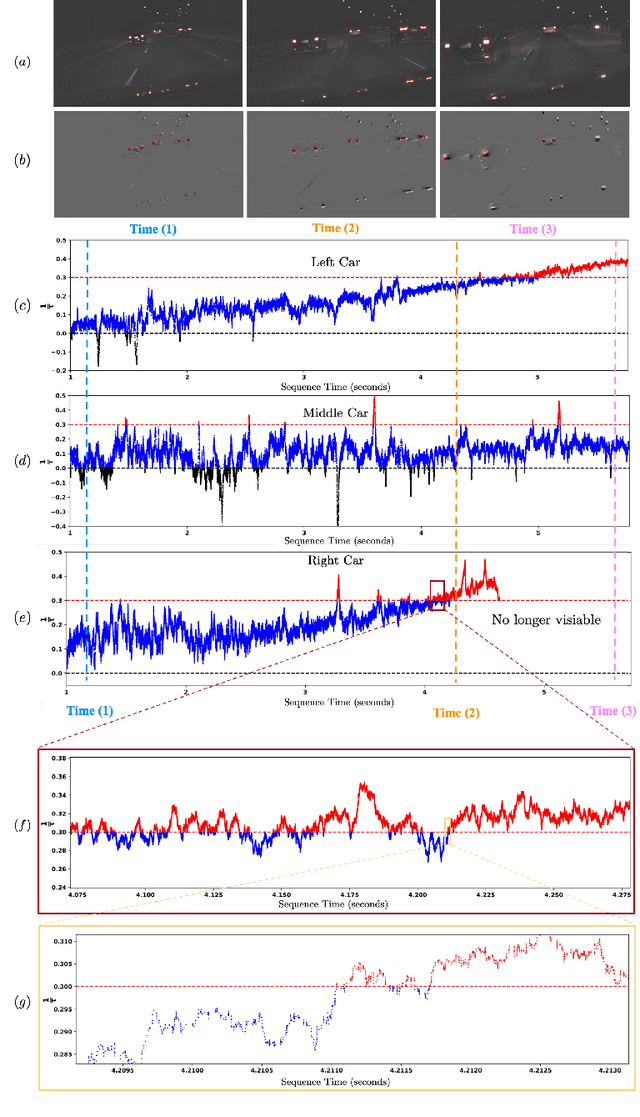
Event-based cameras have become increasingly popular for tracking fast-moving objects due to their high temporal resolution, low latency, and high dynamic range. In this paper, we propose a novel algorithm for tracking event blobs using raw events asynchronously in real time. We introduce the concept of an event blob as a spatio-temporal likelihood of event occurrence where the conditional spatial likelihood is blob-like. Many real-world objects generate event blob data, for example, flickering LEDs such as car headlights or any small foreground object moving against a static or slowly varying background. The proposed algorithm uses a nearest neighbour classifier with a dynamic threshold criteria for data association coupled with a Kalman filter to track the event blob state. Our algorithm achieves highly accurate tracking and event blob shape estimation even under challenging lighting conditions and high-speed motions. The microsecond time resolution achieved means that the filter output can be used to derive secondary information such as time-to-contact or range estimation, that will enable applications to real-world problems such as collision avoidance in autonomous driving.
Learning Discriminative Visual-Text Representation for Polyp Re-Identification
Jul 20, 2023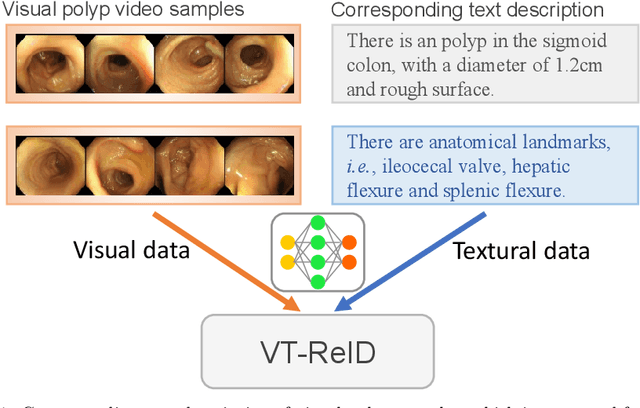

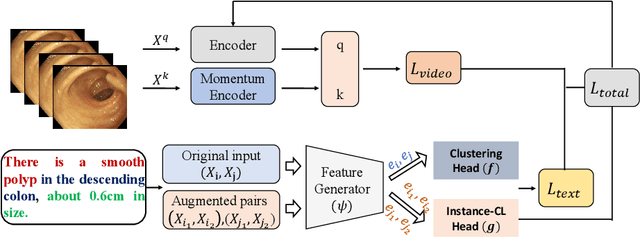
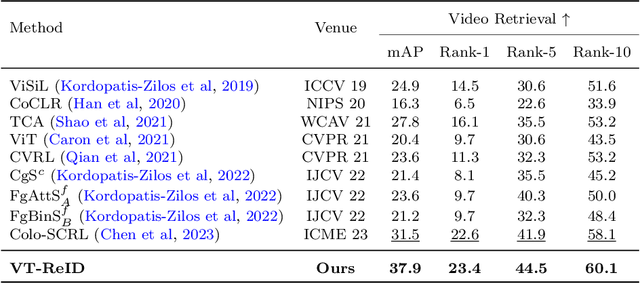
Colonoscopic Polyp Re-Identification aims to match a specific polyp in a large gallery with different cameras and views, which plays a key role for the prevention and treatment of colorectal cancer in the computer-aided diagnosis. However, traditional methods mainly focus on the visual representation learning, while neglect to explore the potential of semantic features during training, which may easily leads to poor generalization capability when adapted the pretrained model into the new scenarios. To relieve this dilemma, we propose a simple but effective training method named VT-ReID, which can remarkably enrich the representation of polyp videos with the interchange of high-level semantic information. Moreover, we elaborately design a novel clustering mechanism to introduce prior knowledge from textual data, which leverages contrastive learning to promote better separation from abundant unlabeled text data. To the best of our knowledge, this is the first attempt to employ the visual-text feature with clustering mechanism for the colonoscopic polyp re-identification. Empirical results show that our method significantly outperforms current state-of-the art methods with a clear margin.
Joint Port Selection Based Channel Acquisition for FDD Cell-Free Massive MIMO
Jul 20, 2023
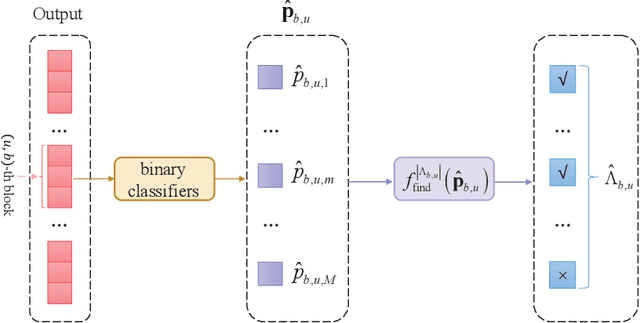
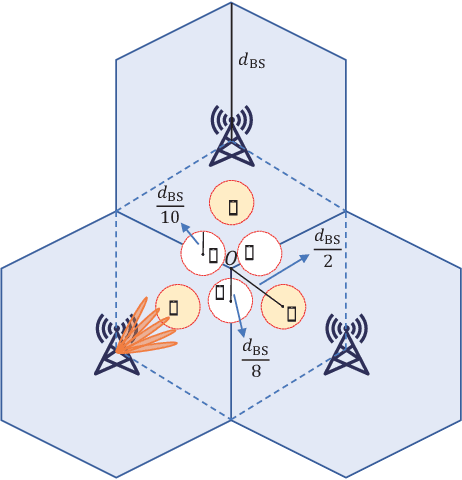
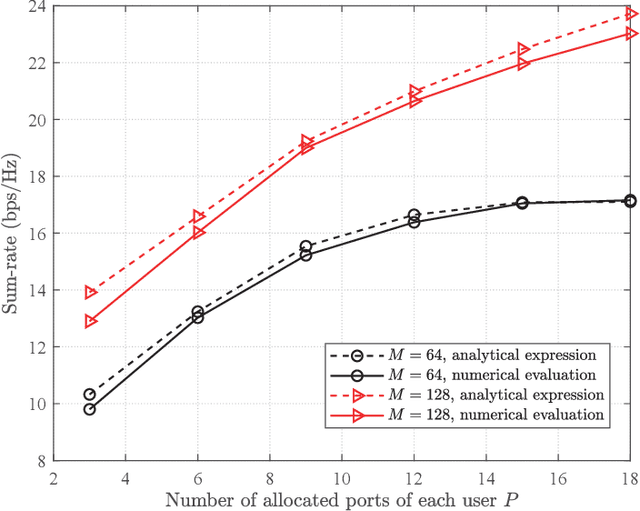
In frequency division duplexing (FDD) cell-free massive MIMO, the acquisition of the channel state information (CSI) is very challenging because of the large overhead required for the training and feedback of the downlink channels of multiple cooperating base stations (BSs). In this paper, for systems with partial uplink-downlink channel reciprocity, and a general spatial domain channel model with variations in the average port power and correlation among port coefficients, we propose a joint-port-selection-based CSI acquisition and feedback scheme for the downlink transmission with zero-forcing precoding. The scheme uses an eigenvalue-decomposition-based transformation to reduce the feedback overhead by exploring the port correlation. We derive the sum-rate of the system for any port selection. Based on the sum-rate result, we propose a low-complexity greedy-search-based joint port selection (GS-JPS) algorithm. Moreover, to adapt to fast time-varying scenarios, a supervised deep learning-enhanced joint port selection (DL-JPS) algorithm is proposed. Simulations verify the effectiveness of our proposed schemes and their advantage over existing port-selection channel acquisition schemes.
DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI
Jul 20, 2023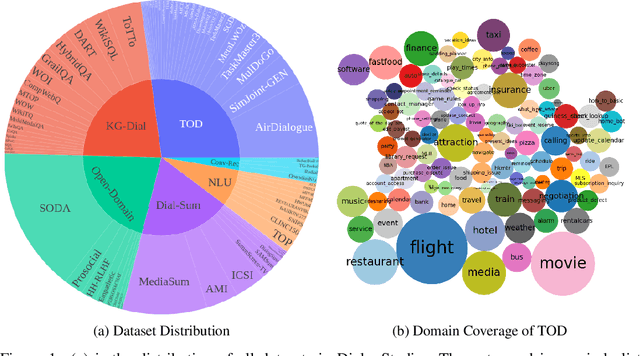

Despite advancements in conversational AI, language models encounter challenges to handle diverse conversational tasks, and existing dialogue dataset collections often lack diversity and comprehensiveness. To tackle these issues, we introduce DialogStudio: the largest and most diverse collection of dialogue datasets, unified under a consistent format while preserving their original information. Our collection encompasses data from open-domain dialogues, task-oriented dialogues, natural language understanding, conversational recommendation, dialogue summarization, and knowledge-grounded dialogues, making it an incredibly rich and diverse resource for dialogue research and model training. To further enhance the utility of DialogStudio, we identify the licenses for each dataset and design domain-aware prompts for selected dialogues to facilitate instruction-aware fine-tuning. Furthermore, we develop conversational AI models using the dataset collection, and our experiments in both zero-shot and few-shot learning scenarios demonstrate the superiority of DialogStudio. To improve transparency and support dataset and task-based research, as well as language model pre-training, all datasets, licenses, codes, and models associated with DialogStudio are made publicly accessible at https://github.com/salesforce/DialogStudio
Addressing caveats of neural persistence with deep graph persistence
Jul 20, 2023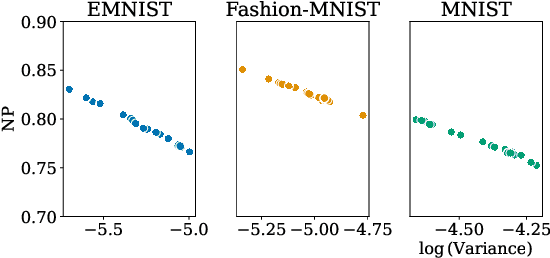
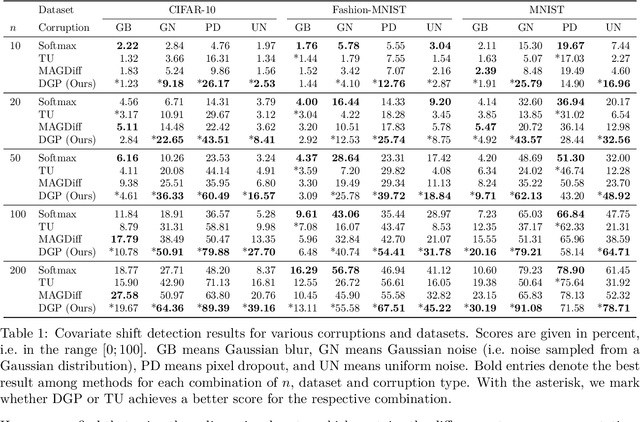
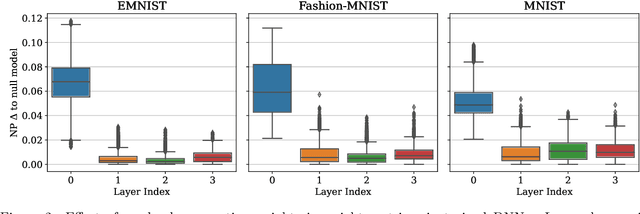
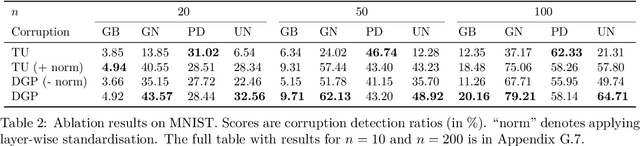
Neural Persistence is a prominent measure for quantifying neural network complexity, proposed in the emerging field of topological data analysis in deep learning. In this work, however, we find both theoretically and empirically that the variance of network weights and spatial concentration of large weights are the main factors that impact neural persistence. Whilst this captures useful information for linear classifiers, we find that no relevant spatial structure is present in later layers of deep neural networks, making neural persistence roughly equivalent to the variance of weights. Additionally, the proposed averaging procedure across layers for deep neural networks does not consider interaction between layers. Based on our analysis, we propose an extension of the filtration underlying neural persistence to the whole neural network instead of single layers, which is equivalent to calculating neural persistence on one particular matrix. This yields our deep graph persistence measure, which implicitly incorporates persistent paths through the network and alleviates variance-related issues through standardisation. Code is available at https://github.com/ExplainableML/Deep-Graph-Persistence .
The Role of Entropy and Reconstruction in Multi-View Self-Supervised Learning
Jul 20, 2023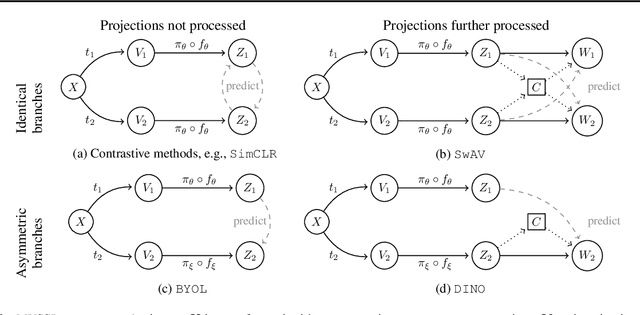
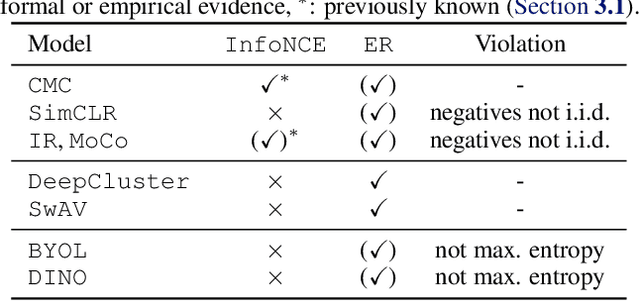
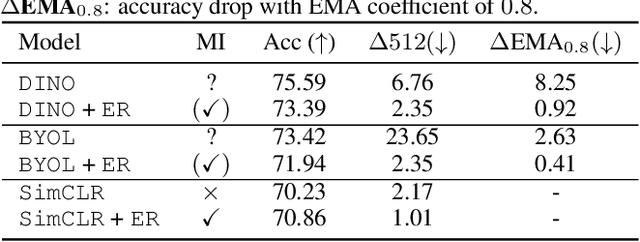
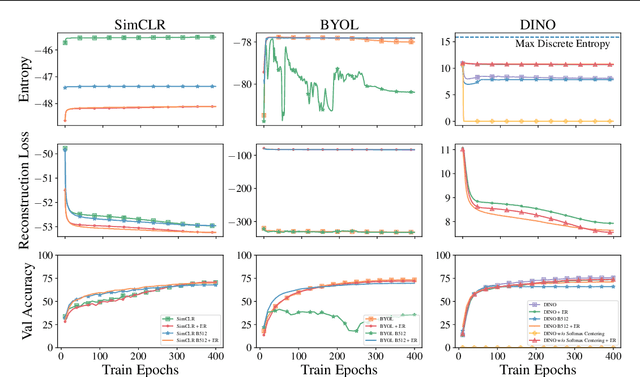
The mechanisms behind the success of multi-view self-supervised learning (MVSSL) are not yet fully understood. Contrastive MVSSL methods have been studied through the lens of InfoNCE, a lower bound of the Mutual Information (MI). However, the relation between other MVSSL methods and MI remains unclear. We consider a different lower bound on the MI consisting of an entropy and a reconstruction term (ER), and analyze the main MVSSL families through its lens. Through this ER bound, we show that clustering-based methods such as DeepCluster and SwAV maximize the MI. We also re-interpret the mechanisms of distillation-based approaches such as BYOL and DINO, showing that they explicitly maximize the reconstruction term and implicitly encourage a stable entropy, and we confirm this empirically. We show that replacing the objectives of common MVSSL methods with this ER bound achieves competitive performance, while making them stable when training with smaller batch sizes or smaller exponential moving average (EMA) coefficients. Github repo: https://github.com/apple/ml-entropy-reconstruction.
Towards Non-Parametric Models for Confidence Aware Image Prediction from Low Data using Gaussian Processes
Jul 20, 2023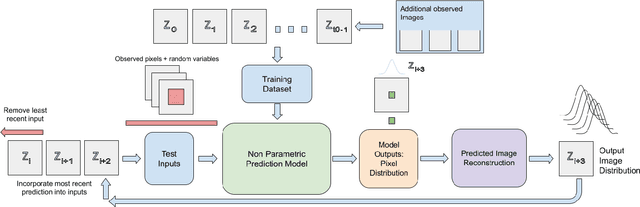
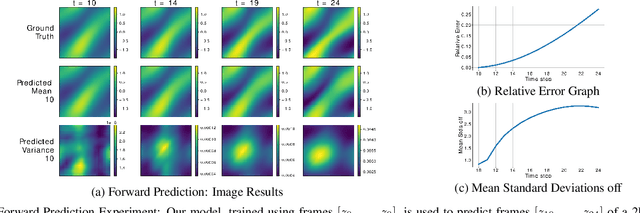

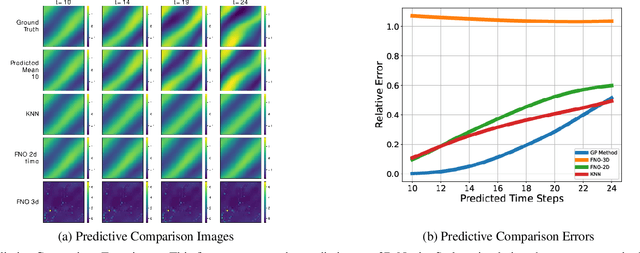
The ability to envision future states is crucial to informed decision making while interacting with dynamic environments. With cameras providing a prevalent and information rich sensing modality, the problem of predicting future states from image sequences has garnered a lot of attention. Current state of the art methods typically train large parametric models for their predictions. Though often able to predict with accuracy, these models rely on the availability of large training datasets to converge to useful solutions. In this paper we focus on the problem of predicting future images of an image sequence from very little training data. To approach this problem, we use non-parametric models to take a probabilistic approach to image prediction. We generate probability distributions over sequentially predicted images and propagate uncertainty through time to generate a confidence metric for our predictions. Gaussian Processes are used for their data efficiency and ability to readily incorporate new training data online. We showcase our method by successfully predicting future frames of a smooth fluid simulation environment.
Extreme Multi-Label Skill Extraction Training using Large Language Models
Jul 20, 2023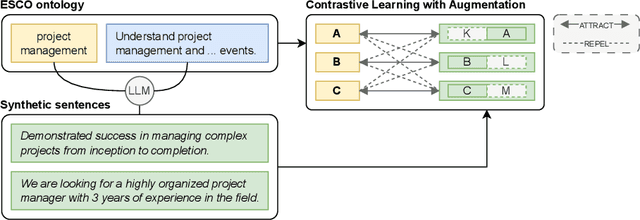
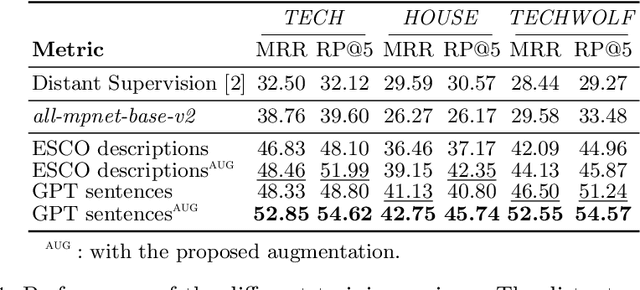
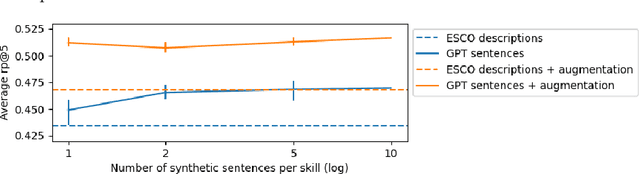
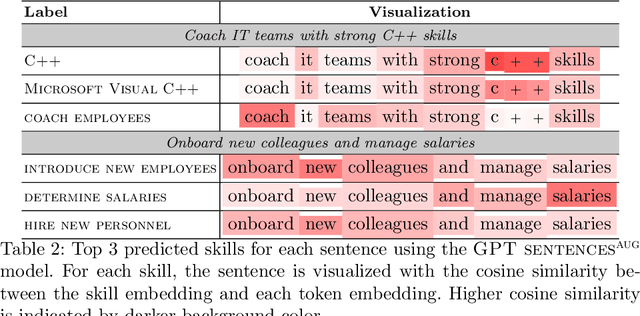
Online job ads serve as a valuable source of information for skill requirements, playing a crucial role in labor market analysis and e-recruitment processes. Since such ads are typically formatted in free text, natural language processing (NLP) technologies are required to automatically process them. We specifically focus on the task of detecting skills (mentioned literally, or implicitly described) and linking them to a large skill ontology, making it a challenging case of extreme multi-label classification (XMLC). Given that there is no sizable labeled (training) dataset are available for this specific XMLC task, we propose techniques to leverage general Large Language Models (LLMs). We describe a cost-effective approach to generate an accurate, fully synthetic labeled dataset for skill extraction, and present a contrastive learning strategy that proves effective in the task. Our results across three skill extraction benchmarks show a consistent increase of between 15 to 25 percentage points in \textit{R-Precision@5} compared to previously published results that relied solely on distant supervision through literal matches.
Quaternion Convolutional Neural Networks: Current Advances and Future Directions
Jul 17, 2023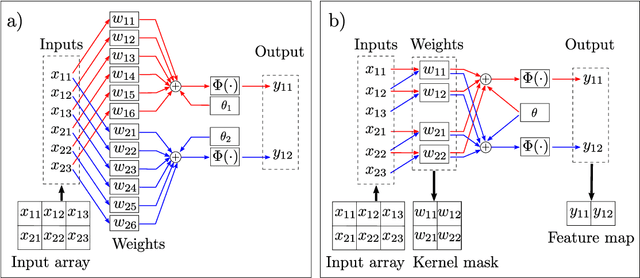
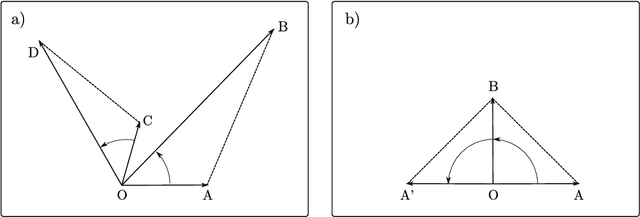
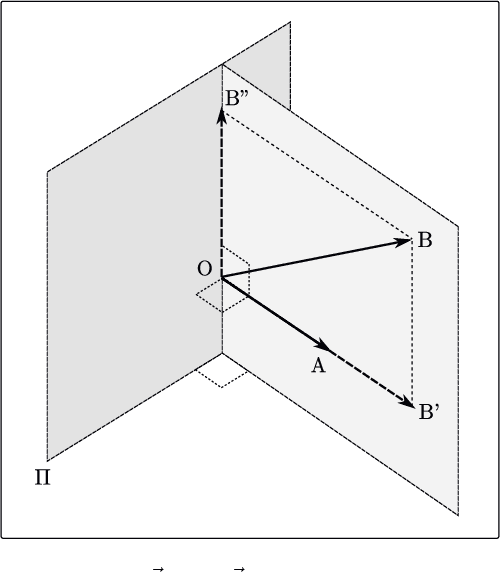
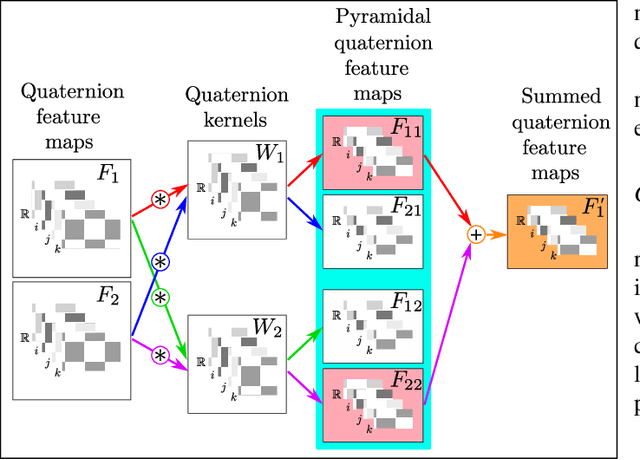
Since their first applications, Convolutional Neural Networks (CNNs) have solved problems that have advanced the state-of-the-art in several domains. CNNs represent information using real numbers. Despite encouraging results, theoretical analysis shows that representations such as hyper-complex numbers can achieve richer representational capacities than real numbers, and that Hamilton products can capture intrinsic interchannel relationships. Moreover, in the last few years, experimental research has shown that Quaternion-Valued CNNs (QCNNs) can achieve similar performance with fewer parameters than their real-valued counterparts. This paper condenses research in the development of QCNNs from its very beginnings. We propose a conceptual organization of current trends and analyze the main building blocks used in the design of QCNN models. Based on this conceptual organization, we propose future directions of research.